
�ں�PPI�ͻ���������ݵĹؼ�������ʶ��
�������ź��ᣬ��ҫƽ
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժ Ҫ��
���˻���������ݺ�PPI���������������ʶ��ؼ������ʵ������Բ��PeC�����������е�ÿһ���ߣ�PeC���ȼ���ñߵľۼ�ϵ���ñ�������2������(������)�������Ƥ��ѷ���ϵ�������ڴ˻����Ͻ�һ��������ñߵ�Ȩֵ��������ÿ���ڵ��PeCֵ��Ϊ�������ӵ����бߵ�Ȩֵ֮�͡����ڽ�ĸPPI�����ϵ�ʵ����������PeC������������8�����������˲���DC��BC��CC��SC��EC��IC��LAC��SoECC���ر�أ���Ԥ��ĵ�����������������������10%������£�PeC��Ԥ��ȷ�������SC��CC�� EC���20%���ϡ�
�ؼ��ʣ�
�ؼ������������������������������������߾ۼ�ϵ����Ƥ��ѷ���ϵ����
��ͼ����ţ�TP301.6��Q31��Q71 ���ױ�־�룺A ���±�ţ�1672-7207(2013)03-1024-06
Essential protein discovery method based on integration of PPI and gene expression data
LI Min, ZHANG Hanhui, FEI Yaoping
(School of Information Science and Engineering, Central South University, Changsha 410083, China)
Abstract: A new method for identifying essential proteins based on the integration of PPI and gene expression data named PeC was proposed. For each edge of the network, its edge clustering coefficient (ECC) and Pearson correlation coefficient (PCC) were calculated. And then, the weight of each edge was computed based on ECC and PCC. Then, a protein��s PeC value was defined as the sum of weights of the edges connected to it. The experimental results on the yeast protein interaction network show that PeC is obviously higher than other eight centrality measures (DC, BC, CC, SC, EC, IC, LAC and SoECC) in the prediction accuracy of essential proteins. Especially, for less than the top 10% proteins selected as the candidate essential proteins, the prediction accuracy of PeC has 20% higher than those of SC, CC and EC.
Key words: essential proteins; protein interaction network; gene expression; edge clustering coefficient; Pearson correlation coefficient
�ؼ���������ϸ���������������ĵ����ʣ����û�����ʽͻ�佫���Ƴ�������йص����ʸ����幦��ɥʧ����������������������[1]����ˣ�ʶ��ؼ������ʶ����о�ϸ�����������ع��̾�����Ҫ���塣ͬʱ���о��������²�������������Ϊ�ؼ�������[2]���ؼ������ʵ�ʶ����ڲ�ԭ����ѧ���о��Լ�ҩ�����Ҳ������Ҫ�����塣������ѧ����һ�����û����ó���RNA���ŵ�ʵ�鷽����ͨ���۲��������������������ʵĹؼ��ԡ���������ʵ��ʶ��ؼ������ʵķ�����Ȼȷ��Ч�����Ǵ��۸���Ч�ʵ͡������������Ž�ĸ˫�ӽ��������ʹ������������ȸ�ͨ���ĵ������鼼���ķ�չ[3]���ɻ�õĵ��������������Խ��Խ�࣬ʹ��������ˮƽ��Ԥ��ؼ������ʳ�Ϊ���ܡ������о������������ʵĹؼ�����������������������Ӧ�ڵ���������������� ��[4]����ˣ�������һϵ�����ýڵ�������Բ�Ȳ���ʶ��ؼ������ʵķ�������õ�һ�������Բ���Ƕ�������(degree centrality)[5]��������ij�������ڵ�Ķ������Ա�ʾΪ����ֱ���������ھӽڵ�ĸ�����Jeong��[5]�����������-�����ԡ�����(centrality- lethality rule)���÷�����ʾһ�������ʲ���������Խ�࣬��������ʶ�ϸ��������Ҳ��Խ��Ҫ��������õĶ����������⣬���н���������[6]���ӽ���������[7]����ͼ������[8]����������������[9]����Ϣ������[10]���ֲ�ƽ����ͨ��[11]�ͱ߾ۼ�ϵ��֮��[12]�����У��ڵ�Ľ���������(betweenness centrality, BC)��ʾ�������������·���о����ýڵ����Ŀռ�������·�����ı������ڵ�Ľӽ���������(closeness centrality, CC)Ϊ�����ڸýڵ㵽�������������нڵ�����·��֮�ͣ��ڵ����ͼ������(subgraph centrality, SC)�Ǹýڵ��������պϻ�·���������ڵ����������������(eigenvector centrality, EC)������Ϊ�����ڽӾ���������������ýڵ�ķ������ڵ����Ϣ������(information centrality, IC)�Dz����Ըýڵ�Ϊ�˵��·���ĵ���ƽ�����ȣ��ڵ�ľֲ�ƽ����ͨ��(local average connectivity��LAC)��ָ�ýڵ���ھӽڵ�˴�֮�乫���ھӽڵ�ĸ���֮�ͳ��Ըýڵ���ھӽڵ�ĸ������ڵ�ı߾ۼ�ϵ��֮��(sum of edge clustering coefficient��SoECC)��ָ�ýڵ��������ӱߵľۼ�ϵ��֮�͡���8�������Բ�ȶ��ѱ��������������йؼ������ʵ�Ԥ�⣬�ұ�֤ʵ�Ƚ���Ч��Ȼ���������Բ�������������PPI����ʶ��ؼ������ʣ�Ԥ���ȷ�ȱȽ��������籾���Ŀɿ��ԡ���ˣ������������һ���µ������Բ�Ȳ���PeC����PPI����Ļ������ںϻ�����������Ϣ������Ԥ�ⷽ���Ե�������������籾���ɿ��Ե������̶ȣ���������Ĺؼ�������Ԥ�ⷽ��PeCӦ���ڽ�ĸ��������������硣
1 �ںϻ������������Բ��PeC
���ǵ��߶ȵĽڵ������ڳ�Ϊ�ؼ������ʣ����ؼ������ʽڵ������ֳɴس��֣����Ҿ��нϸߵĹ���������[13]�����ԣ����һ���ںϻ��������Ϣ���µ������Բ��PeC��PPI������Ա�ʾ��Ϊ1������ͼG(V,E)��ÿ���ڵ��ʾ1�������ʣ�ÿ���߱�ʾ1������ã�����V��ʾ�ڵ�ļ��ϣ�E��ʾ�ߵļ��ϡ������������������ѧ��ͨ������ʵ��õ����������˵����������˶��Ĺ��̣��ڲ�ͬ��ʱ�̵�����X�Ļ������ֵ��ͬ�����Ա�ʾΪX(g1, g2, ��, gk)�����У�gk��ʾ�����ʽڵ�X��ʱ��k�Ļ������ֵ��Ϊ����������������Բ��PeC���������ȸ�����ض��塣
1.1 �߾ۼ�ϵ��(ECC)
�ۼ�ϵ��������Watts��Strogatz��������ڿ̻�������ij���ڵ������ھ�֮�������̶ȣ��Ǹ�������������Ҫ����������֮һ���ѱ��㷺Ӧ���ڵ��������������Ƚϸ�����������˷���[14]�����������ۼ�ϵ���Ķ������ɽڵ���չ���ߣ�����ѡ������[15]�и����ı߾ۼ�ϵ��(edge clustering coefficient, ECC)�Ķ��塣����PPI�����е�1����E(X,Y)����N(X)��N(Y)�ֱ��ʾ�ڵ�X�ͽڵ�Y���ھӽڵ�ļ��ϣ����E(X,Y)�ı߾ۼ�ϵ��������Ϊ
 (1)
(1)
�߾ۼ�ϵ��ECC(X,Y)��һ���ֲ��������̻��˱�E(X,Y)��2���ڵ�X��Y������̶ȡ�E(X,Y)��ȡֵ��ΧΪ[0,1]����ȡֵԽ�����ڵ�X�ͽڵ�Y����ͬһ���صĿ�����Խ��
1.2 ��������Ƥ��ѷ���ϵ��(PCC)
�������������������ʾ�����������˶��Ĺ��̵�һ�����ݣ�������н�ģ��������Ƥ��ѷ���ϵ��(pearson correlation coefficient, PCC)����������õ����ʵĻ�����ǿ���̶ȣ�������X��Y��PCC����Ϊ

 (2)
(2)
���У�kΪ����������ʾ������������е�ʱ������Exp(X,i)��Exp(Y,i)�ֱ�Ϊ������X��Y����iʱ�̵ı���ֵ��Exp(X)��Exp(Y)Ϊ������X��Y������ʱ���µ�ƽ������ֵ����(X)�ͦ�(Y)��ʾ������X��Y������ʱ�̱���ֵ�ı����PCC(X,Y)��ȡֵ��ΧΪ[-1,1]��PCC(X,Y)��0˵������X��Y���ֳ�����أ�PCC(X,Y)��0˵������X��Y���ֳ�����أ�PCC(X,Y)=0˵������X��Y����������ԡ�
1.3 �����Բ��PeC
��Ȼ��������-�����ԡ�������ʾ1�������ʲ���������Խ�࣬���������Խ�����ڳ�Ϊ�ؼ������ʣ����о���������Ȼ����һ���ֵ����ʾ��нϸߵĶȣ������ǹؼ������ʡ�ͨ��ʵ�鷢�֣����൰���ʲ����������������нϵ͵ı߾ۼ�ϵ�����һ�����̶Ƚϵ͡����磬��ͼ1��ʾ�ǹؼ�������YGR254W��67���ھӽڵ㣬���������ھӽڵ�ı߾ۼ�ϵ����ƽ��ֵ��Ϊ0.054�����ھӽڵ�Ĺ������Ƥ��ѷϵ��PCC��ƽ��ֵ��Ϊ0.003��

ͼ1 �ǹؼ�������YGR254W���ھӽڵ�Ĺ�ϵͼ
Fig.1 Relationship figure for non-essential protein YGR254W and its neighbors
���ڶԸ߶ȵķǹؼ������ʵķ������Լ��ؼ������ʽڵ������ɴس����������ڹ��������ʵ�����ñ߾ۼ�ϵ��(ECC)��Ƥ��ѷ���ϵ��(PCC)�������E(X,Y)����ͬһ�صĸ���PC(X,Y)���������£�
 (3)
(3)
PC(X,Y)���������˱�E(X,Y)�Ľڵ�X��Y��������������Եľۼ��̶ȣ����������˽ڵ�X��Y������̶ȶ��ڹؼ��Ե�Ӱ�졣���ǵ��߶ȵĽڵ������ڳ�Ϊ�ؼ������ʣ���PC(X,Y)������E(X,Y)��Ȩֵ����ڵ�X�������Բ��PeC(X)����X�����ӱߵ�Ȩֵ֮�ͣ�
 (4)
(4)
PeC�ۺϿ����˱߾ۼ�ϵ���ͻ���������ݣ������E(X,Y)��Ȩ�ȣ����Խ�һ���ֶ������Խϸߵ������ǹؼ������ʵĽڵ��ų�����ˣ����нϸߵ�ȷ�ȡ�
2 ʵ�����ݼ���������
2.1 ʵ������
�����������У���ĸ�ĵ����������������Ϊ�걸����ˣ�ѡ���ĸ�����������������Ϊ�о�����ʵ�����õ����ݼ���Դ��MIPS[16]���ݼ�������4 546���ڵ��12 319������á��ؼ�������������ͨ������MIPS[16]��SGD[17]��DEG[18]��SGDP[19]4�����ݿ��е����ݵ���������1 285���ؼ������ʡ�ʵ�����õĻ��������������������[20]�����а�����6 777��������36������ʱ���µĻ������ֵ����4 858���������ĸ����������������������ͨ���ȶ����ϵĹؼ������ʼ��ϣ�MIPS���ݼ�����1 016���ؼ������ʣ�3 195���ǹؼ������ʺ�335���ؼ���δ֪�ĵ����ʡ�
2.2 ��������
���ݡ�����-ɸѡ��ԭ���PeC��8�������Բ�ȵ�Ԥ�������бȽϡ����������ǣ�����PeC��8�������Բ�Ȳ������մӴ�С��˳������ѡ��������ǰ1%��5%��10%��15%��20%��25%�ĵ�������Ϊ��ѡ�ؼ������ʣ�ͨ������֪�ؼ����������ݼ�ƥ�䣬�õ�ÿ�ֲ��ʶ����ȷ�Ĺؼ������ʵ���������Ƚϡ�����֮�⣬���������ж�(SN)��������(SP)��F-���(F-measure)����ȷ��(ACC)�⼸��ҽѧ�����е�ָ���PeC����������������8�������Բ�Ƚ���Ƚϡ��⼸������ָ��Ķ������£�
���ж�SNΪ�ؼ������ʱ���ȷ��Ԥ��ı�����
 (5)
(5)
������SPΪ�ǹؼ������ʱ���ȷ���ų��ı�����
 (6)
(6)
ʽ�У�PT��ʾ��Ȳ���ʶ��Ĺؼ�����������֪�ؼ�������ƥ���������PF��ʾ���㷨��ʶ��Ϊ�ؼ������ʵķǹؼ������ʵ�������NT��ʾ�ǹؼ������ʱ�ʶ��Ϊ�ǹؼ������ʵĸ�����NF��ʾ��Ȳ���û��ʶ����Ĺؼ������ʵ�������
F-���FmeasureΪ���жȺ������Եĵ���ƽ��ֵ��
 (7)
(7)
��ȷ��ACCΪ
 (8)
(8)
����Ԥ��ֵ(PPV)VPPΪѡ���ĵ������б���ȷ��Ԥ��Ϊ�ؼ������ʵı�����
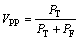 (9)
(9)
����Ԥ��ֵ(NPV) VNPΪ�ų��ĵ������б���ȷԤ��Ϊ�ǹؼ������ʵı�����
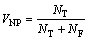 (10)
(10)
3 ʵ��������
ÿ�ֲ�Ȳ���ʶ����ȷ�Ĺؼ�����������ͼ2 ��ʾ��
��ͼ2���Կ���������PeCԤ����ȷ�Ĺؼ������������ձ����8�������Բ��Ԥ����ȷ�Ĺؼ���������������һ����ˮƽ��PeC��CC��SC��EC��3����Ȳ�����Ԥ�������ʸ�13%���ϣ���ǰ1%��5%��10%����ˮƽ��PeC��CC��SC��EC��3����Ȳ�����Ԥ�������ʸ�20%���ϡ�
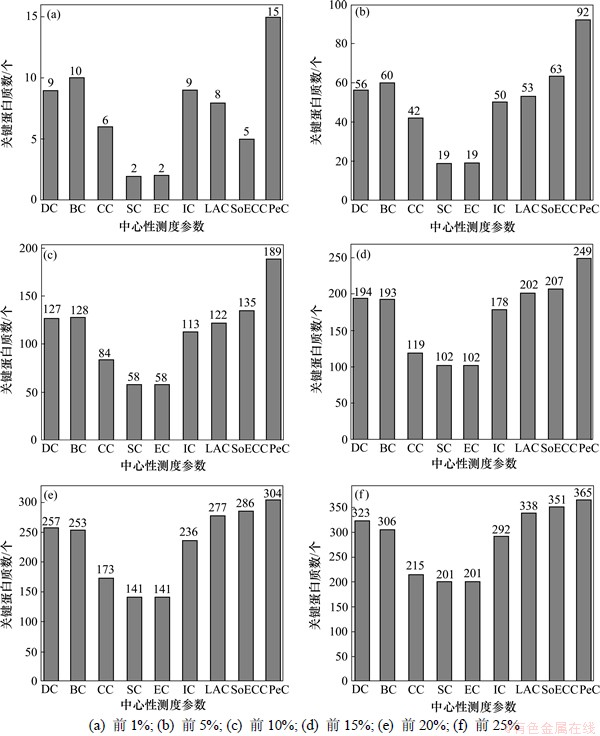
ͼ2 ����PeC������8�������Բ��Ԥ����ȷ�Ĺؼ���������
Fig.2 Number of essential proteins by Pec and eight other centrality measures
ͬʱ��Ϊ�˸�ϸ�µرȽ�PeC������8�������Բ����Ԥ�ⲻͬ�����Ĺؼ�������ʱ��ȷ�ԣ��Ƚ������ǵ�Jackknife��ʵ������ͼ3��ʾ����ͼ3���Կ�����PeC�����Բ������һ�ۻ������ĵ�������ʶ��Ĺؼ������ʶ�������8�������Բ��ʶ��Ķࡣ

ͼ3 PeC������8�������Բ�ȵ�Jackknife
Fig.3 Jackknife of PeC and eight other centrality measures
���⣬�������ж�(SN)��������(SP)��F���(F-measure)����ȷ��(ACC)������Ԥ��ֵ(PPV)������Ԥ��ֵ(NPV)�⼸������ָ���PeC������8�������Բ�Ƚ�����������Ƚϣ�ʵ�������1��ʾ���ӱ�1���Կ���������һָ��(SN��SP��F-measure��ACC��PPV��NPV)�£�PeC��������õĽ����
��1 PeC������8�������Բ�ȵĸ�������ָ��ıȽ�
Table 1 Comparison of Evaluation Indicator by PeC and other eight centrality measures

4 ����
(1) �����һ���µ��ں���PPI�ͻ���������ݵ������Բ��(PeC)��
(2) �������Բ��PeC�ڵ���������������������ԵĻ������ں��˻���������ݣ������˶Ե�������������籾���ɿ��Ե������������Ԥ���ȷ�ԡ���8�ֽڵ������Բ�Ȳ����Աȣ�PeC�ܹ�Ԥ�������Ĺؼ������ʣ���Ԥ��ȷ�ȸ��ߡ����У���MIPS���ݼ�ǰ1%��5%��10%������ˮƽ��PeC��CC��SC��EC��Ԥ��ȷ�Ⱦ������20%���ϡ�
�ο����ף�
[1] Winzeler E A, Shoemaker D D, Astromoff A, et al. Functional characterization of the S. cerevisiae genome by gene deletion and parallel analysis[J]. Science, 1999, 285: 901-906.
[2] Jeong H, Oltvai Z, Barab��si A L. Prediction of protein essentiality based on genomic data [J]. ComPlexUs, 2003, 1(1): 19-28.
[3] Mering C, Krause R, Sne B, et al. Comparative assessment of large-scale data sets of protein�Cprotein interactions[J]. Nature, 2002, 417: 399-403.
[4] Barab��si AL., Oltvai ZN. Network biology: Understanding the cell��s functional organization[J]. Nat Rev Genet, 2004, 5(2): 101-113.
[5] Jeong H, Mason S, Barab��si A L, et al. Lethality and centrality in protein networks[J]. Nature, 2001, 411: 41-42.
[6] Joy M P, Brock A, Ingber D E, et al. High-betweenness proteins in the yeast protein interaction network[J]. Journal of Biomedicine and Biotechnology, 2005(2): 96-103.
[7] Wuchty S, Stadler P F. Centers of complex networks[J]. Journal of Theoretical Biology, 2003, 223(1): 45-53.
[8] Estrada E, Rodr��guez-Vel��zquez J A. Subgraph centrality in complex networks[J]. Phys Rev E, 2005, 71(5): 056103.
[9] Bonacich P F. Power and centrality: A family of measures[J]. American Journal of Sociology, 1987, 92(5): 1170-1182.
[10] Stevenson K, Zelen M. Rethinking centrality: Methods and examples[J]. Social Networks, 1989, 11(1): 1-37.
[11] LI Min, WANG Jianxin, CHEN Xiang, et al. A local average connectivity-based method for identifying essential proteins from the network level[J]. Computational Biology and Chemistry, 2011, 35: 143-150.
[12] WANG Huan, Li Min, Wang Jinxin, et al. New method for identifying essential proteins based on edge clustering coefficient[C]//7th International Symposium on Bioinformatics Research and Applications. Heidelberg: Springer-Verlag, 2011, 6674: 87-98.
[13] PANG Kaifang, SHENG Huanye, MA Xiaotu. Understanding gene essentiality by finely characterizing hubs in the yeast protein interaction network[J]. Biochemical and Biophysical Research Communications. 2010, 401(1): 112-116.
[14] ����. ����������������и��������ģ���ھ��㷨�о�[D]. ��ɳ: ���ϴ�ѧ��Ϣ��ѧ�빤��ѧԺ, 2008: 72-73.
LI Min. Identifying protein complexes and functional modules in protein interaction networks[D]. Changsha: Central South University. School of Information Science and Engineering, 2008: 72-73.
[15] Watts D J, Strogatz S H. Collective dynamics of ��small-world�� networks[J]. Nature, 1998, 393: 440-442
[16] Mewes H W, Frishman D, Mayer K F, et al. MIPS: analysis and annotation of proteins from whole genomes in 2005[J]. Nucleic Acid Research, 2006, 34(1): 169-172.
[17] Cherry J M, Adler C, Ball C, et al. SGD: Saccharomyces genome database[J]. Nucleic Acid Research, 1998, 26(1): 73-79.
[18] ZHANG Ren, LIN Yan. DEG 5.0: A database of essential genes in both prokaryotes and eukaryotes[J]. Nucleic Acid Research, 2009, 37(1): 455-458.
[19] Bruno A, Jef B, Carla C, et al. SGDP: Saccharomyces Genome Deletion Project [EB/OL]. [2007-12-30] http://www-sequence. stanford.edu/group/yeast_deletion_project/deletions3.html.
[20] Tu B P, Kudlicki A, Rowicka M, et al. Logicof the yeast metabolic cycle: Temporal compartmentalization of cellular processes[J]. Science, 2005, 310: 1152-1158.
(�༭ �Կ�)
�ո����ڣ�2012-02-22�������ڣ�2012-05-05
������Ŀ��������Ȼ��ѧ����������Ŀ(61003124)���ߵ�ѧУ��ʿ��ר�����������Ŀ(20090162120073)������ʡ�Ƽ��ƻ���Ŀ(2009FJ3053)
ͨ�����ߣ�����(1978-)��Ů�����������ˣ���ʿ�������ڣ�����������Ϣѧ�о����绰��0731-88877936��E-mail: limin@csu.edu.cn
ժҪ�����һ���µ��ں��˻���������ݺ�PPI���������������ʶ��ؼ������ʵ������Բ��PeC�����������е�ÿһ���ߣ�PeC���ȼ���ñߵľۼ�ϵ���ñ�������2������(������)�������Ƥ��ѷ���ϵ�������ڴ˻����Ͻ�һ��������ñߵ�Ȩֵ��������ÿ���ڵ��PeCֵ��Ϊ�������ӵ����бߵ�Ȩֵ֮�͡����ڽ�ĸPPI�����ϵ�ʵ����������PeC������������8�����������˲���DC��BC��CC��SC��EC��IC��LAC��SoECC���ر�أ���Ԥ��ĵ�����������������������10%������£�PeC��Ԥ��ȷ�������SC��CC�� EC���20%���ϡ�
