J. Cent. South Univ. (2013) 20: 424�C432
DOI: 10.1007/s11771-013-1503-1

Speech enhancement through voice activity detection using speech absence probability based on teager energy
ParkYun-sik1, Lee Sang-min1, 2
1. Department of Electronic Engineering, Inha University, Incheon 402-751, Korea;
2. Institute for Information and Electronics Research, Inha University, Incheon 402-751, Korea
 Central South University Press and Springer-Verlag Berlin Heidelberg 2013
Central South University Press and Springer-Verlag Berlin Heidelberg 2013
Abstract: In this work, a novel voice activity detection (VAD) algorithm that uses speech absence probability (SAP) based on Teager energy (TE) was proposed for speech enhancement. The proposed method employs local SAP (LSAP) based on the TE of noisy speech as a feature parameter for voice activity detection (VAD) in each frequency subband, rather than conventional LSAP. Results show that the TE operator can enhance the ability to discriminate speech and noise and further suppress noise components. Therefore, TE-based LSAP provides a better representation of LSAP, resulting in improved VAD for estimating noise power in a speech enhancement algorithm. In addition, the presented method utilizes TE-based global SAP (GSAP) derived in each frame as the weighting parameter for modifying the adopted TE operator and improving its performance. The proposed algorithm was evaluated by objective and subjective quality tests under various environments, and was shown to produce better results than the conventional method.
Key words: speech enhancement; Teager energy; speech absence probability; voice activity detection
1 Introduction
The performance and speech quality of most current speech processing systems is degraded by various background noises. This problem can be alleviated through a speech enhancement technique that reduces background noise before being encoded by the speech coding system, thereby enabling enhanced speech quality [1�C3]. Most speech enhancement techniques consider relevant procedures, such as calculating the gain in noise suppression, selecting adequate statistical models of speech, and estimating noise power [2�C5]. With the wide dissemination of mobile speech communication, the estimation of noise power has received particular attention, due to the nonstationary characteristics of the noise signal and the difficulty of estimating background noise in low SNR (signal-to-noise ratio) noise environments.
One method widely used to estimate noise power is to update the noise power estimated with a voice activity detection (VAD) algorithm during a nonspeech segment [6�C9]. VAD algorithms are usually designed to detect the presence or absence of speech by using certain decision rules that are derived from various feature parameters which distinguish speech segments from other waveforms. Such parameters are typically based on short-time energy, spectral energy, or zero-crossing rate (ZCR). However, all of these parameters are rather sensitive to noise and cannot fully specify the characteristics of a speech signal. Therefore, several other parameters have also been proposed, including power spectral deviation (PSD), linear prediction coefficients (LPCs), likelihood ratio (LR), and pitch [6�C8].
One of the feature parameters which is widely adopted in the decision rule for VAD is speech absence probability (SAP), which is derived from LR based on statistical models in each frequency subband or each frame. SAP is used as a smoothing parameter for updating noise power in the speech enhancement algorithm [5, 8�C9]. Although these parameters are quite effective for expressing the characteristics of a speech signal, VAD using such parameters still perform poorly in adverse environments. Therefore, to improve the performance of the VAD algorithm, a feature parameter that can sufficiently specify the characteristics of speech and be robust in noisy environments is urgently needed.
In this work, we propose a novel approach to the
VAD algorithm based on Teager energy (TE) [7�C8] which is used to derive SAP for improving the VAD performance in various noisy environments. The TE operator, which provides better characteristics for separating speech from noise, is employed to suppress the influence of a noise signal [10�C13]. Experimental results show that the TE operator can enhance the ability to discriminate between speech and noise and further suppress the components of noise. Therefore, in the proposed method, TE-based local SAP (LSAP) derived in each frequency subband is used as a feature parameter for VAD, rather than conventional LSAP. The proposed VAD method improves the performance of the speech enhancement algorithm in noisy environments. In addition, this method utilizes TE-based global SAP (GSAP) derived in each frame as a weighting parameter for modifying the adopted TE operator and improving the performance of the TE operator.
The performance of the proposed algorithm is evaluated by speech spectrogram, a perceptual evaluation of speech quality (PESQ, ITU-T P.862), the composite measure [14] and mean opinion score (MOS), and it is consequently demonstrated to perform better than the conventional method.
2 Review of teager energy operator
In this section, we briefly review the Teager energy (TE) operator, which is used to suppress the influence of a noise signal. By effectively suppressing corrupted noise, the TE operator improves the ability to discriminate speech characteristics from noise. The TE operator is easily implemented through the time domain, as presented in Refs. [10�C11].
 (1)
(1)
where s(t) is a continuous-time signal, and  . In discrete-time, the TE operator can be approximated by
. In discrete-time, the TE operator can be approximated by
 (2)
(2)
where s(n) is a discrete-time signal. A clean speech signal s(n) is corrupted by an additive noise signal d(n). Assuming that speech is degraded by uncorrelated additive noise, the observed noisy speech signal y(n) is given by
 (3)
(3)
where s(n) and d(n) are zero mean and independent, respectively. Based on this, the TE of y(n) is obtained by
 (4)
(4)
where Y [y(n)], Y [s(n)] and Y [d(n)] are the TE of noisy speech, clean speech, and additive noise, respectively. Also, the cross-TE  of s(n) and d(n) can be computed as
of s(n) and d(n) can be computed as

 (5)
(5)
Since s(n) and d(n) are zero mean and independent, the expected value of the cross-TE is equal to zero. Thus, the expected value of Y [y(n)] is approximated as
 (6)
(6)
In fact, the TE of clean speech is much higher than that of noise. Therefore, Y [d(n)] is negligible compared to Y[d(n)], as given in Refs. [10�C11]:
 (7)
(7)
For this reason, the TE operator can suppress noise signals and provide better discrimination between speech and noise. Therefore, in noisy environments, TE-based feature parameters can enhance the ability to discriminate speech and noise for more effective VAD.
3 Proposed VAD using speech absence probability based on teager energy
As explained in the previous section, the TE operator suppresses noise signals and improves the ability to discriminate between speech and noise. Thus, we propose a novel VAD algorithm using SAP (LSAP and GSAP) based on TE. SAP based on the likelihood ratio employing statistical models has been shown to be a good feature parameter for detecting the presence of speech in noisy environments [5, 9]. However, in adverse noise conditions, VAD algorithms using SAP as a feature parameter still perform poorly. Therefore, in order to take advantage of TE for VAD, the proposed method derives a novel feature parameter using TE-based LSAP (TE-LSAP), instead of the conventional LSAP. In addition, the presented method utilizes TE-based GSAP (TE-GSAP) as a weighting parameter for modifying the adopted TE operator and improving the performance of the TE operator. Figure 1 presents an overall block diagram of the proposed VAD algorithm, which utilizes the proposed TE-LSAP and TE-GSAP. Here, we assume that the following two hypotheses, H0 and H1, indicate speech absence and presence from the enhanced signal derived from the TE operator [9]:

 (8)
(8)
where Y [Y(i, k)] denotes an estimate of the Fourier spectrum of noisy speech based on the TE compared to the conventional Fourier spectrum Y(i, k) with a time index i and frequency index k in the discrete Fourier transform (DFT) domain. Also, Y [D(i, k)] and Y [S(i, k)] represent the Fourier spectra derived from the TE of the noise and clean speech signal, respectively. Under the assumption that Y [D(i, k)] and Y [S(i, k)] are statistically independent, Y [D(i, k)] and Y [S(i, k)] are characterized by zero-mean complex Gaussian distributions, such that [9]:
 (9)
(9)

 (10)
(10)
where ss(i, k) and sd(i, k) are the variance of the speech and estimated noise based on the TE, respectively. Accordingly, the TE-LSAP p(H0|Y [Y(i, k)] is derived from Bayes�� rule, such that [9]

 (11)
(11)
where q=p(H1)/p(H0) and p(H0) represents the a priori probability of speech absence. Substituting Eqs. (9) and (10) into Eq. (11), the likelihood ratio L(Y [Y(i, k)] can be computed in the k-th frequency bin, as given by [9]
 (12)
(12)
where the TE-based a posteriori SNR h(i, k) and the TE-based a priori SNR z(i, k) are defined by [9]
 (13)
(13)
 (14)
(14)
Based on this, in the proposed VAD algorithm using TE-LSAP p(H0|Y[Y(i, k)], speech segments are decided by the decision rule as
 (15)
(15)
where the threshold value T is experimentally determined to be 0.9 based on a large number of noisy speech data samples containing a variety of noises and SNR conditions.
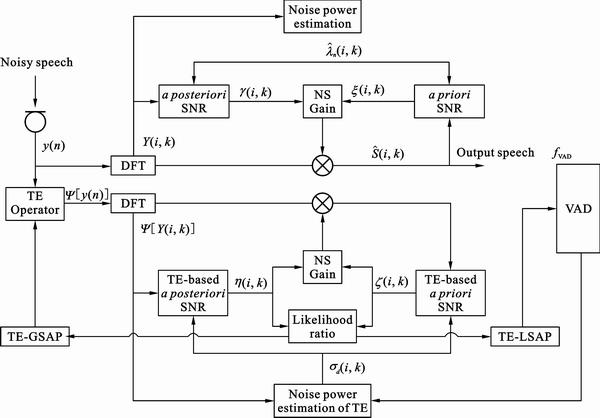
Fig. 1 Block diagram of proposed VAD algorithm for speech enhancement
In addition, the proposed VAD algorithm is further improved by modifying TE 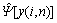 which is derived by the weighting parameter WTE�CGSAP(i) based on TE-GSAP to improve the ability to discriminate between speech and noise in the frame of index i, as given by
which is derived by the weighting parameter WTE�CGSAP(i) based on TE-GSAP to improve the ability to discriminate between speech and noise in the frame of index i, as given by
 (16)
(16)
where WTE�CGSAP(i) is the TE-GSAP smoothed by a recursive averaging as
 (17)
(17)
where the smoothing parameter is set as 0.9. Since the spectral component in each frequency bin is assumed to be statistically independent, TE-GSAP p(H0|Y[Y(i, k)] is obtained by [5]
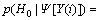

 (18)
(18)
where Y [Y(i)]={Y [Y(i, 1)], Y [Y(i, 1)], ������, Y [Y(i, M)]}.
Figure 2 shows the estimates of TE obtained by the conventional TE operator and by the proposed method based on TE-GSAP. Figure 2(c) show that the weighting parameter based on TE-GSAP is close to zero during speech segments. Thus, when speech is present, the reduced value, as compared to y(n+1)y(n�C1), is subtracted from the energy of noisy speech y(n), and the high value of noisy speech is maintained. On the other hand, the weighting parameter is close to one during nonspeech segments, so when speech is absent, the energy of the noise signal is greatly reduced by the conventional TE operator. Therefore, the proposed scheme using the weighting parameter based on TE-GSAP can improve speech enhancement by providing better discrimination between speech and noise. The difference of TE estimated by the conventional TE operator and by the proposed TE-GSAP method is shown in Fig. 2(d), which shows that the estimated TE derived from the proposed method is more accurate than that of the conventional method when compared with the waveform of the clean speech signal.
Finally, Fig. 3 demonstrates how, as compared to the conventional method, the proposed method improves the a posteriori SNR and LSAP for VAD in conjunction with the input clean speech waveform and noisy speech waveform. Figure 3(c) indicates that, for low input SNR, the conventional LSAP scheme produces an inadequate estimation of a posteriori SNR, since weak speech components are not easily detected in an adverse environment. However, the proposed TE-LSAP method takes advantage of TE to improve the a posteriori SNR, as compared to the conventional LSAP. Also, when both TE-LSAP and TE-GSAP (TE-LSAP & TE-GSAP) are applied to the VAD algorithm, the most effective a posteriori SNR estimate is derived by employing the enhanced noisy speech based on the TE, especially at low input SNR.
Figure 3(d) describes the difference the LSAP of the conventional method versus those of the proposed method. Although the conventional LSAP is quite effective in expressing the characteristics of a speech signal when the speech components are relatively strong, the performance of VAD using such LSAP remains poor at low SNR. Figure 3(d) shows that the LSAP estimation of the conventional scheme does not sufficiently discriminate between speech and noise, since the conventional LSAP estimate is sensitive to noise. On the contrary, in the given noisy conditions, the proposed method featuring TE-LSAP estimation performs well, since the TE operator discriminates well between speech and noise. Additionally, the proposed method based on TE-LSAP & TE-GSAP represents the most improved LSAP estimate among the adopted methods. Finally, Fig. 3 demonstrates that the advantages of the proposed method are particularly notable in adverse environments involving weak speech components and low input SNR.
