DOI: 10.11817/j.issn.1672-7207.2015.08.022
一种低功耗的多端口寄存器文件结构设计
肖建青,娄冕,张洵颖,沈绪榜
(西安微电子技术研究所 集成电路设计部,陕西 西安,710065)
摘要:为了降低寄存器功耗而不损失处理器性能,提出一种基于读写队列的多体寄存器文件结构(multi-bank register file, MBRF)。该结构使用多个寄存器体来分担多端口的访问压力,并且为每个寄存器体设置相应的读写队列;通过指令分解将读写操作缓存在队列中,从而消除多体结构潜在的访问冲突;采用组合和旁路2种分配策略,减少缓冲队列的长度和对寄存器的读写请求。该结构在一个四发射的超标量模拟器上进行评估。研究结果表明:整个寄存器文件最终节省了52%的功耗,而处理器的IPC损失仅为1.6%。与其他寄存器文件相比,基于读写队列的MBRF结构在多发射处理器应用中具有明显的优势。
关键词:多发射;多体寄存器文件;读写队列;访问冲突;指令分解
中图分类号:TP302.2 文献标志码:A 文章编号:1672-7207(2015)08-2914-09
A low power design structure for multi-port register file
XIAO Jianqing, LOU Mian, ZHANG Xunying, SHEN Xubang
(Department of Integrated Circuit Design, Xi’an Microelectronics Technology Institute, Xi’an 710065, China)
Abstract: To reduce the power of register file without bringing processor performance loss, a novel multi-bank register file (MBRF) based on read and write queue was presented. Several register banks were employed to partake the register file access pressure on multiple ports, a read queue and a write queue were organized for each register bank. The read and write operations were decomposed from each instruction into two queues to avoid the potential access conflicts. In addition, both combining and forwarding dispatch strategies were used to reduce the queue length, as well as read and write requires for registers. The design structure was evaluated on a four-issue superscalar simulator. The results show that the total power of register file is reduced by 52% while the processor IPC loss is just no more than 1.6%. Compared with other register files, the MBRF based on read and write queue takes on an evident advantage in multi-issue processor.
