
һ�ֻ���Chord��������Դ��λ����
��־��, ̷���, ������, �½���, ������
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ, ���� ��ɳ, 410083)
ժ Ҫ��
��λ�����Ļ�����, ���������Դ���ص�, ������������Է�Χ��ѯ�Լ���ά��ѯ��˼��, ��������Щ˼������������µ���Դ��λ������������֧��Ķ�ά��ѯ������ ģ��ʵ��������,�÷����������õĿ���չ�ԡ�
�ؼ���: ����; ��Դ��λ; Chord; ��ά��ѯ; ��Χ��ѯ
��ͼ�����: TP302.1 ���ױ�ʶ��: A ���±��: 1672-7207(2005)03-0465-05
A resource-location method of grid based on chord
HU Zhi-gang, TAN Shu-fei, GUI Wei-hua, CHEN Jian-er, CHEN Song-qiao
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: Aimed at the characteristics of grid resources, the ideas of range queries of numerical attributes and multidimensional queries based on the location method of Chord. Furthermore, a single attribute dominated query method was also provided on the basis of these ideas. And simulative experimental results indicate that this method has a good scalability.
Key words: grid; resource location; Chord; multidimensional queries; range queries
�������������ѳ�Ϊ�ֲ�ʽϵͳ�����е�һ���о��ȵ�[1-4], ����,��Դ��λ���������������Ҫ������֮һ, ��������ֱ��Ӱ�쵽���㻷������ԴЭͬ������Ч�ʡ� ��ǰ, ������Դ��λ����������, ��Globus���������е�MDSʵ���˻���LDAP����״Ԫ����Ŀ¼����[5]; Condor�� MatchMaker[6]ʵ���˲�����ȫ����Դ����������ƥ��ļ���ʽ��Դ����ϵͳ����; Web�����е�UDDIʵ���˼���ʽ����ʵ���ͳһ������ ע��Ͳ���[7, 8]�� ��Щ��Դ��λ�ķ��������ڼ���ʽ����ʽ, ������������Ҫ����һ�ֲ������ڼ��п��Ƶġ� ���Ƿֲ�ʽ����Դ��λ������ һЩ����DHTs��P2Pϵͳ(��Chord, CAN, Pastry��[9-13])����Դ��λ���Ծ��зֲ�ʽ�� ����չ���ص㡣 ��Щ���Զ����о��������µ���Դ��λ�������н������, ����,����������Դ�������Լ����ԵĶ�����, ���ܽ�P2Pϵͳ�л��ڹؼ��ֵ���Դ��λ������Ӧ�������� Ϊ��, ����������P2Pϵͳ����Chord�Ļ����������һ���ʺ�������㻷������Դ��λ������
1 Chord��Դ��λ����
1.1 ����λ���صı�ʶ��������ؼ��ִ洢
Chord��������ɢ�к���(��SHA-1)Ϊÿ���ڵ�ؼ��ַ���mλ�ֽڵı�ʶ(identifi-er)[8, 9], �ڵ�ı�ʶ������ͨ��ɢ�нڵ��IP��ַ����, ���ؼ��ֵı�ʶ������ֱ��ɢ�д˹ؼ��֡� ����IP ��ַΪ192.168.0.49 �Ľڵ㾭��SHA-1 ɢ��֮��õ��ı�ʶ��Ϊ30, ���ؼ��֡�Windows��ɢ��֮��Ĺؼ���Ϊ95�� ��ʶ������m�����㹻��, �Ա�֤2���ڵ����2���ؼ���ɢ�е�ͬһ����ʶ���ϵĸ���С�����Ժ��Բ��ơ�
������ɢ����, ÿ���ؼ��ֶ����������ĺ�̽ڵ���, ��̽ڵ��ǽڵ��ʶ�����ڻ���ڹؼ���k��ʶ���ĵ�1���ڵ�, �ɱ�ʾΪsuccessor(k)�� �����ʶ����mλ����������ʾ, ���ҽ���0 ��2m- 1�������г�һ��ԲȦ, ��ô,successor(k) ���Ǵ�k��ʼ��˳ʱ�뷽���������Ľڵ㡣
����ɢ�о��м����ص�, ɢ�к�������ʹ����ƽ��, �����еĽڵ㶼���Խ��յ�������ͬ�����Ĺؼ���; ���ڵ��������뿪ϵͳʱ,�����������Ӱ����Դﵽ��С��
1.2 Chord ���ҷ�ʽ
��Chord��, ÿ��Chord�ڵ�ά���������ڵ������·����Ϣ, �ڵ㲢����Ҫ֪�����������ڵ����Ϣ�� ����mΪ�ؼ��ֺͽڵ��ʶ����λ��, ÿ���ڵ�ֻ��ά��һ����m��������ɵ�·�ɱ�, Ҳ��Ϊָ����� ָ����и���������1��ʾ��
�� 1 Chord ָ���
Table 1 Chord finger table 
Finger[i]Ϊ�ڵ�n�ĵ�i��ָ��, S[i]Ϊָ���ʶ�����е���һ�ڵ��ָ��, ����S[i]=successor(Finger[i])��
Chord �����㷨����:
a. �ڵ�n���յ��ؼ���Ϊk�IJ�ѯ����;
b. ����ָ���, Ѱ�ҵ���k��Finger[i]�� �����, ��S[j](Finger[j]=k)���ظ��ڵ�n�� ���û��, ��Finger[i]��ѡ����ӽ�k��Finger[r], ������ѯ����·��ת����S[r];
c. �ظ���һ����
2 ����Chord��������Դ��λ����
Chordϵͳ����ȷ�ض�λ�ؼ�������λ��, Ȼ��,���ֲַ�ʽ�����������������µ���Դ��λ�������� ��Ϊ�������µ���Դͨ���Ƕ�����������, ���,��Ҫ���ڶ�������ע�����ѯ��
����, һ����Դ�ṩ�������������ע����Դ:
Register
Name=Tsf&&URL=Gram://tsf.csu.edu.cn:8000&&OS-type=Windows&&CPU-speed=833 MHz&&memory-size=512 MB
һ����Դ��ʹ�����������������ѯ����Ҫ����Դ:
Search
OS-type=Windows && 800 MHz��=CPU-speed��=1000 MHz && memory-size >=512 MB
����Դע����û���ѯ����п��Է�������������Դ��λ����Ҫ�ص�:
a. ������Դ�Ķ�����, ��Դ�IJ��ұض�Ҳ�Ƕ�����֧��, �������ɵ���������ֻ�ǵ��ؼ��־����� ��һ����Chordϵͳ�л��ڹؼ��ֵIJ����кܴ����, ����������Դ��λ��Ҫ��ά��ѯ������
b. �۲쵥�����ԵIJ�ѯ����, ���Է��ְ���Դ����ֵ�����Ϳɽ���Դ���Դ��·�Ϊ�ַ�������������������2�֡� �确OS-type��, ��URL��, ��Name�� �����ַ�������, ��������ֵ����ɢ��; ����CPU-speed���͡�memory-size����������������, ���ǵ�����ֵ��������, ���ڸ�����ѯ����ʱ, ͨ����������һ����ֵ��Χ, �����ǵ�����ѯ�ؼ��֡� ���, �������������Բ����ٲ��û��ڹؼ��ֵIJ�ѯ����, ����Ҫһ����Χ��ѯ�ķ�����
���, ��Ҫ�о������������� �ܹ����㷶Χ��ѯ�Ͷ�ά��ѯҪ�����Դ��λ������
2.1 ����Chord�ķ�Χ��ѯ����
������ϵͳ��, ��������ֵ�����Ϳɽ���Դ�����Է�Ϊ�ַ������Ժ�����������2�֡� �����ַ�������, ��������Chord�Ļ��ڹؼ��ֲ�ѯ����, ���Բ���Chord�е�ɢ�к���(SHA-1)Ϊ����ֵ����mλ�ı�ʶ��; ��������������, ��ͨ�����¶���ɢ�к����������ʶ����
��������������a����ֵ��ΧΪ [umax, umin], �ɹ������µ�ɢ�к���:
H(u)=(u-umin) �� (2m-1)/(umax-umin),
u��[umax, umin]��
����ÿ������ֵu, ɢ�к���������һ��mλ�ı�ʶ��H(u), ���ҵ�ui��ujʱ��H(ui)��H(uj),������ֵԽС,���䵽�ı�ʶ��ҲԽС; ��֮, ����ֵԽ��,����ı�ʶ��ҲԽ�� ����u��[umax, umin], �����Ͻ��ۿ��Եõ�H(umax)��H(u)��H(umin)�� ����Chord, Ϊ����ֵu�����ʶ����, ������ֵu�洢��successor(H(u))��, ����ʶ�����ڻ����H(u)�ĵ�һ���ڵ��С� ��֪H(umax)��H(u)��H(umin), ��successor(H(u))��H(u), ���Ƴ�successor(H(umax))��successor(H(u))��successor(H(umin))�� ����NΪ��Դ����ķ���ڵ�, NxΪ��Դ����·��ת��;���ڵ�, W�Ƿ��Ϸ�Χ��ѯ������������Դ��,�������Ͻ���, �ɵõ����������Է�Χ��ѯ�㷨, �����µ��㷨1��
�㷨1���� ���������Է�Χ��ѯ�㷨����:
a. ���ڵ�N�ӵ�����ֵΪu��[x, y]�ķ�Χ��ѯ����, ��ʼ����Դ����W��
b. ����ѯ����·��ת�����ڵ�Nx�ϡ� ����Nx=Successor(H(x)), ����Nx�е���Դע����Ϣ, ������a���㷶Χ��������Դ���ӵ�W�С�
c. ����ѯ����ת������һ����̽ڵ�Ni, ͬ�������㷶Χ��������Դ���ӵ�W�С� �ж�Ni�Ƿ�ΪNy, ����, ����ѯ�������Դ��W���ظ�����˽ڵ�N; ������, ��ִ����һ����
d. �ظ�����c.��
[����] ��ͼ1��ʾ, N15�ӵ���Χ��ѯ����, ��ѯ�ؼ��ַ�ΧΪ1~110����Դ�� ����, ����Chord���ؼ��ֵIJ��ҷ����ҵ��ؼ���K1���ڵĽڵ�N1, Ȼ��, ��N1Ϊ��Χ��ѯ����ʼ�ڵ�, ����ѯ��������ת������̽ڵ�, �ڸ��ڵ���������Դע����Ϣ, ������ؼ��ַ�Χ1~110����Դ���ӵ���Դ����W��, ֱ����ѯ����ؼ���K110���ڵĽڵ�N121, ��ʱ, ֹͣ��ѯ������ѯ���(��Դ����W)���ظ�����ڵ�N15��
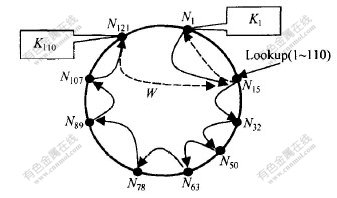
ͼ 1 ��Χ��ѯ�㷨ʵ��
Fig. 1 Example of range queries algorithm
�ò����㷨��ʱ�临�Ӷ�ΪO(lgN+K), ����O(lgN)Ϊ��ѯ����·��ת�����ڵ�Nx������ʱ��, ��O(K)�Dz�ѯ����Ӳ�ѯ��ʼ�ڵ�Nx����ѯ��ֹ�ڵ�Ny��;�����ѵ�ʱ��, ����KΪNx��Ny֮��Ľڵ���, ��ͼ2��KΪ;��N1��N121֮��Ľڵ������
2.2 ������֧��Ķ�ά��ѯ����
�������е���Դ�Ƕ�����ע��Ͳ�ѯ, ����������Դ��λ��Ҫ��ά��ѯ������ ����������Դ�����Լ�Ϊ{a1,a2,a3,��,aM}, ��Ӧ������ֵ����Ϊ{u1,u2,u3,��,uM}, MΪ�̶�ֵ�� ����������Դ��Ϣ�����ԡ�ui, rx������, rxΪ��Դ����ڵ�ַ��Ϣ�� ����Դע��ʱ����Դ��Ϣ�ύ����Ϣ�ڵ�, ������Դ�ĸ�������ֵ��ɢ��ʱ����Ӧһ����Ϣ�ڵ�Ni, ������Դ��ע����Ϣ�ֲ��洢��M����Ϣ�ڵ�λ��, ����������M���ڵ�λ�ô洢��ע����Դ����Ϣ�� ��Ϣ�ڵ������Դ���Լ���ע�����Դ��Ϣ���з���, ����ai����ui, rx����֯��һ��, �������ַ�����������������߲�ѯЧ�ʡ�
�����û��ύ�IJ�ѯ��������:
Search
OS-type=Windows && 800 MHz��=CPU-speed��=1000 MHz && memory-size >=512 MB
����һ��3ά��ѯ����, ��3����������϶��ɡ� Ҫ�����ѯ, ����Ҫ�����Ӳ�ѯ�� ����WΪ����3ά��ѯ��������Դ����, Wi�����������������Դ����, �ɵ�Wi�Ľ���: W=��Wi(1��i��3)�� ��ֱ�۵ķ����Ƿֱ����3���Ӳ�ѯ, ���W1, W2��W3, Ȼ�����õ�����3ά��ѯ��������Դ����W�� �������ַ������Ӳ�ѯ�Ĺ�����û�г��������Դ�г�ָ������(��CPU-speed)�������������Ϣ, �����Ӳ�ѯ��Ҫ����M�ε����������, ��������������ͨ������ ������������, ��������˵�����֧��Ķ�ά��ѯ������
������֧��Ķ�ά��ѯ��������Ҫ˼·��: ����Դ�IJ�ѯ������ѡȡ����ai��Ϊ��ѯ��֧������, ��ai�ĵ����Բ�ѯ������, �ﵽ��ά���Բ�ѯ�� �÷��������������Ϣ�ڵ�����Դ��ע����Ϣ, ����Ҫ�Բ�ѯ�����ĸ�ά���е����ĵ�����ѯ, �������˲�ѯ���̡�
�����㷨ѡȡ����ai��Ϊ��ѯ�����е�֧������, S�dz�����ai�������Ӳ�ѯ�����ļ���, W�Ƿ��϶�ά��ѯ������������Դ����
�㷨2����������֧��Ķ�ά��ѯ�㷨����:
a. ����ڵ�N�ӵ�֧������ai�IJ�ѯ��Χ��[x, y]�Ķ�ά��ѯ����, ��ʼ��W��
b. ����ѯ����·��ת�����ڵ�Nx, ����Nx=Successor(H(x)), ����Nx����Դע����Ϣ, �����϶�ά��ѯ��������Դ���ӵ�W��
c. ����ѯ����ת������һ����̽ڵ�Ni, ͬ���������ά��ѯ��������Դ���ӵ�W�С� �ж�Ni�Ƿ�ΪNy, ����, ����ѯ���(��Դ��W)���ظ�����˽ڵ�N; ������, ��ִ����һ����
d. �ظ�����c.��
���㷨ʵ����ͼ2��ʾ, ͼ��a1Ϊ��ά��ѯ��֧������, R��a1�IJ�ѯ��Χ, R=[30,80], S�dz�����a1�������Ӳ�ѯ�����ļ���, W���ڼ�¼�����ά��ѯ������������Դ�� ��N15�ӵ���ά��ѯ����ʱ, ���Ƚ�����·��ת�����ڵ�N32, �������ýڵ�������S��������Դ, �������¼��W��; Ȼ��,����������ת������̽ڵ�, �ظ���ͬ����, ֱ������ؼ���K80�Ĵ洢λ��N89, ������ѯ, ��������ء�
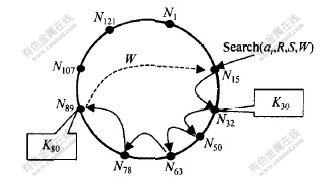
ͼ 2 ��ά��ѯ�㷨ʵ��
Fig. 2 Example of multidimensional queries
algorithm
���㷨��ʱ�临�Ӷ����ڲ�ѯ��ѡȡ��֧������ai�йء� ����,�������![]() �� ����: Si��ʾ����ai�ı�ʶ������[H(uix),H(uiy)]ռ����ϵͳ�����ռ�ı���, ��Ϊ���ԵIJ�ѯ��Χѡ���; Ki=Si��N, Ki��ʾ����ai�ڷ�Χ��ѯ������·��ת���Ĵ����� ���, ������ai��Ϊ֧�����ԵĶ�ά��ѯ�㷨��ʱ�临�Ӷ�ΪO(lgN+Ki)�� ����SminΪѡ���Si����Сֵ, ������С��ʱ�临�Ӷ�ΪO(lgN+N��Smin)��
�� ����: Si��ʾ����ai�ı�ʶ������[H(uix),H(uiy)]ռ����ϵͳ�����ռ�ı���, ��Ϊ���ԵIJ�ѯ��Χѡ���; Ki=Si��N, Ki��ʾ����ai�ڷ�Χ��ѯ������·��ת���Ĵ����� ���, ������ai��Ϊ֧�����ԵĶ�ά��ѯ�㷨��ʱ�临�Ӷ�ΪO(lgN+Ki)�� ����SminΪѡ���Si����Сֵ, ������С��ʱ�临�Ӷ�ΪO(lgN+N��Smin)��
3 ģ��ʵ�������
�������湤��SimGrid[14, 15] ���㷨2���м��������ʵ��, �������˽ṹΪ�����������������, ͨ��ʵ��Ե�����֧��Ķ�ά��ѯ�����������ܽ��з����� �������Թ����ڲ�ѯ�����е������ӳ�, �ɽ��ڲ�ѯ·���Ͼ����Ľڵ���(��ת��)��Ϊ��Դ��λ���ܵ�������, ����С��ѯ��Χѡ���Smin=1%ʱ, ����������ͼ3��ʾ�� ��ͼ3���Կ���,���������ģ������, ��ѯ��ƽ����ת����ڵ���֮��Ĺ�ϵ���³ʶ�����ϵ, �����÷������нϺõĿ���չ�ԡ�
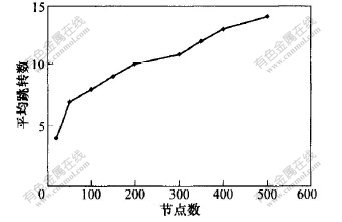
ͼ 3 SminΪ1%ʱ�ڵ����仯��ƽ����ת����Ӱ��
Fig. 3 Influence of changes in node numbers on
average hops with Smin of 1%
Sminֱ��Ӱ����Դ�Ķ�ά��ѯ����, Ϊ��, �о���ͬ��Smin���������Դ��λ���ܵ�Ӱ�졣 ����̶�����ڵ���Ϊ64, ��Դ���Լ���СΪ1, ʵ������ͼ4��ʾ�� �������, �ڹ̶������ģ��������, Smin������ʱ,�����Դ��λ���ܵ�Ӱ�����������Եġ�
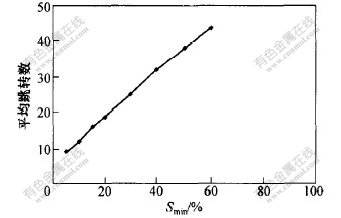
ͼ 4 Smin�ı仯��ƽ����ת����Ӱ��
Fig. 4 Influence of changes in Smin on
average hops
4 �� ��
��Դ��λ�������������Ҫ����ĺ�������֮һ, ͨ��������������Դ������ע�����ѯ���ص�, ����˷�Χ��ѯ�Լ���ά��ѯ���������Դ��λ������ ģ��ʵ��������, �÷�������Ч�ؽ����������е���Դ��λ����Դ��������, �Ҿ������õĿ���չ�ԡ�
�����:
[1]Foster I, Kesselman C. The grid: Blueprint for a future computing infrastructure [M]. San Francisco: Morgan Kaufmann Publishers, 1999.
[2]Foster I, Kesselman C. The physiology of the grid: An open grid services architecture for distributed systems integration[EB/OL]. http://www.globus.org/research/papers/ogsa.pdf, 2002.
[3]Tuecke S, Foster I. Open grid services infrastructure (OGSI), Version 1.0[EB/OL].http://www-unix. globus.org/toolkit, 2003.
[4]Foster I, Kesselman C, Tucke S. The anatomy of the grid: Enabling scalable virtual organizations [J]. International Journal of Supercomputer Applications, 2001, 15(3): 200-222.
[5]Czajkowski K, Fitzgerald S, Foster I. Grid information services for distributed resource sharing[A]. Thomas D. Proceeding of the 10th IEEE HPDC[C]. Washington, DC: IEEE Computer Society Press, 2001. 181-194.
[6]Raman R, Livny M, Solomon M. Matchmaking: distrbuted resource management for high throughput computing [A]. Schaeffer J. Proceeding of the 7th IEEE HPDC[C]. Washington, DC: IEEE Computer Society Press, 1998. 140-146.
[7]Rompothong P, Senivongse T. A query federation of UDDI registries[A]. Aleksy M, Coffey T. Proceedings of the 1st international symposium on information and communication technologies[C].Dublin: Trinity College Dublin Press, 2003. 561-566.
[8]Stoica I, Morris R, Karger D. Chord: a scalable peer-to-peer lookup service for internet applications[A]. Proceeding of ACM SIGCOMM 2001[C]. New York: ACM Press, 2001. 149-160.
[9]Stoica I, Morris R, Liben-nowell D. Chord: a scalable peer-to-peer lookup protocol for internet applications[A]. Ellen W Z. IEEE/ACM Transactions on Networking[C]. New York: ACM Press, 2003. 17-32.
[10]Singh M G. Routing networks for distributed hash tables[A]. Anon. Proceedings of the Twenty-Second Annual Symposium on Principles of Distributed Computing[C].New York: ACM Press,2003. 133-142.
[11]Loguinov D, Kumar A, Rai V. Graph-theoretic analysis of structured peer-to-peer systems: routing distances and fault resilience[A]. Anon. Proceedings of the 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications[C].New York: ACM Press, 2003. 395-406.
[12]Ratnasamy S, Francis P, Handley M. A scalable content-addressable network[A]. Anon. Proceedings of ACM SIGCOMM2001[C].New York: ACM Press, 2001. 161-172.
[13]Rowstron A , Druschel P. Pastry: scalable, decentralized object location and routing for large-scale peer-to-peer systems[A]. IFIP/ ACM International Conference on Distributed Systems Platforms[C]. Heidelberg, 2001.
[14]Legrand A, Marchal L, Casanova H. Scheduling distributed applications: the Simgrid simulation framework[A]. Lee S, Sekiguchi M S. Proceedings of the 3th International Symposium on Cluster Computing and the Grid[C]. Washington, DC: IEEE Computer Society Press, 2003. 138.
[15]Casanova H. Simgrid: A toolkit for the simulation of application scheduling[A]. Craig A L, Paul P. Proceedings of the 1st IEEE/ACM International Symposium on Cluster Computing and the Grid[C]. Brisbane: IEEE Computer Society Press, 2001. 430-437.
�ո�����:2004 -09 -20
������Ŀ:������Ȼ��ѧ�����ص���Ŀ(60433020); ��ʿ�����������Ŀ(2004)
�����:��־��(1963-), ��, ɽ��Т����, ����, ���²���ϵͳ�Ͳ��м����о�
������ϵ��: ��־��, ��, ����; �绰: 0731-8836300; E-mail: zghu@mail.csu.edu.cn
ժҪ: ��Chord��λ�����Ļ�����, ���������Դ���ص�, ������������Է�Χ��ѯ�Լ���ά��ѯ��˼��, ��������Щ˼������������µ���Դ��λ������������֧��Ķ�ά��ѯ������ ģ��ʵ��������,�÷����������õĿ���չ�ԡ�
�ؼ���: ����; ��Դ��λ; Chord; ��ά��ѯ; ��Χ��ѯ
��ͼ�����: TP302.1 ���ױ�ʶ��: A ���±��: 1672-7207(2005)03-0465-05
