
֧��������ƽ�����б����������·���
�����������ڣ����
(�����Ƽ���ѧ ���繤�����Զ���ѧԺ������ ��ɳ��410073)
ժ Ҫ��
�⣬���һ���µ�����֧��������(SVM)����ƽ������б�������������֤������SVMƽ�����б�����SVM���Ž���ƽ����ij�Ҫ�������������ռ�����ⷽ���ϣ�������ѵ�������ķֲ�����ij�ֲ���ʽ��ϵ���ò���ʽ��������ѵ���������Եijͷ�����C+��C-�йأ��빫���ijͷ�����C�ء��������б����Ļ����ϣ�ͨ��ɸѡѵ�������㼰���Եijͷ�����������SVM�Ż������̣�Ϊ��Ч����SVMƽ����IJ����ṩ�������ݺͼ����ֶΡ��������ʵ�������÷�����Ч��
�ؼ��ʣ�
֧�����������ͷ�������ƽ������������
��ͼ����ţ�TP181 ���ױ�־�룺A ���±�ţ�1672-7207(2012)07-2648-07
A new method for discrimination and modification of null solutions in support vector machines
LIU Chun-ming, ZUO Lei, WU Jun
(College of Mechatronics Engineering and Automation, National University of Defence Technology,
Changsha 410073, China)
Abstract: For binary classification problems, a new method for discrimination and modification of null solutions in linear support vector machines (SVMs) was proposed. The following theorems for discrimination of null solutions in SVMs were proved: The necessary and sufficient conditions for the optimal solution of SVMs being a null solution are that for a given training set, the distribution of the positive and negative samples must satisfy an inequality which is related to the respective penalty parameters C+, C- of the two classes, and is independent of the shared penalty parameter C. Based on the above results, a modification method for null solutions in SVMs was presented by selecting samples in the training set, and adjusting the values of penalty parameters, which provides theoretical support and technique method for avoiding generating null solutions in SVMs. Computational examples illustrate the effectiveness of the proposed methods.
Key words: support vector machine; penalty parameter; null solution; convex hull
���ڽṹ������С��ԭ����ͳ��ѧϰ�����ǽ���������ѧϰ���۵���Ҫ�о��ɹ���Ϊ�о�����ѵ����������µ�ͳ��ģʽʶ�𣬲�Ϊ���㷺�Ļ���ѧϰ���⽨��һ���Ϻõ����ۿ�ܡ�ͬʱ��������Ҳ��չ��һ�ָ�Ч�ķ�����ѧϰ�㷨����֧��������(SVM)[1-4]��֧���������ڽ��С�����������Լ���άģʽʶ�������б��ֳ��������е����ƣ��ܹ�������ڴ�ͳģʽʶ���ķ������ܡ����ڲ���֧�������������������ʱ���ܻ�����б�ƽ��ķ�����Ϊ����������������ѵ�������������ռ��еķֲ��Լ����Եijͷ����Ӳ�ͬ��������ƽ�������⡣���֧������������ƽ���⣬��ô�����б������������ռ��е�����������Ϊһ�࣬�����õ������Է��������������á���ˣ�����֧��������ƽ��������ı���ԭ�������ۺ�ʵ��Ӧ���ж�������Ҫ�����塣��֧����������ͳ��ѧϰ���۵������о��У��ص�����α�����һ����ķ���������÷������б����������ṹ��[5-11]������ƽ��������ı���ԭ��ȱ��ȫ������ķ������о�ƽ���������ԭ��������ָ������������ƣ����ҿ���ʹ֧�����������۸������ơ�Bennett��[12]����һ��ƽ����������б����÷���ͨ����ij��ѵ�������ļ�Ȩϵ�����������жϣ�������������ϵ���к�����ã����Ҳ���ֱ�۵�ָ������ɸѡѵ�������͵����ͷ����ӣ�Arreola ��[13-15]Ҳ�������ƵĽ��ۡ��������ȶ�����֧����������Ŀ�꺯����ѵ�������ķֲ����з��������һ���µĻ��������ֲ���ƽ�����б����̶�����������ۣ�Ȼ�����۸���ѵ�������ijͷ����Ӷ�ƽ���������Ӱ�죻����������ƽ��������ļ���;����ʩ���������ʵ����������ĵĽ����ܹ�ֱ�۵�ָ��ɸѡѵ�������͵����ͷ����ӣ�����SVMƽ����IJ�����
1 ����֧������������
֧���������Ľṹ������С��ԭ��(SRM)Ҫ���ڴ�ͳ�ľ��������С��ԭ��(ERM)����ͬ��ERM��ͼ��С��ѵ�����ϵ�����������SRM��ͼ���öԺ����ṹ�����ԵĿ�������С���������յ��Ͻ磬�Ӷ�ʹѧϰ������ø��õ��ƹ����ܣ���ǡǡ��ͳ��ѧϰ��������Ҫ��Ŀ��֮һ[4]��֧���������Ļ����㷨��ģ������Զ����������ģ���˱��ĵ������ص���ʹ��֧�����������ж�ֵ���ࡣ
ͼ1��ʾΪ�����ռ��е������б�ƽ�档��ͼ1��ʾ������һ����ij�����ռ�ij�ƽ���ѵ�����������ж�ֵ��������⡣ѵ��������Ϊ��
![]() (1)
(1)
���У�����xi�����ǴӶ�����������ȡijЩ����ֱ�ӹ����������Ҳ������ԭʼ����ͨ��ij���˺���ӳ�䵽�˿ռ��е�ӳ��������
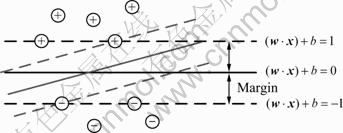
ͼ1 �����ռ��е������б�ƽ��
Fig.1 Optimal distinguish plane in feature space
�������ռ��й����б�ƽ��Ϊ��
![]() (2)
(2)
ʹ�ã�
![]() (3)
(3)
����i=1, 2, ��, l��
���Լ�������߽����С����Ϊ��
![]() (4)
(4)
����SVM���Ż��б�ƽ��Ķ��壬�Ը��б�ƽ������������м�����������ʽ(3)������£������ʹ![]() ���ʱ���б�ƽ��ķ�����w��ƫ����b���ɼ��������б�ƽ������ȼ�����С��ʽ(5)��
���ʱ���б�ƽ��ķ�����w��ƫ����b���ɼ��������б�ƽ������ȼ�����С��ʽ(5)��
![]()
![]() (5)
(5)
ͨ��ʽ(5)��õ��б�ƽ��Ϊ![]() ��ƽ��
��ƽ��![]() ��
��![]() �ϵ����������֧��������
�ϵ����������֧��������
�������Բ��ɷֵ�ѵ���������������ɳڱ���![]() �������ͷ�����C��0����ʽ(5)��дΪ�����������⣺
�������ͷ�����C��0����ʽ(5)��дΪ�����������⣺
![]()
![]() (6)
(6)
��ʽ(5)��(6)�������һ�����͵���Լ���Ķ������Ż����⡣
2 һά�����ռ���ƽ������б���
ͼ2��ʾΪһά�����ռ��е�ƽ�������������ڶ�ͼ2�е�ѵ����������б�ƽ��ʱ������ʽ(6)�е�Cȡ��ֵ��ֻҪ���ڵ���0���õ����б�ƽ�涼��ƽ���Ľ����![]() ��
��![]() �Ľ����ƽ���⡣
�Ľ����ƽ���⡣
������������У��б���![]() ���Ƕ�����Ϊʵ���ֱ�ߡ�Ϊ���ڷ�����ͼ3�ֱ�������
���Ƕ�����Ϊʵ���ֱ�ߡ�Ϊ���ڷ�����ͼ3�ֱ�������![]() ��
��![]() ����������ѵ�������㡣��ͼ3�пɼ����б�����б����w��Ŀ�꺯��������
����������ѵ�������㡣��ͼ3�пɼ����б�����б����w��Ŀ�꺯��������![]() �е�
�е�![]() ������ͼ3�����߶εij��Ⱥ͡�
������ͼ3�����߶εij��Ⱥ͡�
![]()
ͼ2 һά�����ռ��е�ƽ����������
Fig.2 Condition of generating null solutions in one dimension
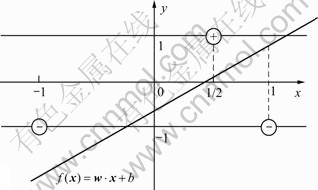
ͼ3 Ŀ�꺯���ļ�������
Fig.3 Geometric signification of objective function
��С��![]() ��������С��ͼ3�����߶εij��Ⱥ͡���ͼ3�ɼ������б���Ϊ
��������С��ͼ3�����߶εij��Ⱥ͡���ͼ3�ɼ������б���Ϊ![]() ʱ��ʹ��
ʱ��ʹ��![]() ȡ����Сֵ2C����w=0��b=-1ʱ��
ȡ����Сֵ2C����w=0��b=-1ʱ��![]() ȡ����Сֵ2C�����ͬʱ��
ȡ����Сֵ2C�����ͬʱ��![]() Ҳȡ����Сֵ0����ˣ���С��Ŀ�꺯��ʽ(6)���õ����б�ƽ��Ϊ
Ҳȡ����Сֵ0����ˣ���С��Ŀ�꺯��ʽ(6)���õ����б�ƽ��Ϊ![]() ���������е������㶼��Ϊ���ࡣ
���������е������㶼��Ϊ���ࡣ
���ƽ�����������ô������ѵ����������Ŀ���ڸ���ѵ����������Ŀʱ���õ����б�ƽ��Ϊ![]() ����֮��
����֮��![]() ����Ŀ���ʱΪ
����Ŀ���ʱΪ![]() ������
������![]() ��
��
Ϊ��ʧһ���ԣ��ܼ�������ѵ����������ĿС�ڵ��ڸ���ѵ����������Ŀ�����ƽ���������![]() ��������������һ����(����Ĭ�ϲ�����ƽ�������
��������������һ����(����Ĭ�ϲ�����ƽ�������![]() )�����û�в���ƽ���⣬��ش���һ��x0ʹ��
)�����û�в���ƽ���⣬��ش���һ��x0ʹ��![]() �����ԣ���ʽ(6)���õ����κ��б��������Ǵ���x 0��ʹ��
�����ԣ���ʽ(6)���õ����κ��б��������Ǵ���x 0��ʹ��![]()
![]() ����
����
![]() (7)
(7)
��ѵ�������У�������������Ϊ��![]() ����������Ϊ��
������������![]() ������
������![]() ���������
���������![]() ��
��![]() �ֱ��ʶ�����Ƿ��ܵ��ͷ����ܳͷ�������
�ֱ��ʶ�����Ƿ��ܵ��ͷ����ܳͷ�������![]() ������
������![]() ��Ϊ��С��Ŀ�꺯����δ�ܳͷ�����������Ӧ��
��Ϊ��С��Ŀ�꺯����δ�ܳͷ�����������Ӧ��![]() ���ܳͷ���������Ҫ����������
���ܳͷ���������Ҫ����������
![]()
����Ӧ��ʽ(7)��ȥ����b��С����Ŀ�꺯��Ϊ��
![]()
![]()
![]()
![]()
![]()
![]()
![]() (8)
(8)
�����Ϸ������۵Ļ����ϣ��ɸ������µ�SVMƽ�����б�����
����1 ��һά�����ռ��У�Ӧ��ʽ(6)���õ�ƽ����ij�ֱ�Ҫ�����ǣ���ѵ��������Ŀ���һ��(��Ŀ���ʱ��ÿһ�࣬�������Ϊ����)�е�ÿ��ѵ������x0�����㣺
 (9)
(9)
֤����
��ʽ(6)���õ����κ��б��������Ǵ���x0��ʹ��![]() ��Ŀ�꺯��ʽ(8)ʽw�Ķ��ζ���ʽ�����Ե���ȡ��Сֵʱ��w=0�ȼ��ڶ����е������б���
��Ŀ�꺯��ʽ(8)ʽw�Ķ��ζ���ʽ�����Ե���ȡ��Сֵʱ��w=0�ȼ��ڶ����е������б���![]() �����㣺
�����㣺
![]()
��

Ϊ��ʧһ���ԣ�����ֻ����w��0�������w��0ʱͬ����
��w��0ʱ����Ϊ![]() ������
������![]() ��x0�ĸ��������㶼���ܳͷ������������Ӧ��
��x0�ĸ��������㶼���ܳͷ������������Ӧ��![]() ������
������
![]() �������ڸ�����x0��
�������ڸ�����x0��![]() Ϊ��ֵ����
Ϊ��ֵ����
��![]() �Ķ����ܳͷ��������㣬���Ӧ��
�Ķ����ܳͷ��������㣬���Ӧ��![]() ��Ȼ������
��Ȼ������![]() ��x0��������������ȫ���ܵ��ͷ�������ƽ���������㣺
��x0��������������ȫ���ܵ��ͷ�������ƽ���������㣺
![]()
Ҳ���Ƕ����е������б������㣺
![]()
���ԣ���С��Ŀ�꺯��ʱ��w=0�ȼ��ڶ����е������б���![]() �����㣺
�����㣺
![]()
�������е�x0�����㣺
![]() (10)
(10)
�Ѹ���������С��������Ϊ��![]() ����Ӱ���������������
����Ӱ���������������![]() �����еĸ������������ܳͷ�����������ʱ�б�ʽ(10)���ȼ����б�
�����еĸ������������ܳͷ�����������ʱ�б�ʽ(10)���ȼ����б�
![]() ��������
��������![]() �����еĸ��������������ܳͷ�����������ʱ�б�ʽ(10)���ȼ����б�
�����еĸ��������������ܳͷ�����������ʱ�б�ʽ(10)���ȼ����б�![]() ��������
��������![]() ������i=1, ��, n-1����ʱ���������ܳͷ�����ĿΪn-i����ʱ�б�ʽ(10)���ȼ����б�
������i=1, ��, n-1����ʱ���������ܳͷ�����ĿΪn-i����ʱ�б�ʽ(10)���ȼ����б�![]() ��
��![]()
![]() ����ֻ��Ը���ѵ�������е�ÿ������x0������ʽ(10)��
����ֻ��Ը���ѵ�������е�ÿ������x0������ʽ(10)��
֤�ϡ�
3 ��ά�����ռ��е�ƽ�����б�
�ڶ�ά�����ռ䣬Ӧ��ʽ(6)���õ�SVMƽ������б��������Դ�һά���εõ��ƹ㣺
����2 �������ռ��У�Ӧ��ʽ(6)���õ�ƽ����ȼ��ڶ�ѵ��������Ŀ���һ��(��Ŀ���ʱ��ÿһ�࣬�������Ϊ����)�е�ÿ��ѵ������x 0�������ⷽ��w�ϣ����㣺
![]() (11)
(11)
����![]() �����
���б���![]() �Ը��������ijͷ���ʶ���ͷ�Ϊ1������Ϊ0��
�Ը��������ijͷ���ʶ���ͷ�Ϊ1������Ϊ0��
��һά�����ռ��У�������2������������ڶ�ά�����ռ��У�������360�㡣Ȼ�����ڶ�ά�����ռ��У�������࣬�������Ƿͷ�Ҳ�����жϣ��ʲ������㡣������������������ĸ���[14]��
��x1, x2, ��, xn�������ռ��е�n���㣬��Q�ǰ�����Щ�����С����(����)����![]()
![]() ��
��![]() ��
��![]() ��
��![]() ��
��
���2��ѵ�������ı������ཻ����ô2����֮������߶ε��д���(��ƽ��) f(x)=0��������֧�������������Ž�[14]�����Ҷ����е�����ѵ����������f(x)��1������ѵ����������f(x)��-1��Ϊ�˱��ڶ�ѵ���������з������У�
����1 �������ռ��У����ѵ��������Ŀ�ٵ�һ��(��Ŀ���ʱ�е�ÿһ��)��ѵ���������ģ�������һ��ѵ���������ɵı���֮�⣬��ôӦ��ʽ(6)���ز�����ƽ���⡣
֤����Ϊ��ʧһ���ԣ�����������Ϊ��![]()
![]() ������������
������������![]() ������m��n����
������m��n����
������������![]() �����ڸ����������ɵı����ڣ������������������ɵı����븺���������ɵı������ཻ�������һ�������б���
�����ڸ����������ɵı����ڣ������������������ɵı����븺���������ɵı������ཻ�������һ�������б���![]() ��ʹ�ã�
��ʹ�ã�
![]()
![]()
��f(x)���������з���ʱ�����еĸ������������ܵ��ͷ����ʴ���x0��ʹ�ã�
![]()
![]()
������
![]() ��
��![]()
��ʽ������ʽ(11)��Ҫ��Ӧ��ʽ(6)���õ��IJ���ƽ���⣬�����֤��
ͼ4��������������һ��ı������Ҳ�����ƽ������������ͼ4�У��������������ĺ������������ķֱ�������һ��ı����ڣ������õ��IJ���ƽ���⣬��������1ֻ�dz�����������DZ�Ҫ������
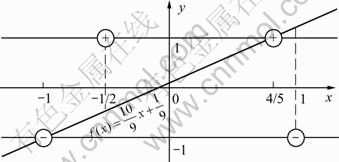
ͼ4 ���Ķ�������һ��ı������Ҳ�����ƽ��������
Fig.4 Center of gravity falling within closed convex hull of other class and not generating null solutions
����2 �������ռ��У���Ŀ��ͬ��2��ѵ��������Ӧ��(6)ʽ���õ�ƽ����ȼ���2������ѵ���������غϡ�
֤������Ҫ�ԡ������ⷽ��w�ϣ������б���![]() ��ʹ�����еĸ��������ܵ��ͷ�������
��ʹ�����еĸ��������ܵ��ͷ�������![]() �����ɶ���2��������ƽ�������У�
�����ɶ���2��������ƽ�������У�
![]()
���ԣ�
![]()
��Ϊ2��ѵ��������Ŀ��ͬ��ͬ���У�
![]()
����
![]()
��w�������ԣ��ɵ�![]() ��
��
����ԡ��Ը��������е�ÿ������x0�������ⷽ��w�ϣ�![]() ���б���
���б���![]() �Ը��������ijͷ���ʶ����
�Ը��������ijͷ���ʶ����![]() ��0ʱ��
��0ʱ��![]() ��
��![]() ʱ��
ʱ��![]() �������У�
��������
![]()
�����õ�ƽ���⣬�����֤��
4 ���ڳͷ�����C��ƽ�����б��� ����
��2���������治ͬ������£������벻ͬ�ijͷ�����![]() ��
��![]() ����ʱ��Ŀ�꺯��Ϊ��
����ʱ��Ŀ�꺯��Ϊ��
![]()
![]()
![]() (12)
(12)
�ȼ���ʽ(6)��C=1����������������Ŀ�ֱ����ӵ�![]() ����
����![]() �������Σ�ͬ���ɵã�
�������Σ�ͬ���ɵã�
����3 �������ռ��У�Ӧ��ʽ(12)���õ�ƽ����ȼ��ڶԼ���![]() �д��һ��(���ʱ�е�ÿһ�࣬�������Ϊ����)�е�ÿ��ѵ������x0�������ⷽ��w�ϣ�����ʽ(13)��
�д��һ��(���ʱ�е�ÿһ�࣬�������Ϊ����)�е�ÿ��ѵ������x0�������ⷽ��w�ϣ�����ʽ(13)��
![]() (13)
(13)
����![]() �����
���б���![]() �Ը��������ijͷ���ʶ���ͷ�Ϊ1������Ϊ0��
�Ը��������ijͷ���ʶ���ͷ�Ϊ1������Ϊ0��
����3 �������ռ��У��������![]() ��С��һ��(���ʱ�е�ÿһ��)��ѵ���������ģ�������һ��ѵ���������ɵı���֮�⣬��ôӦ��(12)ʽ���ز�����ƽ���⡣
��С��һ��(���ʱ�е�ÿһ��)��ѵ���������ģ�������һ��ѵ���������ɵı���֮�⣬��ôӦ��(12)ʽ���ز�����ƽ���⡣
����4 �������ռ��У�����![]() ��2��ѵ��������Ӧ��ʽ(12)���õ�ƽ����ȼ���2��ѵ�������������غϡ�
��2��ѵ��������Ӧ��ʽ(12)���õ�ƽ����ȼ���2��ѵ�������������غϡ�
Bennett��[12]Ҳ�õ�������4��ͬ�Ľ��ۣ�����2��ѵ�����������غϵ�������ٷ��������Կ��Խ��ȶ��ػ�����Թ滮��������
��Щʱ��Ҫ��ijһ�����ֵ���ȷ(������ijͷ�������![]() )�������½��ۣ�
)�������½��ۣ�
����5 �������ռ��У�Ҫ��ijһ�����ֵ���ȷ����ôӦ��ʽ(12)���õ�ƽ����ȼ�����һ���ѵ�������������ڸ���ѵ���������ɵı���֮�ڡ�
֤�� ������踺�����ֵ���ȷ��
��Ҫ�ԡ���Ϊʽ(12)�еijͷ�����![]() ������
������![]() ��������3��֤��
��������3��֤��
����ԡ��ɶ���3��֪���õ�ƽ����ȼ��ڶԸ����е�ÿ������x0�������ⷽ��w���У�
![]() (14)
(14)
�����ڸ��������ܵ��ͷ�ʱ��![]() ��0��ʽ(14)��Ȼ������
��0��ʽ(14)��Ȼ������
�����ڸ��������ܵ��ͷ�ʱ��![]() ������
������![]() ������i=1, ��, n������Ϊ�����������������ڸ����������ɵı����ڣ����Դ���
������i=1, ��, n������Ϊ�����������������ڸ����������ɵı����ڣ����Դ���![]() �У�ʹ�ã�
�У�ʹ�ã�
![]()
![]()
![]()
ʽ(14)�����������֤��
�����������������Ը������ڳͷ����ӵ�SVMƽ������������������
���ͷ����Ӳ��ܸı�ʱ������ɸѡһЩ������ʹ��ѵ��������Ŀ�ٵ�һ��(��Ŀ���ʱ�е�ÿһ��)��ѵ���������ģ���������һ��ѵ���������ɵı����ڣ�����ʹ2���ѵ��������Ŀ��ͬ��ֻҪ����2���ѵ�����������غϼ��ɡ�
���ͷ����ӿ��Ըı�ʱ�����Ըı�ͷ����ӵĴ�С��Ҳ����ɸѡһЩ������ʹ�ü���![]() ��С��һ��(���ʱ�е���һ��)��ѵ���������ģ���������һ��ѵ���������ɵı����ڣ�����ʹ2������
��С��һ��(���ʱ�е���һ��)��ѵ���������ģ���������һ��ѵ���������ɵı����ڣ�����ʹ2������![]() ��ֻҪ����2���ѵ�����������غϼ��ɡ�
��ֻҪ����2���ѵ�����������غϼ��ɡ�
��Ҫ��ijһ�����ֵ���ȷʱ��ֻ�ܹ�ͨ��ɸѡ������ʹ����һ���ѵ�������������ڸ����������ɵı���֮�⡣
5 ����ʵ��
ͼ5��ʾΪ��ά�����ռ���������ѵ�������ֲ�������ѵ����������ĿС�ڸ���ѵ����������Ŀ��Ӧ��ʽ(6)���õ���ƽ���⡣
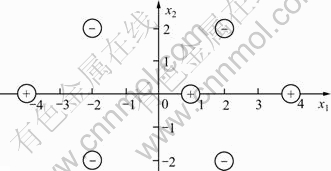
ͼ5 ���������е�ѵ�������ֲ�
Fig.5 Training sample distribution in simulation experiment
���������ѵ�������е�(-4, 0)ȥ������ô����ѵ�����������ľ����ڸ���ѵ���������ɵı���֮�⣬�ʿ��Ա���ƽ����IJ�������ͼ6��ʾ������C=1������Ϊ����ѵ�������������븺��ѵ�����������IJ��غϣ����Ե�����������Եijͷ�����Ҳ���Ա���ƽ����IJ�������ͼ7��ʾ������C+=4��C-=3��
��Ҫ����ѵ����������ֵ���ȷʱ��ͬ��������ѵ�������е�(-4, 0)ȥ������ô����ѵ�����������ľ������˸���ѵ���������ɵı���֮�⣬�����ͼ6��ʾ������C+=4����Ҫ������ѵ����������ֵ���ȷʱ���Ѹ���ѵ�������е�(-2, 2)ȥ������ô����ѵ�����������ľ���������ѵ���������ɵı���֮�⣬�����ͼ8��ʾ������C-=4��
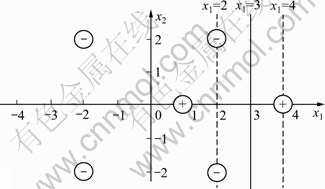
ͼ6 ͨ��ɸѡ������������ƽ����IJ���(Ҫ������������ȷ����)
Fig.6 Avoiding generation of null solutions by filtering some samples (Negative-class training samples must be properly distinguished)
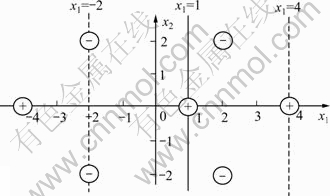
ͼ7 ͨ���������Գͷ�����������ƽ����IJ���
Fig.7 Avoiding generation of null solutions by adjusting respective penalty factors
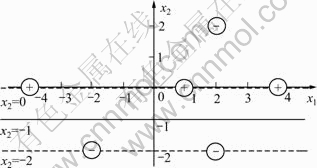
ͼ8 ͨ��ɸѡ������������ƽ����IJ���(Ҫ��������������ȷ����)
Fig.8 Avoiding generation of null solutions by filtering some samples (Positive-class training samples must be properly distinguished)
6 ����
1) ���۷�������֧������������ƽ�����ԭ�õ�һά�����ռ���ƽ����������µ��б����̶��ƹ㵽��ά�����ռ䡣Ȼ�����һЩ���ۣ�������ƽ���������һЩ��ʩ�����ʵ����֤��������Ч�ԡ�
2) �������ƽ��������ķ�����ͨ��ɸѡѵ�����������ı�ѵ���������ģ�����ʧȥ�ܶ���������ԣ��ںܴ�ij̶���Ť�������ķֲ���������ʱ������ɸѡҲ�������ף��������İ취������2���������IJ��غϵ�����£���2�������ijͷ����ӣ�ʹ��![]() ��
��
3) ��ƽ�������������£���Ȼͨ��һЩ��ʩ���Ա���ƽ����IJ�����Ȼ���õ��ķ������ķ������ܴ�������ʱӦ����ȡ���Ӻ��ʵ��������������б�Ҫ�������任��
�ο����ף�
[1] Cristianini N, Shawf-Taylor J. An introduction to support vector machines and other kernel-based learning methods[M]. Cambridge University Press, 2000.
[2] Burges C J C. A tutorial on support vector machine for pattern recognition[J]. Data Mining and Knowledge Discovery, 1998, 2(2): 121-167.
[3] Cortes C, Vapnik V. Support vector networks[J]. Machine Learning, 1995, 20: 273-297.
[4] ������, ����ƽ, ��ʿ��. ����֧���������Ľ���ֱ��ʽ����ѧϰ�㷨[J]. ����ѧ��, 2003, 14(3): 451-460.
CHEN Yi-song, WANG Guo-ping, DONG Shi-hai. A progressive transductive inference algorithm based on support vector machine[J]. Journal of Software, 2003, 14(3): 451-460.
[5] Bennett K, Blue J. A support vector machine approach to decision trees[R]. Troy, NY: Rensselaer Polytechnic Institute Math Repot, 1997
[6] Frphlich H, Chapelle O, Scholkopf B. Feature selection for support vector machines using genetic algorithm[J]. International Journal on Artificial Intelligence Tools, 2004, 13(4): 791-800
[7] Wan V, Renals S. Speaker verification using sequence discriminant support vector machines[J]. IEEE Transactions on Speech and Audio Processing, 2005, 13(2): 203-210
[8] Sungmoon C, Sang H O, Soo-Young L. Support vector machines with binary tree architecture for multi-class classification[J]. Neural Information Processing-Letters and Reviews, 2004, 2(3): 47-51
[9] Howley T, Madden MG. The genetic kernel support vector machine: description and evaluation[J]. Artificial Intelligence Review, 2005, 24(3/4): 379-395
[10] ������, �����, ��־ǿ. ���������ֲ���ƽ��Ľ���֧��������[J]. �������ѧ, 2007, 34(5): 174-176
TAO Xiao-yan, JI Hong-bing, MA Zhi-qiang. Proximal support vector machines for samples with unbalanced distribution[J]. Computer Science, 2007, 34(5): 174-176.
[11] ����, �����, ������, ��. ���ڱ�������������Ե���Է�����. ����ѧ��, 2002, 13(3): 404-409
TAO Qing, SUN De-min, FAN Jing-song, et al. Maximal margin linear classifier based on the contraction of the closed convex hull[J]. Journal of Software, 2002, 13(3): 404-409.
[12] Bennett K P, Mangasarian O L. Robust linear programming discrimination of two linearly inseparable sets[J]. Optimization Methods and Software, 1992, 1(1): 23-34.
[13] Arreola K Z, Fehr J, Burkhardt H. Fast support vector machine classification using linear SVMs[C]//18th International Conference on Pattern Recognition. Hong Kong: Pattern Recognition, 2006: 366-369.
[14] Arreola K Z, Fehr J, Burkhardt H. Fast support vector machine classification of very large datasets[R]. Freiburg: Albert Ludwigs University Freiburg Institute for Information, 2007.
[15] ��Сï, ȫ͢ΰ, �ž�. ����֧�������������ƽ����[J]. ���пƼ���ѧѧ��: ��Ȼ��ѧ��, 2007, 35(10): 57-59.
LIU Xiao-mao, QUAN Ting-wei, ZHANG Jun. Degenerate solution to linear support vector machine[J]. Journal of Huazhong University of Science and Technology: Nature Science Edition, 2007, 35(10): 57-59.
(�༭ ������)
�ո����ڣ�2011-05-03�������ڣ�2011-09-07
������Ŀ��������Ȼ��ѧ����������Ŀ(60774076, 90820302)
ͨ�����ߣ�������(1981-)��������ګ���ˣ���ʿ�о���������ģʽʶ��������ϵͳ�����о����绰��13974914442��E-mail: lccmmm@126.com
ժҪ����Զ���������⣬���һ���µ�����֧��������(SVM)����ƽ������б�������������֤������SVMƽ�����б�����SVM���Ž���ƽ����ij�Ҫ�������������ռ�����ⷽ���ϣ�������ѵ�������ķֲ�����ij�ֲ���ʽ��ϵ���ò���ʽ��������ѵ���������Եijͷ�����C+��C-�йأ��빫���ijͷ�����C�ء��������б����Ļ����ϣ�ͨ��ɸѡѵ�������㼰���Եijͷ�����������SVM�Ż������̣�Ϊ��Ч����SVMƽ����IJ����ṩ�������ݺͼ����ֶΡ��������ʵ�������÷�����Ч��
