��Ƶ���ݴ洢��ʽ���˶������㷨���ڴ����Ч��
�Գ���1��������2�����ƻ�1
(1. ����ѧԺ ��Ϣ�뼤���о��������� ������422000��
2. ����ѧԺ ������ѧϵ������ ������422000)
ժ Ҫ��ͨ�����������˶������㷨���ڴ����ģʽ����ʾ��������ͨ�ü�����������źŴ�������ʹ��ʱ���ڵ�Ч�����⣬�Լ���ɴ������ԭ�����һ���µ��ڴ����Ч�ʸߵ���Ƶ���ݴ洢��ʽ������ʽ�洢��ʽ���о����������ʹ���µ���Ƶ���ݴ洢����������˿绺���߷������ݵ����⣬�������������˶����ƹ����еĸ��ٻ����ܰ��ʣ���ȫ�����㷨�����㷨���������κθĶ�������£����˶����ƹ����ٶ����28%����ˣ�����ʽ�洢��ʽ��ʹ�ã�������Ч�ؼ����˶����ƹ��̡�
�ؼ��ʣ���Ƶ���ݣ��ڴ棻����Ч�ʣ��˶�����
��ͼ����ţ�TP391 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2007)03-0540-05
Video data layout optimization and memory access analysis for
motion estimation
ZHAO Cheng-lin1, LIU Jiang-yun2, ZHAO Yun-hui1
(1. Institute of Information & Laser, Shaoyang College, Shaoyang 422000, China;
2. Educational Science Department, Shaoyang College, Shaoyang 422000,China)
Abstract��The memory access patterns of motion estimation algorithms were analyzed, the cache efficiency, related issues and the causes were revealed when they run on general PCs and digitial signal processors. A new cache efficient video data layout method, i.e., overlapped tiled layout method, was presented. The results show that this new data layout method can be used to resolve the cache split loading issue and greatly reduce the cache miss rate. The new layout method can speed up the spiral full search motion estimation process for 28% without change of the motion estimation algorithm itself. So, the use of the overlapped tiled layout method can speeds up the motion estimation process.
Key words: video data; memory; access efficiency; motion estimation
�˶�����(Motion estimation��ME)����Ƶ����ϵͳ�е�һ����Ҫ��ɲ��֡�Ϊ����˶����Ƶ�Ч�ʣ�һ���棬��������������㷨����Ч�ʵ��о�����������ྫ�ɵ��˶������㷨����һ���棬�о����˶������㷨���ڴ����ģʽ���˶�����Ч�ʵ�Ӱ�졣�о�����������˶������㷨���ڴ����ģʽ���˶�����Ч����������Ҫ��Ӱ�졣���˶����������Ӳ��ʵ���У�Chen��[1-2]�о�������ظ�ʹ���Ѿ������뵽��������ݴӶ���С�������ߵ�ѹ������һ���˶������㷨���ڴ����ģʽͨ���ǹ�����������ģ��˶������㷨�Ŀ��Ƽ�Ŀǰ��������ʵ�ֵ��˶������㷨�У��������е��о��������������Ч�ؼ��������������ֱ�֤�������ȵȷ��棬��һ���㷨�ڴ����ģʽͨ���Dz�����ģ���Ծ�ģ����������ӣ����͵�����������[3]����������[4]��PMVFAST[5]�ȵȣ���������ʵ�ֵ��˶������㷨�ڴ����Ч�ʵ��о����١�Alex��[6]���˶����Ƶ��ڴ����Ч���϶��˶������㷨��ʵ�ֽ�����һЩ���ۣ������ʹ��һ���������������洢���������Ӷ�������߷������ݵ����⣬����֮�����������ǣ��������������[-32��32]�����ڿ������ݵĹ��̺ܰ����ҿ������ݲ����ܽ����ٻ����ܰ��ʣ�����������£����㷨����Ч�Ծͻ������½���Yang[7]������˶������㷨���ڴ������������һЩ�˶������㷨�Ĺ��ĺ�Ч�ʣ�����δ����κν��������Kulkarni��[8]����ڱ������IJ������Ż�ý�����ݵĴ洢��ʽ����������Ľ���취��ʵ���к���ʵ�֣���ʹʵ��Ҳ�����ڳ����ø��ӣ�������Ч�����Ա�֤���������е��о�������[8]��ȫ���ٶ�ԭʼ��Ƶ�����ǰ����õ�ƽ��洢��ʽ��ţ���ͼ�����Ǵ������ң����ϵ�����������ŵ������ڴ����棬��ʱΪ��ʹ�˶����Ʒ���Ҳ����ͼ��߽������ߺ����ұ����һЩ����㣬�Ա������Խ���飬������洢��ʽ���䡣����ƽ��洢��ʽ���ʺ������˶����ƣ���ֱ������˶������㷨�ĸ��ٻ���Ч�ʲ��ߵ�ԭ������һЩ��ƾ��ɵ��˶������㷨��Ч�ʡ�
1���˶������㷨���ڴ����ģʽ
1.1�����ٻ���ṹ
ͨ�ü�����������źŴ�����ͨ�������÷ּ��������ٻ�����Ϊ��һ�����棬��Pentium 4 Northwood ���;Ͳ�������ͼ1��ʾ��8 KB ��·�ּ��������ٻ�����Ϊ��һ�����棬��ÿһ�ߵij�����64�ֽڣ�8 KB�ռ乲��128�ߣ�ͬһ���е���������ͬһ���������32������ͬһ·�� ÿһ�߶�Ӧ�Ļ���1����ǩ�������ٲ�Ѱ�ڻ����е�64�ֽڳ����ڴ��������ֻ���ṹ���������ص㣺a. �ڴ��ڻ����еĵ���͵������߳�NΪ��λ����ͼ1��NΪ64�ֽڣ�b. ��N�ֽڶ�����ڴ��ַ�����������N�ֽڵ��ڴ�λ��ͬһ���У�c. ���µ�����Ҫ����ʱ�����������ǽ�Ҫ���������һ���е���������ٱ��õ���һ�ߡ�

ͼ1����·�ּ��������ٻ���ṹ
Fig.1 Structure of 4-way set associative cache
Ӱ��һ������Ч�ʵ���������¼��֣�a. ����δ���л���(cache miss)��b. �����߳�ͻ(cache conflict)��c. �������ݷ��ʣ���Ҫ���ʵ����ݷ�����2�����ڻ�����(cache split load)��
��3�����ضԳ����Ч�ʶ��кܴ��Ӱ�졣�ڴˣ���Intel Pentium 4������Ϊ�����Աȷ�������δ���л�������е����ݷ���ʱ�ӡ�������һ��4�ֽ�����ʱ���������ʵ�����ǡ����һ�������У������У���ʱ����2��ʱ�����ڣ��������У���ʱ��������14��ʱ�����ڣ����������ݷ��ʾ��൱�ڱ��������ݷ���������ռ���˸���Ļ����ߣ�������������δ���л���ĸ��ʡ�
�˶����ƵĹ��̾����ڸ����IJο�֡��Ϊ��ǰ����һ�����ŵ�ƥ���Ĺ��̡�һ�����õ�ƥ������������¹�ʽ��ʾ��

1.2 �˶������㷨�����ݷ���ģʽ
��ȫ�����㷨Ϊ�������˶������㷨�����ݷ���ģʽ��ȫ�����㷨���ڸ����������������ƥ�����п飬����S��С�Ŀ�͵�ǰ���λ�ƾ��������˶�ʸ����ͨ�����������ڲο�֡���Ե�ǰ��ͬλ�õĿ�������Ͻǵ�Ϊ���ĵ�һ�������������磬��ͼ2��ʾ���˶�����ʾ��ͼ�е���Ӱ�����Ǻ��A����������

ͼ2 �˶�����ʾ��ͼ
Fig.2 Diagram of motion estimation search
��ƽ��洢��ʽ�£���ǰ��������Ͻǵĵ�����16�ֽڶ���ģ���ˣ�ͬһ�еĵ㶼����ͬһ�������ڣ������������ʵ�ǰ��ʱ�������ڿ��߷������⣬���ο�������ȫ��ͬ����ͼ2���Կ����������˶�������ΧΪ[-16��16]���Һ��A����ʼλ����64�ֽڶ��룬����A������е������㣬�����A���˶�ʸ����X����Ϊ�������е㶼��绺���߷������ݡ�ͬ�������D�ұߵĵ�Ҳ���ڿ��߷������ݵ����⣬�����B��C�ᡣ�ɴ˿ɼ�����һ������˶��������̻���ڿ��߷������ݵ����⡣
����ͼ2�����Է���ƽ��洢����һ�����⣬�����������Eʱ��������������������Ӱ��������A���������ظ�����Щ���ݻ����ϱ��û���һ������(����352��288���ϵ�ͼ�����)����ˣ����ɱ����Ҫ���·���һЩ���ݲ����л���������
�Ե��͵�D1���ȵ�ͼ��Ϊ����Ϊ�����������ͼ��Ŀ��ȴ�720���䵽768�������ȷ��ÿ��64�ֽڶ��롣������ÿ��Ҫռ��12�������ߣ������������Ĵ�ֱ�߶���48�У������һ�к����˶����ƹ����������12��48=576�ߣ�Զ����128�ߵĻ�����������ͼ2��֪�����A�����ڴ��������ں��ʱ�Ѿ�������ݵĵ���(���ݵ����Ի�����Ϊ��λ)���ʲ��������ݲ������¼���ͬ����B��C���������D��Ҫ�������ڵ��ұߺ������Լ����º�����ڵ�48�����ݣ��ʷ���48�����ݲ����л�����¼������ԣ�ƽ��ÿ��������12�����ݲ������¼���ÿ������������ƽ��ռ�õĻ�������Ϊ12��
����ķ��������˻����߳�ͻ�������߳�ͻ��ԭ���ǻ����ǰ��߷ּ���֯�ģ��ڴ�������������Ž��κλ������У����Ǹ������ַ��ͬ�Ž���ͬ�ļ����У�����������[6]�еĹ�ʽ���м��㡣������ƽ��ʽ�洢�˶����ƵĻ���Ч�ʻ��һ�����͡�
�߶��Ż���Intel H264 ������(ԭʼ�����ڱ�����ȫ����ƽ��洢��ʽ���)��֧��Hypter Thread ��Pentinum 4 Prescott 3.2 G����������ʱʹ��Vtune 6.0 ʵʱ��ȡ���йظ��ٻ���Ч�ʵij����������1��ʾ��Pentinum 4 Prescott ������16 KB 8-·һ�����ݸ��ٻ��棬1 MB 8-·����ͨ�û��档�ڱ�������ж�ʹ����3���ο�֡���˶�������Χ���£�X����Ϊ(-23��23)��Y����Ϊ(-15��15)��ʵ����ÿ�α���300֡��
��1��Intel H264 ���������ٻ���Ч��
Table 1��Intel H264 encoder��s Cache performance efficiency

�����һָ�����2(��������)��ͨ����ζ������δ���л���Գ����кܴ�ĸ���Ӱ�죬���Կ�������ʹ�Ǹ߶��Ż���H.264 �����������ݵĻ����ܰ���Ҳ��һ�����ص����⡣��ˣ�������Ƶ���ݵ�ƽ��洢��ʽֱ�Ӿ������˶����Ƶ��ڴ����ģʽ���˶����ƹ�����ƽ��洢��ʽ�´��ڸ��ٻ���Ч�ʲ��ߺͿ绺���߷������ݵ����⡣
2����Ƶ���ݵĵ���ʽ�洢
������ķ������Կ��������������ǰ��д�ţ���ɵ�ǰҪʹ�õ������ڿռ��ϲ����������ijɰ����ݰ������֯��ͬһ��������������ţ���Ҫ���ʵ����ݷֱ�����4����飬���������ø��ӣ������ڱ������Գ�������Ż���ʵ����������������������֯��ʽ�����˶�����ʱ����Ϊ����Ч�ʵ��������Լ��ʱ�仹���ܵ����������������ĸ���Ч������������ԭ������˵���ʽ������֯��ʽ���������ϵ���Ϊ����ÿ2�еĺ��ԣ���ͼ3��ʾ���������Ҵ�ֱɨ����������ֱ�����1�С������ԣ�����ж�(2n��2n+1)���������ͺ���ж�(2n-2��2n-1)�����������Լ�(2n+2��2n+3)�������������в����ص�����ͼ4��ʾ��������Ϊ����ÿ2�еĺ��ԣ����ϵ���ˮƽɨ����������ֱ�����һ�С�һ���Զ�������ʵ�ǣ��������ִ洢��ʽ��֯����ʱ���洢�ռ��Լ��ԭ����2�����������(�����ϱ�)��2��(��)�������ұ�(�����±�)��2��(��)����⣬���к����ͬһ֡�ڶ����洢2�Ρ�ֱ���ϻ���Ϊ���ݷ���������ԭ����2���������ڵ���ʽ�洢�ܱ����ظ�����ǰ���Ѿ����ʵ�����(ͼ2�к��A��E���������ص��IJ��ֽ�ֻ������1��)��ʵ�����ݷ����������½���
����ǰ������ӶԱȷ�����ͼ��ˮƽ����ʽ�洢ʱ�˶����ƵĻ���Ч�ʣ���������������[-16��16]���ɵó����½��ۣ�
a. ����ʽ�洢û�п��߷������ݵ����⡣������������ͬһ�е���������ͬһ�����ߣ����ԣ�������ˮƽ���Ǵ�ֱ�ƶ������㣬���ݶ�����ͬһ�ߡ������������С����[-16��16]����ʹ�õ�ǰ�ġ��ߡ�����ʹ�ý��ڵ���һ�顰�ߡ�������S����ԭ����ÿһ����鶼��2�������������ڲ�ͬ�ġ��ߡ������1������ڵ�ǰ���ߡ����Ǹ���Ե�飬ֻ�в������뵱ǰ���ߡ�����ô����������ڵġ��ߡ���һ���Ǹ����Ŀ飬��ȫ�������С�
b. ����ʽ�洢����δ���л���Ĵ���ֻ��ƽ��洢��70%���ҡ���ͼ3Ϊ������Ȼ����ͼ���ǵ��͵�D1����ͼ����ôˮƽ�顰�ߡ��Ŀ���Ϊ(720+32)���߶�Ϊ64�� �˶�����ʱһ�δ���1�����ݣ�������(720+32)�߽�����ٻ��棬�����ظ������κ����ݡ���ƽ��ÿ��������(720+32)/90=8.36 ������δ���л����¼���ֻ��ƽ��洢��70%���ҡ�
c. ����ʽ�洢�����ڻ����ͻ���⡣��������ͬһ���������ڴ洢�ռ���Ҳ���ڡ�
d. ����ʽ�洢��Ҫ��Ĵ洢�ռ��Լ��ƽ��洢�ռ��2����
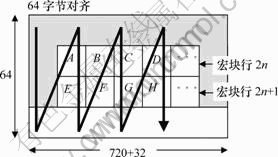
ͼ3 ˮƽ����ʽ�洢ʾ��ͼ
Fig.3 Diagram of horizontal overlapped tiled format

ͼ4 ��ֱ����ʽ�洢ʾ��ͼ
Fig.4 Diagram of vertical overlapped tiled format
3������ʽ�洢��ʵ��
����ʽ�洢�ھ���ʵ��ʱ���������¼������⣺
a. ��Ҫ����ʾ�ؽ���ͼ������Ҫ����ʽת�������ӵ���ʽ�洢ת����ƽ��洢������������õ��������Ϊ������ͨ��������Ҫ��ʾ�ؽ�ͼ����һ���棬�Ա�������˵����ʽת���Ŀ�����Ը��ٻ���Ч�ʱ�ߴ������ŵ���˵���Ժ��Բ��ơ��ڱ�ʵ���У���ÿһ֡�Ľ�β��������1�θ�ʽת�����������������ʽ�洢��Ȼ��������ƽ��洢��
b. ��ʵ�ʵ���Ƶѹ�����У��Ժ��ı���˳��ͨ��������ѭƽ��洢��˳���������������˶�ʸ����Ԥ�����ʱ����Ҫ�������ڵĺ��Ԥ�ǰ�����˶�ʸ����Ȼ��Ԥ����롣����������H.264��˵�����������ΪH.264֧��MBAFFѡ���MBAFFѡ���ʱ��������˳��������ˮƽ����ʽ�洢��ʽ�Ĵ洢˳��1�δ���1�Դ�ֱ���ڵĺ�飬��ˣ�����Ҫ���κ�����ϵĸı䡣������H.263��MPEG-4(Part 2)����Ҫˮƽ����ʽ�洢�ĺ�鴦��˳��ͼ5��ʾ˳��ı䡣���к����������־��������������ָı�Ը��ٻ���Ч�ʲ���Ӱ�죬��Ϊ����2��4��6��8��ż�����ʱ����������Ҫ��������Ȼ�ڸ��ٻ����У���������Ϊ���������Ϻ��ʱ�����16�����ݶ������ǵ������û������ٻ��档��ʵ�ϣ��������������ij������Ŀ��ǣ���Ҫ�ø�������ں����Ϣ�����ҵ����Ԥ���˶�ʸ�������������ȣ�����ʹ��ͼ6��ʾ�ĸ�һ�㴦��˳��Ȼ����m����1���ڵĺ��������ˮƽ���߾��˻���ƽ��洢��ʽ��M��ȡֵ��������ٻ���Ч�ʽ��������͡�

ͼ5 ��鴦��˳��ʾ��ͼ
Fig.5 Diagram of macroblock processing order

ͼ6 ͨ�ú�鴦��˳��ʾ��ͼ
Fig. 6 Diagram of general macroblock processing order
4 ʵ����
ʵ���У��ֱ�ˮƽ����ʽ�洢(m=1)��ƽ��洢��ͬһͼ�������е�ÿһ�����[-16��16]�����������ȫ�����˶�����[10]����Ϊˮƽ����ʽ�洢��ÿһ֡����1�θ�ʽת������Ѱ������ƥ���ʱʹ��PDE�ų������˶������㷨ģ��ʹ��MMXָ��ʵ�֡���2��ʾΪ2�ִ洢��ʽ�ĸ��ٻ���Ч�ʵij������ݡ�ʵ����1̨3.2 G Pentium 4 Prescott ������ɣ�ͼ��ߴ���4CIF(704��576)���ֱ����26֡�˶�����(ֻ��26֡���˶�������Ϊ�˼������ݵIJɼ����̣��ο�֡��Ϊ4)���ɱ�2�ɼ�����2�ִ洢��ʽ�������ʱ�����ڲ�ͬ�����߱�ֵΪ163 68/227 32=0.72����ˣ�ˮƽ���ߴ洢��ʽʹȫ�����˶������ٶ����28%��
��2 ƽ��洢��ˮƽ���߷�ʽ�ıȽ�
Table 2 Comparison between two layout methods

5���ᡡ��
a. ���õ���ʽ�洢��ʽ��ȫ�������˶����ƹ����г��ֵ����ݷ��ʿ绺���߷��ʵ����⡣
b. ʹ�õ���ʽ�洢��ʽ��һ���Ͷ��������ܰд������١�
c. ����ʽ�洢�������ؼ���ȫ�����㷨�˶����ƹ��̣���ԭ�����ƶϣ������µĴ洢��ʽ�Ա���˶������㷨���˶���������ͬ���������ٵ�Ч����
�ο����ף�
[1] Chen C Y, Huang C T, Chen Y H, et al. Level C+ data reuse scheme for motion estimation with corresponding coding orders[J]. IEEE Trans on CSVT, 2006, 16(4): 553-558.
[2] Tuan J C, Chang T S, Jen C W. On the data reuse and memory bandwidth analysis for full-search block-matching VLSI architecture[J]. IEEE Trans on CSVT, 2002, 12(1): 61-72.
[3] Li R, Zeng B, Liou M L. A new three-step search algorithm for block motion estimation[J]. IEEE Trans Circuits Syst Video Technol, 1994, 4(4): 438-442.
[4] Zhu S, Ma K K. A new diamond search algorithm for fast block-matching motionestimation[J]. IEEE Transactions on Image Processing, 2000, 9(2): 287-290.
[5] Tourapis A M, Au O C, Liou M L. Predictive motion vector field adaptive search technique (PMVFAST) enhancing block based motion estimation[C]//Proc SPIE Conf Visual Commun Image Process. Japan, 2001: 883-892.
[6] Lopez-Estrada A A. Understanding memory access characteristics of motion estimation algorithms[EB/OL]. [2007-04]. http://www.intel.com/cd/ids/developer/asmo-na/eng/ 182345.htm.
[7] YANG Sheng-qi, Wolf W, Vijaykrishnan N. Power and performance analysis of motion estimation based on hardware and software realizations[J]. IEEE Transactions on Computers, 2005, 54(6): 714-726.
[8] Kulkarni C, Ghez C, Miranda M, et al. Cache conscious data layout organization for conflict miss reduction in embedded multimedia applications[J]. IEEE Transactions on Computers, 2005, 54(1): 76-81.
[9] Hayes B. Differences in optimizing for the pentium 4 processor vs the pentium III processor[EB/OL]. [2007-04]. http://www.intel.com/ cd/ids/developer/asmo-na/eng/44010.htm.
[10] JVT Reference Software Ver11.0[EB/OL]. [2007-04]. http://iphome.hhi.de/ suehring/tml/.
�ո����ڣ�2007-01-10
������Ŀ������ʡ����������������Ŀ(04C604)������ѧԺ�ص���л���������Ŀ(2003B08)
����飺�Գ���(1965-)���У������۶��ˣ������ڣ�˶ʿ������ͼ��ͼ�����Ƶ�������о�
ͨѶ���ߣ��Գ��룬�У������ڣ��绰��13087399858��E-mail: chenglinzhao@126.com

