J. Cent. South Univ. Technol. (2009) 16: 0976-0981
DOI: 10.1007/s11771-009-0162-8
Log integration on large scale for global networking monitoring
MIAO Jia-jia(缪嘉嘉)1,2, WU Quan-yuan(吴泉源)1, JIA Yan(贾 焰)1
(1. School of Computer, National University of Defense Technology, Changsha 410073, China;
2. Institute of Command Automation, PLA University of Science and Technology, Nanjing 210007, China)
Abstract: Supposing that the overall situation is dug out from the distributed monitoring nodes, there should be two critical obstacles, heterogenous schema and instance, to integrating heterogeneous data from different monitoring sensors. To tackle the challenge of heterogenous schema, an instance-based approach for schema mapping, named instance-based machine-learning (IML) approach was described. And to solve the problem of heterogenous instance, a novel approach, called statistic-based clustering (SBC) approach, which utilized clustering and statistics technologies to match large scale sources holistically, was also proposed. These two algorithms utilized the machine-leaning and clustering technology to improve the accuracy. Experimental analysis shows that the IML approach is more precise than SBC approach, reaching at least precision of 81% and recall rate of 82%. Simulation studies further show that SBC can tackle large scale sources holistically with 85% recall rate when there are 38 data sources.
Key words: machine-learning; clustering; data integration; schema matching; instance matching
1 Introduction
The Internet is now regarded as an economic platform and a vehicle for information dissemination on an unprecedented scale to the world’s population. On the flip side, this success has also enabled hostile agents to use the Internet in many malicious ways[1-2], and terms such as spam, viruses, self propagating worms, and DDoS attacks. In response to such a continually advancing threat, grasping and examining the overall network security situation in real-time have caught more and more attention. MIAO[3] proposed a novel framework to materialize a global view of the network security status based on existing applications. By virtue of data integration technologies, this system can provide the users with a unified interface to perform real-time monitoring and analyzing.
In recent years, work on schema matching can be classified into schema-based and instance-based approaches (For a comprehensive survey on schema matching, see Refs.[4-5]) In the instance-based approach, Semint system[6] uses a neural-network learner, which matches schema elements using properties such as field specification and statistics of data content. LSD system exploits other types of data information such as word frequencies and field formats[7]. Instance matching is related to data exchange, which is the task of restructuring data from a source format (or schema) into a target format (or schema). Clio system introduces value correspondences, which specifies functional relationships among related elements[8-9]. Toward the large scale matching, HE and CHANG[10-11] proposed different approaches by integrating large numbers of data sources on the Internet.
Compared with existing approaches, there are three unique contributions of this work.
(1) A multi-strategy learning technology is developed to find the semantic mappings based on source instances. Considering the special fields of ‘ip_src’ and ‘ip_dst’, this learning approach cannot distinguish the source from the destination. Therefore, a statistics learner is designed to tackle this problem.
(2) A novel framework is proposed to deal with the instance heterogeneous. Different from the traditional approaches, this framework matches the tuples holistically.
(3) The effectiveness of our framework is validated by the real world applications.
2 Problem definitions
2.1 Schema matching
The goal of schema mapping is to produce semantic mappings that enable the query to be based on the global schema. The focus of this work is to compute 1-1 mappings between the global schema and local source schemas. Give the schema names as distinct labels f1, f2, …, fn. Classification is proceeded by training sensor Son a set of training examples {(x1, fi1), …, (xm, fim)}, where xm is an object, and fim is the observed label of that object. During the training phase, the sensor inspects the training examples and builds an internal classification model to classify objects. In the matching phase, by giving an object x, sensor S uses its internal classification model to predict label for x. Here it is assumed that the prediction is in the form of 1|x,
S), …, s(fn|x, S)>, where 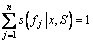 , and s(fj|x, S)
, and s(fj|x, S)
is the confidence score of sensor S, of which x matches label fj. And the higher the confidence score, the more certain the sensor’s prediction.
2.2 Instance matching
Each legacy security system has an attack description table. There are seemingly distinct tuples which represent the same real-world entity. The correlations between different tables can be found, and then the attack_id should be translated to a standard.
Let different tables of attack description be T1, …, Tn, which consist of set of tuples, denoted by Ti=(ti1, …, tim), where tij=ij, DESCij>. For each unique description D, our task is to output the set of IDij, that is, {IDij|DESCij=D}.
3 IML approach
IML operates in two phases: training and matching (see Fig.1). And there exist four major components: sensor, combiner, scorer and manual intervention.

Fig.1 Two phases of IML approach
In the training phase, user prepares the samples for sensor to learn the value characteristic. Then, it trains the combiner to assign the weight to each sensor. The output of the training phase is the internal classification model, for example, the prediction model[12]. In the matching phase, the trained sensors are used to match new source instance. The scorer combines the sensors’ predictions. The output is to map for the target schema. Users can either accept the mapping or provide some feedbacks.
3.1 Training
3.1.1 Data preparation
Let several sources be input, IML begins by asking the user to specify 1-1 mappings between the global schema and the schema of these sources. Furthermore, after a new source is matched by IML, it can serve as an additional training source. This makes IML unique so that it can directly reuse past mappings to improve its performance. Next, user extracts data from the two sources for training.
Suppose that two sources IDS A and IDS B are given by IML, whose schemas are shown in Fig.2(a), together with the global schema. Next user simply has to specify the mapping shown in Fig.2(b). And then the system extracts the samples of data stream at a rate of 5 s-1 (see Figs.2(c) and (d)).
3.1.2 Training of sensors
IML trains each sensor on the training samples. Each sensor examines its training example to construct an internal classification model that helps to match the new sources (see Figs.2(e) and (f)). In this system, there are totally four types of sensors explained as follows.
(1) Format sensor: The format of value can be represented as a regular expression, for instance, the IP value like ‘192.168.0.1’, which can be represented as ‘x.x.x.x’.
(2) Value range sensor: Range is one of the characteristics for those objects whose data types are numbers. For example, the value of length field is [1, 65 535].
(3) Type sensor: The special type is presented in one table, e.g., time type in log table.
(4) Statistics sensor: This sensor can catch the distribution of the data values.
User can define other sensors to extend IML.
3.1.3 Training of combiner
The combiner uses a technique called stacking[13] to combine the predictions of sensors. Training the combiner works in the following steps. Firstly, the combiner asks the sensors to predict the labels of the training examples. Secondly, since the combiner knows the correct result, it is able to judge the situation that each sensor performs with respect to each label. Finally, the combiner assigns to each label fi and each sensor Si (weight  ), which indicates how much it trusts the predictions of sensor Si (see Fig.2(g)).
), which indicates how much it trusts the predictions of sensor Si (see Fig.2(g)).
3.2 Matching phase
Once the sensors and combiner are trained, IML will be ready to predict semantic mappings for new sources. Fig.3 illustrates the matching process on source IDS C.
Firstly, IML extracts a set of log data from IDS C (see Fig.3(a)). Secondly, Fig.3(b) shows that IML begins by matching each data instance of this field, uses the sensors to mach each instance, and then combines their predictions using the combiner. Thirdly, the combiner

Fig.2 Example of training phase: (a) Schema of global and source; (b) Mapping relationship built by users; (c) Instances of two schema; (d) Different sensors; (e) CVs of format sensor; (f) Scores of format sensor; (g) Weights of format sensor

Fig.3 Example of matching phase: (a) Extracting data from IDS C; (b) Source field for example; (c) Sensors and combiner; (d) Processing of user’s feedback
combines different predictions into a single prediction. For each filed, scorer computes a combined score, which is the sum of the scores that are given in the field and weighted by the sensor weights (see Fig.3(c)). Finally, according to the scores, the system takes these predictions together and outputs the 1-1 mappings.
As shown in Fig.3(d), users’ feedbacks can further improve matching accuracy, which are also necessary for matching the ambiguous schema elements. Sometimes the machine cannot precisely determine the mapping relationship. Then the user can intervene it. And this will do better for the situation come next time.
4 SBC approach
SBC operates in two phases: generalizing and clustering. In the generalizing phase, SBC should compute the weightiness of each word in the description field, and then cut the lower ones, which do not matter to understand the tuples. In other words, the remained words are the key ones of each tuple. In the clustering phase, different from the traditional matching approaches, SBC matches the entire input table at one time. A clustering method is used to find the correlations. Firstly, SBC clusters the semantic related descriptions together. Then, the mapping of different IDS emerges naturally. Also, the entire matching of large scale tables benefits that the most representative words will be selected for each attack.
4.1 Generalizing phase
There is a premise that this approach must be taken into account. The weightiness of terms in each tuple is not equal to each other. In fact, the key word is usually the one that does not occur in other descriptions. As shown in Fig.4(a), the word ‘This’ occurs twice in two tuples, and ‘DDoS’ is unique in the whole table of description field. According to this, the frequency of the word is negatively related to the importance of word. This relies on their information entropy[14].
For implementation, SBC splices all descriptions of a certain table as a paragraph (see Fig.4(b)). Then as shown in Fig.4(c), it calculates the weightiness of each distinct term to select the keyword (see Fig.4(d)). The following formula defines the ith term’s information entropy:
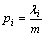 (1)
(1)
where m denotes the sum number of terms in this paragraph; and λ denotes the sum of the occuring time of the certain term. In addition, the weightiness of the term is defined as follows:
 (2)
(2)

Fig.4 Example of generalizing phase: (a) Combining descriptions to paragraph; (b) Calculating terms’ weightiness; (c) Obtaining keyword of each tuple; (d) Keywords
4.2 Clustering phase
Once the generalizing is finished, SBC takes the processed tables as input and matches all the tuples holistically. The data are so simple that just the standard clustering algorithm can finish this job[15].
Fig.5 shows the fast standard clustering algorithm for large scale instance matching. In Fig.5, di,j represents the distance between object[i] and cluster[j]; and δ denotes the threshold that is designed by the SBC. The number of objects with a cluster[j] is denoted as member[j].
As shown in Fig.6(a), the large scale tuples extract their keywords by generalizing method. After the clustering algorithm, SBC finds out the high score of member[j], which means that these terms are frequently used by these legacy security systems, as shown in Fig.6(b). Then, SBC can get the most representative of words for each attack description (see Fig.6(c)).
|
Input: |
object[N]: array of data objects |
|
Output: |
cluster[K]: array of cluster centers |
|
1: |
K=0; |
|
2: |
N=number of objects; |
|
3: |
For i=0 to N?1 |
|
4: |
|
For j=0 to k |
|
5: |
|
If di,j<δ then |
|
6: |
|
object[i] belongs to cluster[j]; |
|
7: |
|
member[j]++; |
|
8: |
|
newCluster=false; |
|
9: |
|
If newCluster then |
|
10: |
|
createCluster(object[i]); |
|
11: |
|
member[j]=0; |
|
12: |
|
K++; |
|
13: |
Output cluster[K] |
|
|
|
|
|
|
Fig.5 Fast standard clustering algorithm for large scale instance matching
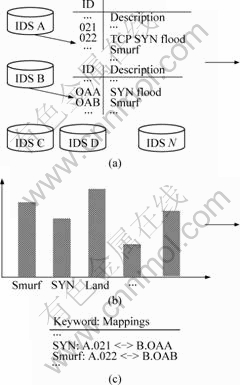
Fig.6 Example of clustering phase: (a) Large scale tuples from different databases; (b) Frequent words used; (c) Mapping relationship of each instance
5 Experiments
The system was used to evaluate the matching accuracy of IML in different sizes of training data sets and the contribution of different components; while experiments were used to evaluate the precise and recall rate of SBC in different sizes of input tables.
In particular, the framework was implemented in C++ and all the experiments were carried out on a Windows XP machine with Pentium-M1.8 GHz and 2.0 G memory.
5.1 Experiment setup
In this domain, there are 38 source schemas used. The input schemas are almost 6-tuple ones, whose characteristics are shown in Table 1.
Table 1 Data sources for experiments

5.2 Experimental results
5.2.1 Schema matching with IML
Fig.7(a) shows the variation of the matching

Fig.7 Results of experiments with IML approach: (a) Matching accuracy of different sample scales; (b) Matching accuracy without some components
accuracy as a function of the number of data available from each source. The results show that the performance of IML stabilizes quickly: it climbs steeply in the range of 5-20, minimally from 20 to 200, and levels off after 200. IML thus appears to be robust, and can work well with little data.
As shown in Fig.7(b), the contribution of sensors and combiner are indispensable. Without sensors or combiner, the accuracy of IML charges downslide clearly. The results show that with the current system, both sensors and combiner make important contributions to the overall performance.
5.2.2 Instance matching with SBC
As mentioned above, the parameters of the generalizing and clustering phrases have a great influence on the precision and recall rate of results.
Fig.8(a) shows different precisions with different parameters, where Nterms denotes the number of terms that are selected as keyword candidates in the generalizing phrase; and δdistance represents the distance threshold when SBC clusters the semantic related keywords. The parameters are set by the experience. For each scale, the three bars (from left to right) different scales of matching table. Fig.8(b) shows different recall
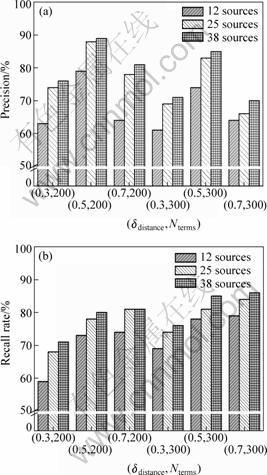
Fig.8 Results of experiments with SBC approach: (a) Precision of SBC with different scales and parameters; (b) Recall rate of SBC with different scales and parameters
rates with different parameters. It can also be discovered that the precision and recall rate of SBC is strongly related to the parameters and input tables’ scale.
According to the data environment, design (δdistance, Nterms)={(0.3, 200), (0.5, 200), (0.7, 200), (0.3, 300), (0.5, 300), (0.7, 300)}. As shown in Fig.8, the keywords should decrease with the increase of Nterms, resulting in that the precision of SBC should decrease, while the recall rate of SBC should be synchronized and grow up. Due to the increase of δdistance, the number of cluster decreases.
6 Conclusions and future work
(1) In schema matching aspect, due to the special situation, the instance-based measure method is focused. The system applies sensors, each of which aims at the problem from different perspectives, and then combines the sensors’ predictions. Experimental results show that IML appears to be robust and efficient.
(2) In instance matching aspect, handling large scale tables together is considered. The large scale tables can provide enough information to select the most representative of words for each attack description. The experiment results verify that SBC is efficient enough.
(3) Next, this work should be extended in two ways. Firstly, the n:m mapping problem should be addressed, which exists in data integration system commonly. Secondly, the clustering algorithm should be improved by tuning parameters.
References
[1] US-CERT. Technical cyber security alerts[EB/OL]. [2005-10-04]. http://www.us-cert.gov/cas/techalerts/.
[2] LI Xiang, LIU Guang-ying, QI Jian-xun. Fuzzy neural and chaotic searching hybrid algorithm and its application in electric customers’s credit risk evaluation[J]. Journal of Central South University of Technology, 2007, 14(1): 140-143.
[3] MIAO Jia-jia. GS-TMS: A global stream-based threat monitor system[C]//Proceedings of the 34th International Conference on Very Large Data Bases. Auckland: VLDB Endowment, 2008: 1678-1687.
[4] DOAN A, HALEVY A Y. Semantic-integration research in the database community[J]. AI Magazine, 2005, 26(5): 183-194.
[5] RAHM E, BERNSTEIN P A. A survey of approaches to automatic schema matching[J]. The VLDB Journal, 2001, 11(1): 334-350.
[6] LI W, CLIFTON C. SEMINT: A tool for identifying attribute correspondences in heterogeneous databases using neural networks[J]. Data and Knowledge Engineering, 2000, 3(4): 49-84.
[7] DOAN A, DOMINGOS P, HALEVY A Y. Reconciling schemas of disparate data sources: A machine-learning approach[C]//Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data. Santa Barbara: ACM Press, 2001: 509-520.
[8] HAAS L M. Clio grows up: From research prototype to industrial tool[C]//Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data. Baltimore: ACM Press, 2005: 805-810.
[9] MILLER R J. The Clio project: Managing heterogeneity[J]. SIGMOD Record, 2001, 30: 78-83.
[10] HE B, CHANG K C. Making holistic schema matching robust: An ensemble approach[C]//Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining. Chicago: ACM Press, 2005: 429-438.
[11] HE B, CHANG K C. Discovering complex matching across web query interfaces: A correlation mining approach[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle: ACM Press, 2004: 148-157.
[12] YANG Q, ZHANG H H, LI T. Mining web logs for prediction models in WWW caching and perfecting[C]//Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago: ACM Press, 2001: 473-478.
[13] TING K M, WITTEN I H. Issues in stacked generalization[J]. Journal of Artif Intell Res, 1999, 10(5): 271-289.
[14] DAEMI A, CALMET J. From ontologies to trust through entropy[C]//Proceedings of the International Conference on Advances in Intelligent Systems―Theory and Applications. Luxembourg: IEEE Computer Society, 2004: 12-43.
[15] BERKHIN P. A survey of clustering data mining techniques[J]. Grouping Multidimensional Data, 2006, 1(2): 25-71.
(Edited by CHEN Wei-ping)
Foundation item: Projects(2007AA01Z126, 2007AA01Z474) supported by the National High-Tech Research and Development Program of China; Project(NCET-06-0928) supported by the Program for New Century Excellent Talents in University
Received date: 2009?01?17; Accepted date: 2009?04?10
Corresponding author: MIAO Jia-jia, PhD; Tel: +86?13770734040; E-mail: elanmiao@gmail.com

