Graph-based method for human-object interactions detection
来源期刊:中南大学学报(英文版)2021年第1期
论文作者:夏利民 吴伟
文章页码:205 - 218
Key words:human-object interactions; visual relationship; context information; graph attention network
Abstract: Human-object interaction (HOIs) detection is a new branch of visual relationship detection, which plays an important role in the field of image understanding. Because of the complexity and diversity of image content, the detection of HOIs is still an onerous challenge. Unlike most of the current works for HOIs detection which only rely on the pairwise information of a human and an object, we propose a graph-based HOIs detection method that models context and global structure information. Firstly, to better utilize the relations between humans and objects, the detected humans and objects are regarded as nodes to construct a fully connected undirected graph, and the graph is pruned to obtain an HOI graph that only preserving the edges connecting human and object nodes. Then, in order to obtain more robust features of human and object nodes, two different attention-based feature extraction networks are proposed, which model global and local contexts respectively. Finally, the graph attention network is introduced to pass messages between different nodes in the HOI graph iteratively, and detect the potential HOIs. Experiments on V-COCO and HICO-DET datasets verify the effectiveness of the proposed method, and show that it is superior to many existing methods.
Cite this article as: XIA Li-min, WU Wei. Graph-based method for human-object interactions detection [J]. Journal of Central South University, 2021, 28(1): 205-218. DOI: https://doi.org/10.1007/s11771-021-4597-x.

J. Cent. South Univ. (2021) 28: 205-218
DOI: https://doi.org/10.1007/s11771-021-4597-x
XIA Li-min(夏利民), WU Wei(吴伟)
School of Automation, Central South University, Changsha 410075, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2021
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2021
Abstract: Human-object interaction (HOIs) detection is a new branch of visual relationship detection, which plays an important role in the field of image understanding. Because of the complexity and diversity of image content, the detection of HOIs is still an onerous challenge. Unlike most of the current works for HOIs detection which only rely on the pairwise information of a human and an object, we propose a graph-based HOIs detection method that models context and global structure information. Firstly, to better utilize the relations between humans and objects, the detected humans and objects are regarded as nodes to construct a fully connected undirected graph, and the graph is pruned to obtain an HOI graph that only preserving the edges connecting human and object nodes. Then, in order to obtain more robust features of human and object nodes, two different attention-based feature extraction networks are proposed, which model global and local contexts respectively. Finally, the graph attention network is introduced to pass messages between different nodes in the HOI graph iteratively, and detect the potential HOIs. Experiments on V-COCO and HICO-DET datasets verify the effectiveness of the proposed method, and show that it is superior to many existing methods.
Key words: human-object interactions; visual relationship; context information; graph attention network
Cite this article as: XIA Li-min, WU Wei. Graph-based method for human-object interactions detection [J]. Journal of Central South University, 2021, 28(1): 205-218. DOI: https://doi.org/10.1007/s11771-021-4597-x.
1 Introduction
Nowadays, rapid progress has been made in visual detection and recognition tasks, comprising object detection [1-3], event detection [4], segmentation [5] and action recognition [6-10]. And the development of these tasks has laid a solid foundation for many related fields, including medical care, self-service retail, security and robotics. However, the successful implementation of such applications requires not only the instance- level detection and recognition, but also the understanding of scene semantics. In other words, it is more useful to understand “what happens in an image” than understand “what is in an image”. Existing research on high-level semantic understanding mainly focuses on scene graph generation [11, 12], visual relationships detection [13, 14], visual question answering (VQA) [15, 16], image caption generation [17] and visual reasoning [18]. Different from the aforementioned studies, we turn our attention to the important but rarely studied task called human-object interactions (HOIs) recognition, which would make a great contribution to image understanding.
HOIs detection which aims to infer possible interactions between the identified human and objects, is a potential research direction of visual relationship detection. In current research and applications, recognizing HOIs can be expressed as detecting triples like[19-23]. As we all know, it is more meaningful to understand the human-centric visual relationships than to understand other visual relationships, for human beings are the subject of society. With the advent of unmanned era, accurate detection and recognition of HOIs has huge demand in practical applications. However, HOIs detection is more complicated than identifying actions or objects separately, so it is still a challenging task. The focus of early works is to learn a powerful representation of HOIs, which models human pose, the appearance information of human and objects and spatial relationship between them [19, 24]. Due to the limitations of traditional handcraft features, the ability of early methods has not been fully developed. However, some of the ideas proposed in previous methods about using context still have far-reaching implications. In recent years, driven by the emergence of some large HOI datasets and the amazing performance of the target detectors based on convolutional neural network, recent works have learned deeper visual representations for HOIs recognition, with excellent performance on these datasets [21, 25-27]. Although many important visual recognition tasks depend heavily on context, these methods do not pay much attention to the significance of context for HOIs understanding tasks. According to psychological experiments, due to the non-isolated existence of objects in the scene, they constitute a very rich context relationship with other objects in the scene and the corresponding environment, which is very important for the recognition of human visual system [28] . For example, when a group of people are sitting around a table to eat, they will inevitably block each other. However, the detected cups, tables and tableware will help us to recognize that the action category of HOI should be eating, not meeting in the office. Recent work in computer vision has shown that graph, as high-level representation of the image, can well model the interactions between objects in image [12]. So, in order to make full use of the contextual cues from objects in the image, we use graph to visualize the rich relations of all instances in the image.
In this work, a novel graph-based approach is proposed for improving the effect of HOIs detection. It utilizes HOI graph to explicitly model all potential HOIs in the original input image. And the real interactions in the HOI graph can be accurately detected and recognized by using graph attention network (GAT) proposed in Ref. [29]. An overview of our proposed method is shown in Figure 1. The whole detection framework can be divided into two parts: 1) HOI graph representation of input image. Firstly, the deep convolutional features and the bounding boxes of the objects in the input image are obtained by the Faster R-CNN. All detected people and objects are regarded as nodes to construct a fully connected undirected graph. Then the graph is pruned to obtain an HOI graph that only retains the edges connecting human and object nodes. Finally, the node feature representations are acquired through two different node feature extraction networks respectively. 2) HOIs detection based on GAT. The obtained HOI graph with feature embedding is fed to the GAT. The output of the model is obtained in two steps. The first step is to judge the real interaction objects with the human based on the attention coefficients of the human node to the neighbor nodes obtained from the GAT output layer. Step 2 is that the HOI category of the human-object node pair judged in the first step are obtained by multiplying the action probabilities of human node and object node.
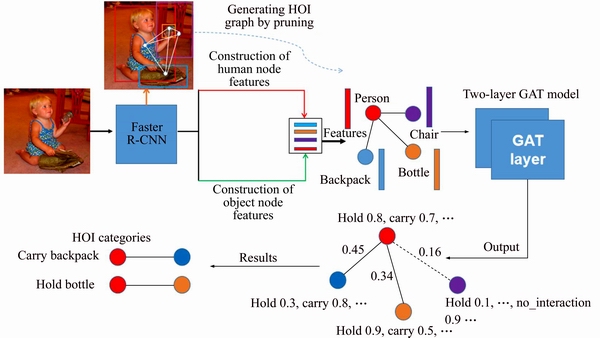
Figure 1 Overview of proposed method architecture (Firstly, the input image is constructed into a HOI graph manually, and then it is sent into the GAT model to infer the real human-object interactions in image)
The main contributions of this paper include: 1) The attention-based node feature extraction networks for object and human are proposed, which has strong robustness for modeling context information; 2) In order to make full use of the global structure information of the scene, a two-layer GAT network is used to broadcast and integrate the node information over the structure of the HOI graph; 3) The proposed model established new state-of-the-art performance on two large-scale HOI benchmark datasets.
The rest of this paper is organized as follows: Section 2 mainly reviews the related work of HOIs detection; Section 3 gives a brief description of HOI graph and introduces in detail the node feature extraction method of HOI graph proposed in this paper; Section 4 describes the HOIs recognition using GAT; Section 5 reports the results of the proposed method on two large datasets and verifies the effectiveness of the proposed method through ablative studies; Section 6 concludes this paper.
2 Related works
This section introduces the related works of this paper. We mainly review the works of human-object interactions. Meanwhile, since our work is to use graph neural network to explore the high-level relations between humans and objects, we briefly introduce the works on graph based network.
2.1 Human-object interaction
HOIs detection is a human-centric problem with fine-grained action categories. Using objects (such as playing basketball) to infer human action, rather than identifying individual action (play) or object instances (basketball), is critical to understand what is happening in the scene. Generally, HOIs detection can be divided into two categories: joint modeling methods based on traditional features and deep learning-based methods. The HOIs recognition methods mainly utilize the appearance of human and objects, posture information, spatial relationship between human and object, and context of interaction. In early phase, methods for HOIs detection mostly focused on modeling the co-occurrence or spatial relationship between human and manipulated objects. The object and human detectors they used were mostly based on handcrafted features.
For instance, GUPTA et al [19] combined a variety of perceptual tasks by a Bayesian approach to gain a deeper understanding of HOIs. PREST et al [30] proposed a weakly supervised learning method. It modeled the spatial information between the human body and the object using a set of visual feature detectors trained by the poselet for identifying and detecting the HOIs. Unlike direct encoding of human-object relationships [31], a more robust method for HOIs recognition, which simulated the interactive context between human and nearby objects, was proposed. Similar to Ref. [31], a mutual context model based on conditional random fields (CRF) was proposed by YAO et al [20], which jointly simulated objects and human poses in HOIs. This method improved the occlusion problem between objects but the workload was relatively large due to the huge number of annotations required for the training images. HU et al [24] used an exemplar-based approach to simulating the interaction between the person and the manipulated object. The method simulated the mutual structure between human and object in a probabilistic manner, thereby avoiding the indispensable of explicit human posture, and overcame the limitations of the existing methods relying heavily on the precise estimation of human body posture.
Obviously, most of these early works are based on low-level visual features with objects and body detectors, and their recognition accuracy is very limited. Recently, some HOIs detection models based on deep learning have been proposed because of the success of deep learning and the emergence of large HOI dataset [21, 25]. Specifically, CHAO et al [21] proposed a multi-stream model which encoded the configuration of human-object box pairs using a convolutional neural networks operating on a two channel binary image called IP (Interaction Pattern). GKIOXARI et al [32] used a mixture density network to predict the distribution over target object locations based on human appearance. Then, the predicted scores of each branch of multi-stream network were fused to accomplish the HOIs recognition task. As attention mechanism has shown excellent results in natural language processing and computer vision, FANG et al [22] introduced attention mechanism into HOIs recognition, and proposed a new paired body attention model, which can allocate different attention to different body pairs. QI et al [27] proposed a completely different end-to-end approach for inferring parse graph based on graph parsing neural network (GPNN). And all HOIs in the image can be predicted at the same time, without the need to predict in pairs as in previous methods. Unlike the works mentioned above, in order to solve the long tail issue, SHEN et al [26] presented a weakly supervised model which extended zero shot learning to HOI recognition. In contrast to previous works, our approach is more comprehensive in exploring local and global contexts.
2.2 Graph neural network
The concept of graph neural network (GNN) is first proposed in Ref. [33], which is mainly used to process graph-structured data. With the emergence of more and more graph-structured data in various fields, such as social network, 3D meshes, or telecommunication network, GNN variants applied to those kinds of irregular data emerged in endlessly, and have shown excellent performance in the corresponding tasks.
In order to avoid complex matrix operations, people have introduced convolution operations into the field of graphs. This algorithm can be divided into two major categories: spectral approaches and non-spectral approaches. GCN [34] is a representative work of spectral methods, and GAT is a representative work of non-spectral methods. The similarity between them is that the features of the neighboring nodes are aggregated to the central node (an aggregate operation), and the local stationary on the graph is used to learn new vertex feature expressions. The difference is that GCN uses the Laplacian matrix and GAT uses the attention coefficient.
In contrast, GAT performs better because the correlation between node features is better integrated into the model. It can be observed in the principle of GAT in Section 4.1 that the important learning parameters in the model are W and a(・), and these two parameters are only related to the node features, and have nothing to do with the structure of the graph. Therefore, changing the structure of the graph in the test task has little effect on GAT. However, since GCN needs to update the node features of the entire graph at a time, the parameters that the model needs to learn are largely related to the graph structure.
For the HOI detection, different training samples have different HOI graphs. This also leads to different graph structures, so networks that require a fixed graph structure (such as GCN) are not suitable for our task. Therefore, in our work, GAT is used to mine human-object relations and identify HOIs.
3 Graphical representation for HOI
As mentioned above, most of the current methods use independent human-object pairs to recognize HOIs in images. However, due to the lack of global structure information, their performance is often disturbed when occlusion exists. To solve this problem, we try to find a data structure that can fully express the relationship of objects in the image. Inspired by Ref. [15, 35-37], we choose the graph structure, which has been proved to have a strong ability to model relationships. Specifically, we construct a fully connected graph G=(V, E) by treating the instance objects in the scene as the nodes of the graph. It means that each object in the image is represented as a node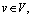 and the potential relationship between different objects is regarded as the edge
and the potential relationship between different objects is regarded as the edge 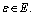 If there are a total of n objects in the image, the graph will be represented as an adjacency matrix An×n of size n×n, whose matrix element
If there are a total of n objects in the image, the graph will be represented as an adjacency matrix An×n of size n×n, whose matrix element 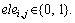 0 means that nodes i and j are not connected, and 1 means connected. In order to better represent our specific task, we only keep the edges connecting people and objects to obtain the graph structure called HOI graph. In other words, the elements in the adjacency matrix of the HOI graph indexed by human and object nodes will be set to 1, and the other elements will be set to 0. The process of generating HOI graph is shown in Figure 2.
0 means that nodes i and j are not connected, and 1 means connected. In order to better represent our specific task, we only keep the edges connecting people and objects to obtain the graph structure called HOI graph. In other words, the elements in the adjacency matrix of the HOI graph indexed by human and object nodes will be set to 1, and the other elements will be set to 0. The process of generating HOI graph is shown in Figure 2.
The HOI graph structure contains the possible relationships of human and objects in the image, and our goal is to automatically infer the real HOIs by preserving the edges with the most interactive possibilities. To achieve that, the first thing we should do is to construct a strong feature representation for each node in the graph. In this paper, different methods are used to construct the features of human node and object node.
3.1 Feature representation of object node
Inspired by Refs. [21, 38, 39], a novel method for feature representation of object node, which introduces the attention mechanism into the construction of node features, is proposed. And the method could be divided into two parts: 1) The appearance feature extraction of the object; 2) Extracting local contextual information of human- object joint region by introducing IP and geometric relationship based attention mechanism.
3.1.1 Appearance feature extraction
For obtaining the appearance feature of object, we first extract the ROI pooled features of objects via Faster R-CNN [3], the object detector is also used for generating the candidate boxes of object instances, and identifying them. Then, the global average pooling (GAP) is applied to get a 512-dimensional vector. Finally, a single fully-connected layer is used to generate the appearance feature of the object. The object appearance feature can be seen in Figure 3.
3.1.2 Local context extraction
In order to extract the local context information of the human-object union region which can provide clues for HOIs recognition, we propose a novel attention-based human-object context modeling method for our task. Different from the attention model designed in Ref. [38], we model the interaction pattern (IP) and geometric relationship into the model, trying to guide the model to highlight the areas of human and object.
First of all, we need to obtain ROI pooled features, IP, and human-object geometric relationship in the human-object union region. ROI pooled feature of human-object joint region is obtained by applying ROI pooling operation for convolution feature map which surrounds human-object region exactly. The IP is obtained from the binary two-channel image generated by a given human-object pair bounding boxes. The geometric relationship between human and object is also generated by a given human-object pair of bounding boxes, which can be obtained by Eq. (1).

 (1)
(1)
where
 represents the boxes of object and human respectively; (x, y) are the coordinates of the center of the box; (w, h) are the width and height of the box.
represents the boxes of object and human respectively; (x, y) are the coordinates of the center of the box; (w, h) are the width and height of the box.
Then, after getting everything we need, we feed them into our attention model in the dotted box in Figure 3. Specially, we first extract the appearance feature from ROI pooled feature of human-object union region by applying global average pooling. Furthermore, in order to model the IP and geometric relationship into our attention model, we concatenate the 256-dimensional interactive feature obtained after three convolution and pooling layers, the 6-dimensional geometric relationship and the appearance feature obtained above. Next, the 774-dimensional feature is fed into a network composed of three full-connected (FC) layers and a ReLU [40] nonlinear layer, and the 512-dimensional feature vector is obtained. Afterward, we get attention map by applying channel-wise multiplication between the convolutional feature map of human-object union region and 512-dimensional weight vector obtained by sigmoid activation. Finally, we extract the local contextual information by the standard process, e.g., applying global average pooling followed by a fully-connected (FC) layer.
