用后验信噪比修正小波包自适应阈值的语音增强算法
张雪英,任永梅,贾海蓉
(太原理工大学 信息工程学院,山西 太原,030024)
摘要:针对固定阈值小波包语音增强算法造成的语音失真问题,提出一种采用后验信噪比修正小波包自适应阈值的语音增强算法。该算法先用结合掩蔽效应改进的非平稳噪声估计算法估计噪声功率,确保计算出准确的节点后验信噪比;再用含有此后验信噪比的Sigmoid函数对相邻帧的随尺度变化的阈值进行平滑,保证了阈值的连续性;进一步用指数化的后验信噪比自适应修正阈值,减少语音失真。实验结果表明:新算法提高了增强语音的信噪比和分段信噪比,与固定阈值小波包语音增强算法相比,具有更好的增强效果。
关键词:小波包;自适应阈值;噪声估计;后验信噪比;语音增强
中图分类号:TN912.3 文献标志码:A 文章编号:1672-7207(2013)11-4566-08
Speech enhancement algorithm based on wavelet packet adaptive threshold revised by posteriori SNR
ZHANG Xueying, REN Yongmei, JIA Hairong
(College of Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China)
Abstract: Aiming at the problem that fixed threshold wavelet packet speech enhancement algorithm causes the speech distortion and residual noise, the speech enhancement algorithm which used the posteriori signal-to-noise ratio (SNR) of wavelet packet nodes to adaptively revise threshold was proposed. In this algorithm, the noise power was estimated by the improved non-stationary noise estimation algorithm that combined with masking effect, which ensured that posterior SNR of nodes was calculated accurately. The adjacent frame wavelet packet threshold which changed with the scale was smoothed by the sigmoid function with the parameter of posteriori SNR, which ensured the continuity of threshold. Furthermore, this threshold was adaptively revised further by the exponential posterior SNR, which reduced speech distortion. The experimental results show that the proposed algorithm improves the SNR and segment SNR (SSNR) of the enhanced speech; compared with the fixed threshold wavelet packet speech enhancement algorithm, the proposed algorithm has better enhanced effect.
Key words: wavelet packet; adaptive threshold; noise estimation; posterior SNR; speech enhancement
语音增强的应用广泛,因此寻找到一种有效算法来滤除带噪语音信号中的噪声,达到较强的抗噪效果是十分重要的[1]。语音增强的目的就是要去除掉背景噪声,提高语音的质量和可懂度,使听音人在乐于接受增强语音的同时能够更好的理解语音,而这些目的通常不能兼得,要根据具体应用有所侧重。小波分析理论是一种运用多分辨率思想分析非平稳信号的方法。到目前为止,小波阈值语音增强方法由于算法简单和适用范围广,成为了最常用的方法之一;其选取相同的阈值对小波各尺度的系数进行处理,虽然可以改善信噪比,但是会带来很大的失真[2-3],因此,该方法中最为关键的一步就是阈值选取的问题。与小波分析方法不同的是,小波包分解对其没有分解的语音信号高频部分也进行了分解,将频带划分得更细致,可以更准确地分析语音信号,近些年提出了基于Teager能量算子[4]和清浊音分离[5]等小波包自适应阈值语音增强方法。文献[4]中的阈值随着小波包系数Teager能量算子的包络自适应调节,变化缓慢的包络引起部分的过阈值增强现象。对清、浊音的准确检测具有一定的复杂度,增强语音中仍有残留噪声[5]。为此,本文作者提出一种用小波包节点的后验信噪比修正自适应阈值的语音增强算法,即用Bark尺度小波包分解得到的节点小波包系数先计算带噪语音的功率,并用结合掩蔽效应改进的非平稳噪声估计算法估计出节点噪声功率,进而计算出准确的节点后验信噪比;接着由含有此后验信噪比的Sigmoid平滑因子对随尺度变化的小波包节点阈值做相邻帧的平滑处理;再用指数化的节点后验信噪比修正阈值,使最终得到的阈值能够随节点后验信噪比自适应调节,更好地抑制噪声,并且对不同噪声的适应性更强。
1 小波包阈值语音增强算法的原理
假设带噪语音信号可以表示为如式(1)的加性噪声模型:
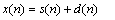 (1)
(1)
式中:s(n)表示纯净语音信号;d(n)表示均值为0的高斯噪声信号。对式(1)两边进行正交小波包变换,可以去除纯净语音信号的相关性,s(n)的能量会集中分布在所有尺度下的模极大值所在的小波包系数上。高斯噪声信号则不然,对其进行小波包处理后还是高斯噪声,噪声小波包系数将互不相关地分布在所有尺度下的全部小波包系数上[6]。因此,为了抑制噪声,可以保留所有尺度下的模极大值所在的小波包系数,剔除或减少剩余小波包系数,仅用保留的小波包系数重构语音信号。
小波包阈值语音增强算法的原理图如图1所示。
从图1可以看出小波包阈值语音增强算法为:首先选择小波包基和小波包分解层数对噪声语音信号x(t)进行小波包变换,获取各个尺度下的小波包系数;接着对分解之后的每一个小波包系数选择合理的阈值进行软阈值或硬阈值函数量化处理,得到阈值处理后的小波包系数;最后对处理后的系数进行小波包重构,获取增强语音信号。

图1 小波包阈值语音增强算法原理图
Fig.1 Principle diagram of wavelet packet threshold speech enhancement algorithm
2 用后验信噪比修正小波包自适应阈值的语音增强算法
2.1 基于改进的噪声估计算法的后验信噪比
噪声的特性变幻无穷,其统计特性在小波包的每个尺度下不同,且在同一尺度的不同点上也不完全均匀;为了增强语音信号能最大程度地接近纯净语音,小波包阈值应随噪声的时变而变化。后验信噪比能够体现出噪声的变化情况,为了估计出准确的小波包阈值,计算出准确的后验信噪比显得尤为重要。后验信噪比计算如下。
(1) 第m帧的第j层第k个节点的后验信噪比可以表示为[7]:
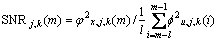 (2)
(2)
其中: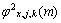 和
和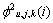 分别为第m帧的第j层第k个节点的带噪语音信号功率和噪声功率;0<l<m。
分别为第m帧的第j层第k个节点的带噪语音信号功率和噪声功率;0<l<m。
(2) 按下式计算:
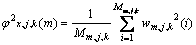 (3)
(3)
其中: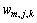 和
和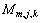 分别为第m帧的第j层第k个节点的小波包系数和该系数包含的语音样点数,这里用语音的小波包系数计算其功率。
分别为第m帧的第j层第k个节点的小波包系数和该系数包含的语音样点数,这里用语音的小波包系数计算其功率。
(3) 节点的噪声功率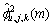 为
为
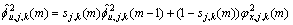 (4)
(4)
其中: 为平滑系数。
为平滑系数。
噪声估计算法在语音增强中具有重要的作用,语音增强算法性能的优劣依赖于能否对噪声的正确估计。传统的非平稳噪声估计算法[8-9]作为目前常用的噪声估计算法之一,对功率谱的平滑系数的取值通常由经验值和语音存在的概率决定,在反映噪声的时变性方面具有局限性,为此,提出一种结合人耳掩蔽效应改进的噪声估计算法,计算出能够随噪声变化的。仿真实验结果表明,改进算法能够估计出与真实噪声功率更接近的节点的噪声功率。
人耳听觉掩蔽效应即为一个声音信号的听觉感受性受到另一个声音信号影响的现象,也就是受能量相对较高的信号影响,能量相对较低的信号将不容易被人耳听到。在噪声环境下,大于掩蔽阈值的语音信号时,人耳可以听到;小于掩蔽阈值的语音信号时,人耳则听不到。利用人耳掩蔽效应,可以把低于掩蔽阈值的部分噪声信号予以保留,减少语音失真,改善增强语音的听觉效果。为了获得估计更准确的噪声和更好的听觉效果,本文用掩蔽阈值对非平稳噪声估计算法中估计语音存在概率的平滑因子进行了自适应调节。图2所示为改进的噪声估计算法流程图。
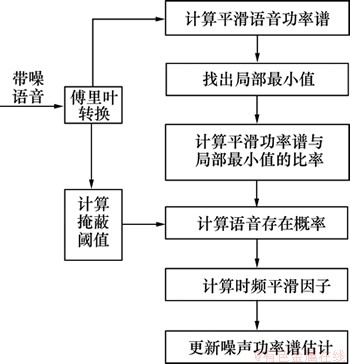
图2 改进的噪声估计算法流程图
Fig.2 Flow chart of improved noise estimation algorithm
按照图2对平滑系数的具体计算如下。
(1) 平滑语音功率为
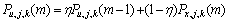 ,0<
,0<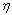 <1 (5)
<1 (5)
其中,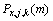 为第m帧的第j层第k个节点的噪声语音的功率,其计算方法同式(3)。
为第m帧的第j层第k个节点的噪声语音的功率,其计算方法同式(3)。
(2) 找出局部最小值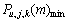 ,如果
,如果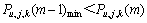 ,那么
,那么
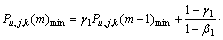
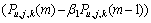 (6)
(6)
否则,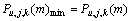 。其中,
。其中,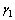 和
和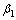 为平滑因子。
为平滑因子。
(3) 计算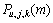 与的比值
与的比值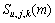 ,判定第m帧是否为语音帧。
,判定第m帧是否为语音帧。
(4) 估计第m帧的第j层第k个节点处语音出现概率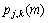 ,在计算掩蔽阈值时,用小波包各个节点的能量代替Johnston掩蔽模型中的Bark临界带功率,其余步骤与Johnston掩蔽模型一致。
,在计算掩蔽阈值时,用小波包各个节点的能量代替Johnston掩蔽模型中的Bark临界带功率,其余步骤与Johnston掩蔽模型一致。
(5) 系数可以表示为
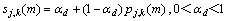 (7)
(7)
对图2中计算语音存在概率和计算掩蔽阈值的具体过程描述如下:
第m帧语音存在的概率p(m, k)为
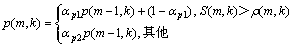 (8)
(8)
其中: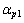 和
和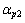 是平滑因子,k为频率点;
是平滑因子,k为频率点;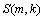 为平滑语音功率谱与其局部最小值的比率;
为平滑语音功率谱与其局部最小值的比率;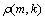 为判定门限。
为判定门限。
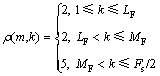 (9)
(9)
其中,LF为1 kHz对应的频率点;MF为3 kHz对应的频率点;Fs为采样频率。
传统算法中和取固定的经验值,本文中取=0.2,用掩蔽阈值调节,其计算如下:
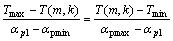 (10)
(10)
其中:T(m, k)为第m帧的掩蔽阈值;Tmax为T(m, k)对应帧的掩蔽阈值的最大值max(T(m, k));Tmin为T(m, k)对应帧的掩蔽阈值的最小值min(T(m, k))。掩蔽阈值T(m, k)的计算参照Johnston掩蔽模型(如图3所示)[10]中的计算方法。
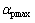 和
和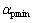 的取值根据具体应用,通过大量实验验证,当实验结果最优时选出最佳值,本文取
的取值根据具体应用,通过大量实验验证,当实验结果最优时选出最佳值,本文取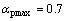 ,
,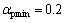 ;当
;当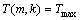 时,
时,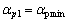 ;当
;当 时,
时,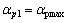 ;当T(m, k)介于Tmax与Tmin之间时,在与之间线性插值。
;当T(m, k)介于Tmax与Tmin之间时,在与之间线性插值。
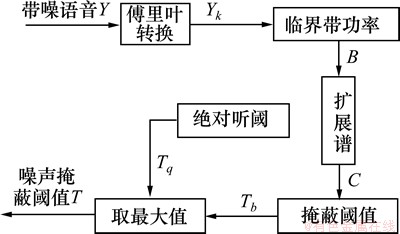
图3 掩蔽阈值的计算过程
Fig.3 Masking threshold computational process
从式(8)和式(10)可以看出,在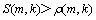 区间,当掩蔽阈值比较高时,部分噪声信号会被掩蔽导致人耳听不到,此时,取较小值,语音存在概率p(m)就为较大的值;当掩蔽阈值比较低时,人耳听到的信号中的噪声会很多,此时,取较大值,语音存在概率p(m)就为较小值。由以上分析可知:经过掩蔽阈值的调整取值更准确,进而估计出更准确的语音存在概率,最终获得估计更准确的噪声。图4所示为采用本文算法和传统算法估计的噪声功率谱图,噪声信号为Noisex92标准噪声库中的white噪声(SNR为3.5 dB)。
区间,当掩蔽阈值比较高时,部分噪声信号会被掩蔽导致人耳听不到,此时,取较小值,语音存在概率p(m)就为较大的值;当掩蔽阈值比较低时,人耳听到的信号中的噪声会很多,此时,取较大值,语音存在概率p(m)就为较小值。由以上分析可知:经过掩蔽阈值的调整取值更准确,进而估计出更准确的语音存在概率,最终获得估计更准确的噪声。图4所示为采用本文算法和传统算法估计的噪声功率谱图,噪声信号为Noisex92标准噪声库中的white噪声(SNR为3.5 dB)。
从图4可以看出,改进的噪声估计算法估计的噪声功率比传统算法估计的噪声功率更接近真实噪声功率,为获得更好的语音增强效果奠定了良好的基础。
2.2 修正的自适应阈值的计算
固定阈值小波包语音增强算法采用固定阈值抑制噪声,在噪声较弱的区域,固定阈值大于微弱语音信号的小波包系数时,微弱语音信号就会被误判成噪声信号;相反,噪声信号就会被误判为有用语音信号。语音信号的小波变换的模值随其分解尺度级数的增大而增大,噪声信号的小波变换的模值随其分解尺度级数的增大而减小[11],因此,随尺度变化的阈值也经常被采用。为了达到更好的增强效果,本文在随尺度变化的阈值基础上提出一种用后验信噪比修正自适应阈值的新算法,其计算过程如下。
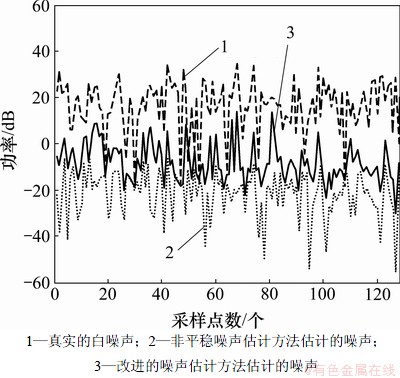
图4 真实噪声和估计的噪声的功率谱图
Fig.4 Power spectrum diagram of real noise and estimated noise
(1) 用Sigmoid函数对每帧的随尺度变化的阈值进行相邻帧的平滑,表达式为:
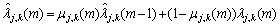 (11)
(11)
 (12)
(12)
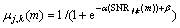 (13)
(13)
其中,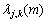 是随尺度变化的阈值;
是随尺度变化的阈值;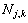 为第m帧的第j层第k个节点的噪声信号长度;
为第m帧的第j层第k个节点的噪声信号长度;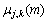 为平滑因子。由于Sigmoid函数是连续、光滑的有界函数,这里用含有后验信噪比因子的Sigmoid函数即对阈值进行相邻帧的自适应平滑,很好地保持了阈值的连续性。
为平滑因子。由于Sigmoid函数是连续、光滑的有界函数,这里用含有后验信噪比因子的Sigmoid函数即对阈值进行相邻帧的自适应平滑,很好地保持了阈值的连续性。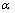 和
和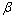 为调节的2个参数,的经验取值范围为1~6,的经验取值范围为10~15;根据具体实验调节和的取值,控制Sigmoid函数的陡峭程度,则调节其平移程度。
为调节的2个参数,的经验取值范围为1~6,的经验取值范围为10~15;根据具体实验调节和的取值,控制Sigmoid函数的陡峭程度,则调节其平移程度。
由式(11)和式(13)可以看出:当后验信噪比很低时,将趋于0,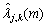 将趋于,平滑处理程度较小;当后验信噪比逐渐增大时,也呈现递增的趋势,平滑程度逐渐增大,直至趋于1时,将趋于
将趋于,平滑处理程度较小;当后验信噪比逐渐增大时,也呈现递增的趋势,平滑程度逐渐增大,直至趋于1时,将趋于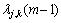 ,即阈值近似与前一帧的阈值相等。
,即阈值近似与前一帧的阈值相等。
(2) 用指数化的后验信噪比再自适应修正平滑后的阈值:
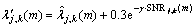 (14)
(14)
其中: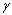 >1,本文取=5时实验结果最优。由式(13)可以看出:
>1,本文取=5时实验结果最优。由式(13)可以看出: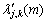 是单调减函数,当后验信噪比很低时,最大;随着后验信噪比的逐渐增大,将逐渐减小,最后趋于。这正符合在噪声强度大(信噪比低)时,阈值应该尽量大,去除更多的噪声;在噪声强度低(信噪比高)时,阈值应该适当的减小,保留更多的语音信号,以减少语音失真的原则。因此,本文的阈值可以随着后验信噪比自适应调节,减少对语音的过度阈值处理,更好地恢复语音信号。
是单调减函数,当后验信噪比很低时,最大;随着后验信噪比的逐渐增大,将逐渐减小,最后趋于。这正符合在噪声强度大(信噪比低)时,阈值应该尽量大,去除更多的噪声;在噪声强度低(信噪比高)时,阈值应该适当的减小,保留更多的语音信号,以减少语音失真的原则。因此,本文的阈值可以随着后验信噪比自适应调节,减少对语音的过度阈值处理,更好地恢复语音信号。
2.3 阈值函数的选取
由于传统硬阈值函数不连续,其在重构语音信号时难免会产生振荡(吉普斯现象);而软阈值函数处理后的语音信号和原始语音信号之间在幅度上总存在着恒定的偏差,并且在处理特性复杂的噪声信号时,增强语音信号的包络显得尤其光滑,带来不可避免的误差[12-13]。鉴于此,本文采用参考文献[14]中提出的一种连续高阶可导的阈值函数,表达式如下:
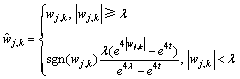 (15)
(15)
其中: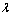 是阈值;
是阈值;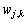 是小波包系数;
是小波包系数;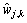 是阈值处理后的小波包系数,
是阈值处理后的小波包系数, ,本文取
,本文取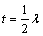 时实验结果最好。
时实验结果最好。
2.4 本文新算法流程图
本文提出的用后验信噪比修正小波包自适应阈值的新算法的流程图如图5所示。新算法为:将带噪语音分帧、加窗之后进行小波包变换,得到小波包系数,用改进的噪声估计算法估计出噪声功率,进而计算出小波包节点的后验信噪比;接着用式(11)对相邻帧阈值进行修正,用式(14)计算自适应阈值;再用计算的自适应阈值对小波包系数进行阈值函数处理,紧接着进行小波包反变换得到增强的小波包系数,并对其进行重叠相加,最后去除加窗引起的增益就得到增强语音。
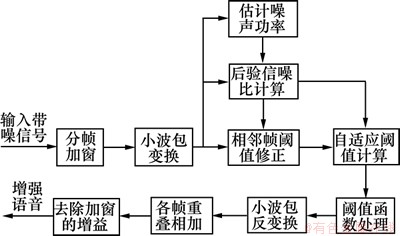
图5 新算法的流程图
Fig.5 Flow chart of new algorithm
3 实验仿真与分析
为了对本文算法的有效性进行验证,用MATLAB7.6.0软件对此算法和固定阈值传统小波包语音增强算法(算法1)以及文献[5]的方法(算法2)进行仿真实验对比。仿真实验中,原始语音是从NOIZEUS语音库中选取的每句时长约为2.8 s的8句语音,其中男声和女声各为4句。噪声为Noisex92噪声库中的白噪声、汽车噪声和F16飞机噪声。通过MATLAB7.6.0软件对原始语音分别叠加以上3种噪声语音,带噪语音的信噪比分别为0,5,10和15 dB。
按照实验结果最优原则,设置帧长为256个采样点,帧移是128个采样点,窗函数为汉明窗,Bark尺度小波包分解树[15]是7层68个子频带的小波包树,小波函数是db5正交小波;分别取参数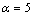 ,
,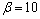 ,
,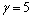 ,
,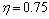 ,
,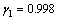 ,
,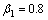 ,
,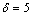 ,
,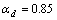 。
。
本文采用信噪比(SNR)、分段信噪比(SSNR)和感知语音质量评价(PESQ)来评价增强后的语音性能,表1所示为3种算法增强后语音的信噪比比较,表2所示为3种算法增强后语音的分段信噪比比较。从表1~2可以看出:本文算法的增强效果在信噪比值和分段信噪比值上较传统小波包增强算法以及文献[5]方法均有一定的提高,其增强的语音效果为最佳。图6所示为3种算法增强后语音的PESQ值比较。从图6可以看出:相比算法1和算法2,本文算法增强后语音的PESQ值为最高,通过主观测听,本文算法增强后的语音质量更好。
图7所示为信噪比为5 dB的白噪声背景下3种算法增强后语音的时域波形图,图8所示为图7中时域波形图对应的语谱图。
从图7可以看出:算法1增强的语音失真较大;算法2增强的语音中仍有残留噪声;本文算法抑制了更多的噪声,在时域波形上最接近于原始语音信号的波形图,较好地保留了原始语音,失真较小。从图8可以看出:本文算法优于其他2种算法。主客观评价方法均证明本文算法对白噪声和有色噪声环境均有效。
表1 3种算法增强后语音的信噪比
Table 1 SNR of enhanced speech by three algorithms dB
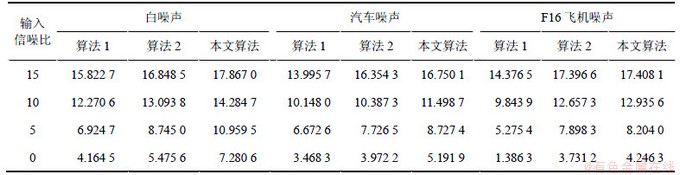
表2 3种算法增强后语音的分段信噪比
Table 2 SSNR of enhanced speech by three algorithms dB
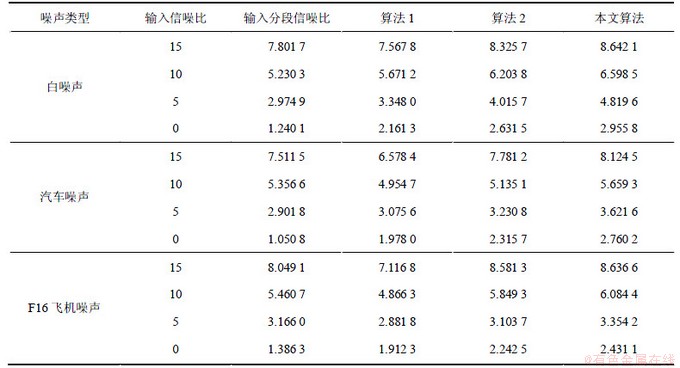
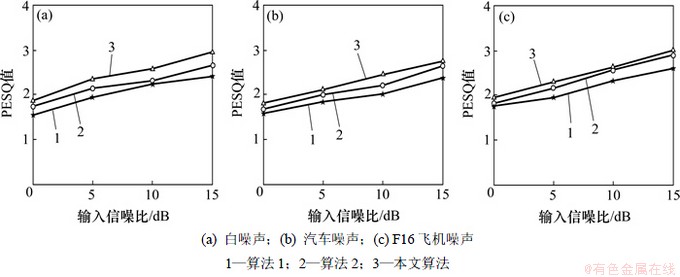
图6 3种算法的PESQ
Fig.6 PESQ of three algorithms
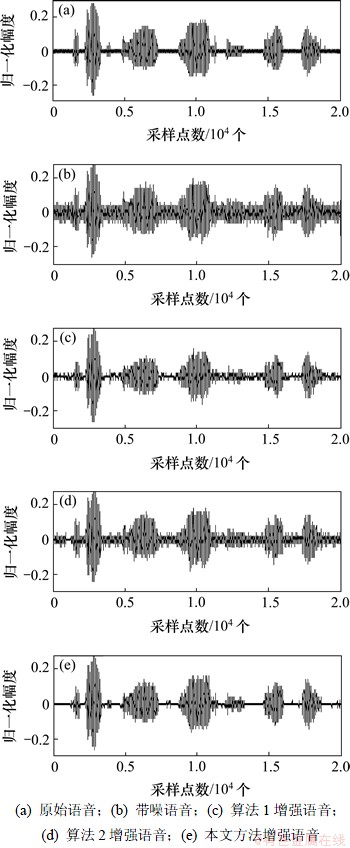
图7 3种算法增强语音时域波形图
Fig.7 Time domain waveform diagrams of enhanced speech by three algorithms
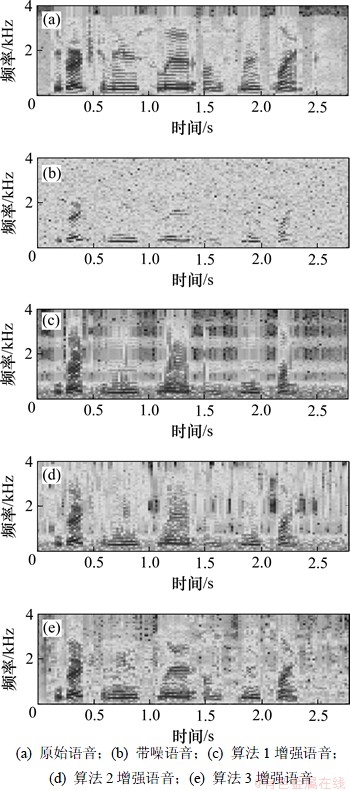
图8 3种算法增强语音的语谱图
Fig.8 Spectrograms of enhanced speech by three algorithms
4 结论
(1) 本文提出的用后验信噪比修正小波包自适应阈值的语音增强算法,采用小波包分解系数计算出小波包节点功率,用结合掩蔽效应改进的噪声估计算法估计出噪声功率,进一步计算出能够准确的表示语音和噪声成分比例的小波包节点后验信噪比;用含有后验信噪比因子的Sigmoid函数平滑处理相邻帧的随尺度变化的阈值;再对该阈值用指数化的后验信噪比进行修正处理,使其随着后验信噪比自适应变化,提高了阈值处理的准确度,得到更有效的增强语音。
(2) 传统小波包语音增强算法与文献[5]中方法相比,新算法在白噪声和有色噪声背景下均取得了更好的增强效果;而且采用了7层68个子频带的Bark尺度小波包分解树,更符合人耳对语音的听觉感知特性。但是本文方法也有不足之处,如阈值函数是引用文献中的,在以后可以考虑改进阈值函数来进一步改善去噪效果。
参考文献:
[1] 张雪英. 数字语音处理及MATLAB仿真[M]. 北京: 电子工业出版社, 2010: 207.
ZHANG Xueying. Digital speech processing and MATLAB simulation[M]. Beijing: Publishing House of Electronics Industry, 2010: 207.
[2] Donoho D L, Johnstone I M. Ideal spatial adaptation by wavelet shrinkage[J]. Biometrika, 1994, 81(3): 425-455.
[3] Johnstone I M, Silverman B W. Wavelet threshold estimators for data with correlated noise[J]. Journal of the Royal Statistical Society, 1997, 59(2): 319-351.
[4] Chen S H, Wang J F. Speech enhancement using perceptual wavelet packet decomposition and teager energy operator[J]. Journal of VLSI Signal Processing, 2004, 36(2): 125-139.
[5] ZHANG Junchang, ZHANG Yi, YE Zhen. Adaptive speech enhancement based on classification of voiced/unvoiced signal[C]// IEEE International Conference on Multimedia and Signal Processing. Guilin: IEEE, 2011: 310-314.
[6] 胡广书. 现代信号处理教程[M]. 北京: 清华大学出版社, 2004: 398.
HU Guangshu. Modern signal processing tutorial[M]. Beijing: Publishing House of Tsinghua University, 2004: 398.
[7] Rama Rao Ch V, Rama Murthy M B, Srinivasa Rao K. Speech enhancement using a modified apriori SNR and adaptive spectral gain control[J]. International Journal of Computer Applications, 2011, 12(12): 13-17.
[8] Fukane A R, Sahare S L. Noise estimation algorithms for speech enhancement in highly non-stationary environments[J]. International Journal of Computer Science Issues, 2011, 8(2): 39-44.
[9] Rangachari S, Loizou P C. A noise-estimation algorithm for highly non-stationary environments[J]. Speech Communication, 2006, 48(2): 220-231.
[10] Johnsotn J D. Transform coding of audio signals using perceptual noise criteria[J]. IEEE Journal on Selected Areas in Communications, 1998, 6(2): 314-323.
[11] 田秀荣. 基于正交小波包分解的语音去噪增强[J]. 计算机仿真, 2011, 28(5): 388-390.
TIAN Xiurong. Speech de-noise and enhancement using orthogonal wavelet packet decomposition[J]. Computer Simulation, 2011, 28(5): 388-390.
[12] YANG Xi, LIU Bingwu, YAN Fang. Speech enhancement using bionic wavelet transform and adaptive threshold function[C]// IEEE Second International Conference on Computational Intelligence and Natural Computing Proceedings. Wuhan: IEEE, 2010: 265-268.
[13] Ghanbari Y, Karami-mollaei M R. A new approach for speech enhancement based on the adaptive thresholding of the wavelet packets[J]. Speech Communication, 2006, 48(8): 927-940.
[14] 王文良. 基于小波包变换的语音增强算法研究[D]. 天津: 天津大学电子信息工程学院, 2007: 36.
WANG Wenliang. Research of speech enhancement algorithm based on wavelet packet transform[D]. Tianjin: Tianjin University. School of Electronic Information Engineering, 2007: 36.
[15] Cohen I. Enhancement of speech using bark scaled wavelet packet decomposition[C]// Proceedings of 7th European Conference on Speech Communication and Technology. Aalborg: IEEE, 2001: 1933-1936.
(编辑 赵俊)
收稿日期:2012-10-18;修回日期:2012-12-22
基金项目:国家自然科学基金资助项目(61072087,61370093);山西省留学回国人员科研基金资助项目(2011-035);2012年度山西省高校高新技术产业化项目(20120010)
通信作者:贾海蓉(1977-),女,山西洪洞人,博士,副教授,从事语音信号处理、DSP应用、多媒体通信等研究;电话:15536925678;E-mail: helenjia722@163.com

