
һ����Խ���ʽѧϰϵͳ��־���ݵ����ͻ��ھ�
�� ̄����ӣ����ӹ�
(�㶫��ҵ��ѧ �Զ���ѧԺ���㶫 ���ݣ�510006)
ժ Ҫ��
��ʽѧϰϵͳ��������־���ݵ����ͻ��ھ����÷�����ѡ���Լ���ѧϰΪ��ܣ�����C4.5Ϊ�����������������ͻ���ͨ��������Ԥ�����Σ������µĻ���K��ֵ������ȡֵ��Լ�㷨�Բ���ȡֵˮƽ�ḻ��������Խ��й�Լ������ģ�ͼ��ɽΣ�����̰���㷨�Ի�������������ѡ��ʹ���ռ���ģ�͵õ�����Ⱦ�������2���ʩ�ڱ�֤ģ�;��нϺ�Ԥ����ֵ�ǰ���£�����Ƚ�����ѧϰ���ۣ�������ϵͳ����������Ϊ�˼��鷽������Ч�ԣ���ֱ��Դ�ڽ����������ʵ���ݡ���KDD Cup 2010��ս���ݼ����м��顣����������÷�������ʵ���ڵ���PC��(CPU��
�ؼ��ʣ�
�������Ǿ�������������ֵ��Լ�����ݼ���������ѧϰ��
��ͼ����ţ�TP181 ���ױ�־�룺A ���±�ţ�1672-7207(2011)S1-0755-05
A lightweight solution to educational log data mining
LIU Kun, XING Yan, CAI Yan-guang
(Faculty of Automation, Guangdong University of Technology, Guangzhou 510006, China)
Abstract: A lightweight framework was presented for educational data mining based on selective ensemble, using C4.5 as the basic learning algorithm. The solution introduces a novel algorithm, based on K-mean, to aggregate the categorical attributes having too much value levels. Finally, some experimental results and discussions are provided to validate the proposed approach, using the challenge data set of educational KDD Cup 2010. The results show that the approach has an efficient model training ability and good model generalization even if the algorithm is applied to a single-core PC with a
Key words: classification; imbalanced data; attribute value aggregation; data reduction; ensemble
�������������������ھ�������ʼӦ����ʵ�������磬ͨ���ھ�����ʽѧϰϵͳ��ѧ����ϵͳ��������������־�����������ѧϰ��֪ʶ��������Ȼ��������Щ��Ϣ������ѧ����ѧϰ��������ȣ��ﵽ���ʩ�̵�Ŀ��[1]��������Ч�ھ��ⷽ�����Ϣ���������ѧ����ѧϰЧ��ʮ������[2]��Ԥ��ѧ����ѧϰ��������Ҫ��Ԥ��ѧ����ѧϰ�������ܷ���Ӧ�µ�ѧϰ������ij��ѧ���ܹ���ȷ���-18+x=15�� Ԥ�����ܷ����5+x=-39������������������ھ���ȣ������������־������2�������ص㣺��һ�����ݹ�ģ������ǧ������¼��ͬʱ��������Ե�ȡֵˮƽҲ�dz��ḻ���������������ȡֵ����ܶࣻ��������ݱ�ǩ�������������ַǾ��⣬������ij�����⣬��������ı���ͨ���Dz��Եȵġ����ݵ���2���ص������2�����⣺���ݹ�ģ����ζ��ѵ�����۱Ƚϴ��������ȡֵ������ڷḻ����������ѵ������������������������ͬʱ��������˹����ϸ֦ĩҶ��Ϣ��������ģ�����(Overfitting)����ʹģ�ͷ��������������ݷǾ���ͨ���ᵼ�·���ģ�͵�Ԥ�⾫���½�����ˣ��ܷ�ɹ��ھ�������ݣ�ȡ����Ԥ�������㷨��ƹ������ܷ���������2�����⡣�ⷽ����о��Ѿ���һЩ�ɹ������磬Cen��[2]ͨ�����ع齨����֪ģ����Ԥ��ѧ����ѧϰ������Thai-Nghe��[3]�Ƚ��˾������뱴Ҷ˹�����ڽ��������ϵı��֡����⣬����Thai-Nghe��[4]����֧���������Խ����������ݷǾ���(Imbalanced classification)��������˳��ԡ�����δ�������������2������ͬʱ���иĽ����о��ɹ����������һ��˫�����¡��������ͼܹ��Ľ������������ھ����÷����Լ���ѧϰΪ��ܣ�C4.5Ϊ������������ͨ��������Ԥ�����Σ��������K��ֵ������ȡֵ��Լ�㷨�Բ���ȡֵˮƽ�ḻ��������Խ���ȡֵ��Լ������ģ�ͼ��ɽβ���̰���㷨�Ի�������������ѡ��ʹ���ռ���ģ�;�������2���ʩ�ڱ�֤ģ�;��нϺõ�Ԥ����ֵ�ǰ���£�����Ƚ�����ѵ�����ۣ�������ϵͳ��Ԥ�����ܡ�Ϊ�˼���ģ�͵���Ч�ԣ�ֱ�Ӳ���Դ��KDD Cup 2010 (URL��https://pslcdatashop.web. cmu.edu/KDDCup)�����ݡ�KDD Cup ����SIGKDD(ACM Special Interest Group on Knowledge Discovery and Data Mining) ��֯�������ھ���֪ʶ������ս����ÿ��ٰ�һ�Σ���SIGKDD ���ʻ���ͬ�ھ��У�ͬʱ����ѧ������ҵ�硣
1 ����
��������������ھ���Ե��ǽ���ʽѧϰϵͳ��־���ݡ���ֱ��Դ��ϵͳ����¼����ѧ������ѧϰ����⼸����������е�ÿ������ϸ�ڡ�KDD Cup 2010 ���ݵ���ʽ��ͼ1��ʾ��Ϊ�˱���˵�����⣬����ʡ���˲������ԡ���Щ������־���ݰ������¼����ؼ�������⡢���衢֪ʶ�㡢��������ͨ��ѧ�����һ��������Ҫ���ɲ��裬ÿ�������Ӧ1�����������֪ʶ�㡣���⣬��������������ͬһ֪ʶ����ܻᱻ����ʹ�ã�����������¼����ij��֪ʶ���������������б�ʹ�õĴ��������ݱ��е�ǰ������ѧϰ�����е������йأ���ͼ���Ѿ�Ȧ�������һ��Ϊ��ǩ���ԣ����ĺ�����ѧ�����ijһ����ʱ�����γ��Եı���(�������ˣ�����������)����ս����������������Ѵ��ϱ�ǩ��ѵ������ѵ���������ѧϰ����������ģ����Ԥ��ѧ��Ӧ��������ı��֡�
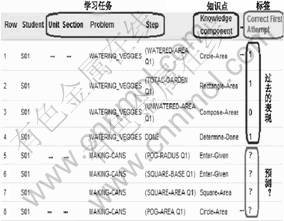
ͼ1 KDD Cup 2010������ʽ
Fig.1 Data format of KDD Cup 2010
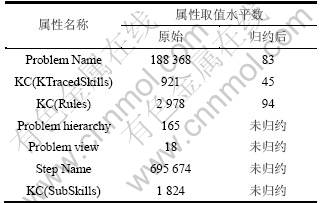