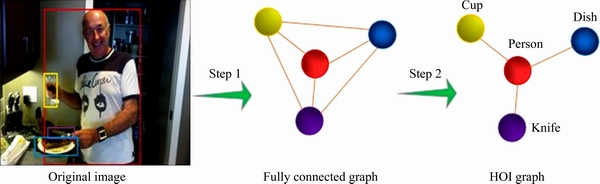
Figure 2 Process for generating HOI graph (The first step generates a fully connected undirected graph whose nodes represent all objects and humans detected in the original image, and its edges represent their relationships. The second step is to generate the HOI graph that preserves those edges connecting human and objects.)
Figure 3 Object node feature extraction network (The network consists of two parts: 1) The 128-dimensional appearance feature of object (shown in yellow) are obtained by some standardized operations; 2) The contextual feature of human-object interaction region is acquired from the proposed attention module. A detailed description of the entire network can be found in Section 3.1)
The 256-dimensional feature vector of object node could be further obtained by concatenating the appearance feature of object and the local contextual informative feature. These processes mentioned above can be expressed as a formula:
 (2)
(2)
where Xo donates the ROI pooled feature of object; Xh,o donates the ROI pooled feature of human-object pair; R represents geometric relationship calculated from boundary boxes information of human and object; Ip represents the relative spatial relationship proposed in Ref. [19]; fh,o donates the union feature map representing human-object pairs; F(・) is a single fully-connected (FC) layer; Att(・) represents the proposed attention model based on geometric relationship and IP, which is used to generate the attention feature map of human-object union region; F′(・) is also a single FC layer;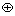 donates concatenating the features; X′ is the output feature. And the detail process is shown in Figure 3.
donates concatenating the features; X′ is the output feature. And the detail process is shown in Figure 3.
3.2 Feature representation of human node
For human nodes of HOI graph, a simple method for constructing the feature representation is proposed, inspired by Ref. [41]. It generates the node feature representation with context, utilizing the ROI pooled feature of detected human and the convolutional feature map of input image. And the architecture could be found in Figure 4.
Firstly, the feature is transformed into 512-dimensional feature by using ROI pooled feature of human region through global average pooling operation, and then the dimension of feature is reduced to 128-dimensional by a fully- connected (FC) layer. Next, the similarity between human appearance feature and convolutional feature is measured by , which means vector dot product, and a human-based attention map is dynamically generated applying the softmax operation. Then, we could obtain the feature vector with contextual information by computing the weighted average of the convolutional features. Finally, the feature of human node is a concatenation of human appearance feature and contextual feature. In this way, both human appearance feature and context information could be modeled into feature representation of human node.
, which means vector dot product, and a human-based attention map is dynamically generated applying the softmax operation. Then, we could obtain the feature vector with contextual information by computing the weighted average of the convolutional features. Finally, the feature of human node is a concatenation of human appearance feature and contextual feature. In this way, both human appearance feature and context information could be modeled into feature representation of human node.
Figure 4 Human node feature extraction network (The detailed description of the entire network can be found in Section 3.2)
4 Human-object interactions detection based on graph attention network
To selectively utilize the embedded features of all nodes in the HOI graph and learn the global structure information of the scene, a two-layer GAT is used for HOIs detection.
4.1 Graph attention layer
In this section, the basic attention head of a single GAT layer would be described which is used in our experiment.
The input of GAT layer is a set of node features,
 where N represents the number of nodes, and F is the dimension of feature in each node. The output of GAT layer is also a series of node features,
where N represents the number of nodes, and F is the dimension of feature in each node. The output of GAT layer is also a series of node features, 

Firstly, in order to get more powerful representation, a shared linear transformation, parametrized by a weight matrix, 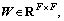 is applied to each node.
is applied to each node.
Secondly, the self-attention on the nodes, a shared attention mechanism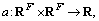 is conducted for computing the coefficients between neighbors. Specifically, the main idea of the shared attention mechanism is to use the self-attention mechanism with the same parameters on each node in the graph,which can make operations more efficient. Self-attention mechanism is the core of graph attention layer, whose idea is to compute the hidden representations of each node in the graph, by attending over its neighbours. The specific implementation process is divided into two steps: the first step is to calculate the initial attention coefficient between the node and its neighbors (such as Eq. (3)), and the second step is to normalize these attention coefficients (such as Eq. (4)).
is conducted for computing the coefficients between neighbors. Specifically, the main idea of the shared attention mechanism is to use the self-attention mechanism with the same parameters on each node in the graph,which can make operations more efficient. Self-attention mechanism is the core of graph attention layer, whose idea is to compute the hidden representations of each node in the graph, by attending over its neighbours. The specific implementation process is divided into two steps: the first step is to calculate the initial attention coefficient between the node and its neighbors (such as Eq. (3)), and the second step is to normalize these attention coefficients (such as Eq. (4)).
The first step is described by formula as follows:
 (3)
(3)
where eij is the initial attention coefficient which indicates the importance of node j’s features to node i.
The second step is to use the softmax function to standardize the attention coefficient calculated so as to clearly observe the attention of different neighbors for node j. The formula is described as follows:
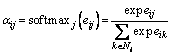 (4)
(4)
where Ni are some neighbors of node i (including i) in the graph.
Finally, the node features are linearly weighted using learned attention coefficients followed by a non-linearity as:
 (5)
(5)
where σ is the non-linearity activation function.
In our experiments, we explained the following main settings. 1) the attention mechanism a, implemented as Ref. [29], is a single-layer feedforward neural network, parametrized by a weight vector and applying the ReLU non-linearity. After fully expanded, the coefficient calculated by the attention mechanism can be expressed as:
and applying the ReLU non-linearity. After fully expanded, the coefficient calculated by the attention mechanism can be expressed as:
 (6)
(6)
where U(・) donates the ReLU function; ・T represents transposition; || is the concatenation operation. We use sigmoid function as the non- linear activation function in the output layer, because for each node, HOIs recognition is a multi-label classification task.
4.2 Loss function and optimization strategy
In this paper, a two-layer GAT model was used to extract high-level relationship structures of HOIs. In the final output layer, the sigmoid function was utilized for all updated nodes to obtain the n-dimensional probability vectors, where n is the number of interactive action classes. Considering that some nodes may have multiple labels at the same time, such as the human node will be labeled both “sit on” and “eating” if a person sitting on a sofa to eat an apple, the multi-label soft margin loss function expressed as Eq. (7) was used. And we used Adam algorithm [42] to minimize the loss.
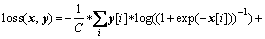
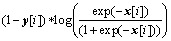 (7)
(7)
where C donates the number of classes;  is the input vector;
is the input vector; 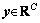 is the target vector.
is the target vector.
Overall, given an input image, we generate HOI graph by detecting all the humans and objects in it, and then extract the embedding features of each node in the graph by using the node feature extraction networks in Section 2, and further classify the nodes through GAT. In this way, we can get all the nodes with interactive action labels. Furthermore, we preserve the edges with high coefficients in the HOI graph, which indicate that the interactions occur in the human-object pairs connected by them. The final human-object interaction score is determined by multiplying the action probabilities of the human node and interactive object node.
5 Experimental results
To evaluate the performance of our model, the experiments are performed on “human and common object interaction detection” (HICO-DET) dataset [21] and “verb in COCO” (V-COCO) dataset [25]. The structure of this section is as follows, we first describe the benchmark datasets (i.e., V-COCO and HICO-DET), evaluation metric, and implementation details. Then, we compare our proposed framework for HOIs detection to the existing approaches, and show that it outperforms the others. Finally, ablation studies are conducted to examine the effect of each proposed component.
5.1 Introduction of datasets
The HICO-DET dataset is a large benchmark for HOIs recognition, which contains spatial annotations of people and objects for each HOI. There are 47774 images in HICO-DET, which are annotated with 600 HOI categories (e.g., “biking”, “walking bicycle”, “riding”), 117 action categories (e.g., “biking”, “walking”) and 80 objects (such as “bicycle”, “horse”), the same as COCO classes. Each image may contain multiple HOI annotations for a total of 150 K annotations. And there are 38116 images (80%) in the entire dataset for train and 9558 images (20%) for test.
The V-COCO dataset is a subset of MSCOCO [43], in which 5400 images are used for training and verification and 4946 images for testing. It annotates 26 commonly used action classes, as well as boundary boxes for human and interactive objects. In V-COCO, people can not only perform multiple actions on the same object (for example, skiing while holding a ski), but also perform the same actions on different types of objects. Specially, three actions (cutting, hitting and eating) can be annotated with two categories of objects (i.e., instruments and direct objects). For example, a person can hit both a racket (musical instrument) and a sports ball (direct object). The datasets we use are shown in Figure 5.
5.2 Evaluation metric
We primarily use mean average precision (mAP) to evaluate HOIs detection according to the standard evaluation metric for object detection. AP based on both recall and precision is considered to be very reliable for detection tasks. In our work, detecting the interactions between human and objects is our ultimate goal, so the actions without any interacting objects (such as running, and smiling) are beyond our scope of exploration. Formally, we believe that HOI detection can only be considered true positive if it satisfies the following three conditions: 1) the IoU between the predicted human bounding box and the ground- truth human bounding box is greater than or equal to 0.5; 2) the predicted object box has IoU greater than or equal to 0.5 with the ground-truth object in interaction; 3) the predicted and ground-truth actions match. The above definition of true positive in HOI tasks is applied to both HICO-DET and V-COCO datasets in our work.
In addition, we also use accuracy as another metric to evaluate our method on the above two datasets.
5.3 Implement details
In our experiment, for detecting the objects and extracting features, we use the object detector called Faster R-CNN[3] with a VGG16[44] feature backbone, pre-trained on MS-COCO dataset which has the same object categories as HICO-DET and V-COCO datasets. Firstly, we extract the object node feature (256×1) from the object node feature extraction network shown in Figure 3. Specifically, the fifth convolutional feature map (14×14×512) obtained from VGG16, the candidate boxes obtained from region proposal network (RPN) and generated IP are fed into our object node feature extraction network. And for human node, the feature (256×1) is acquired through the network structure shown in Figure 4. Then, after obtaining the feature vectors of all the nodes in the HOI graph, they will be sent to the following GAT which consists of two graph attention layers. In the experiment, we fine-tuned the GAT according to our task. There are two main adjustments: 1) the number of hidden neurons we use is 1024. However, it is found that such a large parameter setting not only reduces the speed of the training process, but also leads to over-fitting problems, so we add the Batch normalization (BN) layer after the linear transformation operation of the graph attention network to reduce the impact of over-fitting. In addition, we also try setting it to 256, 512, 2048, etc. But the performances are very poor. 2) Since our goal is to classify nodes with multiple labels, we use sigmoid function to replace the original softmax function for the output of the last graph attention layer. The confidence of the HOI label of the human-object pair is given by the product of the final output probabilities of the human node and the interactive object node. Furthermore, it is actually a multi-label problem for each node (e.g., a person can be standing and looking at skateboard at the same time). Considering this factor, we use multi-label soft margin loss.

