

J. Cent. South Univ. (2020) 27: 449-468
DOI: https://doi.org/10.1007/s11771-020-4308-z
CTCPPre: A prediction method for accepted pull requests in GitHub
JIANG Jing(����), ZHENG Jia-teng(֣����), YANG Yun(����), ZHANG Li(����)
State Key Laboratory of Software Development Environment, Beihang University, Beijing 100191, China
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2020
Abstract:
As the popularity of open source projects, the volume of incoming pull requests is too large, which puts heavy burden on integrators who are responsible for accepting or rejecting pull requests. An accepted pull request prediction approach can help integrators by allowing them either to enforce an immediate rejection of code changes or allocate more resources to overcome the deficiency. In this paper, an approach CTCPPre is proposed to predict the accepted pull requests in GitHub. CTCPPre mainly considers code features of modified changes, text features of pull requests�� description, contributor features of developers�� previous behaviors, and project features of development environment. The effectiveness of CTCPPre on 28 projects containing 221096 pull requests is evaluated. Experimental results show that CTCPPre has good performances by achieving accuracy of 0.82, AUC of 0.76 and F1-score of 0.88 on average. It is compared with the state of art accepted pull request prediction approach RFPredict. On average across 28 projects, CTCPPre outperforms RFPredict by 6.64%, 16.06% and 4.79% in terms of accuracy, AUC and F1-score, respectively.
Key words:
accepted pull request; prediction; code review; GitHub; pull-based software development��
Cite this article as:
JIANG Jing, ZHENG Jia-teng, YANG Yun, ZHANG Li. CTCPPre: A prediction method for accepted pull requests in GitHub [J]. Journal of Central South University, 2020, 27(2): 449-468.
DOI:https://dx.doi.org/https://doi.org/10.1007/s11771-020-4308-z1 Introduction
Various open source software hosting sites, notably Github, provide support for pull-based development and allow developers to make contributions flexibly and efficiently [1]. In GitHub, contributors fork a project��s main repository, and make their code changes independently of one another. When a set of changes is ready, contributors create and submit pull requests to main repository. Any developers can provide comments and exchange opinions about pull requests [2, 3]. Members of the project��s core team i.e., integrators are responsible for inspecting submitted code changes, identifying issues (e.g. vulnerabilities), and deciding whether to accept pull requests and merge these code changes into main repository [1].
As projects are popular, the volume of incoming pull requests is just too large, and puts heavy burden on integrators [1]. Some previous works [4-8] designed methods to help reviewers find appropriate code changes. Besides code change assignment, inspecting code changes also consumes integrators much time and effort because they need to inspect submitted code changes and identify potential issues. An accepted pull request prediction approach can help integrators by allowing them either to enforce an immediate rejection of code changes or allocate more resources to overcome the deficiency.
Integrators can reduce time wasted on the inspection of rejected code changes, and focus on more promising code changes which eventually contribute to open source software projects.
In this paper, an accepted pull request prediction approach CTCPPre is proposed, which builds an XGBoost classifier based on a training set of a project to predict whether pull requests will be accepted. Firstly, 17 features, which are grouped into 4 dimensions namely, code, text, contributor and project are extracted. Code features measure the characteristics of modified codes. In text dimension, features from natural language description of pull requests are extracted. In contributor dimension, features based on previous behaviors of contributors who submit pull requests are extracted. Project features mainly analyze recent development environment in projects. All these features can be automatically and immediately extracted when pull requests are submitted. Based on these 17 features, the extreme gradient boosting (XGBoost) classifier is leveraged to predict accepted pull requests. CTCPPre computes the acceptance probabilities and rejection probabilities of pull requests, respectively. If the acceptance probability is higher than rejection probability, the pull request is predicted as accepted; otherwise, the pull request is predicted as rejected. CTCPPre not only returns prediction results, but also provides acceptance probabilities and rejection probabilities of pull requests, which helps integrators to make decision.
The usage scenarios of our proposed approach are as follows:
1) Without approach. Bob is an integrator in a large open source project team, and his main responsibility is to review pull requests submitted by contributors. Without our approach, he browses pull request lists, and selects pull requests randomly. Then, he inspects code, detects bugs, and discusses with other developers. It wastes much of Bob��s time and effort if a code change he reviews is eventually abandoned, which leads to Bob having less time to evaluate other pull requests.
2) With approach. Bob��s project adopts our approach. Our approach predicts whether the submitted pull request will be accepted. Then, Bob reviews pull requests which are predicted to be accepted first. Bob spend less time on the evaluation of pull requests which are likely to be rejected, and focus on more promising pull requests which eventually contribute to open source software projects.
In order to demonstrate the effectiveness of our approach, 221096 pull requests of 28 large- scale projects on GitHub are analyzed. The experimental results show that on average across 28 projects, CTCPPre has good performances by achieving accuracy of 0.82, area under curve (AUC) of 0.76 and F1-score of 0.88. In comparison with the state-of-the-art approach RFPredict [9], CTCPPre improves accuracy, AUC and F1-score by 6.64%, 16.06% and 4.79%, respectively.
The main contributions of this paper are as follows:
1) An accepted pull request prediction approach CTCPPre is proposed, which leverages XGBoost classifier to analyze code features, text features, contributor features and project features.
2) CTCPPre is evaluated based on a broad range of datasets. Results show that CTCPPre obviously outperforms the state-of-the-art approach RFPredict.
The remainder of the paper is organized as follow. Background and data collection are described in Section 2. The accepted pull request prediction approach CTCPPre is present in Section 3. Section 4 presents an empirical evaluation of the approach. Threat to validity is discussed in Section 5, and Section 6 discusses related works. Finally, conclusions are shown in Section 7.
This paper is an extension of our previous work [10]. Compared with the previous work, our new contributions are summarized as follows:
1) The contributor dimension is added to extract features for the XGBoost classifier, which makes previous behaviors of contributors into consideration.
2) Our approach is evaluated using quantitative analysis in a large dataset containing 221096 pull requests on 28 projects, which ensures the correctness and robustness of our findings.
3) A comparison is made with our approach and the state of art accepted pull request prediction approach. Results show that CTCPPre has better performance.
2 Background and data collection
In this section, firstly the pull-based development model on GitHub is illustrated. Secondly, the process of data collection is introduced. Finally, the core classifier in this paper, namely XGBoost is introduced.
2.1 Pull request evaluation
GitHub is a web-based hosting service for software development repositories. In GitHub, contributors fork a project��s main repository, and make their code changes independent of one another. When a set of changes is ready, contributors create and submit pull requests to main repository. Any developers can leave comments and exchange opinions about pull requests. Developers discuss freely whether code style meets the standard [11], whether repositories require modification, or whether submitted codes have good quality [2]. According to comments, contributors may modify codes. Finally, integrators inspect submitted code changes, and decide whether to integrate these code changes into main repository or not [1]. Integrators act as guardian for project quality [12].
To illustrate the contribution process, Figure 1 shows an example of a pull request with number 6885 in project scala [13]. Firstly, a contributor gm*** modified codes and submitted a pull request. Secondly, an integrator dw*** leaved comments and discussed the pull request. Finally, the integrator dw*** decided to accept this pull request and merge code changes into main repository.
2.2 Data collection
GitHub provides access to its internal data through an API. It allows us to access rich collection of open source software (OSS) projects, and provides valuable opportunities for research.Information is gathered through GitHub API and creates datasets of projects.