���KDD Cup ����������Դ����ʵ���������һ�����������������п�ȱ��ȡֵ��һ�¡����У����ԡ�KC(KTracedSkills) ����50.4%��ȡֵΪ�գ���Щ���Ե�ȡֵ��Сд��һ�¡�����֮�⣬����������4�����ԣ�(1) ���ݹ�ģ����ս���ݰ��н�С���Ǹ��ͺ�8 918 054����¼(���������õ�)�����ڷ����������ݵĺ����ܱȲ���Ҫ�úܶࡣ�����ݹ��ھ��ò������㷨��ʱ�䡢�ռ��ϵ��������ѷ��ļ�����Դ֮���ì�ܡ� (2) ����������Ե�ȡֵˮƽ���ڷḻ���������ȡֵˮƽ��ָ����������ȡֵ�в�ͬȡֵ��������������ֵ�ϵ��ڸ�������ȡֵ����ɼ��ϵ�Ԫ�ظ������ӱ�1���Կ��������ԡ�Problem Name��, ��Step Name��ȡֵˮƽ������10����ֱ��ʹ����Щ���Խ���ѧϰ�������������3�����⣺��һ������ѡ���������㷨��ѵ�����п��ܱ�ȡֵˮƽ���ڷḻ�����Զ�����(dominate)����ʹ�������Ե�Ч�ñ����ԡ���������ڷḻ������ȡֵ��ζ�Ŵ��������ϸ����Ϣ����������ģ����ϡ���Ϊ��ѵ�����г��ֵ�ϸ����Ϣ���ڲ��Լ���δ�س��֡�����������Ҳͨ����������Щϸ����Ϣ�(3) ���ݳ��ַǾ������ԡ����ݷǾ�����ָ���ݼ��в�ͬ���������Ŀ��ռ�������ز��ȡ����ڵڶ��������⣬��������һ���������Զ������һ��ġ���ͳ����ѧϰͨ��������֮���Ǿ���Ļ���ƾ���ģ��������������ྫ��ΪĿ�꣬�����㷨ֻ������߶�����(��������ռ�������Ƶ���һ��)�ķ��ྫ�ȣ��������������������Ԥ�⾫�ȡ�(4) ���Լ����ǿ��ع�ϵ�����Լ�����ϵ���������2��ʾ����ͳ�㷨�ٶ�Ԥ������(����ǩ��������)����������ģ������ر�Ҷ˹��������Խ���Щ����ֱ��Ӧ����ģ��ѵ����
��1 ������Լ���ȡֵˮƽ��
Table 1 Categorical attributes and their value levels
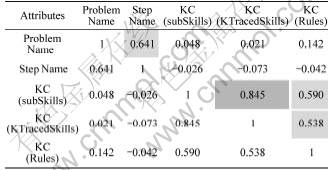
��2 ��������Է������
Table 2 Correlation matrix of massive categorical
2 ����ֵ��Լ
ǰ���Ѿ��ᵽ�����ڷḻ������ȡֵˮƽ����ʹѧϰ��������ͬʱ����ģ����ϡ���ˣ��б�Ҫ�Թ��ڷḻ������ȡֵˮƽ���й�Լ������ȡֵ��Լ��ʹ�ýϸߵĸ���ˮƽ�����������ͬ�������ȡֵ�滻Ϊһ���µ�ȡֵ��
2.1 ��Լ���Ե�ѡ��
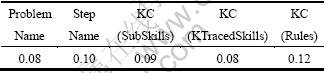
�ھ�����ھ���Ŀ�У��������ֵ���й�Լ�������ף���������ȱ���������ר��ָ��������¡������2��������⣺��һ��ѡ����Щ������Խ��й�Լ�������ÿ��������Ծ����Լ���ĸ�����ˮƽ�ȽϺ��ʡ�����ȱ������ר�ң�������Ϣ�����ʶԼ���ȡֵ�dz��ḻ��������Խ��к����������������Ϣ������ֵ���3���С��ӱ�3���Կ���������ȡֵ�ḻ�������������Ϣ������������Ҳ���ǣ��⼸�����Եķ���ײ�ࡣ��ˣ�������Ϣ�����ʷ��滹������Щ������Խ���ѡ�����ǣ���������Է�������һ��̽����Щ���Լ���ܴ��ڵĹ�ϵ���������2���С���ط�����������Problem Name���롰Step Name������KC(SubSkills)�� �롰KC (KTracedSkills)���ֱ����ǿ�����(һ����Ϊ���ϵ���Ѵ���0.6��Ϊǿ���)��2������ǿ���˵������Ϣ�ϴ���һ���ص�����ˣ��ڹ���ѵ�����������Ӽ�ʱ����ѡ������һ����Ϊ���ߵĴ��������������Է�����֪��һ�����⺬�ж�����裬ͬʱһ����֪ʶ������ڸ�֪ʶ���С���������ڡ�Problem Name���롰Step Name����ѡȡǰ����Ϊ������ ��Ϊǰ�߰����˺��ߣ��ڡ�KC(SubSkills) ���롰KC(KTracedSkills)����ѡȡ������Ϊ����������ͬ�ϡ����ѡ����Problem Name������KC(KTracedSkills)�� �롰KC(Rules)��3��ȡֵˮƽ�dz��ḻ��������Խ�������ȡֵ��Լ��
��3 ������Ϣ������
Table 3 Information gain ratio of massive attributes
2.2 ����ֵ��Լ�㷨
������Լ�����Լ�ѡ����ÿ�����ԵĹ�Լ���ձ�4��ʾ�㷨���С����㷨���ھ���ľ����㷨K-��ֵ���㷨��2���е�Kֵ����K��ֵ�еľ��������Ǵ�����ֵ��Լ�㷨�Ĺؼ�������ͨ�����ʵ�鲢ͨ���˹�������������ȷ���ġ�һ�ֺõľ�������ζ���ڳ�ʶ����ͬ���͵ĸ����Ϊͬһ�ࡣ���磬�������ԡ�Problem Name����Ĵ�������ʽ-18+x=15��5+x=-39 Ӧ����Ϊһ�ࡣ
��4 ����ֵ��Լ�㷨
Table 4 Algorithm of attribute-value-aggregation

�������ֵ�г��ȹ������ַ����ᵼ�¼������������ӣ���˲���ֱ��Ӧ���������㷨��KDD Cup 2010 �����оͺ���һЩ�ر����������硰KC(KTracedSkills)���롰KC(Rules)������ֵ���ַ����dz�����һЩ���ȳ�����8 000���ַ������ھ���ľ����㷨�������������ݶ����DZȽ����ѵģ�����ѵ���ٶȻ����Ա���������Ч��Ҳ�����ˣ��б�Ҫ����һ���������Ƚ���һ���ı��ھ�����Ƶ����ߵ�N���ؼ�����ȡ������N���ݾ����������������ȡN��1����һ���̻ᶪʧһ������Ϣ�������ڽ��ͼ��㸴�Ӷ�ȴ�Ƿdz�����ġ��������������������Ҳ�ǿ�ȡ�ġ�
�ӱ�1��֪�������˴���������ȡֵ������ԭ����������ƽ��͵������ڣ����ʵ�����������ھ�ܹ������ͻ��������塣�ýϸ߲�εĸ������Ͳ�εĸ�����ڷ������������ȼ�����һ�µġ�
3 ģ��ѵ�����
����ѧϰ������ģ��Ԥ�⾫�ȵ�һ����Ч���ԡ�ʵ���������ģ���еĻ�������������ڽ������IJ��ʱ������ģ�ͽ��п��ܵõ����õ�Ԥ�⾫�Ⱥ��ѵķ�������[5-6]�������������������������Ƚ����У���ˣ���ʹѵ������ģ�ͼ���ڲ��죬ֻ�����ʹѵ�����������һ�����켴�ɡ�����ѧϰ����Ӧ�����ݺ�����ģ����Ч�ֶΡ���ͨ�����������ݷ�Ϊ��ݣ�ʹÿ�����ݵĹ�ģ������ʵ�ʼ�����Դ�����ķ�Χ�ڡ����⣬����ѧϰ�������ݷǾ�������Ҳ��һ���ĸ�������[7]����ˣ�����KDD Cup ���������ѡ�ü���ѧϰ��Ϊ����Ǻܺ��ʵģ��ⲻ����ЧӦ���˺������ݹ�ģ������һ���̶���Ӧ�������ݵķǾ��� ���ԡ�
����ѧϰ�����Ϊ2�࣬��Bagging ��Boosting���������Bagging �㷨����Ϊ����ԱȽϼ�����ѵ�����̿��Բ��л����������ڼ�����Դ���������£������ν��л�����������ѵ����ѵ��������ͼ2��ʾ��
�����Bagging��ѧϰ�У���������õ���Bootstrap������һ���зŻ�ȫ��������������ģ��ԭ���ݹ�ģ��ȡ����ڴ˷����ݵĹ�ģ����ֱ�Ӳ���Bootstrap����������Ȼ�в�ͨ����ˣ����ǶԼ��ɿ���еij�������������ơ�����Ƶij����������г������ݾ����������������Ե�ԭ��ʹ�������������ʶȲ��컯�����������5��������������ƣ���һ�����ǵ������ļ�������������ֻ��ȡ50��������ÿ�������Ĺ�ģΪ100 000�������ÿ�������б�ǩ������������ԭ������ͬ������85:15����������ȡÿ�������У�ÿ��ѧ�����ٰ���һ�����⡣���ģ����ò��Żء����������ʽ�����壬��ʣ��������������ȡ15��������ÿ�ݳ�����Ϊ100 000����ΪУ�����ݼ���
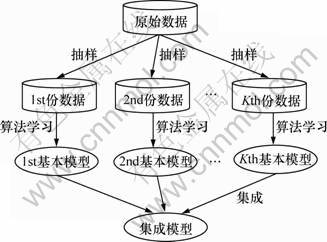
ͼ2 ����ѧϰ���
Fig.2 Idea of ensemble learning
Ϊ�˷�ֹѧϰ����ϣ���ÿ�����ݵ�ѵ��������10��ģ�Ľ�����֤������������������ѵ���ú�����ģ�ͼ��ɽΡ�������꼯��ѧϰ������о��������ڼ���ǰ�Ի�������������ѡ���п����ھ���ģ�͵�ͬʱ��ø��ѵ�Ч��[8]��Ϊ�˽�һ��ʵ��ѧϰ��ܵ����ͻ�����ѵ�����õ�50����������������ѡ�����յõ�13���������������Լ�ͶƱ�������Ϊһ������ѧϰģ�͡���������ѡ����̰���㷨����̽��ɾ������ɡ��ù��̴�50����������ɵļ��Ͽ�ʼ��ÿһ�����ɾ�������е�1��Ԫ��(��һ��������)��Ȼ�����ʣ���Ӽ���ɵ�ģ�����ܣ����������û�������½�����˵��ɾ���ɹ�����֮����˵���˷�������Ӧɾ�����㷨α�������5��ʾ���������õļ���ѧϰģ�͵ı��֣����Ծ��������(Root Mean Square Error)�������ġ����������(RMSE)�����ں���ģ��Ԥ��ֵ����ʵֵ֮��IJ���̶ȡ�����㹫ʽ���£�����ٶ���ʵ��ǩ������Ϊ��1��Ԥ���ǩ����Ϊ��2�����Ц�1=(a11��a12������a1n)����2=(a21��a22������a2n)����
![]()
��5 ����������ѡ���㷨
Table 5 Algorithm for base classifiers selection

��ģ�����յ�Ԥ����֣����ڱ�6�С����Դ��KDD Cup 2010�ٷ���վ���ṩ������ϵͳ����1�������Ƿ����Ľ������2������ս����һ���ijɼ����Աȶ��߿�֪�������������Խ���ʽѧϰϵͳ��־���ݵ����ͻ��ھ�����ֻ��ʧԼ0.06 RMSE�Ĵ��ۻ����˼�����Դ����ľ����ơ�
��6 ����ģ�ͱ���
Table 6 Prediction performance of solution

4 ����
���һ���ͻ������ӽ�������ʽѧϰϵͳ��־�������ھ��м�ֵ����Ϣ����ͨ��������Ԥ�����ζ�����ȡֵˮƽ���ڷḻ�����Խ��и�����Լ�����ڼ���ѧϰ���������������ѡ����ƣ��Ӷ��ý��ٵļ�����Դ�ﵽ�Ϻõ��ھ�Ч�����÷������к�ǿ����������ɲ����ԡ����磬��������Թ�Լ�����е�Ŀ������ѡ��Լʱ��Ծ�������Ӧ��Լ���ĸ������εȷ��棬���������������ר�ң������ø��ѵ�Ч�������⣬��ѵ������������ʱ���ɸ���ʵ�ʼ�����Դ�Է������ĸ������е���������Դ������ǰ���£������ܶ��ѵ��һЩ���������������������ѡ���������У����ں���������ѡ�����������ġ�
�ο����ף�
[1] Feng M, Heffernan N, Koedinger K. Addressing the assessment challenge with an online system that tutors as it assesses[J]. User Modeling and User-Adapted Interaction, 2009, 19(3): 243-266.
[2] Cen H, Koedinger K, Junker B. Learning factors analysis��A general method for cognitive model evaluation and improvement[C]//Intelligent Tutoring Systems. Berlin, Heidelberg: Springer, 2006, 4053: 164-175.
[3] Thai-Nghe N, Busche A, Schmidt-Thieme L. Improving academic performance prediction by dealing with class imbalance[C]//Proceeding of 9th IEEE International Conference on Intelligent Systems Design and Applications (ISDA��09). Pisa: IEEE Computer Society, 2009: 878-883.
[4] Thai-Nghe N, Janecek P, Haddawy P. A comparative analysis of techniques for predicting academic performance[C]//Proceeding of 37th IEEE Frontiers in Education Conference (FIE��07). Milwaukee: IEEE Xplore, 2007: T
[5] Kuncheva L, Whitaker C. Measures of diversity in classifier ensembles[J]. Machine Learning, 2003, 51: 181-207.
[6] Sollich P, Krogh A. Learning with ensembles: How overfittingcan be useful[J]. Advances in Neural Information Processing Systems, 1996, 8: 190-196.
[7] Chen J J, Tsai C A, Young J F, et al. Classification ensembles for unbalanced class sizes in predictive toxicology[J]. SAR and QSAR in Environmental Research, 2005, 6: 517-529.
[8] ZHOU Zhi-hua, WU Jian-xin, TANG Wei. Ensembling neural networks��Many could be better than all[J]. Artificial Intelligence, 2002, 137(1/2): 239-263.
(�༭ �)
�ո����ڣ�2011-04-15�������ڣ�2011-06-15
������Ŀ��������Ȼ��ѧ����������Ŀ(61074147��60374062)���й�-�������Ƽ������о�����������Ŀ
ͨ�����ߣ����(1983-)���У����������ˣ�˶ʿ�о��������»���ѧϰ�������ھ��о����绰��15899961637��E-mail��kunliu0213@163.com
ժҪ�����һ����Խ���ʽѧϰϵͳ��������־���ݵ����ͻ��ھ����÷�����ѡ���Լ���ѧϰΪ��ܣ�����C4.5Ϊ�����������������ͻ���ͨ��������Ԥ�����Σ������µĻ���K��ֵ������ȡֵ��Լ�㷨�Բ���ȡֵˮƽ�ḻ��������Խ��й�Լ������ģ�ͼ��ɽΣ�����̰���㷨�Ի�������������ѡ��ʹ���ռ���ģ�͵õ�����Ⱦ�������2���ʩ�ڱ�֤ģ�;��нϺ�Ԥ����ֵ�ǰ���£�����Ƚ�����ѧϰ���ۣ�������ϵͳ����������Ϊ�˼��鷽������Ч�ԣ���ֱ��Դ�ڽ����������ʵ���ݡ���KDD Cup 2010��ս���ݼ����м��顣����������÷�������ʵ���ڵ���PC��(CPU��
