J. Cent. South Univ. (2012) 19: 2548-2553
DOI: 10.1007/s11771-012-1309-6
Improved speech absence probability estimation based on environmental noise classification
SON Young-ho1, LEE Sang-min1, 2
1. Department of Electronic Engineering, Inha University, Incheon, 402-751, Korea;
2. Institute for Information and Electronics Research, Inha University, Incheon, 402-751, Korea
? Central South University Press and Springer-Verlag Berlin Heidelberg 2012
Abstract: An improved speech absence probability estimation was proposed using environmental noise classification for speech enhancement. A relevant noise estimation approach, known as the speech presence uncertainty tracking method, requires seeking the “a priori” probability of speech absence that is derived by applying microphone input signal and the noise signal based on the estimated value of the “a posteriori” signal-to-noise ratio (SNR). To overcome this problem, first, the optimal values in terms of the perceived speech quality of a variety of noise types are derived. Second, the estimated optimal values are assigned according to the determined noise type which is classified by a real-time noise classification algorithm based on the Gaussian mixture model (GMM). The proposed algorithm estimates the speech absence probability using a noise classification algorithm which is based on GMM to apply the optimal parameter of each noise type, unlike the conventional approach which uses a fixed threshold and smoothing parameter. The performance of the proposed method was evaluated by objective tests, such as the perceptual evaluation of speech quality (PESQ) and composite measure. Performance was then evaluated by a subjective test, namely, mean opinion scores (MOS) under various noise environments. The proposed method show better results than existing methods.
Key words: speech enhancement; soft decision; speech absence probability; Gaussian mixture model (GMM)
1 Introduction
In recent years, speech enhancement has become an indispensable part of speech coding and speech recognition systems. There are two major considerations in speech enhancement, namely, the estimation of speech and noise power estimation. Conventional noise estimation methods average the noisy signal over the non-speech section using a voice activity detector (VAD) [1-2]. Many approaches to the spectral weighting rule have been investigated in order to achieve speech enhancement. These include spectral subtraction [3-5], soft decision [6-8], and minimum mean-square error (MMSE) criterion [9] approaches. These methods are widely used because they are fairly straightforward to implement, they can remove various ambient noises, and they have a low computational load. However, such methods are sensitive to temporal variation because the presence of speech in each sub-band is inherently estimated by the ratio of the local energy.
Meanwhile, a new class of speech enhancement methods have appeared based on Ref. [10]. MALAH et al [10] proposed the “a priori” probability of speech absence based on a simple hypothesis test by comparing the “a posteriori” signal-to-noise (SNR) with a given threshold. However, the “a priori” probability of speech absence used a fixed threshold and smoothing parameter, and when these fixed values are applied to a variety of noisy environments, speech distortion can be observed.
In this work, we propose an improved speech absence probability estimation which controls the values of the threshold and smoothing parameter according to the noise type rather than a fixed threshold and smoothing parameter as in the conventional method. First, in the proposed method, the optimal parameters are achieved for the highest speech quality depending on each noise from various noises, including both stationary and non-stationary environments. Then, the appropriate threshold and smoothing parameter are assigned according to the noise types classified by the Gaussian mixture model (GMM)-based maximum likelihood (ML) method [11-12] at each frame. The performance of the proposed algorithm is evaluated through the mean opinion score (MOS) [13], the perceptual evaluation of speech quality (PESQ) test and composite measure [14-15].
2 Review of speech presence uncertainty tracking method
We briefly review the speech presence uncertainty tracking method used for gain modification as given in Ref. [10]. First, let  denote the noisy speech signal, where s(i) and n(i) are the speech and noise signals, respectively. Applying a discrete Fourier transform (DFT), we have the following equation in the time-frequency domain:
denote the noisy speech signal, where s(i) and n(i) are the speech and noise signals, respectively. Applying a discrete Fourier transform (DFT), we have the following equation in the time-frequency domain:
 (1)
(1)
where t is the frame index, and k is the frequency bin index.
Given two hypotheses,  and
and  , which respectively indicate speech absence and presence, it is assumed that
, which respectively indicate speech absence and presence, it is assumed that
 (2)
(2)
where  ,
, 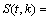
 and
and 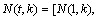
 , respectively. In addition, M is the total number of frequency components.
, respectively. In addition, M is the total number of frequency components.
