��Ⱦ��̬�ֲ����ع���
�ܷñ�1, 2���콨��1��������1, 3��������2
(1. ���ϴ�ѧ �����ѧ����Ϣ����ѧԺ������ ��ɳ��410083��
2. ��ɳ������ѧ ��ͨ���乤��ѧԺ������ ��ɳ��410004��
3. ���������ѧ ���ز����������Ѷѧϵ����ۣ�999077)
ժҪ�������Ⱦ�ֲ��ܶȺ������ԣ��о���Ⱦ��̬�ֲ�����2��ģ���ܶȺ����Ľ������ݡ�����Kullback-Leibler�����о�2��ģ�����ܶȺ����IJ����ԣ�������Ⱦ��̬�ֲ�������ֲ������ܶȺ�������ֵƯ��ģ���ºͷ�������ģ��������ֲ������ܶȺ���֮���Kullback-Leibler�������ʽ���о����������������ֲ�Ϊ����̬�ֲ�ʱ��2��ģ�͵ĸ����ܶȺ����������ֵƽ�Ʋ����˺ͷ����������Ӧ�������أ��ʷ��������ȹ�ϵ����Ⱦ�ֲ��ܶȺ�����һ�±ؽ������ع�����ֺܴ���죻������Ⱦ��̬�ֲ��ع���Ĺؼ�������ѡȡ�����ܶȺ�����������Ѱ��һ���ʺ���ֵ������ɵķ�����
�ؼ��ʣ���Ⱦ�ֲ�����Ⱦ��̬�ֲ��������ܶȺ����������ԣ��أ���ϵ��
��ͼ����ţ�P207 ���ױ�־�룺A ���±�ţ�1672-7207(2013)03-1269-06
Entropy estimation of contaminated normal distribution
ZHOU Fangbin1, 2, ZHU Jianjun1, CHEN Yongqi1, 3, WANG Zhengwu2
(1. School of Geosciences and Info-Physics, Central South University, Changsha 410083, China;
2. School of Traffic and Transportation Engineering, Changsha University of Science & Technology, Changsha 410004, China;
3. Department of Land Surveying and Geo-informatics, Hong Kong Polytechnic University, Hong Kong 999077, China)
Abstract: The probability density function (PDF) feature of contaminated normal distribution was investigated. The Kullback-Leibler distance was suggested to measure PDF difference between mean shift model and variance inflation model. Three Kullback-Leibler distance formulas about contaminated normal basis distribution PDF, mean shift model PDF and variance inflation model PDF were deduced. A numerical simulation was performed to analyze the difference of the two kinds of models. The results show that the PDF difference of two kinds of models is related to mean shift parameter �� and the variance inflation factor �� closely when the main distribution is standard normal distribution and the relationship is nonlinear proportional. Two kinds of general models PDF can not be used to estimate contaminated normal distribution entropy and entropy coefficient. An approximate formula is suggested for entropy estimation of contaminated normal distribution.
Key words: contaminated distribution; contaminated normal distribution; probability density function; difference; entropy; entropy coefficient
����Ⱦ�ֲ������о��ǿ�����ƵĻ���[1]���ڽ������������������ݴ����з�������Ҫ���ã������������ѧ�����ݴ����о��е��ȵ㡣���Դ�19������Ҷ������˹������Ϊ����ѧ��һ����������������1948����ũ��Ϣ�ر�������ظ���ϱ��������㷺Ӧ������Ϣ�ۡ������ۡ�����ѧ����������ѧ����Դ��ѧ�����Ͽ�ѧ��ҽѧ������ѧ������۵�ѧ���С����������������ݴ��������Ӧ�÷dz�������Lee��[2]�����һ�ַ�ģ������������ȵ�ģ���أ���һ��ģ��������������������ԣ���Ӧ���ڻ���Ϣ������һЩ�о��߽����������ڹ���������ģ���е�Ӱ������Ȩ�ؼ����ϵͳ�Ż�����ѡ��[3-6]���磺Zhou��[3]����Ӧ��������ɱ������ۣ�Liu��[4]����Ӧ���ڵ��²ɿ�ѡ���[5]Ӧ���ڻ����ֺ����������ۣ�Han��[6]���3���������˵��������ֵ���㷽��ȷ��Ȩ�صIJ���ѧ�ԣ����÷��[7]��������������ϵͳ���Ե�һЩָ�꣬������ϵͳ�����ء����Է����ء�����ϵͳ�����غ���ϵͳ������ϵ�صĶ��壬��������Щ�����Ӳ�ͬ�Ƕ���������ϵͳ�ڲ��IJ�ȷ���ԣ���������[8-9]��������ͼ�������ű���[10]�����˱�Ҷ˹����ص�ͳ��ѧ���������۷�չ���̼����������ͻ�����ѧ�е�Ӧ�á�Ŀǰ�����о�����ؼ������ͳ�����Ĺ�ϵ����[11-17]�͵����ؼ�����DEM�е�Ӧ������[18-21]��Ҳ������ɹ����磺�ﺣ��[12]�о��˲���ƽ�������벻ȷ���������⣻�������[13]���������ز�ȷ����ģ�ͣ�������[14]�о���δ֪�ֲ������ز�ȷ���ȺͶ�ά����������ز�ȷ���ȣ�Zhu��[14]���������ԭ��������ʽԼ��ƽ������ת���ɺ���ֲ�����⣻��������[15]�о�������صĹ������⣻Chen��[16-17]���������С�������о��˲������Ź��ƺ����ɷַ��������ՕD��[18-21]��������Ӧ���ڵ�����Ϣ������DEM������顣�����о��ɹ����벻���صļ������⣬��ͨ������£��������������������ֻҪ��֪������ܶȺ�������ɸ�����Ϣ�صĶ���������غ���ϵ�����ﺣ��[11]�����˲������ݴ����г�������̬�ֲ������ȷֲ���P-���ֲ��صļ��㹫ʽ��������Ⱦ�ֲ����ع������⣬�������ܶȺ�������IJ�ȷ�����ص�Ӱ�죬Ŀǰ���Ƕ����о����٣���Ⱦ�ֲ��������Լ������ؽ�������Ϊ�ˣ����������о���Ⱦ��̬�ֲ������ܶȺ����Ľ��Ʊ������Kullback-Leibler����[22]�о���Ⱦ��̬�ֲ�����2��ģ�����ܶȺ����IJ����ԣ�̽Ѱ��Ⱦ��̬�ֲ��ع�����ڵ����⡣ͨ������2��ģ�����ܶȺ����IJ����ԣ�������Ⱦ�ֲ��ܶȺ����IJ�һ�±ؽ������ع���ĺܴ���죬������Ⱦ��̬�ֲ����ع���ؼ�������ѡȡ�����ܶȺ�����������Ѱ��һ���ʺ���ֵ������ɵķ�����Ϊ�ˣ����һ����Ⱦ��̬�ֲ��غ���ϵ������Ľ��Ʒ�����
1 ��Ⱦ��̬�ֲ��ĸ����ܶȺ���������ʽ
��Ⱦ�ֲ�ģʽ����Turkey ��1960������ģ����������˲������ݿ������Բ�ͬ�ֲ���ĸ�壬�侭��ģ��Ϊ
 (1)
(1)
ʽ�У�FCΪ����ֲ�������FΪ����ֲ���������ij�ֱ��ֲ���ƻ����ֲ�������HΪ��Ⱦ�ֲ���������Ϊ��Ⱦ�ʡ����ڲ������ݴ�����̬�ֲ���һ����Ϊ���ݵ����������̬�ֲ���ʽ(1)��дΪ
 (2)
(2)
FNΪ��̬�ֲ���������ˣ�ʽ(2)��Ϊ��Ⱦ��̬�ֲ�������
����ʽ(2)��һ�㽫��Ⱦ��̬�ֲ��ĸ����ܶȺ���fC��ʾΪ
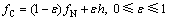 (3)
(3)
������Ⱦ�ʦź���Ⱦ�ֲ��ĸ����ܶȺ���h����ȷ������fC��ȷ����������ѣ�ͨ����Ϊ��Ⱦ��̬�ֲ�����2��ģ�ͣ�������ֵƯ�ơ�ģ�ͺ͡���������ģ��[23]��
1.1 ��ֵƯ��ģ�����ܶȺ���
��ֵƯ��ģ����Ϊ��Ⱦ�ֲ�����������̬�ֲ�����ѧ����������ƽ�ơ�������������̬�ֲ��Ĺ۲����� ��������Ⱦ�ֲ��Ĺ۲�����lj��������ֲ���ѧ�����ı��ƽ�Ʋ���Ϊ�ˣ��������۲�����
��������Ⱦ�ֲ��Ĺ۲�����lj��������ֲ���ѧ�����ı��ƽ�Ʋ���Ϊ�ˣ��������۲�����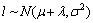 ����
����
 (4)
(4)
ʽ(4)��������ֵƯ��ģ�ͽ���ȾԴ��Ӱ��߶�������ֻ����һ�ص�Ӱ�졣
1.2 ��������ģ�����ܶȺ���
��������ģ����Ϊ��Ⱦ�ֲ�����������̬�ֲ��ķ�����������͡�������������̬�ֲ��Ĺ۲�������������Ⱦ�ֲ��Ĺ۲�����lj��������ֲ�����ı����������Ϊ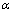 ���������۲�����
���������۲����� ���� ���� 1������
���� ���� 1������
 (5)
(5)
ʽ(5)��������ֵƯ��ģ�ͽ���ȾԴ��Ӱ���ʶ������������˶��ص�Ӱ�졣
1.3 ����������
������Ⱦ��̬�ֲ������ܶȺ�����2��ģ�������۷��������ݴ��������϶��ر�����Ⱦ�ʺ���Ⱦ�ֲ��ı������⣬��Ȼ��������[24]��֤��2��ģ���ڲ������Ź����о��еȼ��ԣ���������ʾ��2��ģ�͵ĸ����ܶȺ�����ͬ�������ͬ������������
��2��ģ�͵ĸ����ܶȺ���������ʽ�Ͽ��Կ��������߾��ܿ�����Ⱦ�ʦŵIJ���֪�ԣ�ģ��������Ⱦ�ֲ���ʵ�ʱ�����ʽ��ͨ���ı�����ֲ������ƽ���������ֲ���ȻΪ��̬�ֲ�����Ԫϲ��[1]ָ���ƽ��ķ����������ϲ������ܣ����������ݴ��������൱��Ч��ϰ���ϣ�������о����÷�������ģ�ͣ���Ҫ������������֤��Ӧ�÷��㡣��һ������£���ѧ�����ͷ����������̬�ֲ���Ψһ�ԣ��ӾصĽǶȿ���2��ģ�͵IJ���̶ȡ���Ȼ����������ģ�ͱȾ�ֵ�ƶ�ģ����Ч�رƽ�ʵ������ֲ�����������ģ�Ϳ�������Ⱦ��ԭ������ֲ��ܶȺ������ص�Ӱ�죬����ֵ�ƶ�ģ�ͽ�����������Ⱦ��ԭ������ֲ��ܶȺ���һ�ص�Ӱ�졣���Ϸ�����������2��ģ���ܶȺ�������IJ���̶ȣ���Ѱ��һ�ַ�������������2��ģ�����ܶȺ����IJ����ԡ�
2 ��Ⱦ��̬�ֲ��ܶȺ����IJ�����
2.1 Kullback-Leibler����
Ϊ�˽�һ��������2��ģ���ܶȺ����IJ��죬�ڴ�����Kullback-Leibler����[22]�о���2��ģ���ܶȺ����ڽ��Ʊ����ϵIJ���̶ȡ�Kullback-Leibler����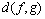 ��
��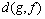 ��һ�㶨��Ϊ��
��һ�㶨��Ϊ��
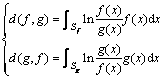 �� (6)
�� (6)
ʽ�У�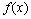 ��
�� Ϊ2���ܶȺ�����Sf��Sg�ֱ�Ϊ����֧�ż�����Լ��
Ϊ2���ܶȺ�����Sf��Sg�ֱ�Ϊ����֧�ż�����Լ�� ����
����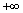 ��
��
2.2 Kullback-Leibler�����µ���Ⱦ��̬�ֲ��ܶȺ���������
��f0��f1��f2�ֱ�Ϊ��Ⱦ��̬�ֲ�������ֲ�����ֵƯ��ģ���ºͷ�������ģ������Ⱦ��̬�ֲ�������ֲ��ܶȺ���������ʽ(6)�����Ƶ�������֮���Kullback-Leibler�������ʽ����
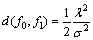 (7)
(7)
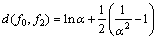 (8)
(8)
 (9)
(9)
��ʽ(7)~(9)���Կ�����f0��f1��f2֮�������ȫȡ���ھ�ֵƽ�Ʋ����ˡ�������������������ֲ��ķ��� ����������ֲ�����ѧ����
����������ֲ�����ѧ���� �ء�������ֲ�Ϊ����̬�ֲ�������2��ģ�͵��ܶȺ�������������ֲ������أ�����˺���ء�Ϊ��ֱ�۱���ٶ�������̬�ֲ�Ϊ����̬�ֲ�����ֵģ�����
�ء�������ֲ�Ϊ����̬�ֲ�������2��ģ�͵��ܶȺ�������������ֲ������أ�����˺���ء�Ϊ��ֱ�۱���ٶ�������̬�ֲ�Ϊ����̬�ֲ�����ֵģ����� ����1��
����1��
������1�е���ֵ��������ʽ(7)~(9)�����Եó���
(1) ��li~N(0, 1)������ ��
�� ��
��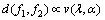 ��
��
(2) ����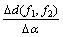 ��
��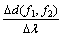 ��
��
���Ͻ���˵����Ⱦ��̬�ֲ��ܶȺ��������ں��ֽ����£�������ȾԴӰ��������������ƫ������ֲ���̬��Խ��Խ���ԣ����Ҿ�ֵ�ƶ�ģ�ͺͷ�������ģ��֮��IJ���Ҳ�����ž�ֵ�ƶ������ͷ����������ӱ�������
3 ��Ⱦ��̬�ֲ��صĽ��ƹ���
3.1 ��Ⱦ��̬�ֲ��ص����Է���
���صĽǶ�ȥ������Ⱦ��̬�ֲ���һ�������̬�ֲ��Ĺ۲�����{Xi} (i=1, 2, ��, n)���������в����ֲ������δ����Ⱦ������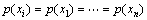 ������۲�����{X i}���ر����ȶ����������к��дֲ�����ݱ���Ⱦ������Ⱦ��Ȼ��������{X i}�е�С��������{X i} (j=1, 2, ��, m; m���� n)����
������۲�����{X i}���ر����ȶ����������к��дֲ�����ݱ���Ⱦ������Ⱦ��Ȼ��������{X i}�е�С��������{X i} (j=1, 2, ��, m; m���� n)���� ������۲�����{X i}���ر�Ȼ�����仯�������ص�������ɣ�{X i}��������Ⱦ���ڵ������Ӧ�ü�С����Ϊ��ͬ�������£���̬�ֲ���������أ���Ⱦ���Ӿ磬������Ӧ��С����Ȼ��������Ⱦ�ʳɷ��ȣ�������Ⱦ�ֲ��ع���Ӧ��ѭ�Ĺ��ɡ�
������۲�����{X i}���ر�Ȼ�����仯�������ص�������ɣ�{X i}��������Ⱦ���ڵ������Ӧ�ü�С����Ϊ��ͬ�������£���̬�ֲ���������أ���Ⱦ���Ӿ磬������Ӧ��С����Ȼ��������Ⱦ�ʳɷ��ȣ�������Ⱦ�ֲ��ع���Ӧ��ѭ�Ĺ��ɡ�
��1 �˺ͦ���ͬȡֵ�µ�d(f1, f2)
Table 1 d(f1, f2)at different �� and ��

��һ������£��صĹ����벻�������ܶȺ�������ͬ���ܶȺ�����Ȼ���²�ͬ�Ĺ�������������Ⱦ��̬�ֲ��ܶȺ����IJ����Կ��Կ���������Ⱦ��̬�ֲ��صĹ����У������κ�һ�ֽ��Ƶĸ����ܶȺ�������������ֵ�ϴ��ڲ�ͬ�̶ȵIJ��죬�������ֲ���������ز����������������ˣ���Ⱦ��̬�ֲ��ع���Ĺؼ�������ѡȡ���ֽ��Ƶĸ����ܶȺ���������Ӧ��Ѱ��һ�ָ��ʺ���������ɵķ�����
3.2 ��Ⱦ��̬�ֲ��ص�һ�ֽ��ƹ���
ͨ������Ⱦ��̬�ֲ��ĸ����ܶȺ��������Է������������Է�����֪����Ⱦ��̬�ֲ����ع��㲻�ܽ����ڶԸ����ܶȺ�����ȡ���ϣ���Ӧ�ø�����Ⱦ��̬�ֲ�������������Ѱ�����������۲���Ⱦ�ֲ�����ʽ��ʽ��������Ⱦ�ʺ�����ֲ��ص���������Ч������Ⱦ��̬�ֲ��صĽ��ƹ��㡣
��ͨ������£���֪ij�ֲַ��ĸ����ܶȺ���f(x)����ɼ�������H(x)��
 (10)
(10)
���ڱ���̬�ֲ�����HN(x)����ϵ��KNΪ��

 (11)
(11)
 (12)
(12)
��ʽ(4)��(5)����ʽ(10)���ɵõ������̬�ֲ���ͬ���غ���ϵ������ʽ��������Ⱦ��̬�ֲ������ܶȺ������ƴ����Ľ������ͬ�������£���̬�ֲ���������أ�����̬�ֲ��ܶȺ�����ʽ������Ⱦ��̬�ֲ�������Ȼƫ��ʧȥ��������Ⱦ��̬�ֲ��о��е����壬��ˣ����ԡ���ֵƯ�ơ���������ģ�͵ĸ����ܶȺ���������Ⱦ�ֲ����غ���ϵ����Ȼ��������ʽ(3)ȫ���������Ⱦ��̬�ֲ��ĸ����ܶȺ�����������Ⱦ�ʦź���Ⱦ�ֲ������ܶȺ���h����ȷ����ͨ�����������ǵĹ����Ѱ�����硰��ֵƯ�ơ��͡���������ģ�͵Ľ��Ʊ�������ǡ���ֵƯ�ơ����ǡ���������ģ�ͣ����߾���ͼͨ�������ڲ����������ָı��Դﵽ�ƽ���Ŀ�ģ������˼���Ⱦ�ʦŵĹ������⣬����Ϊ�����е���Ⱦ���ָı�������ԭ����̬�ֲ������ʣ������ط����ı䡣��Ⱦ�Ĵ��ڵ�����Ⱦ��̬�ֲ�ƫ������ֲ�����Ⱦ�����Ϊ��Ⱦ��̬�ֲ������ܶȺ������Ʊ����һ����Ч��������ˣ�����Ⱦ�ʵ�ͬ���ر��ʣ��������Ч���������Ⱦ��̬�ֲ����غ���ϵ���������ڣ�
 (13)
(13)
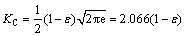 (14)
(14)
�����ݱ���Ⱦ�����صı仯�Ƕ�ȥ���⣬�ۺ�ʽ(13)~(14)����Ⱦ��̬�ֲ����غ���ϵ��������Ⱦ�� �õ���Ч��������ص�����������ֵ���ֹ��ɡ�
�õ���Ч��������ص�����������ֵ���ֹ��ɡ�
3.3 ����
����ȡ������[25]��һ�������GPS RTK�۲����ݣ���Щ���ݹ߳���Ϊ������̬�ֲ�������������[24]������Ϊ�������ݵķֲ�����Ψһȷ��������������Ϊ�������ݷ�����Ⱦ�ֲ����ԣ�����X��������������ֲ����Գ���̬�ֲ����ֱ�ȡ������2����3��Ϊ�ֲ��������Ⱦ�ʣ����ñ���������ع��㷽������X�������������ֲ����غ���ϵ����������������ʵ�ʼ�����ؼ��ԱȽϣ��������2��
��2 �ԦŹ�����غ���ϵ��
Table 2 Estimation of entropy and entropy coefficient based on ��

�ӱ�2���Կ���������Ⱦ�ʺ���������ֲ�����Ϣ����Ч������Ⱦ�ֲ����غ���ϵ����ֻ����Ϊ��Ⱦ�ʵ�ͳ�Ƽ����ϵ����ͬ��ȡֵ���⣬һ�����ֲ�ͬ�ļ��������ӱ���������Ⱦ�ʹ��������������ʵ����غ���ϵ������Աȿ�֪����2�������Ϊ��Ⱦ��ͳ�Ƽ������Ⱦ�ʹ����غ���ϵ�����õرƽ���������ʵ��ֵ�������صĹ���ƽ��̶ȱ���ϵ���Ĺ���ƽ��̶��š�
4 ����
(1) ͨ���������о���Ⱦ��̬�ֲ����õ�2�ֽ��Ʊ���ĸ����ܶȺ��������ԣ��ӾصĽǶ�ָ�������߽����ϵIJ�𣬷�������ģ�͵Ľ��Ƴ̶����ԱȾ�ֵƯ��ģ�͵Ľ��Ƴ̶��š�
(2) Ӧ��Kullback-Leibler�����о���2��ģ�����ܶȺ����IJ����ԡ�������ֲ�Ϊ����̬�ֲ�ʱ����2��ģ�͵ĸ����ܶȺ����������ֵƽ�Ʋ����˺ͷ����������Ӧ�������أ��ʷ��������ȹ�ϵ��
(3) ��ʾ����2��ģ�Ͳ�����Ч������Ⱦ��̬�ֲ��غ���ϵ��������ԭ�����ص�����������ֵ���ֹ��ɸ�������Ⱦ��̬�ֲ��غ���ϵ�������һ����Ч�������֤����������ԡ�
(4) ������Ⱦ�ֲ����ع���ɽ�����Ⱦ�ʺ�����ֲ�����ϵ����ֽ��Ʊ��﷽ʽ���У�����﷽ʽ�д���һ���о���
��л���人��ѧ���ѧԺ�����������ṩ��Դ���ݣ��ڴ����л�⣡
�ο����ף�
[1] ��Ԫϲ, �����, ������. ��Ⱦ�ֲ��ıƽ�������[J]. ���ѧ��, 1999, 28(3): 209-214.
YANG Yuanxi, CHAI Hongzhou, SONG Lijie. Approximation for contaminated distribution and its applications[J]. Acta Geodaetica et Cartographica Sinica, 1999, 28(3): 209-214.
[2] Lee S H, Lee S M, Sohn G Y, et al. Fuzzy entropy design for non convex fuzzy set and application to mutual information[J]. Journal of Central South University of Technology, 2011, 18(1): 184-189.
[3] ZHOU Jian, LI Xibing. Integrating unascertained measurement and information entropy theory to assess blastability of rock mass[J]. Journal of Central South University, 2012, 19(5): 1953-1960.
[4] LIU Aihua, DONG Lei, DONG Longjun. Optimization model of unascertained measurement for underground mining method selection and its application[J]. Journal of Central South University of Technology, 2010, 17(4): 744-749.
[5] ���. ����Ȩ��ģ�͵Ļ����ֺ�����������[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2011, 42(6): 1772-1779.
XIE Chuanyin. Landslides hazard susceptibility evaluation based on weighting model[J]. Journal of Central South University: Science and Technology, 2011, 42(6): 1772-1779.
[6] HAN Runchun, XIAO Jixian. Deciding weighing by entropy value method is an error[C]//Proceedings of Second International Conference on Information and Computing Science. New York: IEECS Press, 2009: 255-257.
[7] ���÷, �����. ���������۸���ϵͳ�Ĵ���[J]. ���ϴ�ѧѧ��: ��Ȼ��ѧ��, 2009, 40(1): 347-351.
WU Hongmei, JIN Hongzhang. Brittleness of complex system based on entropy theory[J]. Journal of Central South University: Science and Technology, 2009, 40(1): 347-351.
[8] ������, �����, ��, ��. һ�ֻ��ھ�ֵ���ʺ�����ص�SARӰ���Ե��ⷽ��[J]. �人��ѧѧ��: ��Ϣ��ѧ��, 2007, 32(6): 494-497.
LIU Junyi, LI Deren, LI Wei, et al. A method for SAR imagery edge detection based on ratio of averages and optimal entropy[J]. Geomatics and Information Science of Wuhan University, 2007, 32(6): 494-497.
[9] Peter E W, Michael W H. Error entropy and mean square error minimization for lossless image compression[C]// Proceedings of IEEE ICIP 2006. New York: IEECS Press, 2006: 2261-2264.
[10] �ű�, ������, ����, ��. Ҷ˹����ص�ͳ��ѧ���������������ͻ�����ѧ�ϵ�Ӧ��[J]. ����ѧ��, 2011, 48(4): 831-839.
ZHANG Bei, LI Weidong, YANG Yong, et al. The Bayesian maximum entropy geostatistical approach and its application in soil and environmental sciences[J]. Acta Pedologica Sinica, 2011, 48(4): 831-839.
[11] �ﺣ��. ���벻ȷ��������[J]. �人���Ƽ���ѧѧ��, 1994, 19(1): 63-72.
SUN Haiyan. Entropy and the uncertainty interval[J]. Journal of Wuhan Technical University of Surveying and Mapping, 1994, 19(1): 63-72.
[12] ������, ����־. ����ز�ȷ����ģ��[J]. ���ѧ��, 2001, 30(1): 48-53.
FAN Aimin, GUO Dazhi. The uncertainty band model of error entropy[J]. Acta Geodaetica et Cartographica Sinica, 2001, 30(1): 48-53.
[13] ����, �����, ������, ��. ��ά����������ز�ȷ����[J]. ����ѧ��, 2006, 27(3): 290-293.
LI Dajun, CHENG Penggen, GONG Jianya, et al. Entropy uncertainty of multi-dimensional random variable[J]. Acta Metrologica Sinica, 2006, 27(3): 290-293.
[14] ZHU J J, Santerre R, Chang X W. A bayesian method for linear, inequality-constrained adjustment and its application to GPS positioning[J]. Journal of Geodesy, 2005, 78(9): 528-534.
[15] ������, ����, ����. ����صĹ��������о�[J]. �人��ѧѧ��: ��Ϣ��ѧ��, 2008, 33(7): 748-751.
YOU Yangsheng, MA Li, LIU Xing. On estimation of error entropy[J]. Geomatics and Information Science of Wuhan University, 2008, 33(7): 748-751.
[16] CHEN Badong, ZHU Yu, HU Jinchun, et al. On optimal estimations with minimum error entropy criterion[J]. Journal of the Franklin Institute, 2010, 347: 545-558.
[17] HE Ran, HU Baogang, YUAN Xiaotong, et al. Principal component analysis based on non-parametric maximum entropy[J]. Neurocomputing, 2010, 73: 1840-1852.
[18] �ՕD, ������, ����, ��. DEM�Ӽ����ֶԵ�����Ϣ�������Ӱ���о�[J]. �人��ѧѧ��: ��Ϣ��ѧ��, 2009, 34(12): 1463-1466.
TAO Yang, TANG Guoan, WANG Chun, et al. Influence of DEM subset partition on terrain information content[J]. Geomatics and Information Science of Wuhan University, 2009, 34(12): 1463-1466.
[19] ϯ��ƽ, ������, ��С��. ���ڵ����صĵ���������ѡ�����о�[J]. �������Ƶ�ѧ��, 2010, 30(4): 247-249.
XI Leiping, CHEN Zili, LI Xiaomin. Discussion on the navigable terrain selection algorithm based on terrain entropy[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2010, 30(4): 247-249.
[20] Wise S. Assessing the spatial characteristics of DEM interpolation error through cross-validatiom[J]. Computers & Geosciences, 2011, 37(8): 978-991.
[21] Wise S. Information entropy as a measure of DEM quality[J]. Computers & Geosciences, 2012, 48(5): 102-110.
[22] ������, ���. �����ֲ������Kullback-Leibler����[J]. �人��ѧѧ��: ��ѧ��, 2007, 53 (5): 513-517.
CAI Zelin, LI Kaican. Maximum Kullback-Leibler distance of some conventional distributions[J]. Journal of Wuhan University: Nat Sci Ed, 2007, 53(5): 513-517.
[23] ������, ���ܱ�. ��ֵƯ��ģ�ͺͷ�������ģ�͵ĵȼ�[J]. ��ɽ����, 1995(1): 8-10.
ZHOU Shijian, ZENG Shaobing. The equivalence of mean shift model and variance inflation model[J]. Mine Surveying, 1995(1): 8-10.
[24] ������, ���. GPS�۲�ֵ���ֲ����о�[J]. ���ͨ��, 2011(2): 6-7, 13.
LAN Yueming, WANG Nan. The study of probability density function for GPS RTK observations[J]. Bulletin of Surveying and Mapping, 2011(2): 6-7, 13.
(�༭ �²ӻ�)
�ո����ڣ�2012-07-10�������ڣ�2012-09-10
������Ŀ��������Ȼ��ѧ����������Ŀ(51278068)������ʡ��������Ŀ(09C089)����ɳ������ѧ��·�ṹ����Ͻ�ͨ��ҵ�ص�ʵ���ҿ��Ż���������Ŀ(kfj100205)������ʡ�ص�ѧ�ƽ�����Ŀ(2012)
ͨ�����ߣ��콨��(1962-)���У�����˫���ˣ����ڣ���ʿ����ʦ�����²������ݴ������о����绰��13873138896��E-mail: zjj@csu.edu.cn

