A novel approach for agent ontology and its application inquestion answering
来源期刊:中南大学学报(英文版)2009年第5期
论文作者:郭庆琳
文章页码:781 - 788
Key words:agent ontology; question answering; semantic web; concept extraction; answer extraction; natural language processing
Abstract: The information integration method of semantic web based on agent ontology (SWAO method) was put forward aiming at the problems in current network environment, which integrates, analyzes and processes enormous web information and extracts answers on the basis of semantics. With SWAO method as the clue, the following technologies were studied: the method of concept extraction based on semantic term mining, agent ontology construction method on account of multi-points and the answer extraction in view of semantic inference. Meanwhile, the structural model of the question answering system applying ontology was presented, which adopts OWL language to describe domain knowledge from where QA system infers and extracts answers by Jena inference engine. In the system testing, the precision rate reaches 86%, and the recalling rate is 93%. The experimental results prove that it is feasible to use the method to develop a question answering system, which is valuable for further study in more depth.
基金信息:the National Natural Science Foundation of China
the National High-Tech Research and Development Program of China
the Foundation of Post-Doctor in China
J. Cent. South Univ. Technol. (2009) 16: 0781-0788
DOI: 10.1007/s11771-009-0130-3
![]()
GUO Qing-lin(郭庆琳)1, 2
(1. Department of Computer Science and Technology, Peking University, Beijing 100871, China;
2. School of Computer Science and Technology, North China Electric Power University,
Beijing 102206, China)
Abstract: The information integration method of semantic web based on agent ontology (SWAO method) was put forward aiming at the problems in current network environment, which integrates, analyzes and processes enormous web information and extracts answers on the basis of semantics. With SWAO method as the clue, the following technologies were studied: the method of concept extraction based on semantic term mining, agent ontology construction method on account of multi-points and the answer extraction in view of semantic inference. Meanwhile, the structural model of the question answering system applying ontology was presented, which adopts OWL language to describe domain knowledge from where QA system infers and extracts answers by Jena inference engine. In the system testing, the precision rate reaches 86%, and the recalling rate is 93%. The experimental results prove that it is feasible to use the method to develop a question answering system, which is valuable for further study in more depth.
Key words: agent ontology; question answering; semantic web; concept extraction; answer extraction; natural language processing
1 Introduction
The traditional search engine has many limitations, for instance, it returns a lot of relative web pages rather than accurate answers. In addition, it only regards keywords as indexes without relating to semantic information, making it difficult to really understand what the user intends to do. In question answering (QA), users can use sentences in daily life to raise questions and the system will return answers to users directly after analyzing and comprehending these questions. Therefore, the QA system better satisfies the users’ requirements. It can be said that the QA system is a new generation of intelligent search engine.
As to the QA system, it can be classified according to the scope of QA as: QA system in the restricted domain and QA system in general use. With the support of TREC, large-scale text oriented English written general QA system research has taken a great leap forward; in particular, some QA systems containing general questions analyzer appeared after TREC8 opened up the QA session, such as Start of MIT [1], JAVELIN of CMU, and QUANTUM system of Concordia University [2]. In terms of QA system in the restricted domain, the QA systems of English, Japanese and German languages have been considerably applied, such as travel consultation system (TCS) with Japanese questions analyzer.
In China, many scientific research institutes and tertiary institutions have made much effort to do the research of Chinese QA system, for example, the QA system of characters’ relationships in “a dream of red mansions” developed by Institute of Computing Technology, Chinese Academy of Sciences; EasyNav, a campus guideline system developed by Tsinghua University, China [3], bank-domain automatic QA system BAQS developed by natural language processing laboratory in Beijing Institute of Technology. In addition, the Chinese Universities of Hong Kong and Taiwan Academia Sinica also have such research achievements. The research of Chinese QA system is just in its initial stage, the precision of the system is not quite high, and the general QA system is still far from the actual application [4].
As is known to all, the path of natural language understanding research is long and formidable. The Chinese QA system in the restricted domain faces many difficulties [5]. The main problems are as follows. Firstly, the precision of answering questions is not high enough. Secondly, there is no ideal way for domain knowledge representation, that is, manual marking is both time and labor consuming; the knowledge representation formed by machine learning, such as automatic generating domain ontology, has not reached the proper standard yet; if the internet is taken as comprehensive knowledge source of multiple domains and the answers are extracted from searched pages, there will be more difficulties to extract answers. Thirdly, the development of the QA system lacks reasonable theoretical reference model. As the QA systems are independently designed and rarely reused, the process is repeated and the efficiency is rather low. Therefore, integrating, analyzing and processing enormous web information in network environment and providing corresponding answers to users’ questions become new hot topics in current researches.
With the vigorous generalization of semantic web by W3C, semantics oriented web information integrating method has been the major point of the research on web information integration technology [6]. One common semantic model should be offered to solve the problem of semantic heterogeneity in semantics oriented web information integration, which is a platform independent of model to block semantic heterogeneity among web information. Due to “the set of concepts and relations among concepts in specific domain” [7], ontology can effectively express the general knowledge in specific domain, which is adaptable to be the common semantic model of semantics oriented web information integration. Adopting ontology in QA system can better indicate the inherent relations among knowledge, rationalize knowledge organizations, reduce redundant memories, and extract semantic answers. The users’ enquiries usually cover many information sources [8]. But, users usually expect to search information using a special ontology without caring for answers received from which information sources or through what kind of processing. To meet this demand, a general ontology should be constructed among local domain ontologies, which is called agent ontology (AO). AO and local ontology should collaborate mutually through the shared lexical collection, and they should be of mapping relations. On such basis, the information-integrated method of semantic web based on agent ontology (SWAO method) was put forward.
2 Agent ontology (AO) and its enquiry rewriting
AO should contain possible concepts and relations among concepts in users’ enquiries and conform to local ontology in semantics as much as possible.
Definition 1 Domain space: Domain space can be defined as
Definition 2 Ontology O can be defined as a 7-tuple:
![]()
where c is the set of concept C (instances of rdfs: Class); ![]() c×c denotes subsumption relation between concepts (instances of rdfs: subClassOf);
c×c denotes subsumption relation between concepts (instances of rdfs: subClassOf); ![]() c×c denotes the set of binary property relationship between concepts (instances of rdfs: objectProperty);
c×c denotes the set of binary property relationship between concepts (instances of rdfs: objectProperty); ![]()
![]()
![]() ×
×![]() denotes hierarchy between properties (instances of rdfs: subPropertyOf); P
denotes hierarchy between properties (instances of rdfs: subPropertyOf); P![]() D×DT is the set of data properties for concept (instances of owl: DatatypeProperty), and DT
D×DT is the set of data properties for concept (instances of owl: DatatypeProperty), and DT![]() D is a data type set; A is the set of axioms expressed in a logical language and can be used to infer knowledge from existing one; and D denotes the domain set containing all instances of concept C. In fact, all elements in ontology O can be expressed as 3-tuple set of the form (subject, predicate, object).
D is a data type set; A is the set of axioms expressed in a logical language and can be used to infer knowledge from existing one; and D denotes the domain set containing all instances of concept C. In fact, all elements in ontology O can be expressed as 3-tuple set of the form (subject, predicate, object).
Ontology mapping between ontologies O1 and O2 can be regarded as follows: some entities in ontology O1 are mapped at most one entity in ontology O2 and vice versa.
Definition 3 Conceptual relation: The n-tuple relation on
pn: W→2Dn
It is the function of the sets about all n-tuple relation on
Definition 4 Let ∑O be the vocabulary of ontology O and use ε to refer to a null entity. Ontology mapping can be defined by a mapping function ρ: ∑Om→∑Ot such that:
![]() ∈∑Om(
∈∑Om(![]() ∈∑Ot: ρ(s)=t or ρ(s)=ε)
∈∑Ot: ρ(s)=t or ρ(s)=ε)
where ?∑Om and ∑Ot are the source ontology and the target ontology of mapping ρ, respectively. Sometimes, ρ(O1, O2) can be used to denote the mapping function from ontology O1 to ontology O2.
AO is constructed according to the local ontology, so its construction process is similar to that of ontology integration in essence. Regarding the local ontology as one viewpoint of AO, construct AO by using heuristic rule and other methods to infer the relations of concepts in different local ontologies through checking and processing the inconsistency among local ontology. Compared with other ontology integration methods [9], the method of AO upon multi-view possesses the following features: applying inconsistency checking and processing strategies upon semantic layer in different ontologies to eliminate the semantic inconsistency between different ontologies; using heuristic rule to obtain relations of concepts between different ontologies in semantic layer and resorting to Prolog clauses to infer and solve the problem of semantic implication; adopting cognate concepts to rewrite ontological graph and dispel the redundancies in AO.
The inconsistency checking and processing between ontology viewpoints is also the process of altering ontology viewpoints, which aims to eliminate the semantic inconsistency. The ontology viewpoints inconsistency-checked and processed are the basis to construct AO. Although the relations of concepts between ontology viewpoints could be fixed by correlation assertion [10], some potential relations have not been explored yet. In that case, heuristic rule is used to seek the possible existing relations of concepts between different ontology viewpoints. Four semantic relations are: Attribute-Of [11], Part-Of, Kind-Of, and Instance-Of. If component set PX of concept X is the true subset of component set PY of concept Y, consider concept X as a component part of concept Y, and their relation is Part-Of. The component part of concepts may consist of smaller parts, so implication relations exist in the component set of concept.
Prolog clauses are resorted to infer the problem of semantic implication. Taking Fig.1 as an example, there are two parts of ontological graphs to describe the Part-Of relations between concepts, to make sure whether concept V1 and concept V2 have Part-Of relation or not.
Predicate C(X) expresses that X is a concept, and P(X) shows that X is a component part. If C(V1) is true, the fact clauses produced in fragment 1 of the ontological graph are as follows and shown in Fig.1.
(1) C(V1).
(2) P(b): -C(V1).
(3) P(c): -C(V1).
(4) P(e): -P(c).
(5) P(f): -P(c).
The conditional clauses produced by V2 in fragment
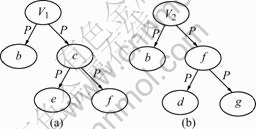
Fig.1 Two fragments of ontological graphs: (a) Fragment 1; (b) Fragment 2
2 of the ontological graph are as follows:
(6) C(V2): -P(f), P(b).
(7) P(f): -P(d), P(g).
Judge whether target C(V2) is true or not by clauses (1)-(7). If C(V2) is true, the hypothesis “the component set of V1 implicates that of V2” will be true. It is easy to infer the truth of C(V2) from clauses (1)-(7), so the hypothesis is valid. Similarly, reproduce clauses to judge whether the hypothesis “the component set of V2 implicates that of V1” is valid or not (the process is omitted). From the result of inference, the hypothesis “the component set of V2 implicates that of V1” is not valid. Therefore, in Fig.1, it is considered that V2 is the component part of V1.
Before obtaining AO from ontology viewpoints, firstly pay attention to a group of special concepts. Here, they are named as cognate concepts, which can be defined as: if there exist a group of concepts in all ontology viewpoints, and each of these concepts in their ontology viewpoints and the relations and concepts are related to these cognate concepts, the group of concepts will be cognate ones. As to cognate concepts, if the intersection of their attribute sets is not empty, we expect to use a public concept to express semantic in AO. Meanwhile, the public concept and cognate concepts should maintain paternity [12]. As a result, we need to alter the ontological graph of ontology viewpoints. The altering process is shown in Fig.2, in which Intent(C)= Intent(A)∩ Intent(B).

Fig.2 Ontological graphs in ontology viewpoints altered according to cognate concepts: (a) Ontological graph 1; (b) On- tological graph 2; (c) Relations between concepts; (d) Altered ontological graph based on graphs 1 and 2
After updating ontological graph based on the cognate concepts, the work of obtaining AO from ontology viewpoints can be done. The steps of obtaining AO from ontology viewpoints Pl, P2, …, Pn are shown as follows.
(1) Obtain the ontological graph G of AO by combining the ontological graphs in Pl, P2, …, Pn, and add the correlation assertion in Pl, P2, …, Pn and relations between concepts received by heuristic rule into G.
(2) Evaluate and alter ontological graph G (adding, deleting and altering the concepts and relations are completed by anthropologists).
(3) Select axiom θ of Pl, P2, …, Pn, which is related to but does not conflict with G as the axiom of AO.
From the above steps, it is concluded that in the process of constructing AO, the work of anthropologists is still of great importance because with ontology as the carrier of shared knowledge, people’s understanding is all along the most significant part.
In the ontology-driven application, users always need to enquire ontology to get their interested concepts and relations [13]. Category C in ontology is described as predicate form C (p1, p2, …, pn), where p1, p2,…, pn are n pieces of data type properties of category C (e.g., daml:DatatypeProperty of DAML+OIL). An enquiry can be expressed by using the following Datalog rule:
Q(X): -C1(X1), C2(X2), …, Cn(Xn)
Among them, Q(X) is the head of Datalog rule X represents the property to be enquired; C1(X1), C2(X2), …, Cn(Xn) are considered as the body of the rule, Ci(Xi) (1≤i≤n) is the sub goal, and X1, X2, …, Xn represent properties in categories C1, C2, …, Cn. Here, Ci(Xi) (1≤i≤n) can be viewed as one relation in the relation model. If X![]() X1∪X2∪…∪Xn, the Datalog rule will be safe. If Q(X) appears at least once in the body of the rule, the Datalog rule will be recursive. If Ci(Xi) (1≤ i≤n) appears in the body of the rule, the Datalog rule is negative.
X1∪X2∪…∪Xn, the Datalog rule will be safe. If Q(X) appears at least once in the body of the rule, the Datalog rule will be recursive. If Ci(Xi) (1≤ i≤n) appears in the body of the rule, the Datalog rule is negative.
Datalog is a category Prolog language for deductive database. It is different from Prolog according to the following items.
(1) Functions will not appear as parameters of predicates in Datalog, but as variables or invariables.
(2) In semantics, Datalog program is built upon model theory other than proof theory of Prolog.
Definition 5 Query equivalence and query including: As to queries Q1 and Q2 in a database D, if Q1(D) ![]() Q2(D), query Q1 will be contained in Q2, denoted as Q1
Q2(D), query Q1 will be contained in Q2, denoted as Q1![]() Q2. If there is no query Q3 to make Q1
Q2. If there is no query Q3 to make Q1![]() Q2
Q2![]() Q3, Q1 will be maximally contained in Q2. If Q1
Q3, Q1 will be maximally contained in Q2. If Q1![]() Q2 and Q2
Q2 and Q2![]() Q3, Q1 and Q2 are called query equivalence.
Q3, Q1 and Q2 are called query equivalence.
In ontology, the most important and usual relation between categories is inheritance relation. Based on the inheritance relation between categories, the concept of category closure is defined as follows.
Definition 6 Category closure in ontology: In ontology O, the category closure of category C is the set of C’s sub-categories in ontologies C and O, denoted as C+.
If query in ontology O: Q(X):-C1(X1), C2(X2), …, Cn(Xn) (Ci (1≤i≤n) belongs to ontology O), the query will find out the solution via the following extended form:
Q(X):-C1(X1)+, C2(X2)+, …, Cn(Xn)+
In SWAO information integrated method, users’ enquiries are based on AO, which needs to be rewritten into local ontology. This process is called enquiry rewriting. In the research of the project, referring to the enquiry rewriting technology in relational database, we express the concepts (mainly referring to catalogue) in ontology as the form of predicates, use Datalog rule to show enquiries, and classify them as global as view (GAV) and local as view (LAV) according to the relation of concepts in AO and in local ontology in order to implement enquiry rewriting algorithm.
Under GAV, the category in middle tier ontology is shown as the category view of local ontology, which is indicated as example 1.
Example 1 BookInfo and AuthorInfo are included in ontology O. BookInfo uses predicate BookInfo (id, title, name, abstract) to express the work of teacher in the university, where id shows the serial number of teacher, title is the name of publication, name means the name of the author, and abstract is the abstract of the publication. AuthorInfo adopts predicate AuthorInfo (id, name, dept) to express semantic, where dept means the department of the author.
Suppose that in the local ontologies O1 and O2, for predicate Teacher(id, name, dept, position), where position means the title of the teacher, we can use the following Datalog rule to show the relationship between categories AuthorInfo and Teacher:
O. AuthorInfo (id, name, dept) :- O1. Teacher (id, name, dept, position).
O. AuthorInfo (id, name, dept) :- O2. Teacher (id, name, dept, position).
Suppose that in local ontology O2, category Publication is to adopt predicate Publication (id, title, abstract) to show sematic, where id means the serial number of the author of the publication, we can apply categories Publication and Teacher to express BookInfo according to the following Datalog rule:
O.BookInfo (id, title, name, abstract) :-
O1. Teacher (id, name, dept, position),
O3. Publication (id, title, abstract).
O.BookInfo (id, title, name, abstract) :-
O2. Teacher (id, name, dept, position),
O3. Publication (id, title, abstract).
Before discussing the query rewrite under GAV, the equivalence rewriting is introduced at first.
Definition 7 Equivalence rewriting: If Q is a query and V={V1, V2, …, Vn} is a set defined by view, query Q′ is the equivalence rewriting of Q when (1) Q′ only uses the view definition in V and (2) Q′ and Q are equivalence queries.
Under GAV, query rewriting is quite direct. The category in AO adopts that in local ontology, so only the definition of the category in AO needs to be expanded during the process of enquiry rewriting. For instance, consider query Q aiming at example 1:
Q. (title, dept):-O. BookInfo (id, title, name, abstract), O. AuthorInfo (id, name, dept), dept=“CS”.
The query rewriting result of Q is as follows:
Q′. (title, dept):-O1.Teacher (id, name, dept, ¤); O3. Publication (id, title, abstract), dept=“CS”.
Q′. (title, dept):-O2.Teacher (id, name, dept, ¤); O3. Publication (id, title, abstract), dept=“CS”.
where “¤” means the omitted parameter variable. Obviously, Q′ is the equivalence rewrite of Q.
Datalog faces to relation database, so rational algebra operation can be used to express the rewriting process of query Q.
3 Concept extraction based on semantic term mining
A complete and accurate ontology is a necessary precondition of ontology-based web information integration [14]. The construction of ontology is nevertheless a kind of time and energy consuming work, so the automation of ontology construction is an important problem that should be solved urgently. Ontology mainly contains knowledge shared in domain while it is implicated in different semantic backgrounds. Therefore, this problem is tough and there is no mature technology so far.
Extracting concepts of domain ontology from data set is the primary method to assist ontology construction at present [15], and the current research mainly focuses on extracting concepts from document set. These methods mainly adopt mathematical statistics and natural language processing, and they also have deficiencies, for example, the precision of extraction is not high, and the completeness of concept extraction results cannot be calculated [16]. For this purpose, the method of concept extraction based on semantic term mining, i.e. CESTM concept extraction method, was put forward. The process of CESTM-based concept extraction from object set is similar to that of constructing concept lattice in essence, in which efficiency is an important factor to influence that of concept extraction. Combining with frequent item-set discovery technology in data mining domain [17], the algorithm of concept lattice structure based upon inter-related suffix tree was presented, which can turn the discovery process of concept connotation into the process of mining closed item-set. The greatest feature of the algorithm is that in the discovery process of concept connotation, candidate set will not be generated, which will largely improve the efficiency of concept extraction.
Formal concept analysis is a branch of applied mathematics [18], which is on the basis of mathematization of concept and concept hierarchy. At present, the method of formal concept analysis has already been widely applied to the concept clustering, data analysis, information search, knowledge discovery, and ontology construction. The method of formal concept analysis was used to find out the internal relation between concepts, which are described by some properties. In order to obtain properties from texts, analyze texts, and extract verb/prepositional phrase, verb/subject phrase and verb/object phrase, the corresponding verb was taken as the property to construct formal context for each appeared noun.
Definition 8 Formal context: One formal context is a triplet (G, M, I), where G and M are sets, and I![]() G×M is a binary relation between G and M. The elements in G are called objects and those in M are properties. For A
G×M is a binary relation between G and M. The elements in G are called objects and those in M are properties. For A![]() G and B
G and B![]() M, there exist
M, there exist
A′:={m∈M|![]() g∈A: (g, m)∈I}
g∈A: (g, m)∈I}
B′:={g∈G|![]() m∈B: (g, m)∈I} (1)
m∈B: (g, m)∈I} (1)
For object set A, A′ is a set of objects with common property in set A; for property set B, B′ is a set of objects with all properties in set B.
Definition 9 Formal concept: Duplet set (A, B) is the formal concept of formal context (G, M, I) if and only if A![]() G and B
G and B![]() M, and A′=B and A=B′. A formal concept that gives context can be defined with the relation between hypernym-hyponym concepts:
M, and A′=B and A=B′. A formal concept that gives context can be defined with the relation between hypernym-hyponym concepts:
(A1, B1)≤(A2, B2)![]() A1
A1![]() A2(
A2(![]() B2
B2![]() B1) (2)
B1) (2)
where “≤” reflects the hierarchy relation between concepts. (A1, B1) is the sub-concept of (A2, B2), and (A2, B2) is the super concept of (A1, B1). All concepts of (G, M, I) constructed by hierarchy relations are called concept lattice. For example, a museum archives an impressive collection of medieval and modern art. The building combines geometric abstraction with classical references that allude to the Roman influence on the region.
Analyze the sentence by analyzer:
houses_subj (museum)
houses_obj (collection)
combines_subj (building)
combines_obj (abstraction)
combine_with (references)
allude_to (influence)
Two questions will be generated after extracting these duplet sets. Firstly, the results analyzer output may be wrong, that is, not all the verb properties duplets obtained are correct. Secondly, not all the verb properties duplets obtained are meaningful in semantics, which can help to distinguish different objects. In order to solve the above problems, some information calculation formula shall be used to set threshold value to measure objects/ properties duplets. Only when these measuring results surpass some certain threshold values, these objects/ properties duplets are what we need. The features of formal concept analysis are more general, easier to be implemented and larger coverage.
4 Answer extraction based on agent ontology
After analyzing the questions presented by users, some entities and their attributes or entity-entity pair will be received, and these results will be submitted to answer extraction module. First of all, map the entity on the corresponding catalogue in class hierarchy of ontology knowledge base. In the following, find out this entity in all the corresponding entities of this catalogue, and then search the attribute value needed. If the corresponding catalogue is searched instead of the entity, it is necessary to trace back to father catalogue and find out whether the attribute exists or not. If the condition is satisfied, the attribute value should be returned. If the condition is not satisfied, it is necessary to trace back again until the direct subclass of abstract class reaches. As to the
Jena inference engine and SPAROL language are resorted to search for answers. Jena inference engine provides perfect support for ontology modeling, operation and inference and other relative activities. SPAROL language is an ontology searching language recommended by W3C, which uses the searching form of SQL sentences [19]. SPARQL language offers the function of ontology enquiry. In ontology, all knowledge is in form of triplet (
The advantage of adopting promiscuous inference mode is that backward rules only work on current relative data set that can obtain better performance. For example, SubPropertyOf restriction implemented by using RDFS rules in one inference can use the following rules: [(? a? q? b) <- (?p Rdfs:subPropertyOf ?q), (?a ?p ?b)]. Every target should be matched with the head of the rule, so every enquiry can activate a dynamic test whether there exists sub-attribute of the current attribute search or not. Oppositely, mixing rules: [(?p Rdfs:subPropertyOf ?q), Not Equal(?p, ?q)-> [(?a ?q ?b)<-(?a ?p ?b)]] preprocesses all sub-attribute relations and store them in a simple chain of rules, which are activated only by finding out an attribute with sub-attribute. If the condition is not satisfied, there is no enquiry time of head for this rule. OWLReasoner [20] was resorted to alter and redefine the needed rules on the basis of Jena’s original rules document, and to infer by promiscuous mode.
5 Experimental results and analysis
1 000 articles about plastics were selected as testing samples from training corpus of People’s Daily in electronic version in 1998 and 2000, among which 50 questions were designed. At the beginning, experts were engaged to carry on artificial mark on the correlation between every question and every article, and then they were tested with the system. Due to the limited space, the experimental data of document recall and precision rates of the first 5 questions are shown in Table 1.
Table 1 Experimental results of QA about recall rate and precision rate
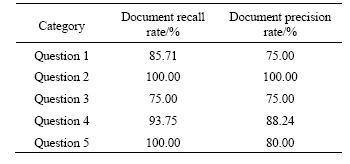
According to Table 1, the document recall rate is above 90% in average and the lowest precision rate also reaches 75.00%, which indicates that the module can meet the searching requirements of users.
General ontology was constructed, which was tested on the QA system of a financial bank. When users enter in the system, they can raise questions with natural language. The results of system testing indicate that, among ![]() questions searched, 797 are answered correctly with precision rate of 56% and recall rate of 65%. The following reasons lead to low precision and recall rates.
questions searched, 797 are answered correctly with precision rate of 56% and recall rate of 65%. The following reasons lead to low precision and recall rates.
(1) No relative knowledge in bank domain is in knowledge base.
(2) Results are not analyzed by question analysis module.
After constructing the general ontology and the AO in bank domain, the system was tested for another time. The precision rate of the system reaches 86%, and recall rate reaches 93%, as illustrated in Table 2.
In the following, Turing test method is adopted to test the results of the QA system. First of all, answers to questions provided by 20 users were extracted with this algorithm. And then the answers of the 20 questions generated automatically by using this algorithm were combined with 40 questions compiled by two professors from department of Chinese language. Finally, the authoritative Chinese expert was invited to carry on black case mark to answers of the questions raised by each user. The testing results are illustrated in Table 3.
From the experimental results of Table 3, we can see that the QA effect of our QA system is 65% better than that of one teacher, and 35% of that of two teachers. It can be seen that, the effect of answers generated automatically by using our algorithm is better than that of manual answers, which reaches the practical level basically.
The QA method based on structural question sentence instances, i.e. SQSI method, is a conventional QA method at home and abroad. An experiment was conducted to compare the QA method based on AO with the SQSI method. The corpus selected in our experiment is the Lancaster corpus of mandarin Chinese (LCMC) [21], which possesses 500 texts with 839 006 words in total belonging to 15 categories and is segmented and labeled with part-of-speech in form of XML. The experiment compared 180 questions in 88 articles covering 8 categories, such as news reports, news editorials and news comments of the corpus. Compared with manual answers of authoritative experts, the recall and precision rates are indicated in Tables 4 and 5.
From Tables 4 and 5, the experimental results of the
Table 2 Comparison of experiment results before and after improving

Table 3 Experimental results of QA by Turing test method

Table 4 Comparison of recall rate of SQSI, expert and AO (%)

Table 5 Comparison of precision rate of SQSI, expert and AO (%)

6 Conclusions
(1) The information integration method of semantic web based on agent ontology (SWAO method) is put forward aiming at the problems in question answering (QA) system, which will integrate, analyze and process enormous web information and extract answers on the basis of semantics. Based on multi-view theory from engineering requirements, agent ontology (AO) construction method upon multi-view theory is presented. At present, the main method of assisting to construct ontology is to extract concepts of domain ontology from data set. Therefore, the method of concept extraction based on semantic term mining (CESTM) is brought forth.
(2) For the problem that the QA system lacks reasonable theory model, the structural model of the QA system is presented by applying AO, from which OWL language is adopted to describe domain ontology knowledge and Jena inference engine is used to infer and extract answers. In this way, the precision rate of the QA system is improved. In system tests, the precision rate reaches 86%, and the recall rate is as high as 93%, which reach the practical level basically. Experimental results indicate that this method is feasible, and has referential significance and high value of in-depth research to the QA system.
References
[1] GUHA R, MCCOOL R, MILLER E. Semantic search [C]// Proceedings of the 15th International Conference on World Wide Web. New York: ACM Press, 2006: 700-709.
[2] HUANG Z S, FRANK V H, ANNETTE T T. Reasoning with inconsistent ontologies [C]// Proceedings of the 19th International Joint Conference on Artificial Intelligence. Edinburgh: Scotland Press, 2005: 188-192.
[3] HUANG Yin-fei, FANG Zheng. The design and implementation of campus navigation system: EasyNav [J]. Journal of Chinese Information Processing, 2001, 13(4): 55-63. (in Chinese)
[4] GUO Qing-Lin. Research on the question answer system based on natural language understanding [C]// Proceedings of the 2007 International Conference on Life System Modeling and Simulation. Shanghai: Shanghai University Press, 2007: 108-113.
[5] GUO Qing-lin, LI Cun-bin. Research on the application of text clustering and natural language understanding in automatic abstracting [C]// Proceedings of the 4th International Conference on Fuzzy Systems and Knowledge Discovery. Haikou: Hainan University Press, 2007: 66-72.
[6] BRICKLY D, GUHA R V. Resource description framework (RDF) schema specification [EB/OL]. [2008-05-06]. http://www.w3.org/ TR/rdf- syntax-grammar/.
[7] HOLSAPPLE C W, JOSHI K D. A collaborative approach to ontology design [J]. Communications of the ACM, 2002, 50(2): 42-47.
[8] XIAO Zhi-qiang, WANG Jin-di, LIANG Shun-lin, QU Yong-hua, WAN Hua-wei. Retrieval of canopy biophysical variables from remote sensing data using contextual information [J]. Journal of Central South University of Technology, 2008, 15(6): 877-881.
[9] LACASTA J, NOGUERAS J. A web ontology service to facilitate interoperability within a spatial data infrastructure: Applicability to discovery [J]. Data and Knowledge Engineering, 2007, 63(3): 947-971.
[10] SONG M, SONG I Y, HU X H. Integration of association rules and ontologies for semantic query expansion [J]. Data and Knowledge Engineering, 2007, 63(1): 63-75.
[11] ABULAISH M, DEY L. Biological relation extraction and query answering from MEDLINE abstracts using ontology-based text mining [J]. Data and Knowledge Engineering, 2007, 61(2): 228-262.
[12] HUANG N, DIAO S H. Ontology-based enterprise knowledge integration [J]. Robotics and Computer-Integrated Manufacturing, 2008, 24(4): 562-571.
[13] CHEN T Y. Knowledge sharing in virtual enterprises via an ontology-based access control approach [J]. Computers in Industry, 2008, 59(5): 502-519.
[14] LEE C S, KAO Y F, KUO Y H. Automated ontology construction for unstructured text documents [J]. Data and Knowledge Engineering, 2007, 60(3): 547-566.
[15] HUANG Y F, HSU C H. PubMed smarter: query expansion with implicit words based on gene ontology [J]. Knowledge-Based Systems, 2008, 21(3): 102-111.
[16] NIE X J, ZHOU J L. A domain adaptive ontology learning framework [C]// Proceedings of IEEE International Conference on Networking, Sensing and Control. Sanya: Hainan University Press, 2008: 1726-1729.
[17] LUO Ke, WANG Li-li, TONG Xiao-jiao. Mining association rules in incomplete information systems [J]. Journal of Central South University of Technology, 2008, 15(5): 733-737.
[18] GANTER B, RUDOLPH P. Formal concept analysis methods for dynamic conceptual graphs [C]// Proceedings of the 3rd International Conference on Formal Concept Analysis. London: Springer-Verlag, 2005: 192-199.
[19] WANG F S, ZANIOLO C. Temporal queries and version management in XML-based document archives [J]. Data and Knowledge Engineering, 2008, 65(2): 304-324.
[20] CASTELEIRO M A, JOSE J D. Clinical practice guidelines: A case study of combining OWL-S, OWL, and SWRL [J]. Knowledge- Based Systems, 2008, 21(3): 247-255.
[21] The Lancaster corpus of mandarin Chinese (LCMC) [EB/OL]. [2008-04-22]. http://www.ling.lancs.ac.uk/corplang/lcmc/.
(Edited by CHEN Wei-ping)
Foundation item: Projects(60773462, 60672171) supported by the National Natural Science Foundation of China; Projects(2009AA12143, 2009AA012136) supported by the National High-Tech Research and Development Program of China; Project(20080430250) supported by the Foundation of Post-Doctor in China
Received date: 2008-12-08; Accepted date: 2009-03-05
Corresponding author: GUO Qing-lin, Associate Professor; Tel: +86-10-51963578; E-mail: qlguo@pku.edu.cn