Based on Gaussian assumption of the clean speech and noise spectra, the probability density functions conditioned on and are assumed to be [8]
 (3)
(3)
where  and
and  are variances of clean speech and noise, respectively.
are variances of clean speech and noise, respectively.
Conditioned on the current observation, , the speech absence probability (SAP),
, the speech absence probability (SAP),  , is given by
, is given by


 (4)
(4)
Here,  is the likelihood ratio computed in the t-th frame and k-th sub-band index as
is the likelihood ratio computed in the t-th frame and k-th sub-band index as

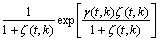 (5)
(5)
where  and
and are the “a posteriori” SNR and the “a priori” SNR [8], which can be respectively written as
are the “a posteriori” SNR and the “a priori” SNR [8], which can be respectively written as
 (6)
(6)
and  is the “a priori” probability of speech absence set to be 0.5 [10]. Value of q has been assumed to be fixed in many previous works. However, MALAH et al [10] proposed a method to allow different q values in different frame bins for each frequency since this number varies in time due to non-stationary of speech. Specifically, in the method of MALAH et al [10], Eq. (4) is re-written as
is the “a priori” probability of speech absence set to be 0.5 [10]. Value of q has been assumed to be fixed in many previous works. However, MALAH et al [10] proposed a method to allow different q values in different frame bins for each frequency since this number varies in time due to non-stationary of speech. Specifically, in the method of MALAH et al [10], Eq. (4) is re-written as
 (7)
(7)
where
 (8)
(8)
Here, αq is a smoothing parameter that is only applied to frames which contain speech section, and I(t, k) is an index function denoting the following hypothesis test by incorporating the “a posteriori” SNR such that
 (9)
(9)
where γTH is a given threshold. Note that, in the method of MALAH et al [10], the availability of a separate estimate of q in each bin for each frame adaptively controls the update of the noise power in the case of speech presence.
3 Proposed speech presence uncertainty method based on noise classification
As mentioned in the previous section, two key parameters of the speech enhancement scheme in Ref. [10], namely, threshold γTH in the “a posteriori” SNR-based hypothesis test and the long-term smoothing parameter αq in the decision distinct values of q, are set to fixed values. However, those parameters should be varied according to the noise type to ensure the best performance. The noise information based on a noise classification algorithm is used for adaptive selection of the parameters in speech enhancement.
3.1 Searching optimal operating values for given noises
The operating values of threshold γTH and smoothing parameter αq are noted. A large smoothing parameter and threshold are desirable to search distinct values of q in the case of non-stationary noises. In the case of the stationary noises, more frequent searching using a smaller smoothing parameter and a lower threshold can be efficient. Based on this motivation, the optimal smoothing parameter and threshold in terms of perceived speech quality are obtained according to the noise classes. For this, we adopt well-known objective quality test that is the composite measure for overall quality, Covl, given by combining the basic objective measures to establish a new measure as follows:
 (10)
(10)
where SPESQ, SLIR, and SWSS represent the perceptual evaluation of speech quality (PESQ) in the ITU-T P.862, the log-likelihood ratio (LLR) and the weighted-slope spectral (WSS) distance, respectively. In Ref. [15], it was shown that the composite measure has a significant correlation with the overall perceptual speech quality as measured by mean opinion score (MOS) testing. By varying threshold γTH and smoothing parameter αq for each noise based on prepared noises, the optimal values designating a highest Covl are obtained. For this, we used the NTT database consisting of a wide variety of speech samples, from which 46 training sentences spoken by two male and two female speakers were prepared. Seven different types of noises such as babble, car, factory, Hf-channel, office, street, and white noise from the NOISEX-92 database were added to the clean speech data at 5, 10, and 15 dB SNRs. Based on this simulation, we identified the optimal values for the given noise types, as listed in Table 1. From the table, it can be seen that the different optimal values are achieved according to different noises. Note that non-stationary noises types, such as babble, factory and office, require a high threshold and a large smoothing parameter. In a similar way, we obtained the 3D mesh curve as a function of the various values of γTH and αq, as plotted in Fig. 1.
Table 1 Optimal threshold and smoothing parameter (frame) selected by comparing composite measure scores
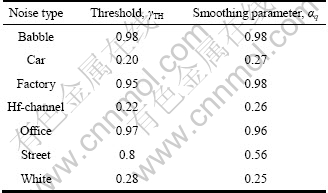
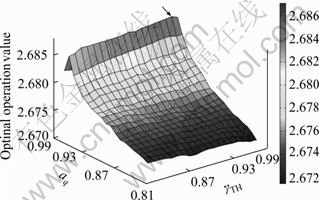
Fig. 1 3D mesh curve of optimal operation values for babble noise 10 dB SNR
3.2 Speech presence uncertainty tracking method based on noise classification
In the previous subsection, optimal values were determined. We should classify the noise signal in real-time to assign the different γTH and αq for different types of noises. This should be done on a frame-by-frame basis during speech pauses for robust classification. For the classification, we should select an effective feature vector characterizing the discrimination among the various noise environments. Based on Ref. [11-12], we chose 10 linear predictive coding (LPC) coefficients, the energy, and the partial residual energy, the running mean of the partial residual energy due to their high classification performance. Using the feature vector, the likelihood for the GMM of a weighted sum of M mixture components is given by
 (11)
(11)
where  , and
, and
 (12)
(12)
Here, αi is the weight for the i-th mixture Gaussian density, x represents an L-dimensional feature vector, μi represents the mean vector, and  is a covariance matrix. These parameters are collectively represented by m, such that
is a covariance matrix. These parameters are collectively represented by m, such that
 (13)
(13)
Based on this, each noise is modeled by the GMM parameter m such as  where s=1 (babble), 2 (car), 3 (factory), 4 (Hf-channel), 5 (office), 6 (street), 7 (white) and 8 (universal background model (UBM)).
where s=1 (babble), 2 (car), 3 (factory), 4 (Hf-channel), 5 (office), 6 (street), 7 (white) and 8 (universal background model (UBM)).
Employing the established model, the current frame is classified into one of the noise types. Indeed, we use the long-term smoothing scheme to prevent abrupt updating such that

 (14)
(14)
where ? is a smoothing parameter. Finally, we classify the noise signal on the current frame t by finding s with the maximum likelihood, assuming that the various types of noise are equally likely as follows:
 (15)
(15)
Figure 2 shows a block diagram of the proposed speech absence probability estimation incorporating GMM. The background noise is not taken into account since we assume that near-end speech absence is not correlated with background noise. It is assumed that S(t, k) and D(t, k) are characterized by separate zero-mean complex Gaussian distribution. Through GMM, each noise type is classified, and then the optimal parameter values are applied to obtain improved speech absence probability. An existing speech presence uncertainty tracking method uses fixed threshold and smoothing parameter values regardless of the noise environment; therefore, this method is unable to accurately determine speech absence or presence, and the comparison of “a posteriori” SNR with the threshold and smoothing parameter is used to decide the “a priori” probability of speech absence by the previous frame weight. To overcome this problem, we use the classified noise information based on  , threshold γTH of Eq. (9) and smoothing parameter αq of Eq. (8), which are substituted for
, threshold γTH of Eq. (9) and smoothing parameter αq of Eq. (8), which are substituted for  and
and  as given in Table 1. Every frame is decided as follows:
as given in Table 1. Every frame is decided as follows:
 (16)
(16)
 (17)
(17)
where we use the long-term smoothing technique to avoid abrupt change of  such that
such that
 (18)
(18)
The smoothing parameter ε is set to be 0.9. Finally, the proposed method devises the speech absence probability estimation based on noise classification information as follows:
 (19)
(19)
Figure 3 shows a typical example in which, it is not difficult to see that the proposed approach is superior to conventional methods, such as, Malah and MCRA method since the proposed method provides a more accurate shape of the corresponding speech segment. As a main application of the proposed technique, a speech enhancement algorithm based on a minimum mean square-error (MMSE) short-time spectral amplitude is adopted, as given by [9]
 (20)
(20)
where  is the estimated clean speech spectrum and
is the estimated clean speech spectrum and  indicates the noise suppression gain. Also,
indicates the noise suppression gain. Also,  and
and are respectively the “a posteriori” SNR and the “a priori” SNR defined by Eq. (6). We only use GMM in speech absence sections to avoid GMM recognition error. In Fig. 4, it is observed that examples of the estimated noise power contour are obtained by the Malah method, MCRA, and the proposed approach in conjunction with the input clean speech waveform and noisy speech waveform. It is demonstrated that the proposed scheme provides a more accurate noise power estimate than previous approaches.
are respectively the “a posteriori” SNR and the “a priori” SNR defined by Eq. (6). We only use GMM in speech absence sections to avoid GMM recognition error. In Fig. 4, it is observed that examples of the estimated noise power contour are obtained by the Malah method, MCRA, and the proposed approach in conjunction with the input clean speech waveform and noisy speech waveform. It is demonstrated that the proposed scheme provides a more accurate noise power estimate than previous approaches.
