
DOI: 10.11817/j.issn.1672-7207.2017.05.014
�ƻ����º����������ݵIJ�ѯ����
��־�գ�����÷���°��֣�֣���⣬����
(���ϴ�ѧ ����ѧԺ������ ��ɳ��410073)
ժ Ҫ��
RDF���ݵĸ�Ч��ѯ���о�RDF�����ڷֲ�ʽ���ݿ�HBase�еĴ洢����������MapReduce��ƺ���RDF���ݵ����β�ѯ���ԣ�����ѯ��ΪSPARQLԤ��������ֲ�ʽ��ѯִ�нΡ�SPARQLԤ���������ʵ�ֻ���SPARQL���������ȵIJ�ѯ�����㷨JOVR��ͨ������SPARQL��ѯ����б����Ĺ�����ȷ�����ӱ���������˳�������ӱ�����SPARQL�Ӿ����Ӳ������ֵ���С������MapReduce�����У��ֲ�ʽ��ѯִ�н�ִ��SPARQLԤ�����λ��ֵ�MapReduce����ʵ�ֶԺ���RDF���ݵIJ��в�ѯ������LUBM���������ݼ��Բ�ѯ����������֤���о����������JOVR�㷨�ܹ���Ч��ʵ�ֶԺ���RDF���ݵIJ�ѯ�������н�ǿ���ȶ��������չ�ԡ�
�ؼ��ʣ�
���д�����������Ϣ��ѯ������MapReduce��SPARQL������RDF��
��ͼ����ţ�TP391 ���ױ�־�룺A ���±�ţ�1672-7207(2017)05-1218-09
Massive semantic data query method based on cloud computing
HU Zhigang, JING Dongmei, CHEN Bailin, ZHENG Meiguang, YANG Liu
(School of Software, Central South University, Changsha 410073, China)
Abstract: In order to achieve the efficient query for large-scale RDF data, the storage method of RDF triples in HBase was analyzed and a two-phase query strategy for large-scale RDF data was designed based on MapReduce, which was divided into two stages, i.e. the SPARQL pretreatment stage and the distributed query execution stage. In the SPARQL pretreatment stage, a SPARQL query classification algorithm-JOVR was implemented, which determined the join order of connection variables by calculating the correlation between the variables in a SPARQL query statement, and then the join between SPARQL clauses was divided into the minimum number of MapReduce jobs according to the connection variables. The distributed query execution phase accomplished large-scale RDF data query concurrently based on MapRdecue jobs from SPARQL pretreatment stage. The strategy was verified by LUMB benchmark set. The results show that JOVR can query large-scale RDF data efficiently with strong stability and scalability.
Key words: parallel processing; semantic information query strategy; MapReduce; SPARQL; large-scale RDF
��������Web�ķ�չ��������RDF(resource description framework)[1]�������ݼ������ӣ���Wikipedia[2]��������Ϣѧ[3]��ý������[4]���罻����[5]�ȡ������ӿ�������(Linked open data, LOD)����Ϊ ��[6]����ֹ��2014-04��LOD�����й�����1 014��RDF�������ݼ�����2011���295��RDF�������ݼ���310�ڸ�RDF��Ԫ����ȣ���ģ������3���ࡣ��ͳ������Web��ѯ�����ܹ��ṩ֧��RDF���ݱ���ѯ����SPARQL(simple protocol and RDF query language)�IJ�ѯ�����������������ڵ��������У���������RDF����ʱ�ļ��������д���ߡ�Ŀǰ��RDF���ݳ��ֳ����ģ�ԡ�����������������Եȴ�����(big data)[7-8]���ԣ���ˣ����Ƕ����ò��м��㼼����������RDF�����Ѵ�ɹ�ʶ��Hadoop��һ�Դ�Ƽ���ƽ̨��������� HDFS(hadoop distributed file system)��MapReduce��ܡ�HDFS�ֲ�ʽ�ļ�ϵͳ���и��ݴ��ԣ��ܹ��ṩ�������������ݷ��ʣ����ʺϺ������ݼ��ϵ�Ӧ�á�������HDFS֮�ϵ�HBase�ֲ�ʽ���ݿ����ܸߣ����ҿɿ��Ըߡ�MapReduce�ֲ�ʽ��������ܹ��ֲ�ʽ����������ʵ�֣���Ч�����������ݣ���ˣ��о���Ա��ʼ���߱������ݴ����������Ƽ��� Hadoop������������Web�о�����[9]�����������о���Ա�����ƻ��������һЩ�������ݴ洢���ѯ���ԣ����ڴ洢�ռ�Ͳ�ѯЧ�ʷ�������Ҫ��һ���о����Ż������ĵ���Ҫ�о��������£�1) ��������[9]����Ĵ洢���������ڡ���Ԫ��ϡ��м���SPO�洢���ԣ����3��HBase��(SP_O��PO_S ��OS_P )�洢����RDF���ݣ�2) ���ʵ��SPARQL��ѯ�����㷨JOVR��ͨ������SPARQL����б���������ȷ�����ӱ���������˳���������ӱ�����SPARQL�Ӿ����Ӳ������ֵ���С������MapReduce�����У������̲�ѯ���ģRDF���ݵ�ʱ�䣻3) ����MapReduce�ֲ�ʽ������ܣ���Ч��ʵ��RDF���ݲ��в�ѯ��
1 ��ظ������о�
1.1 ��ظ���
1) RDF��RDF������S(Subject)��ν��P(Project)������O(Object)����Ԫ��
2) SPARQL��SPARQL��W3C(world wide web consortium����ά������)��������RDF���ݵı���ѯ���ԣ���SQL������ƣ�ͨ��SELECT��ѯ��ʽ�����������������ݡ���1��ʾΪ1����SPARQL��ѯ���ӣ����ڴ�ͼ������ݼ��в��ҳ������Ŀ��
��1 SPARQL��ѯʵ��
Table 1 Example of SPARQL query
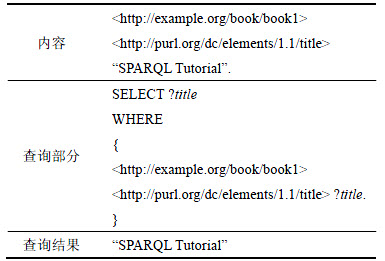
��1�У�SELECT�Ӿ��ʾ��ѯ�����ݣ�WHERE�Ӿ��ʾ����ѯ���������Ԫ��ģʽ������д���?���IJ����Dz�ѯ�е�δ֪�������硰?title����ʾͼ����Ŀ��δ֪������
3) HBase��HBase�ǻ���Google��Bigtable������1���߿ɿ��ԡ������С��������ķֲ�ʽ�洢ϵͳ[12]��HBase�洢������ɢ�����ݣ�����ӳ��(key/value)���ϵ������֮�䣬�洢�����ݴ����Ͽ�����1�źܴ�ı����������п��Ը�����Ҫ��̬���ӣ������к�����ȷ���ĵ�Ԫ(Cell)�����ݣ�����ʱ�������Ϊ����汾��
4) MapReduce��MapReduce��1���ֲ�ʽ������ܣ�����������ΪMap�κ�Reduce�Σ��ֱ�ͨ��Map������Reduce����ʵ�֡���Map�Σ��������ݾ����Զ����Map�������������
1.2 ����о�
RDF�ֲ�ʽ�洢��Ҫ��ΪHDFS��HBase 2�ַ������о���Ա������2�ַ�������˶���RDF��ѯ�㷨��
1) MYUNG��[13]��HDFS�е�RDF�����ļ��ж�ȡ��Ӧ��RDF���ݣ��������MapReduce�����������SPARQL�Ӿ����Ӳ��������÷�����RDF����ֱ�Ӵ�ŵ�HDFS�ϣ�ȱ���˸�Ч�������ṹ���������㷨������SPARQL�Ӿ����ӹ����д����϶��MapReduce����HUSAIN��[14]֤�����ڲ��л����£���������MapReduce�����������ͣ�RDF���ݲ�ѯʱ�����٣�����ͬ������HDFS�洢RDF���ݣ�ȱ�ٸ�Ч�������ṹ������ʵ�ֶԺ���RDF���ݵĿ���������ʡ�
2) SUN��[15]����HBase����������������(S _PO��P_SO��O_ SP��SP_O��PO_S ��SO_P)�洢RDF���ݣ������1����������MapReduce������㷨ʵ��RDF���ݲ�ѯ��FRANKE��[16]�����2��HBase����Tsp��Top�洢RDF���ݣ���SPARQL��ѯ����������ѡȡƥ�����������ٵIJ�ѯ�Ӿ�������ӡ�������Щ�㷨��ֻ�����ڼ���SPARQL��ѯ���м��������������㷨�п��ܻᵼ����SPARQL �Ӿ����ӹ����д��������MapReduce������ˣ�����Щ����²������������̲�ѯʱ�䡣
2 ����HBase��RDF���ݴ洢����
����HBase��RDF��Ԫ��洢����Ŀǰ��Ҫ��3��[15-21]��1) ���ڡ�һ��Ԫ���м���SPO�洢���ԣ�������ѡȡ��Ԫ��
2.1 RDF���ݵ�3�ִ洢����
SUN��[15]���ڡ�һ��Ԫ���м���SPO�洢���������6��HBase��(S_PO��P_SO��O_ SP��SP_O�� PO_S ��SO_P)����HBase�е��м��ֱ�ΪS��P��O��SP��PO��SO�������ڲ�ѯ�п���ƥ�����SPARQL��Ԫ��ģʽ��
FRANKE��[16]���ڡ��й̶����м���SPO�洢���������2��HBase���ݱ�Tsp��Top�������洢P��Ӧ��ֵ���м��ֱ�ΪS��O���ֱ�����ƥ������S�����O��֪��SPARQL��Ԫ��ģʽ������Ԫ��ֱ�洢O��S��
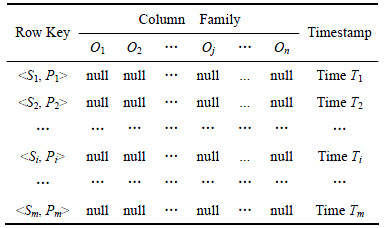
���IJ�������[9]�л��ڡ���Ԫ��ϡ��м���SPO�洢���ԣ����3��HBase��(SP_O��PO_S��OS_P)�洢���ݡ��м��ֱ�ΪSP��PO��OS�ܹ��������п��������ʽ��SPARQL��Ԫ��ģʽ��ѯƥ����������SP_O�ṹ���2��ʾ����2�У�m��n�ֱ�ΪHBase������������������m��0, n��0���м�������ֵ��ν��ֵ�������<>i, Pi>(i��[0, m])�����Ӧ��n������Oj(j��[0, n])��Ϊ����������1�������У�ÿ������Ԫ���Ϊnullֵ����PO_S��OS_P���SP_O�ṹ���ƣ��ֱ�ν��P�ͱ���O������O������S���������Ϊ�м��������д�Ŷ�Ӧ������ֵ��ν��ֵ��
��2 ��SP_O��HBase�еĴ洢�ṹ
Table 2 Storage structure of table SP_O in HBase
��3��ʾΪSPARQL�Ӿ��в�ͬ����Ԫ��ģʽ������HBase��֮��IJ�ѯӳ���ϵ�����С�?S������?P���͡�?O���ֱ��ʾ���ν��ͱ�����δ֪���������С�?���ı�ʾ���ν��ͱ�������֪����
��3 SPARQL��Ԫ����HBase��ӳ���ϵ
Table 3 Mapping relation between SPARQL triple patterns and HBase tables
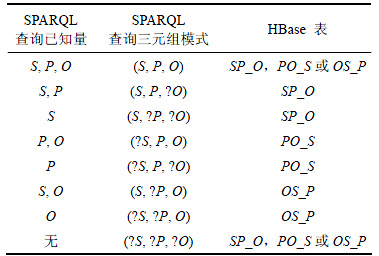
���3��ʾ������Ԫ��ģʽΪ(S, P, O)��(?S, ?P, ?O)ʱ�����Զ�SP_O��PO_S��OS_P������1�ű�����������Ԫ��ģʽ��ֻ��1��������(S, P, ?O)ʱ��������2����ֵ֪S��P��Ϊ�����������Ա�SP_O���м�����ƥ�䣻����Ԫ��ģʽ����2��������(S, ?P, ?O)ʱ������HBase��Scan����������ƣ�������ֵ֪S�ڱ�SP_O���м�������ɨ�裬�õ���ѯ�����
2.2 RDF���ݴ洢���Է�����Ա�
��HBase����Ƶı��������ռ俪���Լ�ʱ�俪��3������Ի��ڡ�һ��Ԫ���м���SPO�洢���ԡ����ڡ��й̶����м���SPO�洢�����Լ����ڡ���Ԫ��ϡ��м���SPO�洢���Խ��жԱȷ��������4��ʾ��
��4 ����HBase�Ĵ洢���ԱȽ�
Table 4 Comparison of storage strategies based on HBase
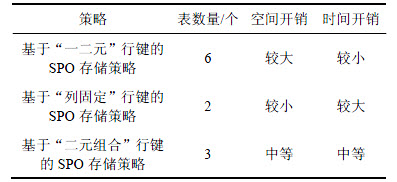
���ڡ�һ��Ԫ���м���SPO�洢���Լ����˲�ѯʱ�䣬����Ҫ��RDF���ݸ���6�Σ������˴洢�ռ�Ŀ�����
���ڡ��й̶����м���SPO�洢�����������2��HBase���ݱ�Tsp��Top����ν��P��Ӧֵ��Ϊ�̶��������������˴洢�ռ䡣����S��OͬʱΪδ֪��ʱ������Ҫ����������1��������ȫ��ɨ�裬��Ȼ�����Ӳ�ѯ���̵�ʱ�俪����
���IJ��õĻ��ڡ���Ԫ��ϡ��м���SPO�洢����ֻ��Ҫ�����ݸ���3�Σ�����ڡ�һ��Ԫ���м���SPO�洢������ȼ����˿ռ俪��������ֻ�е�S��P��O����ͬʱΪδ֪��ʱ�Ż��ȫ��ɨ�裬�����ڡ��й̶����м���SPO�洢������S��OͬʱΪδ֪��ʱ�Ͷ�ȫ������ɨ�衣���ԣ�����ڡ��й̶����м��Ĵ洢������ȼ�����ʱ�俪����
�������������IJ�ȡ�Ĵ洢���������ݴ洢�ռ俪���Ͳ�ѯЧ�ʵ�ƽ�ⷽ��������ơ�
3 RDF���ݵ����β�ѯ����
���������RDF���ݵ����β�ѯ���Ի���SPARQL������Hadoopƽ̨��ʵ�ֺ���RDF���ݵIJ��в�ѯ����ͼ1�е�SPARQL��ѯ���Ϊ�������ܲ��Ե������ʵ�ַ�����
3.1 RDF���ݵ����β�ѯ���Կ��
Ϊ�˷������������ȶ������¸��

ͼ1 SPARQL��ѯʵ��query
Fig. 1 Query example of SPARQL
����1 TP(U)��ʾSPARQL��ѯ����е���Ԫ��ģʽ������UΪ��Ԫ���б������ϣ���{X, Y, Z, XY, XZ, YZ} U��
U��
TP(U)�е�ÿ����ԱS��P��O��������1���DZ���������SPARQL��ѯ��佫�����塣ͼ1��ʾ�IJ�ѯʵ��query����Ԫ��ģʽ���α�ʾΪTP1(X)��TP2(Y)��TP3(Z)��TP4(XZ)��TP5(XY)��
����2 ���ӱ�������2��������
����3 ������ָ��1�����ӱ���Vֱ����ص��������ӱ����ĸ�������ʾΪR(V)��{X, Y, Z}V��
ͼ1��ѯʵ��query����Xֱ����ص����ӱ�����Y��Z���ֱ���Y��Zֱ����ص����ӱ���ֻ��X����ôR(X)=2��R(Y)=1��R(Z)=1��
����4 IRS(U)�Dz�ѯ������MapReduce��������ĺ��б���U���м�������{X, Y, Z, XY, XZ, YZ}U��
����5 ��ѯʱ��ִָ�в�ѯQ����������MapReduce���ѵ�ʱ���ܺͣ���Cost(Q)��ʾ��ÿ��MapReduce���ѵ�ʱ����Cost(job)��ʾ���������ѵ�ʱ���ܺ��ù�ʽ��ʾΪ
 (1)
(1)
���У�Q������ǰSPARQL��ѯ��jobi��ʾ��ǰ��i��MapReduce����nΪMapReduce�����������mΪ���ӱ����ĸ�����
RDF���ݵ����β�ѯ������SPARQLԤ�����ͷֲ�ʽ��ѯִ��2���Σ���ѯ���Կ��ͼ��ͼ2��ʾ��
1) SPARQLԤ����������˻���SPARQL���������ȵIJ�ѯ�����㷨JOVR(join on variable relation)��JOVR���ȸ��ݱ��������ȴ�SPARQL��ѯ��Ԫ����˳���ѡȡ���ӱ�����Ȼ��SPARQL�Ӿ����Ӳ������ֵ���С������MapReduce�����С�
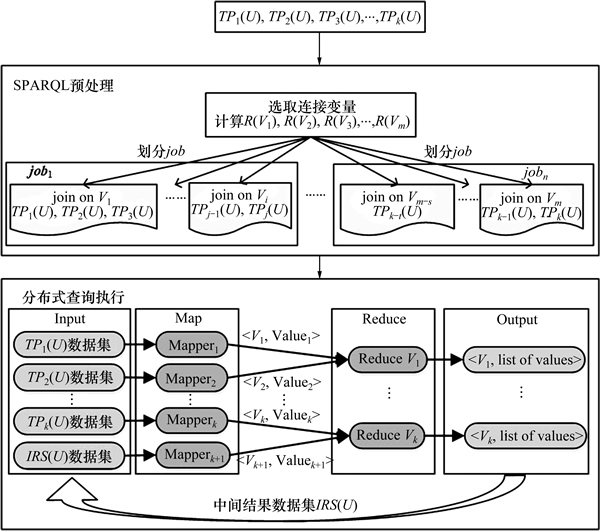
ͼ2 RDF���ݵ����β�ѯ���Կ��ͼ
Fig. 2 Frame of two-stage query strategy for RDF data
2) �ֲ�ʽ��ѯִ�н��жԲ�ѯ�Ӿ��������ʱ����Ҫ�����ݴӶ�Ӧ��HBase���ж�����Ȼ����Map�ν������ݹ�������װ����Reduce�������������
3.2 SPARQLԤ����JOVR�㷨
JOVR�㷨ͨ������SPARQL����������ȷ�����ӱ���������˳�������ӱ���̰�Ļ���SPARQL��ѯ���ﵽ�ֲ�ʽ��ѯ��job(MapReduce����)�������ٵ�Ŀ�ꡣ


�㷨��2���Ƕ�m�����ӱ����������Ƚ��зǽ�������6~12�в���̰�Ļ��ַ���ȷ��ÿ��job�����IJ��������α������ӱ��������ܹ����յ�ǰ����ui���в�ѯ�Ӿ����ӣ������Ӳ������м�����䱣������ʱ����tmp�У�ͬʱ�Ӳ�ѯ�����ȥ���Ѿ��������ӵ��Ӿ䣬�����Ҫ�����Ӳ������뵱ǰ��jobn�С���13~14��ָ����ǰ�����ڿ��Բ������Ӳ������Ӿ䣬���������µ�job���㷨��������15~16��ָ��ǰʣ��IJ�ѯ��䲻�ܰ����κ����ӱ����������ӣ����ڵ�ǰQ�м���temp�е���䣬��ʼ�����µ�job���ظ���4~16�еIJ�����ֱ�����������µ�jobΪֹ��
�������㷨�У���m�����ӱ������п��������ʱ�临�Ӷ�ΪO(mlgm)�����ѭ��(whileѭ��)���ִ��n�Σ��ڲ�ѭ��(forѭ��)���ִ��m�Σ����ԣ����㷨����ʱ�临�Ӷ�ΪO(m(n+lgm))(���У�mΪ��ѯ��������ӱ�����������nΪjob��������1��n��m)��
��ͼ1 ��ʾ��SPARQL��ѯʵ��query�У�����3.1�ڵĶ��壬���Լ����query�����ӱ���X��Y��Z�Ĺ����ȷֱ�ΪR(X)=2��R(Y)=1��R(Z)=1������JOVR�㷨�����չ����ȷǵݼ�����ѡȡ���ӱ����ֱ�ΪY��Z��X����ѯ��Ӧ2��job����ѯ���ֹ�����ͼ3��ʾ��
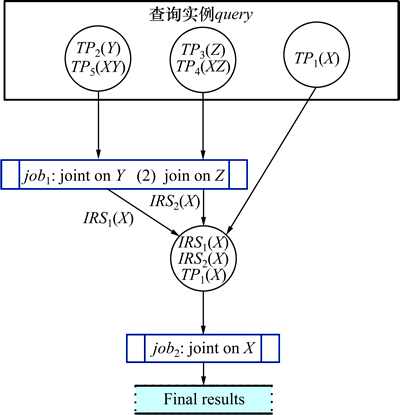
ͼ3 JOVR�㷨�в�ѯ���ֹ���
Fig. 3 Process of query classification in JOVR algorithm
��JOVR�㷨�IJ�ѯ���ֹ��̿��Է�����query��ѯ��ʱ�ܺ�Ϊ ��
��
�����о���Ա����JOVF( join on variable frequency)���㷨[15]����SPARQL��ѯ���֡��������ӱ������ֵĴ������з���������̰��ѡ����ִ����������ӱ�����Ȼ�����θ���ѡȡ�����ӱ������ֵõ�job������JOVF�㷨��ͼ1��ʾ�IJ�ѯʵ��query�У�X��Y��Z���ֵĴ����ֱ�Ϊ3��2��2������ѡ�����ӱ���X��Y��Z������Ϊ3��job�����ֹ�����ͼ4��ʾ��
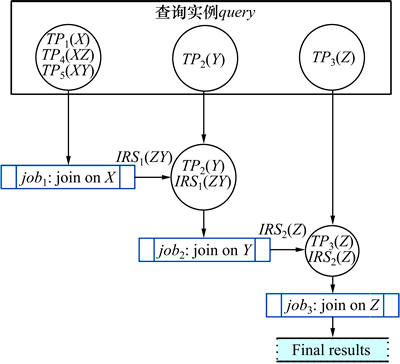
ͼ4 JOVF�㷨�в�ѯ���ֹ���
Fig. 4 Process of query classification in JOVF algorithm
��JOVF�㷨�IJ�ѯ���ֹ��̿��Է�����query��ѯ��ʱ�ܺ�Ϊ

�Աȷ���ͼ3��ͼ4��֪������ͼ1�е�SPARQL��ѯʵ��query��JOVR�㷨��JOVF�㷨���ֵ�job�������٣���ˣ���ѯ���õ�ʱ����١�
3.3 �ֲ�ʽ��ѯִ��
SPARQLԤ�����λ��ֵõ�job�ֲ�ʽ��ѯִ�нλ���MapReduceʵ�ֶ�RDF���ݵIJ��в�ѯ��������ͼ1�еIJ�ѯʵ��query����ÿ��job�����Ӳ����ľ��岽�裬��ͼ5��ʾ��
1) HBase���ݶ�ȡ������ѯ�Ӿ��е���Ԫ��������Ӳ���ʱ����Ҫ�����ݴӶ�Ӧ��HBase���ж�ȡ��
2) Map�Ρ�����ѯ�Ӿ�����Ԫ���Ӧ�����ݼ���
3) Reduce�Σ����ͬһ���ӱ�����Ӧ�Ķ����ѯ�Ӿ�����ӡ���ͼ5 job1�ж�keyΪY���Ӿ����Ӻõ�������key��Ȼ��Y��value�ǽ��������Ӳ������ݵ�value���ֺϲ��������õ�University+X#��������Զ����Reduce����������ս����
���ж��jobʱ��ǰ1��job������Ǻ�1��job������(��ͼ5��ʾ)��job2������ֱ������ڶ�ȡ��X���ݼ���job1��������ݼ�������Map�κ�Reduce�κ����X��Y��Z���ն�Ӧ�����ݣ���SPARQL�IJ�ѯ�����

ͼ5 �ֲ�ʽ��ѯִ�й���ʵ��
Fig. 5 Instance of SPARQL query execution process
4 ʵ�����
4.1 ʵ�黷��
����Hadoop-2.5.2��Ϊ����ƽ̨��ѡȡHBase-1.0.0��ΪRDF��Ԫ��洢���ݿ⣬��ѡ��4̨PC��(��������ΪPentium IV��CPU 3.00 GHz��2 GB�ڴ��160 GBӲ�̿ռ�)�ʵ��ƽ̨��
��ʵ��������������ѧ������Lehigh University Benchmark(LUBM)[17]���������ݼ����ֱ�� 10��50��100��200��300��500 ����ѧ��RDF���ݼ����в��ԡ�
4.2 ʵ���������
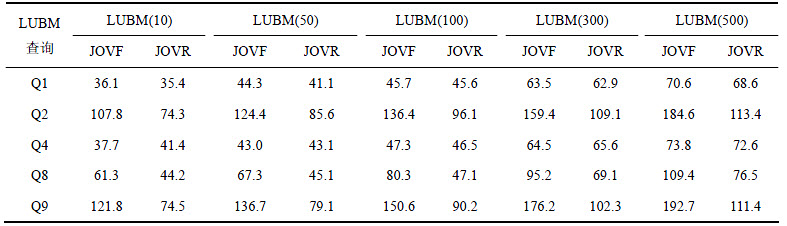
�ڲ�ͬ���ݼ��£��ֱ�����㷨JOVF��JOVR����5������临�ӳ̶��Ͼ��д����Ե�LUBM ��ѯ��䣬����ѯ�����job�Ķ�Ӧ��ϵ���5��ʾ��Ϊ�˱�֤ʵ������ȷ�ԣ���ʵ�齫ÿ����ѯ����ڲ�ͬ���ݼ��·ֱ����5�Σ����ȡ��ƽ��ֵ������ѯ���ѵ�ƽ��ʱ�����6��ʾ��
1) �ɱ�6��֪������Q1��Q4��2����ѯ��䣬JOVF��JOVR�㷨��ƽ��ʱ�伸����ͬ��������Ϊ����2���㷨�У�Q1��Q4����Ӧ1��job(���5��ʾ)��������Q2��Q8��Q9�� JOVF�㷨���ѵ�ʱ��ΪJOVR��1.5�����ҡ��ɱ�5��֪����JOVF�У�Q2��Q8��Q9��Ӧ��job�����ֱ�Ϊ3��2��3����JOVR�����߶�Ӧ��job�����ֱ�Ϊ2��1��2������job������ʱ����ѯʱ�������job�����������Ӧ�������ԣ�JOVR�IJ�ѯЧ�ʱ�JOVF�ĸߡ�
2) JOVF��JOVR�㷨ƽ����ѯʱ���������ݼ���������ֱ���ͼ6��ͼ7��ʾ�����Ų������ݼ���ģ�IJ���������2���㷨��ƽ����ѯʱ�䶼��û�г���ָ���������ƣ�����ƽ��������JOVR��ƽ����ѯʱ��������ʸ�С������JOVR�ڲ�ѯ���ȶ��Է����JOVFǿ��
3) �ɱ�6��֪�����������ݼ�����50��ʱ��JOVF��JOVR�㷨��ƽ����ѯʱ��ֱ�ֻ����Լ1.8����1.7��������JOVF��JOVR���������õĿ���չ�ԡ�
��5 LUBM��ѯ�����job�Ķ�Ӧ��ϵ
Table 5 Corresponding relationship between LUBM query statements and job

��6 LUBMƽ����ѯʱ��
Table 6 Average query time of LUBM s
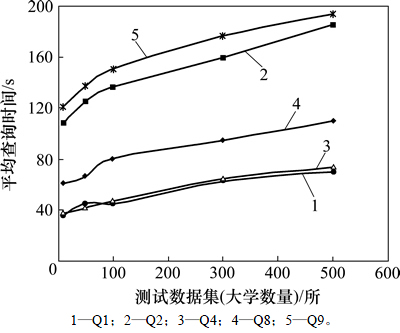
ͼ6 JOVF�㷨ƽ����ѯʱ����������ͼ
Fig. 6 Curves of average query time growth in JOVF
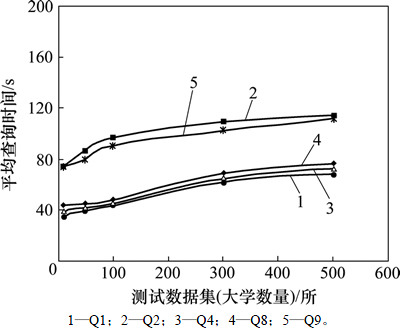
ͼ7 JOVR�㷨ƽ����ѯʱ����������ͼ
Fig. 7 Curves of average query time growth in JOVR
�ۺ����Ϸ�����JOVR�㷨�ڲ�ѯЧ�ʡ��ȶ��Լ�����չ�Է��涼ȡ���˽ϺõĽ�����ܹ����õ�֧�ֺ���RDF���ݵIJ�ѯ��
5 ����
1) �����һ�ֺ���RDF�������β�ѯ���ԣ�����˻���SPARQL���������ȵIJ�ѯ�����㷨JOVR���ﵽ�˷ֲ�ʽ��ѯ�����в�ѯ�����������ٵ�Ŀ�ġ�
2) ��JOVF�㷨��ȣ�JOVR�㷨��ѯЧ�ʸ��ߣ��ȶ��Ը�ǿ���ܹ����õ�֧�ֺ���RDF���ݵIJ�ѯ��
3) JOVR��Ҫ���SPARQL�ļ�ѯģʽ����SPARQL������ͼģʽ�ֲ�ʽ��ѯ�����д���һ���о���
�ο����ף�
[1] BRICKLEY D, GUHA R V. RDF schema 1.1[EB/OL]. [2014-09-21]. http:// www.w3.org/TR/rdf-schema.
[2] HOFFART J, SUCHANEK F M, BERBERICH K, et al. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia[J]. Artificial Intelligence, 2013, 194(1): 28-61.
[3] BELLEAU F, NOLIN M A, TOURIGNY N, et al. Bio2RDF: towards a mashup to build bioinformatics knowledge systems[J]. Journal of Biomedical Informatics, 2008, 41(5): 706-716.
[4] KOBILAROV G, SCOTT T, OLIVER S, et al. Media meets semantic web-how the bbc uses dbpedia and linked data to make connections[C]// European Semantic Web Conference on Semantic Web in Use Track. Heraklion, Greece, 2009: 723-737.
[5] MIKA P. Social networks and the semantic web: a retrospective of the past 10 years[C]// Proceedings of the 24th International Conference on World Wide Web. Florence, Italy, 2015: 1461.
[6] The Linked Open Data. The linked open data project (LOD). [2015-06-08]. http://www.w3.org/wiki/SweoIG/TaskForces/ CommunityProjects/LinkingOpenData.
[7] ��С��, ����. �����ݹ���: �����������ս[J]. ������о��뷢չ, 2013, 50(1): 146-169.
MENG Xiaofeng, CI Xiang. Big data management: concepts, techniques and challenges[J]. Journal of Computer Research and Development, 2013, 50(1): 146-169.
[8] ��ɺ, �����, ������, ��. �ܹ�������: ��ս����״��չ��[J]. �����ѧ��, 2011, 34(10): 1741-1752.
WANG Shan, WANG Huiju, TAN Xiongpai, et al. Architecting big data: challenges, studies and forecasts[J]. Chinese Journal of Computers, 2011, 34(10): 1741-1752.
[9] ����. ����Hadoop�Ĵ��ģ����Web�������ݲ�ѯ�������ؼ������о�[D]. ����: �����ѧ�����ѧԺ, 2013: 39-45.
LI Ren. Researchonkeytechnologies of large-scaled semantic web ontologies querying andreasoningbasedonHadoop[D]. Chongqing: Chongqing University. College of Computer, 2013: 39-45.
[10] ��С��, ����, ����. ����Web���ݹ����о���չ[J]. ����ѧ��, 2009, 20(11): 2950-2964.
DU Xiaoyong, WANG Yan, L Bin. Research and development on Semantic Web data management[J]. Journal of Software, 2009, 20(11): 2950-2964.
Bin. Research and development on Semantic Web data management[J]. Journal of Software, 2009, 20(11): 2950-2964.
[11] BECHHOFER S, HARMELEN F V, HENDLER J, et al. OWL web ontology language reference[EB/OL]. [2009-11-29]. http://w3.org/TR/owl-ref.
[12] ʩ�ݿ�. �����Ƽ���ĺ���������Ϣ�������������о�[D]. �Ϻ�: �Ϻ���ͨ��ѧ����ѧԺ, 2012: 31-35.
SHI Hunjun. Researchofmassivesemantic information parallel inference method basedoncloudcomputing[D]. Shanghai: Shanghai Jiaotong University. College of Software, 2012: 31-35.
[13] MYUNG J, YEON J, LEE S G. SPARQL basic graph pattern processing with iterative mapreduce[C]// Proceedings Massive Data Analytics Cloud (MDAC��10). Raleigh, USA, 2010: 1-6.
[14] HUSAIN M, MCGLOTHLIN J, MASUD M M, et al. Heuristics-based query processing for large RDF graphs using cloud computing[J]. IEEE Transactions on Knowledge & Data Engineering, 2011, 23(9): 1312-1327.
[15] SUN J, JIN Q. Scalable RDF store based on HBase and MapReduce[C]// International Conference on Advanced Computer Theory & Engineering. Chengdu, China, 2010: 633-636.
[16] FRANKE C, MORIN S, CHEBOTKO A, et al. Distributed semantic web data management in HBase and MySQL cluster[C]// Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing. Washington, USA, 2011: 105-112.
[17] GUO Y, PAN Z, HEFLIN J. LUBM: a benchmark for OWL knowledge base systems[J]. Semantic Web Journal, 2005, 3(2/3): 158-182.
[18] LIU B, HUANG K, LI J, et al. An incremental and distributed inference method for large-scale ontologies based on MapReduce paradigm[J]. IEEE Transactions on Cybernetics, 2015, 45(1): 53-64.
[19] CHENG J, WANG W, GAO R. Massive RDF data complicated query optimization based on MapReduce[J]. Physics Procedia, 2012, 25(22): 1414-1419.
[20] LIU L, YIN J, GAO L. Efficient social network data query processing on MapReduce[C]// Proceeding of the 5th ACM Workshop on HotPlanet. HongKong, China, 2013: 27-32.
[21] WEISS C, KARRAS P, BERNSTEIN A. Hexastore: sextuple indexing for semantic web data management[C]// 34th International Conference on Very Large Data Bases (VLDB). Auckland, New Zealand, 2008: 1008-1019.
(�༭ �²ӻ�)
�ո����ڣ�2016-06-16�������ڣ�2016-08-22
������Ŀ(Foundation item)��������Ȼ��ѧ����������Ŀ(61301136, 61572525, 61602525) (Projects(61301136, 61572525, 61602525) supported by the National Natural Science Foundation of China)
ͨ�����ߣ������������ڣ�˶ʿ����ʦ������������Ϣ���������������о���E-mail: yangliu@csu.edu.cn
ժҪ��Ϊ��ʵ�ֶԺ���RDF���ݵĸ�Ч��ѯ���о�RDF�����ڷֲ�ʽ���ݿ�HBase�еĴ洢����������MapReduce��ƺ���RDF���ݵ����β�ѯ���ԣ�����ѯ��ΪSPARQLԤ��������ֲ�ʽ��ѯִ�нΡ�SPARQLԤ���������ʵ�ֻ���SPARQL���������ȵIJ�ѯ�����㷨JOVR��ͨ������SPARQL��ѯ����б����Ĺ�����ȷ�����ӱ���������˳�������ӱ�����SPARQL�Ӿ����Ӳ������ֵ���С������MapReduce�����У��ֲ�ʽ��ѯִ�н�ִ��SPARQLԤ�����λ��ֵ�MapReduce����ʵ�ֶԺ���RDF���ݵIJ��в�ѯ������LUBM���������ݼ��Բ�ѯ����������֤���о����������JOVR�㷨�ܹ���Ч��ʵ�ֶԺ���RDF���ݵIJ�ѯ�������н�ǿ���ȶ��������չ�ԡ�
[1] BRICKLEY D, GUHA R V. RDF schema 1.1[EB/OL]. [2014-09-21]. http:// www.w3.org/TR/rdf-schema.
[7] ��С��, ����. �����ݹ���: �����������ս[J]. ������о��뷢չ, 2013, 50(1): 146-169.
[8] ��ɺ, �����, ������, ��. �ܹ�������: ��ս����״��չ��[J]. �����ѧ��, 2011, 34(10): 1741-1752.
[9] ����. ����Hadoop�Ĵ��ģ����Web�������ݲ�ѯ�������ؼ������о�[D]. ����: �����ѧ�����ѧԺ, 2013: 39-45.
[10] ��С��, ����, ����. ����Web���ݹ����о���չ[J]. ����ѧ��, 2009, 20(11): 2950-2964.
[12] ʩ�ݿ�. �����Ƽ���ĺ���������Ϣ�������������о�[D]. �Ϻ�: �Ϻ���ͨ��ѧ����ѧԺ, 2012: 31-35.
