
����Ӧ��over-relaxed���ٶ�̬��ֵƯ���㷨
�� ��1���� ӱ2������ƽ2���ܷ���2
(1. �廪��ѧ �������ѧ�뼼��ϵ ���ܼ�����ϵͳ�����ص�ʵ���ң�������100084��
2. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410075)
ժ Ҫ��
ժ Ҫ��Ϊ�˽����˹�˾�ֵƯ���㷨�����ٶ���������Ч�ʲ��ߵ����⣬�������Ӧover-relaxed���ٶ�̬���·����Ľ���˹�˾�ֵƯ���㷨�����ȣ��ھ�̬��ֵƯ���㷨���������ݼ��Ķ�̬���»��ƣ�ÿ�ε��������ݼ����µ��µ����ݵ㣬Ȼ�����������оۼ���һ������ݵ���1���������ʾ�����ٲ����������ݣ���֤ȷ�Ե�ͬʱ���ͼ����������ڷ���̬�ֲ������ݼ���̬����ʱ���������ϵ����ݵ�������ٶȽ���������over-relaxed�IJ�����������������ݵ�ĵ������������������ݼ�ֱ���ı仯������Ӧ�ؼ��㲽��������ʵ�����������Ľ���ĸ�˹�˾�ֵƯ���㷨�Գ����Ե��ٶ��������������Ӧ�ý��������������еļ�������
�ؼ��ʣ�
��ֵƯ������˹�����߽��Ż�����̬������
��ͼ����ţ�TP301 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2008)06-1296-07
Adaptive over-relaxed fast dynamic mean shift
YANG Bin1, ZHAO Ying2, FAN Xiao-ping2, ZHOU Fang-fang2
(1. State Key Laboratory of Intelligent Technology and Systems, Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China;
2. School of Information Science and Engineering, Central South University, Changsha 410075, China)
Abstract: An adaptive over-relaxed fast dynamic mean shift was proposed to speed up the convergence of Gaussian mean shift. Firstly, the convergence speed of Gaussian mean shift was improved by dynamically updating the data set and the number of the data set decreased using a special point replacing the points overlapped during the iterations. Secondly, as the data set didn��t follow the normal distribution, the direction of principal component converged more slowly than other directions. So the convergence of the data in the direction of principle component was accelerated by the over-relaxed strategy and the parameter was adaptively calculated by the diameter of the dynamic data set. The experimental results prove that the convergence speed of the proposed method is non-linear and the use of convergence points can lower the complicacy of process of iteration.