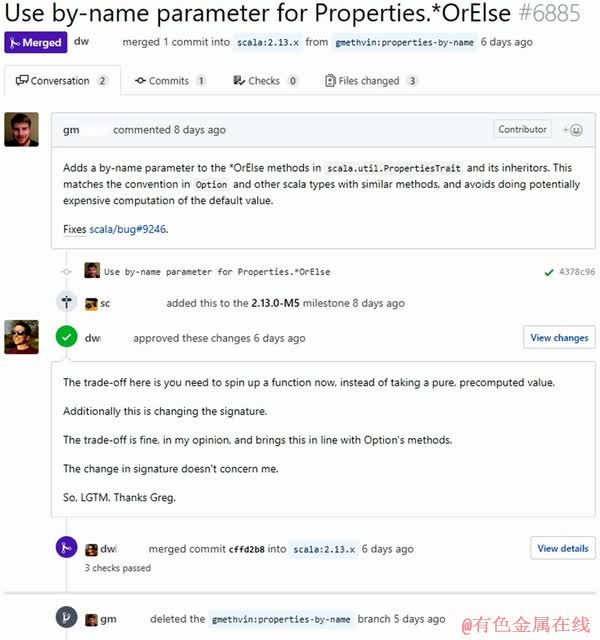
Figure 1 Example of pull request evaluation
In data collection, popular projects are chosen because they receive many pull requests and need prediction of accepted pull requests. VASILESCU et al [14] studied effects of continuous integration on software quality and productivity outcomes, and made their research projects public [15]. A list of projects from this previous work [14] is obtained. Their projects are sorted by the number of pull requests. Then 29 projects with the most number of pull requests are selected.
Pull requests of these 29 projects are collected through GitHub API in August 2016. Queries are sent to GitHub API, its replies are received, and then data from project creation time to July 31, 2016 is extracted. For each pull request, its ID, the contributor who submitted it, the creation time, the close time, paths of modified files and the developer who closed the pull request are crawled. The number of added lines, deleted lines, and commits in a pull request are collected. A pull request might be accepted and rejected, and this code review decision was also crawled. The contributor wrote a title and a body to describe the modification of a pull request, and this text information is gathered.
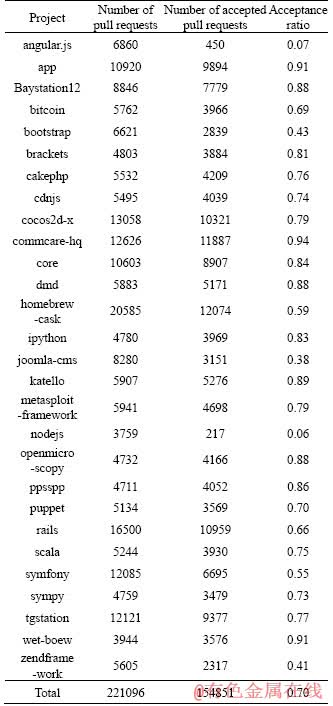
Table 1 presents statistics of collected data. The columns correspond to project name, the number of pull requests, the number of accepted pull requests, and the acceptance ratio. In total, our datasets include 221096 pull requests, and 154851 accepted pull requests from 28 projects. Though datasets of 29 projects are collected, only 28 projects are studied in this paper. This is because in a project spark, almost all pull requests are rejected. This project is excluded, because this project does not need the prediction of accepted pull requests. In Table 1, different projects have various acceptance ratios. 11 projects have acceptance ratios higher than 0.8, while 5 projects have acceptance ratios lower than 0.5.
2.3 XGBoost
XGBoost is a supervised learning algorithm that implements a process called boosting to yield accurate models [16]. The inputs of XGBoostare pairs of training examples 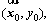
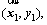 ��,
��, 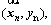 where
where 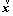 is a vector of features describing the example and y is its label. The output of XGBoost is the predicted value
is a vector of features describing the example and y is its label. The output of XGBoost is the predicted value 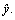 XGBoost aims to minimize the loss function L which indicates the difference between
XGBoost aims to minimize the loss function L which indicates the difference between 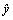 and y.
and y.
Table 1 Basic statistics of projects
XGBoost uses a decision tree boosting algorithm to minimize the loss function L. It builds an ensemble of decision tree models sequentially. XGBoost uses a greedy algorithm to choose a feature as the node to split the tree, which achieves the minimum loss function L based on the current tree structure. More specifically, XGBoost enumerates all the possible tree structures q. The greedy algorithm starts from a single leaf and iteratively adds branches to the tree. Assume that IL and IR are the instance sets of left and right nodes after the split. HL is the loss function of the left subtree, and HR is the loss function of the right subtree. GL is the gradient of the loss function based on the left subtree, and GR is the gradient of the loss function based on the right subtree. �� is a penalty for introducing new leave nodes and �� is the complexity cost of introducing new leaf nodes. Letting I=IL��IR, then the loss function after the split is given by:
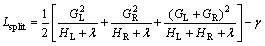 (1)
(1)
XGBoost uses the above formula to evaluate the feature candidates and choose a feature as the node which minimizes the loss function. XGBoost iteratively chooses features and builds an ensemble of decision tree models sequentially. When the tree reaches the preset maximum depth, the iteration stops and the model is finally built.
3 Proposed approach
In this section, our method CTCPPre is described. Figure 2 presents the overall framework of the accepted pull request prediction. The entire framework contains two phases: a model building phase and a prediction phase. In the model building phase, our goal is to build a model for a project from historical pull requests�� features. In the prediction phase, this model is used for a project to predict whether a pull request would be accepted or not. Firstly, features used in our approach are introduced. Then CTCPPre is described to solve accepted pull request prediction problem.
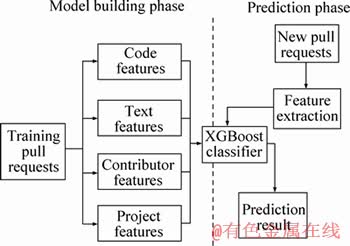
Figure 2 Overall framework of CTCPPre
3.1 Features
As shown in Table 2, code features, text features, contributor features and project features are mainly considered. Code features measures characteristics of modified codes. In text dimension, features from natural language description of pull requests are extracted. In contributor dimension, features based on previous behaviors of contributors who submit pull requests are extracted. Project features mainly analyze recent development environment. All these features can be automatically and immediately extracted when pull requests are submitted. In this subsection, detailed definitions and why these features are chosen are described.
Table 2 Investigated features
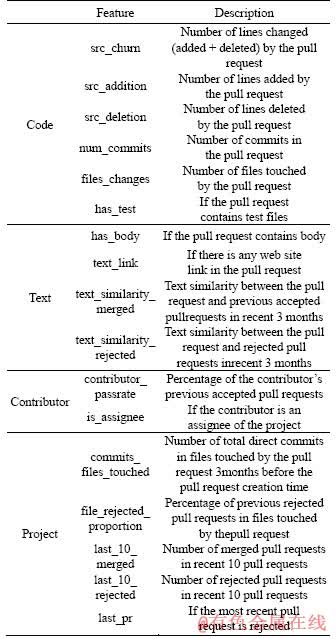
3.1.1 Code features
Code features mainly measure characteristics of codes modified in a pull request. WEISSGERBER et al [17] observed that size of a patch had impacts on its acceptance. The features src_churn, src_addition, src_deletion, num_commits and files_changes are used to quantify the size of a pull request. Furthermore, PHAM et al [18] found that presence of tests in pull requests increased integrators�� confidence in accepting them. Therefore, the feature has_test is used to measure whether a pull request contains test files.
3.1.2 Text features
In previous works [6, 8], text features were used to recommend reviewers who decided to accept or reject code changes. Text features is also considered to capture textual characteristics of messages in pull requests. GOUSIOS et al [9] studied impacts of comments on pull requests�� acceptance. Comments are added after the submission of pull requests. The acceptance is immediately predicted when pull requests are submitted, and comments is not considered because they are not created yet. The text in pull requests�� titles and bodies is mainly studied.
In GitHub, developers are required to write titles and briefly describe pull requests. Different from titles, bodies are not necessary, and they are used to introduce details of pull requests. The feature has_body is used to measure whether pull requests have bodies. Some developers write some links in titles or bodies, and refer related information, such as other pull requests, discussion in Stack Overflow, or some technical websites. Links may provide further information of pull requests. The feature text_link is used to decide whether pull requests include links.
Previous work [8] used text similarity in reviewer recommendation. Text similarity is also studied to predict accepted pull requests. The intuition is that related pull requests are often described in a similar way, and they may have similar code review results. Feature text_similarity_merged uses cosine similarity [19] to compute the text similarity between current pull request and previous accepted pull requests in the last 3 months. Feature text_similarity_rejected computes text similarity between current pull request and previous rejected pull requests in the last 3 months.
3.1.3 Contributor features
Contributor features refer to features which are based on previous experience of the pull request��s contributor. GOUSIOS et al [9] used acceptance rate prior to current pull request in the prediction of accepted pull requests. Following their study, the same feature which is named as feature contributor_passrate is used. In GitHub, an issue or a pull request can be assigned to a specific assignee who is responsible for working on this issue or pull request [20]. Assignees have the crucial role of managing and integrating contributions [21]. The feature is_assignee is considered to judge whether the contributor is an assignee or not. We use gitHub API to collect all assignees of projects [22].
3.1.4 Project features
These features quantify how receptive the project is to pull requests. Following previous work [9], the feature commits_files_touched is considered to measure whether a pull request touches an actively developed part of the system. Various open source projects may have different standards in evaluating pull requests. The stringency of recent code review may influence evaluation results, and thus features file_rejected_ proportion, last_10_merged, last_10_rejected and last_pr are used in the prediction of accepted pull requests.
3.2 CTCPPre
As shown in Figure 2, the entire framework of CTCPPre contains two phases: a model building phase and a prediction phase.
In the model building phase, code features, text features, contributor features and project features are computed for each pull request in training datasets. Then a weighted vector is used to represent each pull request, and each element in this vector corresponds to the value of a feature. There are only two choices of pull request evaluation results, namely accepted or rejected. The prediction of accepted pull requests can be transformed into the binary classification problem, which are often addressed by machine learning techniques [23]. According to pull request features and their known evaluation results in training datasets, a classifier XGBoost is built based on a training set of a project. XGBoost is a scalable end-to-end tree boosting method [16], which assigns label to a data point (in our case: a pull request) with ��accept�� or ��reject��.
In prediction phase, CTCPPre is used to predict accepted pull requests. CTCPPre first extracts code features, text features, contributor features and project features. Then, it processes these features into the XGBoost classifier built in the model building phase, and computes the acceptance probabilities and rejection probabilities of pull requests, respectively. If the acceptance probability is higher than rejection probability, the pull request is predicted as accepted; otherwise, the pull request is predicted as rejected. CTCPPre not only returns prediction results, but also provides acceptance probabilities and rejection probabilities of pull requests, which helps integrators to make decision.
4 Evaluation
In this section, results of proposed approach are presented. The aim of our study is to investigate the effectiveness of CTCPPre approach in predicting accepted pull requests. Firstly, the evaluation procedure, evaluation metrics, and research questions are presented. Then our experiment results that answer these research questions are presented. The experimental environment is a windows 10, 64-bit, Intel(R) Core i5 3.2 GHz PC with 16 GB RAM.
4.1 Evaluation procedure and metrics
In order to simulate the usage of methods in practice, all pull requests are sorted in chronological order of their creation time. Then the pull requests are classified into different groups with an interval of 180 d, and the training sets and testing sets are built. In the first round, the training set is built by pull requests created in 180 d after the first pull request. The testing set is built by pull requests created between 180 and 360 d after the first pull request. Then in the second round, the training set is built using pull requests in 360 d after the first pull request, and build testing set using pull requests created between 360 and 540 d after the first pull request. The similar way is used to build other training sets and testing sets. Finally, the average values of accuracies, area under the curve (AUC), harmonic average of precision and recall (F1), precision and recall of all rounds are computed. This setup ensures that only past pull requests are used to build prediction model.
In order to evaluate our method, accuracy, AUC, precision, recall and F1 are used as evaluation metrics. These metrics are commonly used in evaluation of acceptance prediction approach [9], and reviewer prediction approaches [6, 24].
Accuracy (a) is defined as the percentage of correctly predicted pull requests. If a pull request is predicted as accepted when it is truly accepted, the prediction is correct; if a pull request is predicted as rejected when it is truly rejected, the prediction is correct; otherwise, the prediction is incorrect. Accuracy ranges from 0 to 1, and the larger accuracy indicates better prediction performance.
Receiver operating characteristic (ROC) curve illustrates the performance of a binary classifier, when its discrimination threshold is varied [24].AUC measures the area under the ROC curve. AUC evaluates the probability that a classifier ranks a randomly chosen accepted pull request higher than a randomly chosen rejected pull request. Similar to accuracy, AUC ranges from 0 to 1, and the larger AUC indicates better prediction performance.
In a project, ActualSet includes pull requests which are actually accepted, and RecSet includes pull requests which are predicted as accepted. Precision P is the percentage of pull requests which are correctly labeled as accepted among those that are predicted as accepted. More specifically, the precision is defined as:
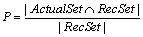 (2)
(2)
R is the percentage of accepted pull requests that are correctly labeled, and it is given by:
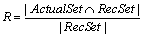 (3)
(3)
F1-score F1 is a summary metric that combines both P and R to measure the performance of the prediction method. It evaluates whether an increase in precision (R) outweighs a reduction in recall (P). It is calculated as the harmonic mean of P and R, which is defined as:
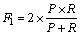 (4)
(4)
In order to compare the five methods, the gain is defined to compare how method 1 outperforms the method 2. As described in initial study [25], accuracy gain, AUC gain, precision gain, recall gain and F1 gain are defined as follows:
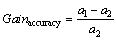 (5)
(5)
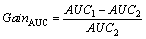 (6)
(6)
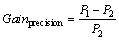 (7)
(7)
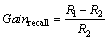 (8)
(8)
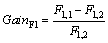 (9)
(9)
where a1, AUC1, P1, R1 and F1,1 evaluate the performance of method 1, and a2, AUC2, P2, R2 and F1,2 evaluate the performance of method 2. If the gain value is above 0, it means that method 1 has better performance than method 2; otherwise, method 2 has better prediction results than method 1.
4.2 Research questions
In this paper, the following six research questions are answered:
RQ1: What is the performance of CTCPPre in predicting accepted pull requests?
CTCPPre is presented to predict whether a pull request will be accepted. The performance of our method is evaluated in terms of accuracy, AUC, F1, precision and recall.
RQ2: How does the performance of CTCPPre and RFPredict [9] compare in predicting accepted pull requests?
In order to evaluate the performance of our approach, CTCPPre is compared with the state-of- the-art approach RFPredict [9].
RQ3: What is the benefit of XGBoost in predicting accepted pull requests?
There are several machine learning algorithms used in prediction models [9, 26]. CTCPPre uses XGBoost classifier to build the prediction model. It is useful to investigate whether XGBoost classifier achieves better performance than some other machine learning algorithms. To answer this question, each dataset is run through three other classification algorithms, namely random forest, naive Bayes and SVM. The performance of the machine learning algorithms is compared in the prediction of accepted pull requests.
RQ4: What is the benefit of feature combination in predicting accepted pull requests?
CTCPPre combines code features, text features, contributor features and project features. It is useful to investigate whether the combination of features could achieve better performance than a single set of feature. The XGBoost classifier is built for each feature set. Compare their performances with results of combined features.
RQ5: How does CTCPPre perform on pull requests submitted by integrators and non- integrators?
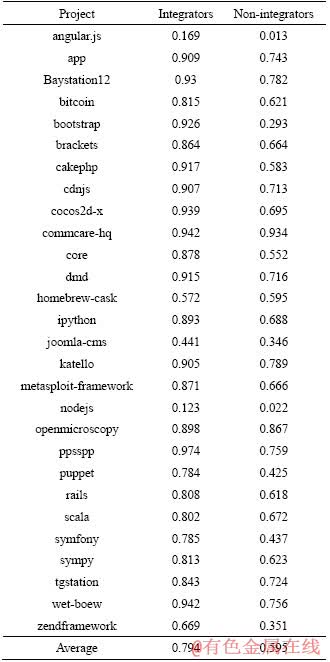
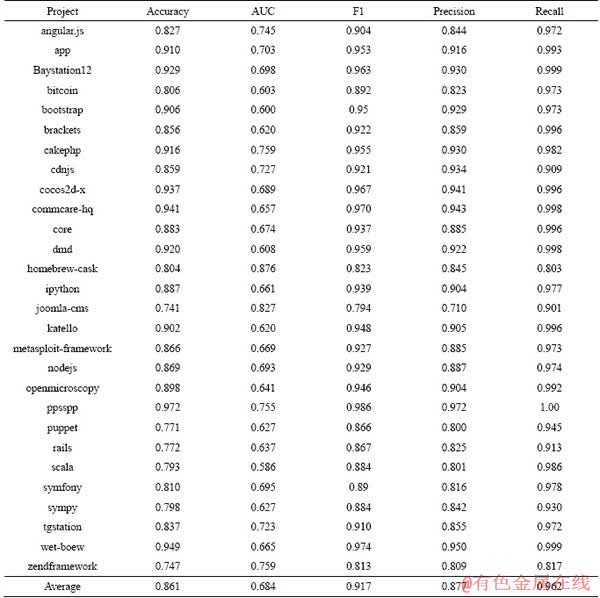
As is shown in Table 3, the average acceptance rate of integrators and non-integrators in 28 projects is 0.794 and 0.595, respectively. The acceptance rate of integrators�� pull requests is much higher than that of non-integrators�� pull requests. So it is useful to investigate the prediction performance of CTCPPre on pull requests of integrators and non-integrators, respectively.
Table 3 Pull request acceptance rate of integrators and non-integrators
4.2.1 RQ1: Performance of CTCPPre
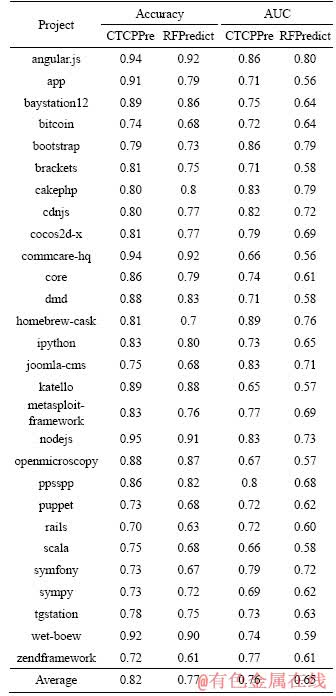
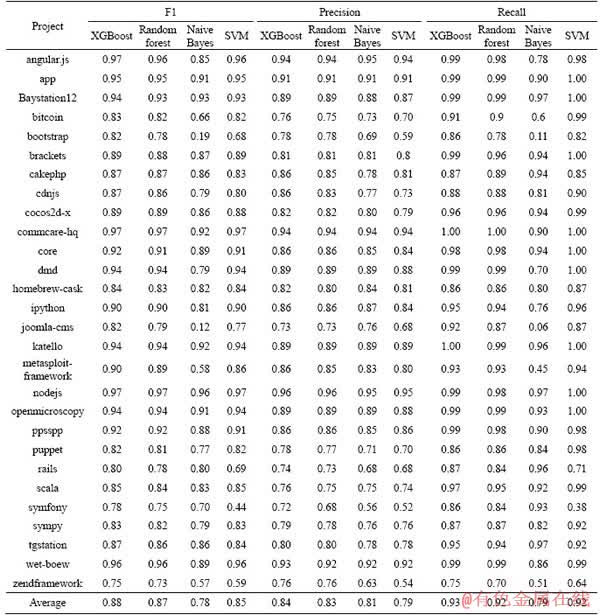
In order to show the performance of CTCPPre, Tables 4 and 5 show the accuracy, AUC, F1, precision and recall of each project in prediction of pull request evaluation result. The accuracy of project nodejs is 0.95, which means 95% of the pull requests in project nodejs are correctly predicted by CTCPPre. 5 projects have accuracies higher than 0.9, and 18 projects have accuracies higher than 0.8. For 28 projects, the average accuracy, AUC, average F1, average precision and average recall of CTCPPre are 0.82, 0.76, 0.88, 0.84 and 0.93, respectively. Results show that CTCPPre performs well in predicting accepted pull requests.
Tables 4 and 5 show that different projects have different results. For example, the accuracy of project nodejs is 0.95, while the accuracy of project rails is only 0.70. As shown in Table 1, the acceptance ratios are different in various projects. For projects with high acceptance ratios or low acceptance ratios, their prediction performance often performs better than projects with median acceptance ratios. In projects with imbalanced data, one class (i.e. majority) usually appears a lot more than another class (i.e. minority), which causes machine learning algorithms to learn features of the majority class better.
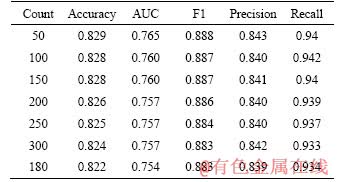
As is described in Section 4.1, training sets and testing sets are mainly built by classifying pull requests into different groups with an interval of 180 d. It is useful to investigate the performance of the method if the pull requests are classified into groups by the number of pull request, instead of by the number of days. All pull requests are sorted in chronological order of their creation time. Then pull requests are classified into different groups with an interval of Count days, and training sets and testing sets are built. The performances of the method when Count equals to 50, 100, 150, 200, 250 and 300 are evaluated, and results are described in Table 6. In order to make comparison, results when pull requests are classified into different groups with an interval of 180 d are also described. The finding is that the interval of Count days has little influence to the performance of CTCPPre. Furthermore, the performance based on datasets counted by the number of pull requests is similar as the performance based on datasets counted by 180 d. Therefore, training sets and testing sets are decided to be built by classifying pull requests with an interval of 180 d in following experiments.
Table 4 Accuracy and AUC of CTCPPre and RFPredict
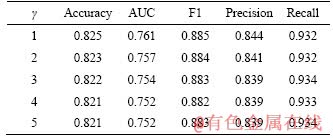
As shown in Table 2, the temporal window length �� is used in features text_similarity_merged, text_similarity_rejected and commits_files_touched to exclude pull requests which are created more than �� months before the new pull request. It is useful to investigate the effect of the temporal window length �� on performance of CTCPPre. Therefore, the method performance is computed with different �� values, and results are described in Table 7. Results show that when CTCPPre achieves the best performance when �� is set as 1. However, the performance difference is small among various settings. Temporal window length �� is set as 3 by default. In practice, open source projects may choose their own settings by experiment results.
Table 5 F1, Precision and Recall of CTCPPre and RFPredict
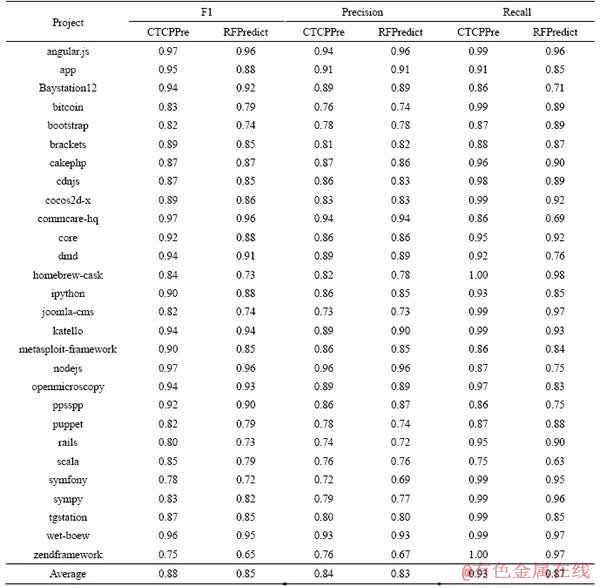
Table 6 Performance based on datasets counted by number of pull requests
RQ1: CTCPPre achieves accuracy of 0.82 and AUC of 0.76 on average.
4.2.2 RQ2: Approach comparison
GOUSIOS et al [9] analyzed pull request features, project features and developer features. Then they built a random forest classifier RFPredict to predict whether pull requests will be accepted or not. Our work considers new features which are not considered by Ref. [9]. For example, features are studied to measure stringency of recent code review, and text features are considered to study pull requests�� description. Furthermore, XGBoost classifier is used to make prediction. RFPredict mainly studies impacts of features on pull request evaluation results, and it considers comments which are not provided immediately after the submission of pull requests. Since new submitted pull requests do not have any comments, features related to comments are excluded when RFPredict is implemented.
Table 7 Performance with different temporal window length ��
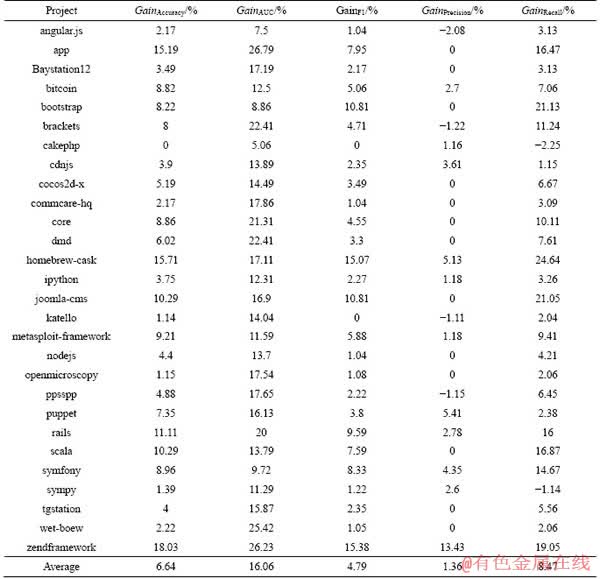
In order to answer RQ2, Tables 4-5 and 8 are presented. Tables 4 and 5 compare accuracy, AUC, F1, precision and recall of CTCPPre and RFPredict. And best results are in bold. Accuracy gains and AUC gains are computed to assess difference between approaches, and describe results in Table 8. In project homebrew-cask, CTCPPre our performs RFPredict by 15.71%, 17.11%, 15.07%, 5.13% and 24.64% in terms of accuracy, AUC, F1, precision and recall, respectively. On average across 28 projects, CTCPPre outperforms RFPredict by 6.64%, 16.06%, 4.79%, 1.36% and 8.47% in terms of accuracy, AUC, F1, precision and recall, respectively. CTCPPre performs better than RFPredict in predicting accepted pull requests.
Table 8 Gains of approaches CTCPPre and RFPredict
RQ2: CTCPPre outperforms RFPredict by 6.64% and 16.06% in terms of accuracy and AUC.
4.2.3 RQ3: Benefit of XGBoost classifier
Several machine learning algorithms are known to perform well and have been used in prediction models [9, 26]. In Figure 2, several machine learning algorithms can be used to build the model for prediction of accepted pull requests. In this subsection, the performance of different machine learning algorithms is investigated. Different machine learning algorithms are used to build classifiers, including XGBoost, random forest, naive Bayes and SVM. Datasets are run through four classification algorithms, and their performance is compared.
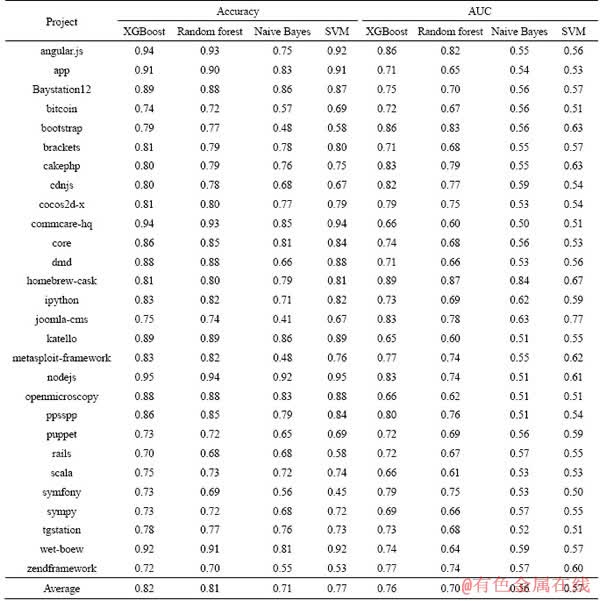
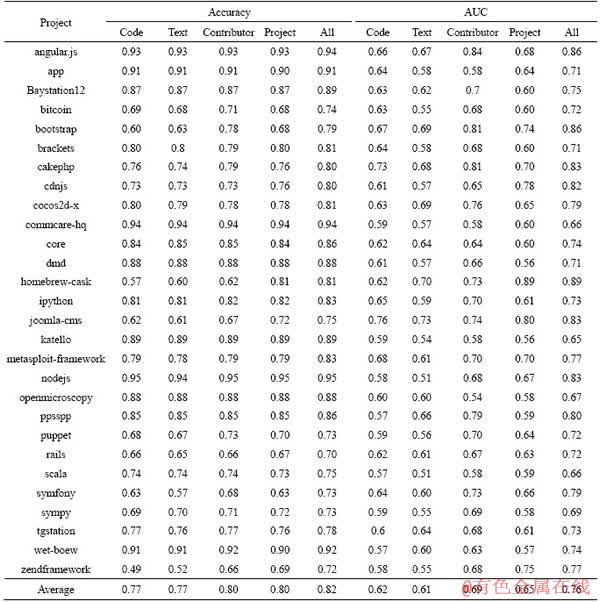
Table 9 shows accuracies and AUC of different machine learning algorithms. The average accuracy of XGBoost in the 28 projects is 0.82, while the average accuracy of random forest, naive Bayes and SVM is 0.81, 0.71 and 0.77, respectively. The average AUC of XGBoost in the 28 projects is 0.76, while the average AUC of random forest, naive Bayes and SVM is 0.70, 0.56 and 0.57, respectively. The prediction based on XGBoost has accuracies and AUC better than other machine learning algorithms. Therefore, XGBoost is chosen in the prediction of accepted pull requests.
Reasons of XGBoost��s good performance are as follow. Firstly, 17 features in code, text, contributor, and project dimensions are considered. The number of features is not large, which is suitable for machine learning algorithms based on trees. As shown in Tables 9 and 10, two tree models XGBoost and random forest perform better than naive Bayes and SVM. Second, XGBoost constructs trees serially [16], while random forest constructs trees in parallel. Constructing the tree serially can optimize the loss function in every tree, which makes higher calculation accuracy of the fitting target value and better classification performance.
RQ3: The prediction based on XGBoost achieves better performance than random forest, naive Bayes and SVM.
4.2.4 RQ4: Benefit of feature combination
In this subsection, it is useful to investigate whether the combination of features could achieve better performance than a single set of features. An XGBoost classifier is built only based on code features, text features, contributor features or project features, respectively. Tables 11 and 12 show performance of predictors based on different features, respectively. The result is that by combining all features in prediction of accepted pull requests, CTCPPre outperforms predictors only based on code features, text features, contributor features or project features in terms of accuracies and AUC. Therefore, the combination of all features is beneficial in prediction of accepted pull requests.
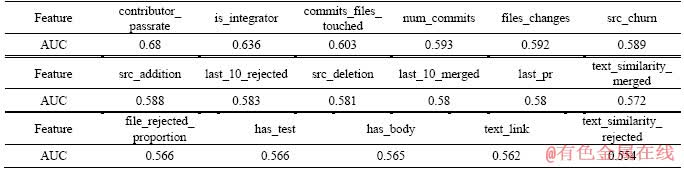
Then feature importance is studied. Predictors are built based on different single feature. Table 13 shows the AUC for predictors based on different single features. The result is that the percentage of the contributor��s previous accepted pull requests is the most significant feature, because the predictor based on this feature achieves the highest AUC. It is also important whether the contributor is an integrator of the project or not.
RQ4: The combination of code features, text features, contributor features and project features is beneficial in prediction of accepted pull requests.
4.2.5 RQ5: Performance on pull requests of integrators and non-integrators
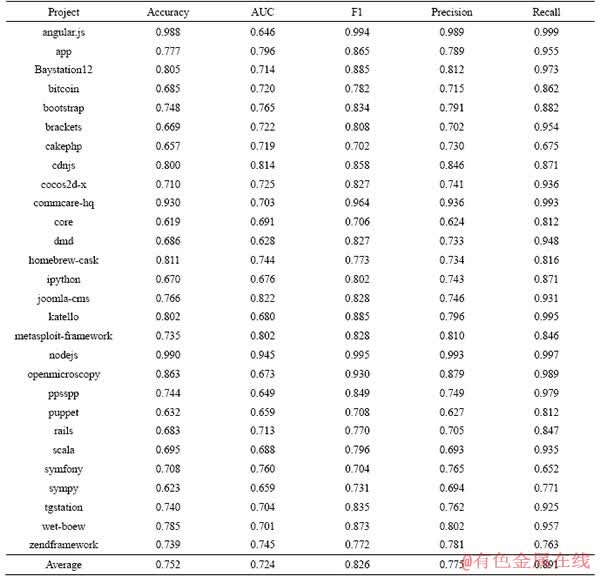
In this subsection, it is useful to investigate the prediction performance on integrators�� pull requests and non-integrators�� pull requests of CTCPPre. CTCPPre is used to predict accepted pull requests of integrators and non-integrators in 28 projects. Tables 14 and 15 show the results of integrators and non-integrators, respectively. The result is that CTCPPre achieves accuracy of 0.861 on integrators�� pull requests and accuracy of 0.752 on non-integrators�� pull requests. Therefore, CTCPPre performs better on integrators�� pull requests than on non-integrators��pull requests.
RQ5: CTCPPre performs better on integrators�� pull requests than non-integrators�� pull requests.
5 Threats to validity
Threats to construct validity refer to suitability of our evaluation measures. We use accuracy and AUC, which are also used by previous works to evaluate effectiveness of accepted pull request predictor [9] and various automated software engineering techniques [6, 24, 27-29]. Therefore, we believe there is little threat to construct validity.
Table 9 Accuracies and AUC of different machine learning algorithms
Threats to external validity relate to universality of our study. Firstly, our experimental results are limited to 28 popular projects on GitHub. We find that CTCPPre achieves higher accuracies and AUC than RFPredict, which are based on 28 projects in our datasets. We cannot claim that the same results would be achieved in other projects. Our future work will focus on evaluation in other projects to better generalize results of our method. We will conduct broader experiments to validate whether CTCPPre performs well in accepted pull request prediction. Secondly, our empirical findings are based on open source software projects in GitHub, and it is unknown whether our results can be generalized to other OSS platforms. In the future, we plan to study a similar set of research questions in other platforms, and compare their results with our findings in GitHub.
Threats to internal validity also relate to bias and errors in our data sets and experiments. We consider ground truth as pull requests which are actually accepted by integrators. Contributors and integrators exchange comments and discuss code changes [30]. Therefore, we believe that most of integrators�� decisions are correct, and they can be used in experiments.
Table 10 F1, precision and recall of different machine learning algorithms
Threats to construct validity relate to the degree to which the construct being studied is affected by experiment settings. We consider 17 features in code, text, contributor and project dimensions. We have not studied all potential features for the prediction of accepted pull requests. In future work, we will study more potential features. For example, some open source software projects adopt continuous integration in code review [14]. In future work, we plan to consider features about continuous integration, and explore how prediction performance changes.
6 Related work
Related work to this study could be divided into two main categories, including pull request evaluation and reviewer recommendation.
1) Pull request evaluation. As is known,previous work [9] is the most related work to our paper on predicting accepted pull requests. GOUSIOS et al [9] analyzed pull request features, project features and developer features. Then they built a random forest classifier RFPredict to predict whether pull requests will be accepted or not. Our work considers new features which are not considered by Ref. [9]. For example, features are studied to measure stringency of recent code review, and text features are considered to study pull requests�� description. Furthermore, XGBoost classifier are used to make prediction, which is proved to perform better than random forest classifier. Experiment results show that XGPrect achieves higher values of AUC and accuracy than RFPredict [9].
Table 11 Accuracies and AUC of different features
There are also other studies about pull request evaluation. GOUSIOS et al [25] took a further step, and studied contributors�� work practices and challenges in contribution integration. VASILESCU et al [14] studied quality and productivity outcomes relating to continuous integration in GitHub. HILTON et al [31] study the usage of continuous integration systems in contribution integration. Different from these works, a different problem is solved and an automatic approach is designed to predict accepted pull requests.
Table 12 F1, precision and recall of different features
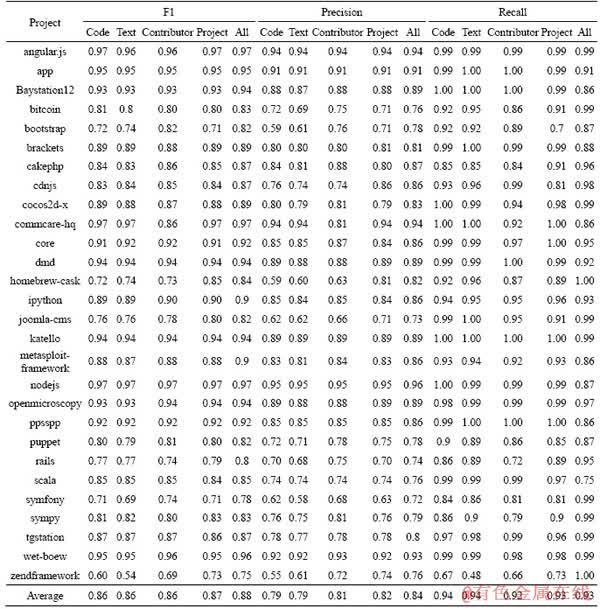
Table 13 AUC of single features
2) Reviewer recommendation. There are also a number of studies on reviewer recommendation. Initial studies [4-6, 24, 32-35] analyze different code review activities and design reviewer recommendation approaches. ZANJANI et al [4] analyzed review comments and proposed a reviewer expertise approach. In order to recommend reviewers, approach WRC analyzed past reviews with the same files [5]. XIA et al [6] proposed a hybrid and incremental approach TIE, which utilized the advantages of both text mining and a file location-based approach. JIANG et al [24] used support vector machines to analyze integrators�� previous decisions, and designed an approach CoreDevRec to recommend integrators [24]. RAHMAN et al [35] proposed a code reviewer recommendation based on cross-project and technology experience. OUNI et al [34] designed a search-based approach to identify most appropriate peer reviewers for code changes.
Table 14 Performance on pull requests of integrators
Instead of reviewer recommendation, an accepted pull request prediction is designed, and another way to help integrator in code review is proposed.
7 Conclusions
In this paper, an approach CTCPPre to predict accepted pull requests is proposed. CTCPPre extracts code features, text features, contributor features and project features. Based on these features, CTCPPre builds an XGBoost classifier based on a training set of a project to predict accepted pull requests. Effectiveness of CTCPPre is evaluated on 28 projects containing 221096 pull requests. Experimental results show that CTCPPre has good performances by achieving accuracy of 0.82, AUC of 0.76 and F1-score of 0.88 on average. It is compared with the state of art accepted pull request prediction approach RFPredict. On average across 28 projects, CTCPPre improves RFPredict by 6.64%, 16.06% and 4.79% in terms of accuracy, AUC and F1-score, respectively. Therefore, CTCPPre is useful to predict accepted pull requests and improve code review process.
Table 15 Performance on pull requests of non-integrators
References
[1] GOUSIOS G, ZAIDMAN A, STOREY M A, DEURSEN A V. Work practices and challenges in pull-based development: the integrator��s perspective [C]// Proceedings of the 37th International Conference on Software Engineering-Volume 1. IEEE, 2015: 358-368. DOI: 10.1109/icse.2015.55.
[2] TSAY J, DABBISH L, HERBSLEB J. Let��s talk about it: evaluating contributions through discussion in GitHub [C]// Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM, 2014: 144-154. DOI:10.1145/2635868.2635882.
[3] RAHMAN M M, ROY C K, KULA R G. Predicting usefulness of code review comments using textual features and developer experience [C]// 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR). IEEE, 2017: 215-226. DOI: 10.1109/msr.2017.17
[4] ZANJANI M B, KAGDI H, BIRD C. Automatically recommending peer reviewers in modern code review [J]. IEEE Transactions on Software Engineering, 2015, 42(6): 530-543. DOI: 10.1109/tse.2015.2500238.
[5] HANNEBAUER C, PATALAS M, STUNKEL S, GRUHN V. Automatically recommending code reviewers based on their expertise: An empirical comparison [C]// Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering. ACM, 2016: 99-110. DOI: 10.1145/ 2970276.2970306.
[6] XIA Xin, LO D, WANG Xin-yu, YANG Xiao-hu. Who should review this change? Putting text and file location analyses together for more accurate recommendations [C]// 2015 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2015: 261-270. DOI: 10.1109/icsm.2015.7332472.
[7] YU Yue, WANG Hua-min, YIN Gang, WANG Tao. Reviewer recommendation for pull-requests in GitHub: What can we learn from code review and bug assignment? [J]. Information and Software Technology, 2016, 74: 204-218. DOI: 10.1016/j.infsof.2016.01.004.
[8] JIANG Jing, YANG Yun, HE Jia-huan, BLANC X, ZHANG Li. Who should comment on this pull request? Analyzing attributes for more accurate commenter recommendation in pull-based development [J]. Information and Software Technology, 2017, 84: 48-62. DOI: 10.1016/j.infsof.2016.10.006.
[9] GOUSIOS G, PINZGER M, DEURSEN A. An exploratory study of the pull-based software development model [C]// Proceedings of the 36th International Conference on Software Engineering. ACM, 2014: 345-355. DOI: 10.1145/ 2568225.2568260
[10] JIANG Jing, ZHENG Jia-teng, YANG Yun, ZHANG Li, LUO Jie. Predicting accepted pull requests in GitHub [J]. Science China Information Sciences, 2019 (letter article). DOI: 10.1007/s11432-018-9823-4.
[11] HELLENDOORN V J, DEVANBU P T, BACCHELLI A. Will they like this?: Evaluating code contributions with language models [C]// Proceedings of the 12th Working Conference on Mining Software Repositories. IEEE, 2015: 157-167. DOI: 10.1109/msr.2015.22.
[12] BACCHELLI A, BIRD C. Expectations, outcomes, and challenges of modern code review [C]// Proceedings of the 2013 International Conference on Software Engineering. IEEE, 2013: 712-721. DOI: 10.1109/icse.2013.6606617.
[13] GMETHVIN. Use by-name parameter for Properties.*OrElse[EB/OL].[2018-05-06].https://github.com/scala/scala/pull/6885.
[14] VASILESCU B, YU Yue, WANG Hua-min, DEVANBU P, FILKOV V. Quality and productivity outcomes relating to continuous integration in GitHub [C]// Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. ACM, 2015: 805-816. DOI: 10.1145/2786805.2786850.
[15] YUE Yue. All projects csv. [EB/OL].[2016-07-04]. https://github.com/Yuyue/pullreq_ci/blob/master/all_projects.csv.
[16] CHEN Tian-qi, GUESTRIN C. Xgboost: A scalable tree boosting system [C]// Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining. ACM, 2016: 785-794. DOI: 10.1145/2939672. 2939785.
[17] WEISSGERBER P, NEU D, DIEHL S. Small patches get in! [C]// Proceedings of the 2008 International Working Conference on Mining Software Repositories. ACM, 2008: 67-76. DOI: 10.1145/1370750.1370767.
[18] PHAM R, SINGER L, LISKIN O, FILHO F F, SCHNEIDER K. Creating a shared understanding of testing culture on a social coding site [C]// Proceedings of the 2013 International Conference on Software Engineering. IEEE, 2013: 112-121. DOI: 10.1109/icse.2013.6606557.
[19] DHILLON I S, MODHA D S. Concept decompositions for large sparse text data using clustering [J]. Machine Learning, 2001, 42(1, 2): 143-175.
[20] Assigning issues and pull requests to other GitHub users[EB/OL].[2018-05-10].https://help.github.com/en/articles/assigning-issues-and-pull-requests-to-other-github-users.
[21] TSAY J, DABBISH L, HERBSLEB J. Influence of social and technical factors for evaluating contribution in GitHub [C]// Proceedings of the 36th International Conference on Software Engineering-Volume 1. IEEE, 2014: 356-366. DOI: 10.1145/2568225.2568315.
[22] Assignees[EB/OL].[2018-05-20].https://developer.github.com/v3/issues/assignees/.
[23] XIA Xin, LO D, WANG Xin-yu, YANG Xiao-hu, LI Shan-ping. A comparative study of supervised learning algorithms for re-opened bug prediction [C]// 2013 17th European Conference on Software Maintenance and Reengineering. IEEE, 2013: 331-334. DOI: 10.1109/csmr.2013.43.
[24] JIANG Jing, HE Jia-huan, CHEN Xue-yuan. Coredevrec: Automatic core member recommendation for contribution evaluation [J]. Journal of Computer Science and Technology, 2015, 30(5): 998-1016. DOI: 10.1007/s11390-015-1577-3.
[25] XIA Xin, LO D, WANG Xin-yu, ZHOU Bo. Accurate developer recommendation for bug resolution [C]// 2013 20th Working Conference on Reverse Engineering (WCRE). IEEE, 2013: 72-81. DOI: 10.1109/wcre.2013.6671282.
[26] MOHAMED A, ZHANG Li, JIANG Jing, KTOB A. Predicting which pull requests will get reopened in GitHub [C]// 2018 25th Asia-Pacific Software Engineering Conference. IEEE, 2018: 375-385. DOI:10.1109/APSEC. 2018.00052.
[27] LAMKANFI A, DEMEYER S, GIGER E, GOETHALS B. Predicting the severity of a reported bug [C]// 2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010). IEEE, 2010: 1-10. DOI: 10.1109/msr.2010.5463284.
[28] LESSMANN S, BAESENS B, MUES C, PIETSCH S. Benchmarking classification models for software defect prediction: A proposed framework and novel findings [J]. IEEE Transactions on Software Engineering, 2008, 34(4): 485-496. DOI: 10.1109/tse.2008.35.
[29] ROMANO D, PINZGER M. Using source code metrics to predict change-prone java interfaces [C]// 2011 27th IEEE International Conference on Software Maintenance (ICSM). IEEE, 2011: 303-312. DOI: 10.1109/icsm.2011.6080797.
[30] GOUSIOS G, STOREY M A, BACCHELLI A. Work practices and challenges in pull-based development: the contributor's perspective [C]// 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE). IEEE, 2016: 285-296. DOI: 10.1145/2884781.2884826.
[31] HILTON M, TUNNELL T, HUANG Kai, MARINOV D, DIG D. Usage, costs, and benefits of continuous integration in open-source projects [C]// Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering. ACM, 2016: 426-437. DOI: 10.1145/2970276. 2970358.
[32] THONGTANUNAM P, TANTITHAMTHAVORN C, KULA R G, YOSHIDA N, IIDA H, MATSUMOTO K. Who should review my code? A file location- based code-reviewer recommendation approach for modern code review [C]// 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER). IEEE, 2015: 141-150. DOI: 10.1109/saner.2015. 7081824.
[33] BALACHANDRAN V. Reducing human effort and improving quality in peer code reviews using automatic static analysis and reviewer recommendation [C]// Proceedings of the 2013 International Conference on Software Engineering. IEEE, 2013: 931-940. DOI: 10.1109/icse.2013.6606642.
[34] OUNI A, KULA R G, INOUE K. Search-based peer reviewers recommendation in modern code review [C]// 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2016: 367-377. DOI: 10.1109/icsme.2016.65.
[35] RAHMAN M M, ROY C K, COLLINS J A. Correct: code reviewer recommendation in github based on cross-project and technology experience [C]// 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C). IEEE, 2016: 222-231. DOI: 10.1145/2889160.2889244.
(Edited by ZHENG Yu-tong)
���ĵ���
CTCPPre��һ��Ԥ��GitHub�б����ܵĹ�������ķ���
ժҪ�����ſ�Դ��Ŀ�����У���Ŀ�յ��Ĺ��������������������ܻ�ܾ���������������˴����˳��صĸ�����һ��Ԥ�ⱻ���ܵĹ�������ķ������������������ܾ̾������������������ྫ��Ͷ�뵽�������Ĺ��������ϡ����������һ��CTCPPre������Ԥ��GitHub�б����ܵĹ�������CTCPPre��Ҫ�����������Ĵ�����������������������Ϣ���ı�������������Ա��ʷ��Ϊ�Ĺ����������Լ�������������Ŀ������������CTCPPre����221096�����������28����Ŀ����Ч�ԡ�ʵ�����������뷨RFPredictԤ�ⷽ��Ƚϣ�CTCPPre�������õ����ܣ�ƽ��ȷ��Ϊ0.82��ƽ��AUCΪ0.76��ƽ��F1����Ϊ0.88����28����Ŀ�У�CTCPPre��ȷ�ԡ�AUC��F1��������ֱ��RFPredict ������6.64%��16.06%��4.79%��
�ؼ��ʣ������ܵĹ�������Ԥ�⣻��������GitHub�����ڹ����������������
Foundation item: Project(2018YFB1004202) supported by the National Key Research and Development Program of China; Project(61732019) supported by the National Natural Science Foundation of China; Project(SKLSDE-2018ZX-06) supported by the State Key Laboratory of Software Development Environment, China
Received date: 2019-04-11; Accepted date: 2019-06-28
Corresponding author: ZHANG Li, PhD, Professor; Tel: +86-10-82317649; E-mail: lily@buaa.edu.cn; ORCID: 0000-0002-2258-5893
Abstract: As the popularity of open source projects, the volume of incoming pull requests is too large, which puts heavy burden on integrators who are responsible for accepting or rejecting pull requests. An accepted pull request prediction approach can help integrators by allowing them either to enforce an immediate rejection of code changes or allocate more resources to overcome the deficiency. In this paper, an approach CTCPPre is proposed to predict the accepted pull requests in GitHub. CTCPPre mainly considers code features of modified changes, text features of pull requests�� description, contributor features of developers�� previous behaviors, and project features of development environment. The effectiveness of CTCPPre on 28 projects containing 221096 pull requests is evaluated. Experimental results show that CTCPPre has good performances by achieving accuracy of 0.82, AUC of 0.76 and F1-score of 0.88 on average. It is compared with the state of art accepted pull request prediction approach RFPredict. On average across 28 projects, CTCPPre outperforms RFPredict by 6.64%, 16.06% and 4.79% in terms of accuracy, AUC and F1-score, respectively.
