
DOI�� 10.11817/j.issn.1672-7207.2019.06.016
����������չʾЧ���Զ����۷���
�Ż�,����ƽ
���廪��ѧ �������ѧ�뼼��ϵ�����ܼ�����ϵͳ�����ص�ʵ���ң����� 100084��
ժ Ҫ��
������������Ӿ�������Ϣ������Ч����3��ά��15�����ص��������չʾЧ��������ϵ�����Զ�������ͳ���ı����չʾЧ����ʵ�����������÷����ܹ����˹��������û��ܿ�ʵ��ȡ��һ�µ�����Ч�������������������������Դ���������۷������ڡ�
�ؼ���:����������ҳ�棻���������չʾЧ�����Զ�����
��ͼ�����:TP391.1 ���ױ�־��:���ױ�ʶ��:A ���±��:1672-7207��2019��06-1378-06
Automatic evaluation method of search snippet presentation performance
ZHANG��Hui, MA��Shaoping
(State Key Laboratory of Intelligent Technology and Systems, Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China)
Abstract: According to the questionnaires and interviewers, a snippet evaluation system for the search snippet presentation performance was put forward, including 15 factors in 3 dimensions, such as attractiveness, informativeness and effectiveness. The presentation performance of the traditional text snippet was evaluated automatically. The experimental results show that this automatic method can achieve a similar result with manually annotated evaluation and users�� experiments. It can also reduce the human resources needed for evaluation and shorten the evaluation feedback cycle.
Key words: search engine result page (SERP); search snippet; presentation performance; automatic evaluation
����������Ϊ����������Ϣ��Դ����Ҫ�Ĺ��ߣ������ǵĹ�����ѧϰ�������з�����������Ҫ�����á�������������û��ύ�IJ�ѯ���ݣ���������������ҳ��(search engine results page��SERP)����ͨ������1�����͵���������б���ÿ����������������⡢ժҪ����ַ���ı���Ϣ�������������漼���ķ�չ��Ҳ���ܰ���ͼƬ����Ƶ��ͶƱ�ȸ������Ϣ[1]��SERP���Կ���ԭʼ�ĵ��ġ���ժ��(abstract)����ժҪ��(summary)���ߡ�Ƭ�Ρ�(snippet)���û�����ԭʼ�ĵ�һ����֪��ֻ�ܸ��ݿ�����������������Ķ�����֪���жϡ���ˣ��������������ֱ��Ӱ���û���������������[2-3]��Ϊ�����û�����ע�����������û���ע����Ҫ�����ݣ�����������������ͻ�Լ������������Ӳ�ͼ��ͼ�ꡢ�ı���ǻ���ӻ���[4-5]���������о�������������������ı�������������û��ѧ��������������ı����ַ�ʽЧ���������о��ص�Ϊ��ȷ���IJ�ѯ���������������£���ۺ����Զ������۲�ͬչʾ����(��ʽ)�����ӣ���ͼ��ע������������Ķ�����棬�����ݡ�չ����ʽ���ḻ�����������������ϵ���걸�ԣ������û�����ͷ�̸������Ӿ�������Ϣ������Ч����3��ά�ȵĽ��չ��Ч��������ϵ������3��ά�Ȳ����������ض��IJ�ѯ������ʵ����ʾ�÷������ڴ�ͳ�ı����������չʾЧ�����۷��棬���˹���ע������û�A/Bʵ�������нϸ�һ���ԣ���˸÷������н�ǿ�Ŀɲ����ԣ����⣬ʹ�ö���ع����ģ��(ordinal logistic regression model��OLRM) �������о���3��ά�ȵ���Ҫ�ԡ�
1 ����о�
�����������ʾ����ͼ1��ʾ�������û��Ķ������������ʱ����ס�����ݣ�ѯ��������Ϊ������������Ƿ����ѯ����֪��������أ�����ѯ���Ƿ�������������������ʾ������ͼ1(a)��ʾ�������ʱ��95%�û���Ϊ����������ѯ��ز��һ���������ס����3������Ϊ����֪��������ɸѡ���͡���Ϣ����������ͼ1(b)��ʾ�������ʱ��ֻ��40%�û���Ϊ����������ѯ��ز����������ס����3�������ǡ��ĵ�������ҡ��͡������ߡ������Կ�������ʹ��ͬ���ı����ݣ����ò�ͬ���ı�ͻ�Լ�������չʾ��Ч���Լ������û��ĸ����Dz�ͬ�ģ���Ӱ���û��ж�����Ժͻ�ȡ��Ϣ��

ͼ1���ı��������ʾ��
Fig. 1��Example of a snippet
���������ժҪ�����������о������Ѿã��������������ժҪ�Ĺ��̿���ԭʼ�ĵ������Զ���ժ�Ĺ��̣������ı��Զ���ժ���۷���Ӧ�õ���������Ҫ����2�ַ�����һ��ֱ�����˹��γɵı���ժ���жԱȣ�ͬʱ���۸���ժ���ݵ������Ժ���������ԣ�����Ӧ�ù㷺��ΪLIN��[6-7]�����ROUGE����������������������ۣ����������ժҪ����1����������������У��Ƚϲ�ͬ�������ժҪ�ľ�����֣���������û�������Ϊ��������ȵ�Ӱ��[8-9]����2�����۸�����ȱ�㣬��������������ı����ݵ��������棬�����ۺ����á�
����SERPչʾ���о���Ҫ������ҳ��Ҫ�ز��֡���С�Լ����з�ʽ�������û�������Ϊ��Ӱ�죬һ��ͨ�������ܿص��û�ʵ�������ʵ���û�������־���ݽ����о�����[10-12]����Щ�о������ں�۵�����SERP��ʾ���ԣ���û���ص��о��������������չʾ���ԡ��������о�������Բ�ͬ��ͻ�Բ����£��������������չʾ��ʽ���û��������̵�Ӱ�졣����ͬ�����ı����ݣ�ѡ��ͬ��ͻ�Բ��ԣ�������û��������̲��������Ӱ�죬SERP����Snippet��ͻ�Ա����������������࣬���ή���û�����Ⱥ�����Ч��[13]��
�������ժҪ�����۲����������ݵ�����[14-16]�����Ұ���չʾ��ʽ�����ۣ�����������ʵ��ӳ1����������û���ʵ�ʸ��ܺ���֪��һ�¡�������Ŀǰ����2���������ս��һ�ǿ�ѧ����ȷ�ض��塰�õĽ�����dz����ѣ����ĵ��о�����������۵�˼�룬�����������ۺ�չʾ��ʽ����֮�����������������������ۻ���Ϊ���ݵ����ۺͻ�����ͬ���ݵ�չʾ��ʽ���ۣ������������ժҪ��������������ѯ������أ��������ڲ�ѯ��ԭʼ�ĵ���ȷ��������£����ܽ������ۣ���û���û���ѯʱ�������۱�ʧȥ���塣���Ľ�������������۷�Ϊ2�������������۵Ļ����ϣ�������ͬ���ݿ�չ�������չʾЧ�������ۣ���Ȼ�����յ��������ۻ���һ���ľ��룬��������Ŀǰ���еķ�����
2 ������ϵ���Զ������㷨
�û��ܿ�ʵ������˹���ע��Ҫ�ķѴ����������������������ڴ��ܹ����Զ��������㷨�����㲢�Ƚ�2�ֲ�ͬ��������������ܽ�ǰ�˹��������������ժҪչ��Ч����ص����أ�Ȼ������û��ڰ�����ͱ�ע��������û�����ͱ�ע�Ľ���뾭��ʹ�����������ʵ���û���רҵ����ҳ����߽��з�̸��ȷ��Ӱ���������ժҪ���ַ�ʽ��15�����أ����1��ʾ��
��1���������չʾЧ��������ϵ
Table 1��Snippet presentation evaluation system

