基于一阶逻辑的非一致性关系数据管理
谢东1, 2,伍锦群3,刘罗仁3
(1. 湖南人文科技学院 计算机科学技术系,湖南 娄底,417000;
2. 中南大学 信息科学与工程学院, 湖南 长沙,410083;
3. 娄底职业技术学院,湖南 娄底,417000)
摘要:对于给定的约束,数据库可能是非一致的。为了获得一致性结果,基于一阶逻辑,提出非一致性关系数据管理框架,研究多种合取查询类型对应的连接图及其连接的充分性,分析一致性查询应答的计算复杂度。在查询连接类型是键-键、非键-键或不充分的键-键,且查询对应的连接图是非环的情况下,一致性查询应答的计算在多项式时间内是可解的。针对大量实际的易处理合取查询,给出查询重写算法获得可重写的查询。算法首先判断初始查询是否为可重写,再基于连接图进行递归计算构造一致性识别语句,然后,与初始查询合取产生一个新的一阶重写查询,用于计算一致性结果。对于非环的自连接查询,由于递归重写算法不能剔除非一致性元组,因此,采用初始查询获取了用于剔除违反键约束的非一致性元组的语句。
关键词:关系数据库;非一致性关系数据;一阶逻辑;查询重写
中图分类号:TP 311 文献标志码:A 文章编号:1672-7207(2011)07-2034-08
Inconsistent relational data management based on first-order logic
XIE Dong1, 2, WU Jin-qun3, LIU Luo-ren3
(1. Department of Computer Science and Technology, Hunan Institute of Humanities, Science and Technology,
Loudi 417000, China;
2. School of Information Science and Engineering, Central South University, Changsha 410083, China;
3. Loudi Vocational and Technical College, Loudi 417000, China)
Abstract: In order to obtain consistent answers over databases that might be inconsistent with respect to a set of integrity constraints, a framework was proposed for inconsistent relational data management based on first-order logic. The join graphs was researched to conjunctive query types and the sufficiency of their join, the computational complexity for consistent query answering (CQA) was analyzed. If the join classes of queries are the key-key, nonkey-key or insufficient key-key, and the join graphs of these queries are acyclic, the computational complexity of CQA is PTIME (polynomial time). For a large and practical class of conjunctive queries, some query rewriting algorithms were proposed to obtain the rewritten query for computing the consistent answers. Firstly, the algorithms judge whether a initial query is rewritable,and the consistent identification statement is constructed based on the join graph by the recursive computation, and the statement combines with the initial query to construct a new first-order rewritten query for computing consistent answers. To acyclic self-join queries, the recursive rewriting algorithms can not eliminate inconsistent results, so the initial query combines with the statement that eliminates inconsistent results with respect to the key constraint.
Key words: relational database; inconsistent relational data; first-order logic; query rewriting
完整性约束(Integrity constraint,IC)作为数据库模式的一部分,有效地保证了数据的完整性和有效性,使数据符合现实世界的实体规则。然而,现实世界的一个实体在数据库中常常是对应多个不一致的数据。当集成分布式和独立数据源时,不同的数据源在集成前是满足各自本地数据库的IC,但集成后可能包含冲突的元组。多个数据源的海量数据集成引起的非一致性数据[1]问题是数据管理领域的一个重要问题。例如,在一个集成系统中,供应商S1有2个余额:10 K和50 K,产生了冲突的信息。给定查询余额大于20 K的供应商,在普通的标准查询中,S1将出现在返回结果中,但并不知道S1的余额大于20 K的确定性有多大,因为S1的余额可能是10 K。非一致性数据库的一个策略是数据清洗[2]。它识别和纠正数据中的错误,恢复数据库到一致性状态,但数据清洗技术是半自动的,需要人为干预,且处理代价昂贵。非一致性数据往往是有用的,不可能为了保存数据的一致性而修改数据,导致有用的数据丢失。替代数据清洗的一种方法是保持源数据不改变,而是在查询时解决非一致性,识别一致性数据。在非一致性数据环境下执行一致性查询,即使不知道正确的一致性数据,也能防止查询结果包含不正确的元组,用户查询能得到符合IC和查询条件的确定性结果,称为一致性查询应答[1]。这种方法能辅助数据清洗工具识别可能的错误数据,从而促进多数据源大规模集成。对不同分类的查询和约束,Chomicki等对一致性查询应答的计算复杂性进行了研究[3]。文献[1]建议一阶查询重写算法,但只能采用无量词的合取查询和二元约束,一些易处理的合取查询也不能进行查询重写。Fuxman等[4-6]基于连接图允许存在量词的合取查询,采用一种连接图(Join graph)的概念。这种连接图的顶点是查询的关系名,边是关系之间的连接属性,边的指向是非键属性指向键属性。若合取查询对应的连接图没有重复的关系或者内置谓词,且其属性连接是充分的,则所对应的连接图也是非环的,这个连接图是1棵树。这类查询是非常普通的,这是由于环很少出现在实际的查询中[7]。Fuxman等[5]主要研究键依赖的合取查询,它能识别出大量的合取查询是一阶可重写的,并且提供了一个有效的查询重写算法,证明了键依赖的树合取查询的CQA计算是PTIME;而对于连接图不是森林的无重复关系的查询,其CQA计算是NP完全问题。对于合取查询的多样性,文献[8-9]提出了非一致性数据库的范围语义,给出了基于一致性查询范围的实际聚集查询重写方法。文献[10-11]对主键约束下的合取查询和一致性连接进行了分析。文献[12-13]提出了一种冲突图的解决方法,把元组冲突图放到内存中,产生一个Java程序的过程化方法计算一致性结果。其前提是数据库中只存在较少的冲突元组。假定冲突的数量对于冲突超图是足够小,能存储到主存中。文献[14-15]基于逻辑编程方法,能处理所有的一阶查询和更多的完整性约束类型,但其重点是基于稳定模型语义的可表达性和获取正确的逻辑结果,而不是计算的有效性和可扩展性,不能产生有效的解决结果。因此,这些系统的计算复杂度比SQL的更高,不能运行在海量数据库上。本文采用一个非常规的约束观点,在查询数据库时约束一组一致性结果。为了避免混乱,把约束称为查询约束,查询约束由每个关系最多1个键组成。本文主要内容如下:(1) 基于一阶逻辑和完整性约束提出了非一致性数据管理框架,分析了多种查询类型对应的连接图及其一致性查询应答的计算复杂度;(2) 在查询连接类型是键-键、非键-键或不充分的键-键等情况下,若查询对应的连接图是非环的,则CQA计算是PTIME的;(3) 针对大量实际的易处理合取查询,提出了查询重写算法,首先判断是否为可重写查询,然后,基于连接图构造一个新的一阶重写查询,用于计算一致性结果,并给出算法的正确性证明。
1 非一致性数据管理框架
1.1 一阶逻辑
一阶逻辑在表示数据库概念方面,提供了一种统一的语言,可作为表示约束和查询统一语言。一阶逻辑的形式语言由各种符号依据一定的语法规则连接起来,用以表示某种逻辑推理。一阶逻辑语言的语义是表示该语言中所指称的对象范围、每一个词和句子所表达的含义。一阶语言中的符号有函数符号和谓词符号,这些都应在它的语义中有具体的含义。任一一阶谓词公式由它们的递归定义,不外乎是在项上由原子谓词公式及量词经逻辑联词?,?, ,∧,∨,→和?所生成。项的递归定义所容纳的基本符号是个体常量、个体变元以及个体函数符号;原子谓词公式实质上是n(n≥0)目谓词变元(n=0时为命题符号)。确定任一一阶谓词公式的取值, 事实上只须对谓词变元(包括零目谓词的命题符号)、个体常量、个体函数和个体域给出解释和指定即可。
,∧,∨,→和?所生成。项的递归定义所容纳的基本符号是个体常量、个体变元以及个体函数符号;原子谓词公式实质上是n(n≥0)目谓词变元(n=0时为命题符号)。确定任一一阶谓词公式的取值, 事实上只须对谓词变元(包括零目谓词的命题符号)、个体常量、个体函数和个体域给出解释和指定即可。
1.2 完整性约束
一个数据库模式是具有有限元数的关系中有限元组的集合。在关系数据库中,采用固定的关系模式S=(U, R, B)。其中:U表示可能的无限数据库域;R表示一组数据库谓词;B表示一组数据库内置谓词(=,≠,>,≥,<,≤)。这个模式决定了一阶谓词逻辑语言L(S)。一个数据库实例D可以看作是数据库元组R*(c1, …, cn)的有限集合(其中:R*为R的1个谓词;c1, …, cn为U中的常数;n为关系的元数)。
完整性约束是一阶谓词逻辑语言L(S)中的语句,是基于模式的一阶查询语言。以下采用P1, …, Pm表示关系;A1, …, An表示原子公式;元组的变量和常量用x, y, …表示;v表示无量词内置谓词;关系P中元组a表示为P(a)。考虑以下几类基本的IC。
(1) 全称约束(Universal integrity constraints): ?A1∨…∨An∨v (若n=2,则为二元约束)。
(2) 否定约束(Denial constraints):?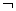 A1∨…∨An∨v。否定约束是全称约束的特殊情况,只包含否定。
A1∨…∨An∨v。否定约束是全称约束的特殊情况,只包含否定。
(3) 函数依赖(Functional dependencies,FD): ?x,y,y*:(P(x,y)∨P(x,y*)∨y=y*)。它是二元否定约束的一个特殊情况,可以采用X→Y的形式表示,X是关系P的一组属性,对应于x;Y是关系P的一组属性,对应于y和y′。
(4) 引用约束(Referential integrity constraints/ Inclusion dependencies,INDs): ?x, y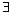 z:(P2(x, y)∨P1(y, z)),可以写成P2[Y2]
z:(P2(x, y)∨P1(y, z)),可以写成P2[Y2] P1[Y1],Y1和Y2分别是P1和P2中对应y的一组属性。
P1[Y1],Y1和Y2分别是P1和P2中对应y的一组属性。
因此,一个查询是L(S)的一阶形式Q(x1, …, xn)。这里x1, …, xn是自由变量,n≥0。如果每个D′∈ Rep(D, IC ):D′╞ Q(t′),那么元组t′=(t1,…, tn)是一致性结果,即x1, …, xn分别取值t1, …, tn。若n=0,则查询是布尔查询,对于每个D′∈Rep(D, IC ),若D′╞ Q(t’),则查询为真,否则为假。
假定在模式中每个关系最多一个键依赖。为了便于指定键依赖,在关系中第1个属性下加下划线。如q=?x, y, z: R1(x, y)∧R2(y, z)表示R1的键属性为x和R2的键属性为y。这里主要关心合取查询类型。实际中,大多数查询属于合取查询。采用x表示出现在键位置的常量或者变量,y表示出现在非键位置的常量或者变量,合取查询可以采用如下的形式:q(z1, …, zk)= ?w1, …, wm: R1(x1, y1) ∧…∧Rn(xn, yn)(其中,w1, …, wm,z1, …, zk为q中出现的变量;z1, …, zk为自由变量)。若w出现在Ri(xi, yi)和Rj(xj, yj),且i≠j,则是一个连接。若w出现在xi和xj,则为键-键连接(key-key);若w出现在yi和yj,则为非键-非键连接(nonkey- nonkey);若w出现在xi和yj,或者w出现在xj和yi,则为非键-键连接(nonkey-key)。
1.3 候选数据库与一致性查询应答
定义1 非一致性数据库(Inconsistent database, IDB[1])。设I是数据库D的一个实例,对于D上的任意IC,若?I╞ IC,则D是一致性,否则D是非一致性数据库。
定义2 对称差(Distance[1])。给定数据库实例I和I′,则2个数据库实例的对称差?(I, I′)=(I-I′)∪(I′-I)。
定义3 候选数据库(Repaired/Candidate database, CDB[1])。给定一组完整性约束∑和数据库实例I,若I′╞∑,则I′是I关于∑的一个CDB,且不存在I*╞∑和?(I, I′) ?(I, I*)。
?(I, I*)。
I′是模式中满足IC的I子集,在集合包含与I有最小的区别。Rep(I, IC ) 表示为I关于IC的候选数据库。候选数据库不唯一,1个候选数据库是I的1个子集,每个候选数据库符合1个可能的已清洗的一致性数据库。
例1 设S是只有一个关系R(name,pay)的模式和实例I= {(Tom,1 000), (Tom,1 500), (Mary,2 000)},其函数依赖为name→pay。
可以看到这个实例I是非一致性的。TOM的工资信息是不确定的。
定义3 存在2个候选数据库I1={(Tom,1 000), (Mary,2 000)}和I2={(Tom,1 500), (Mary,2 000)}。而I3={(Tom,1 000)},I4={(Tom,1 500)}和I5={(Mary, 2 000)}都不是候选数据库,因为这些实例与I的差别不是最小的,如?(I, I1)?(I, I3)。
定义4 一致性查询应答(Consistent query answers, CQA[1])。设I是模式R上一个可能不满足一组完整性约束∑的数据库实例。给定一个查询q,若对于I关于∑的每个候选数据库IREP,都有IREP╞q(t),则t是关于∑的一致性结果,表示为t∈CQA(q, I, ∑)。若为布尔查询,则表示为CQA(q, I, ∑)=true(false)。
例2(继续例1) 假定q1(name)=?pay:R(name, pay),那么q1在I上的一致性结果是{(Tom),(Mary)};假定q2(name, pay)=R(name, pay),那么q2在I上的一致性结果是{(Mary,2 000)},而{(Tom,1 000)}和{(Tom,1 500)}不是一致性结果。这是由于它们没有都出现在I1和I2中。在直觉上也反映了Tom的工资是非一致性的。
例2表明:计算一致性结果与候选数据库相关,而CQA计算所有的候选数据库是不可行的。
1.4 连接图
为了直观地表示查询中的关系属性的连接,采用图表示查询。节点表示查询中的关系,弧表示关系之间采用属性进行连接。
定义5 有向连接图(Directed join graph)。设Q是一个合取查询,若G满足以下条件,则G是一个有向连接图:(1) G的顶点是Q中使用的关系,对于任意的2个顶点Ri和Rj,不存在i≠j;(2) 对于任意顶点Ri和Rj,若Ri的一个非键属性或者键属性等于Rj的键属性,则Ri到Rj存在有向边,边的方向是Ri指向Rj;(3) 对于任意顶点Rk,Ri和Rj,若Ri的一个非键属性等于Rj的键属性,则不存在Rk的一个非键属性等于Rj的键属性;(4) 对于任意的顶点Ri,一定不存在环;(5) 入度为0的顶点数量不超过1个。
条件(1)表示在查询中每个关系最多被使用1次;条件(2)表示主要考虑的是等值连接和键依赖的IC;条件(3)表示如果某个关系的一个键属性等于另一个关系的一个非键属性,则不存在第3个关系的任意一个属性等于第1个关系的一个非键属性;条件(4)表示不能存在自连接;条件(5)表示不存在一个关系的主键连接另外2个关系非主键。
有向连接图的2类连接在试验中(如TPC-H标准)普遍使用,在计算复杂度上是PTIME。若Q是一个合取查询,Q的连接图是有向连接图,则Q是可重写的。可以把查询归为如下几类:
q1=?x,z,y: R1(x, y)∧R2(z, y),q1是非键-非键连接;
q2=?x,y,z,w:R1(x,y)∧R2(z,y)∧R3(y,w),q2是非键-键连接,但入度为0的顶点数量有2个,不是根树;
q3=?x,y,z:R1(z,x,y)∧R2(y,x),q3是存在环的非键-键连接,但x在R1中键属性的连接不是完全的;
q4=?x,y,z:R1(x,z)∧R2(y,x),q4是非键-键连接;
q5=?x,y:R1(x,y)∧R2(y,x),q5是存在环的重复关系的非键-键连接;
q6=?x:R1(x)∧R2(x),q6是键-键连接;
q7=?x,y,z,w:R1(x,y)∧R2(y,z)∧R3(z,w)∧R4(z,c)∧R5(y,c),q7全部为非键-键连接。
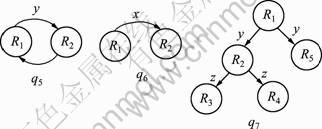
图1 连接图
Fig.1 Join graphs
1.5 不易处理的查询
定义6 设在合取查询Q的Ri(xi,yi)和Rj(xj,yj)中,若xj的每个变量都出现在yi或者xi中,则这个连接是充分的;若xj的每个变量没有都出现在yi或者xi中,则这个连接是不充分的。
这里没有给出一类查询:若xj的每个变量没有都出现在xi中,且i=j,则为重复关系的非键-键不充分连接。
定理1 设在合取查询Q的Ri(xi,yi)和Rj(xj,yj)中,若xj的每个变量没有都出现在xi中,且i=j,则这类查询是不可能的。
证明 假定这类查询是可能的,则xj的元数小于xi的元数。由于i=j,故xi=xj,得到xj的元数等于xi的元数。矛盾。
定理2[3] 对于给定的单一关系的合取查询和键约束,若其连接类型是非键-非键,则CQA计算是NP完全问题。
然而,这种基于键约束的合取查询的连接类型是单一关系的非键-非键连接,在连接图中产生了环。这类查询不属于文献定义的Ctree类型。文献证明了对于Ctree类型,若放松连接约束(例如键-非键的连接不是充分的),则可能导致NP完全问题,对于可计算的合取查询类型C*,当且仅当合取查询的连接图是非环的。然而,没有必要排除大量实际的合取查询类型是一阶查询可重写的,它的CQA计算容易处理。下面证明多个关系下的非键-非键连接也是NP完全问题。
定理3 对于给定的多关系的合取查询和键约束,若其连接类型是非键-非键或非键-键连接(其连接图存在环),则CQA计算是NP完全问题。
证明 该证明可以从单调3-SAT(可满足性)问题进行简化。设β=δ1∧…∧δm∧Ψm+1∧…∧Ψp是一个合取查询,所有出现在δi的是肯定的,出现在Ψi的是否定的。假定2个二元关系R1和R2,关系的第1个属性是键属性。建立一个实例I,若变量v出现在δi,则I(R1)包括元组(i,v);若变量v出现在Ψi,则I(R2)包括元组(i,v),非键-非键类型的查询Q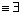 x, y, z: R1(x, y)∧ R2(z, y)或非键-非键连接(其连接图存在环)的查询Qx, y: R1(x, y)∧R2(z, y)。则当且仅当存在I的一个CDB如I*
x, y, z: R1(x, y)∧ R2(z, y)或非键-非键连接(其连接图存在环)的查询Qx, y: R1(x, y)∧R2(z, y)。则当且仅当存在I的一个CDB如I*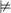 Q,满足β。
Q,满足β。
定理4[4] 设Q是查询x,y,m,z:R1(x,y)∧R2(m,y,z),Q*是查询x,x′,y:R1(x,y)∧R2(x′,y),则从Q*的CQA计算到Q的CQA计算是一个PTIME约简,即从部分键属性连接的CQA计算到非键连接的CQA计算是一个PTIME约简。
定理5 对于给定的合取查询和键约束,如果其连接类型非键-键和无重复关系的键-键连接类型是不充分的,则CQA计算是NP完全问题。
证明 根据定理4,从部分键属性连接的CQA计算到非键连接的CQA计算是一个PTIME约简,则非键-非键和无重复关系的完全不充分的键-键连接的CQA计算到不充分连接的非键-键的CQA计算是一个PTIME约简,而非键-非键连接的CQA计算是NP完全问题,因此,不充分连接的非键-键和无重复关系的完全不充分的键-键连接的CQA计算是NP完全问题。
1.6 易处理的查询
定理6[4] 对于给定的合取查询和键约束,若其连接类型是键-键连接,或者非键-键连接是充分的,且查询对应的连接图是非环的,则CQA计算是PTIME的。
定理7 对于给定的合取查询和键约束,若其连接类型键-键是不充分的,则CQA计算是PTIME的。
证明 根据定理4,从部分键属性连接的CQA计算到非键连接的CQA计算是一个PTIME约简,则其连接类型非键-键的CQA计算到键-键不充分连接的CQA计算是一个PTIME约简。根据定理6, 非键-键的CQA计算是PTIME的,因此,键-键不充分连接的CQA计算是一个PTIME的。
根据定理6和定理7,q4,q6和q7的CQA计算是PTIME的。根据定理2至定理5,q1,q2,q3和q5查询的CQA计算是NP完全问题。
尽管第2个查询存在非键-键连接,但入度为0的顶点数量有2个。实际上,关系R1和R2的连接为非键-非键连接,因而,这种入度为0的顶点数量大于1的非键-键连接是普通非键-键连接的一个子类。因此,把入度为0、顶点数量大于1的非键-键连接、非充分的非键-键连接和完全非充分的键-键连接归类为非键-非键连接,根据这种归类,q1,q2和q3是非键-非键连接。其中q15是最普通的查询。尽管存在大量的不可计算的查询类型,但实际上,这些不可计算的查询类型是很少出现的。q15这类查询是非常普通的,这是由于环是很少出现在实际的查询中,相当多的查询是一个关系的非键属性连接到另外一个关系的键属性上,并且其键属性的连接是充分的。实际上,TPC-H测试基准中22个查询有20个是这类查询。
查询重写是采用一阶查询重写方法对大量易处理的查询进行重写,重写的查询也是一阶的,可以被SQL表示。初始查询和重写查询属于同一类查询,因此,CQA的计算能被相同的数据库查询引擎直接重用,有效地利用现有DBMS的功能,不要求程序的预处理和重加工。这种方法是容易处理的,这是由于重写查询能在PTIME和独立于数据的途径下得到,因而,这种方法在计算复杂度上是PTIME的。
定义7 设R是一个模式,∑是一组完整性约束,q是R上的一个查询。对于R上的每个实例I,t是关于∑的一致性结果,若存在一个查询Q,I╞Q(t)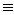 t∈CQA(q,I,∑),则Q是q关于I和∑的一阶重写查询。
t∈CQA(q,I,∑),则Q是q关于I和∑的一阶重写查询。
对于给定的查询,首先要识别是否可计算的,然后根据查询类型选择相应的算法进行计算。对于几类易处理的查询,区分为2类:键-键连接查询和非键-键连接查询,并给出相应的算法。
例3 在关系R(x,y)中,给定查询q=x:R(x,10)和实例I1={(v1,10),(v1,5)},候选数据库为I2={(v1,10)}和I3={(v1,5)},尽管I1╞q,但I3q。而在实例I4= {(v1, 10),(v1,5), (v2, 10)}中,候选数据库为I5={(v1, 10),(v2, 10)}和I6={(v1,5),(v2,10)},则I4,I5,I6╞q。
这里可以通过以下的语句识别一致性?y:(R1(x,y)→y=10,得到如下重写语句:
Q=x:R(x,10) ∧?y:R1(x, y)→y=10。
显然,若给定查询为q=x:R(x,y),则重写查询为:Q=x:R(x, y)∧?y*:R1(x, y*)→y=y*。其中y*为一个可能值。
上面的查询是基于无连接的查询,以下考虑非键-键连接查询。
例4 在关系R(x,y)中,给定查询q=x,y,w: R1(x,y)∧R2(y,w)。在实例I1={R1(v1,a1), R1(v1,a2), R2(a1,b1)},候选数据库为I2={R1(v1,a1),R2(a1,b1)}和 I3={R1(v1,a2), R2(a1,b1)},尽管I1╞q,但I3q。而在实例I4={R1(v1,a1), R1(v1,a2), R2(a1,b1), R2(a2,b1)}中,所有R1中的v1的非键值a1和a2都在R2中出现,因此,I4╞q。这样,可以通过一个语句:?y:(R1(x, y)→w: R2(y,w))进行检测,因此,重写查询是这个语句与原语句的合取。
Q=x,y,w:R1(x,y)∧R2(y,w)∧?y:(R1(x, y)→w: R2(y,w))。
2 算法
2.1 可重写查询判断
算法由3部分组成。首先需要判断查询是否为易处理的,然后给出查询重写算法。由于该方法是基于连接图的,因此,需要考虑子结点的递归计算。以下算法在计算复杂度上较简单,这是由于关系的数量相当有限,而计算并没有涉及数据。
由于无连接的查询是可重写的,因此,算法1首先判断查询的关系数量。若为无连接的简单查询,则返回TRUE并结束程序。通过对关系集合元素的比较得到是否存在自连接,若存在自连接,且连接类型为有环的非键-键连接或非键-非键连接,则返回FALSE并结束程序,否则,返回TRUE并结束程序。若为非自连接,且连接类型为有环的非键-键连接、非键-非键连接、非充分的非键-键连接、完全非充分的键-键连接或者G中入度为0的顶点数量大于1,则返回FALSE并结束程序,否则返回TRUE并结束程序。
算法1 judge-rewritable(q,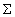 )
)
输入:查询q(v):w:R1(x1,y1)∧…∧Rm(xm,ym);
一组键约束
输出:是否为可重写查询
BEGIN
G=q的连接图;
R={R1,…,Rm};
IF m=1 THEN
RETRUN TURE;结束程序;
ENDIF
FOR n=1 TO m-1 DO
FOR i=n+1 TO m DO
IF R[n]=R[i] THEN
IF R[n]的连接类型为有环的非键-键或非键-非键连接 THEN
RETRUN FALSE;结束程序;
ELSE
RETRUN TRUE;结束程序;
ENDIF
ENDIF
IF R[n] R[i]且R[n]与R[i]不存在连接 THEN
R[i]且R[n]与R[i]不存在连接 THEN
跳过本次循环;
ENDIF
IF R[n]与R[i]的连接类型为{有环的非键-键连接、非键-非键连接、
非充分的非键-键连接完全非充分的键-键连接}
或者G中入度为0、顶点大于1 THEN
RETRUN FALSE;结束程序;
ELSE
RETRUN TRUE;结束程序;
ENDIF
ENDFOR
ENDFOR
END
2.2 重写算法
如果查询是可重写的,那么可采用如下算法得到重写查询。
算法2 rewritten_query(q, )
输入:查询q(v):w:R1(x1,y1)∧…∧Rm(xm,ym);
一组键约束
输出:重写查询
BEGIN
G=q的连接图;
FOR i:=1 to m DO
T1,…,Tm=G的连接分量;
Ri(xi,yi)=Ti的根结点;
Q i(xi,v)=NULL;
FOR j:=1 to m DO
IF Rj(xj,yj)是Ri(xi,yi)的子结点 THEN
Q i= Q i∧Q j;
ENDIF
ENDFOR
IF Ri(xi,yi)为树根 THEN
t=i;
ENDIF
ENDFOR
Q=q∧yt:Rt(xt,yt)∧?yt:Rt(xt,yt)→recure(Q t);
RETURN Q
END
算法2首先得到查询对应的连接图G的连接分量及其根结点。并以结点数进行循环。若某个连接分量的根结点存在子结点,则取得该结点的子结点的查询分量;若该结点为树根,则取得树根所在结点值,然后,返回q∧yt:Rt(xt,yt)∧?yt:Rt(xt,yt)→recure(Q t),调用递归算法。注意在“q∧yt:Rt(xt,yt)∧?yt:Rt(xt,yt)”中,q为初始查询,Rt(xt,yt)为根结点,存在量词与全称量词的指导变项为非键属性。
算法3 recure(q)
输入:形式为Q*∧…的查询;
输出:子结点的重写查询
BEGIN
q对应的结点为R(x,y);
Q*为对应的结点是R(x,y)结点的子结点;
IF q=NULL 且 y=v THEN/*如果是树叶*/
Q =x:R(x,v)∧?v′:(R(x,v′)→v=v′);
ENDIF
IF q=NULL 且 yj =常数c THEN/*如果是树叶*/
Q =x:R(x,c)∧?v′:(R(x,v′)→v′=c);
ENDIF
IF qNULL THEN/*如果不是树叶*/
Q =y:R(x,y)∧?y:R(x,y)→recure(q);
ENDIF
RETURN Q
END
算法3为递归算法。输入为连接分量的所在结点的查询分量,输出为子结点的重写查询。首先取得该查询分量对应的结点及其子结点,若所在结点为树叶且该结点的非键属性中存在初始查询的存在量词的指导变项,则返回x:R(x,v)∧?v′:(R(x,v→)→v=v′) ,存在量词的指导变项为键属性,全称量词的指导变项为非键属性;若所在结点为树叶且该结点的非键属性中在初始查询中等于常数,则返回x:R(x,c)∧ ?v′:(R(x,v′)→v′=c),存在量词的指导变项为键属性,全称量词的指导变项为非键属性;若所在结点不是树叶,则y:R(x,y)∧?y:R(x,y)→ recure(q),进行递归计算,存在量词与全称量词的指导变项为非键属性。
2.3 正确性证明
定理8 对于给定的模式R上的实例I和一组键约束,合取查询q是模式R上的查询且q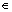 CPIME,Q是通过算法2得到的一阶查询。那么,对于元组t
CPIME,Q是通过算法2得到的一阶查询。那么,对于元组t I,I╞Q(t)?t∈CQA(q,I,∑)。
I,I╞Q(t)?t∈CQA(q,I,∑)。
证明 设G是q的连接图,T1, …, Tm是G的连接分量。假定q的查询形式为w:R(w,z),详细形式为: w1,…,wm:R1(w1,z1),…,Rm(wm,zm),R为合取连接关系集。对于每个1≤i≤m,设Ri(xi,yi)为Ti的根结点,其中wi xi 和zixi。设qi(xi,zi)=wi:Ri(xi,wi,zi),则Qi(xi,zi)= recure(qi)。设I*为I的一个候选数据库,则:
xi 和zixi。设qi(xi,zi)=wi:Ri(xi,wi,zi),则Qi(xi,zi)= recure(qi)。设I*为I的一个候选数据库,则:
(1) 若I╞Q(t),那么存在变量v(z)=t,且I╞ R(w,z)[v],对于每个1≤i≤m,存在v(xi)=ci和v(zi)=ti,即I╞Q(ci, ti)。假定I*q(t),那么,I*q(v)。由于没有wi的变量出现在wj(i≠j,1≤i≤m,1≤j≤m),则I*qi(ci,zi),因而CQA(qi(ci,zi),I,∑)=FALSE,即I Q(ci,zi)。矛盾。
(2) 若t∈CQA(q,I,∑)。假定I Q(t),设存在变量v(z)=t。若I q(z)[v],由于I*I,则I*q(z)[v];若IQi(xi,zi)[v](1≤i≤m),则CQA(qi(xi,zi)[v],I,∑)= FALSE,得到I*qi(xi,zi)[v],即I*q(z)[v]。因此,对于每个变量v(z)=t,都有I*q(z)[v],因而,tCQA(q,I,∑)。矛盾。
3 结论
(1) 基于一阶逻辑和完整性约束,提出了非一致性数据管理框架,通过多种查询类型对应的连接图及其CQA计算复杂度分析,在查询连接类型是键-键、非键-键或不充分键-键的情况下,若查询对应的连接图是非环的,则CQA计算是PTIME的;在查询连接类型是非键-非键、非键-键连接(其连接图存在环)、非键-键或无重复关系的键-键(连接是不充分的)情况下,则CQA计算是NP完全问题。
(2) 针对大量实际的易处理合取查询,提出了查询重写算法。通过判断是否为可重写查询,然后,基于连接图构造一个新的一阶重写查询。算法的正确性证明了一阶查询重写算法能计算一致性结果。
(3) 下一步工作需要扩展非一致性数据管理框架在其他完整性约束类型(如外键约束)的CQA计算,研究其计算复杂性和相应的PTIME查询算法。
参考文献:
[1] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]//Proceedings of the ACM SIGACT– SIGMOD–SIGART Symposium on Principles of Database Systems. New York: ACM Press, 1999: 68-79.
[2] Dasu T, Johnson T. Exploratory data mining and data cleaning[M]. New York: John Wiley, 2003: 10-50.
[3] Chomicki J, Marcinkowski J. Minimal-change integrity maintenance using tuple deletions[J]. Information and Computation, 2005, 197(1/2): 90-121.
[4] Fuxman A, Miller R J. Towards inconsistency management in data integration systems[C]//Proceedings of the International Conference on Information Integration on the Web. New York: ACM Press, 2003: 143-148.
[5] Fuxman A, Miller R J. First-order query rewriting for inconsistent databases[J]. Journal of Computer and System Sciences, 2007, 73(4): 610-635.
[6] Decan A, Wijsen J. On First-order query rewriting for incomplete database histories[C]//Proceedings of the International Conference on Logic in Databases. Wiley: IEEE Press, 2008: 72-83.
[7] Transaction Processing Performance Council. TPC BENCHMARK H standard specification[EB/OL]. [2010]. http://www.tpc.org.
[8] Xie D, Yang L M. Consistent query answering under integrity constraint[C]//Proceedings of the International Conference on Computer Science & Education. Wiley: IEEE Press, 2007: 546-549.
[9] 谢东, 吴敏. 基于范围语义的非一致性数据库聚集查询[J]. 中南大学学报: 自然科学版, 2008, 39(4): 810-815.
XIE Dong, WU Min. Aggregation queries based on range semantics in inconsistent databases[J]. Journal of Central South University: Science and Technology, 2008, 39(4): 810-815.
[10] Wijsen J. On the consistent rewriting of conjunctive queries under primary key constraints[C]//Proceedings of the International Conference Symposium on Database Programming Languages. New York: ACM Press, 2007: 112-126.
[11] Wijsen J. Consistent joins under primary key constraints[C]// Proceedings of the International Conference Workshop on Management of Uncertain Data. New York: ACM Press, 2007: 63-75.
[12] Chomicki J, Marcinkowski J, Staworko S. Computing consistent query answers using conflict hypergraphs[C]//Proceedings of the International Conference on Information and Knowledge Management. New York: ACM Press, 2004: 417-426.
[13] Chomicki J, Marcinkowski J, Staworko S. Hippo: A system for computing consistent query answers to a class of SQL queries[C]//Proceedings of the International Conference on Extending Database Technology. Berlin: Springer-Verlag, 2004: 841-844.
[14] Eiter T, Fink M, Greco G, et al. Efficient evaluation of logic programs for querying data integration systems[C]//Proceedings of the International Conference on Logic Programming. Berlin: Springer-Verlag, 2003: 163-177.
[15] Caniupan M, Bertossi L. The consistency extractor system: querying inconsistent databases using answer set programs[C]// Proceedings of the International Conference Scalable Uncertainty Management Conference. Berlin: Springer-Verlag, 2007: 74-88.
(编辑 陈灿华)
收稿日期:2010-06-15;修回日期:2010-08-21
基金项目:湖南省教育厅优秀青年科研基金资助项目(08B040);中南大学博士后科研基金资助项目(2008)
通信作者:谢东(1971-),男,湖南安化人,博士后,从事数据管理研究;电话:15973868511;E-mail: lgxzy@163.com