Key words: mean shift; Gaussian kernel; bound optimization; dynamic update
��ֵƯ���㷨��һ�ָ�Ч��ͳ�Ƶ����㷨�����ɺ��ܶȹ��ƹ�ʽ�Ƶ����[1]�����������ռ��������ݼ��ܶ������ķ����������ֲ���ֵ[2]�����ڲ���Ҫ����֪ʶ���Ҽ�����ʺ϶�δ֪�����ݼ����з���������������ֵƯ���㷨���㷺Ӧ����ģʽ����[3-4]��ͼ��ָ�[5-6]����Ƶ���ٵ�����[7-9]����ֵƯ���㷨���������ɺ˺�������[10]�����õĺ˺����о��Ⱥˡ�Epanechnikov�˺�˹�ˣ����ǣ����ǵ������ٶȸ�����ͬ�����Ⱥ˺�Epanechnikov�˼���������ٶȿ죬�����㾫�Ȳ��ߡ���˹�˺������㾫�ȸߣ�����Ч����[5]������·��ƽ�����������ٶ�������ˣ��ڴ������ģ�ĸ�ά����ʱ�����ٲ��ø�˹�˾�ֵƯ���㷨���ڴˣ�����������Ҫ��Ը�˹�˾�ֵƯ���㷨�������ٶȺͼ���Ч�ʽ��иĽ���Ϊ����߸�˹�˾�ֵƯ���㷨�������ٶȣ������㷨��Ӧ�÷�Χ����������һЩ�о��߶Ծ�ֵƯ���㷨��ԭ�������������о������ͨ�����ٵ��������ͽ���ÿ�ε����ļ������ķ���������㷨��Ч��[11]��Cheng��[2, 12]������ھ�ֵƯ���㷨���������ݼ���ģ�����ƣ�ÿ�ε�����������ݼ���ֱ�����ݵ��������ֲ���ֵ��Ϊֹ��Fashing��[13]֤�������˺�������������ʱ����ֵƯ���㷨��һ�ֱ߽��Ż��㷨��Carreira[14]���һ��֤���˸�˹�˾�ֵƯ���㷨������EM(Expectation Maximization)�㷨��Salakhutdinov�����over-relaxed���������EM�㷨�������ٶ�[15]�����������ܴ�ʱ�������㷨���ٶȺ�ȷ�Ծ����ߡ����������������Ӧ��over-relaxed���ٶ�̬��ֵƯ���㷨�����㷨�����ڱ��ľ�ֵƯ���㷨�����붯̬���µĻ��ƣ�ÿ�ε��������ݵ㡰Ư�ơ�����ֵ�㴦��ʹ���ݵ�Ѹ�ٵ���������ֵ�㣬�����˵���������ͬʱ����ÿ�ε��������У����ۼ���һ������ݵ���1���������ʾ�����������ȨֵΪ�ۼ����Ȩֵ֮�ͣ���������������������ÿ�ε����ļ������������ݼ���������̬�ֲ�ʱ�����ݼ���ά�ȵ������ٶȸ�����ͬ����������������ٶȿ죬�������ϵ����ݵ������ٶ�����Ϊ�ˣ�����over-relaxed�IJ�������������������ݵ�IJ��������������ݼ���ά�ȵ�ֱ���ı仯������Ӧ�ļ��㲽��������
1 ���ٵĶ�̬��˹�˾�ֵƯ���㷨
1.1 ����˹�˾�ֵƯ���㷨
����dά�ռ�Rd�е�n��������S={xi, 1��i��n}�����ڸ�˹��������k(x)= exp(-x/2) (x��0) ����Ǹ����������������ص㣬��˶�Ӧ�ĸ�˹�˺���Ϊ�� KN(x) = (2��)-d/2exp(-||x||2/2) (x��0)������KN(x)������h���ܶȺ���f�ĸ�˹���ܶȹ��ƹ�ʽΪ��
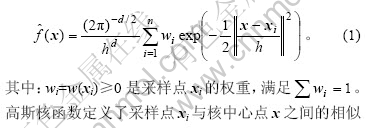
![]()
![]()
���У�wi=w(xi)��0�Dz�����xi��Ȩ�أ�����![]() ����˹�˺��������˲�����xi������ĵ�x֮��������Զ�����xi��x֮��ľ���Խ�������ƶ�Խ�ߣ�����ԽԶ�����ƶ�Խ�͡�����h�����˺˺�����Ӱ�췶Χ�������ܶȹ���f(x)��ÿ�������㴦�ĸ�˹�˺�����Ȩ��͵Ľ���������ܶȼ�ֵ�����Ѱ���ܶ��ݶ�Ϊ��IJ����㣬��
����˹�˺��������˲�����xi������ĵ�x֮��������Զ�����xi��x֮��ľ���Խ�������ƶ�Խ�ߣ�����ԽԶ�����ƶ�Խ�͡�����h�����˺˺�����Ӱ�췶Χ�������ܶȹ���f(x)��ÿ�������㴦�ĸ�˹�˺�����Ȩ��͵Ľ���������ܶȼ�ֵ�����Ѱ���ܶ��ݶ�Ϊ��IJ����㣬��![]() ����ˣ�
����ˣ�
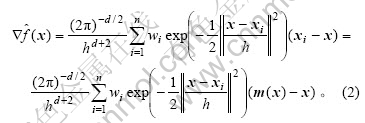
��M(x)=m(x)-x��������ֵƯ����������ʾ�����IJ��������У�

ʽ(3)Ϊ��ֵƯ�Ƶ�����ʽ������ʾ������ļ�Ȩƽ��ֵ�������ڡ����ġ��ĸ����ˣ�m(x)�����ܶ�һ�����x�����ܶȡ���ʽ(1)~(3)�ɵã�
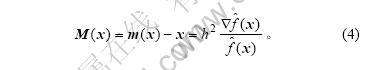
��ʽ(4)��֪��ֵƯ������M(x)�ķ�������ָ���ܶȴ�ķ���ֵƯ���㷨��������Ϊ�ܶȼ���ֵ�㡣��ֵƯ���㷨�Ĺ���Ϊ�����ȴ�S�������ѡ�����ݵ�xi��Ϊ��ʼ�㣬Ȼ����ʽ(3)�Ըõ㲻�ϵص������£�ֱ���������ֲ��ܶȼ���ֵ��Ϊֹ�������ݼ��е�������������ƾ�ֵƯ�ƣ����Ի�����ݼ������еļ�ֵ�㡣�������ӽ��ļ�ֵ��ϲ�Ϊ1����ֵ�㡣
1.2 ���ٵĶ�̬��ֵƯ���㷨
�ڱ���˹�˾�ֵƯ���㷨�У����ݼ�S�̶����䣬·����T���ϸ��¡�Ϊ����߸�˹�˾�ֵƯ���㷨�������ٶȺͼ���Ч�ʣ����ȣ��������ݼ��Ķ�̬���»��������ٵ�����������ͨ���ϲ�������IJ��������������ݼ��IJ�������������͵����ļ���������̬�ľ�ֵƯ���㷨�����ݼ�S��·��Tͬʱ���и��£�ÿ�ε������������ݼ���ÿ�����ݵ�ľ�ֵƯ���������������ݵ���и��£���һ�ε��������µ����ݼ��Ͻ��У�������ݵ��������ֲ���ֵ�㡣
�������ݼ�S={xi, 1��i��n}������̬�ֲ�N(��, ��2)�����У���Ϊ��ֵ����2Ϊ����ɴ������ɿɵ�ʽ(2) �еĸ�˹���ܶȹ��ƺ���f�ֲ�������̬�ֲ� N(��, ��2+h2)����ˣ������ļ������ɵ��ܶȹ���f(x)�ľ�ֵҲ����̬�ֲ���![]() �������ݶ����������㣬���ԣ��ݶȹ��Ƶľ�ֵΪ��
�������ݶ����������㣬���ԣ��ݶȹ��Ƶľ�ֵΪ��![]() [15]����ֵƯ���㷨�IJ���Ϊ��
[15]����ֵƯ���㷨�IJ���Ϊ��

���У�plim��ʾ���ʵļ��ޡ�����[12]֤���˵����ݼ�������̬�ֲ�ʱ����̬���º�����ݼ�����Ȼ������̬�ֲ�����ֵ�̲��䣬�����2��СΪ![]() ��
��![]() ������������������ٶ���ͬ���������ݼ��������˹�ֲ�ʱ�����ݵ������������ֵ�㱣�ֲ��䣬���ǣ������������ݵ�������ٶȲ�ͬ���������ϵ����ݵ������ٶ��������������ϵ����ݵ������ٶȿ졣
������������������ٶ���ͬ���������ݼ��������˹�ֲ�ʱ�����ݵ������������ֵ�㱣�ֲ��䣬���ǣ������������ݵ�������ٶȲ�ͬ���������ϵ����ݵ������ٶ��������������ϵ����ݵ������ٶȿ졣
��̬��ֵƯ���㷨��Ȼʹ���ݵ�����������ֵ�㣬���ǣ����ݼ�����Ŀʼ�ձ��ֲ��䣬���ݵ����ص���һ�𣬶�ÿ�ε�������Ҫ�������ݵ�����Χn-1�����ݵ�ľ��롣Ϊ�˼���ÿһ�ε����ļ���������������������ص������ݵ���1���������ʾ���õ��Ȩֵ�������ص����Ȩֵ֮�͡�
����1 �����ݼ�G={xi, i = 1, ��, l}�еĵ��ص���һ��ʱ����![]() (i, j = 1, ��, l��i��j)��������1����c=(wc, nc)����ʾ���ݼ�G�����У���c��ȨֵΪ
(i, j = 1, ��, l��i��j)��������1����c=(wc, nc)����ʾ���ݼ�G�����У���c��ȨֵΪ![]() ��nc=l��Ϊ��¼�ص������ݵ����Ŀ����ˣ���cΪG�������㡣
��nc=l��Ϊ��¼�ص������ݵ����Ŀ����ˣ���cΪG�������㡣
������������ֵƯ���㷨����Ӱ���㷨��ȷ�ԣ��������ؽ�����ÿ�ε����ļ������������ǽӽ��ܶȼ�ֵ��ʱ�����ݵ���Ŀ�����½��������ٶȵõ��ܴ���ߣ���������ʱ���������������ļ�ֵ�㣬��������ͬһ����ֵ�����ݵ㻮��Ϊһ�࣬ʵ�������ݵ�ķ��ࡣ
���ٵĶ�̬��ֵƯ���㷨��ֹͣ�����ǵ����ݼ���ֻʣ�¼�ֵ��ʱ���Ϳ��Խ�����������ˣ����ԱȽ�����2�ε��������ݼ����������ĸ����������������䣬��n(t) = n(t+1)ʱ����ʾ���Խ���������ͨ��ʵ�鷢�֣������ݼ��а�������ģʽʱ�����ݵ���ܻ����������㣬�������㷨��ȷ�ԡ�ͨ������£���������������ݵ�ĸ����dz��٣�ԶС����������ֵ�㴦�����ݵ��������ˣ�����ͨ���ж�������c�е�nc�������е����ݵ�鲢�����ֵ�������һ���С����ٵĶ�̬��ֵƯ���㷨�ڲ�Ӱ���㷨��ȷ�Ե�����£�ͨ���������ݼ��������������㷨�ļ�������
2 ����Ӧ��over-relaxed���α߽��Ż��㷨
2.1 ���α߽��Ż��㷨��֤��
���ڵ����ݼ���������̬�ֲ�ʱ������������ݵ������ٶ���������֤����̬�ľ�ֵƯ���㷨��һ�ֶ��α߽��Ż��㷨��������over-relaxed���������������������ٶȡ�
��ģʽʶ��ͻ���ѧϰ�����У��ܶ����ⶼ����ͨ���Ż�ij��Ŀ�꺯�����������Ŀ�꺯������ijЩ����ṹʱ���������øýṹ���õ�Ŀ�꺯���ı߽纯������ͨ���Ż��߽������Ŀ�꺯��[13]������������£��߽纯���ڲ����ռ�����Ч�����ױ��Ż�����ijЩ�㴦����Ŀ�꺯����
����2 ��q(x)ΪĿ�꺯����x��X�������ں���p(x)�����е㴦x0������q(x0) = p(x0)��������������p(x)��q(x)������p(x)����q(x)�ı߽纯����
���߽纯��p(x)����Ŀ�꺯��q(x)��������߽纯��p(x)�ļ�����ԶС��ֱ�Ӽ���Ŀ�꺯��q(x)������Ը���p(x)����߽��Ż��㷨���߽��Ż��㷨ͨ��������̬��������߽纯��p(x)�����ֵ�����Ŀ�꺯��q������֤�����ĺͶ�̬�ĸ�˹�˾�ֵƯ���㷨�Ƕ��εı߽��Ż��㷨��
����1 ��˹���ܶȹ���f(x)�ı߽纯��Ϊ��
![]() ��
��
���У�aΪ��������˹�˾�ֵƯ���㷨����߽纯��p(x)����ˣ���˹�˾�ֵƯ���㷨�Ƕ��α߽��Ż��㷨��
֤�� ����֤��p(x)�Ǹ�˹���ܶȹ��ƺ���f(x)�ı߽纯����
��r=||(x-xi)/h||2����p(x)��f(x)����Ϊr�ĺ�������ʱ��
![]()
![]() �� (6)
�� (6)
![]()
![]()
![]() �� (7)
�� (7)
kΪ��˹����������pΪr�����Ժ�������Ϊ��ƽ�档��p(x0) = f(x0)����ã�
![]() ��
��
��ʱ��p(x)��x0����f(x)���У�p(x)Ϊ��f(x)���еij�ƽ�档���ڸ�˹��������k(x)Ϊ�������ܶȹ��ƺ���f(x)�Ǹ�˹�˺����ļ�Ȩ�ͣ���ˣ�f(x)��Ϊ��������Ϊ��ƽ��p(x)���е�x0����p(x0) = f(x0)���������ط���p(x)��f(x)�����㶨��1�����ԣ�p(x)Ϊf(x)�ı߽纯����
����֤����˹�˾�ֵƯ���㷨������߽纯��p(x)��
![]() �� (8)
�� (8)
ʽ(8)��ʽ(2)��ͬ����x��x0ʱ�����е㴦![]() ��ȡ����ֵ����ˣ����ø�˹�˾�ֵƯ���㷨������ñ߽纯��p(x)�����ֵ������˹�˾�ֵƯ���㷨�DZ߽纯��p(x)������㷨��������p(x)��x�Ķ��κ���������p(x)Ϊf(x)���α߽纯������˹�˾�ֵƯ���㷨�Ƕ��α߽��Ż��㷨����̬�ľ�ֵƯ���㷨���º�����ݼ���ԭ���ݼ����ӿռ䣬��ˣ�������ͬ�����ԣ���̬�ľ�ֵƯ���㷨Ҳ�Ƕ��α߽��Ż��㷨��
��ȡ����ֵ����ˣ����ø�˹�˾�ֵƯ���㷨������ñ߽纯��p(x)�����ֵ������˹�˾�ֵƯ���㷨�DZ߽纯��p(x)������㷨��������p(x)��x�Ķ��κ���������p(x)Ϊf(x)���α߽纯������˹�˾�ֵƯ���㷨�Ƕ��α߽��Ż��㷨����̬�ľ�ֵƯ���㷨���º�����ݼ���ԭ���ݼ����ӿռ䣬��ˣ�������ͬ�����ԣ���̬�ľ�ֵƯ���㷨Ҳ�Ƕ��α߽��Ż��㷨��
2.2 ����Ӧ��over-relaxed�߽��Ż��Ľ�
��̬�ĸ�˹�˾�ֵƯ���㷨����ľ�ֵƯ���㷨��ȣ������ٶ���ߡ����ǣ����ڷ���̬�ֲ������ݣ�������������ٶȽ�������ˣ���Ҫ������������ݵ�������ٶȡ����ݶ���1��֤������̬�ĸ�˹���Ƕ��εı߽��Ż��㷨������ͨ��over-relaxed�߽������Զ�̬�ľ�ֵƯ���㷨�������ٶȽ��иĽ���Over-relaxed��̬��ֵƯ���㷨�ĵ�����ʽΪ��
![]() �� (9)
�� (9)
�����¿��������IJ���������=1ʱ��over-relaxed�߽��Ż����DZ��ľ�ֵƯ���㷨�����£�1���ʾ�Ӵ����������ʹ�����㷨�������������ֵ������̫��������㷨���ܷ�ɢ������̫С�������ӿ������ٶȵ�Ч�������ԣ������Ż��IJ�������over-relaxed�߽��Ż��㷨�Ĺؼ�������[15]֤���˵��¡�(0, 2)ʱ���߽��Ż��㷨һ��������Ȼ����������Ż��Ħµļ�����̫�����˵����㷨��Ч�ʣ������ǶԶ�̬�ľ�ֵƯ���㷨�����ݵ㲻�������������ȫ�ֵ����ŵĦ¡�Ϊ����������������ݵ�������ٶȣ��������ݼ��Ͻṹ�ı仯������Ӧ�ؼ���²�����ͨ���������ݼ���ֱ���ı仯������Ӧ�ظ��¸���ά�ȵIJ�����
����3 ����dά��ŷ���ռ�Rd�еIJ�����S = {xi, 1��i��n}��xi = {xi1,��, xid }������� ={��j = max(xij) �C min(xij), i = 1, ��, n, j = 1, ��, d }����Ϊd��d�ĶԽǾ���jΪ�Խ����ϵ�Ԫ�أ��Ʀ�Ϊ���ݼ���ֱ����
t�ε���������ݼ�S(t)��ֱ��Ϊ��(t)���ݿ��ٶ�̬��ֵƯ���㷨��t+1�ε��������ݼ�S��(t+1)��ֱ��Ϊ��(t+1)��2�����ݼ�ֱ��֮��Ϊ�� =��(t) /��(t+1)��Ϊ�˱�֤��������������ٶȣ����ݦ��������Ӧ�¡�����j(j = 1, ��, d)�ܴ���˵����Ϊ��������jΪ1������j(j = 1, ��, d)��С��˵����Ϊ��������ˣ�Ҫ�Ӵ����ݵ��ڸ÷����ϵĵ���������Ϊ�˱�֤������һ���ԣ�������Ҫ�����е����ݵ����Ӳ���������Ҫ���������ϴ��ڱ߽�����ĵ����Ӳ�������ˣ�over-relaxed��̬�ľ�ֵƯ���㷨�IJ���Ϊ��
a. ���ݹ�ʽ(4)�����ֵƯ�ƵIJ���M(x)���������ݼ�S���µ�S�䣻
b. ����S��S�����ά�ȵ�ֱ��������æ�i (i=1, ��, d)�ͦõ�ƽ��ֵ�á䣬�����i=�á�/��i��
����i��1����˵�����ݼ��ڵ�iά����ֱ���仯�ܴ�Ϊ���������нϿ�������ٶȣ�����Ҫ���м��٣���i��1��
��1����i��2����˵�����ݼ��ڵ�iά��ֱ���仯����Ϊ������i����i��
����i��2��Ϊ�˱�֤�����㷨����ɢ����i��2��
c. �������ݼ�S�����ݵ���ݶ�ֵ![]() ��ƽ���ݶ�ֵ
��ƽ���ݶ�ֵ![]() �������ݵ���ݶȴ���ƽ���ݶ�ֵ������Ϊ��Щ���ݵ�Ϊ�߽紦�����ݵ㣬��ô��ڱ߽紦�����ݵ����ţ�
�������ݵ���ݶȴ���ƽ���ݶ�ֵ������Ϊ��Щ���ݵ�Ϊ�߽紦�����ݵ㣬��ô��ڱ߽紦�����ݵ����ţ�
d. ���ݦ�����߽紦�����ݵ�IJ������������ݼ�S��
e. �Ƚ�����2�����ݼ������ݵ���Ŀ���������ֹͣ����������ѭ��ִ�в���a��
3 �����ٶȺ��Ӷȷ���
�����ݼ�������̬�ֲ�ʱ�����ٶ�̬��ֵƯ���㷨ʹ���ݼ��ķ�����������0������
 �� (10)
�� (10)
��ˣ����ٶ�̬��ֵƯ���㷨���㳬���������������ݼ������Ӹ�˹�ֲ�ʱ��Over-relaxed���ٺ�����ݼ������㳬��������������̬�ĸ�˹�˾�ֵƯ���㷨�У����ݼ��ķ���ʼ�ձ��ֲ��䣬![]() ��1����ˣ����ñ��ľ�ֵƯ���㷨ʱ����������[12]��
��1����ˣ����ñ��ľ�ֵƯ���㷨ʱ����������[12]��
����ͨ�������㷨�����ݵ���ʵĴ����������㷨�ĸ��Ӷȡ��ھ�̬�ľ�ֵƯ���㷨�У����ݵ�ļ������ԼΪt1dn2(���У�t1Ϊƽ������������dΪ���ݵ��ά����nΪ���ݵ�ĸ���)����̬�ľ�ֵƯ���㷨�У����ݵ�ķ��ʴ���ԼΪt2dn2(���У�t2Ϊ��̬��ֵƯ���㷨�ĵ�������)����Ϊ���ö�̬�ľ�ֵƯ���㷨ʱ�Գ����Ե��ٶ������������þ�̬�ľ�ֵƯ���㷨ʱ�����Ե��ٶ���������ˣ�t1��t2�����ٵĶ�̬��ֵƯ���㷨�����ݵ�ļ������ԼΪ![]() (���У�n(t)Ϊÿ�ε������ݵ�ĸ�����n��n(t)��n(t+1), t = 1, ��, t2)��over-relaxed���ٶ�̬��ֵƯ���㷨�����ݵ�������Ϊ
(���У�n(t)Ϊÿ�ε������ݵ�ĸ�����n��n(t)��n(t+1), t = 1, ��, t2)��over-relaxed���ٶ�̬��ֵƯ���㷨�����ݵ�������Ϊ![]() ��t2��t3������ٵĶ�̬��ֵƯ���㷨��ȣ�ÿ�ε������������ݵ����Ŀ n(t)��n��(t)��
��t2��t3������ٵĶ�̬��ֵƯ���㷨��ȣ�ÿ�ε������������ݵ����Ŀ n(t)��n��(t)��
4 ʵ����
����Matlab���㷨�������㣬�����˹��ϳɵ����ݽ���ʵ�顣ͼ1��ʾΪ���ٶ�̬��ֵƯ�ƵĹ��̡�ͼ2��ʾΪover-relaxed�Ŀ��ٶ�̬��ֵƯ���㷨�Ĺ��̡���ͼ2���Կ�����������������ݵ�������ٶ���ߡ�

(a) ��1�����(b) ��2�����(c) ��4�����(d) ������
ͼ1 ���ٶ�̬��ֵƯ���㷨
Fig.1 Fast dynamic MS
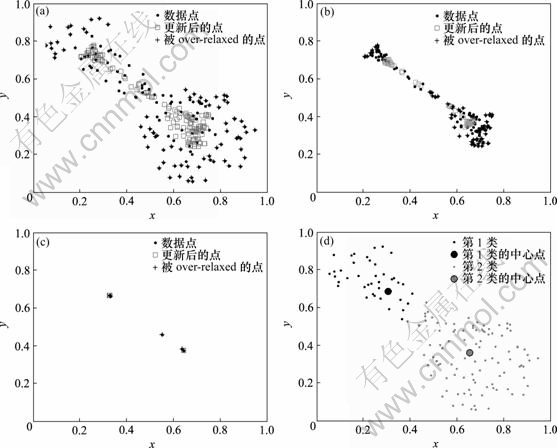
(a) ��1�����(b) ��2�����(c) ��4�����(d) ������
ͼ2 Over-relaxed���ٶ�̬��ֵƯ���㷨
Fig.2 Over relaxed fast dynamic MS
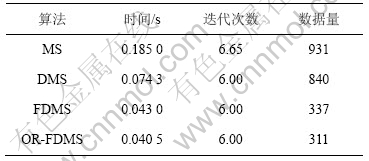
����ֵƯ���㷨(MS)����̬�ľ�ֵƯ���㷨(DMS)�����ٶ�̬��ֵƯ���㷨(FDMS)��over-relaxed�Ŀ��ٶ�̬��ֵƯ���㷨(OR-FDMS)�ļ���ʱ�䡢�������������ݵ�ķ��ʴ������1��ʾ���ɼ���Over-relaxed���ٶ�̬��ֵƯ���㷨����ľ�ֵƯ���㷨�����Ķ�̬Ư���㷨�Լ����ٵĶ�̬��ֵƯ���㷨��ȣ������ٶȷֱ����78.1%��45.5%��5.81%��
��1 �㷨�Ƚ�
Table 1 Comparisons of performance of algorithms
5 �� ��
a. �ڱ��ľ�ֵƯ���㷨�������������ݼ���̬���»��ƣ�ÿ�ε��������ݼ����µ���ֵƯ�Ƶ㣬ʵ���˳����Ե������ٶȡ����ۼ���һ������ݵ�ϲ�Ϊ�����㣬�������ݵ����Ŀ��������ÿ�ε����ļ�������������㷨��Ч�ʡ�
b. �����ݼ�Ϊ����̬�ֲ�ʱ�������������ٶȵ��ڷ�������������ٶȣ�����over-relaxed���������������������ݵ�ĵ������������������ݼ���ֱ������Ӧ����over-relaxed��������һ��������������ϵ������ٶȡ�
�ο����ף�
[1] Fukunaga K, Hostetler L D. The estimation of the gradient of a density function, with applications in pattern recognition[J]. IEEE Transactions on Information Theory, 1975, 21(1): 32-40.
[2] Cheng Y Z. Mean shift, mode seeking, and clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995, 17(8): 790-799.
[3] Comaniciu D. An algorithm for data-driven bandwidth selection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(2): 281-288.
[4] Georgescu B, Shimshoni I, Meer P. Mean shift based clustering in high dimensions: A texture classification example[C]//IEEE International Conference on Computer Vision. New York: IEEE CS Press, 2003: 456-463.
[5] Comaniciu D, Meer P. Mean shift: A robust approach toward feature space analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(5): 603-619.
[6] ����, �� ��, �����. һ�ֻ����Ӿ����Ե�ң��ͼ��ָ�[J]. �����ѧ��, 2005, 28(10): 1687-1691
WANG Zhao-hu, LIU Fang, JIAO Li-cheng. A remote sensing image segmentation algorithm based on vision information[J]. Chinese Journal of Computers, 2005, 28(10): 1687-1691.
[7] Comaniciu D, Ramesh V, Meer P. Kernel-based object tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(5): 564-575.
[8] ������, �� ��, �� ־, ��. Mean-Shift�����㷨�к˺����������Զ�ѡȡ[J]. ����ѧ��, 2005, 16(9): 1542-1550.
PENG Ning-song, YANG Jie, LIU Zhi, et al. Automatic selection of kernel-bandwidth for Mean-Shift object tracking[J]. Journal of Software, 2005, 16(9): 1542-1550.
[9] Collins R T. Mean-Shift blob tracking through scale space[C]// Processings 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Los Alamitos: IEEE Computer Society, 2003, 2: 234-240.
[10] ������, �⸣��, ��ռ��. ��ֵƯ���㷨��������[J]. ����ѧ��, 2005, 16(3): 365-374.
LI Xiang-ru, WU Fu-chao, HU Zhan-yi. Convergence of a mean shift algorithm[J]. Journal of Software, 2005, 16(3): 365-374.
[11] Carreira-Perpinan M A. Acceleration strategies for Gaussian mean-shift image segmentation[C]//Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE CS, 2006: 543-549.
[12] Zhang K, Kwok J T, Tang M. Accelerated convergence using dynamic mean shift[C]//In the 9th European Conference on Computer Vision. New York: Springer, 2006: 257-268.
[13] Fashing M, Tomasi C. Mean shift is a bound optimization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(3): 471-474.
[14] Carreira-Perpinan M A. Gaussian mean shift is an EM algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(5): 767-776.
[15] Shen C, Brooks M J, Hengel A. Fast global kernel density mode seeking with application to localization and tracking[C]//IEEE International Conference on Computer Vision. Los Alamitos: IEEE Computer Society, 2005: 1516-1523.
�ո����ڣ�2008-03-08�������ڣ�2008-06-30
������Ŀ��������Ȼ��ѧ����������Ŀ(60433030)
ͨ�����ߣ��� ӱ(1980-)���У����������ˣ���ʦ������������ʵ���ٳ��С��˹����ܺ���м�����о����绰��0731-2656373��E-mail: Zhaoying511@126.com
