
���ڸĽ����������Ʒ�ģ�͵�����ʶ��
Ԭ �� ��1, 2
(1. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083��
2. �����ƾ���ѧ ��Ϣ����ѧԺ������ �ϲ���330013)
ժ Ҫ��
ժ Ҫ������������ɷ�(HMM)����ʶ��ģ��״̬�������ͬ�ֲ���������ʵ�����Բ���Э���ļ����Լ���ʹ�öγ���Ϣʱ���ڵ�ȱ�ݣ����������ɷ�ģ�ͽ��иĽ�����������ɷ���ģ�͡������ɷ���ģ�Ϳɿ���һ����ѧ���ɶ�������ɷ������ɵĶ���������̣�HMMģ������˫��������̣������HMMģ�Ϳ���Ϊ�����ɷ���ģ�͵������������ɷ���ģ�������������Լ���ȡ����HMMģ�͵Ķ����Լ��衣������������Լ��裬�����Լ����ǹ�ǿ���裬��������������ɷ���ģ�͵�����ģ����������ʵ���������̡��������ɷ�������ʶ��ģ��������״̬�γ���Ϣ�����Զ��������ٶ�������Ԫ�γ����е��������ض�����������ʵ��������������״̬�γ���Ϣ�ĸĽ�����ʶ��ģ�ͱȾ���HMMģ�͵�����������ߡ�
�ؼ��ʣ�
�������ɷ�ģ���������ɷ���ģ�����γ�������ʶ����
��ͼ����ţ�TN912.34 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2008)06-1303-06
A speech recognition method based on improved hidden Markov model
YUAN Li-chi1, 2
(1. School of Information Science and Engineering, Central South University, Changsha 410083, China;
2. School of Information Technology, Jiangxi University of Finance & Economics, Nanchang 330013, China)
Abstract: In order to overcome the defects of the duration modeling of homogeneous hidden Markov model (HMM) in speech recognition and the unrealistic assumption that successive observations are independent and identically distribution within a state, Markov family model (MFM) was proposed. In the speech recognition model based on HMM, the time-sequence structure of speech signal was considered to be a double stochastic process, while Markov family model was a multiple stochastic process which consists of a few Markov chains, so HMM could be considered to be a special case of MFM. Moreover, independence assumption in HMM was placed by conditional independence assumption in MFM, and from the view of the statistics, the assumption of independence is stronger than that of conditional independence, so speech recognition model based on MFM is more realistic than HMM recognition mode. Markov Family model was applied to speech recognition, and duration distribution based MFM recognition mode which takes duration distribution into account and integrates the frame and segment based acoustic modeling techniques, was proposed. The speaker independent continuous speech recognition experiments show that this new recognition model has better performance than standard HMM recognition models.
Key words: hidden Markov model; Markov family model; duration; speech recognition
�������ɷ�ģ��[1](hidden Markov model����HMM)����Ϊ������ʶ����������ɹ���ͳ��ģ��֮һ��HMM�������źŵ�ʱ�����нṹ����ͳ��ģ�ͣ���֮����һ����ѧ�ϵ�˫��������̣�һ�����þ�������״̬����Markov����ģ�������ź�ͳ�����Ա仯������������̣���һ������Markov����ÿһ��״̬������Ĺ۲�����������̡�HMMģ�Ϳɷ�Ϊ��ɢ�������ɷ�ģ��[1](������ɢ�����ܶȺ��������DHMM)�������������ɷ�ģ��[1](�������������ܶȺ��������CDHMM)�Լ��������������ɷ�ģ ��[1](SCHMM��������DHMM��CDHMM���ص�)��
����ʮ�������й�����ʶ����о�ȡ���������չ���������ڳ������������ɷ�ģ���Ժ�ʻ�����������ʶ��[2]ȡ�����ش�ͻ�ƣ�����ʶ���������д���ߣ������ڣ����ȣ������HMM����ε������ɷ�ģ�ͣ���״̬ת�Ƹ���Ϊ������״̬פ�����ȷ���ָ���ֲ�[3]������������ʵ���������̲�������Σ�����������Ȼ���������з������ٵ��˶����ԣ�����֡����������֮���к�ǿ��ʱ������ԡ���������HMMӦ���У�Ϊ�˴������㣬������һ����Ҫ��״̬�������ʸ�������ֲ��ļ��衣���HMM����ʶ��ģ�����е�һЩȱ�ݣ�����������������ɷ���ģ��(Markov family model����MFM)�������ɷ���ģ��(MFM)���ɶ�������ɷ������ɵĶ���������̣���������֮����һ���ĸ��ʹ�ϵ����ģ�������������Լ���ȡ���������ɷ�ģ�͵Ķ����Լ��衣
1 �������ɷ�ģ���������ɷ���ģ��
1.1 �������ɷ�ģ��
����1 (�������ɷ�ģ��) �������ɷ�ģ��[1]��һ����Ԫ��(S, A, V, B, ![]() )�����У�
)�����У�![]() ����״̬����
����״̬����![]() ����������ż��ϣ�
����������ż��ϣ�
![]() ��1��i��N�� (1)
��1��i��N�� (1)
�dz�ʼ״̬���ʷֲ���![]() ����״̬ת�Ƹ��ʷֲ�����
����״̬ת�Ƹ��ʷֲ�����
![]() �� (2)
�� (2)
�Ǵ�״̬siת�Ƶ�״̬sj�ĸ��ʣ�![]() ����״̬���ŷ���ĸ��ʷֲ�����
����״̬���ŷ���ĸ��ʷֲ�����
![]() ��1��k��M��1��i��N�� (3)
��1��k��M��1��i��N�� (3)
��ʾ��״̬siʱ�������vk�ĸ��ʡ�
���������ɷ�ģ�͵Ķ�����Կ�����HMMģ����һ����ѧ�ϵ�˫��������̣�����������3����������Ļ����ϣ������ɷ��Լ��裻�����Լ��裻��������Լ��衣
1.2 �����ɷ���ģ��
����2 �����ɷ���ģ��(Markov family model) �� ![]() ��ʾmά������������з���Xi(1��i��m)ȡֵ������״̬��Si(1��i��m)������Xi (1��i��m)���������ɷ���ģ�ͣ��������������� ������
��ʾmά������������з���Xi(1��i��m)ȡֵ������״̬��Si(1��i��m)������Xi (1��i��m)���������ɷ���ģ�ͣ��������������� ������
a. ÿһ������Xi(1��i��m)����һ��ni�������ɷ�����
![]() �� (4)
�� (4)
b. ������ʱ��![]() ����ijһ��״̬�ĸ���ֻ��÷�����ʱ��
����ijһ��״̬�ĸ���ֻ��÷�����ʱ��![]() ��ǰ״̬��ʱ��
��ǰ״̬��ʱ��![]() ����������״̬�йأ�
����������״̬�йأ�
![]()
![]() �� (5)
�� (5)
c. ���������Լ��裺
![]()
![]() �� (6)
�� (6)
����a���������ɷ���ģ���Ƕ���������̣����������ɷ�ģ�Ϳɿ���һ����ѧ�ϵ�˫��������̡����������˵���������ɷ�ģ�Ϳ���Ϊ�����ɷ���ģ�͵�����������b��ȷ�������ɷ���ģ�͵Ķ�����������֮��Ĺ�ϵ�����ø������ܼ������ɷ���ģ�͵ļ��㡣��������c��ij������ʱ��t��ֵ��֪�������£��ñ�����ʱ��t��ǰ��ni-1��ȡֵ��������������ʱ��tȡֵ��������ģ��������ɷ���ģ�������������Լ���ȡ�����������ɷ�ģ���еĶ����Լ��衣��ͳ��ѧ�ĽǶ���˵��������������Լ��裬�����Լ����ǹ�ǿ���裬����������������Ҳ�������ϡ����������˵�����������ɷ���ģ�͵�����������ģ�ͱȻ����������ɷ�ģ�͵�����������ģ���������������Ե�ʵ���������̡�
2 ���ڶγ��ֲ���MFM����ʶ�� ģ��
�����������У���ͬ˵�����ڲ�ͬ�ᄈ��˵�����ٶȲ����Ǻܴ�ġ�ƫ���������ٹ������������ʶ�����������ٻ�ʹɾ���������ӣ����������ٻ���ɲ���������ӣ��Ӷ�ʹʶ�������½���Ŀǰ�����Ƕ����������о���Ҫ���Ȱ���ij�ַ����õ�ʶ�����ϵ����ٶ�����Ȼ�������ٵĿ�������ת�Ƹ��ʣ�����������µ�״̬��ת�Ƹ��������뿪ת�Ƹ��ʱ�С������ʱ��֮���Ӷ�����ÿ��������Ԫ�ij���ʱ������Ӧ����[4]��
���ڶγ�������ʶ��ģ��[3, 5-8]��ֱ�ӴӶγ�������˵���ٶȵı仯ֱ�ӷ�ӳΪ�γ��ı仯��ͬʱ�����ٱ仯�Զγ���Ӱ����ͬ��������ͬ���½��ģ�������������£�ǰһ��������Ԫ����ƽ���γ�����һ��������ԪҲ������ͬ�����Ƴ�����ƽ���γ������ڿ�������������෴��������һ���϶̵�ʱ����ڣ�1��˵���ߵ�˵���ٶȻ�Ƚ��ȶ�����һ����ʱ������������ٶԶγ���Ӱ�������Ϊ�ǻ���һ�µġ��������Ϳ�����ǰһ��������Ԫ�γ������ֵ��ƫ����Ԥ���һ��������Ԫ�γ��ı仯����[9-13]��
����ʶ��ͳ��ģ��ͨ��������[1]Ϊ�������ʶ��λ[14]����������ģ���������ֵ�״̬��![]() �֣���Ϊsl(l=1, ��, L)����ʱ��n(n��1)������״̬��xn��ʾ��yn��ʾ״̬xn�Ĺ۲�������ϵͳ��״̬xn����פ����ʱ�䳤��(���Ϊ�γ�)�æ�n��ʾ�����йظ���Ϊ��
�֣���Ϊsl(l=1, ��, L)����ʱ��n(n��1)������״̬��xn��ʾ��yn��ʾ״̬xn�Ĺ۲�������ϵͳ��״̬xn����פ����ʱ�䳤��(���Ϊ�γ�)�æ�n��ʾ�����йظ���Ϊ��
![]() ��l=1, ��, L��
��l=1, ��, L��
![]() ��i, j=1, ��, L��
��i, j=1, ��, L��
![]() , l=1, ��, L��
, l=1, ��, L��
����ʶ��ϵͳ�Ĵʻ������ΪV������ÿһ��������ʾΪwv��v=1~V����ÿһ����wv�а���Lv��״̬����Ϊ![]() ��l=1~Lv���ּٶ�һ�������ľ�������Ӧ���������У����۲�����ΪO={o1, o2, ��, oT}����ʶ����ӵĴ�����ΪW={w1, w2, ��, wN}���������еĵ�i (1��i��N) ����wi��Ӧ�ĵ�j(1��j��Li)��״̬��Ϊ
��l=1~Lv���ּٶ�һ�������ľ�������Ӧ���������У����۲�����ΪO={o1, o2, ��, oT}����ʶ����ӵĴ�����ΪW={w1, w2, ��, wN}���������еĵ�i (1��i��N) ����wi��Ӧ�ĵ�j(1��j��Li)��״̬��Ϊ![]() ��ϵͳ��״̬
��ϵͳ��״̬![]() ����פ����ʱ�䳤��(�γ�)��Ϊ
����פ����ʱ�䳤��(�γ�)��Ϊ![]() ����ϵͳ��������״̬����Ϊ��
����ϵͳ��������״̬����Ϊ��
![]() ��
��
����ʶ�����������ɹ۲�����O={o1, o2, ��, oT}������ѵ�״̬����S�����������ѵĴ�����W={w1, w2, ��, wN}������������ܵĴ����У�
![]()
![]() �� (7)
�� (7)
���У�![]() ��K��2����KΪ2, 3ʱ���ֱ��Ϊ˫���ķ��������ķ���
��K��2����KΪ2, 3ʱ���ֱ��Ϊ˫���ķ��������ķ���
��![]() ��ʾ��Ӧ�ڴ�����W�Ŀ���״̬����S�ļ��ϣ�����
��ʾ��Ӧ�ڴ�����W�Ŀ���״̬����S�ļ��ϣ�����
![]() �� (8)
�� (8)
��
![]() ��2��i��N��
��2��i��N��
![]() ��2��j��Li��
��2��j��Li��
��ʾ�εķָ�㣬���ٶ�O={o1, o2, ��, oT} ��һ��M �������ɷ���������
![]()
![]() �� (9)
�� (9)
��ʽ(8)�и���![]() �ļ������£�
�ļ������£�
![]()
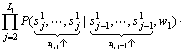

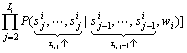 �� (10)
�� (10)
����
![]()
![]()
![]()
![]() �� (11)
�� (11)
��������![]() ��ȡ����ֵ
��ȡ����ֵ![]() ���������ɷ���ģ�͵����������Լ��裬��
���������ɷ���ģ�͵����������Լ��裬��
![]()
![]()
![]()
![]() �� (12)
�� (12)
�ɱ�Ҷ˹��������
![]()
![]() �� (13)
�� (13)![]()
![]() �� (14)
�� (14)
��ʽ(13)��(14)����ʽ(12)�ɵã�
![]()
![]() �� (15)
�� (15)
ʽ(10)�е���������Ҳ��ͨ�����Ƶļ���õ�����������
![]()
�ļ�������������2��������Ԫ��Ķγ������Ϣ��������ʵ�ֵ�ϵͳΪ�γ���Ԫ����ϵͳ����Ȼ��Ҳ����������r��������Ԫ��Ķγ������Ϣ������Ӧ��ϵͳ��Ϊ�γ�rԪ����ϵͳ��
��������ϡ�裬![]() ��ȡ����ֵ
��ȡ����ֵ![]() ����ƽ�������õ���
����ƽ�������õ���
![]()
![]()
![]() �� (16)
�� (16)
���У�![]() Ϊƽ��������0��
Ϊƽ��������0��![]() ��1��
��1��![]() Ϊ״̬�γ�����Ҳ��������д������(��ĸ����ĸ)�����ڵĶγ�����ˣ������ṩ��ģ�ͺ��㷨���кܴ������ԡ��ھ����HMM����ʶ��ģ���У�״̬
Ϊ״̬�γ�����Ҳ��������д������(��ĸ����ĸ)�����ڵĶγ�����ˣ������ṩ��ģ�ͺ��㷨���кܴ������ԡ��ھ����HMM����ʶ��ģ���У�״̬![]() ��פ������
��פ������![]() Ϊ������ϵͳ����״̬i���ڸ�״̬����פ����ʱ��
Ϊ������ϵͳ����״̬i���ڸ�״̬����פ����ʱ��![]() ���γ����Ӽ��ηֲ�[1]��
���γ����Ӽ��ηֲ�[1]��
![]() ��
��![]() ��1�� (17)
��1�� (17)
ʵ��ͳ�ƽ������������HMMģ�����ֶγ��ļ��ηֲ���ʽ���ܺܺõ����������Ķγ�������Ϊ�ˣ������о��߶�ģ�ͽ��иĽ�����״̬�γ�����ֱ������ͳ��ģ���С����õĶγ��ֲ���ʽ��Gamma�ֲ�����˹�ֲ������ɷֲ��;��ȷֲ��ȡ�
3 ʵ����
Ϊ����֤�������������ʶ���������������������顣��ʻ��������������������õ����������ǡ�863���ƻ��ṩ����Ů����83�˵���������¼�����ݡ�ÿ��˵���˶�Ӧһ��520�仰��650�仰���ȵ��ļ�������9���ļ�����ʶ��(���٣��������٣�����3���3���ļ�)������74���ļ�����ѵ�������õ�����[15-17]��14άMFCC��������һ�ײ�ֺͶ��ײ�֣���һ����������һ�ײ�ֺͶ��ײ�֣���45ά�������������1��
��1 ���ض�����������ʶ���ʵ����
Table 1 Experimental results of speaker-independent continuous speech recognition
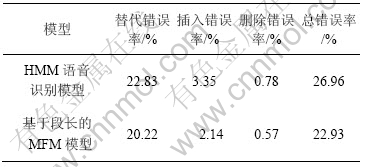
��1�е�HMM����ʶ��ʵ�������������Markovģ�ͣ�����Ӣ�����Ŵ�ѧ�ṩ��HTK(HMM Tool Kit) ���߰��б��롢ѵ����ʶ�����ع��ߡ��ӱ�1���Կ�������������ʴ�22.83%�½���20.22%����������ʴ�3.35%�½���2.14%��ɾ�������ʴ�0.78%�½���0.57%���ܴ����ʴ�26.96%�½���22.93%������½���15%���Դ�ʻ����������������������������ڶγ��ֲ��������ɷ�������ʶ��ģ��(DDBMFM)�˷��˴�ͳHMM�������Ķ����Լ��裬��ʶ�����������Եĸ��ơ���ģ��ͬʱ��ƫ���������ٵ����Ͻ���ʶ��ʱ�����Զ��������ٶ�������Ԫ�γ����е������Ӷ����������ٴ����IJ�������ɾ��������˸���ȷ�ķָ�㣬����˼�����������Ӷ������ϵͳ�����ܡ�
4 �� ��
a. ���������ɷ�ģ�͵Ļ����ϣ������һ���µ�ͳ��ģ�ͼ������ɷ���ģ�͡������ɷ���ģ���Ƕ���������̣����������ɷ�ģ�Ϳɿ���һ����ѧ�ϵ�˫��������̣�����������ɷ�ģ�Ϳ���Ϊ�����ɷ���ģ�͵������������ɷ���ģ�������������Լ���ȡ���������ɷ�ģ���еĶ����Լ��裬��ͳ��ѧ�ĽǶ���˵��������������Լ��裬�����Լ����ǹ�ǿ���裬����������������Ҳ�������ϡ���������������ɷ���ģ�͵�����������ģ�ͱȻ����������ɷ�ģ�͵�����������ģ���������������Ե�ʵ���������̡�
b. �������ɷ���ģ��Ӧ��������ʶ��ͬʱ������ʶ��ģ����ֱ������״̬�γ���Ϣ�����ڶγ�������ʶ��ģ��ֱ�ӴӶγ�������˵���ٶȵı仯ֱ�ӷ�ӳΪ�γ��ı仯�����Զ��������ٽ���������Ԫ�γ��ĵ������������������״̬�γ���Ϣ��MFM����ʶ��ģ�ͱȾ���HMMģ�͵�����������ߡ�
c. �����ɷ���ģ����һ���µ�ͳ��ģ�ͣ��й������ɷ���ģ�͵����ۼ���������ʶ�����Ȼ���Դ����������е�Ӧ���д���һ���о���
�ο����ף�
[1] Rabiner L, Juang B H. Fundamentals of speech recognition[M]. New Jersey: Prentice Hall, 1993.
[2] Chang E, ZHOU Jian-lai, SHOU Di, et al. Large vocabulary mandarin speech recognition with different approaches in modeling tones[C]//Proceedings of the 6th International Conference on Spoken Language Processing(ICSLP 2000). San Jose: IEEE Press, 2000: 983-986.
[3] Mitchell C D, Jamieson L H. Modeling duration in a hidden Markov model with the exponential family[C]//Proceedings of the IEEE International conference on Acoustic, Speech, Signal Process (ICASSP 1993). San Jose: IEEE Press, 1993: 331-334.
[4] Shinoda K, Lee C. A structural Bayes approach to speaker adaptation[J]. IEEE Transaction on Speech and Audio Processing, 2001, 9(3): 276-287.
[5] Vasehgi S V. State duration modeling in hidden Markov models[J]. Journal of Signal Processing, 1995, 41(1): 31-41.
[6] Lai W H, Chen S H. Analysis of syllable duration models for mandarin speech[C]//Proceedings of the IEEE International conference on Acoustic, Speech, Signal Process (ICASSP 2002). San Jose: IEEE Press, 2002: 497-500.
[7] WANG Zuo-ying, XIAO Xi. Duration distribution based HMM speech recognition models[J]. Chinese Journal of Electronics, 2004, 32(1): 46-49.
[8] Hon H W, Wang K S. Unified frame and segment based models for automatic speech recognition[C]//Proceedings of the IEEE International conference on Acoustic, Speech, Signal Process (ICASSP 2000). San Jose: IEEE Press, 2000: 1017-1020.
[9] GONG Yi-fan. Stochastic trajectory modeling and sentence searching for continuous speech recognition[J]. IEEE Transactions on Speech Audio Processing, 1997, 5(1): 33-44.
[10] WANG W J, CHEN S H. The study of prosodic modeling for mandarin speech[C]//Proceedings of the International Computer Symposium (ICS). Hualien: IEEE Computer Society Press, 2002: 1777-1784.
[11] �ϱ��, ��С��, ���ǽ�, ��. �����ڽӿռ��³������ʶ��[J]. ����ѧ��, 2007, 18(11): 878-883.
YAN Bin-feng, ZHU Xiao-yan, ZHANG Zhi-jiang, et al. Robust speech recognition based on neighborhood space[J]. Journal of Software, 2007, 18(11): 878-883.
[12] �����, �� ��, �� ǿ. ����ģ�����������������ʶ��[J]. �����ѧ��, 2006, 29(10): 1894-1900.
LIU Yu-hong, LIU Qiao, REN Qian. Speech recognition based on fuzzy clustering neural network[J]. Chinese Journal of Computers, 2006, 29(10): 1894-1900.
[13] �� �S, ���ľ�, �� ��. ���ں�����ʽ����ģ�͵ĺ����������ִ�ʶ��[J]. �����ѧ��, 2006, 29(4): 635-641.
TANG Yun, LIU Wen-ju, XU Bo. Mandarin digit string recognition based on segment model using posterior probability decoding[J]. Chinese Journal of Computers, 2006, 29(4): 635-641.
[14] �� ��, ������. ������������ʶ���в�ͬ��Ԫ��ѧģ�͵ĸ���[J]. ��������Ϣѧ��, 2006, 28(11): 2045-2049.
ZHANG Hui, DU Li-min. Combination of acoustic models trained from different unit sets for Chinese continuous speech recognition[J]. Journal of Electronics & Information Technology, 2006, 28(11): 2045-2049.
[15] �� ��, �� ��, �� ��. ����С�������Ĵ�ʻ㺺����������ʶ��ϵͳ³���Ե��о�[J]. ������Ϣѧ��, 2006, 20(2): 60-65.
YAN Long, LIU Gang, GUO Jun. A study on robustness of large vocabulary Chinese continuous speech recognition system based on wavelet analysis[J]. Journal of Chinese Information Processing, 2006, 20(2): 60-65.
[16] �����, ������, ������. �����źű����㷨����TMS320C5402ʵʱʵ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2004, 35(1): 117-121.
LIU Ou-geng, HE Su-liang, LONG Yong-hong. An algorithm for altering voice speed and its real-time realization based on TMS320C5402[J]. Journal of Central South University: Science and Technology, 2004, 35(1): 117-121.
[17] ������, �� ��, ������. ����CELP�����������ϵͳ����DSPʵ��[J]. ���Ϲ�ҵ��ѧѧ��: ��Ȼ��ѧ��, 2003, 34(4): 416-419.
QIN Ai-na, YANG Yong, CHEN Ming-yi. CELP based speech coding/decoding system and its DSP realization[J]. Journal of Central South University of Technology: Natural Science, 2003, 34(4): 416-419.
�ո����ڣ�2008-06-05�������ڣ�2008-07-28
������Ŀ��������Ȼ��ѧ����������Ŀ(60663007)�����ϴ�ѧ��ʿ���ѧ����������Ŀ(2007)
ͨ�����ߣ�Ԭ���(1973-)���У����������ˣ���ʿ�����ڣ�������Ϣ����������ʶ���о����绰��0791-3076768��E-mail: yuan_lichi@hotmail.com
