一种面向语音识别的抗噪SVM参数优化方法
白静,杨利红,张雪英
(太原理工大学 信息工程学院,山西 太原,030024)
摘要:为提高机器学习性能,解决语音识别系统在噪声环境中识别率变差等问题,在分析支持向量机(SVM)模型抗噪性的基础上,提出一种基于生境共享机制的并行结构人工鱼群算法(PAFSA)优化SVM参数的方法。该算法对人工鱼群算法的循环主体进行改进,结合小生境技术的共享机制,在寻优的过程中维持样本个体的多样性,提高求解速度和解的精确性,并利用测试函数对该优化方法进行测试和比较,证明其有效性;用PAFSA对SVM中的惩罚因子C及高斯核参数γ进行优化,并将优选的参数用于一个非特定人、孤立词、中等词汇量的语音识别系统中。实验结果表明:当工作在不同信噪比和不同词汇量下,基于PAFSA-SVM模型语音识别率与基本AFSA-SVM模型识别率以及传统的HMM模型识别率相比均有不同程度提高。
关键词:支持向量机;语音识别;并行结构;人工鱼群算法;小生境技术;共享机制
中图分类号:TN912 文献标志码:A 文章编号:1672-7207(2013)02-0604-08
An anti-noise SVM parameter optimization method for speech recognition
BAI Jing, YANG Lihong, ZHANG Xueying
(College of Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China)
Abstract: In order to improve the learning ability of the support vector machine (SVM), and solve the problem that recognition rates of the speech recognition system become worse in the noisy environments, the noise immunity of SVM model was analyzed, and a parallel artificial fish swarm algorithm (PAFSA) was proposed based on niche technology to optimize the penalty parameter C and Gaussian kernel parameter γ of SVM. The method improved the loop body of artificial fish swarm algorithm (AFSA), combined with niche sharing mechanism in the optimization process to maintain the diversity of the sample of individuals, to improve the accuracy of the solution. By using some test functions, it is proved that its feasibility and effectiveness were improved, some optimized parameters were used in a non-specific persons, isolated words, and medium-vocabulary speech recognition system. The experimental results show that the speech recognition correct rates based on SVM using the PAFSA optimization parameters are better than those by the AFSA optimization parameters and traditional HMM model when it works under different SNRs and different words.
Key words: support vector machine; speech recognition; parallel frame; artificial fish swarm algorithm; niche technology; sharing mechanism
语音识别技术是人机接口应用的前沿技术之一,目的是使计算机能够听懂人类语言,实现人机语音通信。但目前多数实际语音识别系统只适合识别“干净”的语音,当存在背景噪声或训练和测试环境不同时,系统性能会急剧下降。作为模式识别的新型方法之一,支持向量机(SVM)[1]能较好地解决小样本、非线性、高维数和局部极小点等实际问题,比基于经验风险最小化的隐马尔可夫模型(HMM)[2]、人工神经网络[3]等方法具有更好的泛化能力和分类精确性[4],更适合用于语音识别。关于支持向量机的理论研究在逐渐增多,但应用研究相对滞后,只在一些领域得到较好应用,如文本自动分类、图像识别、视频编码[5-6]等,近些年SVM应用研究开始扩展到语音识别领域,但还很不够。文献[7-8]是早期的国内将支持向量机应用于孤立词和汉语数字语音识别的文献,取得了与隐马尔可夫模型相当的识别效果,但采用的是最基本的核函数,核参数选用的是经验值,并未对SVM中的参数选择进行描述,而且实验是在非噪音环境下进行的;Liu等[9]将SVM与段长分布HMM融合起来,构造出一种混合系统,将该系统应用到普通话数字语音识别系统中,实验是在不同信噪比下进行的,结果仅优于使用段长分布HMM的结果。在信噪比较高时,能有效改善系统性能,但在信噪比低于15 dB时,效果不好,且整个系统算法比较复杂。李攀等[10-11]将动态时间规整(DTW)算法嵌入支持向量机常用的核函数中,解决了语音段时长不一致的问题, 实现了支持向量机对语音的分类识别,但这仅是一种进行语音识别的方法,SVM的核参数仍然是最基本的经验值。Maldonado等[12]在不同信噪比下对西班牙语的孤立数字进行实验,结果优于使用HMM的结果,但在低信噪比环境下识别率仍不高,未对SVM算法部分进行深入研究。将SVM应用于语音识别有着巨大的研究潜力。已有研究表明:SVM核参数及惩罚因子的选择严重影响着其分类性能,当其值选取合适时,SVM的分类能力明显增强,然而,其参数的选取目前仍没有较有效的方法。人工鱼群算法[13]是一种基于模拟鱼群行为的优化算法,其结构简单、参数调整简单易行,更适合计算机编程处理。本文在分析SVM模型抗噪性的基础上,提出一种改进的人工鱼群算法――基于小生境共享机制的并行结构人工鱼群算法(PAFSA),对支持向量机中核参数及惩罚因子进行优化,并用基于优选参数的支持向量机进行语音识别实验。
1 SVM模型的抗噪性分析
根据SVM定义,对于空间Rn上的线性可分的2类分类问题,有最大间隔原则,即最大化相应的2个支持超平面形成的间隔。由该原则出发,设有l个线性可分的训练样本集T={(x1,y1),(x2,y2),…,(xl,yl)}∈(X,Y)l,输入样本空间xi∈X=Rn,输出yi∈Y,Y=(-1,1)(其中,i=1,…,l),标明它所对应的样本向量xi属于两类中的哪一类,由这一组样本可以确定一个分类超平面w・x+b=0,使得离它最近的每类点与它的距离达到最大值,则所得到的最优化问题为对法向量w和截距b的凸二次规划问题[14]:

这种解法硬性地要求所有样本点都满足和超平面间的距离必须大于1,因此也叫“硬间隔”分类法。对于某些“离群点”,就无法满足这个硬性的条件,从而使得整个问题无解。若继续使用超平面进行分划,则需引入“容错性”,“软化”对分划超平面的要求,即允许有不满足约束条件yi(w・xi+b)≥1的训练点存在。“软化”约束条件的方法是给式(1)中1这个硬性阈值加一个松弛变量,ξi≥0(i=1,…,l),即:
yi(w・xi+b)≥1-ξi;i=1,…,l (2)
只有“离群点”才有1个松弛变量ξi与其对应,没离群的点松弛变量都等于0。松弛变量ξi实际上表示对应点到底离群有多远,其值越大,则点就越远。当ξi充分大时,训练点总可以满足上述约束条件。但应该设法避免ξi取太大,因此,在目标函数里引入惩罚因子C对其进行惩罚,体现重视离群点带来损失的程度。这样,上述原始最优化问题变为:

上述目标函数中既要最小化||w||2 (最大化间隔),又要最小化 (“离群”点离群带来的破坏程度)。当所有离群点的松弛变量的和一定时,C越大,对目标函数的损失也越大,此时应非常重视这些离群点,最极端的情况是C为无限大。这样,只要有1个点离群,目标函数就变成无限大,问题变成无解,这就退化成了“硬间隔”问题。
(“离群”点离群带来的破坏程度)。当所有离群点的松弛变量的和一定时,C越大,对目标函数的损失也越大,此时应非常重视这些离群点,最极端的情况是C为无限大。这样,只要有1个点离群,目标函数就变成无限大,问题变成无解,这就退化成了“硬间隔”问题。
正因为有了最大间隔原则、松弛变量、惩罚因子,才使得支持向量机具有鲁棒性。在对支持向量机鲁棒性正确分析的基础上,当信噪比降低时,语音识别系统抗噪性的研究就是可行的。
2 SVM模型选择
SVM中的非线性分类问题是通过核函数解决的,通过引入核函数技术把低维空间的输入数据通过非线性变换映射到高维特征空间,从而在低维空间的非线性问题可以在高维空间用线性方法来解决,并且不用知道非线性变换以及其对应特征空间的形式。SVM由核函数和训练集完全刻画,SVM分类性能、核函数的选择以及核参数的取值起着非常关键的作用。
采用不同的核函数可以构造不同的支持向量算法。在实际应用中,通常要根据问题的具体情况选择合适的核函数及其参数。高斯核具有较好的适应性,无论是低维、高维、小样本和大样本等情况均适用,是较理想的分类依据函数。因此,本文采用高斯函数作为核函数,其表达式为
K(xi,xj)=exp(-γ||xi-xj||)2 (4)
引入核函数K(xi,xj)后,使用Lagrange乘子法可将式(3)的最优化问题转化为一个二次规划问题:
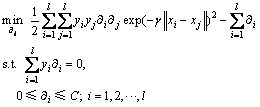 (5)
(5)
其中: i为与第i个样本对应的Lagrange乘子,实质上是凸优化问题的解,i不为零对应的样本点xi就是支持向量。对式(5)求解后,得到相应的决策函数:
i为与第i个样本对应的Lagrange乘子,实质上是凸优化问题的解,i不为零对应的样本点xi就是支持向量。对式(5)求解后,得到相应的决策函数:

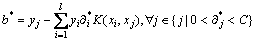
其中:x为待识别样本,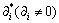 为最优解;b*为分类阈值。
为最优解;b*为分类阈值。
由式(5)可知:SVM分类性能的优劣取决于参数C和γ最小值的求解。核参数γ主要影响样本数据在高维特征空间中分布的复杂程度,但因为具体学习对象的不同,特征相差较大且没有固定的规律,目前参数选择还没有形成统一的模式[15-16],因此,本文提出一种基于小生境共享机制的并行人工鱼群算法PAFSA来优化C与γ。并将优选的参数用于语音识别系统。
3 小生境共享机制并行结构人工鱼群算法的提出
3.1 基于小生境共享机制的并行人工鱼群算法思想
人工鱼群算法是应用动物自治体模型提出的一种自下而上的寻优策略,该算法利用鱼群的觅食、聚群和追尾行为,从构造单条鱼的底层行为做起,通过鱼群中个体的局部寻优,达到全局最优值在群体中凸显的目的。人工鱼群算法具有较强的克服局部极值、取得全局极值的能力,并且算法中只使用目标函数值,无需目标函数的梯度等特殊信息,对搜索空间具有一定的自适应能力。
人工鱼群算法的出现为解决寻优问题提供新的具有竞争力的求解算法,但是其强大的全局搜索能力可能会使之漏掉最优个体而且搜索的随机性,也使得求解精度不高。针对这一问题,本文将基于共享机制的小生境技术[17]引入人工鱼群算法,小生境技术可以维持样本个体的多样性从而避免最优个体的流失。具体算法是将每1代个体划分为若干类,每个类中选出若干适应度较大的个体作为1个类的优秀代表组成1个群,再在种群中以及不同种群中之间杂交、变异产生新一代个体群,同时选择分享机制完成任务。基于这种小生境的人工鱼群算法可以更好的保持个体的多样性,同时具有很强的全局寻优能力。
由于基本人工鱼群算法的主体循环中仅选择追尾、聚群和觅食3种行为中的1种执行,这使得优化结果停滞不前或者错过较优解的概率增大,优化结果不理想。本文对鱼群算法在循环主体处进行改进,提出一种并行人工鱼群算法,进一步降低错过较优解的概率。在初始化后直接分2条路径执行:一条路径执行追尾行为,其中觅食行为设置为随机行为;另一条路径执行聚群行为,同样设置觅食行为为随机行为。最后比较两者的适应值,取最优的结果,记录于公告板,同时更新个体,继续迭代寻优。图1所示为小生境并行人工鱼群算法PAFSA的流程图。
引入小生境共享机制的基本思想是:通过反映个体之间相似程度的共享函数来调节群体中各个个体的适应度,使得在这之后的群体进化过程中,算法能够依据这个调整后的新适应度来进行选择运算,以维持群体的多样性,创造出小生境的进化环境。共享函数是表示群体中2个个体之间密切关系程度的1个函数,表示个体i和j之间的关系,可记为s(i, j)。共享度是某个个体在群体中共享程度的一种度量,它定义为该个体与群体内其它各个个体之间的共享函数值之和,用S表示:
 (6)
(6)
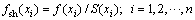 (7)
(7)
其中:xi为样本当前状态;fsh(xi)为xi的共享适应度;f(xi)为xi的适应度;n为种群个数。依据式(6)和式(7)调整各个个体的适应度,由于每个个体的更新比例是由其适应度来控制的,所以,这种调整适应度的方法就能够限制群体中个别个体大量增加,从而维护群体的多样性,并造就一种小生境的进化环境,防止流失最优个体的情况。
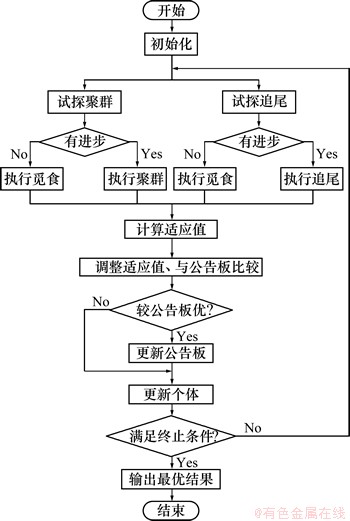
图1 小生境并行人工鱼群算法PAFSA流程图
Fig.1 Flow diagram of PAFSA based on niche sharing mechanism
3.2 PAFSA的算法测试
为检验PAFSA算法的性能,选取以下2个典型的测试函数进行算法性能测试。
测试函数1:Goldstein-Price(GP)函数(n=2)。
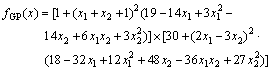
-2≤xi≤2,i=1,2
该函数在定义域范围内的全局最小值为3,最优点为(0,-1)。其三维函数图像如图2所示。
测试函数2:Rastrigin(RA)函数(n=2)。

-1≤xi≤1,i=1,2
该函数的表达式包含多项式及典型三角函数,其在定义域范围内的全局最小值为-2,最优点为(0,0)。其三维函数图像如图3所示。
实验中引入基本粒子群优化算法PSO,将基本AFSA与PAFSA 2个算法的结果进行比较。均选取函数GP和函数RA作为测试函数,通过进行30次独立运行得到平均最小函数值和最小值,实验结果如表1所示。
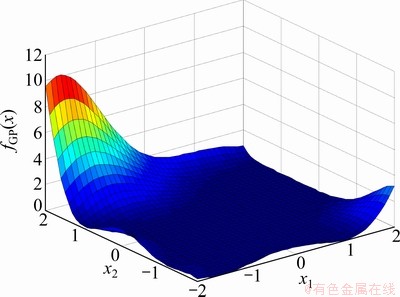
图2 Goldstein-Price(GP)函数图像
Fig.2 Image of Goldstein-Price (GP) function
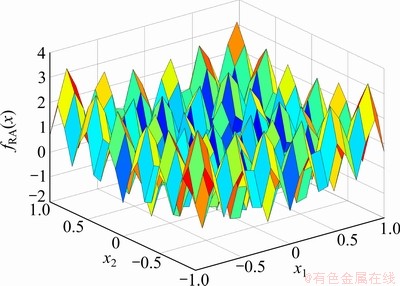
图3 Rastrigin(RA)函数图像
Fig.3 Image of Rastrigin (RA) function
表1 PAFSA与PSO和AFSA算法优化结果比较
Table 1 Comparison of optimized results of PAFSA, PSO and FASA
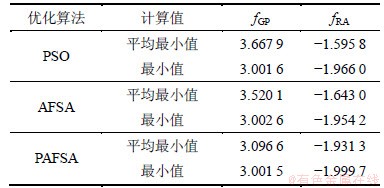
表1表明:PAFSA的优化实验结果比AFSA和PSO的稳定,平均最小值和独立运行最小值更接近理论最优值。图4和图5所示为上述3种优化算法分别对2个测试函数的1次寻优过程对比截图,显示各自的收敛过程。从图4和图5可以看出:PAFSA算法在搜索最优解质量方面要优于AFSA和PSO,即PAFSA能在较少的迭代次数下较快地找出全局最优解,具有较好的收敛性。
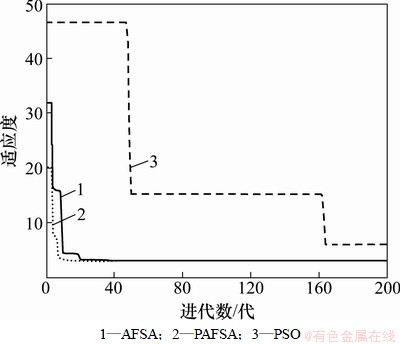
图4 对Goldstrein-Price函数的优化过程
Fig.4 Goldstrein-Price function optimization processes of PAFSA, PSO and AFSA
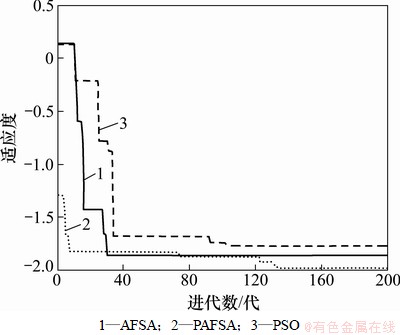
图5 对Rastrigin函数的优化过程
Fig.5 Rastrigin Function optimization processes of PAFSA, PSO and AFSA
3.3 用PAFSA优化SVM参数的实现
将PAFSA产生的初始种群作为SVM参数,代入这些参数进行SVM模型训练和测试。文中将语音词库分为2部分并分别作为训练样本和测试样本,试验后返回一系列训练样本识别率。然后,通过聚群、追尾、觅食等行为寻优产生下一代参数种群,再利用新生子群重复上述操作。在达到一定的代数时,对寻优得到的种群进行分析,依据个体的共享度调整对应个体的适应度,再选取最优个体,进行迭代,直到满足人工鱼群算法中设计的终止条件为止,并将得到的最优参数、最优参数模型作为最终预测模型。图6所示为PAFSA优化SVM参数流程。
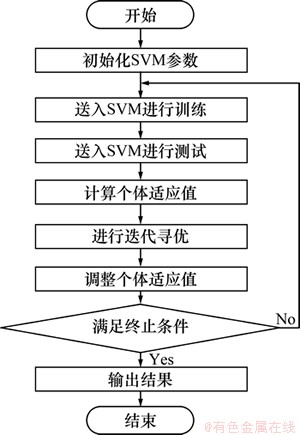
图6 PAFSA优化SVM参数流程图
Fig.6 Flow diagram of SVM parameters optimization by PAFSA
高斯核函数SVM的参数优化可看作是寻找合适的误差惩罚因子C和核参数γ,C与γ构成的二维数组,使SVM有较好的分类性能,即让适应值最大。运用PAFSA在参数C和γ构成的二维平面上寻优,建模的步骤如下。
步骤1:初始化,产生初始种群,确定SVM参数向量(C,γ)的范围及算法中其他参数值。
步骤2:代入SVM模型,利用初始种群对训练集进行训练,由训练好的模型对测试集进行测试,将总体测试样本识别率转换成该模型的适应值。
步骤3:依据适应值,对(C,γ)进行觅食、聚群、追尾等行为进行寻优,产生下一代参数(C,γ)种群。
步骤4:利用得到的子代参数(C,γ)种群,重新对SVM进行训练和测试并计算相应的适应值,进行判断,若达到一定的迭代次数,则依据个体的共享度调整对应个体的适应度,再选取最优个体。
步骤5:运用已得到的子代参数,重新对SVM进行训练和测试并计算相应的适应值,进行判断,若满足人工鱼群算法中训练停止准则,则转到步骤5;否则,返回步骤3继续执行。
步骤6:结束训练,此时得到的参数(C,γ)为最终模型的参数。
4 实验结果与分析
实验中,直接把由采样系统得到的语音数据文件作为处理对象,所采用的语音样本为孤立词。语音信号采样频率为11.02 kHz,帧长N为256点,帧移M为128点。
实验使用9人在不同信噪比(SNR)(0,5,10,15,20,25和30 dB,无噪音)下的发音作为训练数据库,噪声为常见的Gaussian白噪声,其他噪声可通过语音识别系统的前端预处理滤波器滤除掉。语音样本数据的词汇量分别为10,20,30,40和50个词,每人每个词发音3次,因此,整个数据集在不同SNR下分别有10,20,30,40和50个类别,对应的训练样本分别有270,540,810,1 080和1 350个。测试样本由另外7人在相应的SNR和词汇量下,对每个词发音3次得到,对应的测试样本分别有210,420,630,840和1 050个。
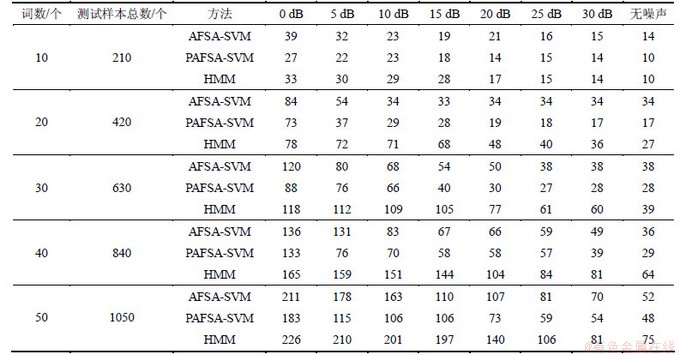
实验输入的语音特征为改进的MFCC特征参数(MFDWCs)[18],该特征的提取符合人耳的听觉特性,具有较好的鲁棒性。表2所示为相同实验条件、不同信噪比和不同词汇量下,基于PAFSA,AFSA的SVM语音识别正确率与HMM的识别率比较结果。表3所示是与表2相对应的错分样本数。
观察实验结果可知:基于本文提出的PAFSA- SVM模型语音识别结果与基本AFSA-SVM模型、HMM识别结果相比较,在不同信噪比和不同词汇量下,识别率均有不同程度提高,即错分样本数均有不同程度减少,尤其在信号的信噪比较低时,PAFSA-SVM错分数比HMM均有减少,最大减少95个(5 dB 50词和10 dB 50词条件下)。这说明SVM具有很强的抗噪能力,进一步表明本文提出的小生境共享机制并行人工鱼群算法是一个较为有效的SVM参数优化方法,可使SVM具有良好的推广能力和较好的鲁棒性。
表2 基于AFSA,PAFSA的SVM与HMM语音识别率比较
Table 2 Comparison of speech recognition rates of SVM based on AFSA, PAFSA and HMM %
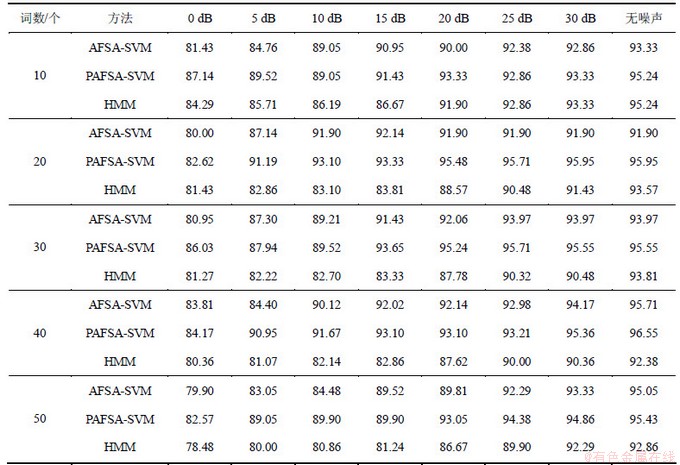
表3 基于AFSA,PAFSA的SVM与HMM语音识别错分样本数
Table 3 Comparison of error classification samples based on AFSA, PAFSA and HMM 个
5 结论
(1) 提出一种并行的人工鱼群算法PAFSA,并引入小生境共享机制技术,降低错过较优解的概率。通过对PAFSA算法中的个体的新局部最优位置以及全局最优位置应用小生境,以维持样本个体的多样性,避免最优个体的流失,保证了PAFSA的求解精度。
(2) 采用测试函数对该算法进行测试和比较,验证了其有效性。运用该算法对高斯核支持向量机参数组(C,γ) 进行优化,并将其用到一个非特定人、孤立词、中等词汇量的语音识别系统中,通过与基于普通AFSA-SVM和HMM的语音识别结果进行比较,证明PAFSA是一种较好的面向语音识别的抗噪SVM参数优化算法,同时也说明SVM在语音识别领域将会有广阔的发展前景。
参考文献:
[1] Cortes C, Vapnik V. Support vector networks [J]. Machine Learning, 1995, 20(3): 273-297.
[2] 黄景德, 郝学良, 王明. 基于HMM的多态系统状态识别模型研究[J]. 测试技术学报, 2012, 26(2): 154-157.
Huang Jingde, Hao Xueliang, Wang Ming. Study of multi-state system states recognition model based on HMM[J]. Journal of Test and Measurement Technology, 2012, 26(2): 154-157.
[3] 毛健, 赵红东, 姚婧婧. 人工神经网络的发展及应用[J]. 电子设计工程, 2011, 19(24): 62-65.
MAO Jian, ZHAO Hongdong, YAO Jingjing. Application and prospect of artificial neural network[J]. Electronic Design Engineering, 2011, 19(24): 62-65.
[4] Arun K M, Gopal M. Reduced one-against-all method for multiclass SVM classification[J]. Expert Systems with Application, 2011, 38: 14238-14248. Acta Electronica Sinica, 2010, 38(7): 1626-1633.
[5] Domenico C, Rostita G. Kernel based support vector machine via semidefinite programming: Application to medical diagnosis[J]. Computer & Operations Research, 2010, 37: 1389-1394.
[6] 吕卓逸, 贾克斌, 萧允治. 低复杂度的快速降尺寸视频转码算法[J]. 通信学报, 2012, 33(1): 160-166.
LV Zhuoyi, JIA Kebin, XIAO Yunzhi. Fast and low-complexity video down-sizing transcoder[J]. Journal on Communications, 2012, 33(1): 160-166.
[7] 苏毅, 吴文虎, 郑方, 等. 基于支持向量机的语音识别研究[C]//第六届全国人机语音通讯学术会议论文集, 深圳: 哈尔滨工业大学, 2001: 223-226.
SU Yi, WU Wenhu, ZHENG Fang, et al. Research of speech recognition based on support vector machine[C]// Proceedings of Sixth China Human-machine Speech Communication Conference, Shenzhen: Harbin Institute of Technology, 2001: 223-226.
[8] XIE Xiang, KUANG Jingming. Mandarin digits speech recognition using support vector machines[J]. Journal of Beijing Institute of technology, 2005, 14(1): 9-12.
[9] Liu J, Wang Z, Xiao X. A hybrid SVM/DDBHMM decision fusion modeling for robust continuous digital speech recognition[J]. Pattern Recognition Letters, 2007, 28(8): 912-920.
[10] 李攀, 杨玮龙, 厉剑. 基于DTW/SVM的语音识别系统在DSP中的实现[J]. 电声技术, 2006(9): 40-44.
LI Pan, YANG Weilong, LI Jian. DSP Implementation of speech recognition based on DTW/SVM[J]. Audio Engineering, 2006(9): 40-44.
[11]  R, Martín-Iglesias D, Gallardo-Antolín A, et al. Robust ASR using support vector machines[J]. Speech Communication, 2007, 49(4): 253-267.
R, Martín-Iglesias D, Gallardo-Antolín A, et al. Robust ASR using support vector machines[J]. Speech Communication, 2007, 49(4): 253-267.
[12] Maldonado S, Weber R, Basak J. Simultaneous feature selection and classification using kernel-penalized support vector machines[J]. Information Sciences, 2011, 181(1): 115-128.
[13] Huang C M, Lee Y J, Dennis K, et al. Model selection for support vector machines via uniform design[J]. Computational Statistics & Data Analysis, 2007, 52(1): 335-346.
[14] 邓乃杨, 田英杰. 支持向量机-理论、算法与拓展[M]. 北京: 科学出版社, 2009: 45-48.
DENG Nanyang, TIAN Yingjie. Support vector machine- theory, algorithms and expansion[M]. Beijing: Science Press, 2009: 45-48.
[15] Wang Z P, Zhao L, Zou C R. Support vector machines for emotion recognition in Chinese speech[J]. Journal of Southeast University, 2003, 19(4): 307-310.
[16] TANG Tao, GUO Qing, YANG Mingchuan. Support vector machine based particle swarm optimization localization algorithm in WSN[J]. Journal of Convergence Information Technology, 2012, 7(1): 497-503.
[17] 秦涵书, 魏延, 曾绍华. 一种基于小生境遗传算法的SVM参数优化方法[J]. 重庆理工大学学报, 2011, 25(12): 89-93.
QIN Hanshua, WEI Yana, ZENG Shaohua. Parameter optimization of SVM for classification based on NGA[J]. Journal of Chongqing University of Technology: Natural Science, 2011, 25(12): 89-93.
[18] BAI Jing, ZHANG Xueying, GUO Yueling. Different inertia weight PSO algorithm optimizing SVM kernel parameters applied in a speech recognition system[C]// International Conference on Mechatronics and Automation, Changchun: IEEE, 2009: 4754-4759.
(编辑 邓履翔)
收稿日期:2012-04-04;修回日期:2012-06-16
基金项目:国家自然科学基金资助项目(61072087);山西省科技攻关项目(20120313013-6)
通信作者:白静(1965-),女,山西太原人,博士,副教授,从事语音信号处理等研究;电话:0351-6018390;E-mail:bj613@126.com

