THRFuzzy: Tangential holoentropy-enabled rough fuzzy classifier to classification of evolving data streams
来源期刊:中南大学学报(英文版)2017年第8期
论文作者:Jagannath E. Nalavade T. Senthil Murugan
文章页码:1789 - 1800
Key words:data stream; classification; fuzzy; rough set; tangential holoentropy; concept change
Abstract: The rapid developments in the fields of telecommunication, sensor data, financial applications, analyzing of data streams, and so on, increase the rate of data arrival, among which the data mining technique is considered a vital process. The data analysis process consists of different tasks, among which the data stream classification approaches face more challenges than the other commonly used techniques. Even though the classification is a continuous process, it requires a design that can adapt the classification model so as to adjust the concept change or the boundary change between the classes. Hence, we design a novel fuzzy classifier known as THRFuzzy to classify new incoming data streams. Rough set theory along with tangential holoentropy function helps in the designing the dynamic classification model. The classification approach uses kernel fuzzy c-means (FCM) clustering for the generation of the rules and tangential holoentropy function to update the membership function. The performance of the proposed THRFuzzy method is verified using three datasets, namely skin segmentation, localization, and breast cancer datasets, and the evaluated metrics, accuracy and time, comparing its performance with HRFuzzy and adaptive k-NN classifiers. The experimental results conclude that THRFuzzy classifier shows better classification results providing a maximum accuracy consuming a minimal time than the existing classifiers.
Cite this article as: Jagannath E. Nalavade, T. Senthil Murugan. THRFuzzy: Tangential holoentropy-enabled rough fuzzy classifier to classification of evolving data streams [J]. Journal of Central South University, 2017, 24(8): 1789-1800. DOI: https://doi.org/10.1007/s11771-017-3587-5.
J. Cent. South Univ. (2017) 24: 1789-1800
DOI: https://doi.org/10.1007/s11771-017-3587-5

Jagannath E. Nalavade1, T. Senthil Murugan2
1. Department of CSE, Veltech Dr. RR & Dr. SR Technical University, Chennai, India;
2. Department of CSE, Veltech Dr. RR & Dr. SR Technical University, Chennai, India
 Central South University Press and Springer-Verlag GmbH Germany 2017
Central South University Press and Springer-Verlag GmbH Germany 2017
Abstract: The rapid developments in the fields of telecommunication, sensor data, financial applications, analyzing of data streams, and so on, increase the rate of data arrival, among which the data mining technique is considered a vital process. The data analysis process consists of different tasks, among which the data stream classification approaches face more challenges than the other commonly used techniques. Even though the classification is a continuous process, it requires a design that can adapt the classification model so as to adjust the concept change or the boundary change between the classes. Hence, we design a novel fuzzy classifier known as THRFuzzy to classify new incoming data streams. Rough set theory along with tangential holoentropy function helps in the designing the dynamic classification model. The classification approach uses kernel fuzzy c-means (FCM) clustering for the generation of the rules and tangential holoentropy function to update the membership function. The performance of the proposed THRFuzzy method is verified using three datasets, namely skin segmentation, localization, and breast cancer datasets, and the evaluated metrics, accuracy and time, comparing its performance with HRFuzzy and adaptive k-NN classifiers. The experimental results conclude that THRFuzzy classifier shows better classification results providing a maximum accuracy consuming a minimal time than the existing classifiers.
Key words: data stream; classification; fuzzy; rough set; tangential holoentropy; concept change
1 Introduction
Data analysis using classifiers is an important task in applications like machine learning, pattern recognition, and data mining [1]. In the classical techniques, the whole dataset is given to the learning algorithm and it can perform effectively in stable locations. The algorithm stores the dataset in electronic format, which can be retrieved later. Moreover, it determines the target concepts that need learning in advance. Generally, solutions and classifiers are easily obtainable for the static classification. However, certain applications like sensor networks, traffic management and telecommunication used at present suggest that the learning algorithm [2] can work perfectly in dynamic backgrounds, in which it generates the data endlessly without storing.
Applications in the field of data stream mining consider data classification as a major approach. In such cases, the size of the data stream is infinite [1, 3-5] and the elements in the data reach the system at a high rate. Furthermore, the data concept can develop with time, called as concept drift [6, 7]. The change of concept makes it unfeasible to store the data streams in the main memory [8]. Thus, it is hard to store, query, and mine the data in this environment. It is related to several features with evaluation resources, which are discussed briefly in the literature to compute huge-sized data. Among various proposals used before, processing data streams in online is an approach which updates the results and responds for the queries without delaying [9].
Since the incoming of data stream is continuous at high rate of speed, the learners must have the intention to deal with this issue [8, 10]. The change in concepts of data stream over time leads to concept-drift. There are many techniques presented in literatures, which can adapt to the issue of concept-drift in data stream classification [11-13]. Most of the approaches consider a static feature space, where the features and the significance are made with the concept change. Thus, the approaches developed in static environment become impractical in applications dealing real world [14]. The models that were used before can be reused to enhance the accuracy and the access time of the learning algorithms, as the concept recurs [15-17].
This work proposes a multi-classification approach for classifying the data streams by automatic detection of concept drift. This technique combines rough and fuzzy set theory to perform multi-classification of data streams. The proposed fuzzy rule classifier is comprised of two main stages: designing a membership function and defining the rules. The characteristics of the new incoming data aid to update these two processes for a dynamic data stream. Rough set theory updates the membership function by extending the boundary regions between the classes on the basis of new incoming data stream over an interval. Then, the proposed methodology utilizes tangential holoentropy-based method to update the rules. Thus, it performs membership function update and rule definition, based on the change of concept and feature space using the theory of rough set and tangential holoentropy.
The chief contributions of the work are as follows:
1) A novel fuzzy classifier, THRFuzzy (tangential holoentropy-enabled rough fuzzy classifier) is introduced with the combined effect of three processes, namely tangential holoentropy [18], rough set [19] and fuzzy set theory [20] for the classification; 2) We use the concept of rough set theory to detect the concept drift; 3) Based on the concept change of rough set theory, the fuzzy membership function is dynamically updated; 4) The kernel-based FCM clustering [21] with the weight of the rules formulates a function that updates the fuzzy rules.
2 Literature review
This section presents the review of various techniques used in the literature for data stream classification. Almost all the approaches, such as adaptive k-nearest neighbor [22], McDiarmid tree algorithm [22], used previously concerns with the modification of conventional classifier such that it could adapt to the change of concept. While, others use different techniques for the identification of concept drift, which then classifies the data stream using an appropriate classification algorithm.
MENA-TORRES et al [9] presented a classification approach, similarity-based data stream classifier (SimC), which uses insertion/removal strategy so that it could easily adapt to the data tendency. SimC considered a set of instances and estimators that ensured the performance of the algorithm. This approach had the ability to find classes or labels while processing the classification and could delete the non-required classes/labels. Two measures, efficacy, i.e. the rate of classification and efficiency, i.e. instant response time, evaluate the performance of the methodology. However, this technique is modeled in such a way to detect and adjust only to rapid concept changes.
ALIPPI et al [22] considered a just-in-time approach for the adaptation, during the identification of concept drift. Change detection tests (CDTs) were developed to examine the structural changes that could occur in industrial and environmental data. CDTs were combined with adaptive k-nearest neighbor and support vector machine (SVM) classifiers, which were then retrained during the detection of concept change. The application design was made considering the complexity of computation and the memory specifications of the CDT and the classifier. The limitation of this approach is that the methodology is designed only for the numerical data.
ZHANG et al [6] developed an ensemble-tree (E-tree) indexing structure for fast prediction to arrange all the classifiers to form a group. E-trees considered the ensembles as spatial databases and utilized an R-tree like configuration, which could balance the height so as to reduce the complexity in prediction time that was expected. By the integration and discarding of classifiers, E-trees could update automatically thus, adapting the latest trends and different patterns of the data streams. The analysis performed on synthetic and real-world data streams, in theoretical and empirical studies ensured that the performance of the method was better. However, maintaining a tree structure is a difficult process and it requires a large memory for storage.
RUTKOWSKI et al [7] developed a technique using decision trees considering the problems in data stream mining. This approach used a solid mathematical model showing better results when compared with the McDiarmid tree algorithm. The decision tree was built with the utilization of the best attribute so that it could divide the desired node. The decision was made such that the attribute chosen as best for the present data stream was the best for the entire data stream. This method worked on the basis of Taylor’s theorem using the properties of the normal distribution. Some of the drawbacks are that the technique does not address the concept drift problem and it fails to handle the data that are irregularly distributed.
BRZEZINSKI et al [2] presented a data stream classifier, known as accuracy updated ensemble (AUE2), to adapt to different types of drift. The classifier integrates certain weighting mechanisms based on accuracy, obtained from block-based ensembles with the Hoeffding trees adopting its incremental nature. This approach when compared with existing techniques like single classifiers, block-based and online ensembles, and hybrid approaches, showed better classification accuracy. Moreover, the memory requirement is less here than other ensemble techniques. Even though the technique is suitable for handling different types of drifts, weight assignments for different data space is a hard task.
GOMES et al [23] developed a classification approach for classifying data streams using a technique, Mining recurring concepts in a dynamic feature space (MReC-DFS). This approach could overcome the challenges of learning recurring concepts that was used in a dynamic space such that the cost of memory, which was required to store past models, was minimum. MReC-DFS used learning process with the utilization of contextual information so that it could identify and handle concept changes. The past models were then merged with a weighted ensemble to handle the recurring concepts. The concept incremental feature selection, which was used to minimize the feature space, permitted the technique to store only the useful features. As a result, the approach could improve the efficiency associated with the memory. But, it requires data distribution to perform the classification.
MASUD et al [24] concentrated on four main challenges, such as, infinite length, concept-drift, concept-evolution, and feature-evolution, for the classification of data streams. Here, the authors used an ensemble approach for the classification, in which every classifier had a class detector to handle the change of concept and concept-evolution. A technique called feature set homogenization was utilized to handle the feature-evolution process. The class detector was designed in such a way to adapt to the new incoming stream, detecting more than a novel class at an instant. However, the technique fails to detect the actual arrival of novel classes.
ABDULSALAM et al [25] presented an online data stream classification strategy considering the issues of classification, as the arrival of data stream was infinite with limited record. This technique consumed a reduced time, handling the irregular arrival of labeled records, and factors to handle the change of concept in the data stream. Moreover, for the short labeled data blocks, the approach could decide the quality of the updated models if it is appropriate for the formation of unlabeled records, or if more labeled records are needed. However, with this hybrid model, it is difficult to handle multiple classes.
3 Motivation behind approach
This section states the problem identified for classifying the data streams presenting various challenges that a classification approach faces, which is to be tackled by the proposed method of data stream classification.
3.1 Problem definition
Consider D the input database, which is split into a number of data samples, called chunks, represented as dl with a size z. Once the chunk data dl is read as input, the approach performs the classification. Each data sample consists of a vector denoted as sj, such that,
which is split into a number of data samples, called chunks, represented as dl with a size z. Once the chunk data dl is read as input, the approach performs the classification. Each data sample consists of a vector denoted as sj, such that, 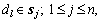 where n is the number of attributes. Identifying the class of the current data chunk is the major challenge considered. During the classification of the chunk data dl, the class labels of the previous chunk data sample, represented as dl-1 is assumed to be known, whereas, the other previous data samples are unknown, according to which the model of data stream classification is designed.
where n is the number of attributes. Identifying the class of the current data chunk is the major challenge considered. During the classification of the chunk data dl, the class labels of the previous chunk data sample, represented as dl-1 is assumed to be known, whereas, the other previous data samples are unknown, according to which the model of data stream classification is designed.
3.2 Challenges
The evolving behavior of data streams makes the learning of classifier with full utilization of data space, a tough process. A standard data mining technique can perform this but requires database scanning at each time instant, which is impractical. Hence, creating a model from the evolving data stream in the data space neglecting multiple scanning is one of the challenges. The second challenge deals with the utilization of a suitable classifier for the dynamic feature space. This is due to the fact that the changing nature of data stream dynamically increases both the record size and the dimension of the feature space. The new incoming data may have more varying boundary than that specified for every feature. Therefore, the classifier is to be modeled such that it can adapt to the boundary drift between the classes during the classification. The classification model must be updated according to the change in the data stream, to make it robust by maximizing the usefulness in classification. Thus, it is necessary for the approach to be incremental to handle the changes instead of formulating an entirely new model. The classification techniques must be designed in a way to handle both numerical and categorical data rather than considering a single attribute, as the real datasets have both.
4 Proposed methodology: tangential holoentropy-enabled rough fuzzy classifier for classification of evolving data streams
This section elaborates the THRF system to perform the classification of evolving data streams. The block diagram of the proposed THRF approach for the data stream classification is a two-stage process, as shown in Fig. 1. The two main tasks involved in THRF are kernel- based FCM enabled fuzzy system and updating of fuzzy rules. Initially, the kernel-based FCM clustering mines the rules and then, with the utilization of a tangential holoentropy function the fuzzy system is updated. The rough set theory by performing COD tests, which detects the concept-drift, updates the fuzzy membership function. Thus, with the rough set approximations and tangential holoentropy function, the proposed approach updates the membership function and the fuzzy rules.

Fig. 1 Block diagram of THRFuzzy system for evolving data stream classification
4.1 Building kernel-based FCM enabled fuzzy system
The first phase of this work is to build a THRFuzzy system using kernel FCM. The proposed approach substitutes the missing values with a value obtained by averaging the attributes and the numerical values indicate the categorical values, which uniquely substitutes every categorical value with numerical value. The classifier model depends on the data stream obtained newly, i.e. dt at a time t. Then, the model is updated continuously using the previous data stream dt-1. Finally, the fuzzy classifier is built by updating the membership function and the fuzzy rules.
4.1.1 Fuzzy membership function
The fundamental step in designing a fuzzy classifier is formulating a membership function that transforms the data values into linguistic variables depending on the membership degree. The membership function creates a curve that is characterized by the nature of data. The membership function considered here is a triangular membership function defining the behavior of data, where each attribute is represented using three membership functions. Therefore, the membership function for the current data stream is denoted as 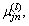 where j represents the attribute index, and n represents the index of the membership function. The following equation defines the membership function as
where j represents the attribute index, and n represents the index of the membership function. The following equation defines the membership function as
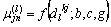 (1)
(1)
where  is the data belonging to the jth attribute of the kth membership function.
is the data belonging to the jth attribute of the kth membership function.
The triangular membership function is then formulated as
 (2)
(2)
The computation of triangular function requires the parameter values p, q and r, which are calculated considering the attribute vector by selecting the minimum, center, and the maximum values from the vector, as follows:
 (3)
(3)
 (4)
(4)
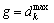 (5)
(5)
where  represents the minimum value of the kth attribute, and
represents the minimum value of the kth attribute, and  represents the maximum value of the kth attribute. Thus, the membership function is computed for all the attributes iteratively. The graphical representation in Fig. 2 depicts a triangular membership function model.
represents the maximum value of the kth attribute. Thus, the membership function is computed for all the attributes iteratively. The graphical representation in Fig. 2 depicts a triangular membership function model.
4.1.2 Fuzzy rule base
Generating fuzzy rules is the next step involved in data stream classification. This utilizes one of the conventional clustering algorithms, kernel FCM clustering to generate the fuzzy rules. The following is the steps in kernel-based FCM clustering for the formulation of fuzzy rules.
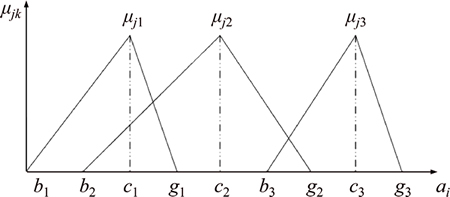
Fig. 2 Sample triangular membership function
1) Discretization of the input data. To begin this clustering process, it requires discretization of the input data stream. Based on the linguistic values that are used for the formulation of membership functions, the chunk data dl is discretized into three sets.
2) Data partitioning. Secondly, the clustering approach executes the partitioning of data stream. Using the class information, the proposed technique divides the chunk data into a set of partitions such that the partitions to be made are equivalent to the number of classes.
3) Applying kernel FCM clustering. Once the partitioning is done, the clustering process begins by adopting kernel FCM clustering. Depending on the number of rules that a class requires, the clustering method creates n-clusters for every set of partitions. FCM clustering permits a part of data in the data stream to involve in few clusters with the utilized kernel function for a significant clustering. Consider  as the kth data object of the first chunk data obtained after the discretization of input data. The aim of this approach is to generate n centroids that form the fuzzy rules. Initially, the technique selects the centroids from the data stream in a random manner, which are represented as
as the kth data object of the first chunk data obtained after the discretization of input data. The aim of this approach is to generate n centroids that form the fuzzy rules. Initially, the technique selects the centroids from the data stream in a random manner, which are represented as 
After the random formation of centroids, it estimates the distance between the data objects and the centroids, and the data objects are clustered such that the distance measure is minimum. This approach maps the data space to a high dimensional feature space. When no more cluster is possible, the process of cluster formation is terminated. The centroid estimation for the new cluster is formulated as
 (6)
(6)
where  is the membership function,
is the membership function,  is the kernel function and
is the kernel function and  is the kth attribute data.
is the kth attribute data.
4) Obtaining fuzzy rules. From the data for which the centroids are estimated, the data in proximity to n- centroid is considered as the rule and transformed into fuzzy format. If clustering is performed for the first class partitions, the estimated centroid is [1 2 1 1], from which the fuzzy rules can be formulated as: if B1 is low or B2 is high or B3 is low or B4 is low then, output is high.
 (7)
(7)
where  denotes the fuzzy rule extracted from the cth class. The rules obtained for all the classes are then grouped to form a fuzzy rule set
denotes the fuzzy rule extracted from the cth class. The rules obtained for all the classes are then grouped to form a fuzzy rule set 
 (8)
(8)
Rule weighting. Assume the rules in the fuzzy set rule Rl as  Using a matching count of the rule that is computed within a discretized database, the weight measure is obtained for every rule as
Using a matching count of the rule that is computed within a discretized database, the weight measure is obtained for every rule as
 (9)
(9)
where  denotes the discretized database of the chunk data dt and
denotes the discretized database of the chunk data dt and  denotes the matching count of the fuzzy rule defined in the discretized database.
denotes the matching count of the fuzzy rule defined in the discretized database.
4.1.3 Data classification using fuzzy system
As soon as the algorithm formulates the membership function and the rule base for the fuzzy system, it performs the classification for the input data stream provided. Thus, the evaluated fuzzy system is given as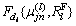 . The score value obtained from the fuzzy system is utilized to classify the data stream.
. The score value obtained from the fuzzy system is utilized to classify the data stream.
4.2 Dynamic updating of THRFuzzy system
This section explains the second phase, updating of THRFuzzy system. The incoming data streams dl are classified after defining the fuzzy system. An important point to be noted is that it is essential to update the fuzzy system for the data stream at previous time interval, i.e. dl-1 in parallel during a concept drift, as the class label of the data stream occurs at the same time. The procedure to update the THRFuzzy system for the data stream at previous time instant dl-1 involves three steps, such as, detecting the change of concept by rough set theory, membership function update, and updating the fuzzy rules using tangential holoentropy function.
4.2.1 Detecting concept change by rough set theory
The concept rough set theory [19] is utilized to detect the change of concept for the data stream dt-1. Rough set theory is an approximation technique that approximates a pair of sets to form the lower and the upper approximations of the input pair of datasets. Consider a set Y having a set of objects, represented as s. The lower approximation of the set can be classified as Y respecting s and the upper approximation also has a higher probability to be classified as the set Y with respect to s, whereas, the boundary region of the set is the set of all objects that can be classified as neither Y nor not-Y, respecting s. The following Eqs. (10) and (11) define the lower and the upper approximations as
 (10)
(10)
 (11)
(11)
With these two approximates, rough set estimates the accuracy of approximation, which is the ratio of lower approximation to the upper approximation as
 (12)
(12)
The change of concept is detected by the accuracy of approximation using a threshold, denoted as Th. A concept drift is identified, when the approximation accuracy αs(Y) produces a value lower than the threshold.
4.2.2 Updating membership function
Followed by the concept drift detection is the membership function update. This requires updating the parameters b, c and g for the drift detected in the data stream at previous time instant, dl-1. The parameter update involves few constraints to be satisfied as follows: 1) Identification of concept change in the incoming data stream by making the accuracy of approximation lesser than the threshold value; 2) The data stream dl-1 at previous interval of time must have different parameter values bl-1, cl-1 and gl-1. Hence, the membership function for the data stream dl-1 is as
 (13)
(13)
Using the triangular membership function for the fuzzy system built, the variables, bl-1, cl-1 and gl-1 are calculated comparing the parameters of the membership functions obtained at previous time interval l-2 and at present interval l-1. Therefore, the variable updates formulated by the comparison are as follows:
 (14)
(14)
 (15)
(15)
 (16)
(16)
The variable update equations state that the range of values in the membership function either increase or reduce automatically for a concept change that occurs in the database.
4.2.3 Updating fuzzy rules by tangential holoentropy function
The last section deals with the fuzzy rule update making use of tangential holoentropy function. After the membership function gets updated, fuzzy rules are updated for the data stream dl-1 with respect to the class labels. We apply the data stream dl-1 as the input to perform the kernel FCM clustering so as to extract the fuzzy rules. Let 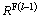 denotes the fuzzy rule obtained for the data stream dl-1. The weight function along with the tangential holoentropy approach updates the fuzzy rules. The rules that are to be substituted with other rules are based on the decision of tangential holoentropy, whereas, the selection of rules is based on the weight of the rules. Then, it finds the rules of the data streams at time instants l-1 and l-2 as,
denotes the fuzzy rule obtained for the data stream dl-1. The weight function along with the tangential holoentropy approach updates the fuzzy rules. The rules that are to be substituted with other rules are based on the decision of tangential holoentropy, whereas, the selection of rules is based on the weight of the rules. Then, it finds the rules of the data streams at time instants l-1 and l-2 as,  and
and 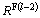 , after which, it computes the tangential holoentropy for all the combination of rules extracted from the data streams at the two specified time limits as
, after which, it computes the tangential holoentropy for all the combination of rules extracted from the data streams at the two specified time limits as

 (17)
(17)
where  represents the informative tangential holoentropy of the rules
represents the informative tangential holoentropy of the rules  and
and  ,
,  represents the tangential holoentropy of the rule
represents the tangential holoentropy of the rule  and
and  represents the conditional tangential holoentropy of
represents the conditional tangential holoentropy of  and
and 
The tangential holoentropy, which is the function of entropy multiplied by a weight factor, is expressed as
 (18)
(18)
where  is the weight factor and is the entropy function of the rule
is the weight factor and is the entropy function of the rule 
The weight factor defined for the tangential holoentropy is given as
 (19)
(19)
The entropy of the rule  regarding the uniquely defined data symbols is defined as
regarding the uniquely defined data symbols is defined as
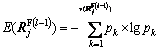 (20)
(20)
where indicates the rule vector; pk denotes the data symbol and  denotes the total number of unique data values in
denotes the total number of unique data values in 
The conditional tangential holoentropy gives the summation of the tangential holoentropy function multiplied by the unique symbol.
 (21)
(21)
The tangential holoentropy function for the rules  regarding the weight and entropy is
regarding the weight and entropy is
 (22)
(22)
where the weight factor for the tangential function is
 (23)
(23)
The entropy function for the rules 
 is,
is,

 (24)
(24)
From the rule obtained, a pair of rules that has minimum tangential holoentropy is chosen for the classification, since these pair of rules is found similar to the rules extracted in the data streams at the two previous time intervals. Among a number of rules identified, the relevant rule is selected and preserved with the decision made by the weight factor.
 (25)
(25)
With the adapted concept change in the evolving data stream, the updated membership function and the fuzzy rules dynamically update the fuzzy system. The data stream classification is then performed for the newly acquired fuzzy system, This process is repeated for the further evolving data streams. Table 1 illustrates the algorithm of the proposed THRFuzzy system for the data stream classification.
This process is repeated for the further evolving data streams. Table 1 illustrates the algorithm of the proposed THRFuzzy system for the data stream classification.
5 Results and discussion
This section demonstrates the results obtained for the experiment carried out using the proposed THRFuzzy system for the classification discussing them on the comparison made with the existing techniques of classification.
5.1 Dataset description
The experiment is verified using three databases such as Skin Segmentation Dataset, Localization Data, and breast cancer dataset, taken from UC Irvine Machine Learning [26]. Skin segmentation data set (Database 1): By sampling R, G, B values from the face images under various age groups like, young, middle and old; race groups like, white, black and Asian; and genders, the skin dataset is obtained. The face images are selected randomly from two databases, FERET and PAL, which has 50859 instances of skin samples and 194198 instances of non-skin samples from a total of 245057. Localization data set (Database 2): The localization database is gathered from certain people who records the data using four different tags (ankle left, ankle right, belt and chest) worn. Every instance forms a localization data for one of the tags that an attribute identifies, making a total of 164860 instances. Breast cancer dataset (Database 3): The third dataset is the breast cancer dataset extracted from the data by chronological grouping. The instances are divided into two classes, with 201 instances for a class and 85 instances for the other class from the total 286 instances. Nine attributes, either linear or nominal, are used to describe these instances.
Table 1 Pseudo code of THRFuzzy for data stream classification

5.2 Evaluation metrics
The evaluation metric used here in this proposed algorithm of data stream classification is accuracy (A). This quantitative parameter refers to the trueness of analysis or an experiment as given below
 (26)
(26)
where TP-true positive indicates correctly identified; FP-false positive indicates incorrectly identified; TN-true negative indicates correctly rejected; FN-false negative indicates incorrectly rejected.
It also measures the computational time so that the performance of the proposed approach can be evaluated as it computes the operating time. The computational time adopts two MATLAB functions, ‘tic’ and ‘toc’, which estimate the start and the elapsed time of the execution.
5.3 Experimental set up
The THRFuzzy classifier is implemented in a system of 64-bits operating in Windows 8.1 that has the following configurations: i5 processor, CPU speed of 2.2 GHz, 4 GB memory. The implementation of the method is in MATLAB (R2014a) with a fuzzy logic toolbox. It considers three parameters, such as, the number of rules, defuzzification method, and threshold to evaluate the performance. Varying these parameters, the performance is checked with the existing adaptive k-NN classifier [22], HRFuzzy to identify the level of performance of the proposed methodology.
5.4 Performance evaluation of THRFuzzy system
This section illustrates the performance evaluation of the classifier regarding the two defuzzification methods, centroid, and bisector, as shown in Fig. 3. Figure 3(a) depicts the graph measuring the accuracy of the proposed method for the first database in varying chunk sizes. As given in Fig. 3(a), the centroid based approach has accuracy more than in bisector method for the chunk sizes from 3 to 7. The maximum accuracy found in centroid method is 99.33% for the size z=3, whereas, in the other method, it is 98.23%. As the chunk size is increased, the accuracy seems reducing for the two methods of defuzzification. The accuracy analysis for the database 2 is shown in Fig. 3(b), in which the bisector approach has higher accuracy than the centroid, unlike the first database. The maximum accuracyattained by THRFuzzy approach in bisector is 88.78%, while in centroid, it is 88%. Figure 3(c) shows the accuracy graph for database 3. Similar to the previous case, the centroid approach has higher accuracy than the other, offering a maximum accuracy of 97.8%, while the bisector approach has 97.39%. Thus, from the analysis made using the two defuzzification approaches, centroid-based classifier offers better accuracy than the bisector fuzzy classifier.

Fig. 3 Accuracy for defuzzification methods:
Figure 4 illustrates the graph plotted for the accuracy against varying chunk sizes based on varying thresholds. The accuracy graph in the first database for two thresholds 0.4 and 0.6 is given in Fig. 4(a), in which the accuracy is maximum, when the thereshold is 0.4. The maximum accuracy is 99.34% for the threshold Th=0.4, whereas, for Th=0.6, it is 98.19%. The accuracy then reduces for the increasing chunk sizes. Figure 5(b) demonstrates the accuracy for the database 2 in two threshold values, in which initially Th=0.6 has maximum accuracy of 88.22%, which then reduces to 87.43% when the chunk size is 7. Meanwhile, the maximum accuracy when Th=0.4 is 88.64% for the maximum chunk size. For the database 3, when the threshold is Th=0.4, maximum accuracy is observed than in the other threshold for most of the chunk sizes, as in Fig. 4(c). A maximum of 97.88% is attained for Th=0.4, while Th=0.6 has 97.51% as the maximum accuracy.
The third analysis of varying rules for the three databases is demonstrated in Fig. 5. Figure 5(a) presents the accuracy graph obtained for database 1 when the number of rules r is varied at 2 and 4. As shown in Fig. 5(a), r=2 has accuracy more than at r=4. An accuracy of 99.33% is obtained in THRFuzzy system for the chunk size 3, when r=2 and 98.24% for the same size when r=4. Figure 5(b) shows the accuracy analysis for the second database, in which r=2 has accuracy higher than in r=4. When r=2, 88.86% is the maximum accuracy at maximum chunk size, while for r=4, the maximum accuracy is 88.68% for the same data size. The accuracy is maximum when r=2 for the database 3 than for the other, as depicted in Fig. 5(c). A maximum accuracy is observed here when the size z=3 with a value97.81% for r=2 and 79.99% for r=4.

Fig. 4 Accuracy for varying thresholds:

Fig. 5 Accuracy for varying number of rules:
5.5 Comparative analysis
This section provides the analysis made in terms of accuracy and computational time by comparing the proposed THRFuzzy classifier with the existing adaptive k-NN classifier and HRFuzzy classifier. Figure 6 illustrates the accuracy analysis obtained for all the three databases under different chunk sizes. The accuracy plot for the skin dataset is exposed in Fig. 6(a). As in Fig. 6(a), the proposed approach could attain a maximum accuracy of 97.11%, while adaptive k-NN and HRFuzzy classifiers have only 88.41% and 87.07% for the size 3. For the further increasing chunk sizes, a similar accuracy can be maintained in the proposed approach. Figure 6(b) depicts the accuracy plot for the second database, which also shows maximum accuracy for the proposed approach. The maximum accuracy in THRFuzzy is 88.87%, while HRFuzzy and adaptive k-NN could provide 87.55% and 83.9% for the chunk size 3.Figure 6(c) demonstrates the accuracy plot for the database 3, in which the accuracy of the proposed approach is high initially, which reduces and then increases before the chunk size 6. When THRFuzzy could attain a maximum accuracy of 97.07%, HRFuzzy and adaptive k-NN could attain only 95.87% and 94.83%, respectively.

Fig. 6 Comparative analysis on accuracy:
Figure 7 depicts the analysis on computational time in the three algorithms to evaluate the performance. For all the databases, it is seen that adaptive k-NN consumes a larger time than the other compared techniques. In Fig. 7(a) the computational analysis for the skin database is shown, in which the time for computation is negligible for the proposed method, while adaptive k-NN consumes the maximum time. THRFuzzy takes a time 5.86 s initially, which then reduced to 4.82 s for the maximum chunk size. The minimum time taken by HRFuzzy and adaptive k-NN is 7.678 sec and 155.648 s for the size 7, indicating that the proposed approach consumed a minimum time for computation than the existing approaches. Figure 7(b) exposes the computational time analysis for the localization database. As seen in the Fig. 7(b), when HRFuzzy and adaptive k-NN classifiers have taken a time of 3.5 s and 63.038 s, THRFuzzy takes only 1.716 s for the computation. Figure 7(c) presents the analysis graph for the database 3. Here, the minimum computational time for THRFuzzy, HRFuzzy and adaptive k-NN is 4.838 s, 2.317 s, and 345.662 s, respectively. Even though the minimum time is observed in HRFuzzy for the chunk size 7, the proposed approach is assumed to have higher performance as the time taken for the computation in other databases are considerably less. Hence, from the overall performance analysis, it is concluded that the proposed THRFuzzy classifier outperforms the existing HRFuzzy and adaptive k-NN classifier with maximum accuracy and minimum computational time.
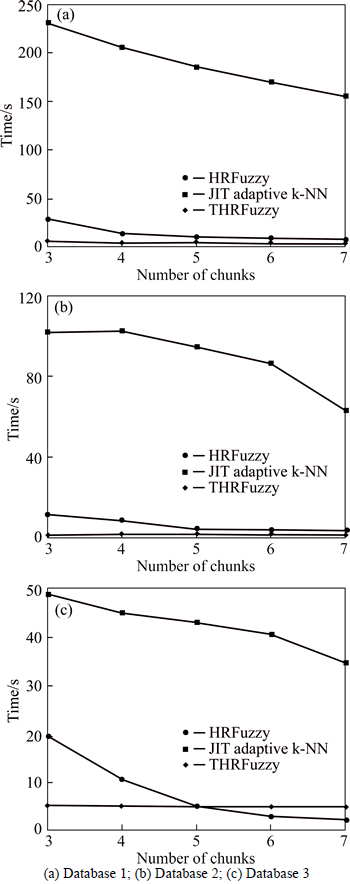
Fig. 7 Comparative analysis on computational time:
6 Conclusions
A novel classifier, THRFuzzy is proposed for the data stream classification utilizing two concepts, rough set theory, and fuzzy set. The classifier model uses a fuzzy membership function and fuzzy rules adopting kernel FCM clustering. The model is then dynamically updated with the utilization of rough set theory and tangential holoentropy function. It detects a concept drift using the lower and the upper approximations with respect to a dataset. Three databases, skin segmentation, localization, and breast cancer datasets are used for the experimentation of the proposed method. The performance comparison of THRFuzzy classifier made with the existing HRFuzzy and adaptive k-NN classifiers regarding accuracy and computational time predicts the efficiency of the proposed algorithm. The future work deals with the inclusion of few learning theories to update the classifier model dynamically.
Acknowledgment
This work is supported by proposal No. OSD/BCUD/392/197 Board of Colleges and University Development, Savitribai Phule Pune University, Pune.
References
[1] ROSS G J, TASOULIS D K, ADAMS N M. Nonparametric monitoring of data streams for changes in location and scale [J]. Technometr, 2012, 53(4): 379-389.
[2] BRZEZINSKI D, STEFANOWSKI J. Reacting to different types of concept drift: the accuracy updated ensemble algorithm [J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(1): 81-94.
[3] ZHU X, ZHANG P, LIN X, SHI Y. Active learning from stream data using optimal weight classifier ensemble [J]. IEEE Trans System, Man, Cybernetics, Part B: Cybernetics, 2010, 40(4): 1-15.
[4] BIFET A, HOLMES G, PFAHRINGER B, KIRKBY R, GAVALDA R. New ensemble methods for evolving data streams [C]// Proc 15th ACM SIGKDD Int’l Conf Knowledge Discovery and Data Mining (KDD), 2009: 139-148.
[5] MASUD M, GAO J, KHAN L, HAN J, THURAISINGHAM B. Classification and novel class detection in concept-drifting data streams under time constraints [J]. IEEE Trans Knowledge and Data Eng., 2011, 23(6): 859-874.
[6] ZHANG Peng, ZHOU Chuan, WANG Peng, GAO B J, ZHU Xing-quan, GUO Li. E-Tree: An efficient indexing structure for ensemble models on data streams [J]. IEEE Transactions on Knowledge and Data engineering, 2015, 27(2): 461-474.
[7] RUTKOWSKI L, JAWORSKI M, PIETRUCZUK L, DUDA P. Decision trees for mining data streams based on the gaussian approximation [J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(1): 108-119.
[8] FAN W. Systematic data selection to mine concept-drifting data streams [C]// Proc ACM SIGKDD 10th Int’l Conf Knowledge Discovery and Data Mining. 2004: 128-137.
[9] MENA-TORRES D, AGUILAR-RUIZ J S. A similarity-based approach for data stream classification [J]. Expert Systems with Applications, 2014, 41: 4224-4234.
[10] HULTEN G, SPENCER L, DOMINGOS P. Mining time-changing data streams [C]// Proc ACM SIGKDD Seventh Int’l Conf Knowledge Discovery and Data Mining. 2001: 97-106.
[11] GAO J, FAN W, HAN J. On appropriate assumptions to mine data streams [C]// Proc IEEE Seventh Int’l Conf Data Mining (ICDM). 2007: 143-152.
[12] KOLTER J, MALOOF M. Using additive expert ensembles to cope with concept drift [C]// Proc 22nd Int’l Conf Machine Learning (ICML). 2005: 449-456.
[13] WANG H, FAN W, YU P S, HAN J. Mining concept-drifting data streams using ensemble classifiers [C]// Proc ACM SIGKDD Ninth Int’l Conf Knowledge Discovery and Data Mining, 2003: 226-235.
[14] KATAKIS I, TSOUMAKAS G, VLAHAVAS I. On the utility of incremental feature selection for the classification of textual data streams [C]// Advances in Informatics. New York, NY, USA: Springer-Verlag, 2005: 338-348.
[15] GOMES J B, SOUSA P A C, MENASALVAS E. Tracking recurrent concepts using context [C]// Proc 7th Int Conf RSCTC. 2010: 168-177.
[16] GAMA J, KOSINA P. Tracking recurring concepts with metalearners [C]// In Proc 14th Portuguese Conf Artif Intell. 2009: 423.
[17] YANG Y, WU X, ZHU X. Mining in anticipation for concept change: Proactive-reactive prediction in data streams [J]. Data Mining Knowl Discovery, 2006, 13(3): 261-289.
[18] HARSHE M S MANASI V. Outlier detection using weighted holoentropy [J]. International Journal of Advances in Engineering Science and Technology, 2016, 5(1): 52-58.
[19] PAWLAK Z. Rough sets [J]. International Journal of Parallel Programming, 1982, 11(5): 341-356.
[20] ZADEH L. Fuzzy sets. [M]. Fuzzy models for pattern recognition: Methods that search for structures in data. NY: IEEE Press, 1992.
[21] THAKUR P, LINGAM C. Generalized spatial kernel based fuzzy c-means clustering algorithm for image segmentation [J]. International Journal of Science and Research (IJSR), 2013, 2(5): 165-169.
[22] ALIPPI C, LIU De-rong, ZHAO Dong-bin, LI Bu. Detecting and reacting to changes in sensing units: The active classifier case [J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2013, 44(3): 353-362.
[23] GOMES J B, GABER M M, PEDRO A, SOUSA C. Mining recurring concepts in a dynamic feature space [J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(1): 95-110.
[24] MASUD M M, CHEN Q, KHAN L, AGGARWAL C C, GAO J, HAN J W, SRIVASTAVA A, OZA N C. Classification and adaptive novel class detection of feature-evolving data streams [J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(7): 1484-1497.
[25] ABDULSALAM H, SKILLICORN D B, MARTIN P. Classification using streaming random forests [J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(1): 22-36.
[26] LICHMAN M. UC Irvine Machine Learning Repository [EB/OL]. [2016-01-10]. http://archive. ics.uci. edu/ml/datasets.html.
(Edited by FANG Jing-hua)
Cite this article as: Jagannath E. Nalavade, T. Senthil Murugan. THRFuzzy: Tangential holoentropy-enabled rough fuzzy classifier to classification of evolving data streams [J]. Journal of Central South University, 2017, 24(8): 1789-1800. DOI: https://doi.org/10.1007/s11771-017-3587-5.
Received date: 2016-04-20; Accepted date: 2017-03-13
Corresponding author: Jagannath E. Nalavade, Assistant Professor; Tel: +91-8329952144; E-mail: jen20074u@gmail.com

