
DOI: 10.11817/j.issn.1672-7207.2018.12.012
����LDA��ģ��C��ֵ��Web�����ܾ���
����ƽ������ѫ��Ф���裬ʯ�����ܲ���
(���ϿƼ���ѧ �������ѧ�빤��ѧԺ��
֪ʶ���������绯�������ʡ��ͨ��У�ص�ʵ���ң����� ��̶��411201)
ժ Ҫ��
���ַ���ͨ���ǽ�Web�������ijһ���̶��Ĺ������У����¸�Web�������������Ա����ԣ�Web�������Դ�����ʽ��͵����⣬���һ�ֻ���LDA��ģ��C��ֵ��Web�����ܾ���������ȣ���ProgrammableWeb.com��վ����ȡWeb�������ݣ�����ȡWeb���������ĵ�����Σ�ʹ��LDA����ģ�Ͷ�Web���������ĵ����н�ģ����ð�����ͬ������Ϣ���ĵ��������������ĵ����������ʹ��ģ��C��ֵ�㷨��Web������ൽ��ͬ�Ĺ������У����Web����Ķ�ܾ��ࡣ�о����������Web����Ķ��������ʵ����˷����ֵľ��ȡ�
�ؼ��ʣ�
Web������ģ��C��ֵ�㷨��LDA����ģ����Web��������
��ͼ����ţ�TP301 ���ױ�־�룺A ���±�ţ�1672-7207(2018)12-2986-07
Web services clustering with multi-functionality based on LDA and fuzzy C-means algorithm
ZHAGN Xiangping, LIU Jianxun, XIAO Qiaoxiang, SHI Min, CAO Buqing
(Key Laboratory of Knowledge Processing & Networked Manufacturing of Hunan Province,
School of Computer Science and Engineering, Hunan University of Science & Technology, Xiangtan 411201, China)
Abstract: Considering that Web service discovery usually classifies Web service into one fixed cluster, which neglects other important function attributions of the Web service, a Web services clustering method with multi-functionality was proposed based on LDA and fuzzy c-means algorithm. The method firstly crawled Web services from ProgrammableWeb.com and extracted the description document of them. Then LDA was used to model the description documents of Web services, and the document-topic matrix which contained different functional information was obtained. Finally, they were clustered into various clusters with similar functionality by exploiting fuzzy C-means algorithm. The results show that the multifunctionality of Web services effectively improve the accuracy of Web services discovery.
Key words: Web services; fuzzy C-means algorithm; LDA topic model; Web services discover
Web������һ�������ڻ�������Ӧ��ϵͳ��������֯�������������һ�����ܵ�����Ӧ�÷�������ʹ�����ܹ�ͨ��Internet�����ʲ�ʹ��[1]������Web���������Ŀ�������ͨ������Web�����Ӧ�ã��������[2-3]���������[4-5]��������Web������Ե�ʮ�ֱ�Ҫ����Web������о�����һ�ִٽ�Web�����ֵ���Ч�ֶΣ��ܹ���Ч�����Web���������������������[6-7]�����û�����Web����ʱ��ͨ���Ǽ����Լ���Ҫ�Ĺ������ƣ���������ͨ���û�����Ķ�����ܣ��ھ�������Щ�������ƵĹ��ܴ���ѡ�������û����������Web�����ڹ��ܴ��н��в��ҽ���Ч�ؽ���Web����������ռ䡣�����о�������Web����ı�ǩ��Web�����ܵĸ���˵��[8],�������ñ�ǩ��Web������й��ܻ��֡�API�ṹ��ͼ1��ʾ����API����5����ǩ���������API����5�ֲ�ͬ�Ĺ��ܡ������մ�ͳ�ľ��������ֻ�ܷ��ָ�API��1�����ܡ�Tools������������硰3D���͡�Visualizations���ȹ��ܾ��������֣��������á���Web������༰�����У��⽫��ɺܴ����Դ�˷ѡ�

ͼ1 API�ṹͼ
Fig. 1 The structure of API
Ŀǰ����Web���������о����Թ���Ϊ3�ࣺ���ڹ������Ե�Web��������о�[9]�����ڷǹ������Ե�Web�����о�[10-11]���������е�Web��������㷨���иĽ����о�[12-13]�����У����ڹ������Ե�Web��������ܹ����Web����������������������ڹ������ƶȵ�Web��������[6-7]�����ȴ�WSDL�ĵ��г�ȡWeb����Ĺؼ�������ͨ������Web����֮����������ƶȵȷ�������Web����֮��������ԡ�LIU��[14]�����Web���������ı�����ȡ�����ݡ������ġ��������ͷ�������4������ʵ��Web������ࡣPOP��[15]���ʹ�û�����Ⱥ�ķ��������ڻ����������ƶȵ�Web������ࣻ���˵�[16]���Mashup����������ĵ�����Ӧ��ǩ�����һ�ֻ���Mashup���������Ե�K-Means�㷨���з�����ࡣ���⣬���ڷǹ������Ե�Web��������о���Ҫ����Web���������(QoS����quality of service)��ͨ��ʹ�õ���QoS�����������������ԡ�ִ��ʱ��ȡ����ǣ���Щ����û�����õ�Web����Ķ����ǩ���������ǽ�Web����̶��طֵ�1���������У�������Web����Ķ�����ԡ�ʵ���ϣ�Web����ı�ǩ�����������Ĺ������ԣ��������ǩ���ñ�����Web����Ķ�����ԡ����ڴˣ��������һ��Web�����ܾ������ͨ����LDAģ����ģ��C��ֵ�㷨���н�ϣ�ʵ�ֶ�Web����Ķ�ܻ��֡�
1 ��������
1.1 LDA����ģ��
LDA��BLEI��[17]�����һ����������ģ�ͣ���һ�ַǼල�Ļ���ѧϰ�㷨��LDA���Խ�ÿƪ�ĵ����ڵ������Ը��ʷֲ�����ʽ�������ܹ�����ʶ����ģ�ı���������������Ϣ������1�����ĸ���ģ�ͣ������ʡ��ĵ�������3��ṹ��LDA�������1�������ϲ�����ͬʱ��ÿ���������ڹ̶��ʱ��ϵ�һ������ʽ�ֲ�����Щ�����ɼ����е������ĵ�������
ͼ2��ʾΪLDA����ģ�͵����ɹ��̡������ĵ���D�У�MΪ�ĵ�������NmΪ��m���ĵ��ĵ���������kΪ���������Zm,nΪ��m���ĵ��е�n���ʵ����⣬wm,nΪ��m���ĵ��еĵ�n���ʡ�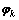 Ϊ���Ӧ�Ϊ������Dirichlet�ֲ�(����ʾ��k�������µĴʷֲ�)��
Ϊ���Ӧ�Ϊ������Dirichlet�ֲ�(����ʾ��k�������µĴʷֲ�)��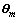 Ϊ�����Ԧ�Ϊ������Dirichlet�ֲ�(����ʾ��m���ĵ��µ�����ֲ�)������1���ĵ�����wm,nΪ���Թ۲쵽����֪�������ºͦ�Ϊ���ݾ�����������������Zm,n��������δ֪����������[18]�����IJ��ü���˹����(Gibbs Sampling)��������������б��������Ϸֲ�Ϊ��
Ϊ�����Ԧ�Ϊ������Dirichlet�ֲ�(����ʾ��m���ĵ��µ�����ֲ�)������1���ĵ�����wm,nΪ���Թ۲쵽����֪�������ºͦ�Ϊ���ݾ�����������������Zm,n��������δ֪����������[18]�����IJ��ü���˹����(Gibbs Sampling)��������������б��������Ϸֲ�Ϊ��
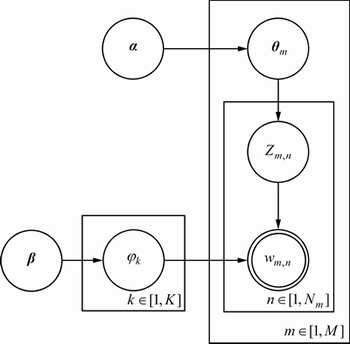
ͼ2 LDA����ģ�͵����ӱ�ʾ��
Fig. 2 Plate Notation of LDA Model

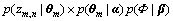 (1)
(1)
LDA����Ҫ�������ƶϳ�ÿһ��Web���������ĵ�������ֲ�������Web���������ĵ�������ֲ�������Ա�����Web������ࡣ
1.2 ģ��C����
ģ�������Ǽල����ѧϰ��һ�֣�����Դ��ģ�����ۡ��ھ��伯�����У�����X�е�ijһԪ��x��Ҫô��ȫ����ij����A��Ҫô��ȫ������A[19]�����߱ؾ���һ��Ԫ��֮��ķ����������ķֽ磬���Ⲣ���ܺܺõط�ӳ���ݵ��������ĵ�ʵ�ʹ�ϵ��������Ϊ����ʵ���磬1������ֻ����ijһ���̶�������ijһ����[20]������1��Web����ͻ��ж�����ܱ�ǩ���̶��ذ�1��Web����ֵ�ijһ�����ܱ�ǩ�У��������������ܱ�ǩ��������Web���������ԣ���ˣ�����ģ��C��ֵ�����㷨������õ�ÿ��Web��������ij�����ܱ�ǩ�ij̶ȡ�ģ��C��ֵ�����ܹ���n������xi(i=1��2������n)���ֵ���Ϊָ����C��ģ�����У��������������Ⱦ��������Ⱦ������ڱ�ʾÿһ����������ij���صĸ��ʡ�ģ��C��ֵ����Ҫ˼����ʹ���������ݲ���ܵĴ�����֮������ݲ����С��ģ��C��ֵ�����㷨��Ŀ�꺯����������ģ������m�����ڿ���ģ�����ķ����̶ȣ���m=1ʱ��ģ��������˻���k-means���ࡣ��Ŀ�꺯��[21]Ϊ
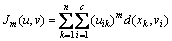 (2)
(2)
���У�d(xk��vi)Ϊxk��vi֮��ľ��룬���IJ������Ҿ�����Ϊÿ��Web���������ķ���ľ��롣ͨ��ʹĿ�꺯��ֵ�ﵽ��С����������Ҫ˼�룬��������������ĺ������ȸ��¹���
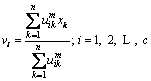 (3)
(3)
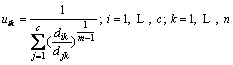 (4)
(4)
���У�V={v1��v2��v3������vc}����ʾ�������ĵ㼯��U=[uij]c��n��Ϊ�����Ⱦ���
ģ�������㷨�������¡�
��1���������ʼ�����Ⱦ���U����ʼ����������V����ʼ�������롣
��2���������������V��
��3�������������Ⱦ���U��
��4��������Ƿ�����������������������㣬���������������ת����2����
ͨ�������㷨���̣����Ի�������Ⱦ�������Web����Ķ��ǩ���ࡣ
2 ʵ�鲽��
��������ķ�����������ͼ3��ʾ����ProgrammableWeb.com��վ����ȡ�����ݰ�����Web����������ĵ��Լ����ǵı�ǩ��Ϣ�����ȣ��Ի�õ�Web����������ĵ�����Ԥ�������õ�Ԥ������������ĵ������ţ�����LDA����ģ��ѵ���õ�ÿһ��Web����Ԥ���������ĵ����ĵ�����ֲ�����������õ���������ģ�����࣬������ɶ�Web����Ķ�ܾ��ࡣ
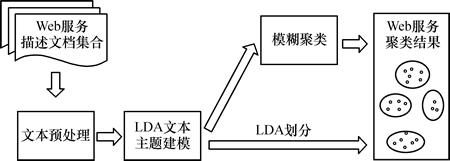
ͼ3 ���ķ���������
Fig. 3 The overall framework of this approach
2.1 �ı�Ԥ����
Web����Ŀ��������ϴ���Web����ʱ�����ӶԸ÷���Ĺ��������ĵ���Web����������ı������˸�Web�����ȫ�����ܡ�����Web����������ĵ�����Web������ж�ܷ��ࡣ������Щ�������д�����������Ϣ��Ϊ������ı�����ľ�ȷ�ȣ����ȶ������ĵ�����Ԥ������
Ԥ������Ҫ�������¼������衣
1) �ı����ݵĻ�ȡ����������ProgramableWeb.com����ȡ��12 919��Web�����Լ����ǵ������ĵ�������Щ�ĵ������иʹ��ÿ���ı��ļ�ֻ����1��Web����������ĵ���
2) �ı����ƻ�(tokenize)�������ʰ��տո���зִʣ����ҽ��������뵥�ʷֿ�������ʹ�õ���python�е���Ȼ���Դ������߰�NLTK(Natural Language Toolkit)���д���[22]��
3) ����ͣ�ô�(stop words)��Ӣ�����кܶ���Ч�Ĵ��Լ������ţ��硰a������to���͡���������Щû��ʵ������Ĵʻ���ű���Ϊͣ�ôʡ�����ʹ��NLTK���Դ���ͣ�ôʱ�����ȥ��ͣ�ôʡ�
4) �ʸɻ�����(stemming)����Ӣ���У�ͬһ�����ʻ���Ϊʱ̬���˳ƵIJ�ͬ���в�ͬ�ı�����ʽ���硰provide������providing���͡�provides��������ʵ���϶���ͬһ�����ʡ�provide����������Щ���ʿ����Dz�ͬ�ĵ��ʣ���ô֮���ʵ����ȷ�Ƚ��ή�͡�����Ҫ���дʸɻ�������
ͨ������4�����裬�ɻ��WSDL�ĵ���������Ĵ��֮�����Щ���������ĵ�ʹ��LDAģ�ͽ������⽨ģ��
2.2 LDA(latent dirichlet allocation)���⽨ģ
��������ȡ�õ�Web����������ĵ��ļ���D={d1��d2��d3������d|D|}�����У�|D|��ʾWeb���������ĵ�����Ŀ��ʹ��LDA����ѵ��ģ��ѵ���õ������⼯��ΪT={t1��t2��t3������tK}�����У�tiΪ�ü��ϵ����⣬�øü����г��ִ������ı�ǩ����ʾ��KΪģ��ѵ��֮ǰ��Ϊ�涨�������������ÿһ���ĵ�di�������⼯��T����1�����ʷֲ�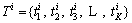 ����ˣ����е�Web���������ֲ��������Ա�ʾΪ1����ά�������ʽ
����ˣ����е�Web���������ֲ��������Ա�ʾΪ1����ά�������ʽ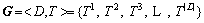 �����ݾ���G����Web������й��ܷ��ࡣ
�����ݾ���G����Web������й��ܷ��ࡣ
2.3 �������������Ⱦ������
ʹ��ģ��C��ֵ�����㷨����LDA��ģ�õ�������ֲ���������G���д������õ������Ⱦ���U������C={c1��c2��c3������cM}��ʾÿһ���ص����⣬�øô��г��ִ������ı�ǩ����ʾ��MΪ����֮ǰ��Ϊ�涨�Ĵصĸ��������������Ⱦ���������Web����ķ���õ�ÿ��Web���������ֲ��������� ��ʾ��i��Web��������ÿ���صĸ��ʡ�
��ʾ��i��Web��������ÿ���صĸ��ʡ�
��ֻ����1��Web�������2����ǩ����ô��Ҫ�������Ⱦ������ҵ���Web����������������ǰ�����ء���ͼ4����֪������1��Web������0.4�ĸ������ڵ�2���أ���0.12�ĸ������ڵ�1���أ���0.04�ĸ������ڵ�M���ء����Web����ı�ǩ���Ǵ�c2��c3���������⡣

ͼ4 �����Ⱦ���
Fig. 4 Membership degree matrix
3 ʵ������
3.1 ���ݼ�����
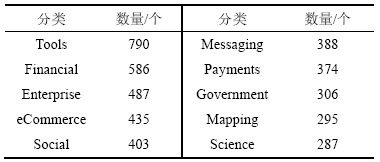
Ϊ����������ķ�������2016-10��2016-11����ProgrammableWeb.com��վ�Ϲ���ȡ12 919��Web�������Ϣ������Web�������ơ������ĵ���ӵ�б�ǩ���͵���Ϣ����ϸ��ͳ����Ϣ����1��
��1 APIͳ����Ϣ
Table 1 Statistical information of API

����ȡ�������У���ǩΪ��Tools����API����790��������ǩΪ��Law������������1��API����ˣ�ѡȡ�˱�ǩ��������ǰʮ��Web������4 351��Web��������ʵ�飬��ϸ��API�ֲ��������2��
��2 ��������ǰʮ��Web�����ǩ�ֲ�
Table 2 The distribution of web services in top 10 categories
3.2 ������
����ȷ�ʡ��ٻ����Լ�F(ȷ�����ٻ��ʵĵ���ƽ��ֵ)����������ķ��������裬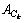 ��ʾ��k��Web����ʵ�ʷ����ǩ���ϣ�
��ʾ��k��Web����ʵ�ʷ����ǩ���ϣ�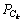 ��ʾ�Ե�k��Web����Ԥ��ķ����ǩ���ϡ�����ʾԤ����ȷ�ı�ǩ���ϡ�|��|��ʾԤ����ȷ�ı�ǩ��������ô��k��Web�����Ԥ��ȷ��pk���ٻ���rk�ֱ�Ϊ��
��ʾ�Ե�k��Web����Ԥ��ķ����ǩ���ϡ�����ʾԤ����ȷ�ı�ǩ���ϡ�|��|��ʾԤ����ȷ�ı�ǩ��������ô��k��Web�����Ԥ��ȷ��pk���ٻ���rk�ֱ�Ϊ��
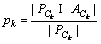 (5)
(5)
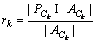 (6)
(6)
���������ĵ���ƽ��ȷ��P��ƽ���ٻ���RΪ��
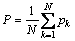 (7)
(7)
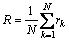 (8)
(8)
����F����ӳ�������ۺ����ܣ�
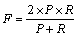 (9)
(9)
3.3 �Աȷ���
���IJ���LDA����ģ���뱾�ķ������бȽϡ�
LDA��������Web����������ı����н�ģ���õ�ÿ��Web���������ı����ĵ�����ֲ���������������ǰN��������ʽ�Web����������⻮�֡�
LDA-FCM���������������᷽������LDA���ɵ�ÿ���ĵ����ĵ�-��������ʹ��FCM�㷨��������������Ⱦ����������Ⱦ����Web������л������⡣
��ʵ���У����Ƚ���2�ַ����ľ������ܱȽϣ�֮����LDA-FCM�����У�ͨ������ģ������m���ҵ�������ֵ����Web������ࡣ
3.4 ʵ����
3.4.1 ģ������m��Web��������Ӱ��
��LDA-FCM�����У�Ϊ���ҳ���ѵ�ģ������m[23]��������һ��ʵ�飬��������k=100������£����m��Web��������Ӱ�졣����ȡ���Ϊ0.1��ͼ5��ʾ�ڲ�ͬmʱLDA-FCM������F�ֲ��������ͼ5���Կ�������m=2.0ʱ��F��ߣ�����mԶ��2.0��F���³����͵����ơ���ˣ���LDA-FCM�����У�ȡm=2.0�����ڻ�ýϺõ�ʵ��Ч����
ͼ5 ��k=100������£�m��ʵ������Ӱ��
Fig. 5 Impact of m on experimental result when k=100
3.4.2 �������ܱȽ�
��LDAԤ���趨��������k����Ϊ20��40��60��80��100����������N=1 000��ͬʱ��LDAģ���е�����������ͦ¸���������K���趨����=50/K����=0.1��ģ�������е�ģ�����ӣ�ȡ֮ǰ������ֵm=2������ظ���M=K������ÿһ��Kֵ��������100��ģ������ʵ�飬�Խ��ͳ�ʼ��ѡȡ�Ծ�������Ӱ�졣
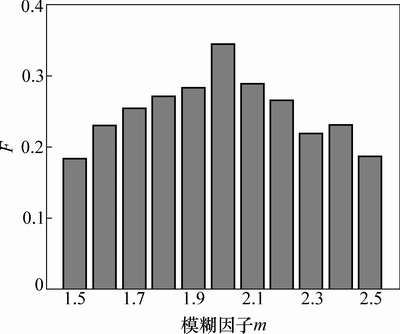
ͼ6��ʾΪ2�ַ�����ȷ�ʡ���ͼ6���Կ�����LDA-FCM��ͬһ�������µ�ȷ�ʱ�LDA�����ĸߡ�������Ϊ������������Web����Ķ���ԣ��Ϻõ�ʶ���Web����Ķ��ֹ��ܡ������������������ӣ�ÿ�ַ�����ȷ�ʶ���������������Ϊ������Խ�࣬���ֳ��Ĵ�������������Խ��ȷ�������ٻ������������ı仯��ͼ7����ͼ7�ɼ�����ͬһ������LDA-FCM�������ٻ���Ҳ��LDA�����ĸߣ���˵��LDA-FCM������LDA�����ܹ����ֳ���������õ�Web�����ǩ���ﵽ�����ľ���Ч����
ͼ6 ����ȷ�����������ı仯
Fig. 6 Precision with the change in the number of topics
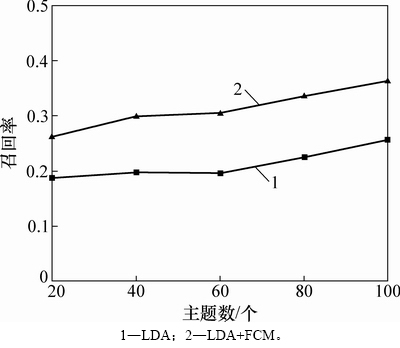
ͼ7 �����ٻ������������ı仯
Fig. 7 Recall with the change in the number of topics
F���������ı仯��ͼ8����ͼ8���Կ�������ͬһ�������£�LDA-FCM�������ۺ�Ч��ҲҪ����LDA�������ۺ�Ч����
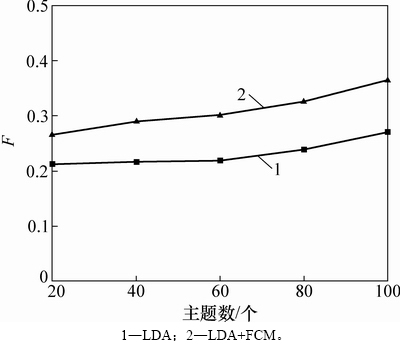
ͼ8 F���������ı仯
Fig. 8 F-score with the change in the number of topics
4 ����
1) ��Ե�ǰWeb��������㷨����ʵ��Web����Ķ�ܾ������⣬���һ�ֻ���LDAģ�ͺ�ģ��C��ֵ�㷨��Web�����ܾ�������÷�������ʹ��LDAģ�Ͷ�Web�����ĵ��������⽨ģ��Ȼ����Web�������������֮��������Ⱦ������������Ⱦ�����书�ܽ��л��֡�
2) ���ķ����ܹ�����Ч�ط���Web����Ķ��ֹ������ԣ����Web�����ֵľ��ȡ�
����һ�������У��⽫Word2Vec��LSTM������ģ�����ϣ���Web�����ĵ����н�ģ���Խ�һ�����Web�����ܷ����ȷ�ԡ�
�ο����ף�
[1] STANCULEA L. Service Oriented Architecture[J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2009, 1(1): 101-105.
[2] NAYAK R, LEE B. Web service discovery with additional semantics and clustering[C]//IEEE/WIC/ACM International Conference on Web Intelligence. Fremont, CA: IEEE, 2007: 555-558.
[3] ZHANG Xizhe, YIN Ying, ZHANG Mingwei, et al. Web service community discovery based on spectrum clustering[C]//International Conference on Computational Intelligence and Security. Beijing, China: IEEE Computer Society, 2009: 187-191.
[4] ZHANG Liangjie, LI Bing. Requirements driven dynamic services composition for Web services and grid solutions[J]. Journal of Grid Computing, 2004, 2(2): 121-140.
[5] DUSTDAR S, SCHREINER W. A survey on web services composition[J]. International Journal of Web & Grid Services, 2005, 1(1): 1-30.
[6] CHEN Liang, HU Liukai, ZHENG Zibin, et al. WTCluster: Utilizing Tags for Web Services Clustering[C]// International Conference on Service-Oriented Computing. Paphos, Cyprus: Springer-Verlag, 2011: 204-218.
[7] ELGAZZAR K, HASSAN A E, MARTIN P. Clustering WSDL Documents to Bootstrap the Discovery of Web Services. IEEE International Conference on Web Services. Washington D C, USA: IEEE Computer Society, 2010: 147-154.
[8] ʯ��, л��, ������. �����������ƶ�����Ϣ����Web�����ǩ�Ż�[J]. С���ͼ����ϵͳ, 2015, 36(6): 1153-1157.
SHI Lei, XIE Tao, CAO Yangjie. Web service tags optimization based on semantic similarity and quantity of information[J]. Journal of Chinese Computer Systems, 2015, 36(6): 1153-1157.
[9] CAO Buqing, LIU Xiaoqing, LI Bing, et al. Mashup service clustering based on an integration of service content and network via exploiting a two-level topic model[J]. IEEE International Conference on Web Services. San Francisco, USA: IEEE, 2016: 212-219.
[10] ZHANG Meng, LIU Xudong, ZHANG Richong, et al. A Web service recommendation approach based on QoS prediction using fuzzy clustering[C]//IEEE Ninth International Conference on Services Computing. Honolulu, USA: IEEE Computer Society, 2012: 138-145.
[11] ZHU Jieming, KANG Yu, ZHENG Zibin, et al. A Clustering-based QoS prediction approach for Web service recommendation. international symposium on object/component/ service-oriented real-time distributed computing workshops[J]. Shenzhen, China: IEEE Computer Society, 2012: 93-98.
[12] PLATZER C, ROSENBERG F, DUSTDAR S. Web service clustering using multidimensional angles as proximity measures[M]. New York, USA: ACM, 2009: 1-11.
[13] SUKUMAR A S S, LOGANATHAN J, GEETHA T. Clustering web services based on multi-criteria service dominance relationship using Peano Space filling curve[C]//International Conference on Data Science & Engineering. Washington D C, USA: IEEE, 2012: 13-18.
[14] LIU W, WONG W. Web service clustering using text mining techniques[J]. International Journal of Agent-Oriented Software Engineering, 2009, 3(1): 6-26.
[15] POP C B, CHIFU V R, SALOMIE I, et al. Semantic Web service clustering for efficient discovery using an ant-based method[M]. Intelligent Distributed Computing IV. Berlin, Heidecberg: Springer, 2010: 23-33.
[16] ����, ��С��, �ܲ���, ��. �ں�K-Means��Agnes��Mashup��������[J]. С���ͼ����ϵͳ, 2015, 36(11): 2492-2497.
HUANG Xing, LIU Xiaoqing, CAO Buqing, et al. MSCA: Mashup service clustering approach integrating K-means and agnes algorithms[J]. Journal of Chinese Computer Systems, 2015, 36(11): 2492-2497.
[17] BLEI D M, NG A Y, JORDAN M I.Latent dirichlet allocation[J]. Journal of Machine Learning Reserach, 2003, 3(3): 993-1022.
[18] AZNAG M, QUAFAFOU M, ROCHD E M, et al. Probabilistic topic models for web services clustering and discovery[C]// ESOCC. Berlin, Heidelberg: Springer-Verlag, 2013: 19-33.
[19] ����, �ڽ�. ���ڻ��ֵ�ģ�������㷨[J]. ����ѧ��, 2004, 15(6): 858-868.
ZHANG Min, YU Jian. Fuzzy partitional clustering algorithms[J]. Journal of Software, 2004, 15(6): 858-868.
[20] HASAN M H, JAAFAR J, HASSAN M F. Development of web services fuzzy quality models using data clustering approach[J]. Lecture Notes in Electrical Engineering, 2014, 285: 631-640.
[21] GHOLAMZADEH N, TAGHIYAREH F, SHAKERY A. Fuzzy clustering for semantic web services discovery based on ontology[J]. International Journal of Information & Communication Technology, 2010, 2(3): 1-8.
[22] LOPER E, BIRD S. NLTK: the natural language toolkit[C]//Proceedings of the ACL Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics. Philadelphia, USA, 2002: 17-21.
[23] ���²�, ��̺�, лά��. ģ��c-��ֵ�����㷨�м�Ȩָ��m���о�[J]. ����ѧ��, 2000, 28(4): 80-83.
GAO Xinbo, PEI Jihong, XIE weixin. A study of weighting exponent m in a fuzzy c-means algorithm[J]. Chinese Journal of Electronics, 2000, 28(4): 80-83.
(�༭ �²ӻ�)
�ո����ڣ�2018-01-12�������ڣ�2018-03-21
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61872139��61873316��61572187��61702181)������ʡ��Ȼ��ѧ����������Ŀ(2017JJ2098��2018JJ2136)(Projects(61872139, 61873316, 61572187, 61702181) supported by the National Natural Science Foundation of China; Projects(2017JJ2098, 2018JJ2136) supported by the Natural Science Foundation of Hunan Province)
ͨ�����ߣ�����ѫ�����ڣ���ʿ����ʦ�����·���������Ƽ��㡢������������������Ӧ�õ��о���E-mail��ljx529@gmail.com
ժҪ������Web�����ַ���ͨ���ǽ�Web�������ijһ���̶��Ĺ������У����¸�Web�������������Ա����ԣ�Web�������Դ�����ʽ��͵����⣬���һ�ֻ���LDA��ģ��C��ֵ��Web�����ܾ���������ȣ���ProgrammableWeb.com��վ����ȡWeb�������ݣ�����ȡWeb���������ĵ�����Σ�ʹ��LDA����ģ�Ͷ�Web���������ĵ����н�ģ����ð�����ͬ������Ϣ���ĵ��������������ĵ����������ʹ��ģ��C��ֵ�㷨��Web������ൽ��ͬ�Ĺ������У����Web����Ķ�ܾ��ࡣ�о����������Web����Ķ��������ʵ����˷����ֵľ��ȡ�
