
���ڸĽ�InDBSCAN�㷨�����������������������������
�����У������ɣ��ź���������
(��̶��ѧ ��е����ѧԺ������ ��̶��411105)
ժ Ҫ��
������������⣬���������䴫�����ɼ�����ӹ������е��������źţ���ȡ��ʱ��ͳ�����������칤������źŵ����������������ܶȴ������Ŀռ����������㷨(InDBSCAN)�Թ�������е��������ź��������������������࣬�Է��������������������ǵ��������ݵ��ڴٳ����ഴ����ͬʱ���������Ѵ��ڵIJ�ͬ��ϲ���������Ľ�InDBSCAN�㷨��ʵ�����������Ľ���InDBSCAN�㷨ʹ�������ݵ������������Ӻ��������������ֲ�״�����ȷ�ʴ�84.03%��
�ؼ��ʣ�
������������������������������������������������
��ͼ����ţ�TP274+.3 ���ױ�־�룺A ���±�ţ�1672-7207(2012)02-0505-06
Incremental cluster analysis for batch drilling-quality based on improved InDBSCAN algorithm
ZHOU You-hang, DONG Yin-song, ZHANG Hai-hua, GUO Hui
(School of Mechanical Engineering, Xiangtan University, Xiangtan, Hunan, China, 411105)
Abstract: Aiming at monitor and analysis on batch drilling-quality, an acoustic emission sensor was used to collect the acoustic emission signal, extract statistic characteristics and then construct the signal characteristic vector. An improved incremental density based spatial clustering algorithm of time-domain applications with noise (InDBSCAN) was put forward to analyze the distribution law of batch drilling-quality indirectly. Take new data insertion into consideration. Because some of the original clusters could be remerged when the new cluster was created, and so the InDBSCAN algorithm was modified. The results show that the conclusion of incremental cluster analysis is more reasonable by the improved InDBSCAN algorithm and the detection accuracy of batch drilling-quality is up to 84.3%.
Key words: batch drilling; process quality; characteristic vector; incremental clustering; analytic hierarchy process
�ڸ߾��ȿ�ϵ������ӹ������У���α�֤������������ǻ�е�ӹ����̵���Ҫ���⡣������������������ⷽʽ�Բ��üӹ����죬Ȼ���������������ͳ�Ʒ��������������ֳ�췽ʽ�����⣬���Զ��������һ��⣬���ܴ�����������������Ŀǰ���Ը߾��ȿ�ϵ�����������������������о�һ����ô���������������̣������з���Ч�����ĵ��߲����Լ��Ľ���ͷ�Ľṹ����������ӹ��ȶ���[1-3]���������������Ƕ��������̵�һ�����ۣ������������г��ֵĸ�������������ء�Ӧ�ô����������������ʱ���������ź���Ϣ�ḻ�����������������ӹ����������Ϣ[4-7]��������ȡ����������ź��빤������������ص����ݣ����1�����ݿ⣬��ͨ�������������[8-10]�����ݿ��е����ݽ��з��࣬������������Ϊ�����࣬Ϊ�ӹ�������������������˹�����ṩ�������ݣ�����˹�����췽ʽ�����Ե����⣬ʵʱ���������������ķֲ����ɣ��ı�������������֤��������ļӹ�����������������������ӣ��������������ź����ݿ��е�����Ҳ�ڲ��ϱ仯��������ͨ�����㷨ʱ��ÿ����1�����ݣ��㷨��Ҫ���¼������е����ݣ����¾��࣬����ʱ�䳤������û������ǰһ�εľ�������Ϣ��InDBSCAN�㷨������������ݵ������˳���أ�������������У������ٶȽϿ�[11-13]����ˣ����㷨�����������������������������������������������У���ӹ������ϸ�ı���һ���ģ����ӹ���������ı������������Ĺ�ģ���仯���������е�InDBSCAN�㷨�У����µ����ݵ����ʱ�������ϲ������²���������ڴٳ����ഴ����ͬʱ�����ܻ������Ѵ��ڵIJ�ͬ��ĺϲ������⣬���������������ӹ���������У�������źŵ����ݵ�ֻ���ӣ���ɾ������ˣ��б�Ҫ��InDBSCAN�㷨���иĽ������⣬�����������ź����ݹ�ģ�൱��ֱ�ӶԼ���ź����ݽ��о������Ѷȡ�Ϊ�ˣ��������߶Լ���ź���ʱ������Ͻ���������ȡ����С���ݹ�ģ���������øĽ�����������InDBSCAN�㷨���������������������ķֲ���
1 ��������
Ӧ�������䴫�����ɼ������������̵��������źţ�����24������ʵ�顣ʵ���о���������£�
������lh=15 mm����f=6.5mm�������Ȧ�=130�㣻���г���ld=1.6mm��������f=30 mm/min������ת��r=500 r/min���ɼ���24���������������(A)�źţ����α��Ϊ1~24����ͼ1��ʾ��
�������̼���źſ��������£�
S=[S1��S2������SN] (1)
ʽ�У�Si��ʾ��i(i=1��2������N��N=24)�����ʵ���е��������ź�������
![]() (2)
(2)
Si,j��ʾ��i����ĵ�j(j=1��2������Mi)���������źŲ�������ֵ��Mi��ʾ��i������������źŲ����ܵ�����
1.1 ��������ź�������ȡ
����źŵ�����������ÿ���źž������ϰ���������㡣��ʱ������ϣ�������ȡ����������������������ԭ���ݡ�Ϊ�˳�ַ�ӳԭ���ݵ���������ÿ
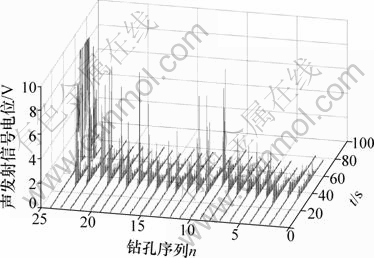
ͼ1 24���������ź�ʱ����ͼ
Fig.1 24 groups of acoustic emission signal waveform in time-domain
һ�����������������ź���ȡ����������ֵ�����ƫб�Ⱥ��Ͷȹ�5����������ÿ���ź���5���������ԣ���������������
![]() (3)
(3)
���У�xi,1Ϊ��i�������źŵľ������������źŵ�ǿ�ȣ�xi,2��i�������źŵľ�ֵ����ӳ�źŵľ�̬���֣�xi,3��i�������źŵı�������źŵ���ɢ�̶ȣ�xi,4��i�������źŵ�ƫб�ȣ���ʾ�źŷ�ֵ�ֲ��IJ��Գ��ԣ�xi,5��i�������źŵ��Ͷȣ���ӳ�źŵ������̶ȡ�
������ȡ��������ֵ�����������������������ڼ�����죬�����ֲ����Ծ��������ɲ���Ӱ��[8]��Ϊ�˱�������Ӱ�죬���������ݱ���[8]�������㷨���¡�
(1) �����ֵ����ƫ��S��i��
![]() (4)
(4)
���У�![]() Ϊ��i(i=1��2������24)����ĵ�f������ֵ��miΪ��5������ֵ�ľ�ֵ����
Ϊ��i(i=1��2������24)����ĵ�f������ֵ��miΪ��5������ֵ�ľ�ֵ����
![]() (5)
(5)
(2) ���������ֵ��
![]() (6)
(6)
���У�f=1��2������5, ��ʾÿ�����ݵ�5��������zi,f��ʾ��i(i=1��2������24)����ĵ�f������ֵ���������ֵ��
���ݱ����õ��������������źŵ������������ݿ�Ϊ��
![]() (7)
(7)
��24���������ź���ȡ�������������������������ֵ��ͼ2��ʾ��
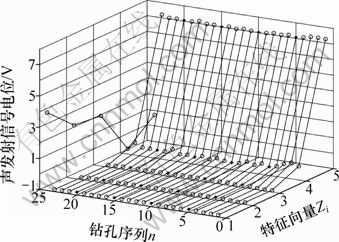
ͼ2 24���������ź����������ı���ֵ
Fig.2 Standardized value of characteristic vector for 24 groups of acoustic emission signal
1.2 ��������ź�����Ȩ�ط���
���������ݿ��У���������ֵ���ڲ�ͬ�����Ϸ�ӳ�������������ԡ�����ʵ��Ӧ���У����ֲ�ͬ���������Զ�ʵ�����������ķ�ӳ�̶Ȳ�ͬ�������Ͷȶ��ź��е�ͻ���ر����У�������ź�ͻ����ܱ�ʾ�������ϻ������б��ѵ��쳣�ķ��������������������������ϸ����ס�����������£�����ͬ���������µ�����źŵķֲ�Ӧ���ƣ���ͬ������������źŷֲ�����Ϳ���ƫб�ȼ�������������Ҳ�ɷ�ӳ�źŵ�ͻ�䣬�������г̶����Բ����Ͷȡ���ˣ��б�Ҫ�������������ݿ�Z�е�5����������Ȩ�ط��䡣���IJ��ò�η�����[14-15]��ʵ������Ȩ�صķ��䡣
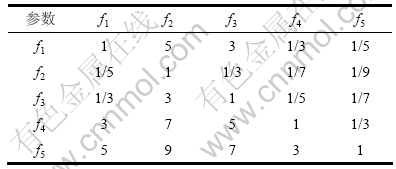
���ݲ�η�����������ʵ�ʹ��������з��ֵ��������źŸ�����Ӱ�������ӹ����������ϵ�����ȴ�������ź�����ָ��������жϾ���[14]����B={bi,j|i=1��2������5��j=1��2������5}����ʾ����ȡֵԭ��[14]���1��ʾ��
Ϊ�˱���Ӧ�ò�η�����������5������һ��ţ�f1-f5�ֱ��ʾ����������ֵ�����ƫб�Ⱥ��Ͷȡ���ˣ�A�ź�����ָ��������жϾ���B���2��ʾ��
Ϊ������Ϊ������ɵ�������Ҫ�����жϾ���B��һ���ԣ����鲽�����¡�
(1) �����Լ���ָ��CI��
![]() (8)
(8)
���У���maxΪ�жϾ���B���������ֵ��F=5Ϊ�жϾ����ά��������ɵæ�max��5.237 5������CI��0.059 4��
��1 �жϾ���ı�ȼ��京��
Table 1 Scale and meaning of judgement matrix

��2 A�ź�����ָ���жϾ���B��Ԫ��ֵ
Table 2 Element value in judge matrix B of A signal characteristic index
(2) ��ƽ�����һ����ָ��RI��������жϾ����ƽ�����һ����ָ��RI������ά������ ��[14-15]��RI��ȡֵ[14]���3��ʾ��
��3 ƽ�����һ����ָ��ȡֵ��
Table 3 Value of average random uniformity index

�ɱ�3��֪�������ж�ӦF=5ʱ��RI=1.12��
(3) ����жϾ���Bһ����ָ��CR��
![]() (9)
(9)
һ��أ���CR��0.1ʱ��������Ϊ�жϾ������������ȫһ�������������ڿ��Խ��ܵij̶�[14-15]�����жϾ���Bһ���Լ���ͨ����ȡ�жϾ�����������ֵ��Ӧ�������������ٶ��������������һ����������ɵó�A�źŵ�Ȩֵ������
![]() (10)
(10)
���Ȩ�����������Ϊ��
![]() (11)
(11)
���У�wk(k=1��2������5)ΪȨֵ����W�ĵ�k��Ȩֵ�����������о��������������������������Щ��Ȩ��������Ϊ�������ʵ�ֶ�����������������������ķ��ࡣ
2 �Ľ���InDBSCAN�㷨
InDBSCAN�㷨��������Ƕ����ݿ�Z�в��������ݵ������������������������Щ���ݵ�ֲ��ڸ�ά�ռ��У���ŷ�Ͼ���
![]() (12)
(12)
��Ϊ�����ݵ�֮�����ƶȵ����ȡ����У�zi��zj�ֱ�Ϊ24��������ݵ��е�����2�������㷨�Ӹı����״̬��������ڰ��������к��ĵ㿪ʼ���д���[15]���ٶ��²�������ݵ�ΪP�㣬���ȶ���һ�������m��m��Z��(Z��=![]() )�еĺ��ĵ㣬������Z�еĺ��ĵ㣬��m�����������ݵ�P�IJ�����ı����״̬�ĵ㣬m������1���㣬Ҳ�����Ƕ���㡣��ô����m�����ڰ��������к��ĵ�Ϊ{R}={q|q��Z��}�еĺ��ĵ㣬��D(q��m)�ܦ�}����Ϊ����뾶��
)�еĺ��ĵ㣬������Z�еĺ��ĵ㣬��m�����������ݵ�P�IJ�����ı����״̬�ĵ㣬m������1���㣬Ҳ�����Ƕ���㡣��ô����m�����ڰ��������к��ĵ�Ϊ{R}={q|q��Z��}�еĺ��ĵ㣬��D(q��m)�ܦ�}����Ϊ����뾶��
��1����ά���ݿ�Ϊ��������С���ϵ���Ϊ5ʱ������[11]�����ݵ�P���뵽���ݿ��������ܲ����Ľ����Ϊ4�֣���ͼ3��ʾ�����У�P����ʵ�������α�ʾ�����������ʵ��Բ���ʾ��
���㷨��ƹ����У����ֻ���1�����û�б����ǣ������²��������P���ڴٳ����ഴ����ͬʱ�����ܻ������Ѵ��ڵIJ�ͬ��ĺϲ�����ͼ4��ʾ�������ݵ�P����֮ǰ����D����������B1��B2���DZ߽�㡣����InDBSCAN���ඨ��Ϊ�����ܶȿɴ��Ե������ܶ���������ļ��ϣ����Դ�ʱB1��B2�ֱ�����2����ͬ�ľ���C1��C2����D�㼰�������ڵ������㲻�����κ�һ�����ࡣ�����ݵ�P����֮��D��B1��B2�����������ڵ����ݵ�����ͬʱ�ﵽ���ٵ���Ŀ��Ҫ���ת��Ϊ���ĵ㣬��P�������������ڵ����ݵ���С��������Ŀ�����Ǻ��ĵ㣬���Դ�����DΪ���ĵ�����ࡣ��ʱ�����ڵ�B1��B2�½����������֮���ֱ���ܶȿɴ��ԣ���ʹ��C1��C2�е��������ݵ����Ϊ���ܶ���������2������ϲ�����������������ֻ���ǵ���D��Ϊ���ĵ������Ĵ�������ô�ͻ���Ե�C1��C2 2��������ĺϲ����Ӷ���ɱ�Ӧ��ͬһ���е����ݵ�ķ��룬�ڱ��ĵ�Ӧ���У��������������������Ŀױ��ֵ���2����ͬ�����С���֮�����ֻ���ǵ�2��������ĺϲ�����ô����Ӧ���������е����ݵ�ȴ��Ȼ�����������㡣����㷨û�п��������������ô�����ݵ������˳��ͬʱ���Ϳ��ܻ������ͬ�ľ����������㷨�������ݵ�����˳���йأ��Ӷ�ʹ������в�ȷ���ԡ�
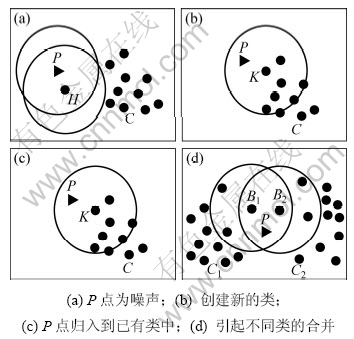
ͼ3 �������ݵ�Pʱ���ܲ�����4�־�����
Fig.3 Four possible cluster results generated while inserting new data P
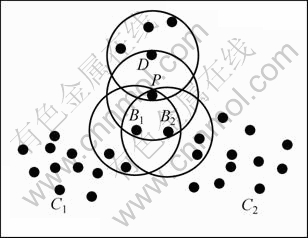
ͼ4 ���������ͬʱ�ϲ�������
Fig.4 Clusters merge while new cluster being created
3 �����źŵ������������
3.1 InDBSCAN��������
�ֱ�ʹ��2�ַ���(ԭ�еĺĽ���InDBSCAN�㷨)��24����������������������1.0��105���������࣬ÿһ�ε�������������˳���Ϊ������ɡ��������������1.0��105�����������У��Ľ���InDBSCAN�㷨ֻ����ͬ1�־�����(���4��ʾ)����ԭ�е�InDBSCAN�㷨�������2�־�����(���5��6��ʾ)��
�ɱ�4~6��֪�����0�е����ݵ�Ϊ�����㡣�ɱ�5��6��֪��ʹ��ԭ�е�InDBSCAN��24�����������������������������࣬����������������˳��IJ�ͬ���������ͬ�ľ��������ڱ�6��ʾ�ľ������У������˺��Ե�������ϲ�����������ѱ�Ӧ���ڵ�1��ĵ�10��12��14��15����������������ݵ���Ϊһ��������������˳�����
��4 �Ľ���InDBSCAN����������
Table 4 Incremental clustering results of improved InDBSCAN

��5 ԭ�е�InDBSCAN����������(No.1)
Table 5 Incremental clustering results (No.1) of original InDBSCAN
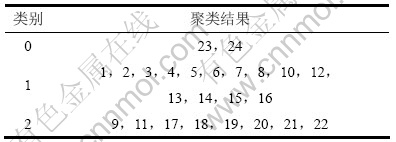
��6 ԭ�е�InDBSCAN����������(No.2)
Table 6 Incremental clustering results (No.2) of original InDBSCAN

3.2 ����������
3.2.1 ������ȷ�ʷ���
����ȷ�ʶԾ�������������[16]��ȷ�ʿ��Ա�ʾ��������ȷ�̶ȣ���ֵԽ�ߣ���������ʵ�ʽ��Խ�ӽ���Ϊ�˶ԸĽ���InDBSCAN�㷨����������������ȷ���������ۣ���24��������ν����˹�����������⣬���������7��ʾ��
��7�У�A����Ϊ������������ף�B����Ϊ�ϸ��Ʒ��C����Ϊ���ϸ��Ʒ����24�ſ����������У��껨�������ر��У�����û�м������С�23������ڱ���������ء�
���㷨�������õ�������ֻ࣬�ǰѲ�ͬ���������������ֿ���������ȷ������ijһ�������������ˣ�ȷ����������������˹������ӳ���ϵ�DZ�Ҫ�ġ������������Ϣ�����е�F-measure����[16]��ʵ����һ�㡣F-measure�����ۺ���Ϣ�����еIJ��ʺͲ�ȫ�ʵ�˼��Ծ������������ۣ��������¡�
��7 �����������������˹������
Table 7 Manual inspection results of batch drilling-quality

���ʣ�
![]() (13)
(13)
��ȫ�ʣ�
![]() (14)
(14)
���У�i=A�䣬B�䣬C�䣬��ʾ�˹���������j=0��1��2��ʾ�㷨����ķ�������Ni,j��ʾ����j�з���i����Ŀ��NiΪ����i�����ж������Ŀ��NjΪ����j�����ж������Ŀ������i��F-measureֵ����Ϊ��
![]() (15)
(15)
�Է���i���ԣ��ĸ�����j��F-measureֵ�ߣ�����Ϊ�þ���j�Ƿ���i��ӳ���������InDBSCAN�㷨���������1�����˹�����A��ľ���ӳ�䣬��Ӧ�أ����2�Ƿ���B��ľ���ӳ�䣬���0�Ƿ���C��ľ���ӳ�䡣���棬ͨ��2��������������������ȷ�ʡ�
(1) ������������ȷ��Pk��
![]() (16)
(16)
���У�NkΪInDBSCAN���������k������ĸ�����RkΪ���k����������������Ӧ���˹������������ͬ�ĸ�����k=0, 1, 2��
(2) ������������ȷ��PG��
![]() (17)
(17)
���У�NC=3ΪInDBSCAN�㷨�������������������ɵã���������ľ�������ȷ��Ϊ84.03%��
3.2.2 ��������Ⱥ�����
�ӱ�3�ͱ�6�ķ����ʶ�������˹�������23�š�24�Ų��ϸ�ף���InDBSCAN��������Ҳͬ���������ϸ�ľ����з���������ɴ˿�����InDBSCAN���кܸߵ���Ⱥ�������ܡ��������������ӹ���������У�ֻҪ�в��ϸ�ײ��������ᱻ��ʱ��������Ȼ���ȡ��Ӧ�Ĵ�ʩ���Ա���������ʧ���֡�
4 ����
(1) ���ڸĽ���InDBSCAN���ǵ������ݵ����ʱ���ܲ���������������ɴ��㷨���ý������������˳���ء�
(2) ʹ����������������������źŽ��з���������Чʵ�������������������ֲ��ķ������÷�����Ϊ��������������������һ����������ṩ��˼·�����ۻ�����
�ο����ף�
[1] XU Xu-song, Cao YAN-long, YANG Jiang-xin. Condition monitor of deep-hole drilling based on multi-sensor information fusion[J]. Chinese Journal of Mechanical Engineering, 2006, 19(1): 140-142.
[2] Kim D W, Lee Y S, Park M S. Tool life improvement by peck drilling and thrust force monitoring during deep-micro-hole drilling of steel[J]. International Journal of Machine Tools & Manufacture, 2009, 49(3/4): 246-255.
[3] Rivero A, L��pez de Lacalle L N, Luz Penalva M. Tool wear detection in dry high-speed milling based upon the analysis of machine internal signals[J]. Mechatronics, 2008, 18(10): 627-633.
[4] ����ƽ, ������, ������. ��������������ھ������ڻ�е������������е�Ӧ��[J]. ���ն���ѧ��, 2008, 23(10): 1933-1938.
SHAO Ren-ping, HUANG Xin-na, HU Jun-hui. Analysis of data mining of clustering and its application to mechanical transmission fault diagnosis[J]. Journal of Aerospace Power, 2008, 23(10): 1933-1938.
[5] ZHOU You-hang, ZHANG Jian-xun. Analysis of Relationship between batch drilling process and Multi-Sensor Synchronization Signals[C]//Proceedings of International Conference on Measuring Technology and Mechatronics Automation, 2009: 127-130.
[6] ������, �Ž�ѫ, ����ׯ. ����˲̬�������������������ź�ӳ��ģ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2010, 41(3): 971-976.
ZHOU You-hang, ZHANG Jian-xun, TANG Wen-zhuang. Mapping between phases and signals in drilling process based on transient features of signals[J]. Journal of Central South University: Science and Technology, 2010, 41(3): 971-976.
[7] Singh R, Khamba J S. Comparison of slurry effect on machining characteristics of titanium in ultrasonic drilling[J]. Journal of Materials Processing Technology,2008, 197(2): 200-205.
[8] Han J W, Kamber M. �����ھ�: �����뼼��[M]. ����, ��С��, ��. 2��. ����: ��е��ҵ������, 2007: 251-301.
Han J W, Kamber M. Data Mining: Concepts and Techniques(Second Edition)[M]. FAN Ming, MENG Xiao-feng, translate. 2nd ed. Beijing: China Machine Press, 2007: 251-301.
[9] �˶�÷, ������, ������. һ�ֽṹ��Web�ĵ������Ͼ����㷨[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2010, 41(5): 1871-1876.
DENG Dong-mei, LONG Ji-zhen, YIN Xiang-zhou. A co-clustering algorithm based on structured Web document[J]. Journal of Central South University: Science and Technology, 2010, 41(5): 1871-1876.
[10] HU Rui-fei, YIN Guo-fu, TAN Ying. Cooperative clustering based on grid and density[J]. Chinese Journal of Mechanical Engineering, 2006, 19(4):544-547.
[11] Ester M, Kriegel H-P, Sander J, etc. Incremental Clustering for Mining in a Data Warehousing Environment[C]//Proceedings of 24th International Conference on Very Large Data Base. New York: USA, 1998: 323-333.
[12] Ester M, Kriegel H P, Sander S, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. Portland, USA, 1996: 226-231.
[13] ���»�, л����. ������������������DBSCAN�����㷨�о�[J]. �������칤ҵѧԺѧ��, 2006, 16(2): 15-17.
XU Xin-hua, XIE Yong-hong. Summarization on incremental clustering and research of incremental DBSCAN algorithm[J]. Journal of North China Institute of Astronautic Engineering, 2006, 16(2): 15-17.
[14] ������, �Ա�, ������. ���ڲ�η�����ģ����ѧ�IJɿ�ѡ��[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2008, 39(5): 875-880.
WANG Xin-min, ZHAO Bin, ZHANG Qin-li. Mining method choice based on AHP and fuzzy mathematics[J]. Journal of Central South University: Science and Technology, 2008, 39(5): 875-880.
[15] DONG Yu-chen, ZHANG Gui-qing, HONG Wei-chiang, et al. Consensus models for AHP group decision making under row geometric mean prioritization method[J]. Decision Support Systems, 2010, 49(3): 281-289.
[16] ����, ��ެ, ��. ������Ч����������[J]. �����Ӧ���о�, 2008, 25(6): 1630-1632.
YANG Yan, JIN Fan, et al. Survey of clustering validity evaluation[J]. Application Research of Computers, 2008, 25(6): 1630-1632.
(�༭ ������)
�ո����ڣ�2011-02-08�������ڣ�2011-05-04
������Ŀ������ʡ��У����ƽ̨���Ż���������Ŀ(10K063)����������ѧ�ع���Ա������������������Ŀ(2009-1590)������ʡ��Ȼ��ѧ����ʡ�����ϻ���������Ŀ(10JJ9005)
ͨ�����ߣ�������(1971-)���У�����˫���ˣ���ʿ�����ڣ��������ֻ�������̻�е�����о����绰��0731-58292222��E-mail��zhouyouhang@xtu.edu.cn
ժҪ���������������������������⣬���������䴫�����ɼ�����ӹ������е��������źţ���ȡ��ʱ��ͳ�����������칤������źŵ����������������ܶȴ������Ŀռ����������㷨(InDBSCAN)�Թ�������е��������ź��������������������࣬�Է��������������������ǵ��������ݵ��ڴٳ����ഴ����ͬʱ���������Ѵ��ڵIJ�ͬ��ϲ���������Ľ�InDBSCAN�㷨��ʵ�����������Ľ���InDBSCAN�㷨ʹ�������ݵ������������Ӻ��������������ֲ�״�����ȷ�ʴ�84.03%��
