DOI: 10.11817/j.issn.1672-7207.2016.07.019
基于深度时空域卷积神经网络的表情识别模型
杨格兰1, 2,邓晓军3,刘琮1
(1. 同济大学 电子与信息工程学院,上海,201804;
2. 湖南城市学院 信息科学与工程学院,湖南 益阳,413000;
3. 湖南工业大学 计算机与通信学院,湖南 株洲,412007)
摘要:基于特征抽取是表情识别算法中的重要步骤,但是现有算法依赖手工设计特征且适应性差等问题,提出基于深度时空域卷积神经网络的表情识别模型,采用数据驱动策略直接从表情视频中自动抽取时空域中的动静态特征。使用新颖的卷积滤波器响应积替代权重和,使得模型能同时抽取到动态特征和静态特征。引入深度学习的多层设计,使得模型能逐层学习到更抽象、更宏观的特征。采用端对端的有监督学习策略,使得所有参数在同一目标函数下优化。研究结果表明:训练后的卷积核类似于Garbor滤波器的形态,这与视觉皮层细胞对激励的响应相似;该模型能对表情视频进行更准确分类;通过与其他几种近年出现的算法进行比较,验证该算法的优越性。
关键词:情感计算;表情识别;时空域;卷积神经网络;深度学习
中图分类号:TP301 文献标志码:A 文章编号:1672-7207(2016)07-2311-09
Facial expression recognition model based on deep spatiotemporal convolutional neural networks
YANG Gelan1, 2, DENG Xiaojun3, LIU Cong1
(1. School of Electronics and Information Engineering, Tongji University, Shanghai 201804, China;
2. School of Information Science and Engineering, Hunan City University, Yiang 413000, China;
3. College of Computer and Communication, Hunan University of Technology, Zhuzhou 412007, China)
Abstract: Considering that the feature extraction is crucial phases in the process of facial recognition, and it incorporates manual intervention that hinders the development of reliable and accurate algorithms, in order to describe facial expression in a data-driven fashion, a temporal extension of convolutional neural network was developed to exploit dynamics of facial expressions and improve performance. The model was fundamental on the multiplicative interactions between convolutional outputs, instead of summing filter responses, and the responses were multiplied. The developed approach was capable of extracting features not only relevant to facial motion, but also sensitive to the appearance and texture of the face. The introduction of hierarchical structure from deep learning makes the approach learn the high-level and global features. The end to end training strategy optimizes all the parameters under the uniform objective. The results show that the approach extracts the two types of features simultaneously as natural outcome of the developed architecture. The learnt fitters are similar to the receptive field area of visual cortex. The model is proved to be effective.
Key words: affect computing; facial expression recognition; spatiotemporal space; convolutional neural networks; deep learning
感知表情有别于理性思维和逻辑推理,是第三类人类智能表情[1]。表情是人类交往的重要渠道,是计算机理解人类行为的前提,也是情感计算的基础。表情识别被广泛地应用于商业营销、人机交互、疲劳驾驶检测、远程护理和疼痛评估等领域。然而,从表情视频中自动识别人脸表情是一项极具挑战的机器视觉任务。光照、位置、化妆、饰物和遮挡等对计算机理解表情都有影响。表情识别系统的实用化需要鲁棒的算法才能实现。现有的表情识别算法大致上可以分为2步:特征抽取和分类识别。在特征抽取阶段,一般采用手工来显性地设计特征。常用的特征描述子有Garbor[2],DAISY[3]和LBP[4]等。在分类识别阶段,上一步生成的特征向量被输入SVM、随机森林等浅层[5]分类器中,进行表情归类。这些分类器的设计原则是分辨类间变换(不同类型的表情)和类内变化(2个人的相同表情)。现有算法存在一些弊端。一是在特征抽取阶段,手工特征的通用性不足。虽然近年来出现了一些基于学习的(learning-based)、数据驱动(data-drive)的特征抽取方法[6],但是它们的优化目标并不直接与表情分类相关,抽取的特征可能引入了与表情无关的其他信息。更为重要的是,现有算法是先独立地抽取视频中的多帧特征再进行汇总,没有考虑多帧之间的相关性,可能会丢失视频时域上的动态特征。而时域动态特征是视频识别区别于静态图像识别的关键。表情视频识别本质上是三维数据的分类。视频数据有1个重要特性,即视频数据在空域(两维)和时域(一维)上都存在着明显的统计相关性。空域相关性构成了图像的边缘、纹理等特征,时域相关性与表情的动态特征密切相关。近年来,深度卷积神经网络(deep convolutional neural networks)在静态图像的空域特征识别方面表现出较明显优势[7-8],但时域特征在视频识别中具有更重要的地位。卷积神经网络是针对静态图像识别设计的,从设计之初[9]就缺乏对时域特征的考虑,这导致深度卷积神经网络在视频识别方面的效果较差。人们对有限的研究[10-12]集中在:扩展(复制)原有卷积神经网络的第1个卷积层,使得每帧都对应1个卷积层,期望通过这些并行多个卷积层来学习到时域特征。但在实验中发现[12],当使用这种改进卷积神经网络来识别人类动作视频时,使用单帧卷积层和使用多帧卷积层的准确率差别不大,也就是说改进后的卷积神经网络本质上还是使用空域特征来识别人体动作的,期望中的时域特征并没有学习。JI等[10-11]通过事先抽取帧与帧之间的光流特征引入时域特征,但是这种方法分隔了特征抽取和分类识别阶段,破坏了端对端的学习结构。在学习时域特征方面,近年来出现了一些符合深层和端到端神经网络架构的算法[13-14]。这些算法的共同点是:通过计算两帧之间的逐元素乘积来抽取时域特征。实际上,这种逐元素乘相当于计算两帧图像的Gabor滤波器响应的平方和。实验表明[14]:在视频识别任务中,基于能量感知模型的算法可以学习到类似于人类大脑视觉皮层V1区复杂细胞(complex cell)的响应。但是,这些基于能量感知模型的算法存在1个明显缺陷,即三维视频数据在输入网络前,必须拉成一维向量的形式。这破坏了空域和时域上的相对位置关系,可能会引起空域和时域相关信息丢失,还会造成高维数据所具有的维度灾难问题。针对以上算法不足,本文作者结合深度卷积网络和能量感知模型的优势,提出一种新的表情识别模型。新模型使用多个并行卷积层从多帧中抽取特征(类似文献[12]中的扩展卷积层),再计算这些特征的两两逐元素乘(类似能量感知模型)。这种神经元间的乘法交互(multiplicative interactions)模型可以显性地学习到时域动态特征。同时,新模型保留了卷积神经网络在处理空域特征上的优势,即直接处理二维图像而不用事先拉成一维向量,这避免了能量感知模型的维度灾难问题。另外,还证明了新模型可以同时学习空域静态特征。因为视频静态特征与表情识别任务是强相关的,所以这是一个有用特性。称这种新模型为基于时空域深度卷积神经网络(spatiotemporal convolutional neural networks,stCNN)的表情识别模型,以强调它能同时学习时空域特征的特性。
1 时空域卷积神经网络
1.1 卷积神经网络结构
卷积神经网络是前馈多层神经网络中具有代表性的一类网络,其思想来源于1962年HUBEL和WIESEL对猫脑主要视觉皮层的研究。深度卷积神经网络通过多个串行的卷积层(convolution layer)和池化层(pooling layer)间隔排列的方式逐层地学习数据特征,其网络结构见图1。其中,卷积层采用卷积操作的方式利用小于图像尺寸的卷积核来扫描整个图像并计算卷积核与图像局部位置的权重之和。当输入数据为二维结构的图像时,因为卷积操作可以直接处理二维拓扑结构,还能减少权值数量,降低网络复杂度,便于特征提取和模式分类。卷积层的输出常常被离散化和归一化,并称之为特征映射(feature maps),每个卷积都对应1个特征映射。特征映射随后被输入到池化层进行空域上子抽样(subsample),比较直接的方法是对输入图像感兴趣点周围的邻居结点计算平均值,每次计算周围邻居结点的步进值在1到最大邻居范围之间。经过池化层处理能减小输出特征映射图的分辨率,降低卷积神经网络对输入图像中待识别对象位置变化的敏感程度,使得卷积神经网络具有一定程度的抗畸变能力。网络的更高层使用更宽泛的感受野对低分辨率特征映射进行结合和进一步抽象,以期获得更具辨识力的特征。网络的最顶层将所有得到的特征映射重新拉成一维向量并结合多分类回归分类器反向传播错误信号来调整网络参数。卷积神经网络主要用来识别位移、缩放和其他形式扭曲不变性的二维图像。网络直接输入训练数据进行学习,避免了手工设计特征。另外,卷积神经网络还可以利用现代GPU的多个流处理器架构进行并行计算,这大大加快了网络的训练速度。卷积神经网络以其独特的卷积操作、卷积核共享和子抽样结构,在二维图像处理方面有着先天优越性,其较强的容错能力、并行处理能力和自学习能力可处理复杂环境下的二维信号识别问题。
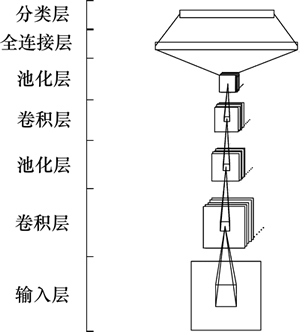
图1 卷积神经网络结构
Fig. 1 Structure of convolutional neural networks
1.2 时空域卷积神经网络的结构
虽然卷积神经网络不能抽取时域上的动态特征,但其适合处理图像二维拓扑结构,并能保持像素间的相对位置关系。本文提出的时空域卷积神经网络将这些优势整合于能量感应模型,以高效地抽取视频中的时空域特征。
时空域卷积神经网络的基本结构如图2所示。从图2可见:为了应对视频的多帧,它首先扩展了原卷积神经网络的卷积层,使得不同的帧都有相应的卷积层对其处理。这种结构保留了卷积层对二维信号处理的优势。其次,为了模拟能量感知模型的逐元素乘操作来捕捉帧之间的时域相关性,还设计了新的乘法层和加法层。
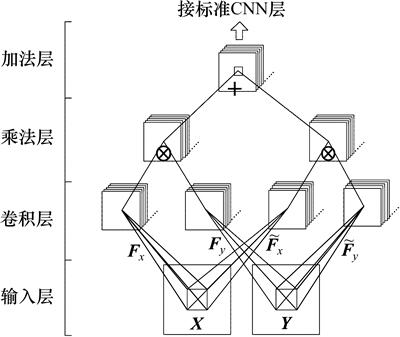
图2 时空域卷积神经网络
Fig. 2 Spatiotemporal convolutional neural networks
时空域卷积神经网络由4层组成。
1) 输入层使用2个相邻帧X和Y作为输入,网络要能捕捉到它们之间时域上的动态特征和空域上的静态特征。
2) 卷积层使用与标准卷积神经网络一样的卷积操作。但这里的卷积核被分成4组,每帧分别对应2组卷积核。将每组中的某个卷积核写作矩阵形式:Fx,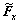 ,Fy和
,Fy和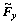 ,则经过训练Fx和Fy,和之间会自动地形成正交基函数对。相应的4个特征映射可以记为:
,则经过训练Fx和Fy,和之间会自动地形成正交基函数对。相应的4个特征映射可以记为: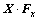 ,
,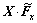 ,
,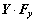 ,和
,和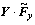 。若输入图像的大小为N×N,卷积核的大小为K×K,则采用有效卷积操作(valid convolution)后的特征映射大小为(N-K+1)×(N-K+1)。注意:在实际操作中,卷积一般采用多通道卷积操作(即3D卷积)来处理彩色图像的RGB三通道;还可以添加偏置参数,以便用仿射来代替线性映射,可以使用stride技术来减少参数,可以使用传统神经网络的非线性激活函数(activation function):sigmoid或者tanh。但是,为了使推导简洁,这里只用简洁的2D卷积来表达公式。
。若输入图像的大小为N×N,卷积核的大小为K×K,则采用有效卷积操作(valid convolution)后的特征映射大小为(N-K+1)×(N-K+1)。注意:在实际操作中,卷积一般采用多通道卷积操作(即3D卷积)来处理彩色图像的RGB三通道;还可以添加偏置参数,以便用仿射来代替线性映射,可以使用stride技术来减少参数,可以使用传统神经网络的非线性激活函数(activation function):sigmoid或者tanh。但是,为了使推导简洁,这里只用简洁的2D卷积来表达公式。
3) 乘法层用来计算2个特征映射之间的逐元素乘(element-wise product)。参与运算的2个特征映射需分别处于2组特征映射中,并分别对应相邻帧X和Y。称乘法层的输出为积映射,则积映射有2组,记每组中的某个积映射为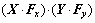 和
和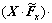
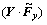 ,这里的“・”表示逐元素乘。注意:在能量感知模型中,2个相邻帧X和Y之间的变换关系也是被表达成这种逐元素乘的形式。
,这里的“・”表示逐元素乘。注意:在能量感知模型中,2个相邻帧X和Y之间的变换关系也是被表达成这种逐元素乘的形式。
4) 加法层用来计算2个积映射的逐元素和(element-wise sum),即
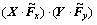 + (1)
+ (1)
这里的“+”表示逐元素求和,称加法层的输出为和映射。因为是逐元素求和,所以和映射的尺寸与上层的一致。每一个和映射都代表了某一特定空时域特征在图像空域上出现的情况。
时空域卷积神经网络有别于标准卷积神经网络之处在于:采用不同帧对应的滤波器响应的乘积操作来代替求和操作。这种乘积操作可看作是2个向量化图像的外积,即2个图像的相关系数,也可看作是能量感知模型的变形。正是这种相关分析给时空域卷积神经网络提供了相邻帧之间的变换信息。
1.3 和映射上的节点值
根据时空域卷积神经网络的结构,输入2个连续帧时网络会在和映射的节点上给出多个响应值。考虑其中1个节点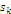 ,此节点的感受野在X和Y上的尺寸为K×K,见图3。图中输入层小矩形框里的图像为节点能见的范围。注意:因为采用了逐元素乘与逐元素加,所以,乘法层和加法层并不改变感受野的范围。
,此节点的感受野在X和Y上的尺寸为K×K,见图3。图中输入层小矩形框里的图像为节点能见的范围。注意:因为采用了逐元素乘与逐元素加,所以,乘法层和加法层并不改变感受野的范围。
节点sk是1个标量,可写作以下形式:
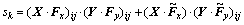 (2)
(2)
这里的i和j用来索引节点sk的感受野范围。
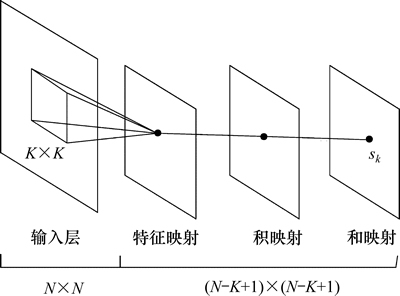
图3 和映射上节点的感受野
Fig. 3 Receptive fields of node on sum map
式(2)中的卷积操作还可以写作矩阵与向量乘的形式。这是因为二维离散循环卷积操作可用1个特殊的块循环矩阵(block circulant matrix)来实现。例如:卷积操作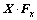 可以写作
可以写作 。其中,x是按照列顺序将矩阵X的列连接而生成,Fx为N2×N2的双块循环矩阵(doubly block circulant),Fx 的每行都包含了合适的滤波器系数来实现X和Fx 之间的二维卷积操作。若把Fx,,Fy和对应的双循环矩阵中的某一行表示成大小为1×N2向量
。其中,x是按照列顺序将矩阵X的列连接而生成,Fx为N2×N2的双块循环矩阵(doubly block circulant),Fx 的每行都包含了合适的滤波器系数来实现X和Fx 之间的二维卷积操作。若把Fx,,Fy和对应的双循环矩阵中的某一行表示成大小为1×N2向量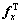 ,
,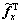 ,
, 和
和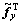 ,由以上分析,式(2)可重新写作:
,由以上分析,式(2)可重新写作:
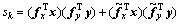 (3)
(3)
由式(3)可知:卷积可以看作在输入图像的一定空域范围内进行线性变换。2个滤波器的响应被先相乘再相加,使得节点sk成为1个时空域特征描述子。卷积操作一般有2个类型:循环卷积(circular convolution)和可用卷积(valid convolution),为了能将其写成矩阵向量乘的形式,这里考虑循环卷积并在Fx的周围增补0直至与x的大小相同。该结论对可用卷积也近似成立。这是因为在计算有效卷积时,卷积核需要整个位于图像的内部,而循环卷积不对此有要求,且当卷积核不能整个位于图像内部时,允许卷积核循环位移,所以,2种卷积生成的结果在图像内部区域是一致的。
2 复平面上的时空特征描述子
这里将证明每个与映射上的每个节点sk都是时空特征描述子(spatiotemporal descriptor),它通过检测复平面上的旋转角度来同时抽取时域上的动态特征和空域上的静态特征。考虑两帧x和y之间的图像变换L,
y=Lx (4)
其中:x和y是矩阵X和Y中每列首尾相接形成的大小为1×N2的向量;L为它们之间的图像变换矩阵(image warp)。注意:这里不是通常意义上的仿射变换(affine transformation)。当使用图像变换时,对应的L是置换矩阵(permutation matrix),这是一种特殊的、用于在像素空间中转换图像内容的矩阵,这种矩阵的每一行和每一列只有1个元素为1,其余全是0。当图像向量与这种矩阵相乘时,可以实现将图像的像素任意排列。实际上,初等几何变换中的平移、旋转、缩放等都可以用置换矩阵来近似描述。显然,置换矩阵是正交规范矩阵,正交矩阵的1个重要性质是:其在复数域上可以被对角化,即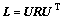 。其中:复数域
。其中:复数域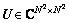 ,为L的特征向量组成的正交规范矩阵且所有元素都为复数,对角矩阵
,为L的特征向量组成的正交规范矩阵且所有元素都为复数,对角矩阵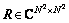 的对角线元素都是模为1的复数。将此公式代入式(4)则有
的对角线元素都是模为1的复数。将此公式代入式(4)则有
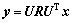 (5)
(5)
若只考虑x在U中1列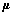 上的投影,则有
上的投影,则有
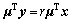 (6)
(6)
其中: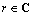 是R中对角线上的1个元素。因为特征向量的选择不是唯一的,可以选择使得其上的所有元素的模也为1,使用欧拉公式,将这些模相同而方向不同的复数中的1个写作:
是R中对角线上的1个元素。因为特征向量的选择不是唯一的,可以选择使得其上的所有元素的模也为1,使用欧拉公式,将这些模相同而方向不同的复数中的1个写作: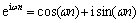 。整列可以写作:
。整列可以写作: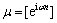 ,i=1, …, N2。其中,
,i=1, …, N2。其中, 表示U中列对应的频率,注意每列对应的频率不同。又因为复数乘实数等于复数的实部乘实数加上复数的虚部乘实数,所以,可以把每个复数拆成cos(实部)和sin(虚部)而不会丢失任何信息。这样,就可以拆成2列u(由cos函数组成的实部)和
表示U中列对应的频率,注意每列对应的频率不同。又因为复数乘实数等于复数的实部乘实数加上复数的虚部乘实数,所以,可以把每个复数拆成cos(实部)和sin(虚部)而不会丢失任何信息。这样,就可以拆成2列u(由cos函数组成的实部)和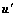 (由sin函数组成的虚部)。相应地,式(6)可以被重新写作:
(由sin函数组成的虚部)。相应地,式(6)可以被重新写作:
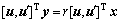 (7)
(7)
其中,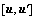 与x、与x之间的点积会生成二维向量,且位于基撑起的二维复平面上。所以,式(7)相当于:先把图像x投影到对应的复平面上得到复数
与x、与x之间的点积会生成二维向量,且位于基撑起的二维复平面上。所以,式(7)相当于:先把图像x投影到对应的复平面上得到复数 ,再将其乘以模为1的复数r (即在复平面中旋转一个角度
,再将其乘以模为1的复数r (即在复平面中旋转一个角度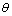 ,由r决定),最后再映射回像素空间。
,由r决定),最后再映射回像素空间。
同理,矩阵U中的每一列(特征向量)都可以按照前面方法被分拆成2列:
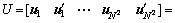
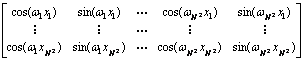
其中:i和j索引列,n索引行。这些被拆分的每对列与离散傅里叶变换有密切的联系。这是因为图像x的离散傅里叶变换是将图像x投影到一组由cos和sin
函数组成的基即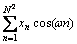 和
和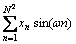 ,并精心设计每组基对应的频率使得基之间正交,即
,并精心设计每组基对应的频率使得基之间正交,即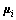 与
与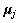 之间正交。显然,规范正交化的矩阵U的列满足此条件,且U中每对被分拆的列组成相位差为90°的正交对(quadrature pairs)。所以,这些正交对相当于离散傅里叶分析中的基函数
之间正交。显然,规范正交化的矩阵U的列满足此条件,且U中每对被分拆的列组成相位差为90°的正交对(quadrature pairs)。所以,这些正交对相当于离散傅里叶分析中的基函数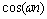 和
和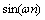 ,其与人类大脑视觉皮层V1区域的简单细胞和复杂细胞有密切的联系,见图7。把x和y投影到U的每列上,就相当于对图像进行了离散傅里叶变换。
,其与人类大脑视觉皮层V1区域的简单细胞和复杂细胞有密切的联系,见图7。把x和y投影到U的每列上,就相当于对图像进行了离散傅里叶变换。
下面证明对于不同类型的图像变换,式(5)中的U或者式(6)中的是相同的,而R或者r不同。对角化理论认为:对所有的线性变换L,若存在1个可逆矩阵U,使得 是对角矩阵,则称所有的L可被同时对角化。同时对角化成立的条件是:不同的L符合交换律,即
是对角矩阵,则称所有的L可被同时对角化。同时对角化成立的条件是:不同的L符合交换律,即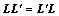 。事实上,不同的置换矩阵L符合交换律。考虑2个相继的平移变换L(向下平移)和
。事实上,不同的置换矩阵L符合交换律。考虑2个相继的平移变换L(向下平移)和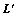 (向左平移),则先向下平移再向左平移
(向左平移),则先向下平移再向左平移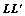 后的目标物体位置和先向左平移再向下平移的位置相同。所以,置换矩阵L符合交换律,U在不同的图像变换中都是相同的,图像变换间的差异只体现在R或者r上。
后的目标物体位置和先向左平移再向下平移的位置相同。所以,置换矩阵L符合交换律,U在不同的图像变换中都是相同的,图像变换间的差异只体现在R或者r上。
下面证明“和映射”上的节点sk是特定图像变换的描述子。从以上分析可见:x和y之间的变换可以通过将x和y投影到响应的复平面上,再通过计算复平面上的旋转角度就可以判定x和y之间的变换类型。假设式(7)中的二维向量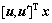 和
和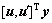 的长度都为1,并设其投影在复平面
的长度都为1,并设其投影在复平面 上的角度分别为
上的角度分别为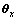 和
和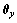 ,则r对应的旋转角度
,则r对应的旋转角度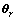 ,也就是和之间夹角-的余弦为
,也就是和之间夹角-的余弦为
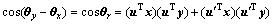 (8)
(8)
若将r吸收进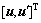 ,即
,即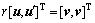 ,并把式(7)重新写作:
,并把式(7)重新写作:
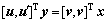 (9)
(9)
则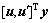 与
与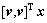 之间的夹角余弦为
之间的夹角余弦为
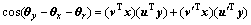 (10)
(10)
当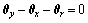 时,式(10)有最大值1。注意到式(10)与式(3)具有相同的形式,所以,式(3)可解释为:当相邻帧X和Y之间存在对应的某种图像变换L时,sk获得最大值。即标量sk反映了特定图像变换是否出现在相邻帧中,也就是说sk是特定图像变换的描述子。
时,式(10)有最大值1。注意到式(10)与式(3)具有相同的形式,所以,式(3)可解释为:当相邻帧X和Y之间存在对应的某种图像变换L时,sk获得最大值。即标量sk反映了特定图像变换是否出现在相邻帧中,也就是说sk是特定图像变换的描述子。
下面证明“和映射”上的节点sk不仅是特定图像变换的描述子,而且是图像内容的描述子。前面在推导式(9)时,使用了假设:二维向量和的长度都为1。这明显是不合理的,因为大部分图像在对应的复平面上的投影长度不为1。例如,图4中,要投影的图像(左下)缺乏竖直方向上频率的内容(frequent contents)(右上),造成其在对应复平面上的投影长度为0(右下)。而其在水平方向频率(中上)对应的复平面上的投影长度不为0(中下)。
由以上分析可知:sk会受到图像内容的影响,但这并不会对表情识别造成不利影响。因为单帧图像中的静态内容也是判断表情分类的重要依据,而人类甚至可以根据单帧的笑脸图像判断出对应的表情是高兴。可见,映射上的每个时空特征描述子sk具有以下性质:1) 和映射上的每个节点sk在自己的感受野中检查特定的图像变换和图像内容是否出现;2) 通过不共享卷积核,1个和映射可以高效地在图像上检查多个不同的图像变换和图像内容。
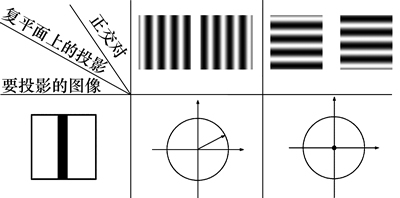
图4 图像在正交对对应的复平面上的投影
Fig. 4 Projection of images on complex planes corresponding to different quadrature pairs
3 基于时空域深度卷积神经网络的表情识别模型
基于时空域卷积神经网络,再结合标准深度卷积神经网络结构设计1种表情识别模型,如图5所示。
图5中,模型使用5个时空域卷积神经网络模块来学习时空特征描述子,并在其加法层输出这些特征描述,训练或测试视频按照5帧一组按顺序输入模型。使用5个连续帧的原因是:在建模动作时,5~7帧就可以较好地表达整个视频的时域特征[15]。所有的卷积层使用localconnect策略,不共享参数。卷积层、加法层和全连接层使用ReLUs非线性,以便加速计算。归一层使用局部响应归一化(local response normalization)来提高模型的泛化能力(generalization)。池化层用来消除数据噪音和小形变带来的不利影响。时空域深度卷积神经网络的卷积层有4组共96个10×10的滤波器。第2个卷积层使用256个5×5的滤波器。第3,4和5个卷积层分别使用384,384和256个3×3的滤波器。最后的全连接层有1 024个神经元,并使用dropout技术来防止过拟合,从而提高模型的泛化能力,dropout的值设定为0.7。所有的池化层使用2×2的重叠滑动窗口进行池化操作。模型相当于把空域深度卷积神经网络模块插入标准的深度卷积神经网络架构中,并使用了2012年imagenet挑战赛冠军Alex Net[7]中的大部分网络参数。期望这种设计可以利用深度学习的层次化结构在网络高层学到抽象的、全局的时空域特征。模型使用有监督策略训练,softmax层连接全连接层来计算每个分类的后验概率。分类误差被反向传播至每一层中计算各参数的梯度。采用基于小批量(min-batch)策略的随机梯度下降算法来更新参数,并对相邻帧组成的数据集进行随机排序以保证每次迭代时采用的小批量数据达到类均衡。实验使用 5 折交叉验证。最后的识别率为 5次实验的平均值。
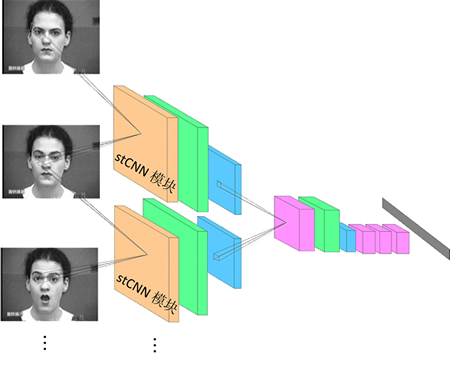
图5 基于深度时空域卷积神经网络的表情识别模型
Fig. 5 Facial expression recognition model based on Spatiotemporal convolutional neural network
4 试验
4.1 CK+人脸表情库
使用CK+人脸表情数据集(extended Cohn-Kanade facial expression)[16]测试基于深度时空域卷积神经网络的表情识别模型。CK+数据集包含了210个人的7种表情(生气、高兴、惊讶、厌恶、恐惧、悲伤、轻蔑)的大约2 000个视频,见图6(a),试验只使用有分类标签的视频子集。视频的空间分辨率为640×490或者640×480,黑白或者彩色图像,该数据库中每个人的每种表情都包括一系列脸部活动,由开始表情到极强表情的表情序列构成,见图6(b)。

图6 CK+人脸表情数据集
Fig. 6 CK+ facial expression datasets
为简化模型,试验将彩色视频转为黑白视频,并把视频的空域尺寸缩小为160×120,视频还经过减像素均值预处理。
图7所示为基于深度时空域卷积神经网络的表情识别模型在训练后相邻帧X和Y对应的16个随机选择的滤波器,发现在自然数据集上,时空域深度卷积神经网络学习到的特征类似于Gabor滤波器的形态,即不同的滤波器对于大小、位置、频率、方向和相位有着不同的选择性。这些滤波器的形态非常类似于神经学在人脑V1区域中发现的简单细胞(simple cells)对外界刺激的响应。图7(a)和图7(b)所示2组滤波器互相成对,与时间存在90°的相位差。

图7 卷积层滤波器的最优响应
Fig. 7 Optimal filter responses of convolutional lay
图8所示为本文模型在CK+数据集上的混淆矩阵。其中,行代表正确的类别,列代表模型的分类结果。从图8可见模型的总体识别率较高,而在伤心和害怕两类上错误率较高,这也与人们的直觉相似,因为有时人类要正确判断这2个类较困难。
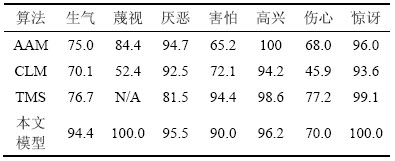
表1所示为本文模型与其他3种算法的平均正确率的比较。从表1可以看出本文模型在7类上的平均正确率为92.3%,高于AAM算法(active appearance models)[16],CLM算法(constrained local models)[17]和TMS算法(temporal modelling of shapes)[18]的平均正确率。
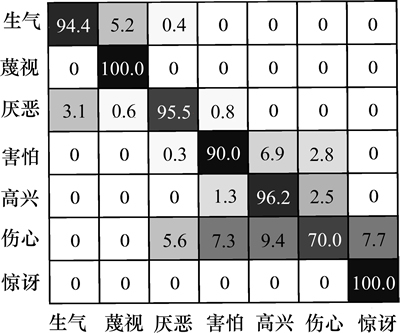
图8 模型在CK+数据集上的混淆矩阵
Fig. 8 Confusion matrix of CK+ dataset
表1 4种算法在CK+数据集上的平均正确率
Table 1 Average recognition accuracy on CK+ dataset %
因为一次性输入模型的连续帧的数量是本模型抽取时空域特征的基础,所以,连续帧数量是决定模型性能的重要参数。此外,对于每一帧都需要1个并行的卷积层,所以,连续帧数量也决定了模型的计算复杂度。通常地,在不影响模型性能的前提下,为了降低计算复杂度和发生过拟合的概率,希望连续帧的数量越少越好。为了研究连续帧的数量对本文模型性能的影响,选择数量从1~10的连续帧,改造识别模型的并行卷积层的数量,在其他参数不变的条件下计算模型在3种类别上的正确率与连续帧数量的关系。这3种类别分别是:惊讶和伤心上的正确率,以及其他4种类别上的平均正确率。图9(a)所示为实验结果。从图9(a)可见:随着连续帧数量的增加,3种表情类别的正确率都呈现稳步上升趋势;当模型看到的表情帧数量从1帧上升到2帧时,3种表情类别的正确率较大提高;当表情帧数量达到5帧时,3种表情类别的正确率逐渐趋于稳定。考虑到模型的计算复杂度,建议连续帧数量取值5是一个较好的折中策略。
与正确率不同,召回率是指识别出的相关视频数量与数据库中所有的相关视频数量的比率,衡量模型对相关视频的查全率。为了研究本文模型在不同连续帧数量下的召回率,计算模型在连续帧数量为1~6帧的条件下6种表情类别的召回率,图9(b)所示为实验结果。从图9(b)可以发现模型的召回率随着连续帧数量的增加呈现上升趋势,但与正确率不同的是其上升趋势并不稳定。与正确率类似,大多数表情类别在连续帧数量达到5帧时,已能较好地覆盖数据库中的样本,但继续增加连续帧数量,个别表情类别出现了召回率下降的趋势,故根据实验结果建议连续帧数量取值在6以下。
4.2 FABO双模态情感数据库
本文模型的1个重要优点是能够端对端地采用数据驱动策略从视频数据中直接抽取时空域特征,这意味着不用人工干预,模型就可自动地借助视频中的其他因素(除去表情因素)来辅助表情识别。为了验证基于模型的这一特性,采用 FABO即身体姿态和人脸表情的双模态情感数据库[19]对本文模型性能进行测试。
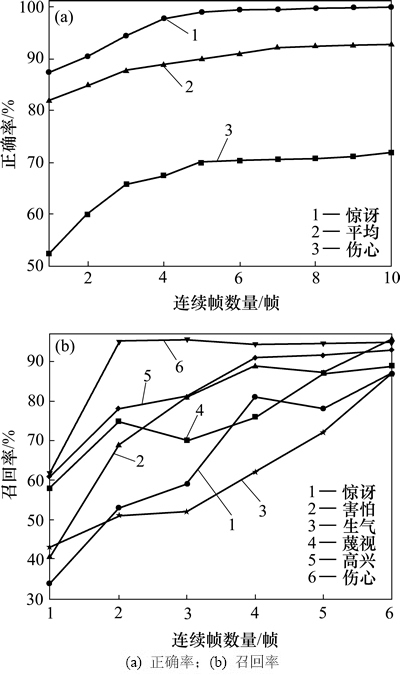
图9 连续帧数量与正确率和召回率的关系
Fig. 9 Relationship between number of contiguous frames and accuracy recall
FABO是目前唯一公开的表情和姿态双模态情感数据库,其理论基础是人类的情感表达并不仅仅通过单种模态,而是多种模态情感信息融合的方式。FABO数据库包括了大约1 900条18~50岁人的双模态视频。
FABO数据库由单模态的表情视频和双模态的表情+姿态视频组成,图10所示为模型在2种模态下的混淆矩阵,2种模态下的平均正确率分别为88.5%和96.1%。从图10可以看出:在表情+姿态双模态下本文模型在7种表情上的正确率都比表情单模态下的正确率高,特别是迷惑类别的正确率从80%提高到89%,这说明姿态能有效地辅助表情识别,而且模型能自动地从姿态中抽取空时域特征。
图11所示为本文模型在表情+姿态模态下与其他3种算法平均正确率的比较结果。为了公平对比,选取的3种算法均采用表情+姿态视频双模态进行处理。3种算法分别是BayesNet,AD+HMM (automatic determination + hidden markov model)和CCA (canonical correlation analysis),数据均来自文献[20]。可以看出本文模型的平均正确率要比其他3种算法的高。
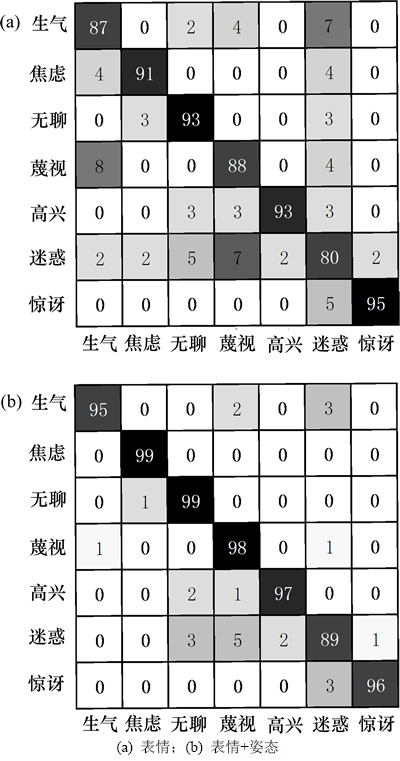
图10 模型在FABO数据库上的混淆矩阵
Fig. 10 Confused martrix of model in FABO dataset
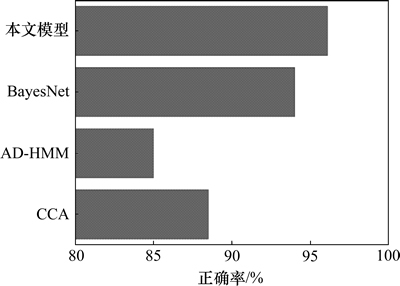
图11 4种算法在FABO数据集上的平均正确率
Fig. 11 Averagerecognition accuracy on FABO dataset
5 结论
1) 提出基于深度时空域卷积神经网络的表情识别模型。使用卷积滤波器的响应积来代替传统神经网络的响应和,使得模型能从相邻帧之间高效地抽取表情的静态特征和动态特征。使用深度学习策略,使模型能逐层抽取更抽象、更宏观的特征。
2) 采用端对端的学习策略,直接从原始像素中学习特征,并将特征抽取和分类识别统一在同个优化目标下,使这2个阶段的参数得到优化,提高了模型在基准测试数据集上的平均正确率。
3) 空时域卷积神经网络还可应用到其他需要学习图像间关系的领域,如人类行为视频分析、双目视觉中的深度估计、全景图拼接等。
参考文献:
[1] GAVRILA D M. The visual analysis of human movement: a survey[J]. Computer Vision and Image Understanding, 1999, 73(1): 82-98.
[2] 宋伟, 赵清杰, 宋红, 等. 基于关键块空间分布与Gabor滤波的人脸表情识别算法[J]. 中南大学学报(自然科学版), 2013, 44(S2): 239-243.
SONG Wei, ZHAO Qingjie, SONG Hong, et al. Keyblock distribution and Gabor filter based facial expression recognition algorithm[J]. Journal of Central South University (Science and Technology), 2013, 44(S2): 239-243.
[3] TOLA E, TOLA E, LEPETIT V, et al. A fast local descriptor for dense matching[C]// IEEE Conference on Computer Vision and Pattern Recognition. Alaska, USA: IEEE, 2008: 1-8.
[4] 陈炳权, 刘宏立. 基于二次修正的LBP算子和稀疏表示的人脸表情识别[J]. 中南大学学报(自然科学版), 2014, 45(5): 1503-1509.
CHEN Bingquan, LIU Hongli. Facial expression recognition based on improved IBP operator and sparse representation[J]. Journal of Central South University (Science and Technology), 2014, 45(5): 1503-1509.
[5] BENGIO Y. Learning deep architectures for AI[J]. Foundations and trends in Machine Learning, 2009, 2(1): 1-127.
[6] HUANG G B, LEE H, LEARNED-MILLER E. Learning hierarchical representations for face verification with convolutional deep belief networks[C]// IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012: 2518-2525.
[7] SKLAN J E, PLASSARD A J, FABBRI D, et al. Toward content based image retrieval with deep convolutional neural networks[C]// SPIE Medical Imaging, International Society for Optics and Photonics. Renaissance Orlando, Florida, at Seaword, USA: SPIE, 2015: 94172c.
[8] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 1-9.
[9] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[10] JI S, YANG M, YU K. 3D convolutional neural networks for human action recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2013, 35(1): 221-231.
[11] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// Advances in Neural Information Processing Systems. 2014: 568-576.
[12] KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]// IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014: 1725-1732.
[13] MEMISEVIC R. Learning to relate images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1829-1846.
[14] LE Q V, ZOU W Y, YEUNG S Y, et al. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis[C]// IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, USA: IEEE, 2011: 3361-3368.
[15] SCHINDLER K, SCHINDLER K, van GOOL L, et al. Action snippets: how many frames does human action recognition requireC]// IEEE Conference on Computer Vision and Pattern Recognition. Alaska, USA: IEEE, 2008: 1-8.
[16] LUCEY P, COHN J F, KANADE T, et al. The extended Cohn-Kanade Dataset (CK+): a complete dataset for action unit and emotion-specified expression[C]// IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: 2010: 94-101.
[17] CHEW S W, LUCEY P, LUCEY S, et al. Person-independent facial expression detection using constrained local models[C]// IEEE International Conference on Automatic Face Gesture Recognition. Santa Barbara, California, USA: IEEE, 2011: 915-920.
[18] JAIN S, HU C, AGGARWAL J K. Facial expression recognition with temporal modeling of shapes[C]// IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011: 1642-1649.
[19] GUNES H, PICCARDI M. A bimodal face and body gesture database for automatic analysis of human nonverbal affective behavior[C]// 18th International Conference on Pattern Recognition. Hong Kong, China, 2006: 1148-1153.
[20] GUNES H, PICCARDI M. Automatic temporal segment detection and affect recognition from face and body display[J]. IEEE Trans Syst Man Cybern B Cybern, 2009, 39(1): 64-84.
(编辑 陈灿华)
收稿日期:2015-07-12;修回日期:2015-09-22
基金项目(Foundation item):湖南省自然科学基金资助项目(2015JJ2046);湖南省教育厅优秀青年项目(12B023) (Project(2015JJ2046) supported by the Natural Science Foundation of Hunan Province; Project(12B023) supported by Science Research Foundation of Education Department of Hunan Province)
通信作者:邓晓军,副教授,从事图像处理和参数优化等研究;E-mail: little_army@139.com

