Tri-party deep network representation learning using inductive matrix completion
��Դ�ڿ������ϴ�ѧѧ��(Ӣ�İ�)2019���10��
�������ߣ��Ժ��� ұ���� �ſ� ���� Ф��֥
����ҳ�룺2746 - 2758
Key words��network representation; network embedding; representation learning; matrix-forestindex; inductive matrix completion
Abstract: Most existing network representation learning algorithms focus on network structures for learning. However, network structure is only one kind of view and feature for various networks, and it cannot fully reflect all characteristics of networks. In fact, network vertices usually contain rich text information, which can be well utilized to learn text-enhanced network representations. Meanwhile, Matrix-Forest Index (MFI) has shown its high effectiveness and stability in link prediction tasks compared with other algorithms of link prediction. Both MFI and Inductive Matrix Completion (IMC) are not well applied with algorithmic frameworks of typical representation learning methods. Therefore, we proposed a novel semi-supervised algorithm, tri-party deep network representation learning using inductive matrix completion (TDNR). Based on inductive matrix completion algorithm, TDNR incorporates text features, the link certainty degrees of existing edges and the future link probabilities of non-existing edges into network representations. The experimental results demonstrated that TFNR outperforms other baselines on three real-world datasets. The visualizations of TDNR show that proposed algorithm is more discriminative than other unsupervised approaches.
Cite this article as: YE Zhong-lin, ZHAO Hai-xing, ZHANG Ke, ZHU Yu, XIAO Yu-zhi. Tri-party deep network representation learning using inductive matrix completion [J]. Journal of Central South University, 2019, 26(10): 2746-2758. DOI: https://doi.org/10.1007/s11771-019-4210-8.

J. Cent. South Univ. (2019) 26: 2746-2758
DOI: https://doi.org/10.1007/s11771-019-4210-8

YE Zhong-lin(ұ����)1, 2, 3, ZHAO Hai-xing(�Ժ���)1, 2, 3, 4, ZHANG Ke(�ſ�)1, 2, 3,ZHU Yu(����)1, 2, 3, XIAO Yu-zhi(Ф��֥)1, 2, 3
1. College of Computer, Qinghai Normal University, Xining 810008, China;
2. Tibetan Information Processing and Machine Translation Key Laboratory of Qinghai Province,Xining 810008, China;
3. Key Laboratory of Tibetan Information Processing of Ministry of Education, Xining 810008, China;
4. College of Computer Science, Shaanxi Normal University, Xi��an 130012, China;
 Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Central South University Press and Springer-Verlag GmbH Germany, part of Springer Nature 2019
Abstract: Most existing network representation learning algorithms focus on network structures for learning. However, network structure is only one kind of view and feature for various networks, and it cannot fully reflect all characteristics of networks. In fact, network vertices usually contain rich text information, which can be well utilized to learn text-enhanced network representations. Meanwhile, Matrix-Forest Index (MFI) has shown its high effectiveness and stability in link prediction tasks compared with other algorithms of link prediction. Both MFI and Inductive Matrix Completion (IMC) are not well applied with algorithmic frameworks of typical representation learning methods. Therefore, we proposed a novel semi-supervised algorithm, tri-party deep network representation learning using inductive matrix completion (TDNR). Based on inductive matrix completion algorithm, TDNR incorporates text features, the link certainty degrees of existing edges and the future link probabilities of non-existing edges into network representations. The experimental results demonstrated that TFNR outperforms other baselines on three real-world datasets. The visualizations of TDNR show that proposed algorithm is more discriminative than other unsupervised approaches.
Key words: network representation; network embedding; representation learning; matrix-forestindex; inductive matrix completion
Cite this article as: YE Zhong-lin, ZHAO Hai-xing, ZHANG Ke, ZHU Yu, XIAO Yu-zhi. Tri-party deep network representation learning using inductive matrix completion [J]. Journal of Central South University, 2019, 26(10): 2746-2758. DOI: https://doi.org/10.1007/s11771-019-4210-8.
1 Introduction
Network representation learning is a key research field in complex networks, which can be utilized by node classification [1], link prediction [2] and recommendation system [3, 4]. Network representation learning aims at generating low-dimensional, compressed, and dense network representation vectors for various network structures. The existing network representation learning methods consist of structure-based algorithms and joint learning-based algorithms. The structure-based network algorithms devote to learning the node��s representations purely based on network structures, which aims at training network embeddings to reflect the network��s structures by optimized algorithms. The joint learning-based algorithms aim at fully applying to network��s various components to learn network representations, such as text content, node��s community, label, etc.
DeepWalk [5] is a state-of-the-art network representation method. It first learns network��s structure features by a shallow neural network model, and then generates efficient vertex��s embeddings for various tasks. DeepWalk algorithm is originally based on Word2Vec algorithm [6] of word representation learning, which regards node sequences of networks obtained by random walk strategy as sentences of language model. From then on, some new representation algorithms were presented, such as LINE [7], GraRep [8], SDNE [9] and node2vec [10]. LINE is a matrix factorization model, which preserves both first and second order proximities between two vertices. Similarly, GraRep is another matrix factorization approach which learns higher order network representations. Those algorithms are just based on the structures of networks to optimize the network representation learning procedures. They are all tested on some real-world network datasets.
However, the network representation learning algorithms based on network structures have nearly reached the bottleneck of its efficiency. Researchers began to wonder whether the other information of networks can contribute to learning the network representations to some extent. To deal with this challenge, some researchers paid more attention to the joint learning based on node��s text context, community, label, etc. Some algorithms were accordingly proposed, such as PTE [11], CECE [12], CNRL [13], TriDNR [14], EP [15], M-NMF [16], etc. In addition, some research achievements assembled the user profile and vertex property into network representations, such as UPPSNE [17], PPNE [18] and AANE [19]. There are some network representation learning algorithms for the heterogeneous-networks and hyper-networks, such as HINE [20] and DHNE [21].
DeepWalk using Skip-Gram model has been extensively used for various network representation tasks. Fortunately, it has been proven that skip- gram with negative sampling (SGNS) implicitly factorizes the SPPMI matrix [22].Motivated by SGNS, it also has been proven that DeepWalk is equivalent to factorize matrix M=(A+A2)/2 [23, 24], where A is the transition matrix of the network. Based on the matrix factorization theory, TADW [25] and MMDW [26] algorithms are subsequently proposed. Max-margin approach is usually applied to some discriminative tasks, such as support vector machines (SVM) [27] and topic model [28]. MMDW first adopted matrix factorization method to train network representations, and the max-margin optimization is then utilized to optimize the learnt representations. TADW embedded the text features into the procedure of matrix factorization.
Singular value decomposition (SVD) was often used for matrix factorization. Its object function is  r<
r< is usually regarded as nodes representations in networks. Most existing algorithms gain the network representations by SVD matrix factorization approach. Inductive matrix completion (IMC) is a new kind of matrix factorization approach proposed by NATARAJAN et al [29], which incorporates two known matrices into a factorization procedure. By this procedure, the factorized target matrix possesses more efficient network features. If the introduced two matrices are accurate and understandable, the factorized target matrices can also learn some valuable information from the introduced two matrices.
is usually regarded as nodes representations in networks. Most existing algorithms gain the network representations by SVD matrix factorization approach. Inductive matrix completion (IMC) is a new kind of matrix factorization approach proposed by NATARAJAN et al [29], which incorporates two known matrices into a factorization procedure. By this procedure, the factorized target matrix possesses more efficient network features. If the introduced two matrices are accurate and understandable, the factorized target matrices can also learn some valuable information from the introduced two matrices.
In our research, we found that matrin-forest index (MFI) algorithm in link prediction was usually able to achieve desirable prediction performance in real-world network datasets. Consequently, we could use MFI algorithm to evaluate the link certainty degrees of existing edges and the link probabilities of non-existing edges. So we could regard MFI algorithm as a fortune-telling role. However, MFI and IMC were not well applied to the algorithmic framework of typical network representation learning method. Therefore, we proposed a semi-supervised tri-party deep network representation (TDNR) algorithm. TDNR algorithm regarded MFI similarity matrix obtained by link prediction as auxiliary matrix X. Meanwhile, it took vertex��s text information generated by SVD as the auxiliary matrix Y. Based on auxiliary matrices X and Y, the learnt network representations were more accurate and discriminative. The detailed illustration of TDNR is shown in Figure 1. The left part is the entire network, and the right part is the local network.
As shown in Figure 1, the solid lines indicate the existing links, and its weight stands for the certainty degrees of the edges between nodes. The dot lines represent the future links, and its weight denotes the future link possibilities of non-existing edges. We found that node 3 and 4 are more likely to be connected in the future.
Our method is expected to be of great improvement for network representation learning with text features, link certainty degrees, the link probabilities based on IMC algorithm, and network structures. As a semi-supervised learning approach, we conducted nodes classification experiments on three real-world networks to verify the performance and effectiveness of TDNR. The experimental results showed its superiority with various baseline approaches and training ratios of training set. The visualization results also showed its discriminative ability on real-world network datasets from diverse domains.
Our key contribution is to define a flexible framework of incorporating the features of link prediction and text features, beside network structures. In conclusion, we embedded the link certainty degrees of existing edges and the future link probabilities of non-existing edges between two vertices into the network representation learning besides text features of networks. We intend to learn the valuable network features from the future views and structures of networks.
2 Method
2.1 Formalization
TDNR is formalized as follows. Suppose that there is a network G=(V, E), where V denotes the node set and E denotes the edge set, i.e.  |V| denotes the size of node set. Our research target is to learn network representations
|V| denotes the size of node set. Our research target is to learn network representations or embeddings for a given node
or embeddings for a given node  where k is the length of network representation and is much smaller than |V|. Note that is not task- specific and it can be applied to diverse tasks, e.g. SVM. We can regard rv as vectors of vertex v and apply them to conduct our classification experiments.
where k is the length of network representation and is much smaller than |V|. Note that is not task- specific and it can be applied to diverse tasks, e.g. SVM. We can regard rv as vectors of vertex v and apply them to conduct our classification experiments.
2.2 MFI similarity matrix
Link prediction is to predict the likelihood of the future association between two vertices based on the known network vertices and structures. This kind of prediction contains the prediction of existing yet unknown links and future links.
Link prediction in complex network has attracted increasing attention from both physics and computer science communities. Link prediction is a crucial research domain for social networks, and it also can be used for information retrieval, bioinformatics and e-commerce. There are various algorithms for link prediction, such as feature-based approaches [30], kernel-based methods [31], matrix factorization-based methods [32] and probabilistic graphical-based methods [33]. These methods differ in complexity, performance, scalability, generalization ability, etc.

Figure 1 Illustration of TDNR
We want to learn some valuable features using some domain algorithms, such as link prediction algorithm. Link prediction can provide the future evolution result of networks, which can guide the evolution procedure of the existing networks. Therefore, the result of link prediction is an important network structure feature. It should be noted that if the link prediction result is applied to optimize network representation learning algorithms, we need to consider how to effectively use future features and existing features.
For the future features, the first step is to research how to learn and obtain valuable future features, and the second step is to explore how to incorporate future features into network representation learning. Fortunately, we found that link prediction algorithm can predict the future link probabilities for non-existing edges in arbitrary networks.
For the existing edges, link prediction algorithm can calculate the vertex��s similarity between two nodes in networks, which is called the link certainty degrees of existing edges. So, we incorporated the future link probabilities of non- existing edges and link certainty degrees of existing edges into network representation vectors. The non- existing links do not exist in real-world network, but they can build associations in future network evolution. Consequently, TNDR possesses the ability of learning features from future views and structures of networks.
Neural network plays an important role in various researches [34, 35]. Here we did not adopt the link prediction algorithms based on neural network due to its higher computation cost. In this paper, we adopted the MFI algorithm to predict the future link probabilities for non-existing edges and the link certainty degrees of existing edges. We also adopted MFI algorithm from link prediction to conduct our experiments on three real-world network datasets. Compared with other link prediction algorithms, the MFI algorithm relatively achieved stable performance, and the results were basically optimal. The detailed results of link prediction are presented in following subsections.
MFI is presented based on matrix-forest theory. Its definition is shown as follows:
 (1)
(1)
where X denotes the MFI similarity matris; L denotes the Laplacian matrix; and I denotes the identity matrix. Generally, if there are more than one edge between two nodes, and even linking edge contains weight information, the each element lxy in L can be defined as follows:
 (2)
(2)
where  is the weight value of the p-th edge between node Vx and Vy. If all spanning forests contain a common root node in network, the spanning forest proportion of commonly inheriting to root node Vx for Vx and Vy is considered as the similarity of the vertex Vx and Vy. MFI��s parameters can be represented as follows:
is the weight value of the p-th edge between node Vx and Vy. If all spanning forests contain a common root node in network, the spanning forest proportion of commonly inheriting to root node Vx for Vx and Vy is considered as the similarity of the vertex Vx and Vy. MFI��s parameters can be represented as follows:
 (3)
(3)
MFI has also been applied to recommendation systems, and the experimental results show that MFI algorithm yields desirable recommendation performance [36]. In our paper, we default that there is only one edge between two vertices and there is no weight information. We also use Eq. (1) to calculate the future link probabilities for non- existing edges and the link certainty degrees of existing edges. And next, we need to research how to embed the matrix X into the framework and procedure of network representation learning of TDNR algorithm.
2.3 TDNR
Generally, DeepWalk algorithm adopts Skip- Gram model and generates node representations for various network structures. It obtains node��s contexts by using random walk. Given a current node Vi, the objective of DeepWalk aims to maximum the likelihood as follows:
 (4)
(4)
where t denotes the half size of context window; |Seq| denotes the size of vertex set.  is defined by Softmax function as follows:
is defined by Softmax function as follows:
 (5)
(5)
where rvi and cvj denote the representations of the current node vi and its context node vj, respectively. And cv denotes the summation operation of context node represeatations. Note that DeepWalk adopts Hierarchical Softmax [37] to speed up the training speed. Afterwards, YANG et al [24] proved that DeepWalk is equivalent to factorize matrix M, which can be calculated by the following equation:
 (6)
(6)
where A denotes transition matrix; ei denotes an indicator vector. Let di be the degree of vertex i, and we have  when
when and
and  otherwise. The time complexity of calculating the accurate matrix M is
otherwise. The time complexity of calculating the accurate matrix M is  Thus, DeepWalk adopts the random walk strategy to avoid the processing of constructing matrix M. Fortunately, YANG et al [24] proposed a simplified calculation approach, finding a threshold between speed and accuracy. The new matrix factorization approach is to factorize the following matrix:
Thus, DeepWalk adopts the random walk strategy to avoid the processing of constructing matrix M. Fortunately, YANG et al [24] proposed a simplified calculation approach, finding a threshold between speed and accuracy. The new matrix factorization approach is to factorize the following matrix:
 (7)
(7)
Considered the efficiency and cost, we factorize the matrix M instead of log2M because the time complexity of calculating accurate matrix M is  compared with that of
compared with that of  and another reason is that log2M has much more non-zero entries than M [23]. The detailed matrix factorization of the DeepWalk is shown in Figure 2.
and another reason is that log2M has much more non-zero entries than M [23]. The detailed matrix factorization of the DeepWalk is shown in Figure 2.

Figure 2 Matrix factorization of DeepWalk
As shown in Figure 2, matrix is factorized into the production form of two matrices
is factorized into the production form of two matrices  and
and  , where
, where  Note that DeepWalk based on matrix factorization regards the matrix W as the vertex representation matrix. Its target is to figure out the closed form of matrix M where M��WTH.
Note that DeepWalk based on matrix factorization regards the matrix W as the vertex representation matrix. Its target is to figure out the closed form of matrix M where M��WTH.
Roughly speaking, the matrix factorization mainly researches how to divide the matrix into multiple matrices. YU et al [23] proposes a matrix factorization approach with a penalty term constraint. Its purpose is to minimize the following loss function:
 (8)
(8)
where ||��|| denotes the Frobenius norm; �� is the balance factor.
We can adopt the Inductive Matrix Completion approach proposed by NATARAJAN et al [29] to incorporate multiple types of features except structures. They applied IMC to the problem of predicting gene-disease associations, and combined multiple types of evidence for diseases and genes to learn latent factors that explain the observed gene-disease associations. Motivated by loss function of Eq. (8), IMC incorporates two known matrices into loss function as follows:
 (9)
(9)
where �� denotes the sample set of matrix  where
where and
and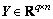 are two known feature matrices. In addition, the convergence proof of IMC can be found in Ref. [38]. In TDNR algorithm, X denotes MFI similarity matrix; Y denotes the text feature reduced dimensional using SVD to 200;
are two known feature matrices. In addition, the convergence proof of IMC can be found in Ref. [38]. In TDNR algorithm, X denotes MFI similarity matrix; Y denotes the text feature reduced dimensional using SVD to 200;  and
and 
Our approach incorporates matrix X and Y into matrix factorization to learn latent factors that explain the observed association amongst text features, structure features, the future link probabilities for non-existing edges and the link certainty degrees of existing edges. On the other hand, matrix X and Y contribute to factorize matrix M by defining them as the extrinsic assistant matrices. The detailed procedures are shown in Figure 3.
Inspired by DeepWalk as matrix factorization, we introduced the vertex��s text feature and MFI similarity matrix into network representation learning based on IMC. Note that TDNR not only incorporates network structure information and vertex��s text features, but also takes the future link probabilities of non-existing edges and link weights of existing edges into account. As shown in Figure 3, MFI similarity matrix X is constructed by the MFI algorithm. Therefore, matrix X consists of the future link probabilities and link certainty degrees between two nodes. The factorization procedure of IMC is to find two matrices W and H, and the factorization condition is M��XTWTHY. As shown in Figure 3, our approach is to factorize the matrix M into the product form of matrices W and H; matrices X and Y remain constants; W and H are our target matrices; k is also the rank of the linear model Z=WTH. Consequently, matrices W and H contain the features from matrices M, X and Y. Q means the result of experiment.

Figure 3 TDNR algorithm framework
Different from other matrix factorizations which focus on factorizing matrix M. IMC matrix factorization can make full use of other features of networks. Since both WT and YTHT learned by TDNR could be recognized as low dimensional, distributed and compressed representations of networks, we then constructed unified representations by concatenating matrices WT and YTHT. Note that the size of the parameter m, p and n are the same size in this paper. In our experiment, we used squared loss in the objective, and regarded missing values as zero.
3 Experiment and evaluation
Classification task is commonly used to weight the algorithm performance [39]. In our experiment, we conducted vertex classification task on three real-world datasets to evaluate the presented model. Meanwhile, we also visualized the learnt representations of three networks to verify that TDNR is qualified to learn discriminative representations. We also showed the results of the algorithm parameter sensitivity.
3.1 Dataset setup
We did our experiments on Citeseer, DBLP (DBLP-V4) and Wiki datasets. The descriptions of dataset are shown in Table 1.
For DBLP dataset, we divided conference papers into 4 research domains, such as database, data mining, artificial intelligent and computer vision. We used DBLP dataset to conduct our visualization analysis in Section 3.6.
The text features in Citeseer and DBLP are short texts [25], i.e. title and abstract. We first deleted all stopwords, and then deleted these words where word frequencies are less than 10. The text information of Wiki is long texts [25], such as webpage contents. We deleted all nodes which have no connection with the other vertices in Wiki.
3.2 Baseline methods
DeepWalk. DeepWalk [5] is a popular network representation learning algorithm, which learns the representations by using the Skip-Gram model and Hierarchical Softmax in open source version. Indeed, DeepWalk can learn the network representation by CBOW model and negative sampling. DeepWalk learns representations based on network structures. We set parameters as follows: window size K=5, walk length ��=80, vector size k=200.
LINE. LINE [7] was proposed to learn network representations for large scale networks. LINE provides two kinds of implementations, called 1st LINE and 2nd LINE. We adopted the 2nd LINE to train and learn the node representations. The same as the DeepWalk, the vector size is set to 200.
MFDW. MFDW is the abbreviated form of DeepWalk as matrix factorization, which simulates the DeepWalk by matrix factorization. MFDW factorizes the matrix M=(A+A2)/2 and uses the learnt matrix W to train classifier.
Table 1 Dataset description

MMDW. The same as MFDW, MMDW also factorizes the matrix M=(A+A2)/2 and takes the learnt matrix W to train classifier. MMDW uses the max-margin approach to optimize learnt matrix W, Thus, the learnt representations possess the discriminative ability.
TEXT. We took text feature matrix  as 200-dimensional representations of networks. The approach of TEXT is a content-based baseline.
as 200-dimensional representations of networks. The approach of TEXT is a content-based baseline.
TADW. It incorporates text features of the vertex into network representation learning with the framework of matrix factorization. TADW is also to factorize the matrix M=(A+A2)/2.
3.3 Classifiers and experiment setup
We conducted our experiments on real-world network datasets. We adopted the vertex��s classification tasks to verify the feasibility of our algorithm. As a semi-supervised algorithm, we chose linear SVM implemented by Liblinear [40] to evaluate proposed algorithm, and randomly generated a portion of the labelled samples as training set, and the remaining is testing set. We then evaluated and calculated the accuracy of classification based on different proportions of training set. The proportion of training set varies from 10% to 90%. Same as the DeepWalk, MFDW and MMDW, we set the vector size to 200. Note that the vector size from TDNR is 200 in vertex classification task. We repeated the trial for 10 times and reported the average accuracy.
3.4 Experimental results and analysis
There are a variety of algorithms of link prediction, such as Common Neighbours (CN), Salton, Jaccard, Hub Promoted Index (HPI), Hub Depressed Index (HDI), LHN-I, Adamic-Adar (AA), Resource Allocation (RA), Preferential Attachment (PA), LNBAA, LNBRA, LNBCN, Local Path(LP), Katz, LHN-II, Average Commute Time(ACT), Cos+, Local Random Walk (LRW), Superposed Random Walk (SRW), Matrix-Forest Index (MFI) and Transferring Similarity based on Common Neighbours (TSCN).
We evaluated the performance of link prediction based on three real-world network datasets, such as Citeseer, DBLP and Wiki. We used the are aunder curve (AUC) index to evaluate the performance of different algorithms of link prediction. All AUC results are shown in Table 2.
As shown in Table 2, MFI algorithm achieves the best performance, which obtains a great improvement compared with other algorithms of link prediction. Using comparative analysis, we found that MFI algorithm is robust on different networks with diverse training ratios ranging from 70% to 90%.
We treated the network representations trained by TDNR algorithm as node��s feature vectors to learn a SVM classifier, and then evaluated their performance with diverse training ratios. The training ratio ranges from 0.1 to 0.9 for SVM classifier. We conducted the experiment for 10 times and reported the average accuracy. The accuracy of vertex classification is shown in Tables 3-5.
From Tables 3-5, we have the following observations:
1) The presented TDNR consistently and significantly outperforms all the baselines on Citeseer, DBLP and Wiki datasets with various training ratios ranging from 10% to 90%. Compared with DeepWalk, TDNR achieves at least 20% improvement on Citeseer and nearly 15% improvement on Wiki when the training ratio is less than 90%, respectively. DeepWalk, MFDW, MMDW and LINE cannot learn desirable representations on Citeseer and Wiki datasets, but TDNR can solve this situation by its integrated learning framework. These results show that TDNR is more efficient and robust, and it especially performs better when the network is a sparse network.
Table 2 AUC on Citesser, DBLP and Wiki datasets

Table 3Accuracy of vertex classification on Citeseer (%)

2) TDNR has a desirable classification performance when network is a sparse network. DeepWalk, Line, MFDW and MMDW learn the network representations solely based on network structures. For the sparse networks, they have a small proportion of network features to learn representations, so that the learnt representations are not robust. Instead, TDNR jointly learns network representations from text information, the link certainty degrees of existing edges and and the future link probabilities of non-existing edges by link predict algorithm. So TDNR possesses the robust learning ability, which is hardly affected by the sparse network structures.
3) For the dense networks, i.e. DBLP, TDNR achieves nearly 2% improvement on DBLP, it demonstrates that all kinds of network representation learning methods nearly achieve the same performance. However, TDNR is still one of the best. TADW learns network representations with both text features and network structures. However, the classification performance of TDNR is better than that of TADW. It demonstrates that TDNR learnt some valuable features from the link certainty degrees of the existing edges and the future link probabilities of non-existingedges.
Table 4 Accuracy of vertex classification on DBLP (%)

Table 5 Accuracy of vertex classification on Wiki (%)

These observations demonstrate that TDNR can learn the network representations of higher quality. Moreover, the classification accuracy of TDNR is also competitive though we do not perform specific optimization for the classification task.
3.5 Parameter sensitivity
TDNR optimizes the procedure of matrix factorization and incorporates extrinsic valuable matrices into network representation learning. TDNR has two parameters: �� and k. We set the training ratio to 50%. We also show the accuracy variations using different representation lengths and �� values in Figure 4.
It is shown the variations of accuracy using different �� and k in Figure 4. We let k vary from 50 to 300 and �� range from 0.1 to 1 for Citeseer, DBLP and Wiki datasets. The accuracy varies within 3.75%, 4.85% and 14.83% for different k and �� on Citeseer, DBLP and Wiki datasets, respectively. The average accuracy varies within 2.0%, 2.8% and 3.4% for the fixed k and �� on Citeseer, DBLP and Wiki datasets, respectively. Therefore, TDNR is a robust and stable algorithm with the variations of �� and k within a reasonable range.
TDNR achieves the best performance when k is 150, 200 and 300 on Citeseer, DBLP and Wiki datasets, respectively. �� has great influence on Wiki, but it has weaker effect on Citeseer and DBLP. The main cause is that Wiki takes long texts as its text features. On the contrary, Citeseer and DBLP adopt short texts to gain the text features.

Figure 4 Effects of �� and k on Citeseer (a), DBLP (b) and Wiki datasets (c)
3.6 Visulization
To demonstrate whether the network representations generated from TDNR work better than DeepWalk, and whether the learned representations show the discriminative ability or not, we randomly choose 4 categories on Citeseer and DBLP. Each category contains 200 nodes generated by random selecting approach. For visualization on Wiki, we visualize all 2405 nodes to 2D space. We adopt t-SNE algorithm to show the visualization results. Based on visualization operation, we want to verify that TDNR is quite qualified to generate discriminative representations for real-world networks.
As shown in Figure 5, we found that TDNR learns the desirable representations with better clustering phenomenon and classification boundary. On the contrary, the representations generated by DeepWalk seem chaotic in 2D visualization results, especially on Wiki dataset. The representations show better clustering phenomenon on Citeseer and DBLP datasets based on TDNR, because the boundaries are clear and discriminative.
Visualization of Wiki using DeepWalk shows a confused discriminative ability, because a large proportion of columns of network representations are extremely close to 0, so the situation introduces fuzzy boundary of discrimination between different representations. By reducing dimension using t-SNE, the representations cannot show better discrimination ability. Therefore, the visualization performance of visualization achieves poor resultson Wiki dataset. In summary, the 2D visualization results demonstrate the effectiveness of our discriminative representations generated by TDNR.
3.7 Case study
Network representation learning is to compress vertex relations into a low-dimensional and compressed network representation vectors. Supposing that we have generated all vertex representations, we can set a target node and find the most relevant vertices using vertex��s similarity calculating methods. Supposing that the learnt representation is available, we can conduct some network tasks, such as node classification, link prediction and personalized recommendation. In our experiment, we conducted an instant similarity recommendation based on cosine similarity between two representations on DBLP dataset. We set the target vertex��s title to ��Maximum Margin Planning��. We calculated the top 5 nearest neighbouring vertices using TADW and TDNR algorithms. The representation length is 200, and training ratio is 50%. The results are shown in Table 5.
The DBLP dataset consists of various field papers, and they are mainly extracted from IJCAI, AAAI, NIPS, ICML, ECML, ACML, IJCAI, UAI, ECAI, COLT, ACL, KR, etc. Firstly, we found in DBLP dataset that some papers are cited by the paper ��Maximum Margin Planning��, or some of them cite the paper ��Maximum Margin Planning��.

Figure 5 2D visualization on Citeseer, DBLP and Wiki datasets:
Table 5 Five nearest neighbors generated by DeepWalk and TDNR in artificial intecligent field

However, all these papers belong to the same label ��Artificial intelligent��. It demonstrates that both TADW and TDNR can learn efficient representations from the network structures.
TDNR incorporates text features, the link certainty degrees of existing edges and the future link probabilities of non-existing edges, so that the accuracy of classification is desirable. TADW algorithm also incorporates the text features of networks into representation vectors. Consequently, the predicted nodes by TDNR and TADW slightly tend to text similarity. For example, the text titles of the top 4 nearest vertices contain the word ��Margin��. All the nearest verticesof TADW are also relevant to ��Maximum Margin��. About the performance of link certainty degrees and future link probabilities, we have verified in classification task.
4 Conclusions
We proposed a novel semi-supervised algorithm, tri-party deep network representation learning using inductive matrix completion. It is a novel and discriminative network representation learning approach which can not only introduce network structure features, but also learn network features from the link certainty degrees of existing edges and the future link probabilities of non- existingedges. Based on three real-world network datasets, we conducted experiments on the task of node classification with different training ratios, and the experimental results demonstrated that TDNR is an effective and robust network representation learning approach compared with the other baseline approaches. Meanwhile, the visualization results of learnt representations show that TDNR is quite qualified to generate the discriminative representations for the real-world networks. The experimental data from TDNR fully shows the feasibility of improving the ability of representation learning using extrinsic features, in terms of the link certainty degrees of existing edges and the future link probabilities of non-existing edges. Learning the featurefrom future network structures is our key contribution to this paper. For future works, we will extend our approach to representation learning of large-scale networks.
References
[1] TSOUMAKAS G, KATAKIS I. Multi-label classification: an overview [J]. International Journal of Data Warehousing and Mining, 2007, 3(3): 1-13. DOI: 10.4018/ jdwm.2007070101.
[2] LIBEN-NOWELL D, KLEINBERG J. The link-prediction problem for social networks [J]. Journal of the American Society for Information Science and Technology, 2007, 58(7): 1019-1031. DOI: 10.4018/jdwm.2007070101.
[3] TU C, LIU Z, SUN M. Inferring correspondences from multiple sources for microblog user tags [C]// The Chinese National Conference on Social Media Processing. Heidelberg: Springer, 2014: 1-12.
[4] YU H F, JAIN P, KAR P, et al. Large-scale multi-label learning with missing labels [C]// Proceedings of the 31st International Conference on Machine Learning. Heidelberg: Springer, 2014: 593-601.
[5] PEROZZI B, AL-RFOU R, SKIENA S. DeepWalk: online learning of social representations [C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 701-710.
[6] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Proceedings of the 27th Annual Conference on Neural Information Processing Systems. Massachusetts: MIT, 2013: 3111-3119.
[7] TANG Jian, QU Meng, WANG Ming-zhe, et al. LINE: large-scale information network embedding [C]// Proceedings of the 24th International World Wide Web Conferences Steering Committee. Heidelberg: Springer, 2015: 1067-1077.
[8] CAO Shao-sheng, LU Wei, XU Qiong-kai. GraRep: learning graph representations with global structural information [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 891-900.
[9] WANG Dai-xin, CUI Peng, ZHU Wen-wu. Structural deep network embedding [C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1225-1234.
[10] GROVER A, LESKOVEC J. Node2vec: scalable feature learning for networks [C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 855-864.
[11] TANG Jian, QU Meng, MEI Qiao-zhu. PTE: predictive text embedding through large-scale heterogeneous text networks [C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 1165-1174.
[12] SUN X, GUO J, DING X, et al. A general framework for content-enhanced network representation learning [EB/OL]. [2018-01-05]. http://pdfs.semanticscholar.org/fad9/08515d1 49bce1fe4bad84728657b8b83009a.pdf.
[13] TU C C, WANG H, ZENG X K, LIU Z Y, SUN M S. Community-enhanced network representation learning for network analysis [EB/OL]. [2017-12-03].http://pdfs. semanticscholar.org/619 9/79db74a6d5896e4f21798614e80f9ce6d107.pdf.
[14] PAN Shi-rui, WU Jia, ZHU Xing-quan, et al. Tri-party deep network representation [C]// International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2016: 1895-1901.
[15] GARCIADURAN A, NIEPERT M. Learning graph representations with embedding propagation [EB/OL]. [2017-12-05]. http://in.arxiv.org/abs/1710.03059v1.
[16] WANG X, CUI P, WANG J, et al. Community preserving network embedding[EB/OL]. [2017-12-05]. https://aaai.org/ ocs/index.php/AAAI/AAAI17/paper/view/14589.
[17] ZHANG Dao-kun, YIN Jie, ZHU Xing-quan, et al. User profile preserving social network embedding [C]// 26th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2017: 3378-3384.
[18] LI C, WANG S, YANG D, et al. PPNE: property preserving network embedding [J]. Database Systems for Advanced Applications, 2017:163-179.
[19] HUANG X, LI J, HU X. Accelerated attributed network embedding [EB/OL]. [2018-01-13]. http://www.public.asu. edu/~jundongl/paper/SDM17_AANE.pdf.
[20] HUANGZ P, MAMOULIS N. Heterogeneous information network embedding for meta path-based proximity [EB/OL]. [2018-01-13]. http://pdfs.semanticscholar.org/52a1/50d6a09 8ef142bece099dadaa613fddbae50.pdf.
[21] TU K, CUI P, WANG X, et al. Structural deep embedding for hyper-networks [EB/OL]. [2018-01-09]. http://media.cs. tsinghua.edu.cn/~multimedia/cuipeng/papers/DHNE.pdf.
[22] LEVY O, GOLDBERY Y. Neural word embedding as implicit matrix factorization [C]// Conference on Neural Information Processing Systems. Massachusetts: MIT, 2014: 2177-2185.
[23] YU H F, JAIN P, KAR P, et al. Large-scale multi-label learning with missing labels [EB/OL]. [2018-01-10]. https://www.cse.iitk.ac.in/users/purushot/papers/leml.pdf.
[24] YANG C, LIU Z. Comprehend deepWalk as matrix factorization [EB/OL]. [2018-01-13]. https://www.resear chgate.net/publication/270454626_Comprehend_DeepWalk_as_Matrix_Factorization.
[25] YANG Cheng, LIU Zhi-yuan, ZHAO De-li, et al. Network representation learning with rich text information [C]// Proceedings of of the 24th International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2015: 2111-2117.
[26] TU Cun-chao, ZHANG Wei-cheng, LIU Zhi-yuan, et al. Max-margin deepwalk: Discriminative learning of network representation [C]// International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann, 2016: 3889-3895.
[27] HEARST M A, DUMAIS S T, OSMAN E, et al. Support vector machines [J]. IEEE Intelligent Systems & Their Applications, 2002, 13(4): 18-28. DOI: 10.1109/5254. 708428.
[28] ZHU J, AHMED A, XING E P. MedLDA: maximum margin supervised topic models [J]. Journal of Machine Learning Research, 2012, 13: 2237-2278.
[29] NATARAJAN N, DHILLON I S. Inductive matrix completion for predicting gene�Cdisease associations [J]. Bioinformatics, 2014, 30(12): 60-68. DOI: 10.1093/bioinformatics/btu269.
[30] AOUAY S, JAMOUSSI S, GARGOURI F. Feature based link prediction [C]// IEEE/ACS International Conference on Computer Systems and Applications. New York: USA, 2014: 523-527.
[31] LI D, XU Z, LI S, SUN X. Link prediction in social networks based on hypergraph [C]// International Conference on World Wide Web. New York, USA: ACM Press, 2013: 41-42.
[32] DONG E, LI J, XIE Z. Link prediction via convex nonnegative matrix factorization on multiscale blocks [J]. Journal of Applied Mathematics, 2014, 15(3): 1-9. DOI: 10.1155/2014/786156.
[33] FARASAT A, NIKOLAEV A, SRIHARI S N, et al. Probabilistic graphical models in modern social network analysis [J]. Social Network Analysis and Mining, 2015, 5(1): 1-29. DOI: 10.1007/s13278-015-0289-6.
[34] MEI Y, TAN G. An improved brain emotional learning algorithm for accurate and efficient data analysis [J]. Journal of Central South University, 2018, 25(5): 1084-1098. DOI: 10.1007/s11771-018-3808-6.
[35] JHA B N, LI H. Structural reliability analysis using a hybrid HDMR-ANN method [J]. Journal of Central South University, 2017, 24(11): 2532-2541. DOI: 10.1007/s11771- 017-3666-7.
[36] FOUSS F, YEN L, PIROTTE A, et al. An experimental investigation of graph kernels on a collaborative recommendation task [C]// International Conference on Data Mining. Piscataway, NJ: IEEE, 2006: 863-868.
[37] MORIN F, BENGION Y. Hierarchical probabilistic neural network language model [C]// 10th International Workshop on Artificial Intelligence and Statistics. Piscataway, NJ: IEEE, 2005: 246-252.
[38] JAIN P, DHILLON I S. Provable inductive matrix completion [EB/OL]. [2017-12-05]. https://arxiv.org/pdf/ 1306.0626.pdf.
[39] LIU P, ZHAO H, TENG J, YANG Y, LIU Y. Parallel naive Bayes algorithm for large-scale Chinese text classification based on spark [J]. Journal of Central South University, 2019, 26(1): 1-12. DOI: 10.1007/s11771-019-3978-x.\
[40] FAN R E, CHANG K W, HSIEH C J, et al. LIBLINEAR: A library for large linear classification [J]. Journal of Machine Learning Research, 2008, 9(9): 1871-1874. DOI: 10.1145/1390681.1442794.
(Edited by ZHENG Yu-tong)
���ĵ���
�����յ�����ȫ����Ԫ��������ʾѧϰ�㷨
ժҪ�����е������ʾѧϰ�㷨�������ѧϰ������ṹ������Ȼ��������ṹֻ�������һ����ͼ���������䲻�ܳ�ַ�ӳ��������������ԡ���ʵ�ϣ�����ڵ�ͨ�������ḻ���ı���Ϣ����Щ��Ϣ���Ա��ܺõ�����ѧϰ�ı���ǿ�������ʾ������ͬʱ������ɭ��ָ��(MFI)����������Ԥ��ָ����ȣ�����нϸߵ�Ԥ��Ч�ʺ��ȶ��ԡ�����Ŀǰ������ɭ��ָ�����յ�����ȫ�㷨��û�кܺõ�Ӧ���ڵ��͵ı�ʾѧϰ����С���ˣ��������һ�ֻ����յ�����ȫ����Ԫ��������ʾѧϰ�㷨(TDNR)�����㷨��һ�ְ�ලѧϰ�㷨�������յ�����ȫ�㷨��TDNR������ṹ������ڵ���ı��������������Ѵ��ڱߵ�����ȷ���ȺͷǴ��ڱߵ�δ�����Ӹ��ʵ��������뵽����ı�ʾѧϰ�����У�ʹ��ѧϰ�õ��������ʾ�����к�������ĸ����������ӡ�ʵ������������������ʵ���������ݼ��ϣ�TDNR���������Ա��㷨�����ӻ�ʵ�������TDNR�㷨�ܹ��������н�ǿ���������������ʾ������
�ؼ��ʣ������ʾ������Ƕ�룻��ʾѧϰ������ɭ��ָ�ꣻ�յ�����ȫ
Foundation item: Projects(11661069, 61763041) supported by the National Natural Science Foundation of China; Project(IRT_15R40) supported by Changjiang Scholars and Innovative Research Team in University, China; Project(2017TS045) supported by the Fundamental Research Funds for the Central Universities, China
Received date: 2018-02-12; Accepted date: 2019-03-30
Corresponding author: ZHAO Hai-xing, PhD, Professor; Tel: +86-971-6318682; E-mail: h.x.zhao@163.com; ORCID: 0000-0003- 0957-1603

