
J. Cent. South Univ. Technol. (2009) 16: 0802-0806
DOI: 10.1007/s11771-009-0133-0
![]()
Wavelet matrix transform for time-series similarity measurement
HU Zhi-kun(��־��)1, XU Fei(�� ��)1, GUI Wei-hua(������)2, YANG Chun-hua(������)2
(1. School of Physics Science and Technology, Central South University, Changsha 410083, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract:
A time-series similarity measurement method based on wavelet and matrix transform was proposed, and its anti-noise ability, sensitivity and accuracy were discussed. The time-series sequences were compressed into wavelet subspace, and sample feature vector and orthogonal basics of sample time-series sequences were obtained by K-L transform. Then the inner product transform was carried out to project analyzed time-series sequence into orthogonal basics to gain analyzed feature vectors. The similarity was calculated between sample feature vector and analyzed feature vector by the Euclid distance. Taking fault wave of power electronic devices for example, the experimental results show that the proposed method has low dimension of feature vector, the anti-noise ability of proposed method is 30 times as large as that of plain wavelet method, the sensitivity of proposed method is 1/3 as large as that of plain wavelet method, and the accuracy of proposed method is higher than that of the wavelet singular value decomposition method. The proposed method can be applied in similarity matching and indexing for lager time series databases.
Key words:
wavelet transform; singular value decomposition; inner product transform; time-series similarity��
1 Introduction
The problem of efficient extraction of similar time series in large databases has received considerable attention by the data mining community because of its application to many fields, including medicine, meteorology, economics, and astrophysics. Many approaches and techniques about the extraction of feature vectors of similar time-series sequences have been suggested in the past decade. The plain Euclidean distance based on time domain analysis was firstly introduced to calculate the similarity, but it could not represent frequency feature of time-series efficiently; what is more, the dimension of feature vector was too high to index in large time series databases [1]. In recent years, reducing dimension methods, such as discrete Fourier transform (DFT) [2-3] and discrete wavelet transform (DWT) [4-6], have been carried out to cut down the dimension of time series. Indeed, they were really useful in reducing dimension. However, the strongest coefficients of DFT cannot reflect the time information efficiently and the coefficients of wavelet were too large to be feature vector. According to the shortcomings and advantages of above-mentioned methods, a new method, called wavelet-SVD, was applied to compression of time series [7-9]. It had low dimension of eigenvector and was very useful in matching problem [10-12], while the singular value only represented the coefficient of sub-space and different matrices had different sub-spaces. So it is hard to say the feature vector is always efficient and accurate.
In this work, a wavelet matrix transformation (WMT), which combines with DWT, SVD and inner product transform, was proposed to extract feature vector of time series to measure the similarity.
2 Wavelet matrix transform
2.1 Discrete orthogonal wavelet transform (DOWT)
DOWT is an irredundant wavelet transformation, by which orthogonal basis can be constructed on the foundation of the discrete framework and an original signal can be projected into orthogonal wavelet subspace. The multi-resolution formula is shown as follows [12]:
 (1)
(1)
where ![]() is the approximate coefficient;
is the approximate coefficient; ![]() is the detailed coefficient; j is the level of the decomposition and j=0, 1, 2, ��, L, L is maximal level of the decomposition; h0 is the low-pass filter and h1 is the band pass filter; D is the down sampling operator.
is the detailed coefficient; j is the level of the decomposition and j=0, 1, 2, ��, L, L is maximal level of the decomposition; h0 is the low-pass filter and h1 is the band pass filter; D is the down sampling operator.
Given a time-series sequence T={t1, t2, ��, tn}, where n is its length. Wavelet coefficient cw={cL, dL, dL-1, ��, d1} can be calculated by DOWT, where ck and dk (1��k��L) represent different approximate and detailed information respectively at each level. The length of each coefficient at different levels is extended to n/2 by padding zero in the rear, and a matrix A��R(L+1)��n/2 is shown as
 (2)
(2)
It is obvious that matrix A can entirely represent time-frequency information of time series, and hence the similarity measurement can be accomplished in wavelet spaces.
2.2 Extraction of uniform orthogonal basics
It is impossible that matrices viewed as the feature vectors of time series, are calculated directly to measure similarity since dimension of matrix is too high. Consequently, matrix decomposition for providing uniform orthogonal basis is carried out to extract feature vectors.
Lemma 1: For a matrix A��Rm��n with m��n and rank of r, the equation of SVD definition is
 (3)
(3)
where matrices U and V are orthogonal matrices, ��=diag(��1, ��2, ��, ��r) is a diagonal matrix, ��i (i=1, 2, ��, r) is the nonzero singular value of matrix A [13-15].
From Lemma 1, it is easily proved that the singular-value decomposition can be written as Corollary 1.
Corollary 1: Matrix A��Rm��n can be expressed by the sum of sub-matrices; and the size of the sub-matrices is m��n and rank of sub-matrices is 1.
![]() (4)
(4)
where r is the rank of matrix A; ui and vi are the ith vectors of U and V, respectively; ![]() ��Rm��n and
��Rm��n and ![]()
From Lemma 1, V is a unitary matrix, which implies that all vectors of matrix are orthogonal each other. Then Corollary 2 can be inferred.
Corollary 2: Two sub-matrices ![]() ��Rm��n, by the SVD of A��Rm��n, are mutual orthogonal.
��Rm��n, by the SVD of A��Rm��n, are mutual orthogonal.
![]() (5)
(5)
where �� is a real constant number.
From Corollary 1 and Corollary 2, Theorem 1 can be inferred.
Theorem 1: Matrix A��Rm��n can be expressed as the sum of subsequences with the same length by SVD and serialization. Each of two subsequences is orthogonal. The expression is
 (6)
(6)
where vA and ![]() are achieved by serialization of A and
are achieved by serialization of A and ![]() respectively; i=1, 2, ��, r.
respectively; i=1, 2, ��, r.
Proof: From Corollary 1, matrix A is decomposed by SVD, and expression (7) can be obtained as follows:
![]() (7)
(7)
By serialization of A, sequence vA can be obtained as follows:
vA=(x1, x2, ��, xm) (8)
where xi is row vector of matrix A, i=1, 2, ��, m.
Sequences ![]() can be obtained by serialization of
can be obtained by serialization of ![]() as follows:
as follows:
![]() =(xi, 1, xi, 2, ��, xi, m) (9)
=(xi, 1, xi, 2, ��, xi, m) (9)
where xi, j is row vector of matrix![]() , i=1, 2, ��, r and j=1, 2, ��, m.
, i=1, 2, ��, r and j=1, 2, ��, m.
From expressions (7)-(9) and ![]() , the first conclusion can be drawn.
, the first conclusion can be drawn.
![]() (10)
(10)
From Corollary 2, the sub-matrices are mutual orthogonal. When all of them are serialized expression (11) can be determined as follows:
 (11)
(11)
Then, expression (12) can be inferred from expression (11), in which ��0�� represents vector; however, ��0�� in expression (12) represents constant.
![]() (i��j; k, l=1, 2, ��, m) (12)
(i��j; k, l=1, 2, ��, m) (12)
Moreover, sequence ![]() in expression (10) can also satisfy expression (13) as
in expression (10) can also satisfy expression (13) as
![]() (13)
(13)
From expression (11), the second conclusion can be drawn as follows:
![]() (14)
(14)
That is: ![]()
So the proof is completed.
The essential of Theorem 1 is to provide uniform complete orthogonal basis, which could be used in inner product transform to extract analyzed and sample feature vectors.
2.3 Time-series similarity measurement
There are different methods to extract feature vectors between sample time-series sequence Tsa and analyzed time-series sequence Tan.
To extract feature vector from Tsa, wavelet transform is initially carried out to obtain wavelet coefficient matrix Msa. Then, the singular value vector ��sa= ![]() and orthogonal matrices
and orthogonal matrices ![]() are achieved by SVD of Msa. Therefore,
are achieved by SVD of Msa. Therefore, ![]() , the serialization of
, the serialization of ![]() , is orthogonal basis to extract feature vector, and ��sa is feature vector of Tsa.
, is orthogonal basis to extract feature vector, and ��sa is feature vector of Tsa.
From Theorem 1, ![]() is the coefficient of
is the coefficient of![]() . Moreover,
. Moreover, ![]() is a complete orthogonal basis. Thereby,
is a complete orthogonal basis. Thereby, ![]() could be expressed as follows:
could be expressed as follows:
![]() (15)
(15)
where < > represents inner product transform, vsa is the serialization of Msa.
To extract feature vector of Tan, the wavelet transform is firstly performed to get wavelet coefficient matrix Man. Then, van is obtained by serialization of Man. Lastly, analyzed feature vector ![]()
![]() is archived by projecting van into
is archived by projecting van into ![]() .
.
![]() (16)
(16)
After extracting feature vector of time series, the Euclidean distance is calculated between the two feature vectors.
![]() (17)
(17)
where dan is the similarity.
Given a reasonable threshold dT, Tsa and Tan are similar when dan��dT. The flow chart of similarity measurement arithmetic is shown in Fig.1.
3 Simulation and analysis
The inverter model is shown in Fig.2(a). When both IGBT T1 and T6 break, the fault wave UBN is shown in Fig.2(b).
3.1 Simulation and analysis of anti-noise ability
A white noise U0 is added to fault wave UBN. The expression is as follows:
Uno(i)=UBN+in?U0 (18)
where in is noise coefficient, 1��in��10.
Wavelet matrix transform (WMT), plain wavelet (PW) and wavelet SVD (WS) are performed respectively to compare the anti-noise ability of proposed method, and the results are shown in Fig.3. To ensure a valid comparison, three methods use the same wavelet ��db3�� and same level of decomposition.
According to Fig.3, similarity of PW increases rapidly, and its curve is nearly linear. However, the similarity of WS increases slower than that of PW. Presenting a striking contrast to the above two methods, the slope of similarity of WMT is remarkably small and its curve looks like a horizontal line. The slope of WMT is nearly 1/30 times as large as that of PW and 1/10 times as large as that of WS. So WMT has good anti-noise ability among three methods.
White noise that contains all frequency information is the most regular noise and can greatly affect wavelet coefficient of each level obtained by DOWT. Thus, it is sure that the similarity can be seriously affected by calculating plain Euclid distance since the effect of white noise is added each time. However, because orthogonal basis from SVD of sample time-series sequence is not correlative with white noise, that is to say, the coefficient from projecting white noise into orthogonal basis is very small. Thus the proposed method has a good anti-noise ability.
3.2 Simulation and analysis of sensitivity and accuracy
From the Fourier transform of UBN, the highest power spectral density of UBN is at 19 Hz. UBN is changed a little in order to test the sensitivity of proposed method, and the expression is shown as follow:
Uno(i)=UBN+i?U19 (19)
where U19 is sine wave at 19 Hz; i is variational
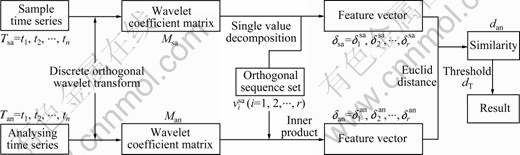
Fig.1 Flow chart of similarity measurement arithmetic
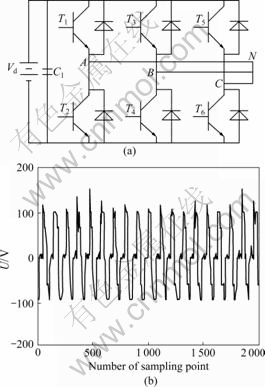
Fig.2 Inverter model and fault wave for similarity measurement: (a) Inverter model; (b) Fault wave
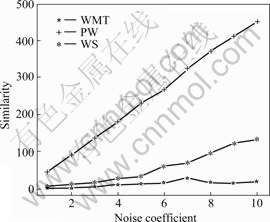
Fig.3 Comparison of anti-noise ability of three methods
coefficient, 1��i��10.
Three methods are used to calculate the similarity and the results are shown in Fig.4.
As shown in Fig.4, three methods all have good sensitivity. The sensitivity of WMT is nearly as same as that of WS, and is 1/3 times of PW, but the anti-noise of proposed method is 30 times of PW as large as that of. Therefore, WMT possesses perfect anti-noise ability and high sensitivity.
The high sensitivity and good anti-noise ability of WMT take advantage of orthogonal basis that is not correlative with white noise, but correlative with the section of time series.
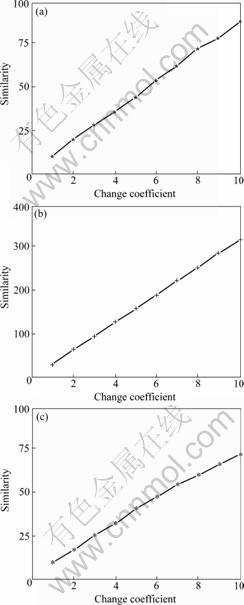
Fig.4 Comparison of sensitivity at different methods: (a) WMT; (b) PW; (c) WS
3.3 Simulation and analysis of accuracy
To compare the accuracy of similarity, the scope of variational coefficient i in expression (19) is changed into 1��i��80. Three methods are carried out to calculate similarity. The results are shown in Fig.5.
As shown in Fig.5, both WMT and PW have good accuracy. However, WS provides the worst result whose curve looks like conic, which means the similarity of WS is not accurate.
The singular value that represents feature of time series very well by SVD of wavelet coefficient matrix can express power distribution of time series, whereas, it is inappropriate for similarity measurement because different matrices have different orthogonal sub-matrix. As shown in Fig.5(c), the curve likes conic. That is, the
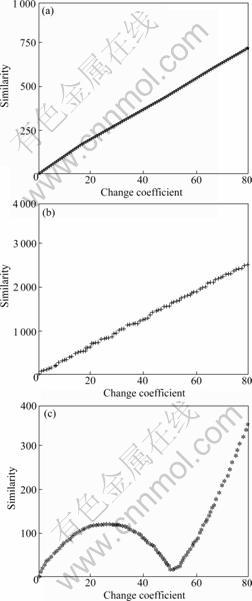
Fig.5 Comparison of accuracy: (a) WMT; (b) PW; (c) WS
signal of at 19 Hz decreases firstly and increases later. Along with the sign of the signal changing from positive to negative at 19 Hz, similarity changes from growth to decline. When the value is as same as former, the similarity is zero. Thus, WS is appropriate for time series, which changes little, and inappropriate for arbitrary time series in large database.
4 Conclusions
(1) The feature vector dimension of proposed method is greatly lower than that of PS, which is very useful to the retrieval of large database.
(2) The anti-noise ability of proposed method is 30 times as large as that of PS and 10 times as large as that of WS.
(3) Although the sensitivity of proposed method is 1/3 times as large as that of PS, the proposed method has remarkable anti-noise ability. Thus, proposed method sacrifices little sensitivity.
(4) The similarity value accuracy of proposed method is markedly higher than that of WS.
(5) WMT is a very efficient and credible method for time-series similarity measurement. It can be used for fault diagnosis based on matching and indexing history fault wave. Moreover, the low dimension of feature vector has potential in retrieval in large databases.
References
[1] AGRAWALl R, FALOUTSOS C, SWAMI A. Efficient similarity search in sequence databases [C]// Proceeding of the 4th International Conference on Foundations of Data Organization and Algorithms. New York: Springer, 1993: 69-84.
[2] RAFIEI D, MENDELZON A. Efficient retrieval of similar time sequences using DFT [C]// Proceedings of the 15th International Conference on Foundation of Data Organizations and Algorithms. New York: Springer, 1998: 249-257.
[3] LI Qiu-dan, CHI Zhong-xian, SUN Rui-chao. A novel similar matching algorithm for time series data [J]. Control and Decision, 2004, 19(8): 915-919. (in Chinese)
[4] FRANKY K C, ADA W, CLEMENT Y. Haar wavelets for efficient similarity search of time-series: With and without time warping [J]. IEEE Transaction on Knowledge and Data Engineering, 2003, 15(3): 686-705.
[5] IVAN P, RANEE J M. Similarity search over time-series data using wavelets [C]// Proceedings of the 18th International Conference on Data Engineering. Washington DC: IEEE Computer Society, 2002: 212-221.
[6] ZHANG Hai-qin, CAI Qing-sheng. Time series similar pattern matching based on wavelet transform [J]. Chinese Journal of Computers, 2003, 26(3): 373-377. (in Chinese)
[7] LIU Jian-guo, LI Zhi-shun, LIU Dong. Features of underwater echo extraction based on SWT and SVD [J]. Acta Acustica, 2006, 31(2): 167-172. (in Chinese)
[8] KONSSTANTINIDES K, YAO K. Statistical analysis of effective singular values in matrix rank determination [J]. IEEE Transaction on Acoustics, Speech and Signal Process, 1988, 36(5): 757-763.
[9] GROUTAGE D, BENNINKK D. Feature sets for non-stationary signals derived from moments of singular value decomposition of Cohen-Posch distributions [J]. IEEE Transactions on Signal Processing, 2006, 48(5): 1498-1503.
[10] MALLAT S. A theory for multi resolution signal decomposition: The wavelet representation [J]. IEEE Transaction on Pattern Analysis and Machine Intelligence, 1989, 11(7): 674-693.
[11] HU Han-hui, YANG Hong, TAN Qing, YI Nian-en. Sintering fan faults diagnosis based on wavelet analysis [J]. Journal of Central South University: Science and Technology, 2007, 38(6): 1139-1173. (in Chinese)
[12] PENG Xiao-qi, SONG Yan-po, TANG Ying, ZHANG Jian-zhi. Approach based on wavelet analysis for detecting and a mending anomalies in dataset [J]. Journal of Central South University of Technology, 2006, 13(5): 491-495.
[13] AKRITAS A G, MALASCHONOK G I. Application of singular value decomposition [J]. Mathematics and Computers in Simulation, 2004, 67(1): 15-31.
[14] VRABIE V D, MARS J I, LACOUME J L. Modified singular value decomposition by means of independent component analysis [J]. Signal Processing, 2004, 84(3): 645-652.
[15] ZHAO Xue-zhi, CHEN Tong-jian, YE Bang-yan. Processing of milling force signal and isolation of state information of milling machine based on singular value decomposition [J]. Chinese Journal of Mechanical Engineering, 2007, 43(6): 169-174. (in Chinese)
(Edited by YANG You-ping)
Foundation item: Projects(60634020, 60904077, 60874069) supported by the National Natural Science Foundation of China; Project(JC200903180555A) supported by the Foundation Project of Shenzhen City Science and Technology Plan of China
Received date: 2008-11-20; Accepted date: 2009-01-14
Corresponding author: HU Zhi-kun, PhD, Associate professor; Tel: +86-731-88836335; E-mail: huzk@mail.csu.edu.cn
