
J. Cent. South Univ. Technol. (2011) 18: 1473-1486
DOI: 10.1007/s11771-011-0863-7![]()
Simultaneous scheduling of machines and automated guided vehicles in flexible manufacturing systems using genetic algorithms
I. A. Chaudhry, S. Mahmood, M. Shami
National University of Sciences & Technology (NUST), Islamabad, PAKISTAN
? Central South University Press and Springer-Verlag Berlin Heidelberg 2011
Abstract:
The problem of simultaneous scheduling of machines and vehicles in flexible manufacturing system (FMS) was addressed. A spreadsheet based genetic algorithm (GA) approach was presented to solve the problem. A domain independent general purpose GA was used, which was an add-in to the spreadsheet software. An adaptation of the propritary GA software was demonstrated to the problem of minimizing the total completion time or makespan for simultaneous scheduling of machines and vehicles in flexible manufacturing systems. Computational results are presented for a benchmark with 82 test problems, which have been constructed by other researchers. The achieved results are comparable to the previous approaches. The proposed approach can be also applied to other problems or objective functions without changing the GA routine or the spreadsheet model.
Key words:
1 Introduction
Production scheduling is concerned with the efficient allocation of resources over time for manufacturing. Scheduling problems arise whenever a common and finite set of resources (labour, material and equipment) must be used to make a variety of different products during the same period of time. The objective of scheduling is to find a way to assign and sequence the use of these shared resources such that production constraints are satisfied and production costs are minimised.
Scheduling in the manufacturing environment can be defined as the process of deciding what happens when and where. A task (what) occupies a dedicated resource exclusively (where) for some period of time (when). Any process that defines a subset of what��when��where can be said to ��do scheduling�� [1].
Scheduling is difficult for a variety of reasons [2]:
1) Desirability: difficulty in determining when a good schedule has been achieved, given that different people, agencies, etc, have different goals and priorities;
2) Stochasticity: unpredictability in the domain that makes predictive scheduling problematical;
3) Tractability: computational complexity of the domain, that is, the ��size�� of the scheduling problem;
4) Decidability: it may be provably impossible to find an algorithm that produces an optimal schedule, depending on the definition of optimality chosen.
In recent years, there has been a growing interest in the implementation of flexible manufacturing systems (FMS) that are manufacturing systems consisting of a group of numerically controlled (NC) machines connected by an automated material handling system under computer control and set-up to process a wide variety of different parts with low to medium demand volume [3].
FMS can also be viewed as an automated job shop. However, because of its integrated nature, a scheduling task for an FMS requires additional consideration of tools, fixtures, automated guided vehicles (AGVs), pallets, etc. Since machines and material handling systems are also more versatile, there is a large number of alternative operations and material handling routes to be considered in the scheduling decision. For a thorough review of the classification, modelling, planning and scheduling of FMS and various models dealing with them can be found in Refs.[4-9].
In scheduling theory, it is often assumed that the time taken to move jobs from one machine to another is negligible. But in many real life situations, this movement can have a significant effect on the completion time of the jobs, thus adding a parameter to the optimisation function. This work looks at the situation where the job travelling time between machines is taken into account. We, therefore, present a spreadsheet based domain independent genetic algorithm (GA) approach for the simultaneous scheduling of machines and AGVs in a FMS. A proprietary software has been used for the same purpose.
The studied flexible manufacturing system is a job shop where the jobs have to be transported between the machines by automated guided vehicles. The FMS consists of a set of different machines performing different tasks and a set of identical AGVs performing the material handling and transportation tasks between the machines. All the unprocessed jobs and AGVs are assumed to be located at the load/unload (L/U) station at the beginning of the schedule.
2 Previous research work
Most of the researchers have addressed the machine and vehicle scheduling as two independent problems. However, only a few researchers have emphasized the importance of simultaneous scheduling of jobs and automated guided vehicles (AGVs).
RAMAN et al [10] formulated the problem as an integer programming problem and a solution procedure based on the concepts of project scheduling under resource constraints. They assumed that the vehicle always returns to the load/unload station after transferring a load, which reduces the flexibility of the AGV and influences the overall schedule length.
ULUSOY and BILGE [11] attempted to make scheduling of AGVs an integral part of overall scheduling activity in an FMS environment. They decomposed the problem into two sub-problems, i.e. machine scheduling problem and vehicle scheduling problem. At each iteration, a new machine schedule, generated by a heuristic procedure, was investigated for its feasibility to the vehicle scheduling sub-problem. The combined machine and material handling system scheduling problem was formulated as a non-linear mixed integer programming (MIP) model.
BILGE and ULUSOY [12] proposed an iterative method based on the decomposition of the master problem into two sub-problems i.e., machine scheduling problem and vehicle scheduling problem. They developed a heuristic, named ��sliding time window (STW)��, to solve the simultaneous off-line scheduling of machines and material handling in FMS. They provided a MIP model to formulate the problem. The MIP heuristic was tested on 82 test problems.
ULUSOY et al [13] proposed a genetic algorithm for this problem. In their approach, the chromosome represents both the operation number and AGV assignment. They developed special genetic operators for this purpose. The computational result shows that the GA developed is an effective solution method for this problem and performs better than the previous approach, i.e., ��sliding time window��. For brevity, the GA coding of ULUSOY et al [13] is called UGA.
ABDELMAGUID et al [14] developed a hybrid genetic algorithm for the problem. The hybrid GA is composed of GA and a heuristic. The GA is used to address the scheduling of the jobs, while the vehicle assignment is handled by a heuristic called vehicle assignment algorithm. They applied their algorithm to a set of 82 test problems, and the comparison of results indicates the superior performance of the developed coding. For computation analysis, the GA coding of ABDELMAGUID et al [14] would be represented as GAA.
MURAYAMA and KAWATA [15-16] also addressed the problem of simultaneous scheduling of machines and AGVs. However, they assumed that AGVs can carry multiple load instead of single load at a time. In both the cases, the genetic algorithms for the problem were applied. MURAYAMA and KAWATA [17] proposed a local search method for simultaneous scheduling of machines and multiple-load automated guided vehicles. They introduced a representation of solutions and a neighbourhood operation considering operation sequence and AGV assignment.
JERALD et al [18] proposed an adaptive GA (AGA) and ants colony optimization (ACO) for a 16-machine and 43-part problem. Their objective function is a combined objective of minimizing penalty cost and minimizing machine idle time. They also examined the speed of the AGV and found that AGA is superior to the ACO algorithm.
JERALD et al [19] compared a GA and an adaptive GA (AGA). They showed that AGA performs better than the GA. JERALD et al [20] considered the scheduling of parts and AS/RS in an FMS using genetic algorithm. They used GA to find out the minimum movement of shuttle for the optimum storage allocation of materials in AS/RS.
MURAYAMA and KAWATA [21] proposed a simulated annealing method for the simultaneous scheduling problems of machines and multiple-load AGVs to obtain relatively good solutions for a short time. The proposed method is based on a local search method for job shop scheduling problems. They provided a new representation of solutions and neighborhood operation in order to consider the transportation by multiple-load automated guided vehicles.
REDDY and RAO [22] addressed multi-objective scheduling problem for simultaneous scheduling of machines and vehicles. They used hybrid multi-objective GA to solve the problem, and considered the combined minimization of makespan, mean flow time and mean tardiness objectives. From now onwards, the GA coding of REDDY and RAO [22] will be represented as PGA.
DEROUSSI et al [23] also addressed the problem of simultaneous scheduling of machines and vehicles in FMS. They proposed a new solution representation based on vehicles rather than machines, whereby each solution can thus be evaluated using a discrete event approach. An efficient neighbouring system is then implemented into three different meta-heuristics, namely iterated local search, simulated annealing and their hybridisation. Their results were compared with previous studies and show the effectiveness of the presented approach.
3 Problem and assumptions
Simultaneous scheduling of the machines and the material handling system in an FMS can be defined as follows: Given the FMS described later, determine the starting and completion times of operations for each job and the trips between workstations together with the vehicle assignment according to the objective of minimising the makespan, Cmax.
It is assumed that all the design and set-up issues for the FMS as suggested by STECKE [24] have already been resolved. Four layout configurations as shown in Fig.1 and ten job sets are used. The number of automated guided vehicles (AGVs) in the system is two. The types and number of machines are known. There is a sufficient input/output buffer space at each machine. Machine loading has been done i.e., allocation of tools to machines and the assignment of operations to machines. Operations are not pre-emptive. Ready times of all jobs are known.
The load/unload (L/U) station serves as a distribution centre for parts not yet processed and as a collection centre for parts finished. All vehicles start from the L/U station initially. There is a sufficient input/output buffer space at the L/U station. Trips follow the shortest path between two points and occur either between two machines or between a machine and the L/U station. Pre-emption of the trips is not allowed. The trips are called loaded or deadheading (empty) trips depending on whether or not a part is carried during that trip, respectively. The duration of deadheading trips is sequence-dependent and is not known until the vehicle route is specified. Processing, set-up, loading, unloading and travel times are available and deterministic.
Vehicles move along predetermined shortest paths, with the assumption of no delay due to the congestion. As a result of this assumption, it would follow that the guide paths on segments can be uni-directional or bi-directional. However, on busy segments, two uni-directional paths should be used instead of a bi-directional guide path so that traffic congestion does not reach a critical level leading to the violation of this assumption. Furthermore, such issues as traffic control, machine failure or downtime, scraps, rework and vehicle dispatches for battery changes are ignored here and left as issues to be considered during real time control.
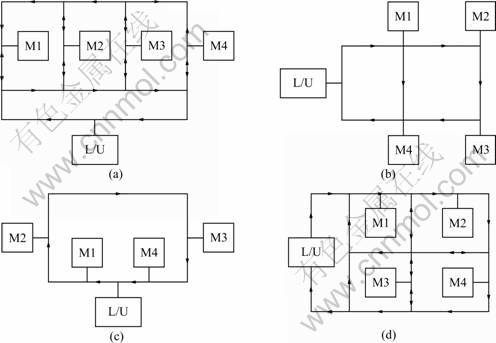
Fig.1 Layout configurations used for examples: (a) LAYOUT 1; (b) LAYOUT 2; (c) LAYOUT 3; (d) LAYOUT 4
The following constraints are to be satisfied by the
AGV travel when scheduling these FMSs:
1) For each operation j, there is a corresponding loaded trip whose destination is the machine where operation j is to be performed and its origin is either the machine where the operation preceding j is assigned or the L/U station;
2) Operation j of job I can start only after the trip to load has been completed;
3) An AGV trip cannot start before the maximum of the completion time of the previous operation of a job and the deadheading trip of the AGV to the job is obtained.
The AGV travel times and the machine allocation and operation times for the jobs are given in Appendix A.
4 Genetic algorithm
GA is one of the problem solving systems based on the principles of evolution and hereditary, and each system starts with an initial set of random solutions and uses a process similar to biological evolution to improve upon them that encourages the survival of the fittest. The best overall solution becomes the candidate solution to the problem.
A detailed introduction to GA can be found in Ref.[25]. One of the earliest reported applications of GA to scheduling was reported by DAVIS [26]. There is a vast literature available for GA application in production scheduling. A review of some of the recent GA applications in scheduling is given by CHAUDHRY [27] and CHAUDHRY and DRAKE [28-29].
The work presented here was carried out using the Microsoft? Excel? spreadsheet and an add-in to provide the GA. This add-in is called Evolver? and is developed and supplied by PALISADE [30]. It implements the sequence optimisation GA and acts upon tables of the form presented in the examples. The use of this proprietary software demonstrates how simple it is to implement the GA approach to schedule optimisation and also enables the immediate implementation, by any reader, of the methods presented here. This is a key aspect of this work.
Evolver? has been used for various problems such as construction of double sampling s-control charts [31], decision support systems [32-33], resource optimization [34], maintenance [35-36], scheduling [27-29, 37-43], site pre-cast yard layout arrangement [44] and to devise optimal integration test orders in object-oriented systems.
The main advantage of the proposed GA approach is that it is a general purpose domain independent, meaning that only the spreadsheet model needs to be changed to suit a particular manufacturing environment rather than the whole GA routine itself. Furthermore, the objective function can be changed without actually changing the model or the GA routine. The presentation of information to user in the form of well-defined spreadsheet tables makes it easier for the user to carry out what-if analysis. Also, the use of spreadsheets is welcomed by production managers as they are used to this kind of tools. We have to take into account that the scheduling solutions provided will be used by non-skilled workers.
The model of a particular scheduling environment, i.e. flow shop or job shop, is built in EXCEL? using the built-in functions of spreadsheet. After the building of the model, the GA is run to optimize the schedule given an objective function.
The schematic in Fig.2 illustrates the integration of the GA with the spreadsheet.
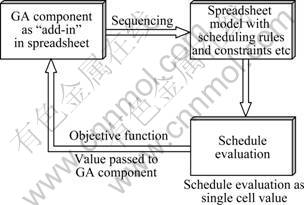
Fig.2 Integration of GA and spreadsheet
The fitness/objective function value is passed on to the GA component as a single cell value for the evaluation of the schedule. After evaluation, if the schedule is found to have better fitness as compared with the other organisms in the population, it is kept in the population, thus replacing the worst performing member of the population.
We have found that a key advantage of a GA is that it provides a ��general purpose�� solution to the scheduling problem, with the peculiarities of any particular example being accounted for in the fitness function without disturbing the logic of the standard optimisation (GA) routine. This means that it is a relatively straight forward and simple matter to adapt the software implementation of the method to meet the needs of particular applications.
4.1 Chromosome representation
In this work, permutation representation is used, i.e. a list of jobs is itself taken as a chromosome. For example, if in a flow shop scenario there are 5 jobs {A- B-C-D-E}, one chromosome according to permutation representation can be {A-B-C-E-D}, while another could be {D-E-C-A-B}.
On the other hand, in a job shop scenario, if there are 2 jobs, each having 3 operations, then the chromosome representation keeping in view the technological constraints (i.e., operation 2 of job 1 cannot be done unless operation 1 has finished and so on) could be given in Fig.3.
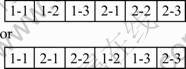
Fig.3 Chromosome representation in job shop scenario
It may be noted here that the chromosome representation caters for only the jobs and is independent of the AGV schedule. The AGV schedule is generated using the Microsoft Excel built in functions. As there are two AGVs in the system which ever AGV is free at a given time is assigned to the job which is free, all these movements are catered for in the spreadsheet model and not in the chromosome. As a result, the GA has to manipulate the job sequence only.
While adapting the GA for simultaneous scheduling of machines and AGVs scenario, the only modification made to the basic spreadsheet model is for the calculation of travel times and AGV assignment. The model works as follows: at the completion of an operation Oi for each job, it is determined which AGV would take the least time to take the job to its next machine depending upon the previous location of the AGV. This AGV is then selected to transport the job. In the same way, all the jobs and the two AGVs are scheduled.
4.2 Reproduction/selection
Unlike many of the reported GAs, which use generational replacement techniques where an entire set of parents is replaced by their children, Evolver uses steady-state reproduction as used in GENITOR GA [45]. The advantage of using steady-state reproduction is that all the genes are not lost as is the case in generational replacement, where after replacement many of the best individuals may not produce at all and their genes may be lost. Steady-state reproduction is a better model of what happens in longer-lived species in nature [45]. This allows parents to nurture and teach their offspring, but also gives rise to competition between them. The steady-state algorithm is described as follows:
Repeat
Create n children through reproduction
Evaluate and insert the children into the population
Delete the n members of the population that are least fit
Until convergence criteria met
In Evolver only one organism (n=1) is replaced at each iteration, rather than an entire ��generation�� being replaced, as is the case in generational replacement. The value of the objective function for a particular chromosome is a measure of its fitness. In this application, parents are chosen with a rank-based mechanism rather than a probability, which is a function of their fitness (roulette wheel selection with each parent having a slot with a size proportional to its fitness) to achieve a smoother probability curve. This prevents good organisms from completely dominating the evolution from an early point.
4.3 Crossover operator
The crossover operator is an important component of GA. The crossover operation generates offspring from randomly selected pairs of individuals within the mating pool, by exchanging segments of the chromosome strings from the parents.
The sequencing GA in Evolver uses order crossover. This operator was developed by DAVIS [46]. This operator is based on using a bit string (zero-one) template to determine which parent will contribute to make the offspring. This fills some positions on offspring by copying the elements from P1 wherever the binary template contains ��1�� in the same position as they appear in P1. The elements from P1 associated with ��0�� in the template appear in the same order in the offspring as they appear in P2. An example is given in Table 1.
Table 1 Uniform order-based crossover
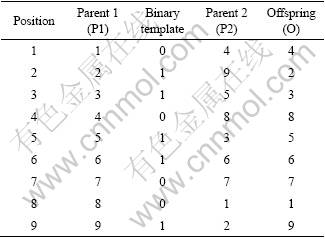
In Table 1 the elements associated with ��1�� in P1 are at position 2, 3, 5, 6 and 9 and are inherited by the offspring in the same positions. The remaining elements associated with ��0�� are 1, 4, 7 and 8. These elements appear in the same order in the offspring as they appear in P2.
4.4 Mutation operator
The purpose of the mutation is to ensure that diversity is maintained in the population. It gives random movement about the search space thus preventing the GA becoming trapped in ��blind corners�� or ��local optima�� during the search. Evolver performs order-based mutation. In this mutation, two tasks are selected at random and their positions are swapped. The ��mutation rate�� determines the probability that mutation is applied after a crossover.
4.5 Precedence constraints
An important facility in Evolver is the ability to include precedent constraints, i.e. certain tasks cannot be done until certain other tasks are finished. When a child is created from two parents, a routine is run to see whether the precedent constraints have been met or not. If not, the routine modifies the child so that it meets all the precedent constraints by altering the position of the precedence violating tasks.
5 Computational analysis
The FMS job shop scenario presented here has been taken from BILGE and ULUSOY [12]. The 82 test problems described are attempted here with the GA. The results have been compared with GA proposed by ULUSOY et al [13] designated as UGA, a hybrid GA/heuristic approach proposed by ABDELMAGUID et al [14] designated as GAA, hybrid multi-objective GA by REDDY and RAO [22] as PGA and a simulated annealing local search proposed by DEROUSSI et al [23] designated as SALS.
The travel times on each layout are given in Appendix A. The loaded trip times are obtained by adding loading and unloading times to travel times. Ten different job sets with different processing sequences, and process times are generated and presented in Appendix A. Different combinations of these ten job sets and four layouts are used to generate 82 example problems. In all these problems, there are two vehicles. The four layouts are assumed to be representative of existing systems and the job sets include between 5 and 8 jobs and between 13 and 21 operations to be scheduled.
A code is used to designate the example problems which are given in the first column. The digits that follow EX indicate the job set and the layout. Thus, EX 53 indicates the instance generated by job set 5 and layout 3.
The problems have been simulated on PIV 1.7 GHz computer having 128 MB RAM. For each of the run, the following parameters have been used: population size of 65, crossover rate of 0.65, mutation rate of 0.001 and stopping criteria of 65 000 iterations which correspond to 210 s on PIV 1.7 GHz computer having 128 MB RAM.
Table 2 consists of results for the four approaches mentioned above i.e. UGA, GAA, SALS, PGA and proposed GA for problems whose tij/pi ratios are higher than 0.25 (total of 40 problems). Table 2 shows the relative performance of proposed GA as compared with four previous approaches i.e., UGA, GAA, SALS and PGA and percentage deviation against each. It also gives the percentage deviation from the best known solution found for each of the forty problems among the five approaches. The summary of results as compared with the proposed GA is given in Table 3. In Table 3 we can see that compared with UGA, the proposed GA obtained same solution for 21 problems, better for 16 problems while for only 3 problems GA was unable to produce better results. However, for GAA, the proposed GA obtained same solution for 27, better for 6 and worse for 7 problems. SALS was the best approach among the four approaches presented here. By comparing the proposed GA with SALS, it obtained same solution for 28 while for 12 problems, proposed GA produced worse results. As compared with PGA, the proposed GA obtained same solution for 27, better for one and worse for 12 problems. Table 4 gives the summary of results against the best known solution for all the five approaches. As far as computation time is concerned, the average time to reach the best solution for the proposed GA was 126 s, and a maximum time required to reach the best solution was 1 260 s with a median of 36 s and mode of 18 s. Figure 4 shows the combined plot of percentage deviation for the comparison of proposed GA with other approaches.
For problems with tij/pi ratios lower than 0.25, the results are represented in Table 5. In Table 5, another digit is appended to the code. Here, having 0 or 1 as the last digit implies that the process times are doubled or tripled, respectively, where in both cases, travel times are halved. Table 5 shows the results for 42 problems.
For tij/pi<0.25, the proposed GA performs same as the GAA [14] and PGA [22] and better in three problems over UGA [13], where UGA performs better in two problems. For problems EX810, EX820, EX830 and EX840, results computed by UGA have been proven to be invalid in ABDELMAGUID et al [14]. Therefore, the results obtained by sliding time window (STW) heuristic [12] are considered to be optimal.
6 Empirical analysis of effects of parameter values on GA performance
The performance of a GA depends upon population size, crossover and mutation rate. Detailed experiments have been carried out to study the effect of these three parameters. The application of the GA to the schedule optimization is repeated here for each of the combinations of the following parameter levels:
Population size: 20, 50, 80
Mutation rate: 0.003, 0.006, 0.009, 0.018
Crossover rate: 0.20, 0.35, 0.50, 0.65, 0.80
Table 2 Comparison of proposed GA with UGA, GAA, SALS and PGA
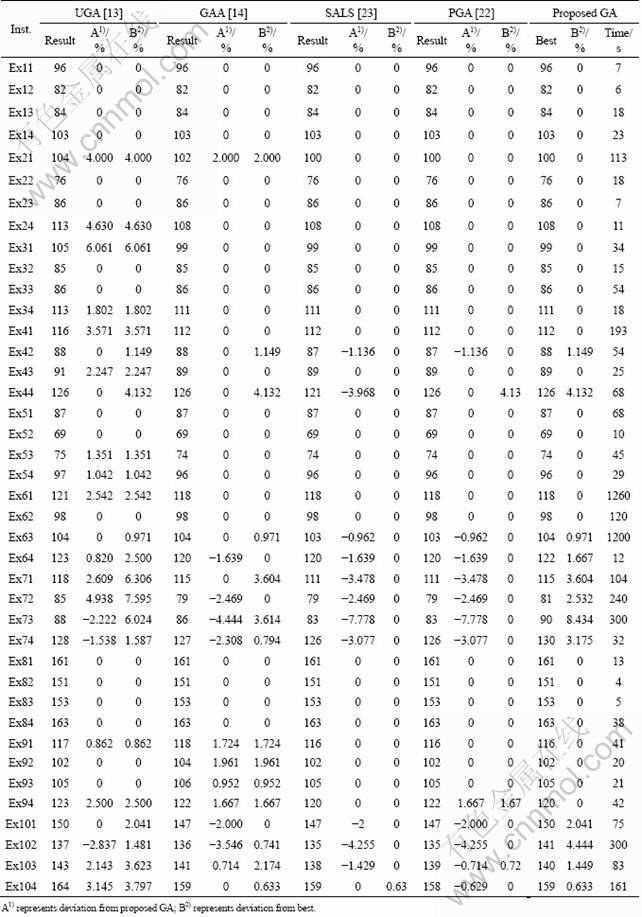
Table 3 Summary of results as compared with proposed GA

For each combination of the parameters, the GA is run for ten different random initial populations. These ten populations are different for each combination. Thus, in total, the GA is run for 600 times. The values chosen for the population size are representative of the range of values typically seen in the literature, with 0.018 being included to highlight the effect of a relatively large mutation rate. The crossover rates chosen are representative of the entire range. The optimal (target) solution known in priori for this schedule is a makespan of 76 units of time.
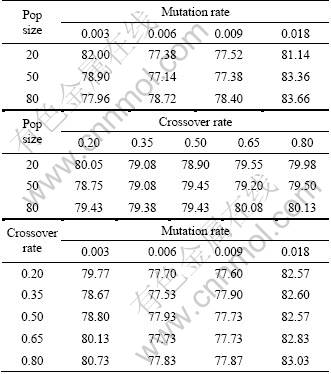
The average makespans achieved after 5 000 iterations are recorded for each pairing of the parameters in Tables 6. These averages are calculated across the different levels of the corresponding third parameter and the different initial populations. So, for example, each average in Table 6 is the average of 50 GA runs (5 crossover rate levels �� 10 initial populations).
In terms of the average makespans achieved, Table 6 begins to highlight that performance diminishes when population size and mutation rate are at their lowest. This suggests that when the population size is very small, a higher mutation rate is required to compensate for the fact that very little mutation will occur (the amount of mutation occurring is proportional to the population size as well as the mutation rate) and that there is less capacity for diversity in the population. When the mutation rate is reduced, the GA search will be inclined to remain longer in the region of local optima. This problem becomes more acute with a small population which has less capacity for diversity so that the population can be more rapidly swamped by the characteristics of a local optima. When the population is large, the smaller mutation rate is the best. This can be explained by the same proportionality rule and the larger population providing more capacity to accommodate diversity. Across the range of population values, performance is diminished when the mutation rate is very high. This is because the population is jumping too vigorously around the search space rather than putting more time and effort into going deeper into the regions of optima, i.e. the mutation operator overpowers the crossover operator.
Table 6 also begins to highlight that from this highly aggregated (averaged) view the crossover rate is not a very significant factor. This finding is in agreement with the findings of GUPTA et al [47] and HAIDA and AKIMOTO [48]. However, more detailed analysis given below identifies situations in which it does become significant.
Table 4 Summary of results as compared with best known solution for all five approaches

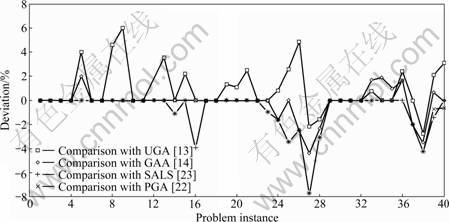
Fig.4 Combined plot showing deviation of proposed GA as compared with four approaches
Table 5 Comparison of proposed GA with second data set results
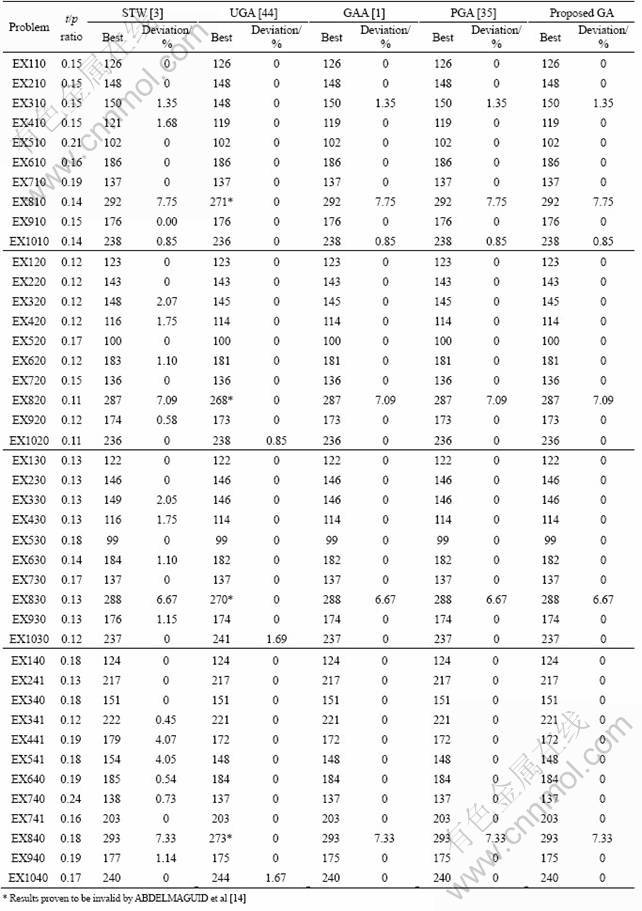
Table 6 Average objective function value
The percentage of trials that have achieved the optimal makespan by the 5 000th iteration are recorded for each pair of parameter level combinations in Table 7. This table appears to give a more sensitive view of the performance: this is an important general result in itself. Table 7 shows that a low mutation rate is unsuitable when the population size is small, whilst too high mutation rate is always unsuitable.
Table 7 suggests an interaction between crossover rate and population size. The general trend in these highly aggregated results is that the crossover rate should be high for small populations but small for large populations.
Table 7 again highlights that the mutation rate should not be too high. It is also shown that a small crossover rate can be used to compensate for the adverse effects of a low mutation rate.
The ��percentage of runs reaching the optimum�� can be used as a metric to study the effects of the different initial populations. This percentage gives an estimate of the probability (p) that a random initial population will converge to the optimal solution: within 5 000 runs in this example. The probability that a population will not converge to the optimal within 5 000 runs is then 1-p, and the probability that with n different initial populations none of them converge to the optimum is (1-p)n. This latter probability enables us to access how many initial populations should be tried, to give a good chance of achieving an optimal solution, if the GA runs are estimated after a given number of trials (in this example 5 000). Figure 5 charts the value of (1-p)n for different values of p and n. This figure can now be used in conjunction with the results in Table 8, which breaks down the two factor-aggregated results into three factor results averaged across 10 initial populations used at each factor combination. For example, the highest ��percentage of runs reaching the optimum�� is achieved with a population size of 20, mutation rate of 0.006 and crossover rate of 0.80. This combination achieves optimum 80% of the times after 5 000 runs. Therefore, the probability of not achieving optimum after, say, 10 runs with different initial populations is (1-0.8)10= 0.000 000 1, i.e. extremely small. Figure 5 can be used to identify how many runs are required to give a reasonable guarantee of reaching an optimal solution with a particular parameter level combination.
Table 7 Average optimal solution achieved
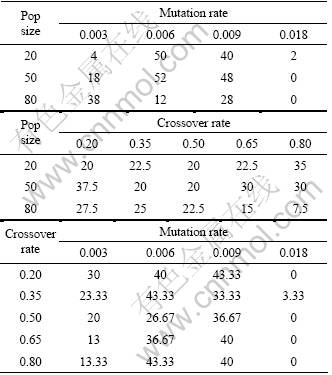
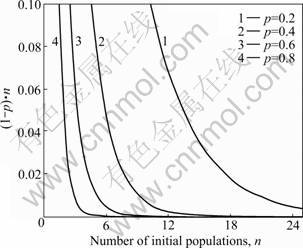
Fig.5 Probability of not converging to optimal solution
Table 8 Percentage optimal solution achieved (%)
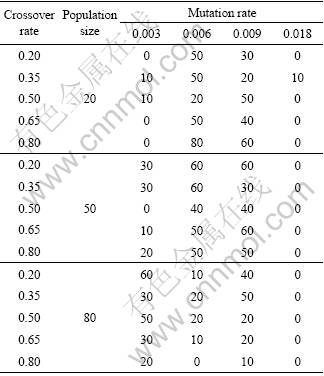
Table 9 gives the average worst case results. It reveals the same trends seen in the previous tables. It shows that some very poor results are achieved if the mutation rate is too high or if the population and the mutation rate are both too low.
Another example, comprising 21 operations i.e. EX103, is chosen for analysis because it is one of the largest schedules. The results for applying the GA to minimise the makespan are given in Table 10. For each combination of parameters, the GA is run for 10 different random initial populations.
Table 9 Average worst case results
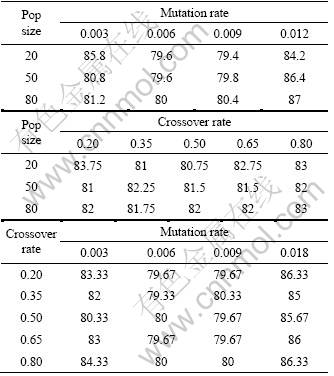
Table 10 shows that once again, at this highly aggregated level, the crossover rate is not a significant factor, except when there is zero mutation. Table 10 also shows that a general trend in performance previously seen in respect of mutation rate. That is, it forms a curve of the form illustrated in Fig.6 which shows that performance degrades at either side of a range of ��good�� mutation values. This relatively flat bottomed curve gives a degree of tolerance to the choice of mutation rate.
Table 10 Average objective function value
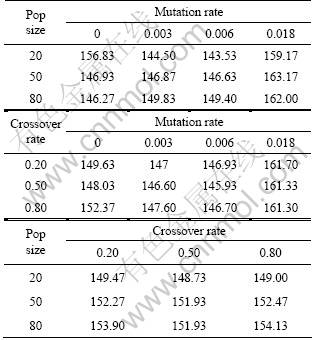
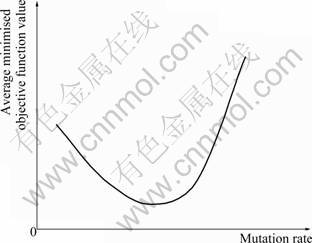
Fig.6 General effect of mutation rate on minimised objective function value
Table 10 reveals an interaction between population size and mutation rate with zero mutation rate being best for the highest population size whilst 0.006 is the best of the rates tried for the lowest population size.
The results show that the performance of the GA is insensitive to the crossover rate. There is also a degree of insensitivity to the mutation rate which possessed a ��range�� over which its value is suitable rather than a more precise value. Furthermore, performance is fairly insensitive to population size provided the mutation rate is in the ��good�� range.
The examples of various shop models presented in this work show that the GA-spreadsheet approach presented performs well on a wide range of shop models with a ��general purpose�� set of parameters.
In proposing GA as a general-purpose scheduler for the real world, it is necessary to establish the importance of parameter tuning. The results found here support the view that tuning the GA parameters is not difficult, as there appears to be a substantial degree of tolerance afforded to the ��best�� or ��suitable�� values. Combined with the user-friendly spreadsheet implementation, there is no reason to conclude that GA could not provide a general purpose manufacturing shop scheduler.
7 Conclusions
1) The application of a simple GA to scheduling job shop FMS is demonstrated, where the objective is to minimize the total completion time for simultaneous scheduling of machines and AGVs. The experiments performed have been reproduced from work reported elsewhere. The results show that the solutions obtained for the proposed approach are comparable to the previous reported studies. The time computation for the proposed GA is also very efficient.
2) The examples presented here have demonstrated how simple it is to adapt proprietary GA software to different scheduling problems. The spreadsheet model can easily be customized to include more number of machine or adding more workers without actually changing the logic of the GA routine, which makes the approach a truly general purpose approach.
3) The empirical analysis of the GA parameters shows that crossover rate is often an insignificant factor in the performance of the GA, in keeping with the findings of GUPTA et al and HAIDA and AKIMOTO. There is a degree of insensitivity to the mutation rate so far as the ��good�� values form a fairly broad range rather than coming at a more precise point. However, outside of the ��good�� range, performance soon deteriorates greatly. It is observed that a low mutation rate is desirable when the population size is large and higher mutation rate is desirable when the population size is small. The sensitivity to population size is greatly reduced when the mutation rate is in the ��good�� range. As a consequence of these findings, it has been argued that GA has the potential to make a general-purpose real-world scheduler.
4) The key advantage of GA portrayed here is that it provides a general purpose solution to the scheduling problem which is not problem specific, with the peculiarities of any particular scenario being accounted for in fitness function without disturbing the logic of the standard optimization routine. The GA can be combined with a rule set to eliminate undesirable schedules by capturing the expertise of the human scheduler
References
[1] VAN DYKE PARUNAK H. Characterizing the manufacturing scheduling problem [J]. Journal of Manufacturing Systems, 1992, 10(3): 241-259.
[2] BRITT D. Managing temporal relations in MAESTRO scheduling system [C]// Proceedings of Space Network Control Conference on Resource Allocation Concepts and Approaches. Greenbelt, MD: NASA Goddard, 1992: 233-240.
[3] GROOVER M P. Automation, production systems and computer integrated manufacturing [M]. New York: Prentice-Hall, 1987.
[4] BUZZACOTT J A, YAO D D. Flexible manufacturing systems: A review of analytical models [J]. Management Science, 1986, 32: 890-905.
[5] GUNASERKARAN A, MARTIKAINEN T, YLI-OLI P. Flexible manufacturing systems: An investigation for research and applications [J]. European Journal of Operations Research, 1993, 66: 1-26.
[6] KUSIAK A. Application of operational research models and techniques in flexible manufacturing systems [J]. European Journal of Operations Research, 1986, 24: 336-345
[7] LIU J, MACCARTHY B L. The classification of FMS scheduling problems [J]. International Journal of Production Research, 1996, 34: 647-656.
[8] MACCARTHY B L, LIU J. A new classification scheme for flexible manufacturing systems [J]. International Journal of Production Research, 1993, 31: 299-309.
[9] STECKE K. Planning and scheduling approaches to operate a particular FMS [J]. European Journal of Operations Research, 1992, 61(3): 273-291.
[10] RAMAN N, TALBOT F B, RACHAMADGU R V. Simultaneous scheduling of machines and material handling devices in automated manufacturing [C]// STECKE K E, SURI R. Proceedings of the Second ORSA/TIMS Conference on Flexible Manufacturing Systems. University of Michigan, Ann Arbor, MI, USA, 1986: 455-466.
[11] ULUSOY G, BILGE U. Simultaneous scheduling of machines and automated guided vehicles [J]. International Journal of Production Research, 1993, 31(12): 2857-2873.
[12] BILGE U, ULUSOY G. A time window approach to simultaneous scheduling of machines and material handling system in FMS [J]. Operations Research, 1995, 43: 1058-1070.
[13] ULUSOY G, SIVRIKAYA-SERIFOGLU F, BILGE U. A genetic algorithm approach to the simultaneous scheduling of machines and automated guided vehicles [J]. Computers & Industrial Engineering, 1997, 24(4): 335-351.
[14] ABDELMAGUID T F, NASSEF O N, KAMAL B A, HASSAN M F. A hybrid GA/heuristic approach to the simultaneous scheduling of machines and automated guided vehicles [J]. International Journal of Production Research, 2004, 42: 267-281.
[15] MURAYAMA N. KAWATA S. An evolutional computing approach to the simultaneous scheduling of machines and automated guided vehicles [J]. Jido Seigyo Rengo Koenkai Koen Ronbunshu, 2004, 47. (in Japanese)
[16] MURAYAMA N, KAWATA S. A genetic algorithm approach to simultaneous scheduling of processing machines and multiple-load automated guided vehicles [J]. Transactions of the Japan Society of Mechanical Engineers C, 2005, 71(712): 3638-3643. (in Japanese)
[17] MURAYAMA N, KAWATA S. Job-shop scheduling considering material handling by multiple-load AGVs [R]. The Institute of Electronics, Information and Communication Engineers, IEICE Tech. Report, 2005, 105(159): 17-21. (in Japanese)
[18] JERALD J, ASOKAN P, SARAVANAN R, RANI A D C. Simultaneous scheduling of parts and AGVs in an FMS using non-traditional optimization algorithms [J]. International Journal of Applied Management and Technology, 2005, 3(1): 305-315.
[19] JERALD J, ASOKAN P, SARAVANAN R, RANI A D C. Simultaneous scheduling of parts and automated guided vehicles in an FMS environment using adaptive genetic algorithms [J]. International Journal of Advanced Manufacturing Technology, 2006, 59: 584-589.
[20] JERALD J, ASOKAN P, PRABHAHARAN G, SARAVANAN R. Scheduling of parts and AS/RS in FMS using genetic algorithm [J]. International Journal of Applied Management and Technology, 2006, 4(1): 25-34.
[21] MURAYAMA N, KAWATA S. Simulated annealing method for simultaneous scheduling of machines and multiple-load AGVs [C]// IJCC Workshop on Digital Engineering. Pyeongchang-gun, Gangwon-do, South Korea, 2006: 55-62. (in Japanese)
[22] REDDY B S P, RAO C S P. A hybrid multi-objective GA for simultaneous scheduling of machines and AGVs in FMS [J]. International Journal of Advanced Manufacturing Technology, 2006, 31(5/6): 602-613.
[23] DEROUSSI L, GOURGAND M, TCHERNEV N. A simple metaheuristic approach to the simultaneous scheduling of machines and automated guided vehicles [J]. International Journal of Production Research, 2008, 46(8): 2143-2164.
[24] STECKE K E. Design, planning, scheduling, and control problems of flexible manufacturing systems [J]. Annals of Operations Research, 1985, 3(1): 3-12.
[25] GOLDBERG D E. Genetic algorithms in search, optimization and machine learning [M]. New York: Addison-Wesley Publishing Company, 1989.
[26] DAVIS L. Job shop scheduling with genetic algorithms [C]// Proceedings of the 1st International Conference on Genetic Algorithms. Hillsdale, NJ: Lawrence Erlbaum, 1985: 136-140.
[27] CHAUDHRY I A. Minimizing flow time for the worker assignment problem in identical parallel machine models using GA [J]. International Journal of Advanced Manufacturing Technology, 2009, 48(5/6/7/8): 747-760.
[28] CHAUDHRY I A, DRAKE P R. Minimizing flow time variance in a single machine system using genetic algorithms [J]. International Journal of Advanced Manufacturing Technology, 2008, 39: 355-366.
[29] CHAUDHRY I A, DRAKE P R. Minimizing total tardiness for the machine scheduling and worker assignment problems in identical parallel machines using genetic algorithms [J]. International Journal of Advanced Manufacturing Technology, 2009, 42: 581-594.
[30] Evolver user��s guide [M]. New York: Palisade Corp, 1998.
[31] HE D, GRIGORYAN A. Construction of double sampling s-control charts for agile manufacturing [J]. Quality and Reliability Engineering International, 2002, 18: 43-55.
[32] BARKHI R, ROLLAND E, BUTLER J, FAN W. Decision support system induced guidance for model formulation and solution [J]. Decision Support Systems, 2005, 40(2): 269-281.
[33] OSTFELD A, MUZAFFAR E, LANSEY K. HANDSS: The hula aggregated numerical decision support system [J]. Journal of Geographic Information and Decision Analysis, 2001, 5(1): 16-31.
[34] HEGAZY T, KASSAB M. Resource optimization using combined simulation and genetic algorithms [J]. Journal of Construction Engineering and Management, 2003, 129(6): 698-705.
[35] SARANGA H, KUMAR U D. Optimization of aircraft maintenance/support infrastructure using genetic algorithms-level of repair analysis [J]. Annals of Operations Research, 2006, 143: 91-106.
[36] SHUM Y-S, GONG D-C. The application of genetic algorithm in the development of preventive maintenance analytic model [J]. International Journal of Advanced Manufacturing Technology, 2007, 32: 169-183.
[37] HAYAT N, WIRTH A. Genetic algorithms and machine scheduling with class setups [J]. International Journal of Computer and Engineering Management, 1997, 5(2): 10-23.
[38] HEGAZY T, ERSAHIN T. Simplified spreadsheet solutions: II. Overall schedule optimization [J]. Journal of Construction Engineering and Management, 2001, 127(6): 469-475.
[39] JEONG S J, LIM S J, KIM K S. Hybrid approach to production scheduling using genetic algorithm and simulation [J]. International Journal of Advanced Manufacturing Technology, 2006, 28: 129-136.
[40] NASSAR K. Evolutionary optimization of resource allocation in repetitive construction schedules [J]. ITcon, 2005, 10: 265-273.
[41] RUIZ R, MAROTO C. Flexible manufacturing in the ceramic tile industry [C]// Proceedings of Eighth International Workshop on Project Management and Scheduling. Valencia, Spain, 2002: 301-304.
[42] SADEGHEIH A. Sequence optimization and design of allocation using GA and SA [J]. Applied Mathematics and Computation, 2007, 186(2): 1723-1730.
[43] SHIUE Y-R, GUH R-S. Learning-based multi-pass adaptive scheduling for a dynamic manufacturing cell environment [J]. Robotics and Computer-Integrated Manufacturing, 2006, 22: 203-216.
[44] CHEUNG S-O, TONG T K-L, TAM C-M. Site pre-cast yard layout arrangement through genetic algorithms [J]. Automation in Construction, 2002, 11: 35-46.
[45] WHITLEY D. GENITOR: a different genetic algorithm [C]// Proceedings of the Rocky Mountain Conference on Artificial Intelligence. Denver: Morgan Kaufman, 1988: 118-130.
[46] DAVIS L. Handbook of genetic algorithms [M]. New York: Van Nostrand Reinhold, 1991: 332-349.
[47] GUPTA M C, GUPTA Y P, KUMAR A. Minimizing the flow time variance in a single machine system using genetic algorithms [J]. European Journal of Operational Research, 1993, 70: 289-303.
[48] HAIDA T, AKIMOTO Y. Genetic algorithms approach to voltage optimization [C]// Proceedings of the IEEE First International Forum on the Applications of Neural Networks to Power Systems. Seattle, USA, 1991: 139-143.
APPENDIX A
Travel time Data Used in FMS Job Shop Scenario
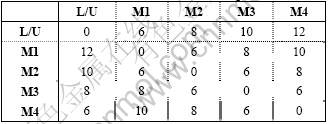
Table A-1. Travel time data for layout 1
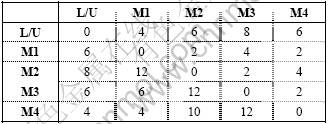
Table A-3. Travel time data for layout 3
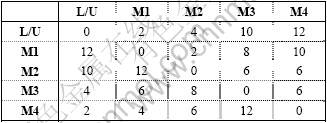
Table A-2. Travel time data for layout 2
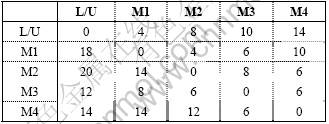
Table A-4. Travel time data for layout 4
Data for Job Sets Used in FMS Job Shop Scenario
Job Set 1
Job 1: M1(8); M2(16); M4(12)
Job 2: M1(20); M3(10); M2(18)
Job 3: M3(12); M4(8); M1(15)
Job 4: M4(14); M2(18)
Job 5: M3(10); M1(15)
Job Set 2
Job 1: M1(10); M4(18)
Job 2: M2(10); M4(18)
Job 3: M1(10); M3(20)
Job 4: M2(10); M3(15); M4(12)
Job 5: M2(10); M3(15); M4(12)
Job 6: M2(10); M3(15); M4(12)
Job Set 3
Job 1: M1(16); M3(15)
Job 2: M2(18); M4(15)
Job 3: M1(20); M2(10)
Job 4: M3(15); M4(10)
Job 5: M1(8); M2(10); M3(15); M4(17)
Job 6: M2(10); M3(15); M4(8); M1(15)
Job Set 4
Job 1: M4(11); M1(10); M2(7)
Job 2: M3(12); M2(10); M4(8)
Job 3: M2(7); M3(10);M1(9); M3(8)
Job 4: M2(7); M4(8); M1(12); M2(6)
Job 5: M1(9); M2(7); M4(8); M2(10); M3(8)
Job Set 5
Job 1: M1(16); M2(12); M4(9)
Job 2: M1(18); M3(6); M2(15)
Job 3: M3(9); M4(3);M1(12)
Job 4: M4(6); M2(15)
Job 5: M3(3); M1(9)
Job Set 6
Job 1: M1(9); M2(11); M4(7)
Job 2: M1(19); M2(20); M4(13)
Job 3: M2(14); M3(20); M4(9)
Job 4: M2(14); M3(20); M4(9)
Job 5: M1(11); M3(16); M4(8)
Job 6: M1(10); M3(12); M4(10)
Job Set 7
Job 1: M1(6); M4(6)
Job 2: M2(11); M4(9)
Job 3: M2(9); M4(7)
Job 4: M3(16); M4(7)
Job 5: M1(9); M3(18)
Job 6: M2(13); M3(19); M4(6)
Job 7: M1(10); M2(9); M3(13)
Job 8: M1(11); M2(9); M4(8)
Job Set 8
Job 1: M2(12); M3(21); M4(11)
Job 2: M2(12); M3(21); M4(11)
Job 3: M2(12); M3(21); M4(11)
Job 4: M2(12); M3(21); M4(11)
Job 5: M1(10); M2(14), M3(18); M4(9)
Job 6: M1(10); M2(14), M3(18); M4(9)
Job Set 9
Job 1: M3(9); M1(12); M2(9); M4(6)
Job 2: M3(16); M2(11); M4(9)
Job 3: M1(21); M2(18); M4(7)
Job 4: M2(20); M3(22); M4(11)
Job 5: M3(14); M1(16), M3(13); M4(9)
Job Set 10
Job 1: M1(11); M3(19); M2(16); M4(13)
Job 2: M2(21); M3(16); M4(14)
Job 3: M3(8); M2(10); M1(14); M4(9)
Job 4: M2(13); M3(20); M4(10)
Job 5: M1(9); M3(16), M4(18)
Job 6: M2(19); M1(21), M3(11); M4(15)
(Edited by YANG Bing)
Received date: 2010-07-23; Accepted date: 2010-10-25
Corresponding author: I. A. Chaudhry, PhD; Tel: +92-300-4279895; E-mail: imran_chaudhry@yahoo.com