Figure 5 Samples of datasets (The first row is samples from HICO-DET dataset, second row is samples from V-COCO dataset)
The proposed model is implemented using PyTorch and deployed on a machine with a single Nvidia Titan XP GPU. The initial learning rate we set is 1×10-3, and the learning rate decreases by 0.7 per 6 epochs. With batch size of 10, the whole training process lasts 20 h and gradually converges.
5.4 Comparing with state-of-the-art approaches
In this work, to evaluate proposed method, we compare it with the previous state-of-the-arts on HICO-DET and V-COCO datasets. In particular, we compare our method with the following approaches in HICO-DET:
1) HO-RCNN [21]. The HICO-DET dataset is established, and a multi-branch architecture with convolutional network is proposed to classify human, object and human-object proposals respectively. Ultimately, the final output is calculated by combining the scores of all three branches.
2) SHEN et al [26]. Different from other methods, zero-shot problem is the focus of their research. The final predictive score for human-object interaction comes from two branch networks based on Faster R-CNN, which are trained to predict verbs and object categories respectively.
3) InteractNet [32]. It extends a human-centric branch based on Faster R-CNN, which is used to estimate the action-specific density map for locating objects. And the branch can generate interaction scores based on the appearance of people, manipulated objects and the distribution of the location of the target objects.
4) GPNN [27]. Similar to the method we proposed, graph parsing neural network (GPNN) infers human-object interactions in graph by message passing, whereas both GPNN [27] and InteractNet [32] are compared in V-COCO dataset.
For HICO-DET dataset, we follow the setting of Ref. [19], and divide the test set into three subsets: full, rare and non-rare. We use mAP and accuracy to evaluate the model on the HICO-DET and V-COCO datasets. The experimental results about mAP are shown in Tables 1 and 2. Comparison of accuracy is shown in Table 3.
Table 1 Comparisons of state-of-the-art approaches on HICO-DET test set
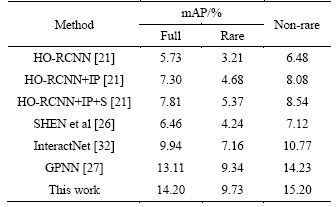
Table 2 Comparisons of state-of-the-art approaches on V-COCO test set

Table 3 Comparisons of state-of-the-art approaches on HICO-DET test set and V-COCO test set
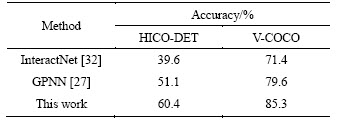
Overall, Tables 1-3 show that our proposed method is superior to other methods in both accuracy and mAP on the HICO-DET and V-COCO datasets.
Specifically, it can be observed from Tables 1 and 2 that our method improves the mAP by 1.09 on HICO-DET and 1.4 on V-COCO compared to the GPNN which has the best performance in the comparison methods, respectively. Table 3 compares the recognition rate of the proposed method with the results reported in the literatures. To be specific, in the experiment, we use the ground truth bounding boxes of human and objects in the test set to analyze the recognition accuracy of the method to avoid the influence of the error generated by the object detector on the performance of the method. As can be seen from Table 3, compared with the best performing method GPNN, our approach has obtained absolute gains of 9.3 on HICO and 5.7 on V-COCO, respectively. According to the results in the above three tables, we can find that whether mAP or accuracy is used to evaluate our model, the results on HICO-DET are lower than V-COCO. The reason is that there are more fine-grained HOI categories in HICO-DET datasets than V-COCO datasets, and there is also a long tail problem in HICO-DET.
The human-object interaction detection visual results are shown in Figures 6 and 7.
5.5 Ablation study
In this section, we validate the effectiveness of our approach by analyzing the contribution of the three model components to the final performance of the model. Table 4 reports the experimental results in the two datasets.
1) The first component we consider is the GAT. The ROI pooled features of human, object and human-object pairs are scored by three fully connected networks. Finally, the HOI action categories are predicted by scoring fusion. This is similar to the previous methods. As can be seen from Table 4, the model without GAT is obviously worse than our complete model. This also provides strong support for our view that modeling advanced relational structure information for deep features is critical for HOI tasks.

Figure 6 Some HOI visual detection results on some test images of HICO-DET dataset (The yellow and blue rectangles represent humans and objects, respectively)

Figure 7 Some HOI visual detection results on some test images of V-COCO dataset (The yellow and blue rectangles represent humans and objects, respectively)
Table 4 Ablation study of our proposed approach (The first four columns of the table report the experimental results on the HICO-DET dataset, while the results on the V-COCO dataset are shown in the last two columns)
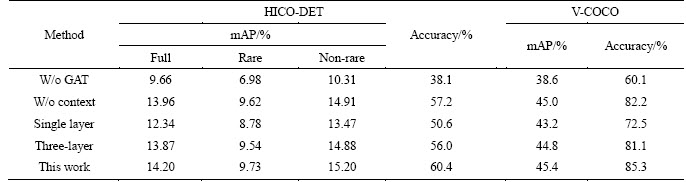
2) Next, we consider the context contained in all node features. It means that we cancel the context modeling in object and human node feature extraction networks. In this way, the features of the nodes sent into the GAT only contain the appearance features of human and objects. This is a big challenge for our model. However, from Table 4, we can see that although the performance of the model is lower than that of the complete model, it is still greatly improved compared with the previous methods. This shows that providing richer context information can help our model to extract more robust high-level relationships.
3) At last, we consider the effect of GAT layers on the model. We experiment with single-layer GAT model and three-layer GAT model respectively. From the results of Table 4, we can see that when the number of layers increases, the effect of the model improves, but when the number of layers increases to a certain extent, the effect decreases.
6 Conclusions
In practical applications such as event detection in surveillance, accurate detection and inference of HOIs are increasingly needed. Since the previous optimal methods only consider the local context in image, a method based on the graph is proposed to eliminate this defect. Our core idea is to use the HOI graph to model the human-object relations in the image, and to construct the human and object node features respectively by using the proposed node feature extraction networks which fuse contextual information. Then, we use GAT to detect and recognize the real HOIs in the HOI graph. Compared with previous state-of-the-art methods on two benchmark datasets, the effectiveness of the proposed method is also proved. For future work, we will try to extend our approach to HOI detection in videos.
Contributors
XIA Li-min provided the concept and edited the draft of manuscript. WU Wei conducted the literature review and wrote the first draft of the manuscript.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
[1] LIN T Y, DOLLAR P, GIRSHICK R, HE K M, HARIHARAN B, BELONGIE S. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125. DOI:10.1109/cvpr.2017.106.
[2] HE K, ZHANG X, REN S, SUN J. Deep residual learning for image recognition [C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2016: 770-778. DOI: 10.1109/cvpr.2016.90.
[3] REN S, HE K, GIRSHICK R, SUN J. Faster R-CNN: Towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI: 10.1109/TPAMI. 2016.2577031
[4] WANG J, XIA L, HU X, XIAO Y. Abnormal event detection with semi-supervised sparse topic model [J]. Neural Computing and Applications, 2019, 31(5): 1607-1617. DOI: 10.1007/s00521-018-3417-1.
[5] WANG P, CHEN P, YUAN Y, HUANG Z, HOU X, COTTRELL G. Understanding Convolution for Semantic Segmentation [C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 1451-1460. DOI: 10.1109/WACV.2018.00163.
[6] GAO R, XIONG B, GRAUMAN K. Im2flow: Motion hallucination from static images for action recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 5937-5947. DOI: 10.1109/ cvpr.2018.00622.
[7] CHERON G, LAPTEV I, SCHMID C. P-CNN: Pose-based CNN features for action recognition [C]// Proceedings of the IEEE International Conference on Computer Vision. 2015: 3218-3226. DOI: 10.1109/iccv.2015.368.
[8] LIU J, WANG G, DUAN L Y, ABDIYEVA K, KOT A C. Skeleton-based human action recognition with global context-aware attention LSTM networks [J]. IEEE Transactions on Image Processing, 2017, 27(4): 1586-1599. DOI: 10.1109/tip.2017.2785279.
[9] MAJD M, SAFABAKHSH R. A motion-aware ConvLSTM network for action recognition [J]. Applied Intelligence, 2019, 49(7): 2515-2521. DOI: 10.1007/s10489-018-1395-8.
[10] XIA L M, GUO W T, WANG H. Interaction behavior recognition from multiple views [J]. Journal of Central South University, 2020, 27(1): 101-113. DOI: 10.1007/s11771- 020-4281-6.
[11] LI Y, OUYANG W, ZHOU B, WANG K, WANG X. Scene graph generation from objects, phrases and region captions [C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 1261-1270. DOI: 10.1109/iccv.2017. 142.
[12] XU D, ZHU Y, CHOY C B, LI F F. Scene graph generation by iterative message passing [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 5410-5419. DOI: 10.1109/cvpr.2017.330.
[13] LU C, KRISHNA R, BERNSTEIN M, LI F F. Visual relationship detection with language priors [C]// European Conference on Computer Vision. Springer, Cham, 2016: 852-869. DOI: 10.1007/978-3-319-46448-0_51.
[14] DAI Y, WANG C, DONG J, SUN C Y. Visual relationship detection based on bidirectional recurrent neural network [J]. Multimedia Tools and Applications, 2019: 1-17. DOI: 10.1007/s11042-019-7732-z.
[15] TENEY D, LIU L, van den HENGEL A. Graph-structured representations for visual question answering [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1-9. DOI: 10.1109/cvpr. 2017.344.
[16] PENG L, YANG Y, BIN Y, XIE N, SHEN F M, JI Y L, XU X. Word-to-region attention network for visual question answering [J]. Multimedia Tools and Applications, 2019, 78(3): 3843-3858. DOI: 10.1007/ s11042-018-6389-3.
[17] CHEN X, ZITNICK C L. Mind’s eye: A recurrent visual representation for image caption generation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 2422-2431. DOI: 10.1109/ cvpr.2015.7298856.
[18] JOHNSON J, HARIHARAN B, van der MAATEN L, HOFFMAN J, LI F F, ZITNICK C L, GIRSHICK R. Inferring and executing programs for visual reasoning [C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 2989-2998. DOI: 10.1109/iccv. 2017.325.
[19] GUPTA A, KEMBHAVI A, DAVIS L S. Observing human-object interactions: Using spatial and functional compatibility for recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(10): 1775-1789. DOI: 10.1109/tpami.2009.83.
[20] YAO B, LI F F. Modeling mutual context of object and human pose in human-object interaction activities [C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2010: 17-24. DOI: 10.1109/cvpr.2010.5540235.
[21] CHAO Y W, LIU Y, LIU X, ZENG H. Learning to detect human-object interactions [C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 381-389. DOI: 10.1109/wacv.2018.00048.
[22] FANG H S, CAO J, TAI Y W, LU C. Pairwise body-part attention for recognizing human-object interactions [J]. Lecture Notes in Computer Science, 2018: 52-68. DOI: 10.1007/978-3-030-01249-6_4.
[23] XIA L, LI R. Multi-stream neural network fused with local information and global information for HOI detection [J]. Applied Intelligence, 2020, 50(12): 4495-4505. DOI: 10.1007/s10489- 020-01794-1.
[24] HU J F, ZHENG W S, LAI J, GONG S G. Recognising human-object interaction via exemplar based modelling [C]// Proceedings of the IEEE International Conference on Computer Vision. 2013: 3144-3151. DOI: 10.1109/iccv. 2013.390.
[25] GUPTA S, MALIK J. Visual semantic role labeling [J]. Computer Science: Computer Vision and Pattern Recognition, 2015: arXiv:1505.04474,.
[26] SHEN L, YEUNG S, HOFFMAN J, MORIG, LI F F. Scaling human-object interaction recognition through zero-shot learning [C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 1568-1576. DOI: 10.1109/wacv.2018.00181.
[27] QI S, WANG W, JIA B, SHEN J, ZHU S C. Learning human-object interactions by graph parsing neural networks [C]// Proceedings of the European Conference on Computer Vision (ECCV). 2018: 401-417. DOI: 10.1007/978-3-030- 01240-3_25.
[28] OLIVA A, TORRALBA A. The role of context in object recognition [J]. Trends in Cognitive Sciences, 2007, 11(12): 520-527. DOI: 10.1016/j.tics.2007.09.009.
[29] VELICKOVIC P, CUCURULL G, CASANOVA A, ROMERO A, LIO P, BENGIO Y. Graph attention networks [C]// International Conference on Learning Representations, 2018. DOI: 10.17863/CAM.48429.
[30] PREST A, SCHMID C, FERRARI V. Weakly supervised learning of interactions between humans and objects [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 34(3): 601-614. DOI: 10.1109/tpami. 2011.158.
[31] DESAI C, RAMANAN D, FOWLKES C. Discriminative models for static human-object interactions [C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. IEEE, 2010: 9-16. DOI: 10.1109/cvprw.2010.5543176.
[32] GKIOXARI G, GIRSHICK R, DOLLAR P, HE K. Detecting and recognizing human-object interactions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8359-8367. DOI: 10.1109/cvpr.2018. 00872.
[33] GORI M, MONFARDINI G, SCARSELLI F. A new model for learning in graph domains [C]// Proceedings of 2005 IEEE International Joint Conference on Neural Networks. IEEE, 2005, 2: 729-734. DOI: 10.1109/ijcnn.2005.1555942.
[34] KIPF T, WELLING M. Semi-supervised classification with graph convolutional networks [C]// International Conference on Learning Representations. 2017.
[35] JAIN A, ZAMIR A R, SAVARESE S, SAXENA A. Structural-RNN: Deep learning on spatio-temporal graphs [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 5308-5317. DOI: 10.1109/cvpr.2016. 573.
[36] CHEN X, LI L J, LI F F, GUPTA A. Iterative visual reasoning beyond convolutions [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7239-7248. DOI: 10.1109/cvpr.2018. 00756.
[37] MARINO K, SALAKHUTDINOV R, GUPTA A. The More You Know: Using Knowledge Graphs for Image Classification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 20-28. DOI: 10.1109/cvpr.2017.10.
[38] HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141. DOI: 10.1109/ cvpr.2018.00745.
[39] PEYRE J, SIVIC J, LAPTEV I, SIVIC J. Weakly-supervised learning of visual relations [C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 5179-5188. DOI: 10.1109/iccv.2017.554.
[40] NAIR V, HINTON G E. Rectified linear units improve restricted boltzmann machines [C]// International Conference on Machine Learning. 2010: 807-814.
[41] GIRDHAR R, RAMANAN D. Attentional pooling for action recognition [C]// Advances in Neural Information Processing Systems. 2017: 34-45.
[42] KINGMA D P, BA J. Adam: A method for stochastic optimization [J]. arXiv preprint, 2014: arXiv:1412.6980,.
[43] LIN T Y, MAIRE M, BELONGIE S, HAYS J, PERONA P, RAMANAN D, DOLLAR P, ZITNICK C L. Microsoft coco: Common objects in context [C]// European Conference on Computer Vision. Cham: Springer, 2014: 740-755. DOI: 10.1007/978-3-319-10602-1_48.
[44] KAREN S Y, ANDREW Z M. Very deep convolutional networks for large-scale image recognition [J]. arXiv preprint, 2014: arXiv:1409.1556,.
(Edited by FANG Jing-hua)
中文导读
基于图的人-物交互行为检测方法
摘要:人-物交互行为检测作为视觉关系检测的一个新分支,在图像理解领域起着重要的作用。由于图像内容复杂多样,人-物交互行为的检测仍是一大挑战。与当前仅依靠人与物体间的成对信息的方法不同,本文提出了一种可以对上下文和全局结构信息进行建模的基于图的人-物交互行为检测方法。首先,为了更好地利用人与物体之间的关系,将图像中检测到的人和对象视为节点,构造人-物交互图。其次,为了获得更鲁棒的人与物体节点的特征表示,通过两个的特征提取网络,分别对全局和局部上下文进行建模。最后,引入图注意力网络,在人-物交互图中的不同节点间迭代传递信息,检测潜在的人-物交互行为。在V-COCO和HICO-DET数据集上的实验验证了该方法的有效性,并表明该方法优于现有的许多方法。
关键词:人-物交互;视觉关系;上下文信息;图注意力网络
Foundation item: Project(51678075) supported by the National Natural Science Foundation of China; Project(2017GK2271) supported by the Hunan Provincial Science and Technology Department, China
Received date: 2019-12-25; Accepted date: 2020-06-14
Corresponding author: XIA Li-min, PhD, Professor; Tel: +86-13974961656; E-mail: xlm@csu.edu.cn; ORCID: https://orcid.org/ 0000-0002-2249-449X

