DOI: 10.11817/j.issn.1672-7207.2018.06.014
面向DFMC的广义模块间包含性关系分析
彭卫平,蒋瑞,雷金,陈磊,张秋华,胡向阳,窦俊豪
(武汉大学 动力与机械学院,湖北 武汉,430072)
摘要:为了有效支持产品变型设计和大批量定制设计,将产品平台中的广义模块按不同属性分成6类,针对分类得到的参数化模型进行包含性关系挖掘。对参数化模型间的包含性关系分析主要包括4个步骤:1) 从广义模块中抽取各类代码作为数据表的字段,将各类零部件的序号作为数据表的事务,构建事务数据表;2) 将事物数据表转化为0-1矩阵,运用Apriori算法找出频繁项集;3) 通过比较频繁k-项集内部的置信度,得到参数化模型之间的强关联关系;4) 得到模型间包含性关系。最后以阀门产品为例,对提出的包含性分析方法进行验证,并输出阀门各个参数化模型间的包含性关系。研究结果表明:经挖掘得到的包含性关系有利于产品与工艺资源的快速检索和再利用,便于产品与工艺的精确和非精确配置,进而促进企业大批量定制产品战略的有效实施。
关键词:广义模块;参数化模型;包含性关系;Apriori算法;
中图分类号:TH122 文献标志码:A 文章编号:1672-7207(2018)06-1414-10
Inclusive relationship analysis of generalized module oriented DFMC
PENG Weiping, JIANG Rui, LEI Jin, CHEN Lei, ZHANG Qiuhua, HU Xiangyang, DOU Junhao
(School of Power and Mechanical Engineering, Wuhan University, Wuhan 430072, China)
Abstract: In order to effectively support the product variant design and the mass customization design, the generalized modules in the product platform were divided into six parameterized models based on different attributes, mining inclusive relationship among these parameterized models. The inclusive relationship analysis mainly includes four steps: 1) Various types of codes were extracted from generalized modules as the code segments, and the serial number of components was used as the transaction to construct the transaction data table; 2) The transaction data table was converted to 0-1 matrix and the frequent item sets was obtained by the Apriori algorithm; 3) The confidence scores in the frequent k-item sets were compared to get the strong relationships; 4) The relationship among the parameterized models was obtained. Finally, the feasibility and effectiveness of the proposed method were verified by a case study of valve. The results show that the inclusive relationship analysis is conducive to rapidly reuse products and process resources, to facilitate the accurate and inaccurate product and process configuration, and to promote the effective implementation of enterprise mass customization strategy.
Key words: generalized module; parameterized model; inclusive relationship; Apriori algorithm
大批量定制设计(design for mass customization,DFMC)是实现大批量定制生产的重要技术,它不再将单一产品作为设计的对象,而是着眼于一类产品[1]。产品模块是产品平台的基本组成元素之一,在面向DFMC中具有十分重要的作用。随着产品复杂程度及用户个性化需求的不断提高,传统物理模块已经难以满足市场的要求。针对传统模块化的局限性,许多学者将参数化技术引入模块化设计中,提出广义模块化设计方法,并成为目前研究的热点。徐燕申等[2]提出了广义模块化的设计思想,建立了广义模块化设计的概念体系。参数化模块中包含性关系的研究直接将产品的功能模型、结构模型和工艺模型集成在一起,支持面向用户进行产品与工艺的创新设计、快速变形、精确配置与非精确配置。李中凯等[3]构建自顶向下映射和自底向上反馈模型,提出客户需求驱动的柔性平台功能模块识别方法。江长华[4]等提出了工艺模块化和工艺模块的概念,提高工艺设计效率,实现工艺的快速制定。邱坤华等[5]对零件工装进行模块划分并进行参数化设计,可以通过比对零件特征以及工艺找到对应产品族,达到快速变型设计的目的。杨卓峰[6]对系统的总体结构和各模块功能进行设计,并从数据库设计入手,开发了面向大规模定制的工艺信息系统。LUH等[7]提出四层次结构关系并用统一的方式描述产品结构模块。WANG等[8]提出了一种产品结构关系用于发展多样化模块化产品。LOPEZ-HERREJON等[9]提出依据功能需求运用参数重构模块特征与联系,并定义了8种模型。ALBLAS等[10]提出一种平台技术用于功能与工艺的关系,用于辅助半导体产品的产品族。SCH NSLEBEN[11]提出了面向Design for order参数化定制方法。在算法研究方面,谢亮等[12-16]分别从关系数据集、Fp-Tree算法、Apriori改进算法、Fp-Growth算法应用到实例等角度进行了一系列关联关系的挖掘。虽然现有研究提出了许多方法产品平台并对产品族进行了结合,但其研究对象多是用于发现产品功能、结构、工艺之间的内在联系,并用不同的方法论证参数化与理模型之间的包含性关系,难以体现参数化模型间的内在关系。本文作者以PLM数据库作为数据来源,不仅将参数化与产品平台相结合,而且基于Apriori算法,对隐藏在参数化模型间包含性关系进行研究,挖掘得到了参数化模型间的内在关系,直接将产品的功能模型、结构模型和工艺模型集成在一起,可促进企业大批量定制产品战略的有效实施。
NSLEBEN[11]提出了面向Design for order参数化定制方法。在算法研究方面,谢亮等[12-16]分别从关系数据集、Fp-Tree算法、Apriori改进算法、Fp-Growth算法应用到实例等角度进行了一系列关联关系的挖掘。虽然现有研究提出了许多方法产品平台并对产品族进行了结合,但其研究对象多是用于发现产品功能、结构、工艺之间的内在联系,并用不同的方法论证参数化与理模型之间的包含性关系,难以体现参数化模型间的内在关系。本文作者以PLM数据库作为数据来源,不仅将参数化与产品平台相结合,而且基于Apriori算法,对隐藏在参数化模型间包含性关系进行研究,挖掘得到了参数化模型间的内在关系,直接将产品的功能模型、结构模型和工艺模型集成在一起,可促进企业大批量定制产品战略的有效实施。
1 广义模块中的参数化模型及其包含性关系
本文中的广义模块来源于PLM数据库,通过数据挖掘的方法获得[2, 16],是传统模块的拓展体,作为产品功能、几何拓扑结构、工艺信息等的载体,通过赋予产品结构参数和变量来获得可参数化变形的参数化模型。在参数化产品平台中的广义模块将产品的节点信息、主属性表、参数表、参数驱动模型、工艺卡片和数据字典等整合在一起,具体形式如图1所示[17]。
在产品平台中由不同属性(结构、功能和工艺)的广义模块组成产品模型,若以结构来分,结构相同的称为参数化同构类SA,结构不同的称为参数化非同构聚类CA;同理,若按功能分,功能相同的称为参数化等效类SF,功能不同的称为参数化非等效聚类CF;若按工艺分,工艺相同的称为参数化等价类SP,工艺不同的称为参数化非等价聚类CP。但仅由1种属性标准分类的模型中也会包含其他的属性。
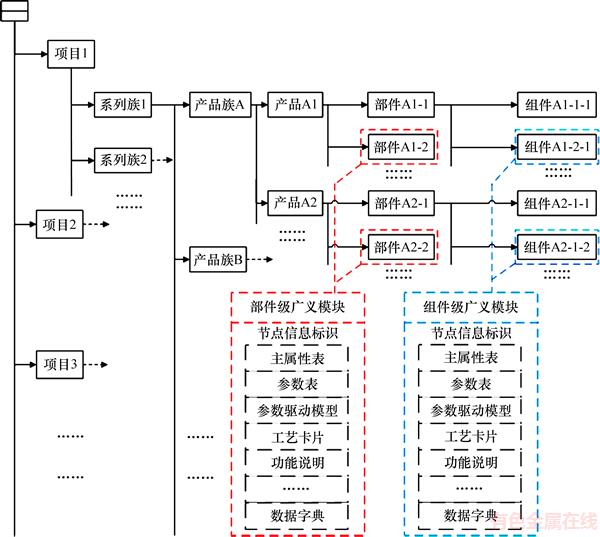
图1 基于PLM数据库的参数化产品平台部分结构示意图
Fig. 1 Structure schematic of parameterized product platform based on PLM database
非等效聚类模型是功能不同的模块集合,每个模块包含的结构和工艺信息都不同,其与同构类和等价类之间关联的部分太少,故对其进行包含性分析没有实际意义。同理,非等价聚类模型与同构类和等效类之间进行包含性分析也没有实际意义。故以上的6类参数化模型间的包含性关系只有10种[18],如表1所示。参数化模型间包含性关系示意图如图2所示。
表1 参数化模型间的10种包含性关系
Table 1 Ten kinds of inclusive relationship among parameterized models
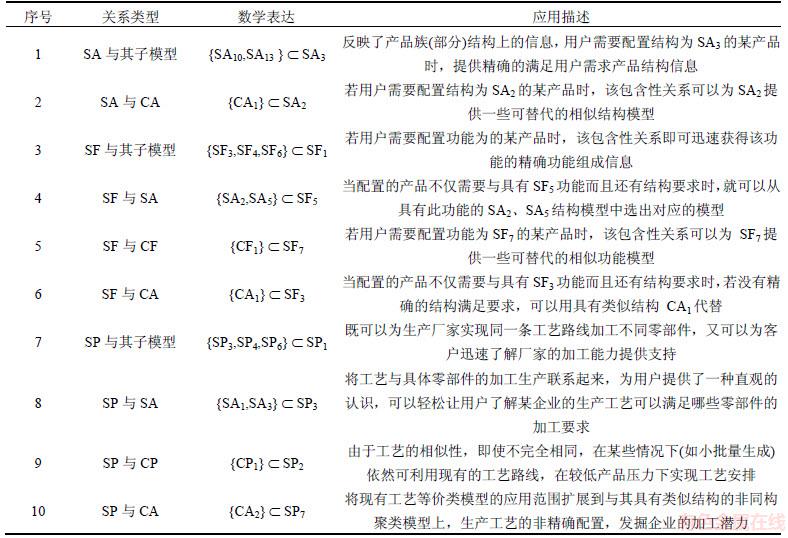
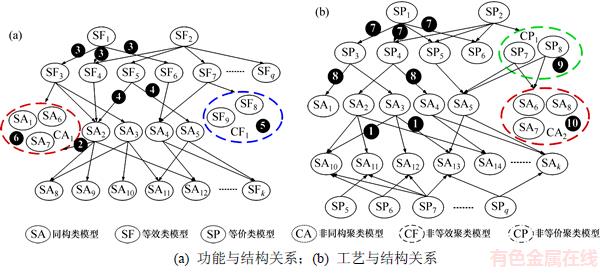
图2 参数化模型间包含性关系示意图
Fig. 2 Schematic diagram of inclusive relationships among parameterized models
2 参数化模型包含关系分析
针对上述模型,在分析其包含关系时,首先对数据进行处理构建事务数据表,其次运用Apriori算法生成项集,再根据实际情况设定合适的支持度和置信度找出包含性关系,最后得出包含性关系。以图2(a)中SF1~SF5这5个等效类参数化模型为例,通过以下分析过程最终得到图2(a)所示中SF1~SF5之间的包含性关系。具体步骤如下。
第1步:事务数据表的构建。
6类参数化模型采用树形存储结构,双亲表示法为具体方式直观地表现出节点的功能、结构与工艺属性。在对等效类参数化模型间的包含性关系进行分析前,应从广义模块中提取等效类参数化模块的相关信息,如表2所示。
从表2中分别提取SF1~SF5这5个等效类参数化模型的父节点和模块标识,构成基本信息,见表3。
从表3中抽取模块标识和等效类标识分别作为表4的行和列,在模块标识与功能标识对应处记为1(表示模块中存在此功能信息),不对应处记为0(表示模块中没有对应的功能信息)。
由表4可见每个模型包含的功能信息,但要找出模型间具体的包含关系,还需找出功能模块的父节点处模块的功能信息。同理,查找每一个模型的父节点,再抽取表2中与这些父节点相同的等效类标识作为表的列,以等效类标识作为表的行,以同样形式构建表5。若无父节点,则整条记录记为空。这样处理的目的是将其转化适宜处理的矩阵形式,方便后续算法的运行。
表2 广义模块中等效类参数化模型提取信息表
Table 2 Extracting information table from equivalent class parameterized model in generalized module
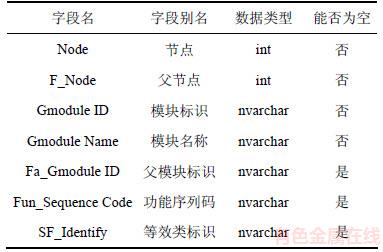
表3 等效类模型的相关信息表
Table 3 Information table of equivalent class model
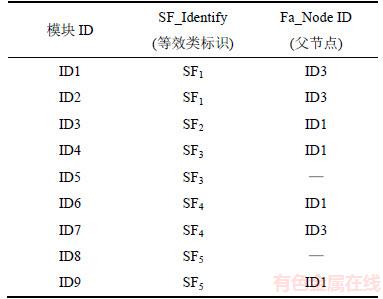
表4 事务数据表I
Table 4 Transaction data table I
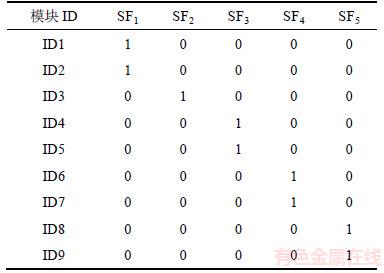
表5 事务数据表II
Table 5 Transaction data table II
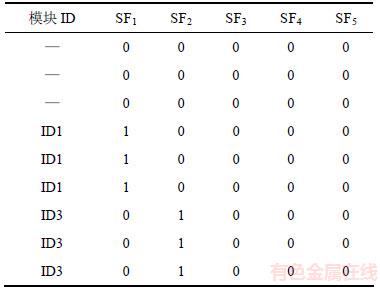
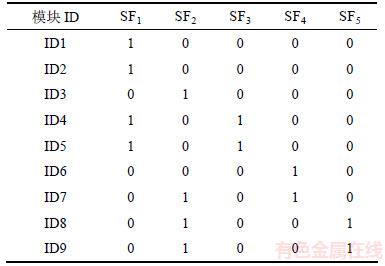
将表4和表5分别转化为0-1矩阵,并将2个矩阵相加得到矩阵H,同时将矩阵H转换成最终用于挖掘的事务数据表,如表6所示。

表6 最终事务数据表
Table 6 Final transaction data table
第2步:候选项集与频繁项集的生成。
经典的关联规则挖掘算法主要有Apriori算法和FP-growth算法[15]。Apriori多次扫描数据库,利用候选项集来产生频繁项集,FP-growth利用树形结构得到频繁项集。因FP-growth的树形结构需要自顶向下生成,而本文所分析的包含性关系采用自底向上处理,若用FP-growth算法则要更多的指针来建立树形结构,占用内存大且效率低,故本文采用Apriori算法。
在参数化模型间的包含性分析中,先运用Apriori算法生成候选项集与频繁项集,再从满足要求的频繁项集中挖掘出包含关系。将具有潜在关联关系的参数化模型称为候选项集,候选1-项集集合是由每一个参数化模型构成的,不具有实际意义,只用于计算过程;候选2-项集集合由各个参数化模型两两组合而成,候选k-项集依此类推。频繁项集是在候选项集中挖掘出的具有确定关联关系的参数化模型,频繁k-项集集合由满足最小支持度设定的候选k-项集构成,频繁1-项集只作为生成候选2-项集的中间数据;频繁2-项集是具有确定的参数化模型间的两两关联关系,频繁-项集依此类推。因本文采用了小规模的数据用于实例,故将最小支持数设定为1,以表6中的事物数据为例对具体生成步骤说明。
从表6可知,该事务数据表的每个事务仅包含1对项目的关联关系。因此,候选项集和频繁项集只需生成2次,即只需生成候选1-项集、频繁1-项集、候选2-项集和频繁2-项集。这样既规避了由频繁(k-1)-项集生成的候选k-项集时,候选项集呈指数增长的状态,又克服了需要多次扫描数据表的弊端。
1) 将表6中模型的数据转化为0-1矩阵H;
2) 生成候选1-项集C1={{SF1},{SF2},{SF3},{SF4},{SF5}};
3) 分别对每行和每列求和,列求和即为支持数,行求和即为模型数,并将模型的支持数按降序排列,得到矩阵H1;

4) 设最小支持数为1,求频繁1-项集 ,则L1={{SF1},{SF2},{SF3},{SF4},{SF5}};
5) 求频繁2-项集L2,删除H1中模型数数小于2的行,保留其余行,得到矩阵H2;

6) 对频繁1-项集中的模型进行组合,
C2={{SF1,SF2},{SF1,SF3},{SF1,SF4},{SF1,SF5},{SF2,SF3},{SF2,SF4},{SF2,SF5},{SF3,SF4},{SF3,SF5},{SF4,SF5}};
7) 计算候选2-项集的支持数,
Support _Count(SF1∩SF2)=0,
Support_Count(SF1∩SF3 )=2,
Support_Count(SF1∩SF4)=1,
Support_Count(SF1∩SF5)=0,
Support_Count(SF2∩SF3)=0,
Support_Count(SF2∩SF4)=1,
Support_Count(SF2∩SF5)=2,
Support_Count(SF3∩SF4)=0,
Support_Count(SF3∩SF5)=0,
Support_Count(SF4∩SF5)=0,
8) 找出不小于最小支持数的项,则频繁2-项集L2={{SF1,SF3},{SF1,SF4},{SF2,SF4},{SF2,SF5}}。
第3步:强关联规则。
在频繁项集的生成过程中,事务数据表的构建较好地规避了经典Apriori算法可能生成过于庞大的候选项集及多次扫描数据表这2个瓶颈。但这样处理方式也会存在弊端,即频繁2-项集虽然明确显示了2个参数化模型之间具有包含性关系,但并没有体现包含与被包含的关系,也不能直接通过设定最小置信度来判断。
通过分析不难发现在每个频繁2-项集的2个参数化模型中,处于较高层级的参数化模型具有更高的置信度。因此,可以通过比较频繁2-项集内部的2个置信度,得到2个参数化模型之间的强关联关系。仍然以表6的事物数据为例,比较每组频繁项集置信度:

输出强关联规则:{SF3}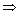 {SF1},{SF4}{SF1},{SF4}{SF2},{SF5}{SF2}。
{SF1},{SF4}{SF1},{SF4}{SF2},{SF5}{SF2}。
第4步:输出结果。
得到强关联关系以后,最终的包含性关系为:{SF3,SF4} {SF1},{SF4,SF5}{SF2}。
{SF1},{SF4,SF5}{SF2}。
3 参数化模型包含关系分析算法
Apriori算法使用逐层迭代的方式,即其中的k-项集被用于探索(k+1)-项集。在包含性分析中,首先扫描事务数据表,统计每个参数化模型标识的支持度,并收集满足最小支持数的模型标识,找出所有频繁1-项集的集合,并记为L1。以此为起点,利用递推关系,直到不能找到频繁k-项集为止。
参数化模型包含性分析的算法流程图如图3所示。
图3 包含性关系分析算法流程图
Fig. 3 Algorithm flowchart of inclusive relationship analysis
算法伪代码如下。
1) 使用逐层迭代的方法,基于候选项集找出频繁项集。
输入:事物数据表D和最小支持度阀值(min_sup).
输出:D中的频繁项集L.
1. 方法:L1=find_frequence_1_itemsets(D) ; //扫描D,找到频繁1-项集
2. For(k=2;Lk-1≠ , k++) { //若频繁k-1不为空集,继续循环
, k++) { //若频繁k-1不为空集,继续循环
3. C =Apriori_gen(Lk-1,min_sup); //通过Apriori_gen过程产生候选项
4. For all transaction t D { //扫描D,进行计数
5. Ck =subset(Ck, t); //得到t的子集,它们是候选
6. For each candidate c∈Cr;
7. c.count++; //对每个候选累加计数
8. }
9. Lk={c∈Ck | c.count min_sup} //得到满足最小支持度的候选
10. }
11. Renturn L=UkLk; //形成频繁项集集合
12. Procedure apriori_gen(Lk-1:frequnce(k-1)itemset);
13. For each itemset l1∈Lk-1 //通过Apriori_gen过程产生候选
14. For each itemset l2∈Lk-1 //对于频繁k-1中的两个项
15. If(l1[1]=l2[1])^ … ^(l1[k-2]=l2[k-2])^(l1[k-1]=l2[k-1]) then{
16. C=l1  l2; //连接步骤,产生候选
l2; //连接步骤,产生候选
17. If has_infrenquent_subset(C,Lk-1) then
18. Delete c; //剪枝步骤,删除非频繁候选
19. Else add to c to Ck; //剪枝步骤,其余作为频繁候选
20. }
21. Return Ck;
22. Procedure has_infrequent_subset(c: candidate k itemset; Lk-1: frenquent (k-1) itemset)
23. For each(k-1)subset s of c //通过 has_infrequent_subset过程测试
24.  //是否为频繁项集
//是否为频繁项集
25. Return TURE;
26. Return FALSE;
2) 生成强关联规则。
输入:频繁项集L和最小置信度(min_conf).
输出:强关联规则.
1. H1≠Φ
2. For each frequent(k) itemset fk,k≥2 { //对于每一个k≥2的频繁项集
3. A=(k-1)itemsets ak-1 such that ak-1fk; //A是任意一个fk中的频繁项集
4. For each ak-1∈A { //对于A中的每一个项
5. Conf=support(fk)/support(ak-1); //计算其置信度
6. IF(conf≥min_conf ) then { //得到满足最小置信度的关系
7. Output the rule 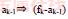
8. With confidence=conf and support=support(fk)
9. Add(fk-ak-1) to H1 //输出关系到H1
10. }
11. }
12. Call ap_genrules(fk-ak-1)
13. }
14. Procedure ap_genrules(fk:frequent(k)itemset,Hm :set of m_item consequents)
15. If(k> m+1) then{ //通过ap_genrules过程
16. Hm+1= ap_gen(Hm);
17. For each hm+1=Hm+1 {
18. Conf=support(fk)/support(fk-hm+1); //计算其置信度
19. If[conf(fk-hm+1)≥conf(hm+1) ]; then //比较各项其置信度大小
20. Out put the rule fk-hm+1  hm+1
hm+1
21. With confidence=conf and support=support(fk);
22. Else
23. Delete hm+1 from Hm+1 //删除非强关联规则
24. }
25. Call ap_genrules(fk,Hm+1)
26. }
4 应用举例
以阀门产品为例,运用上述分析方法,验证某蝶阀产品模型等效类与其子模型间的包含性关系。此蝶阀功能等效类模型如图4所示。
该映射关系用于蝶阀产品的创新及精确确置。表7所示为此蝶阀产品的部分相关信息表。
第1步:事务数据表的构建。
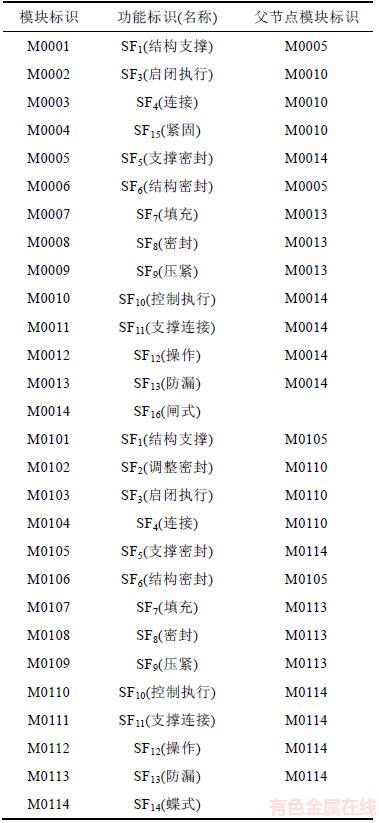
从表7中抽取名为模块标识和等效类标识的字段,如功能为结构支撑的SF1的模块标识分别有M0001,M0101,依次将这些信息写入如表4所示的表中。从表7中查找每个模块标识的父节点标识,再抽取广义模块表中与这些父节点标识相同的模块标识及其等效类标识。例如:模块标识为M0001的SF1的父节点标识为M0005,而模块标识为M0005的模块为SF5,且其父节点为M0014。将此标识及其父节点的关系存于表5中。
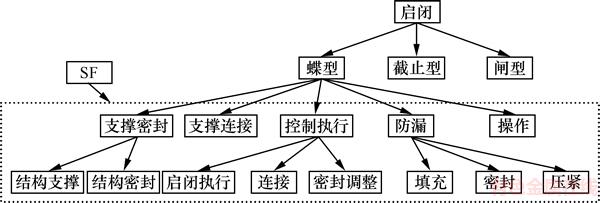
图4 某蝶阀产品功能等效类模型关系图
Fig. 4 Functional equivalent class model of a butterfly valve product
表7 某蝶阀产品部分相关信息表
Table 7 Part of information table of butterfly valve
第2步:候选项集与频繁项集的生成。
1) 将根据上述方法得到的2个事务数据表分辨转化为0-1矩阵,并将2个矩阵相加并分别对行和列求和得到最终用于挖掘的矩阵H1:

2) 生成候选1-项集,得到每个蝶阀功能模块的数据:
C1={{SF1},{SF2},{SF3},{SF4},{SF5},{SF6},{SF7},{SF8},{SF9},{SF10},{SF11},{SF12},{SF13},{SF14},{SF16}};
3) 分别对行和列求和,列求和即为支持数,行求和即为模型数,并将模型的支持数按降序排列。
4) 最小支持数为1,求频繁1-项集L1,得到满足条件的模型,则频繁项集:
L1={{SF1},{SF2},{SF3},{SF4},{SF5},{SF6},{SF7},{SF8},{SF9},{SF10},{SF11},{SF12},{SF13},{SF14},{SF16}};
5) 频繁2-项集L2,删除H1中项目数小于2的行,保留其余行,得到存在有包含性关系的H2矩阵;

6) 对频繁1-项集中的项进行组合,得到候选2项集,计算候选2-项集的支持数,找出不小于最小支持数的项,得到两两相关的产品模型,则频繁项集为
L2={{SF1,SF16},{SF2,SF5},{SF3,SF5},{SF4,SF10},{SF5,SF10},{SF6,SF10},{SF7,SF10},{SF7,SF13},{SF8,SF13},{SF9,SF13},{SF10,SF13},{SF10,SF14},{SF11,SF14},{SF11,SF16},{SF12,SF14},{SF12,SF16},{SF13,SF14},{SF13,SF16}}。
第3步:强关联规则。
比较每组置信度的大小输出强关联规则:{SF1}{SF5},{SF6}{SF5},{SF2}{SF10},{SF3}{SF10},{SF4}{SF10},{SF7}{SF13},{SF8}{SF13},{SF9}{SF13},{SF11}{SF14},{SF12}{SF14},{SF13}{SF14}。
第4步:输出结果。
得到强关联关系以后,最终的包含性关系为{SF1,SF6}{SF5},{SF2,SF3,SF4}{SF10},{SF7,SF8,SF9}{SF13},{SF11,SF12,SF13}{SF14},将所得到的关系见表8。
从表8可知:
1) 支撑密封功能的SF5包含结构支撑SF1和结构密封SF6功能。当用户需要配置功能为支撑密封功能的某产品时,根据表中的包含性关系即可迅速获得匹配的精确功能组成信息:结构支撑SF1和结构密封SF6,再根据具体需要选择精确的功能。更好地体现了此包含性分析在产品精确配置中的应用。
表8 某蝶阀产品功能等效类模型包含性关系结果
Table 8 Results of inclusive relationship for function equivalence class model of butterfly valve

2) 控制执行功能的SF10包含调整密封SF2、启闭执行SF3和连接功能SF4。当用户需要配置功能为控制执行功能的某产品时,便可迅速获得此功能的精确功能,根据需要选择1个最符合产品需要的模型。
3) 防漏功能SF13包含填充SF7、密封SF8和压紧功能SF9,当用户需要配置防漏功能的某产品时,便可从填充、密封、压紧功能选择1个最符合产品需要防漏模式的模型。
4) 蝶式阀门SF14包含支撑连接SF11、操作SF12和防漏SF13功能。当用户需要配置启闭类型的蝶式阀门时,便从支撑连接、操作和防漏等方面考虑匹配1个最符合实际需求蝶阀。
将处理好的数据集导入Weka中,运行得到结果,部分结果如图5所示。
通过将参数化模型转化成数学模型进行分析,可以得出功能不同的参数化模型存在功能可以相互替换的包含关系,而这种规律往往隐含在大量产品数据中难以发现。

图5 功能模型数据在Weka中的运行结果
Fig. 5 Results of functional model data in Weka
通过对产品模块功能、结构、工艺属性的划分,将产品配置转化为模型内部关键属性之间的包含性关系探索的问题。根据客户需求对产品属性进行映射,实现了一种结构化的、分阶段的配置生成方法。实验表明,该方法能够有效地将用户要求分步骤的转化为产品的属性约束,从而完成产品配置的过程。结构和工艺模块的包含性关系的应用也是如此。
5 结论
1) 对广义模块进行分类,得到结构同构类、非同构聚类模型,功能等效类、非等效聚类模型和工艺等价类、非等价聚类模型6类模型。将这6类模型进行参数化定义与表达,对6类模型间存在的10种包含性关系进行了具体分析。
2) 事物数据表的构建完成了模块产品数据表达的矩阵化,避免了经典Apriori算法可能生成过于庞大的候选项集及多次扫描数据库这2个瓶颈,提高了算法的效率,并有助于对模型间包含性关系的挖掘。
3) 通过对阀门产品中蝶阀模块间功能等效类和等效类包含性分析,得到了功能等效类模型之间具体的包含性关系。包含性分析结果能有效获得用户所需此蝶阀产品功能模块的精确组成信息,支持产品的精确配置,结果证明了本方法的有效性。
参考文献:
[1] 马辉, 张树有, 谭建荣, 等. 面向大批量的产品可拓物元模型[J]. 计算机辅助设计与图形学学报, 2005, 17(10): 2299-2304.
MA Hui, ZHANG Shuyou, TAN Jianrong, et al. An extension matter-element model of product family for mass customi-zation[J]. Journal of Computer Aided Design & Computer Graphics, 2005, 17(10): 2299-2304.
[2] 徐燕申, 侯亮, 张连洪, 等. 液压机广义模块化设计原理及其应用[J]. 机械设计, 2001, 18(7): 1-3.
XU Yanshen, HOU Liang, ZHANG Lianhong, et al. Theory of the generalized modular design of hydraulic press and it's application[J]. Journal of Machine Design, 2001, 18(7): 1-3.
[3] 李中凯, 程志红, 杨金勇, 等. 客户需求驱动的柔性平台功能模块识别方法[J]. 重庆大学学报(自然科学版), 2012, 35(9): 22-29.
LI Zhongkai, CHENG Zhihong, YANG Jinyong, et al. A method for identifying flexible platform function blocks driven by customer requirements[J]. Journal of Chongqing University (Science and Technology), 2012, 35(9): 22-29.
[4] 江长华, 常品要. 基于模块化的快速工艺制定[J]. 模具工业, 2011, 37(11): 43-47.
JIANG Changhua, CHANG Pinyao. Rapid process development based on modularity[J]. Die & Mould Industry, 2011, 37(11): 43-47.
[5] 邱坤华, 倪炎榕, 明新国, 等. 基于产品族参数化模块的飞机零件工艺装备变型设计技术[J]. 机械设计与研究, 2015(4): 129-133.
QIU Kunhua, NI Yanrong, MING Xinguo, et al. Based on the product family parameterization module of aircraft parts technology equipment variant design technology[J]. Mechanical Design and Research, 2015 (4): 129-133.
[6] 杨卓峰. 面向大规模定制的工艺信息系统技术研究与实现[D]. 西安: 西北工业大学机械工程学院, 2007: 1-72.
YANG Zhuofeng. Research and implementation of process information system technology for mass customization[D]. Xi’an: Northwestern Polytechnical University, School of Mechanical Engineering, 2007: 1-72.
[7] LUH Y P, CHU C H, PAN C C. Data management of green product development with generic modularized product architecture[J]. Computers in Industry, 2010, 61(3): 223-234.
[8] WANG H J, WU X, WANG X. Research on product modularization and module management[C]// International Conference on Artificial Intelligence and Education. New York: IEEE, 2010: 309-311.
[9] LOPEZ-HERREJON R E, MONTALVILLO- MENDIZABAL L, EGYED A. From Requirements to Features: an exploratory study of feature-oriented refactoring[C]//Software Product Lines International Conference, Munich: DBLP, 2011: 181-190.
[10] ALBLAS A, LINDA L, ZHANG, H W. Representing function-technology platform based on the unified modelling language[J]. International Journal of Production Research, 2012, 50(12): 3236-3256.
[11] SCHNSLEBEN P. Methods and tools that support a fast and efficient design-to-order process for parameterized product families[J]. CIRP Annals: Manufacturing Technology, 2012, 61(1): 179-182.
[12] 谢亮, 张晶, 胡学钢. 主从关系数据库中关联规则挖掘算法研究[J]. 合肥工业大学学报, 2009, 32(5): 663-666.
XIE Liang, ZHANG Jing, HU Xuegang. Main mining algorithm of association rules from relational databases[J]. Hefei University of Technology, 2009, 32(5): 663-666.
[13] 廖福蓉, 王成良. 基于有序FP-tree的最大长度频繁项集挖掘算法[J]. 计算机工程与应用, 2012, 48(30): 147-150.
LIAO Furong, WANG Chengliang. Algorithm for mining maximal length frequent itemsets based on ordered FP-tree[J]. Computer Engineering and Applications, 2012, 48(30): 147-150.
[14] 王政, 韩宁. 应用数据挖掘技术的空调建模[J]. 中南大学学报(自然科学版), 2011, 42(增刊1): 800-804.
WANG Zheng, HAN Ning. Air conditioning modeling by neural network using data mining[J]. Journal of Central South University (Science and Technology), 2011, 42(Suppl 1): 800-804.
[15] 甘超, 陆远, 李娟, 等. 基于Apriori算法的设备故障诊断技术的研究[J]. 组合机床与自动化加工技术, 2014(1): 100-103.
GAN Chao, LU Yuan, LI Juan, et al. Research on fault diagnosis of Apriori algorithm[J]. Modular Machine Tool & Automatic Manufacturing Technique, 2014(1): 100-103.
[16] 晏杰, 亓文娟. 基于Aprior&FP-growth算法的研究[J]. 计算机系统应用, 2013, 22(5): 122-125.
YAN Jie, QI Wenjuan. Study on Aprior & FP-growth algorithm[J]. Journal of Computer Applications, 2013, 22(5): 122-125.
[17] 钟院华. 基于PLM数据库的阀门产品族挖掘方法研究[D]. 武汉: 武汉大学动力与机械学院, 2015: 1-65.
ZHONG Yuanhua. Research on the mining method of valve product family based on the PLM database[D]. Wuhan: Wuhan University. School of Power and Mechanical Engineering, 2015: 1-65.
[18] 闫玮. DPIPP参数化模型间包含性方法的研究与应用[D]. 武汉: 武汉大学动力与机械学院, 2015: 1-62.
YAN Wei. Research and apply on inclusion relation of parameterized model for DPIPP[D]. Wuhan: Wuhan University. School of Power and Mechanical Engineering, 2015: 1-62.
(编辑 赵俊)
收稿日期:2017-06-02;修回日期:2017-08-12
基金项目(Foundation item):国家科技重大专项(2014ZX04015021);国家自然科学基金资助项目 (51275362)(Project(2014ZX04015021) supported by the National Science and Technology Major Project; Project(51275362) supported by the National Natural Science Foundation of China)
通信作者:雷金,博士,讲师,从事数据挖掘算法、产品平台建模研究;E-mail:jinlei@whu.edu.cn