Based on these results, the noise power estimate  can be updated during nonspeech segments, as determined by the VAD algorithm, based on Eq. (15), with the following averaging rule:
can be updated during nonspeech segments, as determined by the VAD algorithm, based on Eq. (15), with the following averaging rule:
 (19)
(19)
where the smoothing parameter an is set as 0.9.
Under the assumption that the spectral components of the input signal at the microphone are statistically independent, the noise suppression filter based on the minimum mean-square error (MMSE) estimator is employed to obtain the spectral estimate of the clean speech from the observed noisy speech Y(i, k). It is useful to consider the estimated speech spectrum  as being achieved from Y(i, k) by a multiplicative gain function GMMSE(��,��), given as [2]
as being achieved from Y(i, k) by a multiplicative gain function GMMSE(��,��), given as [2]
 (20)
(20)
where the gain GMMSE(��,��) of the MMSE estimator is given by [2]
 (21)
(21)
where I0 and I1 are modified Bessel functions of zero and first order, respectively. Also,u(i, k) is defined as
Fig. 2 TE derived by conventional and proposed algorithms (white noise, SNR of 5 dB);
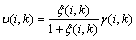 (22)
(22)
where the a posteriori SNR g(i, k) and the a priori SNR x(i, k) are defined by [2]
 (23)
(23)
 (24)
(24)
where ls (i, k) is the estimated speech power and x(i, k)is derived by employing the decision-directed (DD) method to estimate the unknown parameters [2].
4 Performance evaluations
The proposed VAD method was integrated into the speech enhancement algorithm using the suppression gain based on MMSE estimation [2], and was evaluated with both objective and subjective quality comparison experiments under various noise conditions. For experimental data, we used 90 test phrases with a sampling rate of 8 kHz. Each phrase lasted 8 s and consisted of two different meaningful sentences. Three types of noise sources (white, babble, and vehicle noise) from the NOISEX-92 database were added to the clean speech waveform at SNRs of 5, 10 and 15 dB. In addition, to compare performance, we evaluated the objective and subjective quality of output signals obtained by speech enhancement algorithms based on VAD algorithms using both the conventional and proposed schemes.
First, in order to objectively evaluate the performance, we adopted a speech spectrogram and an objective quality test PESQ, which is a worldwide industry standard for objective speech quality testing. We also used the composite measure Covl to evaluate the correlations between several objective measures using the following three subjective rating scales: signal/noise distortions and overall quality, as given by [14]
 (25)
(25)
where SPESQ, SLLR, and SWSS represent the PESQ, the log-likelihood ratio (LLR) and the weighted-slope spectral (WSS) distance, respectively.
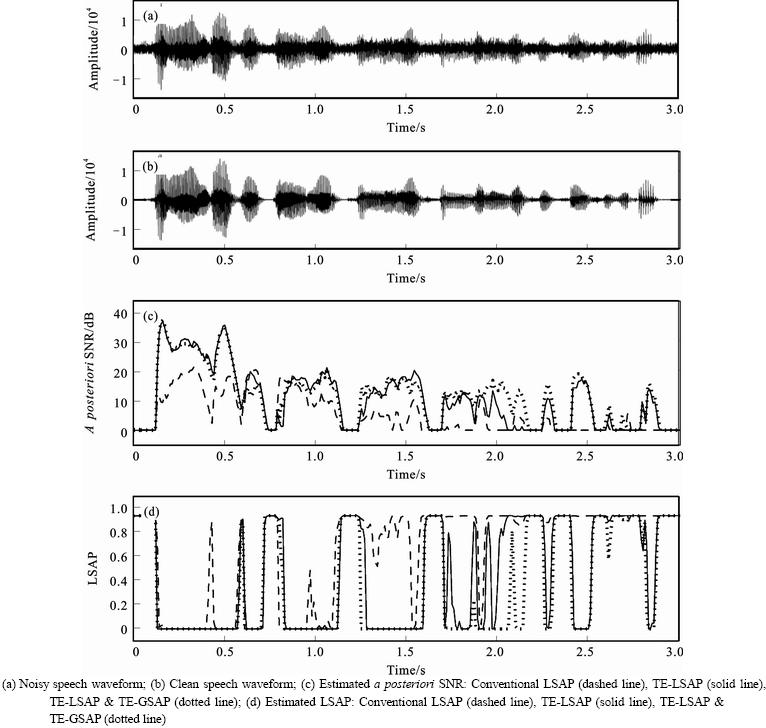
Fig. 3 A posteriori SNR and LSAP estimated by conventional and proposed algorithms (white noise, SNR of 5 dB);
Figures 4 and 5 show the speech spectrograms obtained with the conventional and proposed methods, to provide an easy analysis of the differences in performance. From Figs. 4(d) and 5(d), we can see that the proposed TE-LSAP method is superior to the LSAP-based method. Also, the data in Figs. 4(e) and 5(e) were obtained by the proposed method based on TE-LSAP & TE-GSAP, and it can be seen that the proposed TE-LSAP & TE-GSAP scheme suppresses the background noise more effectively than both the conventional method and the proposed TE-LSAP method. Figures 4(f) and 5(f) show the power of the enhanced output speech obtained by the conventional and the proposed methods, respectively. The results indicate that the proposed TE-LSAP approach outperformed or was at least comparable to the conventional LSAP method, while the proposed method based on TE-LSAP & TE-GSAP performed better than the others.
Table 1 shows the PESQ scores under the given noise conditions. From the PESQ results, we can see that the proposed TE-LSAP method is superior to the previous method based on LSAP. Furthermore, the proposed method based on TE-LSAP & TE-GSAP shows improved PESQ results as compared to the other methods. Also, we added the results in terms of the aforementioned composite measure, with the results presents in Table 2. Similar to the PESQ results, Table 2 illustrates that the proposed TE-LSAP performs better than the LSAP-based method, while the proposed TE-LSAP & TE-GSAP approach outperformed both the conventional LSAP and the proposed TE-LSAP method under the given noise conditions.
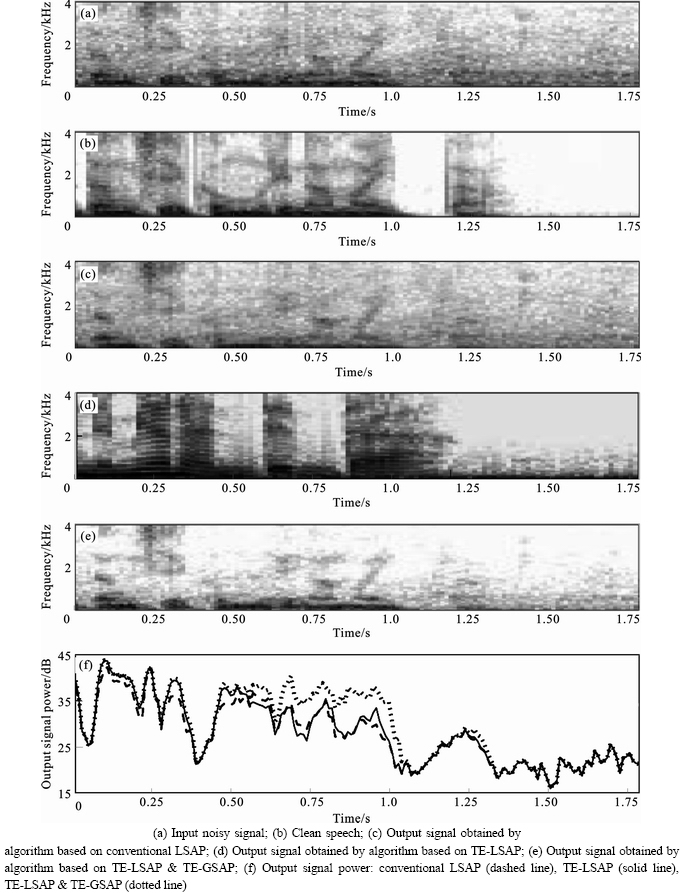
Fig. 4 Speech spectrograms (babble noise, SNR of 5 dB);

Fig. 5 Speech spectrograms (car noise, SNR of 5 dB);
Secondly, in order to evaluate the subjective quality of the proposed scheme, we carried out a set of informal listening tests. Opinion scores were recorded by 10 listeners and averaged to give final mean opinion score (MOS) results. All the scores from the listeners were then averaged to yield the average test results. Table 3 illustrates that the proposed TE-LSAP approach achieves better subjective quality results than the LSAP-based methods, while the proposed TE-LSAP & TE-GSAP approach outperformed the other two methods, under the given noise conditions. These results confirm that the VAD based on the TE-LSAP and the TE-GSAP is an effective approach for speech enhancement.
Table 1 PESQ scores obtained from proposed methods with respect to conventional method under various noise environments

Table 2 Composite measure scores obtained from proposed methods with respect to conventional method under various noise environments

Table 3 MOS results obtained from proposed methods with respect to conventional method under various noise environments

5 Conclusions
1) a novel VAD algorithm is proposed using TE-based SAP. The TE-LSAP estimate derived from the enhanced input noisy signal provided by the TE operator is applied to the VAD algorithm, resulting in more robust feature parameters.
2) Furthermore, the TE-GSAP is used as a weighting parameter modifying the adopted TE operator to yield better performance. The results of objective and subjective evaluation tests show that the performance of the proposed algorithm is superior to that of the conventional technique.
References
[1] TIA/EIA/IS-127. Enhanced variable rate codec, speech service option 3 for wideband spread spectrum digital systems [R]. Eqglewood: TIA, 1996.
[2] Ephraim Y, Malah D. Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator [J]. IEEE Trans Acoust Speech Signal Process, 1984, 32(6): 1109�C1121.
[3] Jeon Yu-yong, Lee Sang-min. A speech enhancement algorithm to reduce noise and compensate for partial masking effect [J]. Journal of Central South University of Technology, 2011, 18(4): 1121�C1127.
[4] McAualy R J, Malpass M L. Speech enhancement using a soft-decision noise suppression filter [J]. IEEE Trans Acoust Speech Signal Process, 1980, 28: 137�C145.
[5] Kim N S, Chang J H. Spectral enhancement based on global soft decision [J]. IEEE Signal Processing Letters, 2000, 7(5): 108�C110.
[6] Karray L, Mokbel C, Monne J. Solutions for robust speech/non-speech detection in wireless environment [C]// Proceedings of IVTTA, Torino, 1988: 166�C170.
[7] Rabiner L R, Sambur M R. Voiced-unvoiced-silence detection using the Itakura LPC distance measure [C]// Proc IEEE Int Conf Acoust Speech Signal Process, Hartford, 1977: 323�C326.
[8] Sohn J, Kim N S, Sung W. A statistical model-based voice activity detection [J]. IEEE Signal Processing Letters, 1999, 6(1): 1�C3.
[9] Sohn J, Sung W. A voice activity detector employing soft decision based noise spectrum adaptation [C]// Proc. IEEE Int Conf Acoustics, Speech, and Signal Processing, Seattle, 1998: 365�C368.
[10] Jabloun F, Cetin A E, Erzin E. Teager energy based feature parameters for speech recognition in car noise [J]. IEEE Signal Processing Letters, 1999, 6: 259�C261.
[11] Wang K C, Tsai Y H. Voice activity detection algorithm with low signal-to-noise ratios based on spectrum entropy [C]// Second International Symposium on Universal Communication 2008, Osaka, 2008: 423�C428.
[12] Chen S H, Wu H T, Chang Y, Truong T K. Robust voice activity detection using perceptual wavelet-packet transform and Teager energy operator [J]. Pattern Recognition Letters, 2007, 28(11): 1327�C1332.
[13] Evangelopoulos G, Maragos P. Multiband modulation energy tracking for noisy speech detection [J]. IEEE Trans ASLP, 2006, 14(6): 2024�C2038.
[14] Hu Yi, Loizou P C. Evaluation of objective quality measures for speech enhancement [J]. IEEE Trans ASLP, 2008, 16: 229�C238.
(Edited by HE Yun-bin)
Foundation item: Project supported by Inha University Research Grant; Project(10031764) supported by the Strategic Technology Development Program of Ministry of Knowledge Economy, korea
Received date: 2011�C11�C03; Accepted date: 2012�C06�C02
Corresponding author: Lee Sang-min, Professor, PhD; Tel: +82-32-860-7420; E-mail: sanglee@inha.ac.kr