Key words: multi-issue; multi-bank register file; read and write queue; access conflict; instruction decomposition
随着计算机体系结构的不断发展,微处理器已经从最初的单发射结构发展为先进的多发射结构,然后又从多线程、同时多线程处理器发展到目前主流的多核、众核处理器。尽管如此,多发射结构(诸如超标量、超长指令字)仍然是构建高性能处理器的基础[1]。为了最大限度地发挥出性能优势,多核处理器在大力开发核间并行的同时,针对每个处理器核仍采用多发射结构来获得更高的指令并行性,例如Intel的酷睿双核四发射处理器、TI的TMS320C6678八核八发射DSP处理器等[2]。在多发射处理器中,为了支持多条指令对操作数的同时访问,其物理寄存器文件必须具备多个端口。然而,多端口的寄存器文件需要增加每个存储单元的字线和位线数量,因此不可避免会产生极其显著的功耗开销,据统计多端口寄存器文件的功耗已占到了整个芯片功耗的10%~25%[3]。其次,多端口还会导致寄存器文件的面积以二次方趋势增长,例如,对于具有512个物理寄存器的八发射Alpha 21464微处理器而言,其16读8写的寄存器文件的面积相当于64 kB一级数据cache面积的5倍[4-6]。由于多端口寄存器文件会产生巨大的功耗和面积开销,严重制约了单芯片多处理器(Chip Multiprocessor, CMP)的进一步发展;因此,对多发射处理器中寄存器文件进行优化,成为了现代高性能低功耗微处理器设计领域中的一项关键技术,这也是微处理器向前发展的迫切需求。为了降低多端口寄存器文件对功耗和面积的负面影响,目前已经有许多优化方法。Sangireddy[7]提出了一种基于指令格式的选择执行技术,它通过限定两源操作数指令的发射数目,从而减少寄存器文件的读端口数,这种方法需要根据译码结果动态调节指令的发射,并且会损失处理器的性能。Balkan等[8]针对短生命周期的目的寄存器采用了选择性写回策略,从而减少寄存器文件的写端口数,但是该方法需要额外复杂的逻辑来探测具有短生命周期特征的目的寄存器,并且如果探测失败则仍然需要写回,因此它存在一定的局限性。Zhang等[9]给出了一种寄存器分组方法,在每个组中寄存器文件只具有很少的端口数,并且它与相应执行部件进行组合。但是,当组间寄存器的值需要同步时,必须通过编译器生成额外的指令来完成,这会影响处理器的执行性能并且不利于扩展。寄存器复制法则是一种较为直观的降低端口数的方法[10],它使用多个寄存器副本,每个副本平分原来的读端口;但为了保证数据的一致性,每个寄存器副本都必须具有与原来相同的写端口数。该方法在寄存器容量较大时仍然会带来巨大的功耗开销。与以上方法相比,多体寄存器文件(multi-bank register file, MBRF)则具有明显的优势[4-5,11]。由于多体结构将原来统一的存储资源平均分配到各个不同的存储体中,每个存储体只具有很少的读写端口和存储表项,并且能并行工作,因此它对解决整个存储器的延迟、面积和功耗效果十分显著。然而,多体结构唯一的缺点是它潜在的体访问冲突将会导致处理器IPC的下降。目前,解决体访问冲突主要是采用多体交叉编址[12]以及根据地址映射表进行动态寻址[13]等访问形式,但这仅限于访问地址具有一定规律的cache或外部主存储器;对于多体寄存器文件而言,指令所访问的寄存器由编译器分配,它对硬件结构完全透明,因此体访问冲突很难消除。目前,MBRF结构一般都通过增加仲裁逻辑来实现,但关键时刻会导致流水线的停顿[11];虽然,它可以采用更多并行的寄存器体以减少访问冲突,但这又会带来更复杂的译码逻辑,并影响寄存器的访问速率。本文作者针对多发射微处理器中多端口寄存器文件的优化设计,在传统MBRF方法的基础上进行改进,提出了一种基于读写队列的MBRF实现结构。
1 基于读写队列的MBRF设计
1.1 设计原理与结构
对于一个N发射的RISC处理器而言,其寄存器文件必须具有2N个读端口和N个写端口,图1所示为面向四发射微处理器的MBRF结构。在多体寄存器结构下,每个寄存器体只有很少的读写端口,但如果同时有多个读写操作去访问某一个寄存器体,那么就会产生体冲突,如图1(a)所示。
这种传统的MBRF设计为了支持指令读写所需的最大访问带宽,它需要8个简单的1r1w寄存器体,但即便如此,体访问冲突仍无法避免, 此时流水线必须停下来等待直到所有访问冲突都得到解决。虽然增加寄存器体的个数可以减少读写冲突,但是寄存器体数的不断增加使得体译码逻辑和相应的控制电路变得更加复杂,反过来影响MBRF在功耗、面积和访问速率上的优越性。
造成这种访问冲突的根本原因在于:以往的设计都是采用基于指令需求的寄存器访问方式。由于各条指令对寄存器的访问需求是不均衡的,有时需求少使得某些寄存器体的端口存在剩余,这里称为“非饱和”;有时需求多又使得这些寄存器体的端口资源不足,即“过饱和”。如果能将各个寄存器体在“过饱和”周期里未能完成的读写操作分配到它的“非饱和”周期里去执行,那么就可以避免体访问冲突和流水线停顿。为此,提出一种更高效的基于读写缓冲队列的访问方式,如图1(b)所示,它将所有指令的读写操作都暂存到缓冲队列中,由缓冲队列统一管理寄存器文件的读写访问。该方法突破了传统意义上的将指令与它所有寄存器访问进行单周期绑定的设计思想,而是允许前后指令的读写操作以流水化的模式并行执行,于是它很好地“隐藏”了“过饱和”周期的流水线停顿。这种访问方式只需要对每条机器指令进行分解,从而将寄存器读写访问与指令执行独立开来,其过程如图2所示。
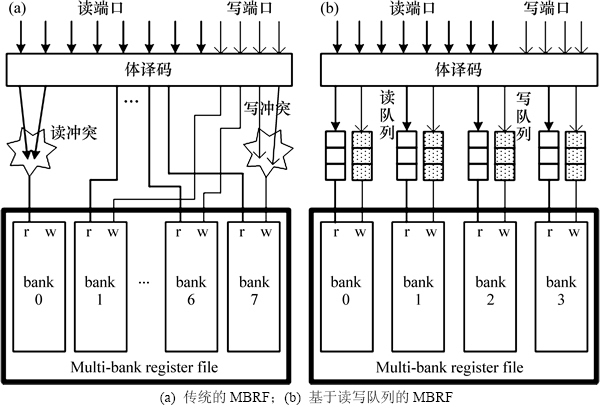
图1 面向四发射微处理器的MBRF结构
Fig. 1 MBRF architectures for a four-issue processor
由于当前的访问操作都缓存在队列中,所以无需提供与指令所需的最大访问带宽一致的寄存器体数,本文采用的基于读写缓冲队列的MBRF结构中只使用了4个寄存器体,这有利于简化多体结构的译码控制逻辑。另外,没有使用公共的缓冲队列,而是让每个寄存器体都具有自己的读写缓冲。因此,当访问操作到来时,它们按照先后顺序依次被分配到相应的队列中,这种基于寄存器体的并行缓冲队列可以实现对寄存器的乱序访问,它与分布式保留站的功能类似,有助于队列的实时释放和处理器性能的提升。
图3所示为读写缓冲队列在多发射处理器中的组织结构,这里假设处理器一共包含128个物理寄存器,那么每个寄存器则需要使用7位地址进行标识。在每个周期,读写操作都根据其地址的最低2位来译码选择对应的寄存器体。体译码之后,读队列中只存有高5位的源寄存器地址src_tag;而写队列中除了高5位的目的寄存器地址dest_tag之外还有32位的结果数据value。源寄存器和目的寄存器的物理地址来自于重命名单元的地址映射表,结果数据则来自于执行单元或者load单元。
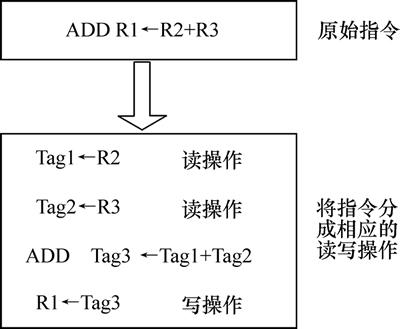
图2 机器指令的分解过程
Fig. 2 Decomposition of machine instruction
1.2 流水线修改
增加读写缓冲队列后,流水线结构修改如图4所示,为了不影响时钟频率,它将原来图4(a)中所示的寄存器访问流水级分成了队列调度级和新的寄存器访问级2部分。队列调度级主要负责读写操作在队列中的分配与释放;新的寄存器访问级则进行多个寄存器体的并行读写。类似于各个执行部件的保留站,增加的访问队列好比是各个寄存器体的“保留站”,因此,本设计将寄存器的乱序访问操作与执行部件的乱序执行重叠起来,如图4(b)所示。当然,为了使保留站中的指令能够正确地获取它从寄存器文件读出的源操作数,该结构仍然需要保留原来的从寄存器文件到保留站之间的数据通路[4]。
1.3 队列的分配与释放
基于以上结构,流水线可以持续不断地对新指令进行译码、并通过重命名分配寄存器读写操作,除非遇到缓冲队列满的情况。设置足够大的缓冲队列当然可以避免队列满的可能性,但其硬件开销太大。本文则采用了一种动态的管理方法,它能够自适应的分配和释放队列元素,从而只需要很小的缓冲队列。
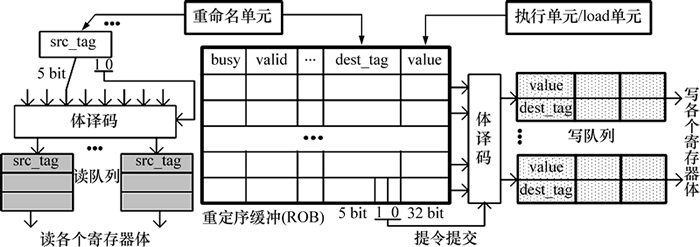
图3 读写缓冲队列的组织结构
Fig. 3 Organization for the read and write queues
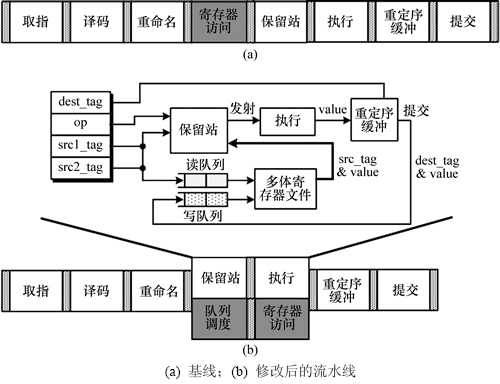
图4 流水线结构
Fig. 4 Pipeline structure
由于读写队列都是针对寄存器体的多个并行缓冲结构,只要其中1个读队列满,处理器就必须停止译码和重命名;而只要其中1个写队列满,就必须停止对指令的提交。为了减小因队列满而导致处理器性能的损失,需要将访问操作平均分配到不同的缓冲队列中,而不能集中于某一个队列上。因此,在寄存器重命名阶段,选择使用位于不同寄存器体中的空闲物理寄存器来对结构寄存器进行重命名[14],从而将相邻读/写操作的寄存器访问分配到不同的缓冲队列中,图5(a)描述了这种基于分体考虑的寄存器重命名策略,图中寄存器编号由小到大代表着连续访问时寄存器的分配情况。
此外,为了得到1个最小的有效的队列长度,避免队列中缓存不必要的访问操作,采用了组合和旁路2种分配策略,如图5(b)所示。若某时刻具有多个访问操作都是针对同一寄存器地址,则可以将这些读操作(或写操作)组合成仅有的1次访问并缓冲在队列中;若当前的访问操作数来自于它相关指令的执行结果、或者与队列中已有的某个访问操作相同,则该访问可以通过旁路方式获取数据而不需缓冲在队列中。事实上,这种分配方式由于减少了不必要的寄存器访问,从而在一定程度上降低了寄存器文件的功耗。
图6所示为队列分配的1个简单例子。首先通过寄存器体轮询的重命名技术将图6(a)中读写访问映射到不同体的寄存器中,如图6(b)所示,这里假设为4个寄存器体;然后按照指令顺序依次把读写操作分配到各自的队列中,如图6(c)所示;采用组合和旁路方式来减少不必要的读写操作在队列中的缓存,得到最终的分配情况如图6(d)所示。可以看到:图6(b)中所有指令的读操作和写操作都只占用了2个队列深度,因此最多2个周期就可以分别完成寄存器的读访问或者写访问。而传统的按照固定指令条数(如4发射结构)进行分配和提交的控制机制,在端口数充足的情况下完成这10条指令所对应的寄存器读写访问也至少需要10/4,即3个周期。显然,这种基于读写缓冲的动态分配策略相比于按固定指令数的分配方式而言具有更高的性能。
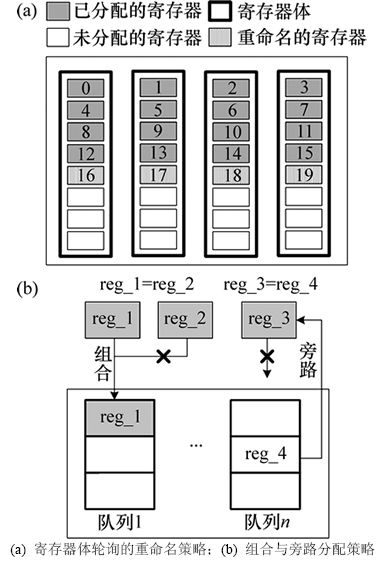
图5 动态调度策略
Fig. 5 Dynamic schedule policies
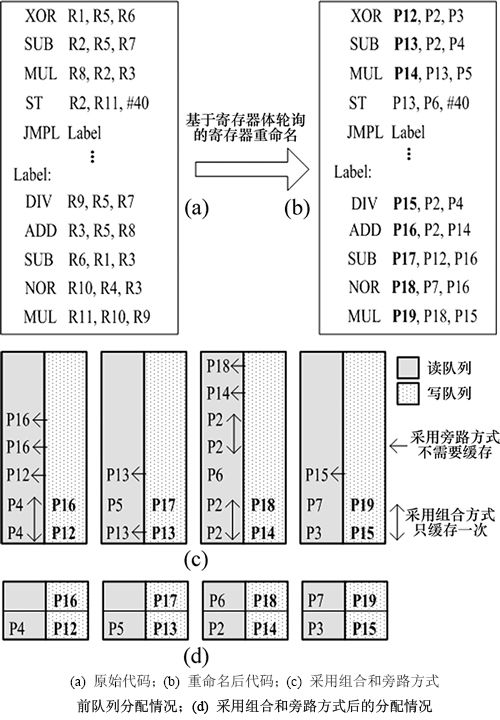
图6 读写队列分配情况示例
Fig. 6 An example for assigning register access queues
在指令执行过程中,各个读写缓冲队列只要非空,它在每个周期都会自动向寄存器文件发出读写操作并随之释放掉队列中的这个元素,所以无需额外的控制策略就可以保证队列元素的有效释放。
2 实验评估
使用Wattch来对上述设计进行性能和功耗的评估。Wattch是基于SimpleScalar平台的一套执行驱动的动态超标量处理器模拟工具[15],已广泛应用于各种新架构思想的模拟和评测中。为了构建本文所提出的处理器结构,对该模拟器进行了如下修改。
1) 原来采用单一存储结构实现的多端口寄存器文件被分成若干个具有很少表项的寄存器体,每个寄存器体只包含1个读端口和1个写端口;同时,每个寄存器体都配置有相应的读写访问队列。
2) 将统一管理的RUU单元实现为结构清晰的IQ(保留站)和ROB等功能子模块;并将隐含在RUU中的重命名寄存器与结构寄存器进行融合,采用RAT表和全局空闲表来完成寄存器的重命名操作,当新分配寄存器读写操作时,能够映射到不同寄存器体的访问队列中。
3) 在该模拟器的基础上,通过修改以ruu_dispatch、ruu_commit等为代表的主要函数,将原来按固定指令数进行分派和提交的机制实现成依据寄存器读写需求与缓冲队列动态自适应的分派和提交指令的控制方式。
模拟的处理器采用类Alpha AXP架构,其主要配置参数如表1所示。考虑到目前主流多核系统中处理器核大多都采用偏于保守或相对适中的发射宽度如四发射,因此本实验主要针对四发射处理器进行模拟。
表1 类Alpha结构的处理器模型
Table 1 Alpha-like processor model

由于该设计结构并不是根据应用程序的私有特性而进行专项优化,它对不同类型的程序都具有较强的通用性。因此,在本次评测中,只是选择了SPEC2006中的一部分典型程序,分别是7个整点基准程序(bzip2,gcc,h264ref,omnetpp,mcf,sjeng和gobmk)以及5个浮点基准程序(bwaves,soplex,gemsFDTD,dealII和leslie3d),并采用Ref数据集作为执行程序的输入激励。各个基准程序的初始化部分被快速模拟跳过,并且执行SimPoint工具所推荐的1亿条指令构成的区间。为了评估基于读写队列的多体寄存器文件结构对处理器性能和功耗的影响,实验中采用了理想的多端口寄存器文件、以及传统的多体寄存器文件结构作为比较的对象,如表2所示。
2.1 参数值的量化
本设计采用了基于读写队列的多体寄存器文件结构MBRF-Qmn,为了得到其最佳的参数值,首先需要分析寄存器体数m以及读写队列长度n对处理器性能的影响。增加寄存器体的个数可以减少体访问冲突,但同时它也增加了译码的复杂度。有研究表明,当寄存器体数超过16以后,MBRF结构在功耗、面积和访问速率上的优越性将不明显[11]。因此,本实验选择了当寄存器体数m分别为1,2,4,8和16时配置各种队列长度n来分析处理器的执行情况。
表2 寄存器文件结构比较
Table 2 Comparison of register file architectures

图7所示为相对于理想的无访问冲突的寄存器而言,MBRF-Qmn在各种参数下处理器的相对执行速率。由图7可见:当m为1和2时,寄存器体访问冲突最严重,此时处理器执行速率比其他情况都要低,随着缓冲队列长度的增加,体冲突逐渐被隐藏,执行速率也相应提高。当m为4和8时,体访问冲突得到有效抑制,并且队列长度n在从0增加到3的过程中,处理器执行速率呈指数型增长,分别达到了理想情况的98%和97%;但在此之后增长变得非常缓慢,这说明3个缓冲队列长度就足以用来消除体访问冲突。当m=16时,体访问冲突已经变得非常小,此时采用长度为1的缓冲队列就足够了;然而由于寄存器体数目庞大,译码逻辑开销显著,使得整体执行速率也只有理想情况的93.5%。
图8所示为相应参数下缓存队列的使用情况。从图8可以看出:在很小的一段范围内,缓冲队列都能够被充分利用;但是当队列长度n达到饱和值以后,其利用率开始呈现明显的下降趋势。此时继续增加队列长度对性能增长意义不大,它只会带来额外的功耗浪费。
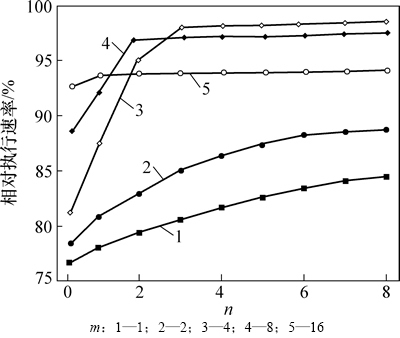
图7 配置值与相对执行速率的关系
Fig. 7 Relationship between execution speed and configuration
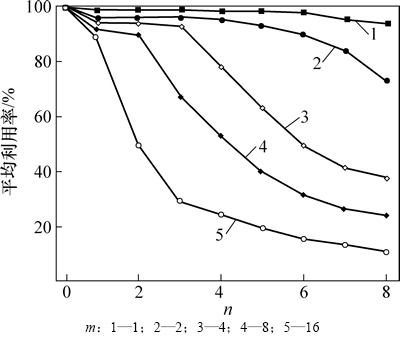
图8 配置值与利用率的关系
Fig. 8 Relationship between usage rate and configuration
综合考虑以上执行速率和利用率,容易得出本设计中最优的参数配置是寄存器体数m=4、队列长度n=3。因此,下面以MBRF-Q43作为设计代表与其他2种寄存器文件结构进行比较。
2.2 性能比较
表2所示的3种寄存器结构对应的周期指令数IPC(instruction per cycle)见图9。其中,传统上通过仲裁逻辑来检测体冲突的MBRF-Tra结构,虽然已经提供了满足最大读写带宽的8个寄存器体,但是其因访问冲突而停顿流水线的本质使得处理器的IPC损失很大。与理想多端口的MPRF-Ide结构相比,其整点基准程序的IPC平均下降5.4%,浮点基准程序则下降6.2%。本文提出的MBRF-Qmn结构在发生访问冲突时,可以将读写操作缓存在队列中而无需停顿流水线,因此提高了多体结构的执行性能。结果表明,当采用参数配置m=4和n=3时,MBRF-Qmn结构在整点和浮点基准程序下其IPC损失分别降到理想情况的1.6%和2.8%。
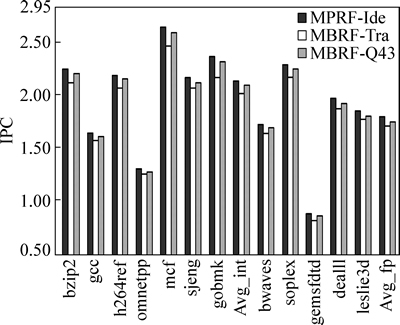
图9 3种寄存器结构对应的IPC
Fig. 9 IPCs for three register file architectures
2.3 功耗比较
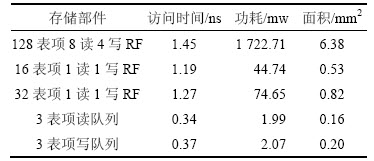
为了比较功耗,首先需要评估各种存储部件在单次访问下的开销。为此,修改了CACTI[16] 并在0.13 μm工艺参数下对3种RF以及很小的读写队列结构进行了访问时间、功耗和面积的估算。表3所示为各种存储部件的评估结果。与理想的8读4写多端口RF相比,MBRF-Tra结构中单个16表项的存储部件的访问时间减少了17.9%;而MBRF-Q43结构中单个32表项的存储部件的访问时间减少了12.4%。由于这2种MBRF结构的辅助逻辑(分别是仲裁电路和读写队列)都安排在专门的流水周期中完成,因此单个存储部件访问时间的减少可以作为该结构下提升处理器主频的参考。从表3可以看出,本文采用的MBRF-Q43设计结构中所增加的读写队列的电路开销都非常小。
表3 各种存储部件的访问时间、功耗和面积估计
Table 3 Access time, power and area evaluation for several storage components
在功耗和面积方面,与理想多端口RF相比,单个存储部件16表项和32表项RF的功耗分别为原来的1/38和1/23,面积分别为原来的1/12和1/8。考虑整个寄存器文件包含的存储体和辅助逻辑之后,MBRF-Tra结构总面积约减少19.5%,MBRF-Q43结构总面积约减少26.1%。
然而,由于单个存储部件单次访问的功耗并不能完全反应负载运行时刻的特征,因此需要考虑运行时刻的功耗情况。MBRF-Tra和MBRF-Q43结构中寄存器体的数目以及解决体访问冲突的管理机制不同,因而它们的功耗分布也就不同。为了便于理解和比较,给出了如下分析模型:
PMPRF-Ide=PIde×(Nread+Nwrite) (1)
PMBRF-Tra=PTra×(Nread+Nwrite)×8+PArb-logic (2)
PMPRF-Q43=PQ43×(NQread+NQwrite)×4+ (PQread×NQread+PQwrite×NQwrite)×4 (3)
其中:PIde,PTra,PQ43,PQread和PQwrite分别为访问128表项8读4写RF、16表项1读1写RF、32表项1读1写RF、3表项读队列以及写队列的1次访问功耗;PArb-logic为通过仲裁逻辑来消除体访问冲突时所产生的功耗;N为对应结构下读访问和写访问的次数。式(1)~(3)分别表示3种结构下寄存器读写访问的总功耗。由于MBRF-Q43结构采用了1.3节所述的组合和旁路的分配方式,消除了不必要的读写操作,因此NQread和NQwrite分别小于Nread和Nwrite,从而有利于功耗的降低。图10和图11所示分别为整个运行过程中3种寄存器结构的读写请求的次数。
从图10和图11可以看出:MPRF-Ide和MBRF-Tra结构下寄存器读请求和写请求的次数几乎保持一致,而且都相对较高。这是因为它们都没有采用读写缓冲队列,还是按照传统方式根据指令的固有需求进行读写访问。实验结果表明,MBRF-Q43结构通过缓冲队列实现动态的读写分配,将读访问请求降低近20%,写请求约降低11%。当然,队列长度越大,通过调度所节省的读写请求的比例也越大,但是这增加了缓冲队列单次访问的功耗。
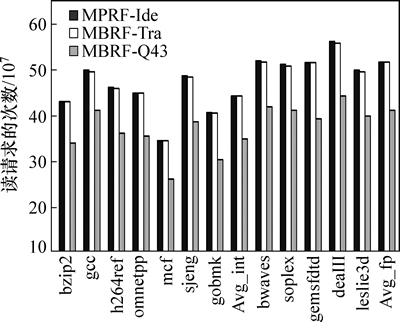
图10 3种寄存器结构的读请求次数
Fig. 10 Read requests for three register file architectures
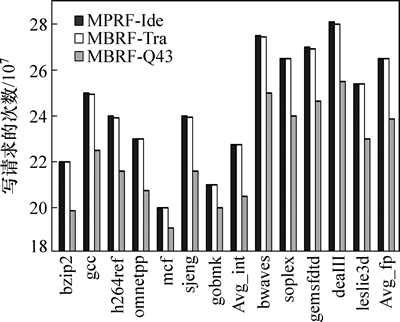
图11 3种寄存器结构的写请求次数
Fig. 11 Write requests for three register file architectures
图12所示为3种寄存器结构的总功耗。从图12可以看到:理想多端口MPRF-Ide结构寄存器的总功耗非常突出。在MBRF-Tra结构中,虽然PTra:PIde= 1:38,但是其8个寄存器体的仲裁逻辑PArb-logic也消耗了与寄存器体等数量级的功耗,因此它的总功耗并不等于理想情况下MPRF-Ide功耗的8/38;实际仿真结果表明:在整点基准程序下MBRF-Tra结构所节省的总功耗为40%,在浮点基准程序下为35%。对于MBRF-Q43结构,虽然单个寄存器体单次访问的功耗较MBRF-Tra结构大,如PQ43:PTra=1.6:1,但它采用缓冲队列节省了相当一部分的读写请求,并且也没有仲裁逻辑PArb-logic的额外功耗开销,因此它比MBRF-Tra结构更省功耗。结果表明:MBRF-Q43结构在整点基准程序下平均节省了52%的功耗,在浮点程序下则节省了47%的功耗。
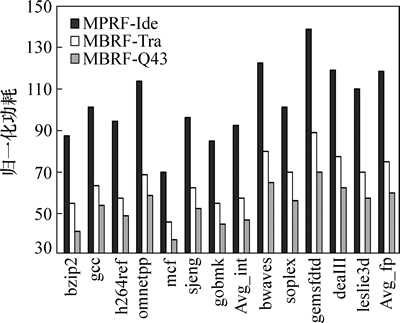
图12 3种寄存器结构的总功耗
Fig. 12 Total power for three register file architectures
3 结论
1) 提出了一种基于读写队列的MBRF结构,它将寄存器访问操作缓冲在读写队列中从而很好地消除了体访问冲突;同时通过组合和旁路2种分配策略可以进一步减少不必要的读写访问。
2) 基于读写队列的MBRF比传统的MBRF更具有优势,它不仅节省了更多的功耗和面积,而且也将IPC损失降低。
参考文献:
[1] Capalija D, Abdelrahman T S. Microarchitecture of a coarse-grain out-of-order superscalar processor[J]. IEEE Transacttions on Parallel and Distributed Systems, 2013, 24(2): 392-405.
[2] Gepner P, Gamayunov V, Fraser D L. The 2nd generation Intel core processor: Architectural features supporting HPC[C]//The 10th International Symposium on Parallel and Distributed Computing. New York: IEEE, 2011: 17-24.
[3] Aggarwal A, Franklin M. Energy efficient asymmetrically ported register files[C]//The 21st International Conference on Computer Design. New York: IEEE, 2003: 2-7.
[4] Hironaka T, Maeda M, Tanigawa K, et al. Superscalar processor with multi-bank register file[C]//The Innovative Architecture for Future Generation High-Performance Processors and Systems. New York: IEEE, 2005: 3-12.
[5] Tseng J H, Asanovic K. A speculative control scheme for an energy-efficient banked register file[J]. IEEE Transactions on Computers, 2005, 54(6): 741-751.
[6] Preston R P, Badeau R W, Bailey D W, et al. Design of an 8-wide superscalar RISC microprocessor with simultaneous multithreading[C]//The IEEE International Solid-State Circuits Conference. New York: IEEE, 2002: 266-334.
[7] Sangireddy R. Instruction format based selective execution for register port complexity reduction in high-performance processors[C]//The Third International Conference on Information Technology: New Generations. New York: IEEE, 2006: 227-232.
[8] Balkan D, Sharkey J, Ponomarev D, et al. Selective writeback: Reducing register file pressure and energy consumption[J]. IEEE Transactions on Very Large Scale Integration Systems, 2008, 16(6): 650-661.
[9] ZHANG Yanjun, HE Hu, SUN Yihe. A new register file access architecture for software pipelining in VLIW processors[C]//The 2005 Asia and South Pacific Design Automation Conference. New York: IEEE, 2005: 627-630.
[10] Kessler R E. The alpha 21264 microprocessor[J]. IEEE Micro, 1999, 19(2): 24-36.
[11] Tseng J H, Asanovic K. Banked multiported register files for high-frequency superscalar microprocessors[C]//The 30th Annual International Symposium on Computer Architecture. New York: IEEE, 2003: 62-71.
[12] 张浩, 林伟, 周永彬, 等. 通用处理器的高带宽访存流水线研究[J]. 计算机学报, 2009, 32(1): 142-151.
ZHANG Hao, LIN Wei, ZHOU Yongbin, et al. High-bandwidth memory accessing pipeline of general purpose processor[J]. Chinese Journal of Computers, 2009, 32(1): 142-151.
[13] 徐金波, 窦勇. 面向多兴趣区域图像处理应用的高效无冲突并行访问存储模型[J]. 计算机学报, 2008, 31(11): 2015-2025.
XU Jinbo, DOU Yong. An efficient conflict-free parallel memory scheme for image applications with multiple interested regions[J]. Chinese Journal of Computers, 2008, 31(11): 2015-2025.
[14] Shen J P, Lipasti M H. Modern Processor Design: Fundamentals of Superscalar Processors[M]. New York: McGraw-Hill, 2004: 237-262.
[15] David B. Wattch version 1.02 download page[EB/OL]. 2013-12-25. http://www.eecs.harvard.edu/~dbrooks/wattch- form.html
[16] Shivakumar P, Jouppi N P. CACTI 3.0: An integrated cache timing, power, and area model[EB/OL]. 2013-12-25. http://www.hpl.hp.com/research/cacti/
(编辑 赵俊)
收稿日期:2014-09-02;修回日期:2014-11-21
基金项目(Foundation item):国家高技术研究发展计划(863计划)项目(2011AA120204);国防科工局“十二五”民用航天预研项目(YY2011-012(D020201))(Project (2011AA120204) supported by the National High Technology Research and Development Program (863 Program) of China; Project (YY2011-012(D020201)) supported by the 12th Five-year Pre-research Program in Civil Spaceflights from the State Administration of Science, Technology and Industry for National Defense)
通信作者:肖建青,博士研究生,从事嵌入式微处理器研究与设计;E-mail:xjq_career@126.com