4 Experimental conditions and results
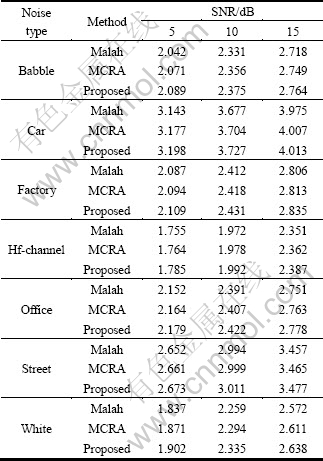
The proposed speech absence probability method was adopted for noise classification algorithm GMM, as in Ref. [10], and was evaluated with extensive objective and subjective tests. For these tests, 96 phrases, spoken by four male and four female speakers, were employed as the experimental data. Each phrase consisted of two different meaningful sentences and lasted for 8 s. Actual noise power estimation was performed for each frame of 10 ms duration with a sampling frequency of 8 kHz. Seven types of noise sources were added to the clean speech waveform at SNRs of 5, 10, and 15 dB. Table 2 gives the PESQ scores under the given noise conditions from the PESQ result. We can see that the proposed approach is superior to or at least comparable to the previous Malah and MCRA methods. Also, the results in terms of the previously mentioned composite measure described in Section 3 are added. Table 3 presents the results in terms of the composite measure for the evaluated noise estimation methods. The proposed method achieves a meaningful performance improvement over the previous methods. We also carried out a set of informal tests under the same noise conditions to evaluate the subjective quality of the proposed method. Subjective opinions were given by a group of 10 listeners; each listener gave a score for each test sentence: 5 (Excellent), 4 (Good), 3 (Fair), 2 (Poor), 1 (Bad). All listener scores were then averaged to yield a mean opinion score (MOS). Table 4 shows that the proposed approach outperforms or is at least comparable to the conventional Malah and MCRA methods under given noise conditions. These results confirm that environmental noise information can be used to effectively improve the subjective quality of speech enhancement.
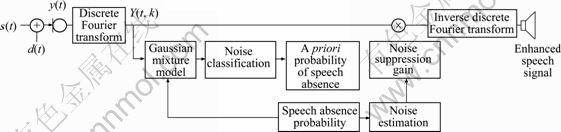
Fig. 2 Block diagram of proposed speech absence probability estimation based on noise classification
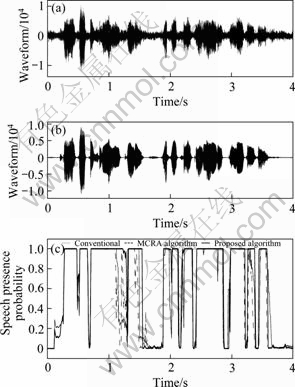
Fig. 3 Comparison of probability (k=3) under babble noise (SNR=10 dB): (a) Noisy speech; (b) Clean speech; (c) Speech presence probability in short-time frame probability
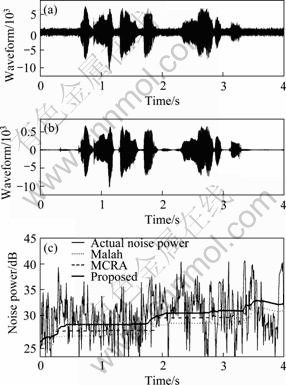
Fig. 4 Comparison of noise power estimation (k=3) under white noise (SNR=10 dB); (a) Noisy speech; (b) Clean speech; (c) Noise power
Table 2 PESQ scores of Malah, MCRA, and proposed methods
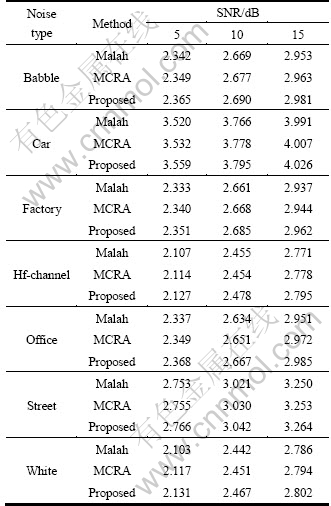
Table 3 Composite measure scores of Malah, MCRA and proposed methods
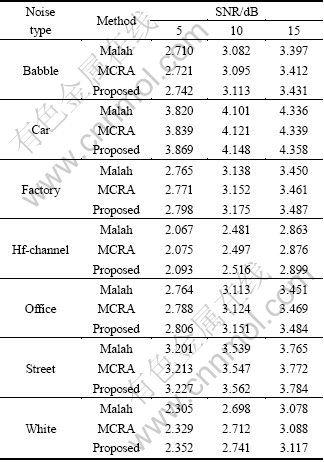
Table 4 MOS scores of Malah, MCRA and proposed methods
5 Conclusions
1) An improved speech absence probability estimation is proposed using a Gaussian mixture model based on noise classification. The principal contribution of this work is the finding the optimal parameter values for a speech presence uncertainty tracking method. Noise types can be divided into two main categories of stationary or non-stationary by testing each noise type.
2) Optimal threshold and smoothing parameter values are varied and applied for each noise type based on the GMM result. Objective and subjective quality tests show that the proposed approach achieves superior performance to the conventional schemes.
References
[1] EPHARIM Y, MALAH D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator [J]. IEEE Trans Acoust, Speech, Signal Process, 1985, ASSP-32(2): 443-445.
[2] SOHN J, KIM N S, SUNG W. A statistical model-based voice activity detection [J]. IEEE Signal Processing Letters, 1999, 6(1): 1-3.
[3] BOLL S F. Suppression of acoustic noise in speech using spectral subtraction [J]. IEEE Trans Acoust, Speech, Signal Process, 1979, ASSP-27(2): 113-120.
[4] LIM J S, OPPENHEIM A V. Enhancement and bandwidth compression of noisy speech [J]. IEEE Trans Acoust, Speech, Signal Process, 1979, ASSP-67(12): 1583-1604.
[5] GOMEZ R, KAWAHARA T. Optimizing spectral subtraction and wiener filtering for robust speech recognition in reverberant and noisy conditions [C]// Proc ICASSP. Dallax, TX, USA, 2010: 4566-4569.
[6] MCAUALY R J, MALPASS M L. Speech enhancement using a soft-decision noise suppression filter [J]. IEEE Trans Acoust, Speech, Signal Processing, 1980, 28(2): 137-145.
[7] SCALART P, FILHO J W. Speech enhancement based on a priori signal to noise estimation [C]. Proc ICASSP. Atlanta, GA, USA, 1996: 629-632.
[8] KIM N S, CHANG J H. Spectral enhancement based on global soft decision [J]. IEEE Signal Processing Letters, 2000, 7(5): 108-110.
[9] EPHRAIM Y, MALAH D. Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator [J]. IEEE Trans Acoust, Speech, Signal Process, 1984, ASSP-32(6): 1109-1121.
[10] MALAH Y D, CPX R, ACCARDI A. Tracking speech presence uncertainty to improve speech enhancement in non-stationary noise environments [C]// Proc IEEE Int Conf Acoustics Speech and Signal Processing. Phoenix, AZ, USA, 1999: 789-792.
[11] XUAN G, ZHANG W, CHAI P. EM algorithm of Gaussian mixture model and hidden Markov model [C]. Proc IEEE International Conference on Image Processing. Thessaloniki, 2001: 145-148.
[12] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted Gaussian mixture models [J]. Digital Signal Processing, 2000, 10: 19-41.
[13] SEOKHWAN Jo, CHANG D YOO. Psychoacoustically constrained and distortion minimized speech enhancement [J]. IEEE Transactions on Audio Speech and Language Processing, 2010, 18(8): 2099-2110.
[14] ITU-T P.862. Perceptual evaluation of speech quality (PESQ), an objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs [R]. 2001.
[15] HU Y, LOIZOU P C. Evaluation of objective quality measures for speech enhancement [J]. IEEE Transactions on Audio, Speech and Language Processing, 2008, 16(1): 229-238.
(Edited by YANG Bing)
Foundation item: Project supported by an Inha University Research Grant; Project(10031764) supported by the Strategic Technology Development Program of Ministry of Knowledge Economy, Korea
Received date: 2011-10-25; Accepted date: 2012-02-29
Corresponding author: Lee Sang-min, Professor, PhD; Tel: +82-32-860-7420; E-mail: sanglee@inha.ac.kr

