
����ͳ�Ƶľ䷨��������
Ԭ���
(�����ƾ���ѧ ��Ϣ����ѧԺ��������֪ʶ���̽���ʡ��У�ص�ʵ���ң����� �ϲ���330013)
ժ Ҫ��
���Դ�����һ���������⣬���Ŵ��ģ��ע����Ľ��������������ͳ�ƾ䷨������Ϊ�ִ��䷨�����������������ڽ��ܾ䷨�������⼰�䷨�����������ⷽ���Ļ�����,����Ҫ�䷨����ͳ��ģ�ͺ����ľ䷨�������о���״���м�Ҫ�����ͷ���,��̽�ֺ��ܽ��˻���ͳ�Ƶľ䷨����ģ�͵IJ���֮���ͷ�չ���ƣ�ָ�����еĺ���䷨�����������ʺϺ�����ص㣬û����Ч�̻�������ı�������,����Ŀǰ����䷨����������Ӣ��������ϴ�;��������Ϣ����䷨����,���ڴ˻����Ͻ����䷨�����������ɫ��ע����ѧϰͳ��ģ��,���Ǿ䷨������һ����Ҫ�о�����
�ؼ��ʣ�
�䷨������ͳ��ģ���������������Ȼ���Դ�����
��ͼ����ţ�TP391.1 ���ױ�־�룺A ���±�ţ�1672-7207(2014)08-2669-07
Statistical syntactic parsing methods
YUAN Lichi
(Jiangxi Key Laboratory of Data and Knowledge Engineering, School of Information Technology,
Jiangxi University of Finance and Economics, Nanchang 330013, China)
Abstract: Syntactic parsing is a fundamental problem of natural language processing, and statistical syntactic parsing based on treebank gradually becomes the mainstream techniques of modern syntactic parsing following the building of large scale annotated treebanks. Firstly, the main treebanks and the main methods to measure syntactic parsing system performances were described. Secondly, the main statistical syntactic parsing models and the current researches on the Chinese syntactic parsing were presented and analyzed. Finally, the problems and the future study trends of statistical syntactic parsing were discussed and summarized. Is is pointed that Chinese syntax analysis methods are not suitable for the features of Chinese, and they do not effectively characterize the essential features of Chinese, thus the performances of syntactic parsing of Chinese are far below the performances of English. To integrate semantic information in syntactic parsing and to establish a joint syntactic and semantic statistical parsing model based on. semantic analysis will be a important study direction of syntactic parsing.
Key words: syntactic parsing; statistical model; semantic parsing; natural language processing
�䷨�����ֳ��ķ���������ָ���ݸ���������Զ���ʶ��������������ľ䷨��λ����Щ�䷨��λ֮��Ĺ�ϵ���䷨��������Ȼ���Դ��������о���ʮ����Ҫ�ĵ�λ�����������һ���Ϊ���²��裺ԭ�����롢���Ӵ����зּ���������������ע������䷨���������弰���ú��ᄈ����������Ŀ����ʽ��ʾ����Ⱥ��ƪ������ȡ����ӷ����Ͻ�ƪ�����⣬�����ʻ���������ų������µ����á��ʻ�����ǻ��������ӷ��������ģ�ƪ������������Ŀ�ġ���ô��һ���õ��˾��ӳɷֵļ������ʾ��������Ӧ���ھ�Ⱥ���֡�ƪ�����⣬���ǻ������롢�������塢�˻��Ի����鱨�����ȷ��棬������ʵ�����塣�䷨����ͬʱҲ�ǹ��ϵ�һ���о����⡣��20����50���������������ⱻ�����������Ȼ���Դ����о��Ѿ���60����ʷ���䷨����һֱ���谭��Ȼ���Դ�����չ����Ҫ�ϰ������ž䷨������2���ѵ�[1-2]���ڣ�
(1) ���塣����һ�������������ʹ����һ���dz��ľ��ӣ�Ҳ�����ж��־䷨���������
(2) �����ռ�䷨������һ����Ϊ���ӵ�����ѡ����������ӳ��ȳ�ָ���������������ռ��
��ˣ�����ƾ䷨����ģ��ʱ��������ƺ�ģ�͵ĸ��Ӷȣ��Ա�֤�䷨�������ܹ��ڿɽ��ܵ�ʱ�������������ŵľ䷨���������䷨�������о������Ϊ2��;�������ڹ���ķ����ͻ���ͳ�Ƶķ���[3-11]�����ڹ���ķ�������֪ʶΪ�������������(rationalism)������������ѧ����Ϊ������ǿ������ѧ�Ҷ������������ʶ�����÷�����Ĺ�����ʽ���������������Ϊ���������ԡ����ڹ���ķ����ڴ������ģ��ʵ�ı�ʱ�����������Ƕ����ޡ�ϵͳ��Ǩ���Բ��ȱ�ݡ�20����90���������Ȼ���Դ���������ʼ��С��ģ�������Դ���������ģ��ʵ�ı����������Ŵ��ģ��ע����Ľ��������������ͳ�ƾ䷨������Ϊ�ִ��䷨��������������[12]������ͳ�ƾ䷨����ģ�͵�Ŀ�����Ը��ʵ���ʽ�������ɸ����ܵľ䷨�������(ͨ����ʾΪ�����ʽ)���������ɸ����ܵķ��������ֱ��ѡ��һ������ܵĽ��������ͳ�Ƶľ䷨����ģ��[3]��ʵ����һ�����۾䷨��������ĸ������ۺ���������������һ���������s�����ľ䷨���������������һ����������P(t|s)�����ɴ��ҳ��þ䷨����ģ����Ϊ�������ľ䷨������������ҵ� ���䷨��������������ռ�ΪS��T(����SΪ���о��ӵļ��ϣ�TΪ���о䷨��������ļ���)�������������۾䷨�������⼰�䷨�����������ⷽ���������е���Ҫ�䷨����ͳ��ģ�ͺͷ������м�Ҫ���ܺ������������ľ䷨�������о���״������������̽�ֻ���ͳ�Ƶľ䷨����ģ�͵IJ���֮���ͷ�չ���ơ�
���䷨��������������ռ�ΪS��T(����SΪ���о��ӵļ��ϣ�TΪ���о䷨��������ļ���)�������������۾䷨�������⼰�䷨�����������ⷽ���������е���Ҫ�䷨����ͳ��ģ�ͺͷ������м�Ҫ���ܺ������������ľ䷨�������о���״������������̽�ֻ���ͳ�Ƶľ䷨����ģ�͵IJ���֮���ͷ�չ���ơ�
1 �䷨�������⼰��������
1.1 �䷨�������Ͽ�
ͳ�ƾ䷨����ģ�͵�ѵ��[4]���Բ�����ָ��ѧϰ��ʽ��Ҳ���Բ�����ָ��ѧϰ��ʽ����ָ��ѧϰ��ʽһ��ֻ��Ҫ����һ���ķ������ɸ�û���κξ䷨��ǵľ��ӾͿ����Զ��ع��Ƴ�ģ�͵����в�������ָ��ѧϰ��ʽͨ����Ҫ��һ�������л�ȡ�䷨����ģ�͵ĸ��ֲ����;䷨֪ʶ����ν������ָ�Ծ����еľ䷨�ɷֽ����˻��ֺͱ�ע�����ϣ����п�����ȡ���������õľ䷨�ֲ���Ϣ����������ָ���ķ���������ָ���ķ���������Ҫ����ȥ������䷨�����ľ���, ��ˣ�����Ľ������ͳ�ƾ䷨�������Ŀ������о����Ż����Ե�֧������[1]��
1961�꣬�����ϵ�һ�����ģ�������Ͽ⡪�������Ͽ���֣���־�����Ͽ�����ѧ����[5]��Ӣ��������о����磬��չҲ�ܿ졣����2���Ƚϴ�Ĺ�����Ŀ�ǣ�Ӣ����Lancaster-LeedS������Ŀ��������Ϧ�����Ǵ�ѧ��PennTreebank��Ŀ[1, 4]��1984��1988���5��䣬Ӣ��Lancaster��ѧ��UCREL�о�С���ܹ��ӹ�������200����ʵ��������ϡ�Penn TreeBank�DZ�Ϧ�����Ǵ�ѧ�����������ϱ�ע��Ӣ�ľ䷨�������⡣��ǰ��ΪATIS�ͻ������ձ�(Wall Street Journal)���⣬���ĵ�1�汾������1991�꣬��2�汾��Penn TreeBank������1994�ꡣPenn TreeBank���ķ���ע�⣬����ע�˲���������Ϣ���ӵ�1�汾�����ڣ���������һֱ���ڲ��ϵ�ά������������ע��ģ�ѽӽ�5������ӣ�100������ʡ�Penn treebank���нϸߵ�һ���Ժͱ�עȷ�ԣ���Ŀǰ�о�Ӣ�ľ䷨���������ϵı�ע���Ͽ⡣���⣬�Ƚ�������Ӣ�������IBM�о�Ժ���⣬�����ȡ�Լ�����ֲ�����⽨�輼���ϣ�Charniak��[13]������ʹ���Զ��䷨���������ķ����۸�����ע������㷨��
��������[2, 4]����������Ƚ������������ı�������(Chinese Treebank)���廪��ѧ��������(Tsinghua Chinese Treebank)��̨������Ժ����(Sinica Treebank)������ѧ�����������ġ������ձ������ϡ���������ҵ��ѧ���������о�������ȡ�Chinese TreeBank (CTB)�DZ�Ϧ�����Ǵ�ѧ��1998�꿪ʼ��ע�ĺ���䷨���⡣������Դ���й���½����ۡ�̨���ý��������Ϣ����2000�귢��CTB1.0�������Ѷ�ζ����Ͻ����˸��������ӣ�Ŀǰ�����°汾ΪCTB6.0���ð汾������2 306ƪ�������£���28 295�����ӹ��ɣ���781 351���ʡ�CTB�ı�ע����������Ӣ������ı�ע��ϵ��������33�ִ��Ա�Ǻ�19�ֶ�������ǡ�Ŀǰ��������������ľ䷨�����о�����CTBΪ�����Ͽ⡣Tsinghua Chinese TreeBank(TCT)���廪��ѧ�����ϵ���ܼ�����ϵͳ�����ص�ʵ������Ա�Ӻ���ƽ�����Ͽ�����ȡ��100���ֹ�ģ�������ı��������Զ��䷨�������˹�У�ԣ��γɸ������ı�ע�������ľ䷨�ṹ�������ľ䷨�������ϡ�Sinica TreeBank��̨������Ժ�ʿ�С�������Ժƽ�����Ͽ�(Sinica Corpus)�г�ȡ���ӣ����ɵ����Զ������ɾ䷨�ṹ�����������˹��ġ���������õijɹ���
1.2 �䷨����ģ����������
�䷨����ģ�����������Ǿ䷨�����о�����Ҫ���ݣ��������䷨����ģ�͵�ѡ����Ż������Ͽ�����ѧ�����ԺԾ䷨����ģ�͵�����ͨ�����ǻ���ijһ���Ͽ����[14]���䷽���ǣ������Ͽ���ѡȡһ���־��ӣ������Ͽ��ע�Ľ����䷨����ϵͳ��ע�Ľ�����жԱȡ��������Ͽ�ķ������ŵ������Ͽ�Ľ�������ͳһ�ı�ע��ϵ�½��У���ע�ľ��Ӿ��нϸߵ�һ���ԣ��ڴ˻����ϵ����۾��нϺõ�һ���ԡ������Ͽ��ģ�ϴ�����Խ��нϴ��ģ�����ۣ������۾��н�ǿ�Ŀ��ԺͿɱ��ԡ�
Ŀǰʹ�ñȽϹ㷺�ľ䷨�����������ⷽ����PARSEVAL ������ϵ[6-7]������һ�����ȱȽ����С���Ϊ��������۷�������Ҫָ����ȷ��(P)���ٻ���(R)������������(C)���ۺ�ָ��F���䶨�����¡�
��ȷ��P���������䷨����ϵͳ�����������гɷ�����ȷ�ɷֵı�����
�ٻ���R���������䷨����ϵͳ��������������ȷ�ɷ���ʵ�ʳɷ��еı�����
�ۺ�ָ��F��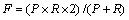 ��
��
����������C��������1���������������ijɷֱ߽罻��ijɷ���Ŀ��ƽ������
2 �䷨����ͳ��ģ�͵��о���״
��20����90 �������������������Դ�Ļ�ȡ������ף�����ͳ�Ƶķ�����ʼ����Ȼ���Դ��������Ϊ���������ַ�������ͳ��ѧ�Ĵ��������Ӵ��ģ���Ͽ��л�ȡ���Է�������Ҫ��֪ʶ�������˹���Ԥ�����ٶ�����ѧ�ҵ����������Ļ���˼���ǣ�(1) ʹ�����Ͽ���ΪΨһ����ϢԴ�����е�֪ʶ(����ͳ��ģ�͵Ĺ��췽��)���Ǵ����Ͽ��л�ã�(2) ����֪ʶ��ͳ�������ϱ����ͣ����в�������ͨ��ͳ�ƴ��������Ͽ����Զ���õ�[8]��
����ͳ�Ƶķ�������Ч�ʸߡ�³����ǿ���ŵ㣬������ʵ���Ѿ�֤���˸÷�������Խ�ԡ�Ŀǰ��ͳ�Ʒ����Ѿ����䷨�������о����ձ���á�Ϊ����ͳ�ƾ䷨����������Ҫ��ѭijһ���ϵ�����ݸ���ϵ���ȷ������ı�ʾ��ʽ��Ŀǰ���ھ䷨������ʹ�ñȽϹ㷺���ж���ṹ��������[9]��
2.1 ����ṹ�
��ǰ����ṹ�䷨�����ձ���ڸ������������ķ�(probabilistic context free grammar��PCFG)�����ģ�Ļ������������ķ�������(������������)�ij��ּ���شٽ�����һ������о���
2.1.1 ���ڴʻ㻯PCFG�ľ䷨����ģ��
�������о������У��������������ķ��Ķ���ṹ�䷨��������ֱ�Ӵ��˹���ע�������ж�ȡ�ķ����������Ƶ����Ϊ����ĸ���[10]�������ʵ�ּ����ǣ���ǰ���о������������ַ��������ܲ������롣����Ҫԭ���������������ķ��еĶ����Լ��裬����Щ�����Լ�����ʵ���������������������Ϊ��ͻ��PCFG�����еĶ����Լ����������ܶ��о���ת���о����ڴʻ㻯PCFG�ľ䷨����ģ�͡��ʻ㻯PCFGָ���ķ�����������ʻ����Ϣ�����ھ䷨����ÿ�����ս���ڵ��ϱ�ע�ʻ���Ϣ�����ôʻ���Ϣ�ſ����������ķ��Ķ����Լ��衣Magerman[11]���ȿ�չ�����������о���������֤�˴ʻ���Ϣ����Ч�ԡ�Charniak��[12-14]����ƽ�����һ������о���
2.1.2 ���ڸĽ�PCFG�ľ䷨����ģ��
Petrov��[14]���ʵ���˻�������ģ�͵ľ䷨������������ģ�ʹӾ䷨������Ӧ���ӵ����ϸ��ʳ��������ݺ����Ķ����Լ���ԴӾ䷨�������ӵ��������ɹ��̽��н�ģ����Ӣ��Penn�����ϵõ����ٻ��ʺ�ȷ�ʷֱ�Ϊ89.6%��89.8%�����ܸ��ڴ�������ڴʻ㻯PCFG�ľ䷨����ģ�͡�Finkel��[15]ָ����ͳ��PCFGģ���ڼ������ʽ����ʱ�����õ�������ģ�ͣ����õ���Ϣֻ���ڲ���ʽ��������Ϣ����û�з������������ӡ���ˣ���������ڼ������ʽ����ʱ����ȡ�б�ʽģ�ͣ����õ���Ϣ���������������ӵIJ���ʽ��Ϣ���ʻ�/���Ա�ע��Ϣ[13]����Ȼ�����б�ģ�͵ľ䷨�������о���ʷ��Խ϶̣����ǣ������б�ģ�͵ľ䷨�������Ѿ�������������ģ�͵ľ䷨�������ɱȽϵ�����[16-17]��
2.2 �����
�����������������ϵ�ľ䷨�����ܵ���Խ��Խ������ӡ�������ɷ�������ѧ��Tesniere���[4]�����������Ȼ�ʻ㻯�ģ�ֱ�Ӱ��մ���֮��������ϵ����������������дʻ�����汾��������ģ�����ͬ���Լ�������������ͨ�ģ���ˣ��������һ�ֿ�Խ���Խ��ޡ��۽�ʾ�����������ڹ��ɵľ䷨����[6]����ͬ�ڶ����ķ��������ķ�������Ϊÿ�������д���1��Ψһ�����Ĵʣ�֧���ž������������еĴʣ�������ֱ�ӻ������������Ĵʣ�ͬʱ�������г������Ĵ���ÿ���ʶ�ֻ��1����֧�䡣�����ķ�����ʹ������䷨����ʾ����������Ľṹû�з��ս�㣬�����֮��ֱ�ӷ��������ϵ������1������ԣ�����һ���Ǻ��Ĵʣ�Ҳ��֧��ʣ���һ�������δʣ�Ҳ�д����ʡ������ϵ��1������ʾ�������满��
Melchuk[17]��Ӣ�����������۽�����ȫ��ϵͳ���о���Eisner[18]���Ƚ�Penn Treebankת��Ϊ�����ʾ��ʽ��Ȼ���������䷨������ʵ�顣������ת��ʱ��Eisner[18]�ų��˰������ʵľ��ӣ�������ľ���ʹ�ù�������Զ�ת����ʵ���У�Eisner[18]ʹ������˵���ߵ�����ģ�ͣ��õ���90.0%������ȷ�ʡ�Yamada��[19]��Penn Treebank �еľ�����ȫת��Ϊ����ṹ��Ȼ��ʹ��ȷ���Եķ����㷨�����90.3%��ȷ�ʣ�ΪӢ��������������춨�˼�ʵ�Ļ�����
2.3 ��䷨�����������
����������Ե�һģ�͵ľ����ԣ���һ���о��ص��Ƕ���䷨����������ϡ����ַ��������ö���߾��ȵĻ��䷨�������������߸��ʽ��������Ϸḻ�䷨�ṹ���������ǽ��кϳɴ�����Ŀǰ���ϳɷ�ʽ��Ҫ�����������[20-21]�ͺ�ѡ��������[22]������������ǶԺ�ѡ���е������������飬�γ�һ���µ����ž䷨������ѡ���������ǶԺ�ѡ����ֵ�������¹��㣬ѡ����ֵ��ߵĺ�ѡ����Ϊ���ķ������������[22]��ʵ���в���5���߾��ȵľ䷨�������������������£��ٻ���Ϊ90.6%��ȷ��Ϊ91.3%����������Ϻ�ʵ�������£��ٻ���Ϊ91.0%��ȷ��Ϊ93.2%������[22]�����˺�ѡ����������Charniak[12]��Petrov��[14]����Ļ��䷨����������������2���䷨������ϵͳ�ֱ�������ŵ�50�������ʵ���F1Ϊ92.6%��
3 ���ľ䷨�����о���״
��Ӣ�ľ䷨������ȣ����ľ䷨�����о�������
�ڻ��ڷǴʻ㻯PCFG�ľ䷨����ģ�ͷ��棬��ӱ��[23]�������������㷨��������С��ģ���ı�����������ȡ�������ô��ģ�����÷ִʱ�ע�����Ͽ�Թ������ѵ��������Ժ�����ص�(�ر��Ǻ�����ʵ��ص�)������䷨�ṹ���ֵĸ���������PCFG�Ķ����Լ��衣ʵ��������������䷨�ṹ���ָ����ܹ���߾䷨��������ȷ�ʺ��ٻ��ʡ��ڻ��ڴʻ㻯PCFG�ľ䷨����ģ�ͷ��棬�ܺ���[1]�����Ĵ�����ģ��Ӧ���ڹ�������ҵ��ѧ���������о������⣬������ȷ�ִʣ��䷨����ȡ�õ��ٻ��ʺ�ȷ�ʷֱ�Ϊ80.9%��79.3%��������[24]�������Ĵ������ĺ���ͳ�ƾ䷨����ģ�ͣ��ڴ��Դ����ͻ������ʶ���ʶ���϶�Bikel����Collins���Ĵ��������ʾ䷨����ģ�ͽ����˸Ľ����ڻ��ڸĽ�PCFG�ľ䷨����ģ�ͷ��棬Petrov��[14]���Զ��������ص���������㷨Ӧ�����������⣬������ȷ�ִʣ���CTB5.0ȡ�õ��ٻ��ʺ�ȷ�ʷֱ�Ϊ85.7%��86.9%���ǵ�ʱ�ѱ���Ļ�����ȷ�ִʵĵ�ģ�����ľ䷨���������ֵ��
�ں��﷽�棬����䷨�����Ĺ����ڽ�������ʼ�ܵ����ӡ�Zhou[25]����������ⷽ����о���֮һ�������÷ֿ��˼�룬Ӧ��һЩ�ƶ���������ȶԾ��ӽ��зֿ鴦�����ҳ���ϵ�̶�����飬Ȼ����������ӽ������������Lai ��[26]ʹ�û��� span��˼���Լ�Gao ��[27]������ָ���ķ����ں��������������������о�����Ƽ��[28]�����һ��ȫ�µķֲ�ʽ����䷨�����������÷�����������Ȳ�����1���������Ϊ������λ���Ե����Ϲ������ӵ�����ṹ���ڲ��ڣ�ͨ��������õ��������ӽṹ���ڲ����֮�䣬����״̬ȷ���Ե�ת�ơ��������[29]������ѧϰӦ�õ���������䷨����������ѡ��䷨ģ��Ԥ�ⲻ��ʵ�������˹���ע��������Ƚ��˶��ֺ�������䷨ģ��Ԥ����Ŷȵ���
Ԭ���[6]������Ĵ������䷨����ģ�ͣ�����˻�����۽ṹ�����������ϵ�ľ䷨����ģ�͡�ģ���ڹ���ķֽ⼰���ʼ���������ḻ��������Ϣ���Ȱ�������������Ϣ,Ҳ������۽ṹ�����������Ϣ, ��CTB5.0ȡ�õ��ٻ��ʺ�ȷ�ʷֱ�Ϊ87.43%��88.76%������ʹ�õ�һ�ľ䷨����ģ���⣬Ҳ���о��߽�϶���ģ�͵�������������ѡ�����ŵľ䷨����Ϊ��������磬Zhang��[22]��Charniak[12]�䷨�����������ĺ�ѡ�䷨��Ϊ���룬ͨ��ϵͳ�ϳɵķ�������ѡ�����ŵľ䷨����Ϊ�����
4 ̽��
���������ͳ�ƾ䷨������Ϊ�ִ��䷨���������������������ڵķ�����ȣ����ڵľ䷨����������ǿ������ʵ�������л�ȡ�ķ�֪ʶ��ʹ��ѵ��������ģ���ӷ���ʵ�����������ٽ��˾䷨�������ܵ����[2]������ʴι�ģ����Penn Treebank �Ľ���������ƶ���Ӣ��䷨�������о���Penn Treebank �Ĺ�ģ��ע�����ߡ���Ϊ��Ҫ���ǣ����Ѿ���ΪӢ��䷨������ʵ�ϵı����������е��о����������ڸ�������У����ʹ���о��ߵ��о��ɹ����ԱȽϡ����Լ̳С��������������ص�[30]ʹ�����Ͽ��ڱ�ע��ϵ�ı�����ϵͳ���ͼӹ���ȵȷ���������ѣ�������Լ�������ͳ�ƾ䷨������һ���ܴ��ƿ����
Collins��������Ĵ������ľ䷨����ģ��[7]�ǵ�ǰ�䷨����������ģ�ͣ������˼����������������ķ�����������ʻ㻯��Ϣ�Ͷ�������Ĵ���Ϣ����2����Ϣ��������ǿ�˾䷨����ģ�͵�����������Ȼ�������ɱ���ش��������ص�����ϡ�����⡣���ڴ����ͳ������ģ���ǽ��ͳ��ģ������ϡ�����⣬��߾䷨����ϵͳ���ܵ���Ҫ�����������㷨�кܶ��֣����ɹ��Ϊ2�ֻ������ͣ���ξ�����Dz�ξ��ࡣ�Dz�ξ���ֻ�Ǽذ�����ÿ���������������֮��Ĺ�ϵ��ȷ������ξ����ÿһ���ڵ����丸�ڵ��1�����࣬Ҷ�ڵ��Ӧ���������ÿ�������Ķ������㷨��������������������(���������)����ͳ��ͳ�ƾ����ͨ������̰��ԭ�������ϵ���Ȼ�������������Ϊ�б��������ִ�ͳ��������Ҫȱ���Ǿ����ٶ�������ֵ�Խ��Ӱ���������ֲ����š�Ԭ���[31]���û���Ϣ�����˻����ڽӹ�ϵ�����������ϵ��2�ִ����ƶȶ��壬�ڴ����ƶȵĻ����������һ�����¶��ϵķֲ�����㷨���ϳɹ��ؽ�������Ĵ������䷨����ģ������ϡ������,���������˾䷨������ϵͳ���ܡ�
����ľ䷨����������һ���֪ʶ������֪ʶ���õĹ��̡�����������б�ʾ�������̺��ĸ���֪ʶ����ʹ��ͳ��ѧϰ�ķ�����ȡ��Щ���ӵIJ�ͬ��ε�֪ʶ��������Ӧ���ں���䷨��������һ���ȵ�����[30]�������������Ȼ���Դ�����һ���ؼ����⡣��ΪĿǰ���ȵ��о�����֮һ�������ɫ��ע(semantic role labeling, SRL)��dz���������(shallow semantic parsing)��һ�֣���ʵ�����ھ��Ӽ������dz�����������������ڸ������ӣ��Ծ��е�ÿ��ν�ʱ�ע��������Ӧ������ɷ֣���ȷ������Ӧ�������ǣ��������������ɫ(��ʩ���ߡ������ߵ�)���������ɫ(��ص㡢ʱ�䡢��ʽ��ԭ���)������ν�����IJ�ͬ,���Խ����е�SRL��Ϊ������ν��SRL��������ν��SRL���塣�����ɫ��ע�ѹ㷺Ӧ������Ϣ��ȡ���Զ��ʴ𡢻������롢��Ϣ�������Զ���ժ�������й�����ǰ����Ŀǰ������������ɫ��עϵͳ����ͳ��ѧϰ�ķ���������ͳ����Ȼ���Դ��������ķ�չ��һ���������Ÿ�����Ĺؼ������Ƕ����������ѧϰ���⡣��ͳ����Ȼ���Դ�������ͨ���ǰ�˳��һ����һ��ִ�еģ����磬һ���Ƚϵ��͵�������Ϣ��������ֱ��Ƿִʡ����Ա�ע��Ȼ�������ʶ�𡢾䷨�����������������Ϣ��ע�ȡ������䷨�����������ɫ��ע����ѧϰģ��(�ھ䷨�����Ĺ����У�����������Ϣ��ע��������ͬʱ����ע��������Ϣ�������ʽ�ĸ��ʼ���)��һ����������о�����
5 ����
(1) Ŀǰ�Ժ���䷨�������о�ͨ����������һ����С�������Ϲ�ģ�½��У�ͬʱ���ں��﷽�棬���⽨�蹤�����в�࣬��ȱ��ͳһ�������ע��ϵ����ȱ�ٴ��ģ����������,ȱ��һ����Ӣ��Penn Treebank�����ı����ϣ���ҲΪ���ֺ������ͳ�Ƶľ䷨�������������ܱȽϴ������ѡ�
(2) ͳ�ƾ䷨�������ٵ���һ����Ҫ��������η��ֺ����þ���ǿ������������������֪ʶ��ͬʱ��֤����֪ʶ��Ӧ�ò���ʹģ�͵IJ����������Ͷ��������ص�����ϡ�����⡣
(3) �䷨�ṹ�Ǿ䷨��ʽ���������ݵ�ͳһ�塣�Ծ䷨�ṹ����Ҫ������ʽ����������䷨��η������䷨��ϵ�����Լ����ͷ����ȣ�����Ҫ������������������Ծ䷨�ṹ���������Խȫ�桢Խ��̣���Խ�п��ܶԾ䷨��ʽ�ϵĸ���������п�ѧ�������Ľ��͡�
�ο����ף�
[1] �ܺ���. ���ڴʻ㻯ͳ��ģ�͵ĺ���䷨�����о�[D]. ������: ��������ҵ��ѧ�����ѧԺ, 2006: 15-83.
CAO Hailong. Research on Chinese syntactic parsing based on lexicalized statistical model[D]. Harbin: Harbin University of Technology. School of Computer Science and Technology, 2006: 64-83.
[2] ��ΰ��, �ܿ���, ��ά��. ����ͳ��ѧϰģ�͵ľ䷨������������[J]. ������Ϣѧ��, 2013, 27(3): 9-19.
WU Weicheng, ZHOU Junsheng, QU Weiguan. A survey of syntactic parsing based on statistical learning[J]. Journal of Chinese Information Processing, 2013, 27(3): 9-19.
[3] Ԭ���. ���������ϵ�ľ䷨����ͳ��ģ��[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2009, 40(6): 1630-1635.
YUAN Lichi. Statistical language paring model based on dependency[J]. Journal of Central South University(Science and Technology), 2009, 40(6): 1630-1635.
[4] �����. ���ľ䷨���������������ѧϰ�����о�[D]. ����: ���ݴ�ѧ�������ѧ�뼼��ѧԺ, 2010: 64-103.
LI Junhui. Research on joint syntactic and semantic parsing for Chinese[D]. Suzhou: Soochow University. School of Computer Science and Technology, 2010: 64-103.
[5] ��ң, ����, ������, ��. ����ͳ�Ƶľ䷨������������[J]. �������ѧ, 2003, 30(9): 54-58.
MENG Yao, LI Sheng, ZHAO Tijun, et al. The overview of statistical natural language parsing technology[J]. Computer Science, 2003, 30(9): 54-58.
[6] Ԭ���. ������۽ṹ�����������ϵ�ľ䷨����ͳ��ģ��[J]. ����ѧ��, 2013, 41(10): 2029-2034.
YUAN Lichi. A statistical parsing model based on valence Structure and semantic dependency[J]. Acta Electronica Sinica, 2013, 41(10): 2029-2034.
[7] Collins M. Head-driven statistical models for natural language parsing[J]. Computational Linguistics, 2003, 29(4): 589-637.
[8] ��ǿ. �������Ͽ������ͳ��ѧ����Ȼ���Դ�����������[J]. �������ѧ, 1995, 22(4): 36-40.
ZHOU Jiang. Corpus-based and statistics-oriented natural language processing techniques[J]. Computer Science, 1995, 22(4): 36-40.
[9] ����ɽ. ����ͳ�Ʒ����ĺ�������䷨�����о�[D]. ������:��������ҵ��ѧ�������ѧ�뼼��ѧԺ, 2007: 5-30.
MA Jinshan. Research on Chinese dependency parsing based on statistical methods[D]. Harbin: Harbin University of Technology. School of Computer Science and Technology, 2007: 5-30.
[10] Jurafsky D, Martin J H. Speech and language processing[M]. Upper Saddle River: Prentice Hall, 2009: 14-108.
[11] Magerman D M. Statistical decision-tree models for parsing[C]//Proceedings of the 33th Annual Meeting of the Association of Computational Linguistics. Boston, MA, 1995: 276-283.
[12] Charniak E. A maximum-entropy-inspired parser[C]// Proceedings of the First Conference of the North American Chapter of the Association for Computational Linguistics. Seattle, Washington, 2000: 132-139.
[13] Charniak E. Top-down nearly-context-sensitive parsing[C]// Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, MIT, Massachusetts, USA, 2010: 674-683.
[14] Petrov S, Barrett L, Thibaux R, et al. Learning accurate, compact, and interpretable tree annotation[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Sydney, Australia, 2006: 433-440.
[15] Finkel J, Kleeman A, Christopher D. Manning. efficient, feature-based,conditional random field parsing[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics. Columbus, Ohio, USA, 2008: 959-967.
[16] Carreras X, Collins M, Koo T. Dynamic programming, and the perceptron for efficient, feature-rich parsing[C]//Proceedings of the 12th Conference on Computational Natural Language Learning. Manchester, UK, 2008: 9-16.
[17] Melchuk I A. Dependency syntax: Theory and practice[M]. Albany: State University Press of New York, 1988: 20-76.
[18] Eisner J. Bilexical grammars and a cubic-time probabilistic parser. [C]//Proceedings of the Fifth International Workshop on Parsing Technologies. Boston, Mass, 1997: 54-65.
[19] Yamada H, Matsumoto Y. Statistical dependency analysis with support vector machines[C]//Proceedings of the 8th International Workshop on Parsing Technologies. Nancy, 2003: 195-206.
[20] Henderson H, Brill E. Exploiting diversity in natural language processing: Combining parsers[C]//Proceedings of the Joint Sigdat Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. College Park, MD, USA, 1999: 187-194.
[21] Sagae K, Lavie A. Parser combination by reparsing[C]// Proceedings of the Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. New York, 2006: 129-132.
[22] ZHANG Hui, ZHANG Min, Tan C L, et al. K-best combination of syntactic parsers[C]//Proceedings of the Joint Sigdat Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. Singapore, 2009: 1552-1560.
[23] ��ӱ, ʷ����, ����. һ�ֻ��ڸ������������ķ��ĺ���䷨����[J]. ������Ϣѧ��, 2006, 20(2): 1-7.
LIN Ying, SHI Xiaodong, GUO Feng. A Chinese parser based on probabilistic context free grammar[J]. Journal of Chinese Information Processing, 2006, 20(2): 1-7.
[24] ����, ������, �ܿ���, ��. ���Ĵ������ĺ���ͳ�ƾ䷨����ģ�͵ĸĽ�[J]. ������Ϣѧ��, 2008, 22(4): 3-9.
HE Liang, DAI Xinyu, ZHOU Junsheng, et al. Improvements on head-driven probabilistic parsing for Chinese[J]. Journal of Chinese Information Processing, 2008, 22(4): 3-9.
[25] Zhou M. A block-based dependency parser for unrestricted Chinese text[C]//Proceedings of the 2nd Chinese Language Processing Workshop. Hong Kong, 2000: 78-84.
[26] Lai T B Y, Huang C N, Zhou M, et al. Span-based statistical dependency parsing of Chinese[C]//Proceedings of the 6th Natural Language Processing Pacific Rim Symposium (NLPRS2001). Tokyo, Japan, 2001: 677-684.
[27] Gao G F, Suzuki H. Unsupervised learning of dependency structure for language modeling[C]//Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics. Sapporo, Japan, 2003: 521-528.
[28] ��Ƽ, �ڳ���. �������б�עģ�͵ķֲ�ʽ����䷨��������[J]. ������Ϣѧ��, 2010, 24(6): 14-22.
JIAN Ping, ZONG Chengqing. Layer based dependency parsing by sequence labeling models[J]. Journal of Chinese Information Processing, 2010, 24(6): 14-22.
[29] ������, ��÷ɽ, ��ͦ. ��������ѧϰ����������䷨����[J]. ������Ϣѧ��, 2012, 26(2): 18-22.
CHE Wanxiang, ZHANG Meishan, LIU Ting. Active learning for Chinese dependency parsing[J]. Journal of Chinese Information Processing, 2012, 26(2): 18-22.
[30] ������, �κ���, ��, ��. ����ͳ�Ƶľ䷨���������о�[J]. ��������������, 2006, 27(12):2207-2210.
WANG Jizeng, REN Haozheng, LUO Heng, et al. Research on method of syntax parsing based on statistical approach[J]. Computer Engineering and Design, 2006, 27(12): 2207-2210.
[31] Ԭ���. ���ڴʾ��������䷨����[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2011, 42(7): 2023-2027.
YUAN Lichi. Dependency language paring model based on Word Clustering[J]. Journal of Central South University(Natural Science), 2011, 42(7): 2023-2027.
(�༭ �²ӻ�)
�ո����ڣ�2013-05-25�������ڣ�2013-09-10
������Ŀ��������Ȼ��ѧ����������Ŀ(61262035)������ʡ��Ȼ��ѧ����������Ŀ(20142BAB207028��20122BAB201033)������ʡ�������Ƽ���Ŀ(GJJ14335��GJJ12742)
ͨ�����ߣ�Ԭ���(1973-)���У����������ˣ���ʿ�������ڣ�������Ȼ���Դ����о����绰��0791-83983891��E-mail��yuanlichi@sohu.com
ժҪ���䷨��������Ȼ���Դ�����һ���������⣬���Ŵ��ģ��ע����Ľ��������������ͳ�ƾ䷨������Ϊ�ִ��䷨�����������������ڽ��ܾ䷨�������⼰�䷨�����������ⷽ���Ļ�����,����Ҫ�䷨����ͳ��ģ�ͺ����ľ䷨�������о���״���м�Ҫ�����ͷ���,��̽�ֺ��ܽ��˻���ͳ�Ƶľ䷨����ģ�͵IJ���֮���ͷ�չ���ƣ�ָ�����еĺ���䷨�����������ʺϺ�����ص㣬û����Ч�̻�������ı�������,����Ŀǰ����䷨����������Ӣ��������ϴ�;��������Ϣ����䷨����,���ڴ˻����Ͻ����䷨�����������ɫ��ע����ѧϰͳ��ģ��,���Ǿ䷨������һ����Ҫ�о�����
[1] �ܺ���. ���ڴʻ㻯ͳ��ģ�͵ĺ���䷨�����о�[D]. ������: ��������ҵ��ѧ�����ѧԺ, 2006: 15-83.
[2] ��ΰ��, �ܿ���, ��ά��. ����ͳ��ѧϰģ�͵ľ䷨������������[J]. ������Ϣѧ��, 2013, 27(3): 9-19.
[3] Ԭ���. ���������ϵ�ľ䷨����ͳ��ģ��[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2009, 40(6): 1630-1635.
[4] �����. ���ľ䷨���������������ѧϰ�����о�[D]. ����: ���ݴ�ѧ�������ѧ�뼼��ѧԺ, 2010: 64-103.
[5] ��ң, ����, ������, ��. ����ͳ�Ƶľ䷨������������[J]. �������ѧ, 2003, 30(9): 54-58.
[6] Ԭ���. ������۽ṹ�����������ϵ�ľ䷨����ͳ��ģ��[J]. ����ѧ��, 2013, 41(10): 2029-2034.
[8] ��ǿ. �������Ͽ������ͳ��ѧ����Ȼ���Դ�����������[J]. �������ѧ, 1995, 22(4): 36-40.
[9] ����ɽ. ����ͳ�Ʒ����ĺ�������䷨�����о�[D]. ������:��������ҵ��ѧ�������ѧ�뼼��ѧԺ, 2007: 5-30.
[23] ��ӱ, ʷ����, ����. һ�ֻ��ڸ������������ķ��ĺ���䷨����[J]. ������Ϣѧ��, 2006, 20(2): 1-7.
[24] ����, ������, �ܿ���, ��. ���Ĵ������ĺ���ͳ�ƾ䷨����ģ�͵ĸĽ�[J]. ������Ϣѧ��, 2008, 22(4): 3-9.
[28] ��Ƽ, �ڳ���. �������б�עģ�͵ķֲ�ʽ����䷨��������[J]. ������Ϣѧ��, 2010, 24(6): 14-22.
[29] ������, ��÷ɽ, ��ͦ. ��������ѧϰ����������䷨����[J]. ������Ϣѧ��, 2012, 26(2): 18-22.
[30] ������, �κ���, ��, ��. ����ͳ�Ƶľ䷨���������о�[J]. ��������������, 2006, 27(12):2207-2210.
[31] Ԭ���. ���ڴʾ��������䷨����[J]. ���ϴ�ѧѧ��(��Ȼ��ѧ��), 2011, 42(7): 2023-2027.
