
����С���˷����ĵ����㷨��ʵ�ּ���
Ԭ����������
(�������ӿƼ���ѧ ����ѧԺ���������뵼����������������ص�ʵ���ң����� ������710071)
ժ Ҫ��
������еĶ���С���˷��������һ�ּ��ܹ��Ż����ڲ��ӷ������������Ż������ӷ����λ���ĵ����㷨���������㷨��ʵ�ּ����ϣ����Ŀǰ����������㷨��������Ԫ���뱻�Ż�ϵͳ�Ӷ�����ϵͳ�Ż�Ч�������⡣�ڽ��ܸ��㷨�����ۻ�����ʵ��ϸ�ں�Ϊ��ȡ�ø��ӿۡ�������ͳ�����Եĵ����Ż�Ч�����Ը��㷨��ij���д�����ͬ����С���˷�������Ƶģ������Ż����Ż���FPGA���Խ����ʾ��ռ���ʽ�����39.3%���Ĵ�������������45.0%���ڴ�ռ���ʽ�����36.9%�����㷨��һ�ָ�Ч�ĵ����㷨�����ҽ����һ���㷨ʵ�ּ�����ȱ���벻�㣬�������ڶԺ��д���С���˷������ϵͳ���е����Ż������������źŴ����������˲����ȡ�
�ؼ��ʣ�
����С���˷����ӷ���������λ����ȱʡ������Ԫ�������������
��ͼ����ţ�TN702��TN402 ���ױ�־�룺A ���±�ţ�1672-7207(2014)01-0132-10
Low power methodology and implementation for fixed-point decimal multiplier
YUAN Bo, LIU Hongxia
(Key Lab of Ministry of Education for Wide Band-Gap Semiconductor Devices, School of Microelectronics,
Xidian University, Xi��an 710071, China)
Abstract: A low power methodology for fixed-point decimal multiplier in IC design was presented to optimize the number and width of the adders that were inside of synthesized multiplier. In terms of methodology implementation, it resolved the problem of optimization logic joining into optimized system, which existed in present low power design. The theoretical basis and the design method were explained. In order to get more objective and statistical test result, the methodology and implementation were used to optimize a radio-frequency module. FPGA test results show that logic utilization is reduced by 39.3%, the total number of registers used is reduced by 45.0%, and the total block memory bits utilization is reduced by 36.9%. These results show that the proposed low-power design is an effective method, which has good performance on optimizing the system including large-scale decimal multipliers, such as DSP and digital filter.
Key words: fixed-point decimal multiplication; number of addition; width; omit; logic cell; power consumption; area
����VLSI(�����ģ���ɵ�·)��Ƽ����Ľ����������ܴ���оƬ�Ѿ���Ϊͨ�š����ӡ��ռ似��������ز����ٵ���ɲ��֡���ˣ����д���С���˷������ģ��Ҳ��Ƶ����Ӧ���ڸ���оƬ�͵�·�У����������˲����������źŴ������ȵȡ�����һ��˷����㣬�书�ĺ������Ҫ��Դ���ڲ��ӷ�����������������ܹ��ڱ��ֳ˷�����ȷ�ȵ�ǰ���¼������ڲ��ӷ������������������Ч���ó˷����Ĺ��ĺ����[1]�������ڶ���С���˷����㣬Ϊ�˱��ֽϸߵ����㾫�ȣ���ȻҪ�����ڲ��Ĵ�����ӷ��������ļĴ������ֽϿ���λ������ͬʱ�ᵼ��ϵͳ���ĺ�������֮������ͼ��С�ڲ����Ĵ���λ�������������˷����Ĺ��ĺ��������˷�����ľ�����ʧ�����ɱ���[2]���ֽε�������У���������ϣ��ͨ������ϵͳʱ��Ƶ�ʡ����������źŷ�ת�ȷ���������ϵͳ���ġ����н���ϵͳʱ��Ƶ�ʻ���Ч����ϵͳ���ģ���ϵͳ���ܺ���Ч��Ҳ����֮���ͣ������������źŷ�ת��Ȼ����Ӱ��ϵͳ���ܣ�����Ҫ��ϵͳ�����Ӷ�����Ƶ�·�����ʹ��ϵͳ�������Ĺ��ĺ�����������ĵ�������У�
(1) �ſ�ʱ�ӡ�����Ҫ���ô���������Ʒ���������������״̬�������෭תʱ��ͨ���ر�ʱ����ʱ�ӣ�ʹ���������־�̬��ͬʱ����Щʱ�����Ϊ�����źŵ������Ҳ�����ھ�̬������ʵ�ֽ����ĵ�����[3]���÷�����ȱ������Ҫ��ʱ����ʱ������˼����������ʹ���ܹ��ڲ�����������״̬ʱ�ر�����ʱ�ӣ����ڽ��Ͳ������ĵ�ͬʱ��������������Ķ���Ĺ��ģ�Ӱ�첿�������Ż�Ч����
(2) ���������롣���Ż�������ϵͳ�е�������������ģ�飬��Ҫ��������ϵͳ��������״̬�£����������������������ʱ��ʹģ����������뱣�֡�0������ֹ����������ϵͳ���������źŷ�ת���÷���ʹϵͳ���������־�ֹ������ϵͳ��Ҫ��������ʱ����ģ����������뻹ԭʹ����������[4]���÷�����ȱ������Ҫ������ģ�����������ӿ�������ʹ���ܹ��ڴ�������״̬���������źŸ���0������ͬʱ�����˿����������Ķ���Ĺ��ģ�Ӱ��ģ������Ż�Ч����
(3) �洢���ֿ���ʡ���Ҫ�����ǽ�ϵͳ�д洢���������ڲ�����ģ�������������зֿ飬Ȼ���ø�λ��ַ�߽���Ƭѡ����[5]������ijϵͳ���䵽1��128 kB��RAM�����ڲ�2����ģ�������Ҫ1��64 kB��RAM����ʱ����ѡ��2��64 kB��RAM��17λ�ĵ�ַ�ߡ����е�16λ��ַ��ֱ���ṩ��2��RAM�����λ��ַ�߽ӵ�����RAM��Ƭѡ��CS��ͨ�����ַ��������ܴ�CPU ������ʲô���ĵ�ַ����ÿ��ֻ��ѡ��1��64 kB��RAM�������õ���128 kB��RAM����ÿ�ζ�Ҫѡ��1��128 kB��RAM��������֪��1��64 kB RAM�Ĺ���ҪԶС��1��128 kB RAM�Ĺ��ġ��÷�����ȱ������Ҫ����ַ���ߵ�λ������ͬʱ����Ƭѡ����ʹϵͳ�ڽ�����ͬʱ����������������Ƭѡ�������Ķ���Ĺ��ģ�Ӱ��ϵͳ�ĵ����Ż�Ч����
���ĵ�Ŀ�������������Ӧ�ñ����Լ����е�����ƵIJ��㣬���һ����Զ���С���˷�����ĵ�������㷨��ʵ�ּ��������ŵ����ڣ�
(1) ���ڸ��㷨���Ż��˷����ڲ��ӷ��ṹ���֣�û�������κε�ȱʡ��������˲���ʧ�˷����㾫�ȣ�����ֻ�Ǽ����˳˷����ۺϺ�ת��Ϊ�ӷ���������������Ҫ����ϵͳ����ʱ��Ƶ�ʺ�����ѹ�����ή��ϵͳ����Ч�ʡ�
(2) ���ڸ��㷨�����ڸ����ӷ�����У�Ԥ�ȼ������Ҫ�����ճ˷�����б�ȱʡ�ġ���С����λ������˿���ֱ���ڱ����ӷ������ȱʡ����С�����ӷ������λ�������ڲ����ͳ˷������ٶ������㾫�ȵĻ����Ͻ��ͳ˷����Ĺ��ĺ������
(3) ���������������ֻ�������˷���ϵ���С�1�������к�λ�ò����Լ��㣬��˾��������ٶȿ죬ռ����Դ�٣������е��ŵ㡣
(4) ���ڸ��㷨������һ��ȫ�µ�ʵ�ּ�����ʹ���ۺϺ�ֻ���Ż������������ϵͳ�ż���·�����Ż��㷨����������Ԫ�������뵽ϵͳ�С����ں��д��ģ�˷������ϵͳ���������ڲ����˷��������Ż��������Ĺ��ĺ�����ۼ��뱻�Ż�ϵͳ���Ӷ������Ż�Ч����
1 ���ڶ��������С���˷�����
�ڶ��������ֵ�·����У����ݿ���n���ܱ���������������һ��Ϊ��1����С����ʾΪ��ռ�á���һ��1���ı�������ˣ�nλ��С��B���Ա�����������Ϊ��������X [6]��
 (1)
(1)
����16λС��0.141677856����ʽ(1)����������Ϊ0.141677856/(216-1)=9285(10010001000101b)������65536(1111,1111,1111,1111b)����һ��Ϊ��1���������ݲ����ĽǶ��������൱�ڽ�0.141677856����16λ������С���˷�����Ϳ�����ʱת��Ϊ�����˷����㣬���˷������Ҫ����16λת����С�������ܵõ����յ�С���˷���������
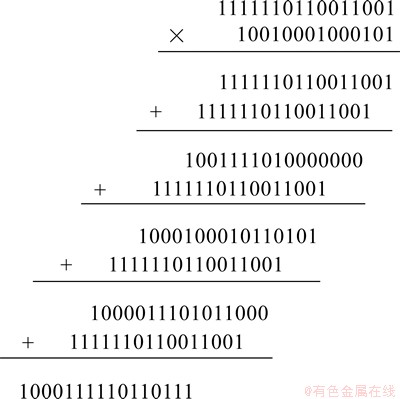
��16λС���˷�64921��0.141677856Ϊ������ʽ(1)����������Ϊ64921��9285����˷���ʽ��ͼ1��ʾ�������˷�������Ϊ100011111011011101111000111101b��Ȼ������16λ�õ�С���˷�������10001111101101.1101111000111101b������16λ��λ������Ϊ10001111101101.11b��
С���˷����ڲ��Ĵ�����λ�������������ľ������������Ĵ���λ���������Ǽ�����������ͨ·��������ʧ[7]������������ݵ�λ����Bin����������ݵ����λ��ΪBmax=Nlog2RM+Bin-1����������ֵ[8]�����У�NΪ�ڲ��ӷ����������RMΪС���˷������㾫�ȡ����Կ���Bmax�ᵼ�ºܴ��λ������ʱ����Ҫ��С���˷����ڲ������ӷ�������ضϺͽ��ƴ���[9]����������������Դ����������ģ����ҷ��Ӿ��ȷֲ�����������i���ӷ�����Ľض����ΪEi=2Bi������Bi�������ĵ�λ�������ľ�ֵ�ͷ���ֱ�Ϊui=0.5Ei�� [10]���������ݵ�λ�������½�����ȷ�ȵ���Ҫ������Ҫ��ǰ2Nλ������ܺ�С�ڻ��ߵ�������2N+1�����Դ���������������ʽΪ
[10]���������ݵ�λ�������½�����ȷ�ȵ���Ҫ������Ҫ��ǰ2Nλ������ܺ�С�ڻ��ߵ�������2N+1�����Դ���������������ʽΪ
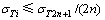 ��i=1, 2, ��, 2n (2)
��i=1, 2, ��, 2n (2)
������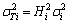 ��
��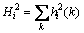 ��
��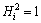 ����
����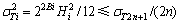 ���ɴ˿ɵ���ÿһ����������λ������ʽΪ
���ɴ˿ɵ���ÿһ����������λ������ʽΪ
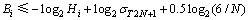 (3)
(3)
ʽ�У�BiΪ�������Ҷ˱���ʽ����ֵ�������������ʽ(3)���Ҷ˵�2���֪��Ҫ����ijһ������λ��������Ҫ���������ȥ��λ������������һ�����λ��ΪBout����2N+1����������λ��Ϊ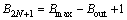 ��
��
��ͼ1�ɼ����ó˷�����ת��Ϊ4�μӷ����㣬�Ҹ����ӷ���������λ���ֱ�Ϊ19��23��27��30�����������ӷ������������16λ�����������д���16λ�����ݵ�λ����˷���������Ϊ1000111110110111b����ͼ2��ʾ����ͼ1��ʾ��ԭ�����ȴ����൱�����

ͼ1 64921��9285�ij˷���ʽ
Fig. 1 Formula of 64921��9285
ͼ2 ����16λ���ݿ��ȵij˷���ʽ
Fig. 2 Formula of maintain 16-bit data width in each adder
��С���˷������У��м�����ӷ����������ĩλ������¼��ӷ����㣬���Ϊ�˱�����������ȷ�ԣ���Ҫ���������м�����ӷ������ֻ������ĩ���ӷ�����н���ȱʡ������С���˷�λ��Ҫ�������ֽϴ������ۻ�[11]�������ڸ����ӷ������Ԥ�ȼ����������ĩ���ӷ�����б�ȱʡ��������ĩλ�������ڸ����ӷ��������ǰȱʡ���������Ч���ٸ����ӷ����λ����ͬʱ��֤������������ȷ�ԡ�
2 ���ݿ��ȵ��Ż�
�����˷�����A��B�ļ��������ʽ(4)��ʾ[12]�����б������ͳ����ֱ�ΪA��B��B�Զ����Ʊ�ʾΪb3b2b1b0��
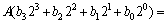
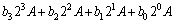 (4)
(4)
���ϵ��b0��ʽ(4)��ת��Ϊ
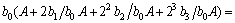
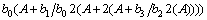 (5)
(5)
��ʽ(5)�ɵã���b0Ϊ��0������bi2iA��ҲΪ��0������˶���ÿһ����ĸ��Ϊ��1���������������Ϊ��0�����ɴ˿ɵö���ʽ��
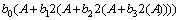 (6)
(6)
��ȼ۶���ʽΪ��
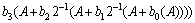 (7)
(7)
��ʽ(7)���Կ����������ӷ������ĩλ�������¼��ӷ����㣬��Ȼ��Ϊ�¼��ӷ������ĩλ���ڡ�����ܹ�ȱʡ�����ӷ��������ĩiλ(i�����¼��ӷ���������һ������������λ��)������Լ����¼��ӷ������λ������ȱʡ����Ҳֻ�ǡ���С����λ��(The last-significant-bits)����Щ����С����λ��Ҳ���������������б�ȱʡ����
��ͼ1�˷���ʽ��ʽ(7)�����Ż���ȱʡ�����ӷ�����ġ���С����λ����ij˷���ʽ��ͼ3��ʾ��ĩ���ӷ����Ϊ10001111101101110b���������Ż������й�ȱʡ λ����ˣ���������Ͻ������3λ���ɵó�С���˷������������16λ���ݿ���Ϊ10001111101101.11b�����Ż�ǰ��ȫһ�¡���ע��Ż�������ӷ����λ���ֱ��Ϊ17��17��17��17����Ƚ��Ż�ǰ��λ��19��23��27��30�����Լ�����ڳ˷�����64921��9285�ڲ�����ʡ�Ĵ���λ��
λ����ˣ���������Ͻ������3λ���ɵó�С���˷������������16λ���ݿ���Ϊ10001111101101.11b�����Ż�ǰ��ȫһ�¡���ע��Ż�������ӷ����λ���ֱ��Ϊ17��17��17��17����Ƚ��Ż�ǰ��λ��19��23��27��30�����Լ�����ڳ˷�����64921��9285�ڲ�����ʡ�Ĵ���λ��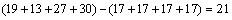 λ��ͬʱ�Ż�û�д���������û�н��ͳ˷�����ȷ�ȡ�
λ��ͬʱ�Ż�û�д���������û�н��ͳ˷�����ȷ�ȡ�
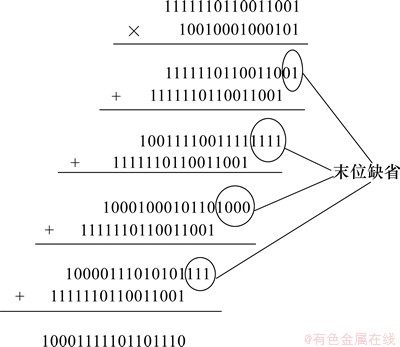
ͼ3 ȱʡ�Ż�����
Fig. 3 Omit operation process
3 �˷�ϵ�����Ż�
���ڶ����Ƴ˷����㣬�ձ������λ���㷨����ÿһ�����ֻ������ɱ�����������и�λ��˲�����Ȼ���ռӷ�����������ֻ����[13]����8λ�����Ƴ˷�����111011b��1110111bΪ������˷���ʽ��ͼ4��ʾ����˷��ṹ��ͼ��ͼ5��ʾ������xΪ��������

ͼ4 111011b��1110111b�ij˷���ʽ
Fig. 4 Formula of 111011b��1110111b
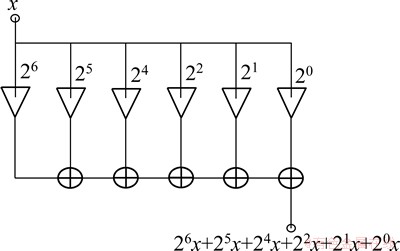
ͼ5 �˷����ڲ��ṹ��ͼ(ϵ��Ϊ1110111b)
Fig. 5 Multiplier structure schematic (the coefficient is 1110111b)
�۲췢�ֳ˷������ڲ���λ������Ĵ���m������С�1���ĸ���n������أ���ͼ4�г˷�����ת��Ϊ5����λ�����㣬������1110111b����6����1�������ǵĹ�ϵ���� ���������ܹ��跨���ٳ����С�1���ĸ�������ͬһ�˷����������ļӷ��������ͻ���٣��ó˷����Ĺ��ĺ����Ҳ����֮����[14]��
���������ܹ��跨���ٳ����С�1���ĸ�������ͬһ�˷����������ļӷ��������ͻ���٣��ó˷����Ĺ��ĺ����Ҳ����֮����[14]��
���������������X��������������1��ȡ�����Ϊ ����ʽ(8)��ʾ[15]������
����ʽ(8)��ʾ[15]������ ��
�� �ֱ�Ϊ�����С�1�������λ�����λ����ʱ�ö��������в����������ġ�1������
�ֱ�Ϊ�����С�1�������λ�����λ����ʱ�ö��������в����������ġ�1������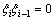 ��
��
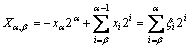 (8)
(8)
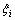 ��ʽ(9)�ó�������
��ʽ(9)�ó�������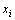 Ϊ�ö���������
Ϊ�ö���������
 (9)
(9)
���ʽ(8)��ʽ(9)�����Գ˷�ϵ���������ġ�1��ȡ���룬����ڸ�����ϵ������L��Mλ�IJ���Ϊ
 (10)
(10)
��LδԼ��ʱ��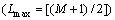 ��
��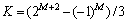 (���У�KΪ���볤��)��һ��Lmaxȷ����Kc��ʽ(11)�ó���
(���У�KΪ���볤��)��һ��Lmaxȷ����Kc��ʽ(11)�ó���
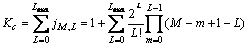 (11)
(11)
���磬��������1110111b�IJ�����������ͼ6��ʾ��
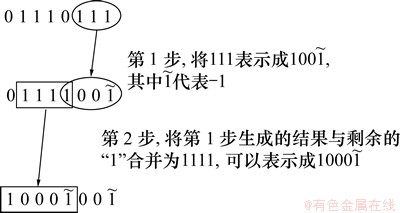
ͼ6 ��������1110111b�IJ���������
Fig. 6 Complement calculation process of binary 1110111
�����Ż���ϵ��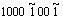 ���µij˷���ʽ��ͼ7��ʾ���µij˷��ṹ��ͼ��ͼ8��ʾ�����Ż�ǰ�ij˷�������ȣ����ǵó���ͬ��������1101101101101b������λ��������5�μ���Ϊ2�Ρ����Կ������Ż����ڼ��ٳ˷����мӷ��������Ч��������ͬʱ��Ӱ���������뾫�ȡ�
���µij˷���ʽ��ͼ7��ʾ���µij˷��ṹ��ͼ��ͼ8��ʾ�����Ż�ǰ�ij˷�������ȣ����ǵó���ͬ��������1101101101101b������λ��������5�μ���Ϊ2�Ρ����Կ������Ż����ڼ��ٳ˷����мӷ��������Ч��������ͬʱ��Ӱ���������뾫�ȡ�
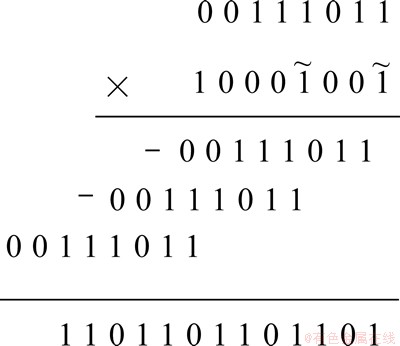
ͼ7 �Ż���Ķ����Ƴ˷���ʽ
Fig. 7 Optimized binary multiplication formula
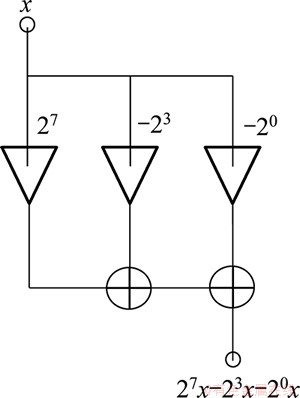
ͼ8 �Ż���ij˷����ڲ��ṹ��ͼ
Fig. 8 Structure schematic of optimized multiplier
4 �Ż��㷨��ʵ�ּ���
����ֽε�������д��ڵ����⣬���Ż����ϵͳ����������һ���ֵ����㷨�����Ĺ��ĺ���������ǻ��ۼ����Ż����ϵͳ�Ӷ�����ϵͳ�����Ż�Ч����Ϊ�˽�������⣬���Ŀ�����һ���µ��㷨ʵ�ּ����������Ա����Ż��㷨��������Ԫ�����Ż���ij˷�������һ�����������Ч����
����С���˷������Ƚ�ϵ����ʽ(1)����������������ϵ��X�����λ���λ�������ꡰ1�����¼��λ�úͷ��ţ��ֱ��Ա���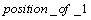 ��
��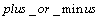 ��ʾ����x(i)=1
��ʾ����x(i)=1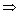 position_of_1(i)=1��
position_of_1(i)=1��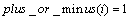 ��ͬʱ��1����������1���Ա���
��ͬʱ��1����������1���Ա���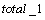 ��ʾ����
��ʾ����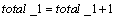 ���ꡰ0�����ж�֮ǰ��û�������ġ�1�����ڣ����У�����Щ������1������ǰ�������㷨����ת����Ȼ��������3��������
���ꡰ0�����ж�֮ǰ��û�������ġ�1�����ڣ����У�����Щ������1������ǰ�������㷨����ת����Ȼ��������3��������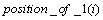 ��
��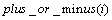 �������ޣ���������λ�������������㷨������X���λ������ϵ��X���Ż������������㷨�Գ˷���ϵ��1110111b(��ͼ6��ʾ)�����Ż���ķ��沨����ͼ9��ʾ�����湤��ΪMentor Graphic��˾��modelsim���Ż����Ϊ��total_1=3, position_of_1=730, plus_or_minus=100�����Ż����ϵ�����ܹ���3����1�������ǵ�λ�÷ֱ��ڵ�0λ����3λ����7λ�����ǵķ��ŷֱ�Ϊ������������������ǰ�������������һ�¡�
�������ޣ���������λ�������������㷨������X���λ������ϵ��X���Ż������������㷨�Գ˷���ϵ��1110111b(��ͼ6��ʾ)�����Ż���ķ��沨����ͼ9��ʾ�����湤��ΪMentor Graphic��˾��modelsim���Ż����Ϊ��total_1=3, position_of_1=730, plus_or_minus=100�����Ż����ϵ�����ܹ���3����1�������ǵ�λ�÷ֱ��ڵ�0λ����3λ����7λ�����ǵķ��ŷֱ�Ϊ������������������ǰ�������������һ�¡�

ͼ9 1110111b���Ż����沨��
Fig. 9 Simulation waveform of optimized 1110111b
�������������������Ż��㷨ʵ��Ϊһ������find_multi_factor_f(x)������������뱻�Ż�������롣�Ż�ʱֻ����øú���������������xΪ�˷�����С��ϵ�������Ϊ�Ż����ϵ������3��������ʾ��
Constant mum_to_add_c:integer:=find_multi_factor_f(x). otal_1;
Constant shift_bits_c:nature_array:=find_multi_factor_ f(x).position_of_1
Constant add_sign_c:std+ulogic_vector:=find_multi_ factor_f(x).plus_or_minus
�����Ż�����Գ�����ʾ��ԭ�����ڣ�
(1) �ڳ˷����ۺϳ��ڣ�����3������������Ż�����find_multi_factor_f(x)����ó����ۺϺ˷�������������Щ�������ת��Ϊ��Ӧ����λ�ӽṹ�������е��Ż��㷨����Ԫ��������˷�����
(2) �Ż�����еij���shift_bits_c (�Ż���ϵ���и���1����λ��)ǡ�ÿ���Ϊ��һ������Ը����ӷ����λ�����Ż��㷨�����ã�ʡ�������������̣��ӿ�����ٶȡ�
����Ż��˷���ģ��mtplr_mutiplication������������Ϊmulti_find_g������˿�Ϊ��x_i��n������˿�Ϊz_o������С���˷���ϵ����ģ����������multi_find_g���룬��������x_i���룬���ݿ�����n���룬���ճ˷���������z_o�����ͼ10��ʾΪ���Ż��˷���ģ���ʵ�塣
��ģ���ڲ��������Ż�����find_multi_factor_f(x)����ʹС���˷���ϵ��ͨ����������multi_find_g�����Ż�������������Ϊ3��������num_to_add_c��shift_bits_c��add_sign_c�����뱻����������λ�ӷ����㡣
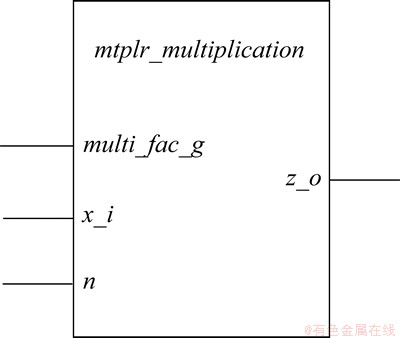
ͼ10 mtplr_mutiplication��ʵ��
Fig. 10 Entity of mtplr_mutiplication
�����Ż���ϵ���С�1����λ���Ѿ��ڳ�������shift_bits_c�б��棬�ֱ��Ϊn1, n2, ��, nk����ˣ��ۺϺ��һ���ӷ������ɱ�����A����n1λ��A����n2λ���ɣ���ȱʡ�ӷ��������ĩn2λ����Ĵ�����Ϊ��һ���м���A1����i���ӷ�������A����niλ��ǰһ���м���Ai-1���ɣ���ȱʡ�ӷ��������ĩniλ����Ĵ�����Ϊ��i���м���Ai���������ƣ�ֱ��������k-1���ӷ������Ż��㷨��ͼ��ͼ11��ʾ��
�����Ҫ����ĩ���ӷ��������С�������������ڿ�ʼ�ȶ�nλС���˷���A��B��С��ϵ��B�������������������൱�ڽ�B����nλ�������ĩ���ӷ������Ҫ����nλת����С����õ����ճ˷������Ȼ���ڡ�ȱʡ�����������ȱʡλΪnk�������Ż��������Ѿ�������nkλ���������һ���ӷ����Ľ��ֻ������n-nkλ����z_o�����
�Ժ��д���С���˷�����ϵͳ�����Ż�ʱ�����Ż��˷���ģ��mtplr_mutiplication���ڿ�����ϵͳ��Ʒ��룬��ϵͳ��ʵ������ģ�鲢�滻��ԭ�и���ϵ���˷������滻ʱ����ʵ����ģ������������趨Ϊ����Ӧ�˷���ϵ����
ϵͳ��ƵIJ���������һ��ȷ�������ڲ����˷���ϵ��Ҳ��ȷ������FIR�˲���Ϊ����һ��������ͨ����������ֹƵ�ʵȲ���ȷ�������ڲ����˷�����ϵ��Ҳ��ȷ�����˷���ϵ��������������������Գ��������ԭ���ǣ�����ֻ�ܴ����ʵ����ڲ��õ���ֵ�Ҳ����ٸı䣬��������ֵ���������ʵ���ⲿ�ṩ���������߿��Դ�����ͨ�����������������趨�����ظı��ģ����ڲ���·�ṹ�������滻ʱֻ�轫���˷�ϵ��ͨ��������������ģ����ʵ�ֲ�ͬ���Ż��˷�����ͼ12��ʾΪ�滻16λС���˷�y=0.141677856x���Ż��˷������Ż��˷���ģ�顣ǰ�������ٵ�16λ����С���˷�����64921��0.141677856���Ż����沨����ͼ13��ʾ�����г˷�ϵ��multi_find_gΪ0.141677856��������x_iΪ 64921��λ��nΪ16���˷����ڲ�4���ӷ�������A1��A2��A3��A4�ֱ�Ϊ10011110011111111b��10001000101101000b��10000111010101111b��10001111101101110b������16λ������z_oΪ9197.75����10001111101101.11b����ͼ3�е�����������һ�¡�
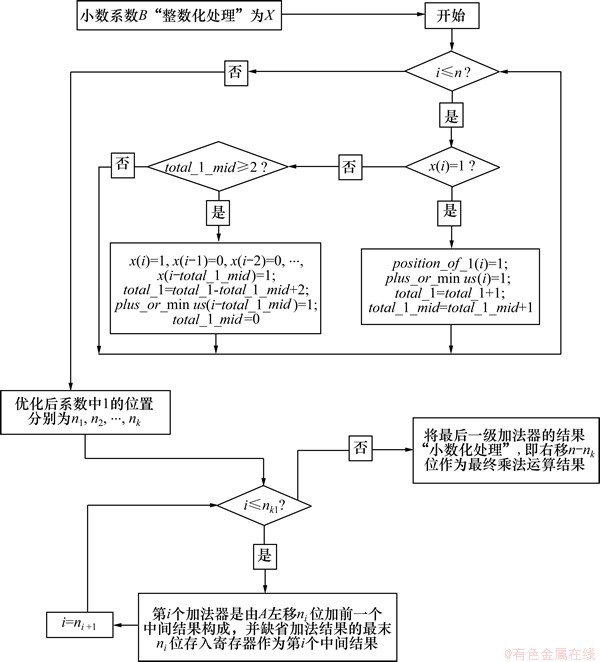
ͼ11 С���˷����Ż�����㷨��ͼ
Fig.11 Optimization methodology schematic of decimal multiplier

ͼ12 �滻16λС���˷�y=0.141677856x���Ż��˷���ģ��
Fig. 12 Optimized multiplication module that is instead of 16-bit decimal multiplier y=0.141677856x
���ۺϳ��ڣ��˷�����ϵ��ͨ��ģ����������multi_find_g�����Ż������У��õ���3��������ʾ���Ż�ϵ�����ۺ�ʱ������Щ�������˷����Ϳ���ת��Ϊ��Ӧ����λ�ӷ�����ͬʱ���ݼ�¼�Ż���ϵ���С�1��λ�õij���shift_bits_c����Ը����ӷ����ȱʡ���Լ��㾫�����κι�������ĩλ���Ӷ����ٸ����ӷ����λ������ʱ���е��Ż�����Ԫ�����������ϵͳ�ۺϺ���ż���·�У���ģ���ڲ�ֻ����ȱʡ������δ���Ӷ���������㡣
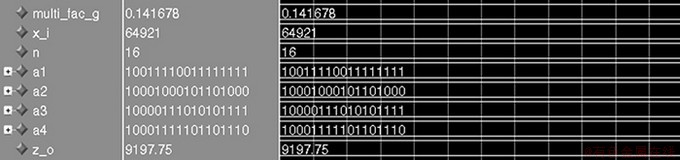
ͼ13 С���˷�64921��0.141677856���Ż����沨��
Fig.13 Simulation waveform of optimized decimal multiplication 64921��0.141677856
5 �Ż�Ч����֤
Ϊ�˲����Ż�Ч������ij���д��������˲����������źŴ�������Ƶģ����Ϊ���Զ���������Ż�������Ƶģ��߱������źŵ��Ƽ����书�ܣ����ڲ�������״�˲�����WDF�˲����Ȳ�ͬ���͵������˲������Լ��źŴ������Ⱥ��д���С���˷��������ģ�顣
�Ż�����IJ��Թ���ΪSequence Design��˾�� Power Theater����Ϊ�����ļ��㹤�ߣ������Զ�ϵͳ��ǰ��RTL��������ȷ�Ĺ��ĺ�������ֱ��øù��߶��Ż�ǰ����Ƶģ�飬�����������Ż��㷨ƥ��һ��ʵ�ּ����Ż�������Ƶģ�飬�Լ����������Ż��㷨ƥ�䱾������ʵ�ּ����Ż�������Ƶģ��ֱ���в��ԣ�3�β����ж���Ƶģ��Ĺ�����ѹ������ʱ��Ƶ�ʵ������������������һ�¡���1��¼��3�β������õĹ��IJ��Խ������2��¼��3��ʵ�����õ����������Ԫ�������Կ������Ż�ǰģ��Ĺ���Ϊ10.7 mW������Ԫ��Ϊ95 962�����Ϊ1.479 mm2�������������Ż��㷨ƥ��һ��ʵ�ּ����Ż������ϲ����ֱ�Ϊ6.903 mW��70 220��1.147 mm2���ֱ�35.51%��7.06%��22.45%���Ż����֤�����������㷨���нϺõĵ���Ч������ȫ���ձ������������㷨�Ż������ϲ����ֱ�Ϊ6.31 mW��67 888��1.119 mm2���ֱ��ٴν���8.55%��3.32%��2.44%��˵����������ʵ�ּ���ȷʵ��������ϵͳ�������Ч���������Ŀǰ������������ڵ����⡣
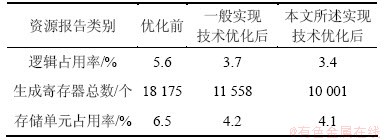
Ϊ�˽�һ�����Ա������������㷨��Ӳ���Ż�Ч�����ֱ���Ż�ǰ����Ƶģ��;�һ������㷨�Ż������Ƶģ���Լ��������������㷨�Ż�������Ƶģ�����FPGA���ԡ����Բ���Stratix ������EP4SE820F43C3�ͺ�FPGA��Ϊ����ƽ̨�����Ҳ���Quartus����ΪFPGA�ı��롢�ۺϹ��ߣ��ù���������ATERA��˾��������Ϊҵ���ձ��Ͽɵ�һ��FPGA�������ߡ��Ż�ǰģ����һ��ʵ�ּ����Լ���������ʵ�ּ����Ż����ģ�龭Quartus����롢�ۺϺ������������Դ����Ա����3��ʾ���ɱ�3�ɼ����ñ���ȷ��¼��3�β����в��Զ�����ڸ��ͺ�FPGA����Դռ����������Կ����Ż�ǰ��Ƶģ��Ը�FPGA����ռ����Ϊ5.6%�����ɼĴ�������Ϊ18 175���洢��Ԫռ����Ϊ6.5%�������������Ż��㷨ƥ��һ��ʵ�ּ����Ż�������Ƶģ��Ը�FPGA����ռ����Ϊ3.7%�����ɼĴ�������Ϊ11 558���洢��Ԫռ����Ϊ4.2%���ֱ�33.93%��36.41%��35.38%�������������Ż��㷨ƥ�䱾������ʵ�ּ����Ż�����Ƶģ��Ը�FPGA����ռ����Ϊ3.4%�����ɼĴ�������Ϊ10 001���洢��Ԫռ����Ϊ4.1%���ֱ��ٴν���8.11%��13.47%��2.38%��FPGA���Խ���Ա����ԣ�������Power Theater��ȡ�õĹ��ķ���������Ǻϡ��������ھ�һ��ʵ�ּ����Ż�����Ȼ���˷����Ľṹ��λ�������Ż������Ż��㷨����ԪͬʱҲ�����뵽���˷����У�������һЩ����Ԫ����������������һ���������Ż�Ч����������������ʵ�ּ����Ż��˷����Ľṹ��λ��ͬ���õ��Ż������ұ������Ż��㷨����Ԫ���뵽���˷����У����������Ż�����������ĸ����á�����2��ʵ�ּ������ò��Խ�����ܴ����Ҫԭ��
��1 3��ʵ�����õ���Ƶģ������
Table 1 Power analysis record of RF module in 3 experiments mW
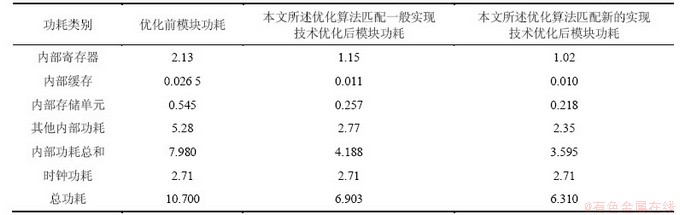
��2��3��ʵ�����õ���Ƶģ������Ԫ�������
Table 2 Logic cell number and area of RF module in 3 experiments

��3 FPGA���Խ���Ա�
Table 3 FPGA test result comparison
6 ���ۺϹ����Զ��Ż�����ĶԱ�
��Ӳ�����������е��ۺϽΣ�һЩ�ۺϹ������Դ���IP���ܹ���ijЩ����Ա��ۺ϶��������Ӧ���Զ��Ż���������������ĵȡ�Ϊ�˶Աȱ������������㷨���ۺϹ����Զ��Ż����ܵ�Ч������Synopsys��˾��DC(Design Compiler)��δ���Ż���ԭʼ��Ƶģ������ۺϣ�DC��Ϊҵ�ڹ㷺�Ͽɵ����ۺϹ��ߣ������Ը������������Լ�������Զ��ۺϳ��Ż�����ż���·�����Ӳ��������ܡ�
������DC��Լ���ļ�synopsys_dc.setup�����������С����������Ҫָ�����ǣ�DC�е�Լ���ļ��п�������ijһ������������ı�������������ܣ�������ֱ�ӵľ����������ʱ��Ȩ�⣬���Ϊ��ʹ�ۺϺ���Ƶģ�������빦���ܹ��ﵽ��С��synopsys_dc.setup��û�ж���ʱ�����κ�Լ������ζ���ڴ�Լ����������Ƶģ�������빦����С�����ؼ�·������ʱ�����൱����������Ŀ������DC�ܹ��ﵽ����С�����������뱾�������㷨��ʵ�ּ�����ȡ�õĽ�����жԱȡ�
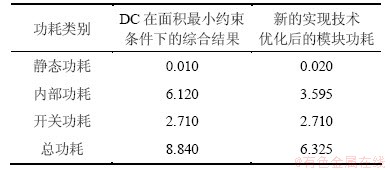
�ۺ���ɺõ��ĸ���Ľ�����4��ʾ�����������5��ʾ��Ϊ�˱��ڶԱȣ�����1�ͱ�2�б��������Ż������Ż���IJ��Խ�����롣���Կ�����ͬһ��Ƶģ�龭DC�������С��Լ���������ۺϺ�ģ����ܹ��Ľ�Ϊ8.84 mW�������Ϊ1.357 mm2���������������Ż������Ż������ϲ����ֱ�Ϊ6.325 mW��1.119 mm2���ɴ˿��Եó����������Ż�������ȡ�õĵ���Ч�������ۺϹ���DC�ܹ��ﵽ�����Ž����
��4 ��Ƶģ��ĸ���ĶԱ�
Table 4 Power consumption comparison of RF module mW
��5����Ƶģ���ۺϺ������Ա�
Table 5 Area comparison of RF module mm2

7 ����
(1) ����Ƶģ��Ĺ��ķ�����FPGA���Խ������������������ĵ����㷨�Ժ��д���С���˷������ϵͳ���Ż�Ч��ʮ��������
(2) ���㷨��ʵ�ּ����ϣ������Ŀǰ����������㷨����������Ԫ������ϵͳ�Ӷ�����ϵͳ�Ż�Ч�������⣬�������ֽ�һ��ʵ�ּ�����Ƚϣ����ķ�����FPGA���Խ����������������ʵ�ּ������Ż�Ч�������ֽ�һ��ʵ�ּ����Ľ����
(3) ��ҵ�ڹ㷺�Ͽɵ����ۺϹ���DC�Զ��Ż��Ľ����ȣ���������ĵ��ļ������и��ŵĵ���Ч����
(4) Ŀǰ�Ըõ��ļ�����ijһͨ��оƬ�Ż���оƬ�ѻ���65 nm������ͶƬ��оƬ���Խ�����á�
�ο����ף�
[1] �˾�, ������. ȫ���ֽ��ջ���һ�ֵ��IJ�ֵ�˲����ṹ����VLSIʵ��[J]. �������ӿƼ���ѧѧ��,2010,37(2):320-325.
DENG Jun, YANG Yintang. The VLSI implementation of a low-power interpolation filter structure in all-digital receiver[J]. Journal of Xidian University, 2010, 37(2): 320-325.
[2] ����, ��ΰ��, ��ع��, ��. һ������UWB���ն˵Ĵ�ͨ�˲������������[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2012, 43(2): 554-560.
WANG Bin, WU Weiren, QU Yuxuan, et al. Analysis and design of a band-pass filter for UWB receiver[J]. Journal of Central South University (Science and Technology), 2012, 43(2): 554-560.
[3] ������, ��С��, ˮ����. һ�����DFT�����˲���������㷨[J]. �������ӿƼ���ѧѧ��,2010,37(4):689-693.
JIANG Junzheng, WANG Xiaolong, SHUI Penglang. A new algorithm of DFT modulated filter[J]. Journal of Xidian University, 2010, 37(4): 689-693.
[4] Kodi A K, Sarathy A, Louri A, et al. Adaptive inter-router links for low-power, area-efficient and reliable Network-on-Chip (NoC) architectures[C]// ASP2DAC 2009. Athens: Ohio Univ, 2009: 1-126.
[5] Kodi A K, Louri A, Wang J M. Design of energy-efficient channel buffers with router bypassing for network-on-chips (NoCs)[C]// 10th International Symposium on Quality of Electronic Design. San Jose, CA, USA, 2009: 826-832
[6] Wong A C W, Kathiresan G, Chan C K T, et al. A1V wireless transceiver for an ultra low power SoC for biotelemetry applications[C]// European Solid State Circuits Conf. Abingdon: Toumaz Technol Ltd, 2007: 127-130.
[7] Priest D M. Algorithms for arbitrary precision floating point arithmetic[C]// 10th IEEE Symposium on Computer Arithmetic. Los Alamitos, CA, USA. 1991: 132-144.
[8] �ް���, ������, �ں���. ���ֻ�������Ӧ��λ������FDOA�����㷨[J]. ���ݲɼ��봦��, 2012, 27(1): 538-545.
LUO Baiwen, WAN Kangming, YU Hongyi. Two kinds of estimation algorithm based on adaptive phase compensation FDOA[J]. Journal of Data Acquisition and Processing, 2012, 27(1): 538-545.
[9] Daniele L, Macro R. Binary canonic signed digit multiplier for high-speed digital signal processing[C]// The 47th IEEE International Midwest Symposium on Circuits and Systems. Hiroshima, Japan, 2004: 205-208.
[10] Hartley R I. Subexpression sharing in filters using canonic signed digit multipliers[C]// IEEE Transactions on Circuits and Systems ��. Analog and Digital Signal Processing. Schenectady, NY, 1996: 52-54.
[11] Graillat S, Langlois P, Louvet N. Compensated Horner scheme[R]. Perpignan, France: University of Perpignan, 2005: 10-26.
[12] Losada R A, Lyons R. Reducing CIC filter complexity[M]. Natick, MA, USA: IEEE Signal Processing Magazine MathWorks Inc., 2006: 124-126
[13] Meyer-Baese U. Digital signal processing with field programmable gate arrays[M]. New York: Springer Publishing Company, 2007: 539-790.
[14] Karlsson M. Implementation of digital serial filters[R]. Sweden: Link ping Studies in Science and Technology Dissertations, 2005: 925-1102.
ping Studies in Science and Technology Dissertations, 2005: 925-1102.
[15] Lyons R G. Understanding digital signal processing[M]. Upper Saddle River, New Jersey: Prentice Hall, 2004: 556-561.
(�༭ ����ƽ)
�ո����ڣ�2012-12-11�������ڣ�2013-03-06
������Ŀ��������Ȼ��ѧ����������Ŀ(60976068)���������Ƽ����¹����ش���Ŀ�����ʽ�������Ŀ(708083)����������ʿ�����������Ŀ(200807010010)
ͨ�����ߣ�Ԭ��(1982-)���У����������ˣ���ʿ�о��������´��ģ���ɵ�·����о����绰: 13991300901��E-mail: wison_yuan@hotmail.com
ժҪ����Լ��ɵ�·ǰ������еĶ���С���˷��������һ�ּ��ܹ��Ż����ڲ��ӷ������������Ż������ӷ����λ���ĵ����㷨���������㷨��ʵ�ּ����ϣ����Ŀǰ����������㷨��������Ԫ���뱻�Ż�ϵͳ�Ӷ�����ϵͳ�Ż�Ч�������⡣�ڽ��ܸ��㷨�����ۻ�����ʵ��ϸ�ں�Ϊ��ȡ�ø��ӿۡ�������ͳ�����Եĵ����Ż�Ч�����Ը��㷨��ij���д�����ͬ����С���˷�������Ƶģ������Ż����Ż���FPGA���Խ����ʾ��ռ���ʽ�����39.3%���Ĵ�������������45.0%���ڴ�ռ���ʽ�����36.9%�����㷨��һ�ָ�Ч�ĵ����㷨�����ҽ����һ���㷨ʵ�ּ�����ȱ���벻�㣬�������ڶԺ��д���С���˷������ϵͳ���е����Ż������������źŴ����������˲����ȡ�
