������ģ�͵��ı������Զ���ȡ�㷨
����1, 2��������1������2, 3
(1. �����ѧ �������ѧ�뼼��ѧԺ�����죬400030��
2. �����ʵ��ѧ �������ѧ�뼼���о��������죬400065��
3. ���Ͻ�ͨ��ѧ ��Ϣ��ѧ�뼼��ѧԺ���Ĵ� �ɶ���610031)
ժҪ�����ۺϿ�������������ֲ��ֲ������ϣ����һ�ָ����ܵ��ı������Զ���ȡ�㷨���㷨�����������ȸ���������ֲ����������������κ�����֪ʶ���ܸ��������ֲ��ص��Զ���ȡ�������ȸߵ���������ʵ�������������������������������١����ྫ�ȸߵ��ص㣬�������Աȵ�ǰ��Ҫ������ѡ���������š�
�ؼ��ʣ��ı����ࣻ������ȡ����ģ�ͣ������ȣ���̬����
��ͼ����ţ�TP18 ���ױ�־�룺A ���±�ţ�1672-7207(2011)03-0714-07
Text feature automatic selection algorithm based on cloud model
DAI Jin1, 2, HE Zhong-shi1, HU Feng2, 3
(1. College of Computer Science, Chongqing University, Chongqing 400030, China;
2. Institute of Computer Science and Technology, Chongqing University of Posts and Telecommunications,
Chongqing 400065, China;
3. School of Information Science and Technology, Southwest Jiaotong University, Chengdu 610031, China)
Abstract: Combining the overall with the local distribution of features in categories, a high performance algorithm for feature automation selection (Named FAS) was proposed. By using FAS, the feature set was obtained automatically and the distribution of features was amended by using cloud model theory. The results show the selected feature set has fewer features and better classification performance than the existing methods.
Key words: text classification; feature selection; cloud model; membership degree; dynamic clustering
�ı��Զ���������Ϣ�����������ھ�������о��ȵ�����ļ������������õ��˹㷺��ע�Ϳ��ٷ�չ������Ϣ����[1]�������Ƽ�[2]����������[3]���ı�����ʶ��[4]����ҳ����[5]���������Ź㷺Ӧ�á��ı��Զ��������Ҫ����֮һ�������ռ�ά������[6]����ν��������ռ�ά����Ϊ�ı��Զ���������Ҫ���Ƚ�������⡣����ѡ�����ı�������ά��һ����Ч����[6]���ܶ�ѧ�߶Դ˽�����������о���������˺ܶ���Ч�ķ������ȽϾ�������ĵ�Ƶ��DF[7]����Ϣ����IG[7]����2ͳ����CHI[7]������ϢMI[8]�Ͷ��ַ������[9]�ȡ���Щ������������ѡ�������㺯��ֵ��Ȼ���Խ���ѡ��ǰ������������ѡ������У�ѡ��߶���һ����Ҫָ�ֱ꣬��Ӱ�����ı���������ܡ�ʵ��֤�����������������ֳ��������������ӣ�Ч��������߲���Ѹ�ٽӽ�ƽ�ȵ��ص㣻�����������������ܷ������ܽ���[10-13]�����������������ѡ��߶Ȳ����ܴ������ʹ��������������ںܶ�����¿��Ը��Ʒ�������Ч������ȷ������ѡ��߶�ʱ����������ѡ��ͨ�����þ�����㷽����������������ľ���ֵ(PFC)�����(THR)������ͳ������ֵ(MVS)�������ռ�ϡ����(SPA)�����������ı����ɱ���(PCS)��һЩѡ��[14]����Щ������ijЩ�ض����Ͽ���ȡ�ñȽϺõ�Ч������ͨ��Ϊ�۲����û����ƶϣ����ۻ�������֣��������ı��Զ�����Ľ�һ���ƹ��о�����ˣ��о�����Ӧ�ı����Ե������Զ���ȡ�����Ƿdz���Ҫ�ġ���ģ����һ�ֶ��Զ���ת��ģ��[15-18]��������������õ���ѧ���ʣ����Ա�ʾ��Ȼ��ѧ������ѧ�д����IJ�ȷ������[18]����ģ�Ͳ���Ҫ����֪ʶ�������ԴӴ�����ԭʼ�����з�����ͳ�ƹ��ɣ�ʵ�ִӶ������Ե�ת�����������߽��������������ֲ��ϵĦ�2�ֲ������������ģ���ڶ���֪ʶ��ʾ�Լ����ԡ�����֪ʶת��ʱ���������ã������������ȸ���������ֲ��������������ҹ�����һ����̬�����㷨����ȡ���������ڴ˻��������һ�ָ������ı������Զ���ȡ�㷨�����㷨����Ҫָ��������Ŀ���ܸ��������ֲ��ص��Զ���ȡ�����ȸߵ��������������Ϳ�����ʵ�������������������������������١����ྫ�ȸߵ��ص㣬�������Աȵ�ǰ��Ҫ������ѡ�����š�
1 �ı�����ѡ��
����ѡ����ͨ������һ���������ֺ������Ѳ����ռ������ͶӰ�������ռ䣬�õ��������ռ��ֵ��Ȼ���������ռ��е�ֵ��ÿ��������������������ѡ��û�иı�ԭʼ�����ռ�����ʣ�ֻ�Ǵ�ԭʼ�����ռ���ѡ����һ������Ҫ�����������һ���µĵ�ά�ռ䡣
����ѡ�����ı�������ά��һ����Ч������Ŀǰ���е�����ѡ����Ҫ��Ϊ2�ࣺ(1) �����ڴ�Ƶ������ѡ������DF��IG����2ͳ����CHI��MI�ȣ�(2) ��������������ѡ������CTD����ѡ��[19]�ʹ���ǿ�����Ϣ��SCIW����ѡ��[20]�ȡ���1���ǿ����Ƶ����������ϵ�����ֲ�����2���ǿ�������Ϣ�����Դ�Ƶ����������ϵ�����ֲ����Dz���֡��������Ч�ؽ�ϴ�Ƶ��������������ֲ����ڵ�������ϵķֲ�������������Ը�������ѡ�����ܡ�
���⣬��������������(ECE)���ı�֤��Ȩ(WET)��������(OR)��һЩ����ѡ��������[21]��DF��IG��MI��CHI��ECE��WET��OR��Щ����ѡ�������˱Ƚϣ����������OR������Ч����ã�IG��CHI��ECE��Ч����֮��WET��DF��Ч���ٴ�֮��MI��Ч������Yang��[7, 22]��ΪIG����õIJ��֮һ��Forman��[10]�ֱ����Ч�ԡ�����������������Ч���Ļ���ȷ���Բ�ͬ����ѡ�������˹㷺�Ƚϣ����������CHI��IG��ͳ��������Ϸ�������һ�������ơ�
����������������Щ����������ı������Ч����û�о������ơ�������Ϊ�ı����౾���漰ѵ�����ݼ��ϱ������ص㣬ͬʱ����ͬ�������ķ���Ч��Ҳ������ͬ[10-11]��
2 ���ڦ�2ͳ�������ı������ֲ�����
��2ͳ����[7]�ĸ����������������飬������������ti�����Cj֮���ͳ������ԡ�ʵ��֤����һ�ֱȽϺõ�����ѡ��[10, 21]��������ti��Cj֮����Ͼ���һ�����ɶȵĦ�2�ֲ����衣ti����Cj�Ħ�2������ʽ���㣺
 (1)
(1)
ʽ�У�NΪѵ���������ĵ�������AΪ������Cj���ĵ�Ƶ����BΪ������Cj�൫����ti���ĵ�Ƶ����CΪ����Cj�൫������ti���ĵ�Ƶ����D�ǼȲ�����CjҲ������ti���ĵ�Ƶ������֪������ti�����Cj�����ʱ��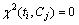 ����ʱ����ti�������κ������Cj�йص���Ϣ������ti�����Cj��ͳ�������Խǿ��
����ʱ����ti�������κ������Cj�йص���Ϣ������ti�����Cj��ͳ�������Խǿ��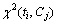 Խ��ʱ������ti�����������Cj�йص���Ϣ��Խ�ࡣ
Խ��ʱ������ti�����������Cj�йص���Ϣ��Խ�ࡣ
�ɦ�2���㹫ʽ���Կ�������2ͳ�Ʒ�����Ϊ����ѡ��ʱ��ֻ�����������������ĵ����ֵ��ĵ�Ƶ������ijһ����ֻ��һ���ĵ��������ĵ���Ƶ�����֣���ͨ����2���㹫ʽ����Ħ�2ͳ��ֵ�ܵͣ�������ѡ��ʱ�����������ʾͻᱻ�ų����������������ĵ���Ƶ�����ֵ������ʺ��п��ܶԷ���Ĺ��ܴ���רָ������Ǧ�2ͳ�ƵIJ���֮�������Ե��ĵ�Ƶ������� �ɿ���
�������Ϸ��������������ڸ������֮��ķֲ���������������������Ħ�2�ֲ����������£�
 (2)
(2)
��F�Ĺ�����Կ�����F�е�ÿһ�з�ӳ�������ڲ�ͬ����еķֲ������ÿһ�з�ӳ����ͬһ����в�ͬ�����ķֲ�����������߽���������ܹ�������ӳ�����������ķֲ������ҿ����ֲ��˦�2ͳ������Ϊ����ѡ���ϵ�ȱ�㡣
3 �����������ȵ��ı������Զ���ȡ�㷨
ͨ������ÿһ����ϲ�ͬ�����Ħ�2�ֲ�����ɼ���һЩ��2�ϴ������������г���Ƶ�ʼ��ͣ�����һЩ������г��ֱȽ�Ƶ����������2������С�������쳣�ij�������������Щ���������˦�2ͳ��������ti��Cj֮����Ͼ���һ�����ɶȵĦ�2�ֲ���������ֲ�Ӱ��ϴ���Ҫ�����������ɴˣ�����Ϊÿ����������һ��ģ���������ģ�Ͷ���������ϵķֲ����ж����������������������Ħ�2����Ӧ�������ȼ���������
3.1 ��ģ�ͼ��
��ģ��������ֵ��ʾij�����Ը������䶨����ʾ֮��IJ�ȷ����[15-18]���Ѿ������ܿ��ơ�ģ������ȶ������õ�Ӧ�á�
����1[15] ��U��һ������ֵ��ʾ�Ķ�������C��U�϶��Ը��������ֵ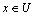 �Ƕ��Ը���C��һ�����ʵ�֣�x��C��ȷ����
�Ƕ��Ը���C��һ�����ʵ�֣�x��C��ȷ����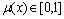 �����ȶ���������������: U��[0, 1],
�����ȶ���������������: U��[0, 1],  , x����(x)����x������U�ϵķֲ���Ϊ�ƣ���Ϊ��C(X)��ÿһ��x��Ϊһ���ƵΡ���������Ӧ��������nά�ռ䣬��ô�����ع���nά�ơ�
, x����(x)����x������U�ϵķֲ���Ϊ�ƣ���Ϊ��C(X)��ÿһ��x��Ϊһ���ƵΡ���������Ӧ��������nά�ռ䣬��ô�����ع���nά�ơ�
����2[23] ��X��һ����ͨ����X={x}����Ϊ����������X�е�ģ������ ����ָ��������Ԫ��x������һ�����ȶ�����������
����ָ��������Ԫ��x������һ�����ȶ�����������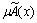 ������x���������ȡ�
������x���������ȡ�
�������ڻ��������ϵķֲ���Ϊ�ơ��ڶ�ģ�����Ĵ��������У�������ijһ�㵽����������֮���ӳ����һ�Զ��ת��������һ���������������ߣ��Ӷ��������Ƶĸ��
��������Ex(Expected value)����En(Entropy)������He(Hyper entropy)��3�������������������һ���������Ex���Ƶ�������ռ�ֲ��������������ܹ��������Ը���ĵ㣻��En�������Ը���Ŀɶ������ȣ���Խ��ͨ������Խ��ۣ�Ҳ�Ƕ��Ը��ȷ���ԵĶ������ɸ��������Ժ�ģ���Թ�ͬ����������He���صIJ�ȷ���Զ��������ص��أ����ص�����Ժ�ģ���Թ�ͬ��������3������������ʾ�Ķ��Ը����������������C(Ex��En��He)����Ϊ�Ƶ�����������
�������㷨[15]���������㷨[15]����ģ����2�����������ؼ����㷨��ǰ�߰Ѷ��Ը�������������任Ϊ������ֵ��ʾ��ʵ�ָ���ռ䵽��ֵ�ռ��ת��������ʵ�ִӶ���ֵ�����Ը����ת������һ�鶨������ת��Ϊ����������{Ex��En��He}����ʾ�Ķ��Ը��
3.2 �����������ȵ��ı������Զ���ȡ�㷨
ͨ��������2�ֲ�����������ȡֵ������ӳ�������������������ô�С��Ҳ��ӳ�˸���������ÿһ���Ĺ��׳̶ȡ�ͨ����ģ�������Ⱥ��������룬������������������еķֲ������ͨ����ȡÿһ�����������ߵ����������ϲ��������յķ����������ϣ��������Ա��������������������������ͬʱ���ijЩ����������(������ijһ���г���Ƶ�ʴ�������ָ��ʵ͵�����)�����
�ڶ�����ȡֵ���������ȱ�ʾ������������ϵ�ȡֵ��ʾ����[0��1]�����ϵ�����ֵ�����������������Խ����������Խ�ߡ���ÿһ��������������������кܴ�һ���������������������ȼ��ͣ���Ҫ�����������г���ɸѡ������������ȡ��������
����3[17] һά������U�У���һС�����ϵ��Ƶ�Ⱥ?x�Զ��Ը���A�Ĺ���?CΪ��

�ɶ���3�����Լ���õ�U������Ԫ�ضԸ���A���ܹ���CΪ��

���У�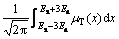 =99.74%�����ԣ���������U�еĶ��Ը���A�й����ƵΣ���Ҫ��������[Ex-3En, Ex+3En]����ˣ����Ժ��Ը�����֮����ƵΡ�
=99.74%�����ԣ���������U�еĶ��Ը���A�й����ƵΣ���Ҫ��������[Ex-3En, Ex+3En]����ˣ����Ժ��Ը�����֮����ƵΡ�
�������Ϸ�����ͨ��������Եõ�λ������[Ex-0.67En, Ex+0.67En]��������ռ����������22.33%�������Ƕ����Ĺ���ռ50%���ܹ�����������ȡ��Ҫ���ʽ��ڴ����������ɸѡΪ��ѡ��������
����������ȡ�ϣ����Բ��ö�̬��������д��������ǣ��ھ�������У�������Ӧ���������ݱ��������йأ�������һ������ֵ����ˣ���������̽����������ֱ�������������Ҫ���˼·���������̬�����㷨��
�㷨1����̬�����㷨��
���룺�������Ci//����2���Ц�2�ֲ�����F�е���������
�������������Ti��
�㷨���裺
(1) ��ȡCi�����в��ظ���������������������������� {dij, Clusterid}������ClusteridΪ��������š�
{dij, Clusterid}������ClusteridΪ��������š�
(2) ���㶯̬���������ֵe��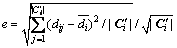 (����������ƽ������ƽ�����)���������õ��������ݣ��������ѵ���������ݵ����������������㡣
(����������ƽ������ƽ�����)���������õ��������ݣ��������ѵ���������ݵ����������������㡣
(3) ��ʼ���K=1��v=e+1 //vΪѭ�����Ʊ�����
(4) WHILE (v��e) DO //��v��eʱ������ľۺϳ̶��Ѿ��ȽϺã����������
1) ������������TC���� ƽ���ֳ�K+1�ݣ�ȡ�����Ҷ˵����TC����Ϊ
ƽ���ֳ�K+1�ݣ�ȡ�����Ҷ˵����TC����Ϊ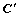 ��K����µij�ʼ���ͬʱ����Ԫ��Clusterid��Ϊ0��
��K����µij�ʼ���ͬʱ����Ԫ��Clusterid��Ϊ0��
2) �趨��ʱѭ�����Ʊ���e1=0��
3) ��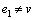 ʱ��ִ������ѭ��: //�����ȶ�����ı������Ϊ�ȶ�ֵ��
ʱ��ִ������ѭ��: //�����ȶ�����ı������Ϊ�ȶ�ֵ��
�� e1=v��
�� ������ÿ��ֵ��TC�и������룬����鲢��������С������У�
�� ���ݼ�Ȩƽ������TC�и��������ľ��룻
�� ����TC�и����ı���Si����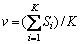 ��
��
4) K=K+1 //�����������1��������һ�ֵľ��ദ����
LOOP
(5) ��������� ��Ϊ��������������Ϊ
��Ϊ��������������Ϊ ������Ϊ���Ci������������������
���������Ci������������������ ��
��
(6) RETURN Ti��
�㷨1�ĸ��Ӷȷ����������Ci��������ƽ������Ϊn���㷨ʱ�临�Ӷ���Ҫ�ɲ���(4)����������(4)��һ�����͵�k��ֵ����[24]����ʱ�临�Ӷ�Ϊ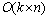 ����ˣ�����(4)��ʱ�临�Ӷ�Ϊ
����ˣ�����(4)��ʱ�临�Ӷ�Ϊ (���У�kΪƽ���������)�����㷨1��ʱ�临�Ӷ�Ϊ���ռ临�Ӷ�ΪO(n)��
(���У�kΪƽ���������)�����㷨1��ʱ�临�Ӷ�Ϊ���ռ临�Ӷ�ΪO(n)��
���㷨1�Ļ����ϣ������һ�����������µ��ı������Զ���ȡ�㷨�����㷨����Ҫָ��������Ŀ���ܸ��������ֲ��ص��Զ���ȡ�����ȸߵ���������������㷨2��
�㷨2�������������ȵ��ı������Զ���ȡ�㷨(FAS)��
���룺������2�ֲ�����F��ѵ����TR��
�������������ѡ����ѵ���� ��
��
�㷨���裺
��ʼ�������� ��
��
����ѡ��F��ÿһ��Ci���������²��账����
1) �����������㷨����Ci����������C(Ex, En, He)��
2) �����������㷨��Ci����ֵת���ɶ�Ӧ�����ȣ�
3) ��Ci������[Ex-0.67En, Ex+0.67En]�������ɾ�����õ�����Լ�����������
4) �������ϵ�����̬�����㷨(�㷨1)�õ�ѡ���������Ti��
5) 
6) ɾ��TR�в�����T������������õ�ѡ������ѵ������
�㷨2�ĸ��Ӷȷ�������ѵ�������ƽ��������Ϊn�������Ϊm�����㷨2��ʱ�临�Ӷ�Ϊ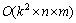 (kΪƽ���������)���ռ临�Ӷ�ΪO(n)��
(kΪƽ���������)���ռ临�Ӷ�ΪO(n)��
4 ʵ�鼰��������
Ϊ�˲��Ա����㷨����Ч�ԣ���FAS�㷨���к���ԱȲ��ԡ�ʵ���У��������ܽϺõ�kNN�������㷨[25](k=30)�����ı�������ԡ����Խ����ȷ��(��������ȷ��/ʵ�ʷ�����)����ȫ��(��������ȷ��/Ӧ����)�ͺ�ƽ�� (PΪȷ�ʣ�RΪ�ٻ���)�������⡣
(PΪȷ�ʣ�RΪ�ٻ���)�������⡣
4.1 ���Ͽ�
ʵ��ѡ���������Ͽ�TanCorpV1.0[26] ��Ӣ�����Ͽ�Reuters-21578[27]�� TanCorpV1.0�����ı�14 150ƪ������Ϊ12�ࡣ����ͣ�ô��Ƴ����ʸɻ�ԭ�ȴ����õ�����72 584����
����Reuters-21578��ʹ��ֻ��1�������ÿ��������ٰ���5 �����ϵ��ĵ����������õ�ѵ����5 273ƪ�����Լ�1 767ƪ������ͣ�ô��Ƴ����ʸɻ�ԭ�ȴ����õ�13 961��������
4.2 ʵ����̼��������
��������ѡ��ͨ�����þ��鷽ʽ��ȷ��������Ŀ��Ϊ�˵õ�������ѡ���ڴﵽ��ѷ�������ʱ�����������������������������ķ�����ȷ�������Խ�����1��2��ʾ��
�ӱ�1��2���Կ�����IG��CHI�������������������ӣ��������������Ͽ죬��MI������Ҫ����������϶࣬��������������ͬʱ�����������ﵽij����ֵʱ��������ѡ�����ܾ���ﵽ���״̬��������ֵ�Ļ�ȡ������ѡ���IJ�ͬ�����Ͽ�IJ�������в�ͬ����Ҫ����ʵ����ܵõ���
��ʹ��FAS�㷨��TanCorpV1.0���Զ���ȡ��������ƽ��Ϊ1 380������Reuters-21578���Զ���ȡ��������ƽ��Ϊ239������������Ҫ�κξ���֪ʶ����������������������������ѡ��������������FAS�㷨ѡ������������з�����ԣ����ܱȽϽ������3��4��
�ӱ�3��4���Կ�������IG��CHI��MI��3��
��1 TanCorpV1.0�ϸ�����ѡ���ڲ�ͬ�����������ܱȽ�
Table 1 Performance of feature selection methods with different number of features on TanCorpV1.0

��2 Reuters-21578�ϸ�����ѡ���ڲ�ͬ�����������ܱȽ�
Table 2 Performance of feature selection methods with different number of features on Reuters-21578

��3 TanCorpV1.0�ϸ�����ѡ���������ܱȽ�
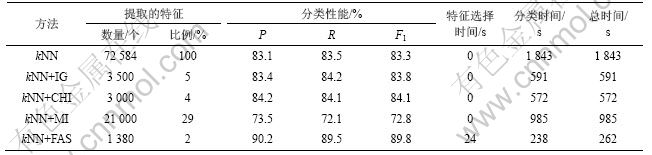
Table 3 Classification performance comparison on TanCorpV1.0
��4 Reuters-21578�ϸ�����ѡ���������ܱȽ�
Table 4 Classification performance comparison on Reuters-21578
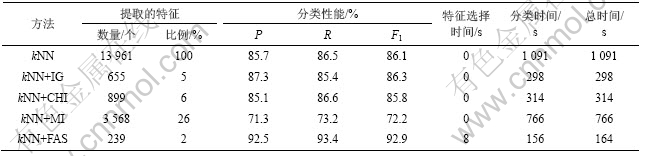
�㷨��ȣ�FAS�㷨��ȡ�����������и����١����ྫ�ȸߵ��ص㡣kNN������TanCorpV1.0�ϵ���ú�ƽ��(F1=84.78%)[26]��Reuters-21578�ϵ���ú�ƽ��(F1=86.1%)[22]��ȣ�����FAS�㷨��ȡ�������ϣ�kNN������ƽ�������5%~6%��˵�����㷨��ȡ�����������бȽϸߵ��������������
�ӷ����ʱ�俪����������ȻFAS�㷨��������ȡ�κķ���һ����ʱ�䣬���������Ͽ���Զ�����������������ʱ�䡣������Ϊ���������ʱ����Ҫ������ѡ�����ʱ��ɡ�FAS�㷨��ʱ�临�Ӷ�Ϊ(kΪƽ�����������nΪ��������mΪ�����)����ͨ�������㷨��ʱ�临�Ӷ�����Ϊ ���ϣ��������Ķ��ٶ���������ʱ��ķ�����������Ҫ�����á�IG��CHI��MI��Ȼ��ѡ��β���Ҫ�ķ�ʱ�䣬��һ��������ҵ����ŵ���������Ҫ��β��ԣ���һ����������ѡ����Զ��FAS�㷨�ֱ࣬�ӵ�����������ʱ��ķѴ�������ӡ�
���ϣ��������Ķ��ٶ���������ʱ��ķ�����������Ҫ�����á�IG��CHI��MI��Ȼ��ѡ��β���Ҫ�ķ�ʱ�䣬��һ��������ҵ����ŵ���������Ҫ��β��ԣ���һ����������ѡ����Զ��FAS�㷨�ֱ࣬�ӵ�����������ʱ��ķѴ�������ӡ�
�����ܱȽϷ������֣�FAS�㷨��ȡ������������Ȼ����IG��CHI�㷨�Ľ����һ�룬�������������Ը��ں��ߡ�������������������ѡȡ�仯�� �¡�Ϊ�ˣ���TanCorpV1.0Ϊ���������������ֲ��������ͼ1��ʾ��
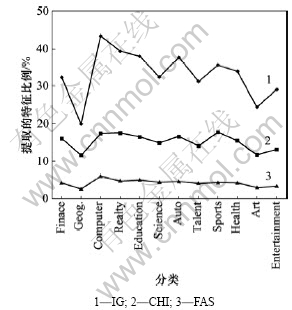
ͼ1 TanCorpV1.0�ϸ�����ѡ���������ֲ����
Fig.1 Distribution of feature sets selected by different selection method on TanCorpV1.0
��ͼ1���Կ�����FAS�㷨��ȡ��ÿ��������Ҫ������������֤�˲�ͬ���֮��ؼ��������¾��ȷֲ���ͬʱ������������ȸ��������ֵ�Ħ�2�ֲ����бȽϺõ������������Ч������ı��ķ������ܣ������������ٵ��������Ϊ���ԡ�
5 ����
(1) ���������FAS�㷨��ȡ���������������������������١����ྫ�ȸߵ��ص㣬�����������Ƚ����˷���ʱ�䡣
(2) FAS�㷨���������Աȵ�ǰ��Ҫ����ѡ���������š�
�ο����ף�
[1] Charles-Antoine J, John E, France B. Controlled user evaluations of information visualization interfaces for text retrieval: literature review and meta-analysis[J]. Journal of the American Society for Information Science and Technology, 2008, 59(6): 1012-1024.
[2] Haruechaivasak, Choochart J, Wittawat S. Implementing news article category browsing based on text categorization technique[C]// Proc of Web Intelligence and Intelligent Agent Technology (WI-IAT 2008). Piscataway: IEEE, 2008: 143-146.
[3] Myunggwon H, Chang C, Byungsu Y, et al. Word sense disambiguation based on relation structure[C]// Proc of Advanced Language Processing and Web Information Technology (ALPIT 2008). Piscataway: IEEE, 2008: 15-20.
[4] Xuerui W, Mccallum A, Xing W. Topical n-grams: phrase and topic discovery, with and application to information retrieval[C]// 7th IEEE International Conference on Data Mining (ICDM 2007). Piscataway: IEEE, 2007: 697-702.
[5] Selvakuberan K, Indradevi M, Rajaram R. Combined feature selection and classification: A novel approach for the categorization of web pages[J]. Journal of Information and Computing Science, 2008, 3(2): 83-89.
[6] �ս���, �Ų���, ���. ���ڻ���ѧϰ���ı����༼���о���չ[J]. ����ѧ��, 2006, 17(9): 1848-1859.
SU Jin-shu, ZHANG Bo-feng, XU Xin. Advances in machine learning based text categorization[J]. Journal of Software, 2006, 17(9): 1848-1859.
[7] Yang Y M, Pedersen J O. A comparative study on feature selection in text categorization[C]// Proc of the 14th International Conference on Machine Learning (ICML 1997). San Francisco: MIT Press, 1997: 412-420.
[8] Jana N, Petr S, Michal H. Conditional mutual information based feature selection for classification task[C]// Proc of the 12th Iberoamericann Congress on Pattern Recognition (CIAPR 2007). Berlin: Springer-Verlag, 2007: 417-426.
[9] Santana L E A, de Oliveira D F, Canuto A M P, et al. A comparative analysis of feature selection methods for ensembles with different combination methods[C]// Proc of Internation Joint Conference on Neural Networks (IJCNN 2007). Piscataway: IEEE, 2007: 643-648.
[10] Forman G. An extensive empirical study of feature selection metrics for text classification[J]. Journal of Machine Learning Research, 2003, 3(1): 1533-7928.
[11] Kim H, Howland P, Park H. Dimension reduction in text classification with support vector machines[J]. Journal of Machine Learning Research, 2005, 6(1): 37-53.
[12] Rogati M, Yang Y. High-performing feature selection for text classification[C]// Proc of the 11th ACM Int��l Conf on Information and Knowledge Management (CIKM 2002). McLean: ACM Press, 2002: 659-661.
[13] Makrehchi M, Kame M S. Text classification using small number of features[C]// Proc of the 4th International Conference on Machine Learning and Data Mining in Pattern Recognition (MLDM 2005). Berlin: Springer-Verlag, 2005: 580-589.
[14] Soucy P, Mineau G W. Feature selection strategies for text categorization[C]// Proc of the 16th Conf of the Canadian Society for Computational Studies of Intelligence (CSCSI 2003). Halifax: Springer-Verlag, 2003: 505-509.
[15] �����. ��ȷ�����˹�����[M]. ����: ������ҵ������, 2005: 171-177.
LI De-yi. Artificial intelligence with uncertainty[M]. Beijing: National Defense Industry Press, 2005: 171-177.
[16] �����, ������. ����̬��ģ�͵�������[J]. �й����̿�ѧ, 2004, 6(8): 28-34.
LI De-yi, LIU Chang-yu. Study on the universality of the normal cloud model[J]. Engineering Science, 2004, 6(8): 28-34.
[17] �����, ������, ���o, ��. ��ȷ�����˹�����[J]. ����ѧ��, 2004, 15(11): 1583-1594.
LI De-yi, LIU Chang-yu, DU Yi, et al. Artificial intelligence with uncertainty[J]. Journal of Software, 2004, 15(11): 1583-1594.
[18] �Ź���, ������, �����, ��. ������ģ�͵�ȫ�����Ż��㷨[J]. �������պ����ѧѧ��, 2007, 33(4): 486-491.
ZHANG Guang-wei, KANG Jian-chu, LI He-song, et al. Cloud model based algorithm for global optimization of functions[J]. Journal of Beijing University of Aeronautics and Astronautics, 2007, 33(4): 486-491.
[19] Bong C H, Narayanan K. An empirical study of feature selection for text categorization based on term weightage[C]// Proc of the IEEE/WLC/ACM Int��l Conf on Web Intelligence (WI 2004). Beijing: IEEE Computer Society Press, 2004: 599-602.
[20] Li S, Zong C Q. A new approach to feature selection for text categorization[C]// Proc of the IEEE Int��1 Conf on Natural Language Processing and Knowledge Engineering (NLP-KE 2005). Wuhan: IEEE Press, 2005: 626-630.
[21] ������, ��εȻ, ����, ��. �����ı������е�����ѡ���㷨�о�[J]. ��ͨ���о�, 2005, 3(129): 44-46.
HU Jia-ni, XU Wei-ran, GUO Jun, et al. Study on feature selection methods in Chinese text categorization[J]. Study on Optical Communications, 2005, 3(129): 44-46.
[22] ����, �����, ����, ��. �ı�����������ѡ���Լ���о�[J]. ������о��뷢չ, 2008, 45(4): 596-602.
XU Yan, LI Jing-tao, WANG Bin, et al. A study on constraints for feature selection in text categorization[J]. Journal of Computer Research and Development, 2008, 45(4): 596-602.
[23] �Ź���, �����, ����, ��. ������ģ�͵�Эͬ�����Ƽ��㷨[J]. ����ѧ��, 2007, 18(10): 2403-2411.
ZHANG Guang-wei, LI De-yi, LI Peng, et al. A collaborative filtering recommendation algorithm based on cloud model[J]. Journal of Software, 2007, 18(10): 2403-2411.
[24] Dai W H, Jiao C Z, He T. Research of k-means clustering method based on parallel genetic algorithm[C]// Proc of the 3rd Int��l Conf on Intelligent Information Hiding and Multimedia Signal Processing (IIHMSP 2007). 2007: 158-161.
[25] Yang Y, Liu X. A re-examination of text categorization methods[C]// Proc of the 22nd Annual Int��l ACM SIGIR Conf on Research and Development in Information Retrieval (SIGIR 1999). Berkeley, 1999: 42-49.
[26] Tan S, Cheng X, Ghanem M, et al. A novel refinement approach for text categorization[C]// Proc of the 14th ACM Conf on Information and Knowledge Management (CIKM 2005). Bremen: ACM Press, 2005: 469-476.
[27] David L. Reuters-21578 test collection[EB/OL]. [2007-02-04]. http://www.daviddlewis.corn/resources/testcollections/reuters 21578/.
(�༭ �Կ�)
�ո����ڣ�2010-06-07�������ڣ�2010-09-28
������Ŀ�������ش�Ƽ�ר���ӿ���(2008ZX07315-001)���������ش�Ƽ�ר��(2008AB5038)�������У��������ҵ��������Ŀ(CDJXS11181160)
ͨ�����ߣ�����(1978-)���У����������ˣ���ʿ�о�����������Ȼ���Դ�����������Ϣ�����о����绰��13062352289��E-mail: daijin@cqupt.edu.cn

