����ͼ��ʶ������������֤��ʶ��
������1, 2���˷�1, 2
(1. ����������ѧ �Զ���ѧԺ��������100081��
2. ����������ѧ �������Զ�����ϵͳ�ص�ʵ���ң�������100081)
ժҪ�����һ�ֻ���ͼ��ʶ������������֤��ʶ�����ܿ��١���Ч��ʶ��������֡�Ӣ����ĸ�ȶ����ַ�����֤��ͼ�����ȣ�����֤��ͼ����лҶȻ�����ֵ����ȥ���Ԥ�����������˳�������Ϣ��ͻ���ַ��������õ������������Ķ�ֵͼ����Σ�����һ�־����Ľ��ġ��ں�ͶӰ���Ե���ͨ��ָ��õ����ַ�ͼ�������ٴΣ��Ա��ַ�ͼ�����������ȡ��������ѵ�������磻�����������ѵ��Ч��ʵ���ַ�ʶ����Matlab�����´�����ͬ��վ�Ĵ�����֤��ͼ��ʵ������������������ķ��������ַ����в������������϶����֤����кܸߵ�ʶ���ʺ���Ч�ԡ�
�ؼ��ʣ���֤�룻ͼ��ʶ�������磻Ԥ�������ַ����ָʶ��
��ͼ����ţ�TG146.2+1 ���ױ�־�룺A ���±�ţ�1672-7207(2011)S1-0048-05
CAPTCHA recognition based on image recognition and neural networks
LIAN Xiao-yan1, 2, DENG Fang1, 2
(1. School of Automation, Beijing Institute of Technology, Beijing 100081, China;
2. Beijing Key Laboratory of Automatic Control System, Beijing Institute of Technology,
Beijing Institute of Technology, Beijing 100081, China)
Abstract: Based on image recognition and neural networks (NNs), a rapid and effective CAPTCHA recognition method was proposed which has different characters of numbers and English letters. Firstly, pre-operating was put in practice, including graying, binaryzation and removing noise to get the binary image with higher quality. Secondly, images with single character were acquired through an improved segmentation algorithm combining connected domain and projection together, and then normalized. Thirdly, features of character image samples were extracted; the NNs were built and trained. Finally, the trained NNs were tested to realize character recognition. Based on the software environment of Matlab, the recognition processing and result of many CAPTCHA images from different websites were proposed. The experiments show that the method is effective and feasible for the CAPTCHAs which contain irregular placed characters and much noise.
Key words: CAPTCHA; image recognition; neural networks; pre-operating; character; segmentation; recognition
��������������Ϣ��ȫ�����Ż�������Ѹ�ٷ�չ��Ϊ���ܹ�ע�����⡣��Ϊ������ʮ����Ҫ����Ϣý�飬���չ��������̳�����������͡���������Ȼ���������������棬���Ƕ�����������֤�����ɺ�ʶ�������о�Ҳ��֮�ս����¡�Ϊ�˷�ֹ�����ƽ����롢ˢƱ����̳��ˮ�ȣ�Խ��Խ�����վ��ʼʹ����֤�롣��ν��֤�룬���ǽ�һ��������������ֻ���ţ�����һ��ͼ��ͼ�������һЩ�������أ����û�����ʶ�����е���֤����Ϣ����������ύ��վ��֤����֤�ɹ������ʹ����ij��ܡ������Ч��ʵ�ֶ���վ����̳����֤���ʶ����ģʽʶ���ڸ��ӻ�����Ӧ���е���Ҫ���⡣��Ŀǰ��������о����������֤��ʶ����Ҫ��Ϊ3�ࣺ����ģ��ƥ��ķ����������ַ��ṹ�ķ����ͻ���������ķ���������[1-3]�������ʶ���㷨����֤��ͼ��Ҫ��ϸߣ����ʽ�̶���������������ʽ����ȣ���ʶ����ַ�����Ҳ��Ϊ��һ��Ӧ��ʱ����һ���ľ����ԡ�Ϊ�ˣ������������һ������Ч��ʶ��������ֺ�Ӣ����ĸ���ַ����в������϶���������֤��ͼ��ķ�����
1 ʶ������
������Ƶ���֤��ʶ��������ͼ1��ʾ�����ȣ�����վ�ϻ����֤��ԭͼ���ɲ��ý�ͼ�����ͼ��URL�����ر���ķ������У���õ���֤��ԭͼһ�㶼�Dz�ɫͼ����Ҫ�ȶԲ�ɫͼ����лҶȻ��������õ�256ɫ�Ҷ�ͼ���Ž��Ҷ�ͼ���ֵ����ȥ�����ű����������ַ���Ϣ���õ�ֻ�����ڡ�����ɫ��(0,1)��ֵͼ��ֵͼ�������ںܶ��������������ȥ�봦����Ȼ������Ԥ������ͼ���ϵĵ����ַ��ָ����������ѵ�����Ͳ��Լ���ѵ�����е��ַ�ͼ���������˹����������ѵ����������ѵ������������趨ֵ���ò��Լ����ַ�ͼ����в��ԣ������Խ����������ʶ����Ҫ������������������ѵ���͵��ڡ������ѵ���õ������������֤��ͼ����ַ�ʶ�𣬲����ʶ������

ͼ1 ��֤��ʶ������ͼ
Fig.1 Flow chart of CAPTCHA recognition
2 ʵ�ַ���
2.1 Ԥ����
��֤��ͼ���Ԥ������ָ�ڶ���֤��ͼ����зָ������ȡ��ʶ��ǰ�����еĴ�����Ԥ��������ҪĿ���Ƕ�һ�������ĺ����ַ���ͼ��ͻ��ͼ�������ַ��йص�ijЩ��Ϣ��������ȥ��ijЩ����Ҫ����Ϣ��ʹ�����Ժ����ʶ���ԭʼ���ַ�ͼ���ʶ����ʺϡ�Ԥ������Ҫ�����ҶȻ�����ֵ����ȥ��3�����衣
�ҶȻ��ǽ���ɫͼ��任�ɻҶ�ͼ��Ĵ������̡����IJ��ü�Ȩƽ��ֵ������R��G��B�ֱ��ʾ��ɫͼ���к�ɫ����ɫ����ɫ�ķ���ֵ��Gray��ʾ�Ҷ�ͼ������ֵ�����У�
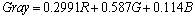 (1)
(1)
��ֵ���Ĺؼ�������ֵ��ѡȡ����Bw��ʾ��ֵͼ�������ֵ��ͨ���趨�ʵ�����ֵT���Ҷ�ͼ������(0,1)��ֵͼ��Ĺ���Ϊ��
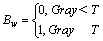 (2)
(2)
�����ַ��ͱ������ϴҶȼ��ֲ����ɽ�Ϊͳһ����֤�룬��ֵ��ʱ����Ostu�㷨ȷ����ֵ��Ostu�㷨��һ��ȫ����ֵ���������˼���ǣ����ݻҶȼ�ֱ��ͼ���Ҷ�ͼ����ijһ��ֵ���ָ��2�ࣺһ���Ӧ�ڱ����������֣���һ���Ӧ��ǰ���ַ����֡������ֳɵ���������ڷ�����С����䷽�����ʱ��ȷ������ֵΪȫ����ֵ�������ǻҶȷֲ������Ե�һ�ֶ�������ֵԽ��˵����ͼ��ֳɵ������ֲ��Խ������䷽�����ԭ��ȡ����ֵ�ķָ���ζ�Ŵ��ָ�����С�����㷨������ͼ��ͼ2��ʾ������(i, j)��ʾ�������ص㣬T��ʾȫ����ֵ��G��ʾ����һ�������õ�����䷽�max(G)��ʾ��䷽��Gȡ�õ����ֵ��
��ֵͼ���д��ڽ϶����������ʱ������ַ��ָ��ʶ�����ѡ�Ϊ��������Ϣ�IJ���Ӱ�죬�б�Ҫ����ȥ�봦���˳�������Ⱦ����������������ͨ����ֵ�˲����ȡ������㷨��ʱ�俪��С����ֻ��ȥ�������������㣬Ӧ�÷�Χ���ޡ���ͨ����Ҫ���ͼ�����������ͨ�����������ַ�������������ٽ�ֵѡȡ����ʱ��ȥ�����ͼ��ʧ�档��ֵ�˲������ǽ���ά�˲���������������ֵ����ֵ��Ϊ�µ�����ֵ������ǰ�������еĵ㣬����ͼ���е�������������������������ܺõ��˳����á����ݲ�ͬ��������ʽ���ص㣬ѡ��ǡ����ȥ�뷽������Ҫʱ������ȥ�뷽�����ʹ�ã��Ծ����ܺõ��˳����������������ַ���Ϣ��
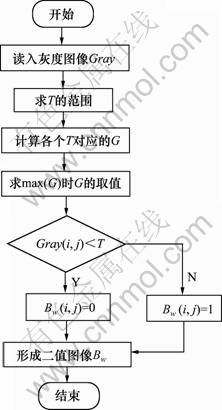
ͼ2 Ostu�㷨��ֵ������ͼ
Fig.2 Flow chart of Ostu arithmetic of binaryzation
2.2 �ַ��ָ�
�ַ��ָ�Ч��ֱ��Ӱ�����ַ�ʶ���ȷ�ԣ���ȡ���ĵ����ַ���Я������ϢҪ�����������࣬�����ʹ�������ַ�ʶ�������Ӧ�еĴ�������
���������һ�ָĽ�����ͨ��ָ���ܹ���Ч�ش��������ַ�ճ������֤�롣����Ԥ�����Ķ�ֵͼ���У�����ֵΪ1�ĵ�ֱɶ����ͨ�ĵ�Ⱥ������ͨ������1����ͨ���п��ܰ���1�������ַ�����ˣ��������ͨ�ָ�õ���ͼ����н�һ��������ͨ���������������ͶӰ���ԣ��ڶ��ηָ�ʱ�ܺõ�ʵ���˵����ַ�����ȡ���������¡�
��1�����ָ���ͨ��ͼ�������ͨ���ǣ������˳�����δ�����Ǿ�����ǰ��ͨ�磬�Դ�Ϊ�߿�ָ����Ǿ�����Ӿ�������ֵΪ��ŵĵ㻹ԭΪ1�����Ӿ������³�Ϊ(0,1)��ֵ����ӦΪһ����ͨ��Ķ�ֵͼ�Ա�Ǿ����ÿ�����������ͬ���Ĵ�����ʵ�ֳ����ָ
��2�����ж��ַ���������һ���������ָ�ͼ����ͼ�������ͳ��ͼ�����ַ����ص��ܺͣ��жϸ��������Ƿ��������ַ������ǣ�ת��һ����������ǰͼ��Ϊ�����ַ�ͼ�ָ���ɡ�
��3�������ηָ��������ַ���ͼ����д�ֱͶӰ�������Ӧ���ַ����������Ӧ���ַ�֮��Ŀ�϶�����ݲ�������λ��ȷ��ͼ���ˮƽ�ָ�㣬�õ�������ͼ���ٶ�ÿһ����ͼ����ˮƽͶӰ��ȷ���ַ�����ͼ�д�ֱ�����ϵ�λ�ã���ͶӰ�����±߽紦�и���ͼ��������ɸ����ַ��ķָ
�ַ��ָ���еõ��ĵ�����ͼ���С��ͬ��Ϊ���ڴ���������˫���Բ�ֵ�����б����������õ���Сͳһ���ַ�ͼ��
2.3 �������ַ�ʶ��
���������ɴ����˹���Ԫ(������Ԫ)�㷺�������ɵ����磬�������ִ�������ѧ����ʶ��ѧ��������Ϣ�����о��Ļ�����������ģ����к�ǿ������Ӧ�Ժ�ѧϰ������������ӳ��������³���Ժ��ݴ��������㷺Ӧ����ģʽʶ�𡢼��������ࡢ�����Ϳ���ϵͳ���о�����[4]���������ַ�ʶ����һ�ֽ��Ƚ���ʶ�����㷨���������������Ƶ������Ͻ���ͨ����ǿ��������֤���ַ�ʶ�����ȷ�ʺܸߡ�
2.3.1 ������ȡ
����������ѵ��ʱ�������������ϢӦ�����ܵؼ����걸���Ӷ��������ַ�������ͬʱ�������縴�ӶȺ�ѵ����ʱ���������ʱ���趨���ַ�ͼ��ߴ�Ϊ35��20������700�����ص㣬��Ϊ���������������Ȼά��������ˣ����ȶ��ַ�ͼ�����������ȡ[5-6]���ַ���������ͶӰ���ԡ������������ֿ����Ժͷֶ����Եȡ����ĸ���ͶӰ������ȡ�ַ����������岽������������
(1) �ַ���ֵͼ����raw��ʾ���������ص�Ϊ(i,j)�����У�i=1, 2, ��, 20��j=1, 2, ��, 35��
(2) ��ʽ(3)��ʽ(4)�ֱ������ַ�ͼ��Ĵ�ֱͶӰ��ˮƽͶӰ���õ�raw_X��raw_Y��ʽ(5)��(6)��ʾ��
(3) ����ʽ(7)����ַ�ͼ�����������raw_XY����Ϊ55��1����������
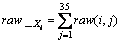 (3)
(3)
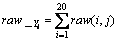 (4)
(4)
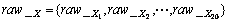 (5)
(5)
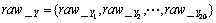 (6)
(6)
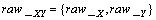 (7)
(7)
2.3.2 ����ѵ��
����ѵ��ǰ����Ҫȷ��������IJ�����ÿ����Ԫ�ĸ��������磬�ٶ�������֤��ͼ�����32���ַ�������8�����֡�24��СдӢ����ĸ�����ľݴ����������������Ľṹ�����������������磺1������㡢1���������1������㡣���ô�ʶ���ַ���ͶӰ���Խ���������ȡ�õ���55ά������������ˣ���������55����Ԫ����������Ԫ������ѡ��û��ͳһ�Ĺ�������ȡ16�������ַ����ж����Ʊ��룬32���ַ���Ҫ5λ����������ʾ����ˣ���������5����Ԫ��
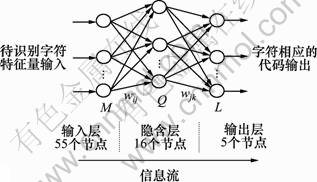
ͼ3 �ַ�ʶ��������ṹͼ
Fig.3 Structure of NNs for character recognition
������������ٶ�������֤��ͼ���Դ�ʶ���ַ�������Ϊ���롢���ַ���Ӧ�����ƴ���Ϊ���������������ṹ��ͼ3��ʾ���������������������ѡȡ�ʵ��������ַ�����ѵ�����硣������������������趨��Ŀ��ֵʱ����ѵ����������������������á�
2.3.3 �ַ�ʶ��
������ѵ����ɺ������ַ�ʶ�𡣶Դ�ʶ���ַ�����������ȡ�Ĺ�����д����������Ӧ�����������������磻���罫ʶ��õ��Ķ����ƴ���������ٸ���Ԥ���趨���ַ�-������ձ�ȷ���ַ����Ͳ����ʶ������
3 ʵ��
Ϊ��֤���������Ŀ����Ժ���Ч�ԣ������Ա���FTP����(1)������֮��PT����վ(2)���ٶ�����(3)��CSDN(4)���Ѻ�����(5)��5����վ����֤��Ϊ�о�������Matlab�����±��ʵ�����㷨��ȫ���̣�������֤��ͼ��ĻҶȻ�����ֵ����ȥ����ַ��ָ������Ĺ���������ѵ�������߲��ԣ��Լ�����ѵ���õ�������ʶ���ַ��ȡ�
�ٶ�������֤��Ϊ������ʵ���еĴ������̼���˵���������֤��ͼ���ص㣬��Ԥ����ʱʹ��Matlabͼ��������������Ӧ�ĺ�����ɻҶȻ���ȫ����ֵ����ֵ����ȥ��β�����ֵ�˲�������ʵ�鷢�ֲ�ͬ���ڵ��˲�Ч����ͬ��ѡȡЧ����ѵ�3��3���ڡ��ַ��ָ�ʱ���ñ��ĸĽ�����ͨ��ָ���������Ĵ���Ч����ͼ4��ʾ�������編�ַ�ʶ��Σ�������ͼ3��ʾ�����˼·����Matlab�����¹��������������磬��������������ð��������ַ�ͼ���������ѵ�������硣����23 107��ѵ�����������Ϊ0.001 999 95�������������趨��Ŀ�����0.002������ѵ���ɹ��������ڲ��Լ�����֤���ʶ��ƽ�������������ѵ�������ı仯������ͼ5��ʾ��

ͼ4 �ٶ�������֤���Ԥ�������ַ��ָ�
Fig.4 Pre-operating and character segmentation of Union Baidu CAPTCHA
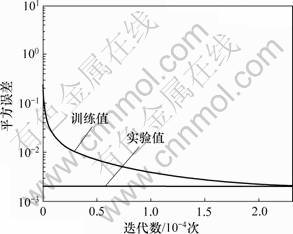
ͼ5 �ٶ�������֤��ʶ��������ѵ�����
Fig.5 Training result of NNs for character recognition of Union Baidu CAPTCHA
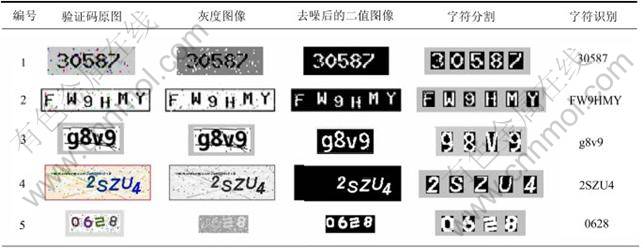
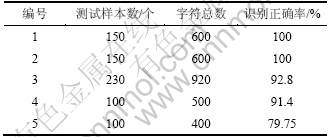
ʵ�����ô�������ͼ��Գ�������˲��ԣ���ͬ��֤��ʶ����̵Ĵ���Ч�����1��ʾ�����ͳ�����2��ʾ����վ1��2����֤���ַ��������������٣�ʶ���ʴﵽ100%����վ3��4����֤����������϶ࡢ�ַ�����б��ʶ����Ҳ���ﵽ��90%���ϡ�
��1 ��ͬ��֤��ʶ��ʵ��Ĵ���Ч��
Table 1 Treatment effects of different CAPTCHAs�� recognition experiments
��2 ʵ����Խ��ͳ��
Table 2 Statistical data of test experiments
4 ����
�����ϻ���ͼ��ʶ������������֤��ʶ���ܹ���Ч��ʶ���ַ����в������������϶����֤��ͼ����֮�����������ѵ�����̻����ٵ���Ҫ�˹����룻���ַ����Ρ���Ƕ���ת����֤��ʶ��Ч�����д����ƣ������վ5����֤��ʶ���ʲ������롣���Ķ�����֤���Զ�ʶ������������о���Ӧ�þ���һ���Ľ�����壬��ά�����簲ȫ����ֹ��������Լ�����������������˵ȷ�����й�����Ӧ��ǰ����
�ο����ף�
[1] �˴��, ����. һ�ֻ����ⲿ������������֤��ʶ��[J]. �������Ϣ, 2007, 23(25): 256-258.
PAN Da-fu, WANG Bo. A digit validation image recognition algorithm based on exterior contour[J]. Microcomputer Information, 2007, 23(25): 256-258.
[2] ����, ����, ������. ������֤��ʶ���㷨���о������[J]. �����������Ӧ��, 2007, 43(32): 86-87.
WANG Hu, FENG Lin, SUN Yu-zhe. Research and design of digital character-based CAPTCHA decoder[J]. Computer Engineering and Applications, 2007, 43(32): 86-87.
[3] ԭ����, ������, �չ���. �����ַ������������ַ�ʶ���㷨[J]. ������, 2009, 29(1): 56-58.
YUAN Yu-lei, JIANG Li-xing, QIN Gui-qin. Digital character recognition algorithm based on character feature[J]. Hydrographic Surveying and Charting, 2009, 29(1): 56-58.
[4] ����ѧ, ��־ǿ. ������������MATLAB R 2007ʵ��[M]. ����: ���ӹ�ҵ������, 2008: 1-8.
GE Zhe-xue, SUN Zhi-qiang. Neural network theory and MATLAB R2007 realization[M]. Beijing: Publishing House of Electronics Industry, 2008: 1-8.
[5] ������, �ܸ�, ������. һ�ֻ���������BP �����糵���ַ�ʶ��[J]. ��ľ˹��ѧѧ��: ��Ȼ��ѧ��, 2009, 27(6): 831-833.
MA Xiao-juan, ZHOU Gang, PAN Ren-long. License plate character recognition based on BP neural network[J]. Journal of Jiamusi University: Natural Science Edition, 2009, 27(6): 831-833.
[6] Guyon I, Elisseeff A. An introduction to variable and feature selection[J]. J Mach Learning Res, 2003(3): 1157�C1182.
(�༭ �²ӻ�)
�ո����ڣ�2011-04-15�������ڣ�2011-06-15
������Ŀ�������н���ίԱ�Ṳ����Ŀר������(XK100070532)
ͨ�����ߣ��˷�(1981-)���У��Ĵ��ϳ��ˣ���ʿ����ʦ������������Ϣ�����о����绰��010-68948971��E-mail: dengfang@bit.edu.cn

