基于OpenMP的文件压缩与解压的并行设计模型
胡荣1,邹承明2
(1. 湖南工学院 计算机与信息科学学院,湖南 衡阳,421002;
2. 武汉理工大学 计算机科学与技术学院,湖北 武汉,430070)
摘要:在多核环境下,对文件压缩与解压并行算法进行研究,提出一种基于OpenMP的文件压缩处理并行设计模型。该模型由查找热点代码、并行化分析、并行建模、实现、调试等步骤组成。以动态哈夫曼算法为研究算法,将多核压缩处理并行设计模型应用到文件压缩与解压中。并在文件并行处理过程中,与数据分解法相结合对数据文件进行分割,将分解后的数据由主线程分给多个处理器上的多个子线程来并行处理,以此提高多核处理器的利用率并提高文件压缩效率。最后通过实验模拟验证模型以及算法性能。研究结果表明:在八核处理器下通过对文本文件、图像文件和音频文件等多种不同类型文件进行压缩解压试验,验证了动态Huffman并行算法与串行算法相比其加速比可以达到1.5~8.0倍,性能也得到很大提高。
关键词:OpenMP;并行设计模型;多核多线程;Huffman并行算法
中图分类号:TP311 文献标志码:A 文章编号:1672-7207(2014)08-2684-07
File compression and decompression parallel design model based on OpenMP
HU Rong1, ZOU Chengming2
(1. College of Computer and Information Science, Hunan Institute of Technology, Hengyang 421002, China;
2. School of Computer Science and Technology, Wuhan University of Technology, Wuhan 430070, China)
Abstract: The parallel algorithm was studied for the compression and decompression of file under multi-core environment. The file compression processing parallel design model was proposed based on OpenMP, and the procedures of the model include finding the hot spot, parallel analsis, modeling, realizing and debugging. Taking the dynamic Huffman algorithm as the research algorithm, the multi-core compression processing parallel design model was applied in the compression and decompression of file. To improve the utilization of multi-core processor rate and speed up the file compression efficiency, the method of data decomposition was used to decompose data for parallel processing when the parallel algorithm deals with file compression and decompression. Finally, experimental evaluation was performed to demonstrate the efficiency. The results show that conducting compression and decompression test through different files such as word documents, image files and audio files in the octa-core processor, the speedup of the dynamic Huffman parallel algorithm is 1.5 to 8.0 times higher than that of the serial algorithm, and the performance is greatly improved.
Key words: OpenMP; parallel design model; multi-core and multi-threading; Huffman parallel algorithm
随着计算机硬件、软件技术的不断发展,信息量和数据量呈几何级数增长。在遥感领域,对遥感数据、雷达数据的处理在实时性上都有较高要求,若直接进行数据传输或者存储,不仅成本高、难度大,而且有时难以实现。一种有效的解决方法就是对数据进行无损压缩。现有的无损压缩算法种类繁多,算法思想成熟,但其在进行压缩解压时大多存在处理速度较慢、实时性差等缺点。而随着多核并行技术的发展,仅仅依赖单核对数据进行压缩解压处理,其处理效率没有太大的提升空间。将多核并行技术和数据压缩算法进行有效结合,即采用多核处理器构架的高性能计算机系统来实现数据并行处理,可为提高数据处理效率提供研究方向。目前,多核并行设计实现方法多种多样,如采用并行加速模拟来实现并行设计的并行模拟[1-2]、直接执行[3]、FPGA加速[4]等,其能够利用目标的并行特征,在低成本的计算机上实现,具有广阔的应用前景[5]。但在进行数据压缩解压研究时还是以串行压缩为主,如:林蔚等[6]对主要数据压缩算法在无线传感器网络中的应用进行了研究,分析了各算法的特点,其主要侧重于压缩算法的串行数据处理;陈庆辉等[7]根据中文文本的结构特点,提出了一种改进的LZW算法,压缩比有所提高;韩凯等[8]虽提出了一种多核高速数据无损压缩的方法,但在减小压缩比的前提下大幅度提高了压缩速度,且其实现需要专有的编码器压缩系统,这使得该算法对硬件要求较高。以上研究有的对串行算法进行改进,有的通用性较差。数据处理效率总是有限的,无法满足遥感数据实时性处理,为此,本文作者在OpenMP 模型下提出一种易于通用的文件压缩处理并行设计模型,使其适用于采用不同压缩算法实现数据流的并行压缩解压。并以改进的Huffman编码为研究对象,结合多核处理器系统的高性能特点,进行动态哈夫曼算法 OpenMP 并行加速模拟。在保证压缩效率的前提下,大幅度地提高压缩速度,充分发挥其多核处理器的性能。
1 基于OpenMP的动态哈夫曼算法多核并行模型及实现
1.1 多核文件压缩处理并行模型
多核构架下的多核并行技术为文件压缩处理提供了更好的处理平台,原有数据压缩处理方法在多核下不能充分发挥其作用。由此根据多核环境的并行特性,采用一种改进的多核文件压缩处理并行设计模型。其模型的具体实现步骤如下。
Step 1 对串行算法使用Intel Vtune性能分析器发现串行算法的热点代码。
Step 2 分析串行算法的并行化可行性。
Step 3 并行建模,实现并行算法。
Step 4 采用Intel线程检测器、Intel线程直方统计器和Intel性能分析器对并行算法进行调试与优化。
Step 5 检测并行算法的负载平衡以及多核利用率情况。
Step 6 采用Intel线程检测器查找并行算法中的潜在错误。
Step 7 跳转到Step3对并行算法进一步改进。
基本构造如图1所示。

图1 多核文件压缩处理并行设计模型
Fig. 1 Multi-core file compression processing parallel design model
由图1可知:对多核文件压缩处理首先就是要找到串行算法的热点代码,即程序最耗时部分。热点代码最利于实现并行处理,并能较大幅度地提高算法执行效率的程序部分。若算法热点代码与算法核心部分相吻合,则易于进行并行处理,得到更好的算法性能。其次,除热点代码外,执行时间较长或执行频率较高的算法部分的并行处理也能大幅度提高算法加速性能。为了更好地实现此并行设计模型,下面以动态哈夫曼算法为例在双核、四核、六核、八核计算环境下验证并行设计模型的有效性。并通过不断地对该模型及算法进行调试与优化改进,使其并行算法达到最优性能。
1.2 基于OpenMP的动态哈夫曼算法的实现
1.2.1 OpenMP模型
OpenMP并行设计语言是以线程为基础,通过一系列的编译指导语句来实现并行化,提供较完整的并行化控制语言。OpenMP的运行使用Fork-Join模型[9]。与MPI相比,其具有更好的可移植及易编程的特点[10-12]。在运行中,主线程采用并行化计算方式,随之产生对应的线程来执行并行任务。在并行中,主线程和子线程同时工作。其并行化程序执行完后,衍生的子线程就随之撤销或者挂起,不再运行,程序运行返回到主线程。
随着多核处理器的普及,为了提高多核处理器利用率,采用OpenMP并行设计语言进行设计。设计人员只需要思考哪部分代码可以用多线程运行,如何重构算法以获得更好性能。对最耗时且能并发运行的部分则使用OpenMP并行设计语言,将极大地提高程序的性能。
1.2.2 动态哈夫曼编码
动态哈夫曼编码是一种无损压缩算法,构造1棵不断变化的哈夫曼树,在进行第n个字符压缩时完全根据前面n-1个字符生成的哈夫曼树来实现。无论是压缩还是解压缩均使用同一哈夫曼树,并根据同一方法对哈夫曼树进行更新,故不需在解压缩时保存哈夫曼树,从而使得动态哈夫曼编码可以实时实现。
压缩和解压缩均对原始数据进行1次扫描,且二叉树的初始化都使用同一首字符来实现,再动态地对第n个字符进行压缩或解压缩。每压缩或解压1个字符时,二叉树都随之发生变化,与静态哈夫曼算法相比,不需要对哈夫曼的编码对照表进行保存,省去了保存哈夫曼码表的步骤。
解压缩与压缩文件过程相反,具体过程如下。
Step 1 定义一个结点结构体和数组,存放哈夫曼编码。
Step 2 对链表头结点和树的根节点进行初始化,且将根结点加入建立的双向链表中。
Step 3 将第1个字符添加到树和链表中。再遍历其后所有需要解压缩数据,采用按位逐一读取的方式。
Step 4 解压缩后树及链表都需要实时更新。
文件压缩具体流程如图2所示。
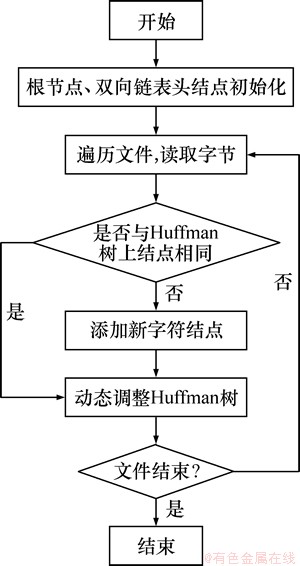
图2 动态哈夫曼算法压缩文件流程
Fig. 2 File flow of dynamic Huffman compression
1.2.3 动态哈夫曼并行算法及实现
对算法进行并行设计。首先借助Intel Vtune来发现动态哈夫曼算法的热点代码,找到其中最耗时部分;随后通过并行设计方法重点处理这部分代码。在多核多线程环境下,利用Fork-Jion模型,提出动态哈夫曼并行算法。算法具体过程如下。
Step 1 多核CPU获取待压缩的文件。
Step 2 对待压缩文件由各处理器进行数据分块至各个线程,实施细粒度型并行化。
Step 3 对数据源判断是否需更新动态Huffman编码器,若不需更新,则转Step 5;若需更新,则执行下一步更新操作。
Step 4 建立新的编码器。
Step 5 对当前文件采用动态Huffman编码进行数据压缩,并返回压缩结果。
其处理器对文件压缩过程如图3所示。

图3 动态Huffman并行算法压缩过程
Fig. 3 Compression process of dynamic Huffman parallel algorithm
在并行设计模型及算法实现过程后,还要对结果进行调试与优化,以保证模型及算法具有最优效率。这主要是由于串行编程会产生错误,并行程序同样也会存在错误问题,随之还可能导致任务定位不准确:所以,采用多线程来完成运行程序的工作也提高了程序设计错误的风险,而有些错误一般很难存在于单线程程序中。由此可见,在并行处理结束后,对处理结果进行调试与优化尤为重要,其主要方法可以通过采用Intel线程检测器来测量没有发生但可能发生或即将发生多线程错误的位置。通过线程检测器快速查找并修复Win和 OpenMP 线程中的Bug。线程错误在并行处理时易产生,且不易发现,这极有可能导致不可预测的后果,从而降低并行处理效率。
2 结果与讨论
2.1 性能评估
衡量并行程序设计的指标就是用最优串行算法的执行时间除以并行程序的执行时间所得到的比值,这就是加速比。加速比能够描述对程序并行化之后所获得的性能收益[13]。
 (1)
(1)
其中:s(p)为加速比;tw为最优串行算法的执行时间;ti为并行程序的执行时间。
在衡量并行程序设计带来的性能时,一般将任务分割为多个不同的子任务,再最大限度地并行处理子任务,此时加速比还与程序中串行程序的比例有关。加速比s(p)又可定义为
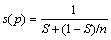 (2)
(2)
其中:S为程序中串行程序的比例;n为处理器核的数量。若将n设为∞,且设定最优串行算法的运行时间为1,则式(2)可表示为
 (3)
(3)
从式(2)可知:要提高并行程序的执行效率,可提高处理器核的数目并增加程序的并行化。在机器的处理器核一定时,可以通过提高并行化来提高程序执行率。Amdahl定律[14]则提出用来计算并行化程序在性能提升上的理论最大值,其计算式为
 (4)
(4)
其中:s(p)为加速系数;p为CPU个数;F为串行部分所占整个程序执行时间的比例,这也是进行并行化程序设计需要考虑的问题之一。
效率则用于衡量 CPU 的使用率,它主要是指完成某一个任务时,单处理器的执行时间与多核并行的执行时间乘以参与运算处理器核数的比值,其效率为
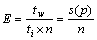 (5)
(5)
当效率E为1时,表明所有运行的处理器都是满载工作的,但在一般情况下,其值小于1。
对于固定问题,一般加速比越大,程序的性能越好。但通常执行率是由很多因素决定的,在程序编写后,在执行率达不到预期目标时,要仔细考虑执行期间可能产生影响的所有因素。当多核机器的处理器核和并行比例已确定时,在OpenMP模型下编写应用程序时还考虑的因素,如:
(1) 执行OpenMP本身会导致一部分并行带来的效率降低。
(2) 在应用程序执行过程中,有多个同步点,线程只在同步点同步后才可以继续执行后面的代码。
(3) 串行运行程序的基本特点是线程之间存在同步开销问题[15]。
2.2 实验测试
本文使用的开发工具为 Microsoft Visual Studio 2008,并行设计的实现则基于 OpenMP 编译指导语句。实验测试平台为拥有8个CPU的计算机,Intel Xeon X5355 CPU/2.66GHz,内存为8G。
为保证动态哈夫曼算法在串行设计中的正确性,并确保之后并行化的顺利进行,先对动态哈夫曼算法的串行程序进行测试,并将动态哈夫曼算法与静态哈夫曼算法的压缩效果进行对比,如表1所示。压缩不同类型文件的执行效果见表2。
为了明确优化效果,需要通过特定方式来衡量程序执行的效率,即通过衡量时间的方法来获得。一般时间函数粒度太大,而毫秒级的精度不满足小程序运行效率的需求。在Windows环境下,可以通过QueryPerformanceCounter函数获得高精度性能计数器。
从表2可知:对不同类型文件进行压缩时,其加速比都在1~2之间,有的甚至接近2(处理器核数目)。可见,并行程序大大提高了多核处理器的利用效率,并行模拟大幅度提高了多核处理器的利用率。从表2可以看出加速比和原文件的大小存在一定联系。
为了使数据采集更为完整,测试压缩同一种类型不同大小文件的加速比,选取文件格式为doc格式,如表3所示。
从表3可知:对不同大小的word文件进行压缩时,随着被压缩文件的容量逐渐增大,加速比也随着增加,但不会超过极限n(处理器核的数量)。这证明在压缩文件足够大时,实验结果可以达到预期效果。
压缩不同大小文件的执行效果见表3。从表3可知:当文件为28.0 kB时,其加速比只有0.886,由此可知当文件过小时,加速比甚至小于1,即并行程序性能反而比串行程序性能差。产生这种情况最主要的原因是:若被压缩文件过小,则使用 OpenMP 进行并行化后带来的效率不足以抵消 OpenMP 本身引入的开销;并行程序的并行化部分主要在数据压缩上;随着被压缩文件的增加,并行化比例将提高,此时加速比上升,使用OpenMP进行并行化后产生的效率已经远远超过 OpenMP本身引入的开销,与 Amdahl 定律相符。由此可见:基于OpenMP 模型并行化设计适用于具有较大计算规模的程序,只有在此情况下,才能使并行化性能提高远远大于OpenMP开销,从而提高其总体性能。
表1 静态哈夫曼算法与动态哈夫曼算法串行压缩结果
Table 1 Results of static Huffman algorithm and dynamic Huffman algorithm of serial compression
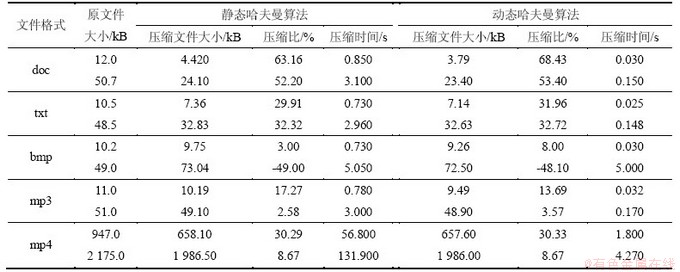
表2 压缩不同类型文件的执行效果
Table 2 Different types of file compression performance
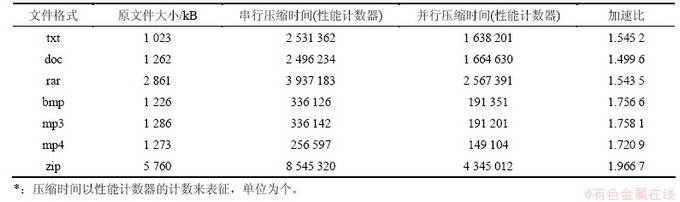
表3 压缩不同大小数据的执行效果
Table 3 Different sizes of data compression performance

图4所示为分别采用双核处理器、四核处理器、六核处理器、八核处理器测试压缩不同大小的同类型文件,选取的文件类型为doc格式、bmp格式、mp3格式、mp4格式,其文件加速比与压缩文件大小的关系。从图4可知:对于不同类型不同大小的文件,其用双核处理器、四核处理器、六核处理器及八核处理器进行并行压缩,加速比都达到1.5~8.0,有些甚至非常接近处理器核的数目。这表明基于 OpenMP 的压缩解压程序的算法并行性得到了极大提高。
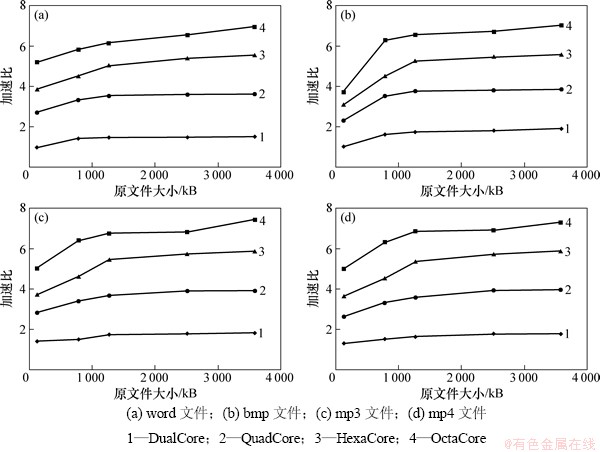
图4 不同类型文件的加速比与压缩文件大小的关系
Fig. 4 Relationship between speedup and compressed file size
但在实际情况中,开发更大的并行性所得到的性能效益可能很小,即在并行程度不高或者既定的情况下,随着计算机处理器核数量的增大,应用程序的效率并不一定能显著提高。图5所示为并行率确定为0.5时,增加处理器核数目对加速比的影响。由图5可知:当并行率为0.5时,根据Amdahl定律即式(4),增加处理器核数量时,加速比最大值为2。不论如何增加处理量数目,加速比均不会超过这个极值,可见提高程序的并行化比例具有重要意义。
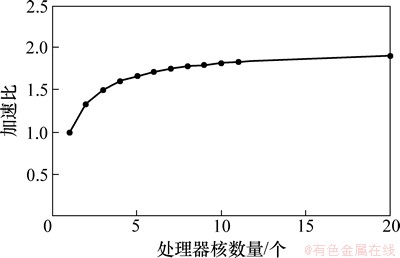
图5 加速比与处理器核数量的关系
Fig. 5 Relationship between speedup and processor number
3 结论
(1) 基于OpenMP文件压缩处理并行设计模型有效地将多核并行技术和数据压缩算法结合起来,快速地提高了数据文件的处理效率,与其他并行压缩算法相比,具有良好的可扩展性,且成本小,易实现,解决了现有方法处理效率低、实时性差的问题。
(2) 基于OpenMP的动态Huffman多核并行模型及算法对数据文件进行并行压缩与解压,可使其加速比达到1.5~n(处理器核的数目,n>1.5),有些甚至非常接近于处理器核数目,具有较高加速比以及计算效率,算法性能明显提高。
(3) 基于 OpenMP 的动态Huffman多核并行模型及算法建立了数据无损压缩的一种新方法,有效解决了文件压缩与解压算法由于单CPU硬件制约导致压缩瓶颈的问题,这也是采用多核并行加速的关键。
(4) 在OpenMP模型下进行并行压缩解压处理,应保证压缩解压文件具有一定规模,即基于OpenMP 模型并行化设计适用于具有较大计算规模的程序,而对于小规模文件压缩解压加速效果较差。算法的并行化比例越大,其加速效果越好。
参考文献:
[1] Das S R, Fujimoto R, Panesar K S, et al. GTW: A time warp system for shared memory multiprocessors[C]//Proceedings of the Winter Simulation Conference. Lake Buena Vista, USA: IEEE Press, 1994: 1332-1339.
[2] Chen J, Annavaram M, Du bois M. SlackSim: A platform for parallel simulations of CMPs on CMPs[J]. ACM SIGARCH Computer Architecture News, 2009, 37(2): 20-29.
[3] Miller J E, Kasture H, Kurian G, et al. Graphite: A distributed parallel simulator for multicores[C]//Proceedings of the 16th IEEE International Symposium on High-Performance Computer Architecture. Bangalore, India: IEEE Press, 2010: 1-12.
[4] DOU Yong, LEI Yuanwu, WU Guiming, et al. FPGA accelerating double quad-double high precision floating-point applications for exscale computing[C]//Proceedings of the 24th IEEE International Conference on Supercomputing. Tsukuba, Japan: IEEE Press, 2010: 325-336.
[5] 焦帅, 徐卫志, 唐士斌, 等. PartitionSim:一个面向众核结构的并行模拟器[J]. 计算机学报, 2011, 34(11): 2084-2092.
JIAO Shuai, XU Weizhi, TANG Shibin, et al. PartitionSim: A parallel simulator for many cores[J]. Chinese Journal of Computers, 2011, 34(11): 2084-2092.
[6] 林蔚, 韩丽红. 无线传感器网络的数据压缩算法综述[J]. 小型微型计算机系统, 2012, 9(9): 2043-2048.
LIN Wei, HAN Lihong. Summary of data compression algorithm in wireless sensor networks[J]. Journal of Chinese Computer Systems, 2012, 9(9): 2043-2048.
[7] 陈庆辉, 陈小松, 韩德良. 中文文本压缩的LZW算法[J]. 计算机工程与应用, 2014, 50(3): 112-116.
CHEN Qinghui, CHEN Xiaosong, HAN Deliang. Compression algorithm LZW on Chinese text[J]. Computer Engineering and Applications, 2014, 50(3): 112-116.
[8] 韩凯, 赵思聪, 张利, 等. 一种多核高速数据无损压缩方案及FPGA实现[J]. 计算机仿真, 2013, 30(10): 245-248.
HAN Kai, ZHAO Sicong, ZHANG Li, et al. Multi-core lossless compression system for high-speed data and its FPGA implementation[J]. Computer Simulation, 2013, 30(10): 245-248.
[9] Greg S, Richard B, YANG Xiaoyun. Multicore image processing with OpenMP[J]. IEEE Signal Processing Magazine, 2010, 27(2): 134-138.
[10] Bhattacharjee A, Contreras G, Martonosi M. Parallelization libraries: Characterizing and reducing overheads[J]. ACM Trans on Architecture and Code Optimization, 2011, 8(1): 5-29.
[11] Schmidl D, Terboven C, Mey D, et al. Binging Neste OpenMP programs on hierarchical memory architectures[R]. Tsukuba, Japan: Center for Computing and Communication of RWTH Aachen University, 2010: 5-8.
[12] 王铮. 一种支持OpenMP线程绑定的分布式构件模型[J]. 计算机应用与软件, 2013, 30(3): 203-206.
WANG Zheng. A distributed component model with OpenMP thread affinity support[J]. Computer Applications and Software, 2013, 30(3): 203-206.
[13] Akhter S, Roberts J. 多核程序设计:通过软件多线程提升性能[M]. 李宝峰, 富弘毅, 李韬, 译. 北京: 电子工业出版社, 2007: 167-170.
Akhter S, Roberts J. Multi-core programming: Increasing performance through software multi-threading[M]. LI Baofeng, FU Hongyi, LI Tao, trans. Beijing: Electronics Industry Press, 2007: 167-170.
[14] Hill M D, Marty M R. Amdahl’s law in the multicore Era. Univ. of Wisconsin computer sciences technical report CS-TR-1593[EB/OL]. [2007-04-21]. http://www.cs.wise.edu/ multifacet/papers/trl593_amdahl- multicore.pdf.
[15] 殷顺昌, 赵克佳. 一种基于POMP的OpenMP程序负载均衡分析方法[J]. 计算机工程与应用, 2006, 42(35): 133-138.
YING Shunchang, ZHAO Kejia. Method for load balance of OpenMP programs based on POMP[J]. Computer Engineering and Applications, 2006, 42(35): 133-138.
(编辑 陈灿华)
收稿日期:2013-09-19;修回日期:2013-11-24
基金项目:湖南省科技计划项目(2013GK3036);湖南省教育厅科学研究项目(12C0653);衡阳市科技计划项目(2013KG71)
通信作者:邹承明(1975-),男,湖北武汉人,博士,教授,从事嵌入式系统、高性能计算研究;电话:18062009298;E-mail:zoucm@whut.edu.cn

