
DOI: 10.11817/j.issn.1672-7207.2019.03.011
���ھ���������ͼ��Ԥ������Ŀ�����Ļ��㷨
�����1���Ⱞ��1������1����ΰ2
(1. ����ѧ �����Զ�������Ϣ����ѧԺ�����300072��
2. �й���ѧԺ�Զ����� ģʽʶ������ص�ʵ���ң�������100000)
ժ Ҫ��
�жԲ�ͬ��������Զ���������⣬���һ�ֻ��ھ����������ģʽʶ���㷨����29�ֲ�ͬ�ߴ����˿����ĸ�͵�Ƭ���з��ࡣ���Ȳɼ������������ͼ�����ݣ�ͨ��������ǿ�õ����ݼ���Ȼ�����һ�ּľ��������硣���һ�ֶ�ͼ���е�Ŀ��λ�ý������Ļ���ͼ��Ԥ�����㷨�����ܹ���ȡͼ����Ŀ�����ڵ��������ƶ���ͼ������λ�á��о�����������벻����Ŀ�����Ļ��㷨�Ĵ�ͳ������ȣ�����ȷ�ʴ�97.59%������99.96%���������ȷ�ʵ������ȷ�ʴ�85.83%������99.67%��ʹ�þ���������Ա���������Ŀ�����Ե�ͼ����з���ʱ��ʹ�ñ��������Ŀ�����Ļ��㷨����ͼ��Ԥ�����ܹ�������������ʶ��ȷ�ʡ�
�ؼ��ʣ�
�����ʶ����������������������ǿ�����Ļ���Ŀ����ȡ��
��ͼ����ţ�TP 391.4 ���ױ�־�룺A ���±�ţ�1672-7207(2019)03-0579-08
Target-centralization algorithm used for image preprocessing of CNN
DONG Qiucheng1, WU Aiguo1, DONG Na1, FENG Wei2
(1. School of Electrical and Information Engineering, Tianjin University, Tianjin 300072, China;
2. National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy of Sciences, Beijing 100000, China)
Abstract: To solve the problem of classifying different parts automatically in industrial production, a pattern recognition algorithm based on convolutional neural network was raised and 29 different sizes of screws, nuts and washers were classified. Firstly, image data of the parts that were going to be classified were collected, and the dataset was created by data augmentation. Then, a simplified convolutional neural network was designed. An image preprocessing algorithm to centralize the position of the target in the image was raised, which can extract the target area in the image and move it to the center of the image. The results show that compared with traditional method without target-centralization algorithm, the total error is raised from 97.69% to 99.96, and the accuracy of the part which has the lowest accuracy is raised from 85.83% to 99.67%. When convolutional neural network is used to classify images which has pure background and obvious object, using the target-centralization algorithm raised in this paper to preprocess the images can improve the accuracy of the network significantly.
Key words: parts; recognition; convolutional neural network; data augmentation; centralization; object extraction
���Ź�ҵ4.0ʱ���ĵ�����ͼ��ʶ�����ڹ�ҵ�����е�Ӧ��Խ��Խ�㷺���ѱ����ڲ�Ʒ��⡢�������ߴ����������档���ʶ�������ҵ���������г����ұ�Ҫ�Ĺ������������Ѳ�ͬ�����Ŀ�����������ȷ�ķ��ദ����Ҳ�������ڷּ�����������Ĺ����������˹��������ʶ�𣬷���Ч�ʵ͡��ɿ��Բ�ɱ��ߡ�Ϊ����߹�ҵ�������Զ��������ܻ��ij̶ȣ����û����Ӿ���Ƴ��ܹ�Ӧ����ʵ������������Զ�ʶ��ϵͳ��Ϊ��ǰ��ҵ�Զ����������Ҫ���⣬������Ҫ�����������ʵ�ü�ֵ[1-2]�����е����ʶ���㷨��������������ͳ����ѧϰ�Ļ�����ʽ������ȡһ�����ʵ����������ٽ���Щ�����ṩ���Ļ���ѧϰ�㷨[3-8]����Щ�㷨�Ĺ�ͬ�ص�������������������˹�ѡȡ�ģ��������˹���Ƶ��㷨������ȡ�ġ�Ȼ����������ѡȡ������Ҫ�������飬���������������ܵ����ƣ�����չ�Բ��ѡ�����Ҫʶ����������϶�ʱ���˹���ȡ������������������ѡȡ��������һ�������ŵġ�HINTON��[9]��������ѧϰģ�͡����ֹ������������ķ�����ȣ��������ѧϰģ��ֱ�ӴӴ�������ѧϰ���������������������ݱ����ķḻ�ں���Ϣ[10]����������ѧϰ�����ڼ�����Ӿ�������ֳ����DZ��������������[11]��Ϊһ����������ѧϰ�ܹ���ƾ��������ı����ܵ��㷺�Ĺ�ע����һϵ�д��ģ��ϸ���ȵ�ͼ��ʶ��������ȡ�þ�ɹ�[12]��������������һ���µ�Ŀ�����ʶ�����÷����ܹ�ʵ���Զ�����ͼ��������ȡ�������ʶ�������Ϊһ�壬��ͨ������ʵ������ѧϰ[13-14]������ҵ��Ϣ���̶ȸߡ��Ͷ����ܼ����ɱ���Χ����Ƿdz��ʺ��˹����ܼ������ӵ�����ͬʱ���˹����ܼ���Ҳ�dz��ʺϽ������ҵ���ٵ���ս���粻�ȶ������������ʡ����������ȱ������ԡ����ܹ��������Լ������ɱ������ȡ��˹����ܼ��������������Щ���⣬�����ʼ����̣�����������ڣ�������Ӧ��ƿ�������ٲ��Ϻ���Դ�˷ѣ�������߲�����Ϊ���ܹ���ԭ������ʶ����Ȼͼ��ľ�������������ʶ��ҵͼ����Ҫע���Ȼͼ���빤ҵͼ��IJ�֮ͬ������������ṹ���㷨������Ӧ�ĵ�����Ľ�����Ȼͼ��(����ImageNet���ݼ�)�ձ�ɫ�ʷḻ������࣬��״����������������Ϊ���ӣ�����ҵ�ֳ�����ͼ��ɼ�ʱ��������ȶ���ͬ�����ÿ�βɼ�����ͼ������Ŀ��ͻ����������Ϊ���������ڴˣ���������������Ⱦ�������������ƣ���������ʶ��������ص㣬���һ�ּľ��������磬��29�ֲ�ͬ�ߴ����˿����ĸ����Ƭ���з��࣬������ͼ��Ԥ����������һ�ֻ��ڱ�Ե����Ŀ�����Ļ��㷨��ͬʱ��֤�������������ʶ����ͬ���ࡢ��ͬ�ߴ��ͼ���ȷ�ʣ����ھ����������ڳߴ���������Ӧ�þ���һ���IJο���ֵ��
1 ͼ��ɼ���������ǿ
1.1 ͼ��ɼ�
1.1.1 �������
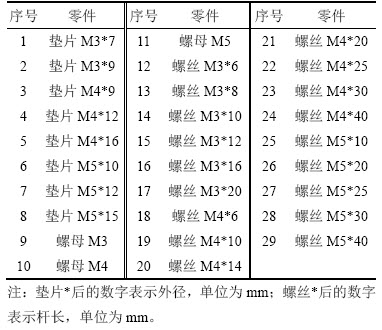
����������Ϊ��˿����ĸ����Ƭ3�࣬ÿ������ַ�Ϊ��ͬ�ijߴ磬һ�й�29�������������˿18�֣���Ƭ8�֣���ĸΪM3��M4��M5��3�֡�
29������ı�ż��ߴ����1��ʾ��
��1 �����ż��ߴ�
Table 1 Number and size of parts
1.1.2 ͼ��ɼ�����
ͼ��ɼ�ʱ������ͷ���㷽��ֱ�������ƽ�棬������ͷ����������λ�ñ��ֲ��䣬��ͼ1��ʾ����������ģ��ʵ�ʹ�����λ�ù̶�������ͷ��ֱ���㴫�ʹ����˶�����������Σ�ͬʱ����ʹ�����ͼ���еĴ�С�ܹ���ӳͼ���ʵ�ʴ�С��ÿ������任��ͬ�ĽǶȡ�λ������40�Σ���ģ��ʵ�ʹ��������λ�úͰڷŽǶȶ�������ġ�
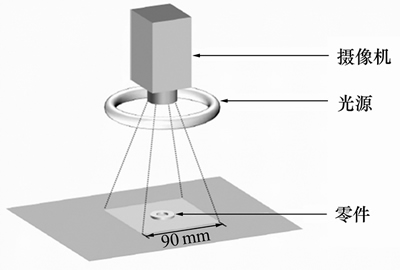
ͼ1 ͼ��ɼ�ʾ��ͼ
Fig. 1 Diagram of image acquisition
1.2 ������ǿ
Ϊ��ֹ�������ϣ�����ѵ����������Ӧ�����ܴ��ǣ�ͨ���˹�����ͼ��ɼ��ķ�ʽ��ȡ���ݵ�Ч�ʺܵͣ������㹻���������Ҫ�ܳ�ʱ�䡣����ͼ��ʶ��������˵��ʹ��������ǿ��������������һ��Ч�ʺܸ�����֮��Ч�İ취��ͼ��ʶ�������г��õ�������ǿ�����У�ƽ�ơ���ת����ת�����š�ɫ��ƫ�Ƶȡ�������������е�ʵ�������ѡȡ��ƽ�ơ���ת������ƫ�ơ��Աȶ�ƫ��4��������ǿ������δ���÷�ת��ԭ���Ǵ����������Ϊ���ҶԳƣ���ת�����Ѿ�����ģ��������нǶȵ������û�б�Ҫ�ٽ��з�ת������δ���÷�ת�����ŵ�ԭ�����ڸ������У�ͼ��Ĵ�С��������ijߴ磬�����൱�ڸı�����ߴ磬�Ӷ��ı�ͼ�����
1.3 ����ʵ��
ͼ2��ʾΪ29�������Ӧ��ԭʼͼƬ��ԭʼͼ��Ϊ3 120���ء�3 120���صĻҶ�ͼ��Ӧ�������ƽ���ʵ�ʳ�����Ϊ90 mm��90 mm�����ȶ�ͼ�����0��~360�㷶Χ����Ƕȵ���ת����ͼ3��ʾ���м��ɫԲ������Ϊʼ�ջᱻԭͼ���ǵ�����Ȼ���ͼ�����IJ���2 048���ء�2 048���ص�ͼ�����Ͻ�����Ϊ[460, 610]�е���������������ü����ܱ�֤ͼ������ĺڱᱻ��ȫ��ȥ������ʹͼ���м������õ�����������ͬʱ����λ���ϵ�����ԡ��ٽ��ü����ͼ��������128���ء�128���أ���ʱ��ÿ�����ض�Ӧ��ʵ�ʳ���Ϊ0.46 mm����Ը�ͼ������������ƫ����Աȶ�ƫ�ƣ�ƫ�Ʊ��ʾ�Ϊ0.9~1.1��ÿ��ͼƬ�ظ�100�Σ��õ�100�Ų�ͬ��ͼ��ͼ4��ʾΪ����3��ԭʼͼƬ����������ǿ��õ��IJ��ֽ�������յ����ݰ���29�������ÿ�������Ӧ4 000��ͼƬ����116 000��ͼƬ��
2 ����������
��������������LeCun�������һ��ר����������������������ṹ���ݵ������磬����ʱ���������ݺ�ͼ�����ݡ����������������Ӧ������������[3]������������ͨ��Ȩֵ�����;�������ֱ�Ӵ�����άͼ�����˴�ͳģʽʶ���㷨�и��ӵ�������ȡ�������ؽ�����[15-18]��
����������Ļ����ṹ����������ͳػ��㡣��������һ���ѵ���ľ����˹��ɡ�������Ҫ��ȡ�������ܶȣ�������ͨ���̶��IJ���������ͼ�����������㣬���ɼ�����任���������ͼ���ػ���ͨ���ھ����������֣�ͨ��������ͼ�����²�������������ά�Ȳ����Ƹ��š�

ͼ2 ԭʼ���ͼƬ
Fig. 2 Origin images of parts
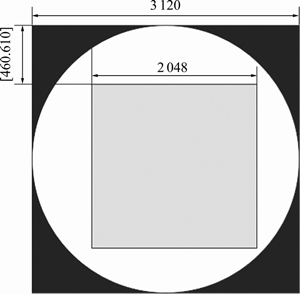
ͼ3 �������ʾ��ͼ(��λ������)
Fig. 3 Diagram of random crop

ͼ4 ������ǿ���
Fig. 4 Results of data augmentation
2.1 ����ṹ
���ݾ���������Ļ����ṹ����ϴ��������ݼ�����������������ͼ5��ʾ�ľ���������ģ�͡�����������Ĵ�ο���AlexNet[19]��VGGNet[20]�Ľṹ�����ʶ��������״�ϼ����ԣ�������ṹ�����˽ϴ��
SIMONYAN��[20]ָ���������С�����˵IJ�������һ���ϴ�����˾�����ͬ��С�ĸ���Ұ���Ҳ������٣������Ը�ǿ����ˣ���ǰ2���������в�����2��3��3�ľ����ˣ��൱�ڶ������ṩ��5��5�ĸ���Ұ��
�������������Ϊ1��128��128�ľ���������ǿ���ͼ��1�����������32��3��3�ľ����ˣ����ά��Ϊ32��126��126����2��������ͬ������32��3��3�ľ����ˣ����ά��Ϊ32��124��124��Ȼ��һ�������˴�СΪ2��2�����ػ��㣬���ά��Ϊ32��62��62����3�����������64��3��3�ľ����ˣ����ά��Ϊ64��60��60��Ȼ���پ���һ�������˴�СΪ3��3�����ػ��㣬���ά��Ϊ64��20��20����4�����������128��3��3�ľ����ˣ����ά��Ϊ128��18��18��Ȼ���پ���һ�������˴�СΪ2��2�����ػ��㣬���ά��Ϊ128��9��9���ٽ������ά����չ���ɳ���Ϊ10 368��һά����������һ�����Ϊ256��ȫ���Ӳ㣬���һ�����Ϊ29��ȫ���Ӳ㣬�õ�����������
���о�����IJ�����Ϊ1������䣻�������ػ���IJ�����������˵ı߳���ͬ������䣻�������ļ����ʹ��Softmax�⣬�������еļ������Ϊ�������Ե�Ԫ��
�ڵ�1������������ÿ�����ػ�����涼������0.25��Dropout[21]���ڵ�2��ȫ���Ӳ����������0.5��Dropout��
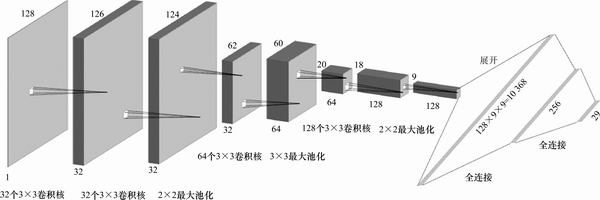
ͼ5 ����������ṹ
Fig. 5 Diagrams of convolutional neural network
2.2 ѵ������
ÿ�������ͼƬ��40��ԭʼͼƬ����100��������ǿ�õ�����ÿ������ӵ��4 000��ͼ�����ݡ���ǰ28��ԭʼͼƬ������ǿ��õ���2 800��ͼ����Ϊѵ��������12��ԭʼͼƬ������ǿ��õ�1 200��ͼ����Ϊ���Լ�����Ϊ���Լ���ԭʼͼƬ��ѵ�����IJ�ͬ�����ԣ���ʹ����ȫ�µ�ͼƬ�������ȷ��Ҳ������Լ�����ͬ���������ܵ�������ǿ��Ӱ�졣
����ѵ��������õ�����Ӧѧϰ���㷨ΪAdam[22]��ѧϰ��Ϊ1��10-4��ѵ��ʱ��ÿ������32��ͼƬ��������������������[23]��
3 Ŀ�����Ļ�
�ھ����������ѧϰ�㷨�Լ�ѵ��������Ĺ����У�����Ҫ��ԭʼ���ݽ������Ļ��ͱ������������ݾ������Ļ��ͱ����������Ϊ��ֵΪ0������Ϊ1�ķ��ӱ���̬�ֲ������ݡ����Ļ��ͱ������������ܹ���������������������֮��IJ����ԣ�ʹ���Ǿ�����ͬ�ij߶ȡ��ڻع������У����ܹ�ȡ���������ٲ�ͬ���������������ֵ���ϴ�������������������ѵ�������У����ܼ���Ȩ�ز�����������
��������ѵ���Ĺ����У�������������������������һ�����ͼ������ؽ������Ļ��ͱ����Ĵ��������ǣ�ÿ��ͼ���������λ����������ֵġ���Ȼ��ͳ������Ϊ�����������ͼ�������ж���Ŀ����ͼ���е�λ���أ����������ʶ�������У��������������Ϊ������������ͬ���ͬ��С�����ͼ����Ŀ�����״����������ͬ�����ڴ�С�ϴ��ڲ�𣬼���ͬ���ͼ���IJ���С����Ŀ��λ�õ������ģ�������ֲ�ࡣ��ʵ�����н����Ҳ���֣�����������������������ͼ����ռ�Ƚ�С����������ͬ���ߴ�������֮�������ȷ�ʽϵͣ�����ijЩ�ߴ��С����״���Ƶ�����������������ȷ���������紫ͳ�㷨��
Ϊ�˽�����������������״����С���Ƶ�Ŀ�겻���е����⣬��������˽�ͼ���е�Ŀ��������Ļ��ķ�����Ŀ�����Ļ��㷨��˼·�ǣ�ͨ����ͼ���еĴ�ʶ��Ŀ���λ���ƶ���ͼ������Ĵ���ʹ��ͬ���IJ�ͬͼ���IJ�ྡ������С���Ӷ�ͻ����ͬ���ͼ��֮��IJ�ࡣ�÷���������һ��������������Ϊ֧�ţ���ʵ�����н���У��÷���Ҳʹ�������ʶ��ȷ�ʵõ�������������
3.1 ��Ե��ȡ
ͨ����������4�������Sobel������ȡ��Ե����4�����ӵ���ʽ���£�
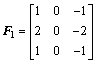 (1)
(1)
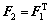 (2)
(2)
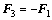 (3)
(3)
 (4)
(4)
������������ƣ���4�����ӷֱ�����ҡ����ϵ����ƶ���ÿ���ƶ��IJ���Ϊ1��������Fi���ǵ���ԭͼ������ɵľ���Ϊx�������Ϊ
 (5)
(5)
���У�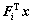 ΪFi��x�ĵ��(��ӦԪ�س˻�֮��)��bΪ��ֵ��
ΪFi��x�ĵ��(��ӦԪ�س˻�֮��)��bΪ��ֵ��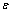 Ϊ��Ծ�������˲���ѡȡ���ʵ���ֵ(����ȡֵΪ20)��ʹ������������ܸ��������ȫ����4����������4����Ե��ȡ�������ȡ�������õ����ս��������ͼ�����ȡ�����ͼ6��ʾ��
Ϊ��Ծ�������˲���ѡȡ���ʵ���ֵ(����ȡֵΪ20)��ʹ������������ܸ��������ȫ����4����������4����Ե��ȡ�������ȡ�������õ����ս��������ͼ�����ȡ�����ͼ6��ʾ��
ͼ6 ����ͼ���Ե��ȡ���
Fig. 6 Results of edge extraction of some images
��ͼ6�ɼ���ͼ�����������������š�Ϊ����ȷ�ж����λ�ã�������ȡͼ���е������ͨ��ķ�����������ֹ�˴�ͳ���˲��������ܵ��µ������˳�����ȫ�����⣬�Ӷ���ȫ�����������ĸ��š�
�ҳ������ͨ��õ����ľ��ΰ�Χ�߿���ȡԭʼͼ��߿��ڵ�ͼ��Ϊԭʼͼ����������ֵ�ͼ��
3.2 Ŀ�����Ļ�
Ϊ����֤Ŀ�����Ļ��㷨����ȷ�ԣ��ֱ�������3�����ݼ�����1�����ݼ�����ȡ���ΰ�Χ���ڵ�ͼ���ı�ͼ��λ�ã���2�����ݼ�����ȡ����Ŀ������ͼ�����Ͻǣ���3�����ݼ�����ȡ����Ŀ������ͼ�����ġ���3�ַ����õ������ݼ��IJ���ͼ����ͼ7��ʾ��

ͼ7 3�����ݼ��IJ���ͼ��
Fig. 7 Some images of three datasets
����ǰ������۷�������1�����ݼ�δ�ı�Ŀ��λ�ã���ȥ���ֱ������൱��ͻ����Ŀ������λ�ã�����Ϊ��δ�ı�Ŀ��λ�ã��²�������ݼ���ȷ����ԭʼ���ݼ����ƻ����и��ƣ���2�����ݼ���Ŀ������ͼ�����ϽǴ���ͳһ��Ŀ��λ�õ���δͳһ�����Ĵ����൱��һ�������������Ļ�����ԭʼ���ݼ���ȷ�����Ӧ�õ������Ե����������Բ����3�����ݼ�������ȫ�ؽ�Ŀ������ͼ�����ġ�
4 ʵ����
4.1 ����ѵ��
�ֱ�ʹ��ԭʼ���ݼ���Ŀ����ԭλ�á����Ͻǡ����ĵ����ݼ�ѵ�����磬��ѵ������ȫ����������������ѵ��80�Ρ���ÿ�����ݼ��еIJ��Լ�����ʧ����ֵ�仯���߽��бȽϣ������ͼ8��ʾ��

ͼ8 ��ʧ����ֵ�仯����
Fig. 8 Curves of loss function value
��ͼ8�ɼ�����ѵ�������У�ԭʼͼ���Ŀ����ԭλ�õ����ݼ�ѵ���ٶȼ�����ͬ����Ŀ�������ϽǺ�Ŀ�������ĵ����ݼ�ѵ���ٶ�Զ����ԭʼ���ݼ���ѵ���ٶȣ���Ŀ�������ĵ����ݼ���ѵ���ٶ��Դ���Ŀ�������Ͻ����ݼ���ѵ���ٶȣ�˵��Ŀ�����Ļ��ܹ�ǿ�����ݵ��������ӿ���������������ͬѵ�������£���ʧ������С���Ӷ��ﵽ����ѵ��ʱ���Ŀ�ģ������Ļ��̶�Խǿ��ѵ���ٶ�Խ�졣
4.2 ȷ��
ԭʼ���ݲ��Լ��ۺ�ȷ��Ϊ97.59%��Ŀ����ԭλ�õIJ��Լ��ۺ�ȷ��Ϊ98.57%��˵����ȥ������Ҳ������һ����ȷ�ʣ���Ŀ�������ϽǵIJ��Լ��ۺ�ȷ��Ϊ99.88%��Ŀ�������ĵIJ��Լ��ۺ�ȷ��Ϊ99.96%��˵��Ŀ�����Ļ��ܹ������������ȷ�ԣ���ȷ�������Ļ��̶ȵ����Ӷ����ߡ�
�����Լ���ÿ�������ȷ�����2��ʾ��
��2 ÿ�������ȷ��
Table 2 Accuracy of each %
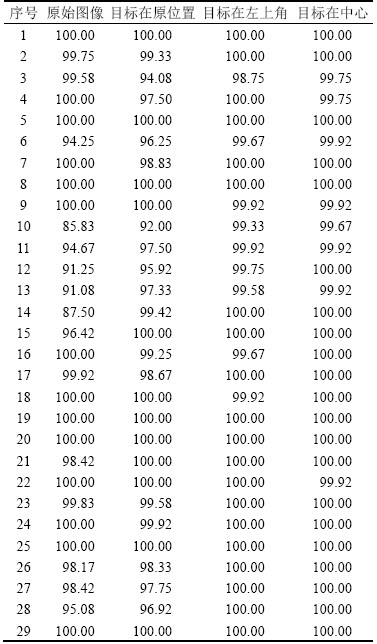
�ɱ�2��֪����ԭʼͼ����з��࣬ȷ����͵����Ϊ10�ţ�ȷ��Ϊ85.83%��29������н���15�������ȷ�ʴ���99.9%��ʹ��Ŀ�����Ļ��㷨��ÿ�������ȷ�ʶ���99.5%���ϣ���26�������ȷ�ʾ�����99.9%��10�������ȷ��Ҳ������99.67%��˵��Ŀ�����Ļ��㷨�ܹ�ʮ����������������ȷ�ʡ�
5 ����
1) �����һ�ֻ��ڱ�Ե��ȡ�������ͨ���Ŀ�����Ļ��㷨���ڶ�29�ֲ�ͬ�ߴ����˿����ĸ�͵�Ƭ�ķ��������У�ϵͳ������ȷ�ʴ�97.59%������99.96%��
2) ����������㷨�ܹ��Ա��������Ĺ�ҵͼ�����ȷ���࣬��Ŀ��ռͼ�������С�Ҳ�ͬ����ͼ�����ʱ��ʹ��Ŀ�����Ļ��㷨��ͼ�����Ԥ�����ܹ�������������ȷ�ʡ�ͬʱ������ʶ����ͬ��״����ͬ�ߴ��ͼ����������Ҳ�кܸߵ�ȷ�ʡ�
�ο����ף�
[1] ������, ��ݸ�, л��. ����LabVIEW��BP����������ʶ��ϵͳ[J]. �DZ������봫����, 2017(1): 119-122.
HE Xiaoyang, XU Huigang, XIE Qi. Recognition system of parts based on LabVIEW and BP neural network[J]. Instrument Technique and Sensor, 2017(1): 119-122.
[2] ����ǿ. ���ڻ����Ӿ��Ĺ�ҵ�����˷ּ�ϵͳ���[D]. ������: ��������ҵ��ѧ��Ϣ���������ѧԺ, 2016: 1.
HE Zeqiang. Design of industrial robot sorting system based on machine vision[D]. Harbin: Harbin Institute of Technology. School of Information and Electrical Engineering, 2016: 1.
[3] GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning[M]. Cambridge, MA: The MIT Press, 2016: 3.
[4] ˾С��, ���Ľ�, ��һ��. �����Ӿ������ʶ��Ͷ�λ[J]. ��ϻ������Զ����ӹ�����, 2016(10): 70-73.
SI Xiaoting, WU Wenjiang, SUN Yilan. The identification and positioning of parts based on machine vision[J]. Modular Machine Tool & Automatic Manufacturing Technique, 2016(10): 70-73.
[5] ������, ������, ��ѩ, ��. ���ڻ����Ӿ��Ĺ�ҵ�����˷ּ����о�[J]. ����ҵ�Զ���, 2013(17): 25-30.
LIU Zhenyu, LI Zhongsheng, ZHAO Xue, et al. Research of sorting technology based on industrial robot of machine vision[J]. Manufacturing Automation, 2013(17): 25-30.
[6] �����, ����, �����, ��. ����LBP��SVM�Ĺ���ͼ������ʶ���о�[J]. ����������ѧѧ��, 2016, 30(1): 77-84.
WU Yihong, XU Gang, JIANG Juanjuan, et al. Research on workpiece image feature recognition based on LBP and SVM[J]. Journal of Chongqing University of Technology (Natural Science), 2016, 30(1): 77-84.
[7] �볤��, ���, ��Ծ��. ���KPCA��SVM�Ļ�е�����״ʶ���о�[J]. ��е�������Զ���, 2016(4): 132-134.
FENG Changjian, WU Bin, LUO Yuegang. Research on shape recognition of mechanical parts based on hybrid KPCA and SVM[J]. Machine Building & Automation, 2016(4): 132-134.
[8] �, ����, �����, ��. �����Ӿ��ĺ��ӹ�������ʶ��������㷨�о�[J]. ��ֵ����, 2016, 35(4): 97-101.
LI Chun, LI Lin, ZOU Yanbiao, et al. Research on on-line recognition and classification of weldment based on machine vision[J]. Value Engineering, 2016, 35(4): 97-101.
[9] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504.
[10] ����, ���, ������, ��. �������ѧϰ���ֻ��ͼʶ��[J]. �Ĵ���ѧѧ��(���̿�ѧ��), 2016, 48(3): 94-99.
ZHAO Peng, WANG Fei, LIU Huiting, et al. Sketch recognition using deep learning[J]. Journal of Sichuan University (Engineering Science Edition), 2016, 48(3): 94-99.
[11] L CUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 2001, 86(11): 2278-2324.
CUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 2001, 86(11): 2278-2324.
[12] �����, ��һ��, ������. ����ͼ�������Է��������������IJ����涨λ��ʶ��[J]. ũҵ����ѧ��, 2017, 33(6): 156-162.
YANG Guoguo, BAO Yidan, LIU Ziyi. Localization and recognition of pests in tea plantation based on image saliency analysis and convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering, 2017, 33(6): 156-162.
[13] ���Ƴ�, ��ͯ��, ֣ΰ, ��. ������Ⱦ���������ķ�����Ҫ���ٷ���ʶ��[J]. ũҵ����ѧ��, 2017, 33(15): 219-226.
ZHOU Yuncheng, XU Tongyu, ZHENG Wei, et al. Classification and recognition approaches of tomato main organs based on DCNN[J]. Transactions of the Chinese Society of Agricultural Engineering, 2017, 33(15): 219-226.
[14] SERMANET P, EIGEN D, ZHANG X, et al. OverFeat: integrated recognition, localization and detection using convolutional networks[EB/OL]. [2013-12-21]. https://arxiv.org/ abs/1312.6229.
[15] HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]// Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770-778.
[16] ��ѧ, ������. ����CNN����������α��������д����ʶ��[J]. ����������ѧѧ�� (��Ȼ��ѧ��), 2014, 42(1): 72-76.
GAO Xue, WANG Youwang. Recognition of similar handwritten Chinese characters based on CNN and random elastic deformation[J]. Journal of South China University of Technology(Natural Science), 2014, 42(1): 72-76.
[17] GLOROT X, BORDES A, BENGIO Y, et al. Deep sparse rectifier neural networks[C]// International Conference on Artificial Intelligence and Statistics. Cambridge, MA: The MIT Press, 2012: 315-323.
[18] ZHOU Y T, CHELLAPPA R. Computation of optical flow using a neural network[C]// IEEE International Conference on Neural Networks. Piscataway, NJ: IEEE, 1988: 71-78.
[19] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(2): 2012.
[20] SIMONYAN K, ZISSERMAN A. Very Deep Convolutional networks for large-scale image recognition[EB/OL]. [2014-10-15]. https://arxiv.org/abs/1409.1556.
[21] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[22] KINGMA D P, BA J. Adam: A method for stochastic optimization[EB/OL]. [2014-12-22]. https://arxiv.org/abs/ 1412.6980.
[23] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL]. [2015-01-11]. https://arxiv.org/abs/1502.0316.
(�༭ �Կ�)
�ո����ڣ�2018-03-12�������ڣ�2018-04-26
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61402374) (Project(61402374) supported by the National Natural Science Foundation of China)
ͨ�����ߣ��Ⱞ�������ڣ���ʿ����ʦ���������ܻ����ռ���ϵͳ�����о���E-mail��agwu@tju.edu.cn
ժҪ��Ϊ�����ҵ�����жԲ�ͬ��������Զ���������⣬���һ�ֻ��ھ����������ģʽʶ���㷨����29�ֲ�ͬ�ߴ����˿����ĸ�͵�Ƭ���з��ࡣ���Ȳɼ������������ͼ�����ݣ�ͨ��������ǿ�õ����ݼ���Ȼ�����һ�ּľ��������硣���һ�ֶ�ͼ���е�Ŀ��λ�ý������Ļ���ͼ��Ԥ�����㷨�����ܹ���ȡͼ����Ŀ�����ڵ��������ƶ���ͼ������λ�á��о�����������벻����Ŀ�����Ļ��㷨�Ĵ�ͳ������ȣ�����ȷ�ʴ�97.59%������99.96%���������ȷ�ʵ������ȷ�ʴ�85.83%������99.67%��ʹ�þ���������Ա���������Ŀ�����Ե�ͼ����з���ʱ��ʹ�ñ��������Ŀ�����Ļ��㷨����ͼ��Ԥ�����ܹ�������������ʶ��ȷ�ʡ�
[1] ������, ��ݸ�, л��. ����LabVIEW��BP����������ʶ��ϵͳ[J]. �DZ������봫����, 2017(1): 119-122.
[2] ����ǿ. ���ڻ����Ӿ��Ĺ�ҵ�����˷ּ�ϵͳ���[D]. ������: ��������ҵ��ѧ��Ϣ���������ѧԺ, 2016: 1.
[3] GOODFELLOW I, BENGIO Y, COURVILLE A. Deep learning[M]. Cambridge, MA: The MIT Press, 2016: 3.
[4] ˾С��, ���Ľ�, ��һ��. �����Ӿ������ʶ��Ͷ�λ[J]. ��ϻ������Զ����ӹ�����, 2016(10): 70-73.
[5] ������, ������, ��ѩ, ��. ���ڻ����Ӿ��Ĺ�ҵ�����˷ּ����о�[J]. ����ҵ�Զ���, 2013(17): 25-30.
[6] �����, ����, �����, ��. ����LBP��SVM�Ĺ���ͼ������ʶ���о�[J]. ����������ѧѧ��, 2016, 30(1): 77-84.
[7] �볤��, ���, ��Ծ��. ���KPCA��SVM�Ļ�е�����״ʶ���о�[J]. ��е�������Զ���, 2016(4): 132-134.
[8] �, ����, �����, ��. �����Ӿ��ĺ��ӹ�������ʶ��������㷨�о�[J]. ��ֵ����, 2016, 35(4): 97-101.
[10] ����, ���, ������, ��. �������ѧϰ���ֻ��ͼʶ��[J]. �Ĵ���ѧѧ��(���̿�ѧ��), 2016, 48(3): 94-99.
[13] ���Ƴ�, ��ͯ��, ֣ΰ, ��. ������Ⱦ���������ķ�����Ҫ���ٷ���ʶ��[J]. ũҵ����ѧ��, 2017, 33(15): 219-226.
