
DOI: 10.11817/j.issn.1672-7207.2018.10.016
��������ҵ��Ľ���ؿ��ӻ�ϵͳ�����ʵ��
�����У��ι�̷ݶ��������
(���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083)
ժ Ҫ��
�����칹����ϵͳ�����ĺ���������־�ṹ���ӡ���ȡ���ѡ�����Ч�ʵ��Լ����ܼ�ʱ���ֽ����쳣�����⣬�����ʵ��һ����������ҵ��Ľ���ʵʱ���ϵͳ�����ṩ�������ݵĿ��ӻ����������ȣ�ϵͳ�Խ�����־�йؼ�����ָ����вɼ����ṹ���洢��Ȼ��ͨ������ѧϰ�����Խ���������ʵʱԤ�⣬�ṩ�������쳣�澯�����ͨ�����ӻ���ʽ���칹����ϵͳʵʱ��أ����Խ��������ṩ��ǶȵĿ��ӻ��������о������������ϵͳ�������ۡ��������á��������죬�ܺܺõ��������й�����Ա��ҵ���������
�ؼ��ʣ�
������־��ʵʱ�����������Ԥ�������ӻ�������
��ͼ����ţ�TP393 ���ױ�־�룺A ���±�ţ�1672-7207(2018)10-2490-08
Design and implementation of transaction monitoring visualization system oriented to banking business
REN Linan, DUAN Guihua, TAN Di, WANG Jianxin
(School of Information Science amp;Engineering, Central South University,Changsha 410083,China)
Abstract: Due to the complex structure, difficulty of extraction, low efficiency of analysis and the failure of timely detection of transaction abnormalities caused by the growing heterogeneous bank transaction system, a real-time transaction monitoring system for banking business that provides the visual analysis of transaction data was designed and realized. Firstly, the system collected the key common indicators from the transaction log and stored them in a structured way, and then predicted the volume of transactions through machine learning and provided alerts of abnormal volume, and finally heterogeneous trading systems were monitored in real time through visualization and multi-perspective visual analysis of transaction data were provided. The system has a beautiful interface, good interaction and excellent performance, which can well meet the analyst's needs of banking analysis.
Key words: transaction log; real-time monitoring; trading volume forecasting; visual analysis
������������ҵѸ�ٷ�չ�����и���ҵ���ѳ�Ϊ�����������Ҫ��ɲ��֡��û������еĽ������У������˴����Ľ�����־�������û���Ϣ��ҵ����Ϣ�Ƚ��������Ϣ����βɼ����洢����غͿ��ӻ����ཻ�����ݳ�Ϊ�˸������з�����Ա��ע�Ľ���֮һ��һЩ�о���Ա�������ص���־���ݲɼ����洢����ӻ��������������־��Ϣ���ݲɼ��ͷ�����Ч�ʡ�CHAMARTHI��[1]ʵ����splunk�ڵ��Ų��ŵ�Ӧ�ã�splunkʵʱ�ɼ��ʹ洢��ͬ�ڵ����־���ݣ��ṩ����ʽ�����Ϳ��ӻ��������ҳ��ƶ��������е��쳣�绰������û���BIRJALI��[2]����˻���Apache Flume���罻�����вɼ��罻ý�����ݵķ���������Ԥ���������ݴ洢��Hadoop�У����ʹ��InfoSphere BigInsights�Ը����ݽ��з����Ϳ��ӻ���BAI[3]���Flume�����һ��ʵʱ�Ĵ����������������÷�������ʹ��Flume�������ն��ռ���־��Ȼ��ͨ��ElasticSearch������������rowkey�б������Hbase����rowkeyֱ�Ӵ����ݿ��л�ȡ���ݡ��÷����ڴ�������־�����о��нϺõĿ����ԡ�SANJAPPA��[4]������һ��ʹ��Logstash�����ռ���־��ϵͳ����ϵͳ�ܹ������������͵���־���ݣ�����ʶ�������еĶ�����BAJER[5]����˻���ELK(Elastisearch��Logstash��Kibana)�Ŀ�Դ�����������������е�Ӧ�÷���������ȡ�Ϳ��ӻ��йؽ�����Ӫ��������ļ��⡣���н�����־��Դ�ڴ������칹����ϵͳ��Ϊ�˿�ʵʱ��ظ�����ϵͳ�Ĺؼ�ָ�꣬��Ҫ�����ɽ�����ϵͳ�����Խṹ��ͼ���Դﵽ������Ա���ٶ�λ��ij�쳣ָ����������ϵͳ��Ŀ�ģ��Ӷ���һ���ٺͷ����쳣ԭ������⡣SHAHZAD��[6]���ܺͱȽ���HTML5��jQuery��D3.js��GOJS��JSmol��Highchart��Bootstrap�Ȼ���Web�Ĺ��ߺͿ⣬���ڻ���������Ľ���ʽ���ӻ���BOONNAVASIN��[7]���GOJS�������˹����ɽ�����ϵͼ��������Ϊ��ҽ���˽ⲡ�˼�ͥ��Ϣ����Ҫ��Ϲ��ߣ����ṩ����Ч�Ĵ洢�ͼ���������ͬʱ�����н������ݾ��к�ǿ��ʱ������ԣ����ڵ��͵�ʱ�����ݣ�Ŀǰ�������н�������ʱ�����ݵ�Ԥ�ⷽ���ѱȽϳ��첢�㷺Ӧ���ڸ��� ��[8]���������������е���־�ɼ����洢�Ϳ��ӻ������������������splunk��Flume��ELK��������Ȼsplunk�����˴����ḻ�����ݲɼ��Ϳ��ӻ����ߣ�����ʹ�óɱ��ϸߣ������ٶȽ����Ҽ۸�ELKջʹ�ú�ά���ɱ��ϵͣ����㷺Ӧ������־���ݵIJɼ��ʹ洢Ӧ���У�����Logstash���������������ȶ���ȱ�㣬��Ҫ��һ���Ľ��������о��Ŀ��ӻ����������ͳ�Ʒ�����������ȱ�������ԡ�����Χ����������չ���о���������Ʋ�ʵ������������ҵ��Ľ����ϵͳ������Kafka[9]��Logstash[10]��Elasticsearch[11-12]��Spark Streaming[13]�ȼ���ʵ�ֽ�����־�IJɼ��ʹ洢��ͨ������ѧϰ�����Խ���������Ԥ�Ⲣ�ṩ�澯����ɿɽ����ļ�غͿ��ӻ���������ϵͳ��Ҫ�������£�1) �������п�Դ��־�ɼ����ṹ���洢�Ϳ��ӻ���������������˲ɼ����̺��������������̵��Ż�������2) ����˽�����Ԥ�ⷽ�����ܹ��ڼ�ع�������Ч�ṩ�쳣�澯��3) �ṩ��ҵ����ࡢ�������ߡ����ݶԱȷ��������彻����Ϣ��λ�ͽ�����ϸ�ȷḻ�Ŀ��ӻ���������߷���Ч�ʣ�4) ����˷ḻ�Ľ�����������������ϵͳ������ṹͼ�Ĵ��������(��������ش��ڣ���߽���ʵʱ��ص��û�����)��ʱ����ơ�����ָ��ѡ���ײ�ѯ�ȡ�
1 ϵͳ���
1.1 ��������
���ĵ�����������Դ��ij��������������EIX(enterprise information exchange server����ҵ��Ϣ����������)������ǰ�úͷ�˰ǰ��4������ϵͳ����־���ݡ�ԭʼ���ݰ����û���Ϣ�ͽ�����Ϣ�����ϵͳ�ķ���Ŀ���Լ��û���˽������ֻ��ȡ�����еĽ�����Ϣ���������ݽ�����Ԥ������Ԥ����������ݹ���1 981.3��������¼��ʱ����Ϊ5�¡�
������Ϣ��Ҫ���������š�����ʱ�䡢����ϵͳ��ҵ����롢ҵ����������������������������Ӧ��(�ɹ��롢ʧ����)����Ӧ��������������ʱ�ȣ����������Щ������Ϣ���������˿��ӻ�������
1.2 �������
���IJ���B/S�ܹ���ƣ���Ҫͨ���ɼ�����칹����ϵͳ����־����ȡ�ؼ�ָ��ṹ���洢��ʵ���˽���ϵͳ����뽻�����ݿ��ӻ������ȹ��ܡ�ϵͳ���ܽṹ������ϵͳ���ϼ��ģ�顢��ϵͳ�������ӻ�����ģ�顢�¼��б�ģ�顢ͳ�Ʊ���ģ�顢������ģ���ϵͳ����ģ�飬��ͼ1��ʾ��
1) ��ϵͳ���ϼ��ģ�������ϵͳ�����Խṹͼ������ģ�顢�ཻ��ϵͳʵʱ�����澯��ģ���Լ�ϵͳ�佻�����ݶԱȷ�����ģ��3�����֡�
�� ��ϵͳ�����Խṹͼ������ģ��ɸ����û����й�����ϵͳ�������˽ṹͼ��ʵʱ�����Զ���ļ�������档
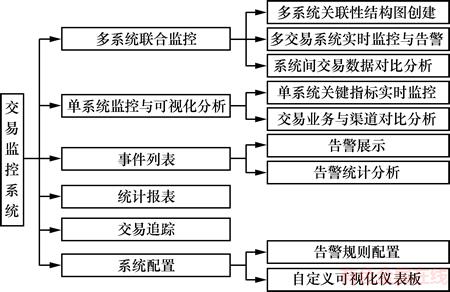
ͼ1 �����ϵͳ����ģ��ṹ
Fig. 1 Diagram of transaction monitoring system function module structure
�� �ཻ��ϵͳʵʱ�����澯��ģ��Ĺ�������ʾ��λʱ���ڵ�ϵͳ���ơ���������ҵ��ɹ��ʡ������ɹ��ʺ�ƽ��������ʱ�Ƚ���ָ����Ϣ�����ݷ���������������ʵʱ���ָ��ˢ�£������쳣���ݺͷ����������ж����쳣��ǣ�ͬʱ�������Ա���澯��Ϣ��
�� ϵͳ�佻�����ݶԱȷ�����ģ���ͨ��ͼ���ȿ��ӻ���ʽ��ʾ�������ϵͳ��Ľ�������������ʱ�����׳ɹ���3��ָ��ĶԱȽ�������ṩֱ�۷���������
2) ��ϵͳ�������ӻ�����ģ�������ϵͳ�ؼ�ָ��ʵʱ��ء�����ҵ���������Աȷ���2�����ܡ�
�� ��ϵͳ�ؼ�ָ��ʵʱ��ع����ǶԵ�������ϵͳ�Ľ�������������ʱ�����׳ɹ�����3��ָ����п��ӻ�չʾ����������ʵʱˢ���Դﵽʵʱ���Ч����
�� ����ҵ���������Աȷ����������Կ��ӻ��ķ�ʽչʾ����ҵ�������ָ���ڽ����еķֲ����죬���ڷ�����Ա�������⡣
3) �¼��б�ģ������澯չʾ�澯ͳ�Ʒ���2�����ܡ�
�� �澯չʾ����ϵͳָ���쳣ʱ���и澯���澯��Ϣ����ϵͳ���ơ��쳣ָ�����͡��쳣ֵ�������쳣ʱ�䣬����Ϣ���б�����ʽ���澯ʱ����ʾ���û�����ģ���ṩ�˽���ϵͳ��ָ������ɸѡ���ܣ���������Ա�����˽��ض��澯��Ϣ��
�� �澯ͳ�Ʒ����ɷֱ𰴽���ϵͳ�澯������ͼ���ȿ��ӻ��ķ�ʽչʾ�澯����ͳ�ƣ���������Աֱ�۷����澯���ɺ����ơ�
4) ͳ�Ʊ���ģ���ṩ�˽�������ݿ������ɱ����Ĺ��ܣ�������Ա�ɸ���ʱ�䷶Χѡ������ʱ��εı�����������ձ����±��ȡ�
5) ������ģ���ṩ�˹ؼ��ֲ�ѯ���ܣ�������Ա�ɸ��ݵ�ǰ��Ҫ��ҵ��������ϵͳ����ʱ�����֪�������Խ��в�ѯ�������ݲ�ѯ������ٶ�λ������ȷ������ϸ��¼��
6) ϵͳ����ģ������澯�������ú��Զ�����ӻ��DZ���2�����ܡ�
�� �澯��������Ϊ������Ա�ṩ�����ø澯ָ�����͡�Ƶ�ʡ����澯��������ֵ���澯ʱ�䷶Χ�ȹ���Ĺ��ܣ�ϵͳ�����ݸ��������ṩ�澯��
�� �Զ�����ӻ��DZ���Ϊ������Ա�ṩ���Զ�����ӻ�������չ�ӿڣ�ϵͳ���ݽ������ݷ��������ṩ������ϵĿ��ӻ��DZ���ӿڣ�������Ա�ɰ������ӹ������ýӿڣ��Ӷ���ȡ��������Ŀ��ӻ��������û�нӿڿ����㣬����ϵͳ����Ա�������룬����Ա���ͨ����Ϊ�俪�ſ��ӻ��ӿڡ�
1.3 �ܹ����
�������Ϲ����������������ͼ2��ʾ��ϵͳ�ܹ���ϵͳ��Kafkaϵͳ[10]��ELKЭ��ջ[12]��Spark Streaming������������[14]�����ݿ�洢��������WebӦ�÷�������ɡ�
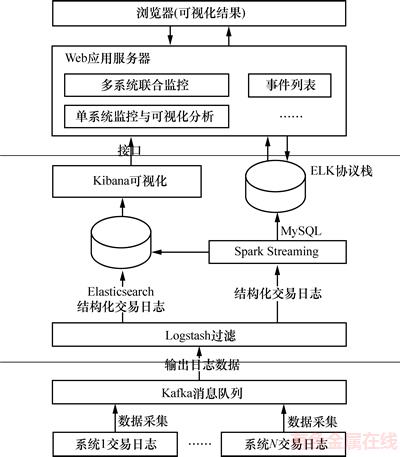
ͼ2 �����ϵͳ�ܹ�ͼ
Fig. 2 Architecture transaction monitoring system
1) Kafkaϵͳ�����÷ֲ�ʽ������Ϣ���з�ʽ�������ռ�������Ӧ��ϵͳ�Ľ�����־���ݣ�������ݾۺϺʹ�����̣���֤�ɼ������еĸ�Ч�ԡ���ά���Ժ��ȶ��ԡ�
2) ELKЭ��ջ����Kafka�ɼ������ݴ�������־�ɼ���������Logstash��Logstashͨ����������ϵͳ���ơ�����ʱ�䡢�������͡���������������λ������ʱ������Ӧ�롢��Ӧ������������9��ָ����й���������ݽṹ���ֱ�洢��Elasticsearch�������Spark Streaming��ElasticsearchΪKibana�ṩ���ݼ����ͷ��ʽӿڣ�Kibanaͨ���ڲ���װ�Ķ���ͼ�����ߣ��������״ͼ����״ͼ������ͼ�ȣ��Դ洢��Elasticsearch�е����ݽ��������ھ��������ӻ���
3) Spark Streaming��������������Spark Streaming���������Logstash�ṹ�������ݽ���ͳ�ƺ�Ԥ���ʵʱ���㴦�������ս�����������ܺ����Elasticsearch��MySQL���ݿ⡣
4) ���ݿ�洢�����������ݿ�洢����������ϵͳ���ݵij־û��洢����Ҫ�洢�û���Ϣ��������Ԥ���������Լ����û�����Ƶ����������Ϣ�ȡ�ϵͳ�����˽�Ϊ������MySQL���ݿ⣬MySQL��������С����Ч������չ����ά�����ŵ㡣
5) WebӦ�÷��������û�ͨ��Internet��WebӦ�÷��������н�����WebӦ�÷���������MVC(Model View Controller)ģʽ����ʾ�㡢����ģ�ͺͿ���������ϣ���ʾ�����û��ṩ�ѺõĿ��ӻ����棬���������������û��ύ�����������д�����json����ת����ģ���ж�Ӧ������ģ�ͣ�Ȼ�������Ӧ��ҵ�������ݵ��ý��ѡ�ص���ͼ�����ı�ʾ�����MVC�����˼�룬����MVVM (Model-View-ViewModel)ģʽ[15-16]��HTML DOM��ͼ��(View)������ģ��(Model)���룬ViewModel������ҵ���������ֱ���View��Model˫��ͨ�ţ���ģʽʹ��ͼ�㹦�ܵ�һ�������ڴ���������־�Ŀ��ӻ��У����������ҳ��ļ��غ���ȾЧ�ʡ�
1.4 ����ģ�����
1.4.1 ��ϵͳ���ϼ��
���и��칹Ӧ��ϵͳ֮��Ľ�����һ���Ĺ����ԣ������������ڵĽ�����Ϣ�����һ��������ǰ�úͷ�˰ǰ�õĽ�����ˮ����ˣ����ڶ������ϵͳ�����ϼ�ؿ������û���ֱ�۵��˽�ȫ�ּ����Ϣ������û����顣����ͨ���Ը��ཻ��ϵͳ��־�ķ�������ȡ���ױ�����������ʱ�������ɹ��ʺ�ҵ��ɹ���4������ָ�꣬Ϊ������Ա�ṩ������ϵͳ�����Խṹͼ�Ľ����Թ��̣����ͨ����ѧͳ�������ѧϰ�ȷ���ʵ�ֶ�ϵͳ�����ϼ�ء�
1) ������ϵͳ�����Խṹͼ�����IJ��û���HTML5�Ľ���ͼ�ο�GOJS[17]��ʵ�ֶ�ϵͳ�����Խṹͼ�Ĵ�����GOJS��һ��ģ��-��ͼ�ṹ����ͼ��ģ�͵Ŀ��ӻ���ģ������ͼ���������֣�ģ��ͨ��2������ṹ�洢���ֱ�Ϊ�ڵ���������������飬�ڵ�����洢Ӧ��ϵͳ�Ļ�����Ϣ�ؼ�ָ�����ݣ���������洢Ӧ��ϵͳ֮��Ĺ�����ϵ��ͼ3��ʾΪ��ϵͳ�����Խṹͼ�������̡�
�û�ͨ����ק����˵��������������ק������ָ��λ�ã�����Ӧ��ϵͳ���ƺͻ��˻����������������ȡ��ϵͳ�Ľ�������������ʱ�������ɹ��ʺ�ҵ��ɹ���4���ؼ�ָ�꣬Ȼ��ϵͳ��ָ����Ϣ��ϵͳ�淶��������������У�Ӧ��ϵͳ�ڵ�(NodeDataArray)������ɡ��û���ͨ��������(LinkedDataArray)����Ӧ��ϵͳ֮������˹�ϵ����ΪӦ��ϵͳ���ӱ�ע˵�����������ͼ(view model)�Ĵ�����ϵͳ������������ͼ�ṹ(Data Model)�洢�����ݿ��С��û��������ͼ��������ʵʱ�������Ӧ��ϵͳ�Ľ���״̬�����IJ�����ѯ��ʽ������������ָ�����ݱ仯��ʵʱ����������ͨ��ˢ��Data Model�ķ������½ڵ�ģ��(NodeTemplates)��������ģ��(LinkedTemplate)���Դﵽʵʱ��ص�Ч����
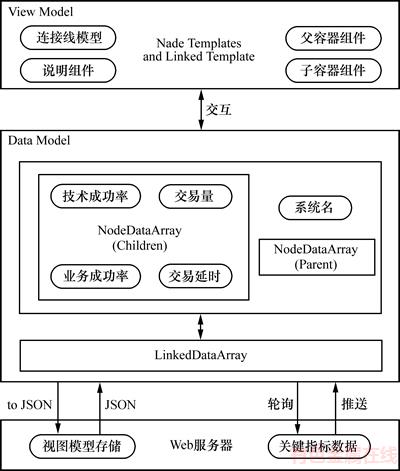
ͼ3 ��ϵͳ�����Խṹͼ��������
Fig. 3 Creation process of multi-system correlation chart
2) ��ϵͳ���ϼ����澯�����IJɼ��Ľ�������Դ����ɢ�ģ��辭��Spark Streamingʵʱ���㽫������ϵͳ�Ľ�������ͳ�ƺͻ��ܣ�������ش洢��MySQL���ݿ�������У�WebӦ�÷���������ѯ�ķ�ʽ��MySQL����ʵʱ���ݲ���ʾ�ڶ�ϵͳ�����ṹͼ�У��Դﵽ��ص�Ŀ�ġ����Ľ�϶�ʱ�����ݽ�������ʵʱԤ�����Ϊ���ø澯����ĸ�Ԥ�ṩ�澯���ƣ��澯���Ͱ���4���ؼ�ָ�꣬���н�����ʱ�������ɹ��ʺ�ҵ��ɹ��ʵĻ���ͨ����Ϊ���������壬�������Ļ���ֵͨ������ѧϰ������Ԥ�����õ���
����ͨ��ͳ�Ʒ�������ǰ��ϵͳijһ���ڵĽ�����ˮ���ݣ����ָ�ϵͳ�Ľ�������ʱ��������Ե�����ԣ�������һ�������ԣ����ѡ��Spark�������ع�ģ�������н�������Ԥ�⡣ͼ4��ʾΪ����ǰ��ϵͳ2017-06-04��12(������һ�����պ���һ����һ)�Ľ���������ͼ��
��ͼ4��ʾ������ͼ���Է��֣���������1 d��8����10�����������֮��ʼ���½����ƣ�����1�㵽3����һ�γ������������½����賿���ҽ���������1 d�нϵ�״̬��������8�����ҡ�1���ڹ����ս���������ϸߣ���ĩ��������Խϵ͡��ڽڼ��գ�����������ڷǽڼ��սϵͣ��ڼ��ս�����ĵ�1 d�Ľ�����Ҳ����Խϵ͡���ˣ����������һ�ָ澯�����еĽ�����Ԥ�ⷽ�����������ͼ5��ʾ��
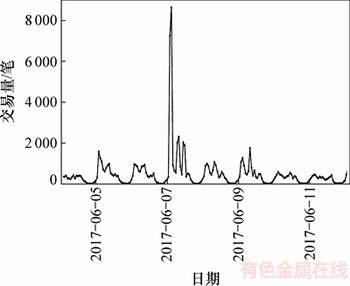
ͼ4 ����ǰ��ϵͳһ���ڽ���������ͼ
Fig. 4 Trending chart of trading volume of outbound-front system within a week

ͼ5 ������Ԥ�����
Fig. 5 Process of trading volume forecast
���ȣ�������ϵͳ��1���еĵڼ��졢1 d�е�Сʱֵ��Сʱ�еĵڼ���ʮ���ӡ��Ƿ�ڼ��ա��Ƿ��ٽ��ڼ������6��������Ϊ��ʷ���ݵ�������ǩ��Ȼ��ͨ����һ����������ǰ��ϵͳ�Ľ��������֣���ϵͳ����������½�������ij��ʱ���м���������ü�������Ԥ�����һ��Ӱ�죬ʹ�ö�Ӧʱ�̵�Ԥ��ֵҲ�ἤ������ʵ�ʽ�����Զ����Ԥ��ֵ�����������Ա��ĸ�����̬�ֲ���3��ԭ�����ʷ���ݽ���ȥ�롣�����ʷ���ݴ���������ǩ��ȥ�����Spark�������ع�ģ��[18-20]����ʷ���ݽ���ѵ���������ʵʱ�洢��Elasticsearch������Ҫ�澯��������Ϣ�洢��MySQL��
1.4.2 ��ϵͳ�������ӻ�����
���IJ���Kibana���ӻ�������Elasticsearch�еĽ������ݣ�ʹ�����ڲ��ḻ��ͼ������WebӦ�÷���������ʵ�����ݵ�ʵʱ�������ӻ�������ͼ6��ʾΪ����Kibana�Ľ������ݿ��ӻ����̡�
Kibana���ӻ�����Elasticsearch���ݾۺϵ��������ͣ����ۺϺͿ̶Ⱦۺϡ����ۺ��������ͼ����ͼ�ķ���������̶Ⱦۺ���������ͼ������ͼ����������Ϊ�̶ȵķ��������Kibanaͨ����������ƥ��ģʽʵʱ����Elasticsearch������ݼ����������ͼ��������ʱ��Ϊ���ᡢ������Ϊ�����ꡢ����Ӧ�����Խ��������ӻ�����������ͼ��������ʱ��Ϊ���ᡢ������Ϊ�����ꡢ��������Խ�����ʱ���ӻ������ñ�ͼ�Խ���ҵ��ռ�ȿ��ӻ������ñ���Խ���������ӻ�������ָ��Ŀ��ӻ�ͼ���Ƕ�����Visualize������Visualize���ϵ�Dashboard�DZ��壬����URI�ӿڣ���WebӦ�÷��������ã�������Ա���趨ɸѡָ���ʱ�䷶Χ�õ����ӻ��IJ�ѯ�����
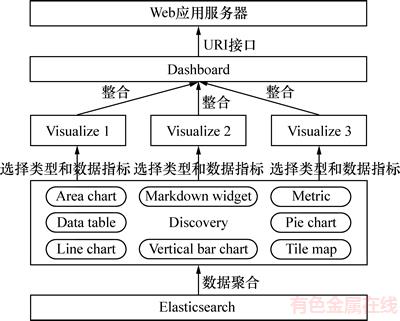
ͼ6 ����Kibana�Ľ������ݿ��ӻ�����
Fig. 6 Transaction data visualization process based on Kibana
1.4.3 ������
���IJ��ùؼ�ָ��������ƣ�Ϊ������Ա�ƶ������ӻ����������ѯ��ϵͳ�ṩ����ϵͳ���ơ���������ʱ�䡢��������(�ɹ���ʧ�ܵ�)������(����)��������ʱ6��ָ��IJ�ѯ�ӿڣ���������IJ�ѯ�������й���ɸѡ�����ؿ��ӻ��������ͼ7��ʾ�����ȣ�Kibana���ݲ�ѯָ���ƶ�3��Visualize(���ӻ�ͼ��)��һ�ǶԽ������ƶ�ͳ�Ʊ�ǩ�����ǶԽ����������ƶ�����ͼ�����Ƕ������ѯ�����������ƶ���ϸ�б�����3��Visualize�������Dashboard(���ӻ��DZ���)��������ʽ�淶�Ľӿڡ�Ȼ���û������ѯʱ��Web���������ղ�ѯ��������������ƴ�Ӳ�ѯ��䣬����Kibana�ӿڣ���ظ��û����ӻ������

ͼ7 ������ʱ��
Fig. 7 Timing diagram of transaction tracking
2 ϵͳʵ��
���ڸ���ϵͳ��ƣ�ʵ������������ҵ��Ľ����ϵͳ��������Ա��ͨ��Web�����������ؽ���۲�����ָ��仯�������׳����쳣����������������澯��ǣ�������Ա�ɵ����������쳣��ϵͳ���Ե�ǰ�������ݽ��з�������λ�쳣�������������ڽ�������Ѹ�ٶ�λ������ϸ�������쳣ԭ��
2.1 ��ϵͳ���ϼ��
��ϵͳ���ϼ��ģ��Ϊ������Ա�ṩ�˸����칹ϵͳ��Ĺ����Թ���ϵͳ���˽ṹͼ�Ľ������̣�����ȷ������������ϵͳ����ݷ�����Ա�����Ĺ�����ϵ��ʾʵʱ������ݡ�ͼ8��ʾΪ�������������EIX������ǰ�úͷ�˰ǰ��4������ϵͳ��ʵʱ����DZ��壬�DZ�����ڽ������쳣��ϵͳ����ʱ����澯��ǡ�
2.2 ������Ԥ�����
ͼ9��ʾΪ����ǰ��ϵͳ12 h�ڵĽ�����Ԥ������ʵ�ʽ�����ֵ�ĶԱȷ������ߡ���������ö�ʱ���ڽ�����Ԥ������ʵ��ֵ�仯���ƻ�����ϣ�Ԥ��ֵҲ����ֵ������Χ�ڣ�Ч�����á�
2.3 ��ϵͳ�������ӻ�����
����������ǰ��ϵͳ4 h�ڵĽ�������ݿ��ӻ�Ϊ�����Ե�ϵͳ�������ӻ�ģ���ʵ�ֽ�����������ͼ10��ʾ�����ӻ����ݰ����û��Զ����Ƶ�ʽ��и��£�Ĭ��ÿ10 s���¡��������ͽ�����ʱ������ͼ��ʱ��Ϊ������ʾ�������ƣ���ͼ10(a)~(b)��ʾ�������������в�ͬ���ߴ�����ͬ������Ӧ��(�ɹ���ʧ�ܵ�����)��������ʱ�в�ͬ���ߴ�����ͬҵ�����ͣ����ֲ�ͬҵ���ڽ��ײ���ʱ����ʱ������ƣ���������ҵ���еķֲ�����ñ�ͼչʾ����ͼ10(c)��ʾ��������Ա�ɰ�������ѡ�и���Ȥ������ѡ�к�ϵͳ��ֻ�ṩ��ѡ����Ŀ��ӻ���������û�����һ��������ͬʱ�ɲ鿴�����ͼ���ṩ�Ľ�����ϸ��(��ͼ10(d))���û�����ѡ��ˢ��Ƶ�ʺ�ʱ�䷶Χ���л�ʵʱ���ģʽ�ͱ���ģʽ��

ͼ8 ϵͳʵʱ���ͼ
Fig. 8 System real-time monitoring chart

ͼ9 �ؼ�ָ��Ԥ����ʵ��ֵ�Աȷ�������
Fig. 9 Curve comparison of key indicators forecast and actual value
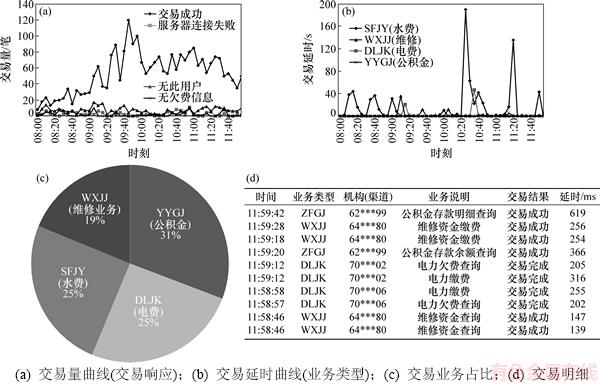
ͼ10 ��ϵͳʵʱ�������ӻ�����
Fig. 10 Single-system real-time monitoring and visual analysis
3 ����
1) ������Ƶ���������ҵ��Ľ���ؿ��ӻ�ϵͳ������н���������־���вɼ����ṹ���洢����ά�ȿ��ӻ������뽻����Ԥ��澯��Ϊҵ�������Ա�ṩ�˷���ֱ�۵ļ�ػ������������ǰ�Խ������ⶨλ�����������Լ������ͽ������ʱ�����⣬���������˹���Ч�ʡ�
2) ���������ϵͳ�ܹ��Ϳ��ӻ����������ڶ���������־�IJɼ�����ӻ������У����нϸߵ���ֲ�ԡ���չ���븴���ԡ�
�ο����ף�
[1] CHAMARTHI, PRASAD S, MAGESH S. Application of splunk towards log files analysis and monitoring of mobile communication nodes[J]. International Journal of Applied Science and Engineering Research, 2014, 3(2): 478-483.
[2] BIRJALI M, BENI-HSSANE A, ERRITALI M. Analyzing social media through big data using infosphere biginsights and apache flume[J]. Procedia Computer Science, 2017, 113: 280-285.
[3] BAI J. Feasibility analysis of big log data real time search based on Hbase and ElasticSearch[C]//Ninth International Conference on Natural Computation (ICNC). Shenyang, China: IEEE, 2013: 1166-1170.
[4] SANJAPPA S, AHMED M. Analysis of logs by using logstash[C]//Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications. Singapore: Springer, 2017: 579-585.
[5] BAJER M. Building an IoT Data Hub with Elasticsearch, Logstash and Kibana[C]//IEEE 5th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW). Prague, Czech Republic: IEEE, 2017: 63-68.
[6] SHAHZAD F, SHELTAMI T R, SHAKSHUKI E M, et al. A review of latest web tools and libraries for state-of-the-art visualization[J]. Procedia Computer Science, 2016, 98: 100-106.
[7] BOONNAVASIN M, RATTANATAMRONG P. EnGeno: Towards enabling a medical genogram library for supporting home-visit patient diagnosis[C]//IEEE 5th Global Conference on Consumer Electronics. Kyoto, Japan: IEEE, 2016: 1-4.
[8] AIGNER W, MIKSCH S, SCHUMANN H, et al. Visualization of time-oriented data[M]. London: Springer, 2011: 45-68.
[9] KREPSJ,NARKHEDEN,RAOJ.Kafka:Adistributedmessagingsystemforlogprocessing[C]//Proceedings of the NetDB. Athens, Greece: ACM, 2011: 1-7.
[10] WANG G, KOSHY J, SUBRAMANIAN S, et al. Building a replicated logging system with Apache Kafka[J]. Proceedings of the Vldb Endowment, 2015, 8(12): 1654-1655.
[11] GORMLEY C, TONG Z. Elasticsearch the definitive guide: a distributed real-time search and analytics engine[M]. Sebastopol California, USA: O��Reilly Media Inc, 2015: 61-127.
[12] ANDREASSEN O ��, CHARRONDI RE C, DE DIOS FUENTE A. Monitoring mixed-language applications with elasticsearch, logstash and kibana (ELK)[C]//Proceedings of the 15th International Conference on Accelerator and Large Experimental Physics Control Systems. Melbourne, Australia, 2015: 786-789.
RE C, DE DIOS FUENTE A. Monitoring mixed-language applications with elasticsearch, logstash and kibana (ELK)[C]//Proceedings of the 15th International Conference on Accelerator and Large Experimental Physics Control Systems. Melbourne, Australia, 2015: 786-789.
[13] LIAO Xinyi, GAO Zhiwei, JI Weixing, et al. An enforcement of real time scheduling in spark streaming[C]//Sixth International Green and Sustainable Computing Conference. Las Vegas, NV, USA: IEEE, 2016: 1-6.
[14] BIFET A, MANIU S, QIAN J, et al. StreamDM: advanced data mining in spark streaming[C]//IEEE International Conference on Data Mining Workshop. Atlantic City, NJ, USA: IEEE, 2015: 1608-1611.
[15] LI Xiaolong, CHANG Daliang, PENG Hui, et al. Application of MVVM design pattern in MES[C]//Cyber Technology in Automation, Control, and Intelligent Systems (CYBER). Shenyang, China: IEEE, 2015: 1374-1378.
[16] SORENSEN E, MIKAILESC M. Model-view-viewmodel (MVVM) design pattern using windows presentation foundation (WPF) technology[J]. MegaByte Journal, 2010, 9(4): 1-19.
[17] GoJS-Interactive Diagrams for JavaScript and HTML[EB/OL]. [2017-08-30]. https://gojs.net/latest/index.html
[18] GULLER M. Machine Learning with Spark[M]. Berkeley, CA. USA: Apress, 2015: 153-205.
[19] MENG X, BRADLEY J, YAVUZ B, et al. Mllib: machine learning in apache spark[J]. The Journal of Machine Learning Research, 2016, 17(1): 1235-1241.
[20] GUAN Lei, HU Guangjun, WANG Zhuan. Research on network security situational awareness technology based on big data[J]. Netinfo Security, 2016, 16(9): 16-22.
(�༭ ����ƽ)
�ո����ڣ�2017-12-12�������ڣ�2018-01-24
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61572530��61602171)(Projects(61572530, 61602171) supported by the Natural National Science Foundation of China)
ͨ�����ߣ��ι���ʿ�������ڣ����¼�������硢���簲ȫ�о���E-mail��duangh@csu.edu.cn
ժҪ��������������������칹����ϵͳ�����ĺ���������־�ṹ���ӡ���ȡ���ѡ�����Ч�ʵ��Լ����ܼ�ʱ���ֽ����쳣�����⣬�����ʵ��һ����������ҵ��Ľ���ʵʱ���ϵͳ�����ṩ�������ݵĿ��ӻ����������ȣ�ϵͳ�Խ�����־�йؼ�����ָ����вɼ����ṹ���洢��Ȼ��ͨ������ѧϰ�����Խ���������ʵʱԤ�⣬�ṩ�������쳣�澯�����ͨ�����ӻ���ʽ���칹����ϵͳʵʱ��أ����Խ��������ṩ��ǶȵĿ��ӻ��������о������������ϵͳ�������ۡ��������á��������죬�ܺܺõ��������й�����Ա��ҵ���������
