
DOI: 10.11817/j.issn.1672-7207.2017.08.036
�����ÿ������г����������������
�����ܣ��˽�ɽ������ϼ��������
(1. ���Ͻ�ͨ��ѧ ��ͨ����������ѧԺ���Ĵ� �ɶ���610031��
2. ���Ͻ�ͨ��ѧ ȫ����·�г�����ͼ�����з���ѵ���ģ��Ĵ� �ɶ���610031)
ժ Ҫ��
���������ģ���ӡ�������ѵ��ص㣬�����ÿ���ֵļ��ԣ����ÿ���������Ϊ�������������ý��ڴ����㷨������о��ࡣ�ڴ˻����ϣ������г����з����γɵķ������磬�����ͬ����ÿͳ˳����������迹�ļ��㷽��������������ֵ��ÿͳ˳���������ѡ��ģ�ͣ��������Ӧ���������������㷨���Ա�����Ϊʵ�������ݿ����������������ÿ��������������������֤���о��������������·�����ÿͻ���Ϊ6�����ʱ��������õľ���Ч�����ڴ˻����Ͽ�������ȷ����80%���ϡ������ÿ���ֵ��������䷽���ܹ��õ�ȷ���������������Ӷ�Ϊ�г����з����ĵ����ṩ�������ݡ�
�ؼ��ʣ�
�ÿ��г����з����������������ÿ���������ڴ����������г�����������
��ͼ����ţ�U268.6 ���ױ�־�룺A ���±�ţ�1672-7207(2017)08-2245-06
Train service network flow assignment based on passenger classification
WANG Wenxian, PAN Jinshan, L Hongxia, ZHANG Ruiting
Hongxia, ZHANG Ruiting
(1. School of Traffic and Transportation, Southwest Jiaotong University, Chengdu 610031, China;
2. National Railway Train Diagram Research and Training Center, Southwest Jiaotong University, Chengdu 610031, China)
Abstract: According to the railway network multi-flow path optimization problem of passenger train plan. The simplifying method of passenger classification was firstly adopted, which takes individual feature of passengers as analyzing parameter. And affinity propagation algorithm is used for the cluster of passengers. On that basis, service network constructed by train plan is built, together with the network impedance of different passengers. Then the passenger flow assignment model of train service network reflecting passenger category was established, and relevant strengthening algorithm is designed. Taking Baoji-Chengdu Railway as an example, its cluster partitioning on passenger categories and traffic load verification was analyzed according to passenger survey results. Cluster analysis results show that when the railway travel passengers are divided into six categories, the clustering effect is the best, and on this basis, the passenger flow distribution also shows that the accuracy is above 80%. The flow distribution method based on the classification of passenger categories can get accurate flow distribution results, so as to provide a reasonable basis for the adjustment of train operation plan.
Key words: passenger train plan; flow assignment; passenger classification; affinity propagation cluster; train service network
���ÿ��г����з������γɵĸ��������Ͻ��п������䣬�о��ÿ����г��ϵķֲ�״�������ÿ��г����з����������Ż�����������Ҫ���塣GOOSSENS[1-2]��IC��IR��AR 3����·�����ӣ�������ڿ��з�����ѡ���ġ�ģʽ·���������ÿ�·��ѡ����Ϊ�ܻ�Ϊ����Ʒ�����⡣����ǿ��[3]�����ÿͳ��з���Ч�����������ͬ�����г�����������ķ�����˫��滮ģ�ͣ����û����㷨������⡣��������[4]�����˲�ͬ�г��ȼ�����ͬͣվ�������ÿͳ��гɱ���С�Ŀ��������Ŀ������ģ�͡����ڵ�[5]�ڷ���������ͬ���о��롢��ͬ����Լ�������֯���ÿͳ˳�ѡ���Ӱ������ϣ������г����з����������缰�Ľ�F-W�������䷽����١贵�[6]�����ÿͳ��й��̼����г���������Ļ����迹������ںϸĽ���Ⱥ���������Լ�Frank-Wolfe���ع���Ļ������㷨�������о���Ҫͨ���������ֿ�������ģ�ͣ���Ʋ�ͬ����ʽ�㷨ʵ�ֿ����ڲ�ͬ�г��ϵļ��أ����У��ÿͳ˳�ѡ������ǿ��������㷨��Ƶ��������ݡ��������ÿͶԳ˳�������ѡ���������ƫ���ԣ���ͬ���͵��ÿ;��в�ͬ�����۳˳�����������á����ң���·�����ÿ������ڶ࣬�˳�ѡ����Ϊ�ܵ����ڶ����ص�Ӱ�죬��ͬ�ÿ͵ij˳�ѡ�������ͬ��Ҫʵ�ֶ�ÿ���ÿ͵ij˳�ѡ����Ϊ���з�����һ����ģ�Ӵ�����⡣����·�����ÿͽ�����֣������ÿ͵��������Լ��������������������ѡ����Ϊ���ÿͽ��й鲢���Ǽ��г�����������ο��������������Ҫ����֮һ��Ŀǰ���������·�����ÿ��������ͳһ��������С���[7-8]���ݳ�������������ÿ����ԣ����ÿͷ�Ϊʱ���͡������͡�������3�ֻ������ͣ����÷�����Ҫ�������飬������Ϊ���ַ�ʽ��Ч�ʺ;��ȵͣ����ܺܺõط�ӳ���������������[4-6]���乹���Ŀ�������ģ��������ʱ���ֵ����Ϊ�ÿͲ�λ��ֵ����ݣ�������о�����������ʾ����·�����ÿ͵ij���ѡ����Ϊ����ȫ�������ÿ͵�����ˮƽ������ˮƽ���ÿ������������䡢�Ա𡢳���Ŀ���Լ����з�����Դ������˳�ѡ����Ϊ�нϴ�Ĺ���������������ԽϺõؽ����һ���⣬�䱾���Ǹ��ݶ�����ijЩ�����ϵ������ԣ���ģʽ�ռ����������ݼ����ֳ����ɸ�������ķǿ��Ӽ�������û������֪ʶ������£����������ݰ��������ʵ�������ϵ���з���[9]������������ǰ���о��Ļ����ϣ��Ƚ���·�����ÿ���ֵ�������Ϊ���������ı�����Ȼ����ý��ڴ����ķ������ÿͽ��л��֣���Բ�ͬ�����ÿ������˳�������ü��㷽�����ڴ˻����Ͻ��������ÿ�������ij˳�����ѡ�����ѡ��ģ�ͣ�����г����������������䷽�������ͨ��������·ʵ�ʿ������г����з������ݶ�ģ�ͺ��㷨���з�����֤��
1 ��·�ÿ����
��·�ÿ͵����������������䡢�Ա������롢����Ŀ�ġ����з�����Դ�����أ��������Զ���˳�ѡ���������ϴ��Ӱ��[3]�����������Խ���������������������Ϊ�����ÿ;�����������Բ�����
���ڴ����㷨(���AP)����FREY��[10]�������һ�־����㷨�����䲻�ܳ�ʼ�������ѡ������ƣ���������Ϊ�ȶ��������ڴ������ģ��������ʱ�����ٶȸ��죬��������ȷ���ʱ���ѡ��AP�㷨�Գ����ÿͽ�����֡�
AP�㷨��ԭ����1) �����ݼ�������N���ÿ���������Ϊ��ѡ���������Ϊÿ���ÿͽ����������ÿ͵������̶ȵ���Ϣ��������2���ÿ�xi��xk֮������ƶȣ��洢��N��N���ƶȾ���S�С�2) ��s(i��k)��ʾ�ÿ�xk�ڶ��̶����ʺ���Ϊ�ÿ�xi�����������ʼ���������ÿ�������ѡ�г�Ϊ������Ŀ�������ͬ�����趨����s(k��k)Ϊ��ֵͬp��3) �㷨������2����Ҫ����Ϣ�����������ŶȾ���R�Ϳ��öȾ���A��r(i��k)�Ǵ�xiָ��xk��������ʾxk�ʺ���Ϊxi��������Ĵ����̶ȣ�a(i��k)�Ǵ�xkָ��xi��������ʾxiѡ��xk��Ϊ������ĺ��ʳ̶ȡ����������ÿ�����xi���������������Ŀ��Ŷ�r(i��k)�Ϳ��ö�a(i��k)֮�ͣ�������֮����������xkΪ�������AP�㷨�ĵ���Ϊ����2����Ϣ��������µĹ��̡�
�㷨�����������¡�
Step 1 ��ʼ����
�����������ƶȾ���Ԫ��s(i��k)���������ŷʽ����Ϊ��ȣ���
 (1)
(1)
���öԽ���Ԫ��s(i��k)Ϊ��ͬ����������ֵ��
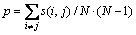 (2)
(2)
���ÿ��ŶȾ���R�Ϳ��öȾ���A�ij�ʼֵΪ0��
Step 2 ������
1) ���¿��öȺͿ��Ŷȡ����ŶȾ���Ԫ��r(i��k)���¼��㹫ʽΪ
 (3)
(3)
���öȾ���Ԫ��a(i��k)���¼��㹫ʽΪ
 (4)
(4)
2) ��������������Ŷ�����ö�֮�ͣ�����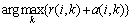 �ҵ�ÿ��������������������
�ҵ�ÿ��������������������
Step 3 ��������
�ж���Ϣ���������Ƿ�ﵽ���õ������������������㷨��ֹ������Step 2��
2 �г��������繹�����迹ȷ��
2.1 �г��������繹��
������·������·���˽ṹͼG=(V��E)�Լ������ÿ��г�L(���У�VΪ����վ����EΪ���ӿ���վ�����μ�)��ͼ1��ʾΪ6����վ��5�����乹�ɵ���·��·����Ӧ���ÿ��г����з�����
ͼ2��ʾΪͼ1��ʾ�����γɵĸ����г��������� ��������ڵ�V�ͷ���E����ɡ�
��������ڵ�V�ͷ���E����ɡ�
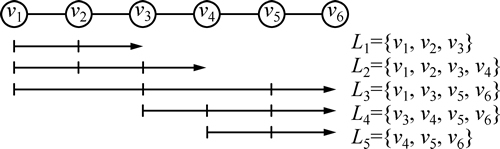
ͼ1 ��·��·�����г����з���ʾ��ͼ
Fig. 1 Railway line and train plan

ͼ2 �����г���������ʾ��ͼ
Fig. 2 Complex train service network
�������漰�ķ������������ÿ��г����з����γɣ����ڲ�ͬ�����ÿͳ˳�ѡ����������硣�ڽ��п�������ʱ�����ݽ������ÿͳ˳���ʽ����(�绻�˴����ȹ���)����С�ÿͳ˳���ѡ����������Χ���Ӷ���������Ĺ�ģ��
2.2 �����迹ȷ��
��ͬ���͵��ÿ;��в�ͬ�����۳˳�����������ã�����OD�������ÿ���������ΪN���г����������е�ijOD��r-s��ĵ�n���ÿͶ��ԣ������ѡ��ı�ѡ�˳���������Ϊ ����ѡ���k�ֳ˳������Ĺ������Ϊ
����ѡ���k�ֳ˳������Ĺ������Ϊ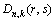 ����
����
 (5)
(5)
ʽ�У�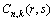 ΪOD��r-s���n���ÿͶԵ�k�ֳ˳��������з��õ�ȷ���
ΪOD��r-s���n���ÿͶԵ�k�ֳ˳��������з��õ�ȷ���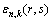 Ϊ��Ӧ���������
Ϊ��Ӧ���������
�����о��г˳������Ĺ����������Ʊ��֧��������ʱ���Լ��г����ʶȣ���
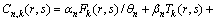
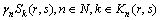 (6)
(6)
ʽ�У���n����n�ͦ�nΪ��n���ÿ͵Ĺ������ָ��Ȩ�أ� ��
��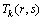 ��
��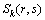 Ϊ��k�ֳ˳���ʽ��Ʊ��֧��������ʱ�䡢�Լ��˳����ʶȣ�
Ϊ��k�ֳ˳���ʽ��Ʊ��֧��������ʱ�䡢�Լ��˳����ʶȣ�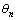 Ϊ��n���ÿ͵�ƽ��ʱ���ֵ��
Ϊ��n���ÿ͵�ƽ��ʱ���ֵ��
����ʵ�ʳ˳��У��ÿ������ῼ�dz����г���ʼ���յ�ʱ���ϵķ���̶ȣ������ڸ�����û�����٣��������뷽��ϵ���ĸ����ʽ(6)�Ľ����£�
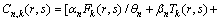
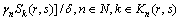 (7)
(7)
ʽ�У���Ϊ�ÿͳ˳�����ϵ������ȡֵ��������[11]�������õ��ÿ�SP�ʾ�����ͳ�Ƶó���
���ʶ���������[12]�ijɹ�����������ƣ�ͻָ�ʱ����������
 (8)
(8)
ʽ�У�TmaxΪ�ָ�ƣ��������ʱ�������ͨ��ȡ14~15 h����kΪѡ��k�ֳ˳���ʽ��ƣ�ͻָ�ʱ�����Сֵ(���˳�ʱ��Ϊ0ʱ��ƣ�ͻָ�ʱ��)��fkΪ��λ����ʱ���ƣ�ͻָ�ʱ�䡣
����ȡֵ���1��ʾ��
��1 ��k�� k��ȡֵ
k��ȡֵ
Table 1 Values of ��k and k
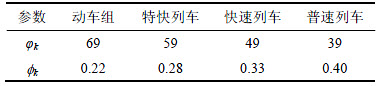
3 �˳�����ѡ��ģ�����㷨
3.1 ��ѡ�˳�������ȷ��
�����г�ʱ�̱���������·����Ϣ����ȷ���ÿͳ˳���������ʱ�������г�ʱ�̱���վ�����еõ�������е��ÿͳ˳�������Ϊ���ڼ��㣬ȡ��˴���Ϊ1��
ijOD��r-s���ԣ��������г�����L={li|i=1��2������N}�У��ֱ��ҳ�����rվ��sվ���г����ϣ����ֱ��ΪLr��Ls��
ֱ�﷽�����˼·����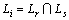 �����г�
�����г� ����rվ��sվ�����г�li��rվ�ķ���ʱ��trf(li)���ڵ���sվ��ʱ��tsd(li)����trf(li)��tsd(li)�����rվ�����г�li�ɵ���sվ��
����rվ��sվ�����г�li��rվ�ķ���ʱ��trf(li)���ڵ���sվ��ʱ��tsd(li)����trf(li)��tsd(li)�����rվ�����г�li�ɵ���sվ��
���˷������˼·����Lj=Lr-Ls�����г�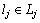 ֻ����rվ����Lk=Ls-Lr�����г�
ֻ����rվ����Lk=Ls-Lr�����г�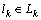 ֻ����sվ�����г�lj��rվ�Ժ�ij�վ���г�lk��sվ��ǰ�ij�վ���Ի��ˣ���
ֻ����sվ�����г�lj��rվ�Ժ�ij�վ���г�lk��sվ��ǰ�ij�վ���Ի��ˣ��� ����
���� ��
��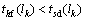 �����ʾ��rվ�����г�lj��hվ���Ի����г�lk����sվ���Ӷ���һ�����˵ij��г˳�������
�����ʾ��rվ�����г�lj��hվ���Ի����г�lk����sվ���Ӷ���һ�����˵ij��г˳�������
�ٶ�������������е�����������������ҷ���Gumbel�ֲ�����ijOD���n���ÿ�ѡ���k�ֳ˳������ĸ���Ϊ
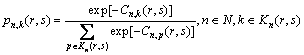 (9)
(9)
3.2 �������������㷨���
���ݸ����ÿ͵ij˳�������ã���Logitģ�ͼ�����Ը��ֳ˳�������ѡ����������г����з����γɵij˳������������ν����������أ�Ȼ����ݳ˳������뿪���г��Ĺ����Խ��������ۼӣ��õ��ÿ��ڸ��г��ϵ��������������������������¡�
����1 ����AP�㷨������OD���ÿͽ�����֣�OD��r-s���n���ÿ�����Ϊ ��
��
����2 ȷ���г�����������ÿ��OD��r-s��ı�ѡ�˳���������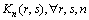 ��
��
����3 ����ʽ(7)����OD��r-s��ÿ���ÿ͵ĸ���ѡ�˳��������������
����4 ����ʽ(9)����OD��r-s�����ѡ�˳�������ѡ����� ��
��
����5 ������ÿ�ֱ�ѡ���������������䣬����ʽΪ
 (10)
(10)
����6 �жϸ�OD��ÿ���ÿͶ��Ƿ���ɷ��䣬����ת����7������ת����2��
����7 ���� ������˳��������г����������㹫ʽ���£�
������˳��������г����������㹫ʽ���£�
 (11)
(11)
 (12)
(12)
���У� Ϊ0-1��������ʾ�г�����������OD��r-s��ij˳�����k���г�a�Ĺ���ϵ������r-s��ij˳�����k���г�a�γɣ�ȡֵΪ1������Ϊ0��
Ϊ0-1��������ʾ�г�����������OD��r-s��ij˳�����k���г�a�Ĺ���ϵ������r-s��ij˳�����k���г�a�γɣ�ȡֵΪ1������Ϊ0��
4 ʵ����֤��������
��2014��ױ����߿��з���������ͳ������Ϊ�����������ÿ��г����з����Ŀ������䰸����������ؿ�����������·�ܹ�˾�г�����ͼ�����з���ѵ���ĵ������á�Ϊ������������·��������С��վ������鲢����������վ����վ�㣬����10�������ڵ㡣
��·��վ�ı��Ϊ1~10������Ϊ�ɶ������������������͡���Ԫ����ƽ�ء����������ء����ء��������������Ϲ���3���г�ʼ���յ���վ���ֱ��dzɶ�����Ԫ�������������г������������������������ľ˹����³ľ�롢������������������֣�ݡ����ݡ��Ϻ������������ݡ����ݡ�����ൺ�����С����ͺ��ء�̫ԭ�ȡ����з�������32�Ա��������ÿ��г������У��Ǽʿ����г�8��/d���ؿ��г�2��/d�������г�19��/d�������г�3��/d�����忪�з������2��ʾ�������ÿ��г������������Ʊ�ۡ�����ʱ�䡢����ʱ�䡢�г���Ա������12 306��·��Ʊϵͳ��ѯ��
��2 ������������
Table 2 Line plan of Baoji-Chengdu railway

����2.2����ַ���������AP���෨���ÿͽ�����֡�AP�㷨������������ʱ��������־���������Щ������в�ͬ�ľ�������������������Ч�����ۡ�������Ч�������Dz������ָ����ȷ�������㷨�������ĸ�������Ϊ���ţ����Ӧ�ľ�����Ŀ��Ϊ��Ѿ����������õ���Ѿ�����Ч��ָ��Ϊ��Calinski-Harabaszָ�ꡢHartiganָ���In-Group Proportionָ��ȣ�����㷽��������[13]��
��AP�㷨��õľ��������ֱ���������3��ָ����м��㣬������3��ʾ���ɱ�3��֪��CHָ�ꡢHartָ���Լ�IGPָ��õ�����Ѿ�������Ϊ6�������ʾ�ͳ�ƽ������ͬ����ÿͶԳ˳�����ָ������ص�����Ȩ���Լ�ƽ��ʱ���ֵ���4��ʾ��
����Matlab����������4.2�����������㷨�����г����������������䣬�õ��г��ڸ��������������������5��ʾ�����㹲��ʱ25.7 s��
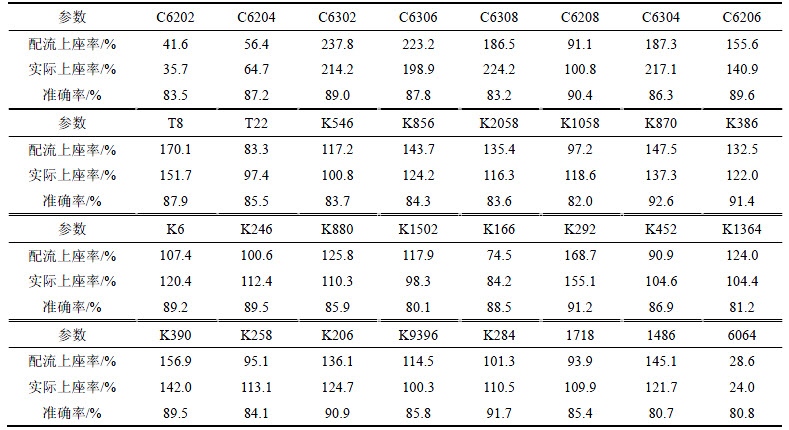
�ӱ�4���Է��֣����ݻ����ÿ������г��������������õ����г������ʵ�ȷ�ʽϸߣ�����80%���ϡ����ݱ�5������������Զ��г����з������е��������������ʽϵ��г����ɲ��õ����г�ͣվ�����IJ��ԣ����������ʹ����г������ڸó�����ʱ�����ڼӿ����г����Ӷ����г�������������ۺ��Ż������磬����C6302��C6304��C630��C6308�����������ʱ������8:30��12:30���ÿͷ���ϵ���ߣ����ÿͼ���ѡ���⼸���г�������ɲ�ȡ�ӿ���ͬ�������εijǼ��г����Է�̯��������6064�г��������ʲ����룬����ȡ����ͬʱ����1486�ڻ�������ص�ͣ��վ�㣬������ԭ6064�г��Ŀ�����
��3 ��ͬ����������Ч��ָ��ֵ
Table 3 Validity index of different clusters

��4 ��ͬ����ÿ͵ij˳�ѡ�����
Table 4 Boarding choice parameters of different travelers

��5 �����������
Table 5 Result of train flow assignment
5 ����
1) �ڼȶ��ÿ��г����з������γɵķ��������ϣ��Կ�������������о��������䡢�Ա����������������Ϊ���Բ��������ý��ڴ����㷨����·�ÿͽ��о��������ͨ��CH��Hart�Լ�IGPָ��ȷ������Ѿ��������ڴ˻����ϣ�����˻��ڲ�ͬ����ÿ͵������迹ֵ���㷽�����������ֲ�ͬ�������Ŀ�������ģ�ͣ����Ա�ѡ�˳������Լ��������ع��������ơ�
2) ��2014�걦����Ϊʵ�����п����������㣬�����ʾ�㷨���ڽ϶�ʱ���ڻ�ý�����Ҹ��г����������ʵ�ȷ�ʾ���80%���ϡ�
3) ��������Ŀ����������۷���Ϊ��·���˹������Ÿ����ÿͳ��������г����з���������Ӧ�Ե����ṩ�������ݡ�
�ο����ף�
[1] GOOSSENS W. Models and algorithms for railway line planning problems[D]. Maastricht, Netherlands: University of Maastricht, 2004: 1-46.
[2] GOOSSENS W, HOESEL S, KROON L. On solving multi-type railway line planning problems[J]. European Journal of Operational Research, 2006, 168(2): 403-424.
[3] ����ǿ, �ź���, ë����, ��. ����ר���ÿ��г����з����Ķ�Ŀ��˫��滮ģ��[J]. ����ѧ��, 2006, 28(5): 6-10.
HE Yuqiang, ZHANG Haozhi, MAO Baohua, et al. Multi objective Bi-level programming model of making train working plan for passenger-only line[J]. Journal of the China Railway Society, 2006, 28(5): 6-10.
[4] ������, �Ƽ�, ����Ԩ. ����ר���ÿ��г����з����Ŀ������䷽��[J]. ���Ͻ�ͨ��ѧѧ��, 2006, 41(5): 571-574.
ZENG Kaiming, HUANG Jian, PENG Qiyuan. Research on assignment of passenger train plan for dedicated passenger traffic lines[J]. Journal of Southwest Jiaotong University, 2006, 41(5): 571-574.
[5] ����, ��С��, ١�, ��. �����ÿ��г����з����Ŀ������䷽���о�[J]. ��ͨ����ϵͳ��������Ϣ, 2011, 11(3): 87-92.
NIE Lei, HU Xiaofeng, TONG Lu, et al. Research of passenger flow assignment based on passenger train plan[J]. Journal of Transportation Systems Engineering and Information Technology, 2011, 11(3): 87-92.
[6] ١�, ����, ������. ���ڸ����г���������Ŀ������䷽���о�[J]. ����ѧ��, 2012, 34(10): 7-15.
TONG Lu, NIE Lei, FU Huiling. Research on passenger flow assignment method based on complex train service network[J]. Journal of the China Railway Society, 2012, 34(10): 7-15.
[7] ��С��. �����·���˷������ж��ο������似���о�[D]. ����: ������ͨ��ѧ��ͨ����ѧԺ, 2012: 28-34.
HU Xiaofeng. Research on technologies of mutli-level passenger flow assignment in the mixed-train service network[D]. Beijing: Beijing Jiaotong University, 2012: 28-34.
[8] ����. ������·���ο������䷽����ϵͳ���[D]. ����: ������ͨ��ѧ��ͨ����ѧԺ, 2013: 28-32.
LIU Jian. Multilevel passenger flow assignment method in high speed railways and the computer system design[D]. Beijing: Beijing Jiaotong University, 2013: 28-32.
[9] ����Ⱥ. �ִ�ͳ�Ʒ���������Ӧ��[M]. ����: �й������ѧ������, 1999: 215-216.
HE Xiaoqun. Modern statistical methods and applications[M]. Beijing: Chinese People University Press, 1999: 215-216.
[10] FREY B J, DUECK D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976.
[11] ʷ��, ������, ����. ��·�ÿͳ˳�ѡ����Ϊ����Ч��[J]. �й�������ѧ, 2007, 28(6): 117-121.
SHI Feng, DENG Lianbo, HUO Liang. Boarding choice behavior and its utility of railway passengers[J]. China Railway Science, 2007, 28(6): 117-121.
[12] ���ŷ�, ������, ������, ��. ��Ŀ����·�ÿͳ˳������Ż�ģ�ͼ��㷨�о�[J]. ��ͨ����ϵͳ��������Ϣ, 2013, 13(5): 72-78.
YANG Xinfeng, LIU Lanfen, LI Yinzhen, et al. Route selection for railway passengers: a multi-objective model and optimization algorithm[J]. Journal of Transportation Systems Engineering and Information Technology, 2013, 13(5): 72-78.
[13] ������, ����Դ, ������. ���ڽ��ڴ����㷨����Ѿ�����ȷ�������Ƚ��о�[J]. �������ѧ, 2011, 38(2): 225-228.
ZHOU Shibing, XU Zhenyuan, TANG Xuqing. Comparative study on method for determining optimal number of clusters based on affinity propagation clustering[J]. Computer Science, 2011, 38(2): 225-228.
(�༭ �°���)
�ո����ڣ�2016-09-30�������ڣ�2016-12-02
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61273242��61403317��71403225); �й���·�ܹ�˾�Ƽ��о��ƻ���Ŀ(2014X004-D��2015X008-B)(Projects(61273242, 61403317, 71403225) supported by the National Natural Science Foundation of China; Projects(2014X004-D, 2015X008-B) supported by Science and Technology Plan of China Railway Corporation)
ͨ�����ߣ������ܣ���ʿ�����½�ͨ����滮������о���E-mail��wwx530@163.com
ժҪ������г����������������ģ���ӡ�������ѵ��ص㣬�����ÿ���ֵļ��ԣ����ÿ���������Ϊ�������������ý��ڴ����㷨������о��ࡣ�ڴ˻����ϣ������г����з����γɵķ������磬�����ͬ����ÿͳ˳����������迹�ļ��㷽��������������ֵ��ÿͳ˳���������ѡ��ģ�ͣ��������Ӧ���������������㷨���Ա�����Ϊʵ�������ݿ����������������ÿ��������������������֤���о��������������·�����ÿͻ���Ϊ6�����ʱ��������õľ���Ч�����ڴ˻����Ͽ�������ȷ����80%���ϡ������ÿ���ֵ��������䷽���ܹ��õ�ȷ���������������Ӷ�Ϊ�г����з����ĵ����ṩ�������ݡ�
[3] ����ǿ, �ź���, ë����, ��. ����ר���ÿ��г����з����Ķ�Ŀ��˫��滮ģ��[J]. ����ѧ��, 2006, 28(5): 6-10.
[4] ������, �Ƽ�, ����Ԩ. ����ר���ÿ��г����з����Ŀ������䷽��[J]. ���Ͻ�ͨ��ѧѧ��, 2006, 41(5): 571-574.
[5] ����, ��С��, ١�, ��. �����ÿ��г����з����Ŀ������䷽���о�[J]. ��ͨ����ϵͳ��������Ϣ, 2011, 11(3): 87-92.
[6] ١�, ����, ������. ���ڸ����г���������Ŀ������䷽���о�[J]. ����ѧ��, 2012, 34(10): 7-15.
[7] ��С��. �����·���˷������ж��ο������似���о�[D]. ����: ������ͨ��ѧ��ͨ����ѧԺ, 2012: 28-34.
[8] ����. ������·���ο������䷽����ϵͳ���[D]. ����: ������ͨ��ѧ��ͨ����ѧԺ, 2013: 28-32.
[9] ����Ⱥ. �ִ�ͳ�Ʒ���������Ӧ��[M]. ����: �й������ѧ������, 1999: 215-216.
[11] ʷ��, ������, ����. ��·�ÿͳ˳�ѡ����Ϊ����Ч��[J]. �й�������ѧ, 2007, 28(6): 117-121.
[13] ������, ����Դ, ������. ���ڽ��ڴ����㷨����Ѿ�����ȷ�������Ƚ��о�[J]. �������ѧ, 2011, 38(2): 225-228.
