
J. Cent. South Univ. Technol. (2008) 15: 733-737
DOI: 10.1007/s11771-008-0135-3
![]()
Mining association rules in incomplete information systems
LUO Ke(�� ��)1, WANG Li-li(������)1, 2, TONG Xiao-jiao(ͯС��)1
(1. School of Computer and Communication Engineering, Changsha University of Science and Technology,
Changsha 410076, China;
2. Department of Computer Science and Technology, Dezhou University, Dezhou 253023, China)
Abstract:
Based on the rough set theory which is a powerful tool in dealing with vagueness and uncertainty, an algorithm to mine association rules in incomplete information systems was presented and the support and confidence were redefined. The algorithm can mine the association rules with decision attributes directly without processing missing values. Using the incomplete dataset Mushroom from UCI machine learning repository, the new algorithm was compared with the classical association rules mining algorithm based on Apriori from the number of rules extracted, testing accuracy and execution time. The experiment results show that the new algorithm has advantages of short execution time and high accuracy.
Key words:
1 Introduction
Incomplete information system (IIS) widely exists in real life. Incompleteness of objects is the biggest obstacle of studying from data. There are two types of approaches for IIS. One is to handle the incomplete objects so that they become complete systems. The main methods include removing methods[1], filling the missing values[2-4], expanding methods[5]. But relative to the original data, these methods above may make the data distorted to some degree, and noisy may be introduced into datasets, and therefore the rules extracted are unusable. The other is to obtain the rules from IIS directly. The common method is based on rough sets[6-7]. In Ref.[6], an approximation set based on non-symmetric similarity relation was defined, and an algorithm for certain rule induction was developed to mine the rules directly. This method can only mine certain rules, but cannot extract potential probable rules which meet some confidence criteria. In Ref.[7], attributes were partitioned into complete parts and incomplete parts complied with hierarchical principle, and then they used different approaches hierarchically to mine rules satisfied with confidence directly. The disadvantage of this method is that it is inefficient when more missing values almost exist in every attribute, and the method degenerates into single layer.
Association rules mining, as an important technique of data mining, was firstly developed by AGRAWAL et al[8]. We note that most of algorithms for association rules mining are only applied to complete systems. An ordinary way in IIS is to transform incomplete databases into complete ones first[9-13], and then to mine association rules.
Therefore, in this work an algorithm to mine association rules in incomplete information systems was presented and the support and confidence were redefined based on the rough set theory.
2 Basic concepts
2.1 Association rules
The aim of association rules mining is to find out the hidden, interesting relationships among the items in large datasets. The basic concepts of mining association rules are given as follows[14].
Let I={I1, I2, ��, Im} be a set of items and D={t1, t2, ��, tn} be a set of transactions, where ti is a set of items such that ti��I. An association rule is an implication of the form ![]() , where
, where ![]() and
and ![]() Rule
Rule ![]() holds in set D with support(s) and confidence(c), where s is the percentage of transactions in D that contains both X and Y, and c is the percentage of transactions in D containing X that also contains Y.
holds in set D with support(s) and confidence(c), where s is the percentage of transactions in D that contains both X and Y, and c is the percentage of transactions in D containing X that also contains Y.
An association rule must satisfy a user-set minimum support(minsup) and minimum confidence(minconf). Rule![]() is called a strong association rule if s��minsup and c��minconf.
is called a strong association rule if s��minsup and c��minconf.
2.2 Association rules with decision attributes
Usually association analysis is not given decision attributes so that we can find association and dependence between attributes to the best of our abilities. But the aimless analysis may take much time and space. Decision attributes determined can reduce the amount of candidate sets and searching space, and then improve the efficiency of algorithms to some extent[12].
In addition, users are not interested in all association rules, but they are just concerned about the associations among condition attributes and decision attributes. So, in this work we just mine association rules with decision attributes, in which, we consider attributes that users are concerned about as the decision attributes and other attributes as the condition attributes.
2.3 Incomplete information systems (IIS)
IIS is the widest form of data existence. The definition of incomplete information systems (IIS) is given as follows[15].
Definition 1 Information system S is a tuple S=(U, A, V , f), where U is a nonempty finite set of objects called the universe of discourse; A is a nonempty finite set of attributes containing sets of condition attributes C and decision attributes D, where A=C��D, C��D=![]() and x��U, a��D, f(x, a)��*, i.e. there are no missing values in decision attributes; Va is a set of values for
and x��U, a��D, f(x, a)��*, i.e. there are no missing values in decision attributes; Va is a set of values for
attribute a, ![]() f: U��A��V is an information
f: U��A��V is an information
function, and it gives a value to every attribute, i.e.![]() , x��U, f(x, a)��Va.
, x��U, f(x, a)��Va.
If ![]()
![]()
![]() the information system is called incomplete information system(IIS), otherwise it is complete.
the information system is called incomplete information system(IIS), otherwise it is complete.
3 Approaches to mining association rules in IIS
3.1 Preprocessing by rough sets
It is hoped to handle data with no changes of the original information for mining association rules in IIS. Rough set theory is a new mathematical approach to deal with imprecision, uncertainty and incompleteness[16]. In this work, equivalence relation, upper and lower approximation, and boundary are redefined for mining association rules with decision attributes.
Definition 2 Let IS=(U, A, V, f ) be a complete information system, ![]() >, where a��A, v��Va.
>, where a��A, v��Va.
Definition 3 Let IS=(U, A, V, f ) be a complete information system, equivalence relation RX based on item X is expressed as
![]() (1)
(1)
where RX indicates the set of objects that match X in U.
Because there are missing values(*) in IIS, the equivalence relation does not exist in datasets. But we can define the maximum set and the minimum set of objects matching to items. These definitions are similar to upper and lower approximations in classical rough set.
Definition 4 Let IIS=(U, A, V, f) be an IIS, for x��U, we denote RX as the maximum set of the objects that are equivalent to X, i.e.
RX![]() (2)
(2)
and denote ![]() as the maximum set of the objects that are similar to X, i.e.
as the maximum set of the objects that are similar to X, i.e.
![]() (3)
(3)
the boundary of X is defined as
![]() RX (4)
RX (4)
It can be seen from Definition 4 that ![]() indicates the set of objects that are surely unable to match X; and U-RX indicates the set of objects which may not match X.
indicates the set of objects that are surely unable to match X; and U-RX indicates the set of objects which may not match X.
3.2 Redefinition of support and confidence
When mining association rules in IIS, if we use the same support and confidence as complete information system, we may not find useful rules. If we lower the parameters, useful rules may be covered by a lot of new and useless rules. So in this work, some concepts of association rules are redefined.
3.2.1 Estimates of support and confidence
In IIS the support and confidence are not as easily calculated exactly as those in complete databases. But the minimal and maximal possible values of support and confidence can be defined.
Definition 5 The minimal possible support (Smin) of items of X is

and the maximal possible support(Smax) of items of X is
![]() (6)
(6)
Definition 6 The minimal possible confidence (Cmin) of the association rule![]() is
is

and the maximal possible confidence(Cmax) of the association rule![]() is
is
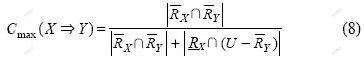
Based on the above definitions, Property 1 can be expressed easily.
Property 1 Smin(X)��s��Smax(X), Cmin![]() ��c��Cmax
��c��Cmax![]() .
.
3.2.2 Predictions of support and confidence
The above formulas give the estimates of support and confidence of rules in IIS. When the difference between the minimal and the maximal possible support is great, it is still very difficult to process the data. It is very favorable to the problem if we can predict the values of support and confidence that are closer to the actual ones.
In the rough set theory, the uncertainty of rough set is caused by the uncertainty of rough boundary[16], and the greater the rough boundary of X is, the smaller the certainty of rough set is. The greater difference between the minimal and the maximal possible support shows that the boundary of rough set X is large. We reduce the difference based on rough boundary so as to predict the support value close to the actual one.
Definition 7 Prediction support(Spre) of items of X is
![]() (9)
(9)
According to the definitions of Smin, Smax and boundary of X, property 2 can be obtained.
Property 2 Let X be a set of items, then there exists |bnR(X)|/|U|= Smax(X)-Smin(X).
Definition 7 is redefined as
![]() (10)
(10)
Definition 8 The prediction confidence(Cpre) of the association rule ![]() is
is

It can be seen from Eqn.(10) that when the difference between the minimal and the maximal possible support is great, the rough boundary is great too, i.e. the denominator in the formula becomes small. Judging from this, the difference is reduced by enlarging Smin(X) which is the most conservative value of the support, so we can predict the support value closer to the actual one.
The strong association rule is redefined after the prediction support and the prediction confidence are introduced.
Definition 9 The rule ![]() is called a strong association rule if Spre
is called a strong association rule if Spre![]() ��minsup and Cpre
��minsup and Cpre![]() ��minconf.
��minconf.
4 Description of mining algorithm
In Ref.[12], an algorithm for mining association rules with decision attributes was proposed in complete information system. This algorithm was based on classical Apriori, ensuring that Lk certainly included decision attributes. On the basis of this algorithm, the prediction support and prediction confidence were introduced in mining algorithm in this work. And then an algorithm for association rules with decision attributes in incomplete information system (MARDA_IIS) was put forward. MARDA_IIS consists of two steps that are expressed respectively as follows.
Step 1 Generating all frequent. An improved Apriori is used to discover all frequent items. The length of frequent items is not more than the sum of count of condition attributes and count of decision attributes. The algorithm is as follows.
C1={large 1-itemsets}; /*Generate itemsets*/
for all candidates c��C1
{compute Spre(c) according to formula (10); /* Compute prediction support of c��C1*/
if (Spre(c)��=minsup )
L1={c��C1|Spre(c)��=minsup}; /*Generate frequent 1-itemsets*/
��
if (c���L1|Spre(c��)��=minsup&&d���L1|Spre(d��)��= minsup) /* c���Condition attribute set C, d���Decision attribute set D */
{for (k=2; k��=Count(D)+1; k++) /*Generate candidates contained all decision attributes and one condition attribute*/
{Ck=Apriori_gen(c���L1, d���Lk-1); /*Generate new candidates */
for all new candidates c��Ck
{compute Spre(c) according to formula(10); /*Compute prediction support of c��Ck*/
if (Spre(c)��=minsup)
Lk={c��Ck | Spre(c)��=minsup};
}
}
for (k=3; k��=Count(D)+Count(C); k++) /* Generate candidates contained all decision attributes and condition attributes */
{Ck=Apriori_gen(c���Lk-1, d���L k-1);
for all new candidates c��Ck
{
compute Spre(c) according to formula (10);
if (Spre(c)��=minsup)
Lk={c��Ck | Spre(c)��=minsup};
}
��
��
Answer=��Lk.
Step 2 Mining association rules according to confidence.
For each frequent itemset c��L
for each c���subset(c), d���subset(c) /* c��� Condition attribute set C, d���Decision attribute set D */
{compute Cpre (c���d��) according to formula (11); /* Compute prediction confidence of rules*/
if Cpre(c���d��)��=minconf
output (c���d��);
}
5 Experiments
The following three experiments used Mushroom dataset obtained from UCI machine learning repository. This dataset contains 23 discrete attributes with 8 124 samples and 2 480 missing values. In this work, we only mined that Mushroom is edible or poisonous, so the attribute ��class name�� was determined as decision attribute. To testify the effectiveness and performance of MARDA_IIS, in the first experiment MARDA_IIS was compared with the classical association rules mining algorithm based on Apriori(MAR_Apriori). And before Apriori, missing values were completed based on fuzzy-clustering in Ref.[9]. The experiment was executed on Celeron(R) CPU 2.53 GHz machine and the software was VC++. The experiment results are listed in Table 1.
Table 1 Results of the first experiment using Mushroom dataset from UCI

It can be seen from Table 1 that the number of rules obtained by MARDA_IIS is nearly as much as that by the algorithm based on Apriori. But MARDA_IIS has obvious improvement in accuracy and speed compared with MAR_Apriori. So the new algorithm has high speed and efficiency without processing missing values.
Some missing values were introduced into the Mushroom dataset at random for several times, and the percentages of the missing values in the dataset were not the same each time. The second and third experiments were executed on such datasets. The second experiment compared the testing accuracy for both algorithms in the first experiment with mine rules when the percentages of missing values changed. The results are shown in Fig.1.

Fig.1 Comparison of testing accuracy for two algorithms
From Fig.1, it can be seen that the testing accuracy of MAR_Apriori is always smaller than that of the new algorithm MARDA_IIS, and declines quickly. This demonstrates that completing the missing values maybe introduce noisy so as to extract invalid rules in MAR_Apriori, and the more the missing values, the lower the accuracy. But the accuracy of the new algorithm is less affected by missing values.
The third experiment compared the execution time for both algorithms with mine rules when the percentage of missing values changed. The results are shown in Fig.2.

Fig.2 Comparison of execution time of two algorithms
It can be seen from Fig.2 that the execution time of MAR_Apriori is always more than of the new algorithm MARDA_IIS. This indicates that the process of firstly completing the missing values and then mining rules in MAR_Apriori has higher time complexity than mining rules directly without processing missing values in MARDA_IIS. And the more the missing values are, the more the execution time in MAR_Apriori is.
6 Conclusions
1) The new algorithm does not change the structure of incomplete information system and keeps the original information true.
2) Equivalence relation, upper and lower approximation, and boundary are defined based on item sets in the new algorithm.
3) Some concepts of association rules such as support and confidence are redefined in incomplete information system. The prediction support and confidence of rules are proposed. Useful association rules in IIS can be effectively discovered based on the prediction values.
4) Users can decide to use the possible values or prediction values of support and confidence according to the real situation, so as to improve the flexibility of the association rules and make better use of knowledge.
References
[1] QUINLAN J R. Unknown attributes values in induction [C]// Proceedings of the 6th Int Workshop on Machine Learning. New York: IEEE Press, 1989: 164-168.
[2] ZHANG Qing-hua, WANG Guo-yin, HU Jun, LIU Xian-quan. Incomplete information systems processing based on fuzzy-clustering [C]// Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligent Agent Technology. New York: IEEE Press, 2006: 486-489.
[3] ZHANG Li-zhong. A data packing method of statistic judge based on rough sets in incomplete information system [J]. Computer Applications, 2007, 27(6): 1385-1387. (in Chinese)
[4] ZHANG Hong-zhen, CHU Dian-hui, ZHEN De-chen. Rule induction for incomplete information system [C]// Proceedings of the 4th International Conference on Machine Learning and Cybernetics. New York: IEEE Press, 2005: 1864-1867.
[5] WILLIAMS D, LIAO Xue-jun, XUE Ya. On classification with incomplete data [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(3): 427-436.
[6] QU Bin-bin, LU Yan-sheng. Rule induction algorithm based on rough sets for incomplete information system [J]. Mini-Micro Systems, 2006, 27(4): 698-700. (in Chinese)
[7] XING Hua-ling, LIU Si-wei, GAO She-sheng, TANG Shi-jie. Research of data mining method for incomplete information system [J]. Application Research of Computers, 2008, 25(1): 90-92. (in Chinese)
[8] AGRAWAL R, IMIELINSKI T, SWAMI A. Mining association rules between sets of items in large databases [C]// Proceedings of the 1993 ACM SIGMOD Conference on Management of Data. Washington D C, 1993: 207-216.
[9] KRYSZKIEWICZ M. Probabilistic approach to association rules in incomplete databases [C]// Proceedings of 1st International Conference on Web-Age Information Management. London: Springer-Verlag, 2000: 133-138.
[10] CHEN Xiao-hong, LAI Bang-chuan, LUO Ding. Mining association rule efficiently based on data warehouse [J]. Journal of Central South University of Technology, 2003, 10(4): 375-380.
[11] GUAN J W, BELL D A, LIU D Y. The rough set approach to association rule mining [C]// Proceedings of the 3rd IEEE International Conference on Data Mining. New York: IEEE Press, 2003.
[12] TONG Zhou, LUO Ke. Mining of association rules with decision attributes based on rough set [J]. Computer Engineering and Applications, 2006, 42(25): 166-169. (in Chinese)
[13] SUN Guo-zi, YU Ding-wen, WU Zhi-jun. Research on global product structure model based on rough set [J]. Chinese Journal of Computers, 2005, 28(3): 392-401. (in Chinese)
[14] HAN J, KAMBER M. Data mining: Concepts and techniques [M]. San Francisco: Morgan Kaufmann Publishers, 2001.
[15] ZHANG Wen-xiu, WU Wei-zhi, LIANG Ji-ye, LI De-yu. Rough set theory and method [M]. Beijing: Science Press, 2001. (in Chinese)
[16] PAWLAK Z. Rough sets: Theoretical aspects of reasoning about data [M]. Boston: Kluwer Academic Press, 1991.
(Edited by CHEN Wei-ping)
Foundation item: Projects(10871031, 60474070) supported by the National Natural Science Foundation of China; Project(07A001) supported by the Scientific Research Fund of Hunan Provincial Education Department, China
Received date: 2008-02-26; Accepted date: 2008-04-15
Corresponding author: LUO Ke, Professor, PhD; Tel: +86-731-2309788; E-mail: luok@csust.edu.cn