�������о��ɹ��ͱ��Ŀ�չ���û���ע�����ʾ���û���Ϊ��������к�����ص���Ƶ���ͼ�����ʵ��ı�ͻ�Ա������ḻ���ı�ͻ����Ϣ�Լ����ŵ�������Դ�ܹ������û����Ķ�����֪���飬�����Ϣ�ļ���Ч�ʡ�
�����������������ѯ������������ݶ�ȷ��ʱ��2�������չʾ������ҪԴ��ͻ�Բ��ԵIJ��졣Ŀǰ����������������������ı�չʾ���棬ͨ�����ò�ѯ�ʱ���ͻ�Բ��ԣ����Խ���1��������Ϊ���ջ�������չ����ʽ�����ӣ�һ�ַ����ǶԱȲ��ջ��������˹���ע�����û��ܿ�ʵ�飬���Ե���������һ�ַ����Ǹ��ݱ�1�����Ӱ�����أ�������չʾЧ���÷֣��Զ���������������
����������ϵ���Ӿ����е�ÿ�����أ��������Ϊ���ǡ�����1�֣������0�֡����ĵ��о��ص��Ǵ��ı����������չʾЧ����ͳһ����û����Ƶ�Ͳ�ͼ������������Ӿ����÷ֶ�Ϊ0�����Ժ��Բ��ơ�������Ϣ��������ѯ��𰸰��������������ƽ������ԡ�����Լ������Word2Vec�㷨(https://code.google.com/p/word2vec/)����SogouT���ݼ�(http://www.sogou.com/labs/dl/t-e.html)ѵ���õ��������������Ϊ���������������ƶȵ÷֡������֪���𰸻��Ϊ�գ������Ϊ0�֡����ʵı������������ܹ������û�ע�������������û��������ţ���Ӧ����һ�����䣬��������ȡ1�֣�����ȡ0�֡������û���ע�Ľ�������IJ��õı����������Ϊ[2,7]������������Ϊ[10%,20%]��ͻ�����ݵĿɶ��Կ��Բ������Ĵ�����Ѷȵȼ������ִʵ������Լ��Ǻ����ַ����������㣬���ҽ���(0,1)��һ�������������Ѷȵȼ����ݡ�����ˮƽ�ʻ��뺺�ֵȼ���١�������δ��¼����ͺ��֣�������Ѷȵȼ����㡣������Ч�����������Ϊ���ǡ�����1�֣������0�֡�����Ȩ����Ϊ����վ������������������(0,1)��һ�����������3��ά�ȵ÷ֽ��м�Ȩƽ��������ѡ�õļ�Ȩϵ����Ϊ1/3�����յõ��������������չʾЧ���÷֡�����ͼ1�е�2��չʾ��������չʾЧ���÷ֱַ�Ϊ0.23��0.07��ͼ1(a)��ʾ��ͻ���������ѯ����ز��ҿɶ��Ը�ǿ��
3 ʵ�����ͷ���
3.1��ʵ�����ݡ�
���������û��ύ��ѯ���Թؼ���Ϊ��������93.15%�IJ�ѯ����3��[17]��ѡȡNTCIR Imine[18]�е�12�Թ�24�����IJ�ѯ������2��(4��)�������ѯ(navigational tasks, NA)��2��(4��)�������ѯ(transactional tasks, TR)��8��(16��)��Ϣ���ѯ(informational tasks��IN)��ÿ������IJ�ѯ��������,�Ѷ��൱���������������Google�������棬ȥ��SERP�к���ͼƬ����Ƶ�ȵĴ�ֱ�������ѡȡ�������ı���ǰ10����������յõ�24����ѯ�Ͷ�Ӧ��240�����������
��Google��������չʾ�����������Ϊ�ԱȻ�����ΪP1��Ϊ��P1���жԱȣ��˹���ע��һ�����������չʾ��ʽ����ΪP2�������ṩ���û���ѯ����˵������ѯ�Լ����κ��ı�ͻ��Ч����������������û�������������Ͳ�ѯ�����⣬��ע��Ҫ�ġ�����������������м�ֵ�ġ��ñ�ͻ�ԵĴ�/���ÿ�������������10���û���ע����ij�����ﱻ4�������û���עΪͻ�Դʣ��������ͻᱻͻ����ʾ����ô�趨����Ϊ����Googleͻ�Բ��Ա�������ı�������
3.2��Ӱ��������Ҫ�Է�����
Ϊ������ͬά�ȶ������������Ч����Ӱ��̶ȣ�ʵ��Ҫ���ע�û���P2������240����������ij���Ч�������������Լ�����Ϣ������Ч�������ֱ���(�Ӿ���ά�ȵ÷�ȫ��Ϊ0)������Ϊ0��3��4��(����3��ʾ����Ч���dz��ã�0��ʾ����Ч������)��������4����ע�ߣ���ע��֮���ƽ��kappaϵ��Ϊ0.507������һ���е�һ�µĽ��[19]��
ʹ��ʽ(1)��ʾ��OLRMģ��[20]��������ϵ��2��ά�Ⱥ��ܵ÷ֵĹ�ϵ���з�����

ʽ�У�OverallΪ�������Ч���÷֣�jΪ����Ч�������п��ܵ÷ֳ�����ȡֵΪ[1,3]��X1��X2�ֱ�Ϊ��Ϣ������Ч��ά��������

��2����ע����ع����
Table 2��Regression analysis of annotated results

������ϳ���ģ�ͣ�������Ҫ���ĵ��Dz�ͬά��������Ӧ����Դ�С��ֵ��ע����ǣ���ͬ�ı�ע����ϵĦ�֮�䲻��ֱ�ӽ��бȽϡ��ӱ�2���Կ�����������Ӧ��p��С��0.01��˵����2��ά������������������ճ���Ч����������Ӱ�죻���Ӧ�Ħ¾�Ϊ��ֵ��˵����Щ���������Ч��������صġ���Ϣ�������Ħ½ϸߣ�˵������ı������ժҪ���ݵ�ͻ��Ч���������Ϣ��Դ�����ߵȸ�����Ϣ�Ǹ�����Ҫ��������
Ϊ�˽�һ������15����������Ҫ�ԣ�����һ�ּ�ֵķ���������ʽ(2)����÷�G��������������k������������

ʽ�У�


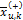



��������������G���3��ʾ������������1һ�¡��ӱ�3���Է��֣�������8����������һ�������������������ߵ�3������������Ϣ����ά�ȣ��ֱ�Ϊ����ͻ�Դ����ѯ������ԡ�ժҪ��ͻ�Դʵ������Լ�ժҪ��ͻ�Դ����ѯ������ԡ�
��3������������Ӱ����G
Table 3��Influence G score of characteristic parameters

3.3�����˹������һ���ԶԱȡ�
��24����ѯ��240����������γ�10�ݵ����ʾ���ÿ���ʾ���Ӧ24�����⣬��ͼ2��ʾ��ÿ�������Ӧһ����ѯ��ͬһ�����������2�ֲ�ͬչʾ��ʽ�������ڶ��û������˹����⣬ѡ���������ʾ��ʽ�������⡣�Է�ʽһ�ͷ�ʽ����ѡ�������������á�
��ÿ���ʾ����ռ�100��ʹ���������泬��3����ѧ��Ϊ�������ϵ��û����ݣ�������Ӧÿһ����ѯ(�������)������100���˹����������ȡ�

ͼ2��������˹���������ʾ�ʾ��
Fig. 2��An example of satisfaction questionnaire
����240��������������ݵ����ʾ�����������û�����P1����P1��1�֣���P2��0�֣�����P1��0�֣�P2��1�֡�������������ͬ����1�֡����ڶ���240����������������Զ������㷨���õ�P1��P2չʾЧ���÷֣���P1>P2����P1��1�֣�P2��0�֣�����P1��0�֣�P2��1�֡�������������ͬ����1�֡������Զ��㷨�õ��Ľ�����˹�����õ�����������ϵ����P1������Spearmanϵ��Ϊ0.853��P2������Spearmanϵ��Ϊ0.859��˵�����ñ���������Զ��㷨�Դﵽ���˹����������ˮƽ��
ÿ����ѯ��SERP��10������������û�����SERP������Ȳ���10�����������ƽ������ȣ�ͳ�ƽ����ͼ3��ʾ��
ƽ��47%�û�����P2��չʾ��ʽ������P1���û�����24%��������29%�û���Ϊ��������Ӧ24����ѯ����SERP���û�����������18��ʹ��P2չʾ���Ե�SERP��4��ʹ��P1չʾ���Ե�SERP��������2��SERPʹ��2��չʾ���Ը��û��ĸо����ͼ3���Կ�������������������ԣ�P2��P1���á����Ƕ���ijһ������˵�����ֲ��Ը����Dz�ȷ���ģ���Ҳ˵��չʾЧ�����ѯ������ء�

ͼ3��SERP�����ͳ�ƽ��
Fig. 3��SERP satisfaction statistics results
3.4�����û�A/B����ʵ��һ���ԶԱȡ�
���Ŀ�����ʵ�������������������������������ܣ�ͬʱ��¼�û�����꽻�����ݡ����Ĺ�����12�����������2��չʾ�Ķ���ʵ�飬ÿ�����24����ѯ������12����ѯ����P1չʾ������12������P2չʾ������ϣ������������������еķ�������֤ÿ����������ͬ�ĸ���չ�ָ��û�������ÿ��չʾ�µ�ÿ���������ռ���6���û����������ݣ�ͳ�ƽ�����4��ʾ�����У��������½���ͳ��������ָ��p<0.1�������P1��չʾ���ԣ�P2չʾ�����£��û��Ķ�ժҪ��ʱ����̣����ҵ�����������Ⱥ�������������Լ��٣�˵���û����Ѹ��ٵ�ʱ����ܻ�
������Ľ����������������Ч�档��ˣ�P2�DZ�P1���õ�ͻ�Բ��ԡ������˹�������Զ�����õ��Ľ�����һ�¡�
��4���û�A/B����ʵ����
Table 4��User A/B test experimental results

4 ������չ��
1) ����Ϣ�������������ʱ���������ʺ���������ʵ��Ӧ�û������������������ϵ���Զ������㷨��Ϊ��Ϣ�����������Ҫ�о����⡣�������һ���ۺϿ����Ӿ�������Ϣ������Ч����3��ά�ȹ�15��ָ����������չʾЧ��������ϵ������ϵ���н�ǿ�Ŀɲ����ԣ����˹���ע������û�A/Bʵ����ȡ������һ�µĽ��ۣ�ʹ�����ع�ģ����Ͻ����ʾ����Ϣ������Ч���������������չʾЧ��������Ӱ�죬����Ϣ����Ӱ�����
2) ���������չʾЧ����������һ�����ӵ���������ʵ�ʲ�ѯ�������͡��������Ϣ��������أ���һ������ϲ�ѯ�������������ͣ�����������ϵ����ȡ���ʵĿ�������ʵ������������չʾЧ�����Զ����ۡ�
�ο����ף�
[1] CHEN Ye, LIU Yiqun, ZHOU Ke, et al. Does vertical bring more satisfaction?: Predicting search satisfaction in a heterogeneous environment[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. ACM, Melbourne, Australia,2015: 1581-1590.
[2] LI Kang, LI Yi, RICHARD Q.Disambiguating intents within search engine result pages: U.S. Patent 9183310[P]. 2015-11-10.
[3] LURIE E, MUSTAFARAJ E. Investigating the effects of Google's search engine result page in evaluating the credibility of online news sources[C]//Proceedings of the 10th ACM Conference on Web Science. New York, USA: ACM Press, 2018: 107-116.
[4] PARTHASARATHY S K, AHMED J, SARAF Y, et al. Clustering web pages on a search engine results page: U.S. 9842158[P]. 2017-12-12.
[5] CUTRELL E, GUAN Zhiwei. What are you looking for?:an eye-tracking study of information usage in web search[C]// Conference on Human Factors in Computing Systems, CHI 2007, California, USA: DBLP, 2007: 407-416.
[6] LIN Chinyew, OCH F.J. Looking for a few good metrics: rouge and its evaluation[C]// Proc of the Ntcir Workshops, Tokyo, Japan. 2004:1-8.
[7] LIN Chinyew, HOVY E. Automatic evaluation of summaries using N-gram co-occurrence statistics[C]// Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology. Association for Computational Linguistics, Edmonton, Cadana, 2003:71-78.
[8] MURRAY G, KLEINBAUER T, POLLER P, et al. Extrinsic summarization evaluation: a decision audit task[J]. Acm Transactions on Speech and Language Processing, 2009, 6(2):1-29.
[9] OVER P, DANG Hua, HARMAN D. DUC in context[J]. Information Processing & Management, 2007, 43(6):1506-1520.
[10] RELE R S, DUCHOWSKI A T. Using eye tracking to evaluate alternative search results interfaces[J]. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 2005, 49(15): 1459-1463.
[11] KAMMERER Y, GERJETS P. How the interface design influences users' spontaneous trustworthiness evaluations of web search results: comparing a list and a grid interface[C]// Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications. New York, USA: ACM Press, 2010: 299-306.
[12] OSTERGREN M, SEUNG-YON Y, EFTHIMIADIS E N. The value of visual elements in web search[C]// Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM Press, 2010: 867-868.
[13] �Ż�, ����, ����Ⱥ, ��. �ı�Ʈ����Զ����������û���Ϊ��Ӱ��[J]. �廪��ѧѧ������Ȼ��ѧ�棩, 2018, 58(8): 703-709.
ZHANG Hui, SU Ning, LIU Yiqun, et al. Effect of snippet text bolding in search user behavior. Journal of Tsinghua University (Science and Technology), 2018, 58(8): 703-709.
[14] SAVENKOV D, BRASLAVSKI P, Lebedev M. Search snippet evaluation at yandex: lessons learned and future directions[C]// International Conference of the Cross-Language Evaluation Forum for European Languages. Heidelberg,Berlin: Springer, 2011:14-25.
[15] MARCOS M C, GAVIN F, ARAPAKIS I. Effect of snippets on user experience in web search[C]// Proceedings of the XVI International Conference on Human Computer Interaction. New York, USA, ACM, 2015:47-55.
[16] AGEEV M, LAGUN D, AGICHTEIN E. Towards task-based snippet evaluation: preliminary results and challenges[C]//MUBE (SIGIR Workshop), Dublin, Ireland, 2013: 1-2.
[17] ��ۼ�, ����Ⱥ, ����,��. ���ڴ��ģ��־���������������û���Ϊ����[J]. ������Ϣѧ��, 2007, 21(1):109-114.
YU Huijia, LIU Yiqun, ZHANG Min, et al. Research in search engine user behavior based on log analysis[J]. Journal of Chinese Information Processing,2007, 21(1):109-114.
[18] LIU Yiqun, SONG Ruihua, ZHANG Min, et al. Overview of the ntcir-11 imine task[C]// Proc. 11th NTCIR Workshop Meeting, Tokyo, Japan,2014: 8-23.
[19] COHEN J. Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit[J]. Psychological Bulletin, 1968, 70(4):213-220.
[20] KLEINBAUM D G, KLEIN M. Ordinal logistic regression[M]// Logistic Regression. New York: Springer, 2010:331-343.
���༭ ��������
�ո����ڣ� 2018 -10 -08; �����ڣ� 2018 -12 -21
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61622208, 61732008, 61532011) (Projects(61622208, 61732008, 61532011) supported by the National Natural Science Foundation of China)
ͨ�����ߣ��Żԣ���ʿ����ʦ���������������û���Ϊ�����о���E-mail: zhanghui_china@yeah.net
ժҪ:�����û�����������������Ӿ�������Ϣ������Ч����3��ά��15�����ص��������չʾЧ��������ϵ�����Զ�������ͳ���ı����չʾЧ����ʵ�����������÷����ܹ����˹��������û��ܿ�ʵ��ȡ��һ�µ�����Ч�������������������������Դ���������۷������ڡ�
