A product module mining method for PLM database
来源期刊:中南大学学报(英文版)2016年第7期
论文作者:雷金 雷佻钰 彭卫平 钟院华 张秋华 窦俊豪
文章页码:1754 - 1766
Key words:product design; module division; product module mining; product lifecycle management (PLM) database
Abstract: Modular technology can effectively support the rapid design of products, and it is one of the key technologies to realize mass customization design. With the application of product lifecycle management (PLM) system in enterprises, the product lifecycle data have been effectively managed. However, these data have not been fully utilized in module division, especially for complex machinery products. To solve this problem, a product module mining method for the PLM database is proposed to improve the effect of module division. Firstly, product data are extracted from the PLM database by data extraction algorithm. Then, data normalization and structure logical inspection are used to preprocess the extracted defective data. The preprocessed product data are analyzed and expressed in a matrix for module mining. Finally, the fuzzy c-means clustering (FCM) algorithm is used to generate product modules, which are stored in product module library after module marking and post-processing. The feasibility and effectiveness of the proposed method are verified by a case study of high pressure valve.
J. Cent. South Univ. (2016) 23: 1754-1766
DOI: 10.1007/s11771-016-3229-3
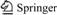
LEI Tiao-yu(雷佻钰), PENG Wei-ping(彭卫平), LEI Jin(雷金), ZHONG Yuan-hua(钟院华),
ZHANG Qiu-hua(张秋华), DOU Jun-hao(窦俊豪)
School of Power and Mechanical Engineering, Wuhan University, Wuhan 430072, China
 Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Central South University Press and Springer-Verlag Berlin Heidelberg 2016
Abstract: Modular technology can effectively support the rapid design of products, and it is one of the key technologies to realize mass customization design. With the application of product lifecycle management (PLM) system in enterprises, the product lifecycle data have been effectively managed. However, these data have not been fully utilized in module division, especially for complex machinery products. To solve this problem, a product module mining method for the PLM database is proposed to improve the effect of module division. Firstly, product data are extracted from the PLM database by data extraction algorithm. Then, data normalization and structure logical inspection are used to preprocess the extracted defective data. The preprocessed product data are analyzed and expressed in a matrix for module mining. Finally, the fuzzy c-means clustering (FCM) algorithm is used to generate product modules, which are stored in product module library after module marking and post-processing. The feasibility and effectiveness of the proposed method are verified by a case study of high pressure valve.
Key words: product design; module division; product module mining; product lifecycle management (PLM) database
1 Introduction
Modular design is an effective way to realize mass customization, which can not only improve the efficiency of product design and development, but also manage product lifecycle data effectively. The basic idea of modular design is to get many products through different options and combinations of a series of standardized, independent and easily variant modules. Modular design includes two processes, i.e., module division and module configuration. Module division is to divide the product into independent standard cells in structure or function from different perspectives according to the division principle. Module division is the foundation of modular design, which directly affects product function, performance, cost, etc. Therefore, it is necessary to take a further study on product module division. On the other hand, with the increasing application of product lifecycle management (PLM) technology, enterprise’s product data grow very fast. Product data contains advanced management ideas and process knowledge. Most of the existing module division methods are based on the process of forward planning, which means that product modules are planned and designed from the source of product development. Hence, the existing product data in PLM database may not be fully used in module division. It is necessary to study how to reuse the existing product data, and it has become a hot issue in many fields how to mine product module and other knowledge from these data.
At present, module division methods have three kinds: the function structure heuristic method, the modular function deployment method and the design structure matrix-based method [1]. In the aspect of the first method, i.e., function structure heuristic method, MCADAMS et al [2] emphasized the importance of product function and structure in modular design. STONE et al [3] proposed a heuristic module creation method to plan modules, which took the energy flow, material flow, signal flow and stress, etc. as the basis. DAHMUS et al [4] processed the module creation in product family variant design using the STONE’s method. BRYANT et al [5] developed a modular design approach based on function structure during the product redesign process. In the aspect of the second method, i.e., modular function deployment method, KRENG and LEE [6] studied two-stage division method on the basis of the quality function deployment, which achieved the goal of module division through modular product analyzing and linear programming. After the analysis of the attributes of product lifecycle, ERICSSON and EKIXON [7] summed up module drivers and used the quality housing to analyze the relationship between customer demand and product design features, and then planed the module form and assembly pattern. The last method, i.e. design structure matrix-based method, is the most common method of modular design, which takes data matrix as the basis. This method could accommodate different optimization techniques and clustering algorithms, such as genetic algorithm, extension theory, simulated annealing algorithm, fuzzy number diagram. GU and SOSALE [8], SAND [9], YU [10] made a thorough study on data matrix. They combined different data matrixes of the features of product functional structure, physical structure, lifecycle features into a data matrix through the normalization process. After that, a clustering algorithm was taken to generate modules. TSENG et al [11], UMEDA et al [12], KRENG and LEE [13] explored the interaction among components and studied the module division for the green and the whole lifecycle, and finally generated the module by genetic algorithm and self-organizing map. SMITH and YEN [14] introduced atomic theory into modular design. Because of the complexity of modern products, the interaction among parts or components becomes ambiguous or difficult to express, thus fuzzy set theory is introduced into the module division and becomes a research hotspot. WANG [15], and LI [16] used the greedy clustering algorithm to cluster product parts or components into modules. QIAN [17] analyzed the similarity and independence of product components from the perspective of environment, and completed module division through the fuzzy graph method. QIAN and ZHANG [18] divided product modules using fuzzy connectedness and fuzzy analytic hierarchy process. NEPAL [19] applied the fuzzy logic model to calculate the performance index of product quality and cost, and evaluated modules finally.
Of these three methods, the first method discusses module forming from a functional point of view. It focuses on the removal or replacement of components while ignores the potential effect from the replacement of internal components and change in the boundary conditions of the module. The second method considers the characteristics of product lifecycle, and it places more emphasis on the management of the theory of modularity, but it has not enough consideration on the interactive relations among parts, so it does not apply in complex product module division. The third method can accommodate different optimization techniques and clustering algorithms. It is easy to be computerized and apply to the module division of complex products. Therefore, a product module mining method is proposed for PLM database in this work, which belongs to the third category. Product structure trees (PST) and bill of materials (BOM) are taken as the data source and extracted from PLM database by the data extraction algorithm. Standardized product data are acquired based on the data cleaning technology (including data normalization based on data dictionary and the structure logic check based on PST and BOM association rules). And then, product modules are generated after the analysis for the standardized product data by FCM algorithm and they are stored in product module library after the steps of module marking and module post- processing. A widely used module division method is taken as a comparison, and the results show that the proposed method is more suitable for engineering practice.
2 Product module mining method
In this section, the framework of the proposed product module mining method for PLM database is outlined, which realizes the goal of product module mining from the enterprise existing product data. The procedure of product module mining is shown in Fig. 1.
The proposed method mainly includes the following three steps: data extraction and integration, product module mining, module marking and post-processing. Data extraction is to extract the required product data (PST and BOM) from the PLM database by a data extraction algorithm. Data integration is to preprocess the extracted defective data using data cleaning technology (including data normalization and structure logical inspection). The purpose of this step is to provide standardized data for product module mining. Then, the FCM algorithm is used to cluster the fuzzy matrix, which is established after the analysis of integrated product data based on the function similarity and structure correlation among parts. As a result, the dynamic clustering tree is obtained, which is the final division of the product module. Module marking is to use a code with sufficient information to uniquely mark a module. Module post- processing includes product structure pruning and module attribute modification. Finally, the product module is stored in the product module library. The details of the three phases are discussed as follows.
2.1 Data extraction and integration
Product data in PLM have some quality defects, such as complex relationship, fuzzy expression, plenty of redundant data. So, it is necessary to extract and integrate the product data before product module mining. Then we can get the product data which is suitable for the module mining algorithm. Data extraction and integration include the steps of data extraction, data normative processing and product structure logical inspection.
2.1.1 Data extraction
The organization form of product data in PLM is a type of hierarchical tree structure. As to this form, there are mainly two kinds of extraction algorithms (bottom-up and top-down) at present. The former one is easily interfered by data source, such as noise data, and ambiguous data, while the latter one requires that each of the underlying data objects must be unique globally. But PLM database does not satisfy these requirements. Therefore, in the study, a new extraction algorithm which is a combination of top-down and bottom-up extraction algorithm is proposed. The course of the algorithm is shown as follows.

Fig. 1 Procedure of product module mining
Product data extraction Algorithm 1:
Input: PLM database
Output: Product data record
Method:
1) Find the specified product root node;
2) Search the main attribute of the root node of the product and storage in the specified division;
3) Repeat;
4) Traverse the adjacent nodes of the root node using the breath-first search algorithm;
5) Search the main attribute of the adjacent nodes and storage in the specified division;
6) Until traverse all product nodes;
7) Assembling extracted product record upward start from the leaf nodes;
8) Until assembling the root node.
2.1.2 Data normalization
There may be some problems in extracted product data, such as the non-uniform naming, inconsistent coding, attribute value lost, noise data, ambiguous data. So, it is necessary to implement data normalization on the basis of PLM data dictionary. Firstly, data with defect are detected and extracted. Then, the data are compared and analyzed with the data dictionary. Lastly, the data is normalized processed. The details of the method are as follows.
1) Consistent processing of product code
Each data object has its own code and conforms to the corresponding coding rules in PLM database. However, due to the difference of designer or department, the coding rules may be inconsistent. According to the organization mode of product data, the code of data objects (product, parts, documents, 2D/3D model, etc) is compared with the code in data dictionary. If the code of the same object is inconsistent, it will be corrected according to the coding standard of data dictionary.
2) Processing of ambiguous data
Ambiguity means uniform in naming of product data object. In other words, the same object has two kinds of expressions. The primary task of this processing stage is checking out ambiguous product data object. An improved neighbor sorting algorithm is used to solve this problem, which could be divided into four following steps.
Step 1: Extract product data objects that need to be detected from PLM database. One object is a record. Field includes product name, structure attribute, function attribute, process attribute, etc.
Step 2: Select sort key field. The key field is the structure attribute, function attribute, process attribute, etc., in PLM database.
Step 3: Sort the entire data set repeatedly to make the ambiguous record as close as possible in physical location.
Step 4: Detect ambiguous record. The method is shown in Fig. 2. Select a fixed window with a size of w. Then, slide the window on the data set from top to down. After that, compare the first record in this window with the rest of the record in the window one by one, and calculate the similarity. If the similarity of two records is greater than a given threshold value, it will be considered that the two records are descriptions of the same object, that is, there is an existence of ambiguity. Detection is completed until the window sliding to the end of the data set. Finally, ambiguous product data object is detected, and it is corrected according to the data dictionary.
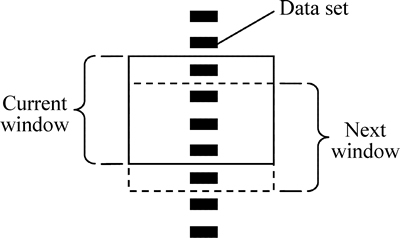
Fig. 2 Window moving in record detection
3) Processing of missing or incorrect attribute data
There is wrong or lost with product data during the process of PLM database entering. A method, integrative application of statistical analysis method, sub box, simple rule base, and the constraint relationship among attributes, is used to solve this problem. The specifics of the method are as follows.
Statistical analysis method: Use the Chebyshev’s inequality to calculate the value range of expectation and standard deviation of product attribute. And judge whether the attribute value is abnormal or incorrect by investigating each attribute value range.
Binning: Attribute value is distributed to a series of equal height or width “box”. Then the averages of the elements in the box are calculated. Missed or abnormal attribute value is replaced by this average.
Simple rule database and the constraint relationship among attributes: For example, the value of attribute a should be two times that of attribute b. If the attribute value is not satisfied with this constraint rule in the actual detection, the value of the attribute is problematic.
2.1.3 Structure logical inspection
This method includes the structural integrity inspection and the correctness inspection of correlation relationship. The field of the parent node in the BOM can clearly describe the relationship among parts. The PST can clearly describe the structure hierarchy relation of a product, and manage all the data related to the product.
This method needs to traverse all the product structure trees to judge whether the structure is complete and the connection among the parts is correct. The breath-first search algorithm is used to traverse PLM database in this work, and these steps of the algorithm are shown as follows.
Breath-first search Algorithm 2:
1. Initializing queue Q;
2. Accessing vertex v; visited[v]=1; Vertex v entering the queue Q;
3. While (Queue Q is not null)
3.1 v= Out of opposite element of queue Q;
3.2 w= The first neighbor contact of vertex v;
3.3 While (w existence)
3.3.1 If w is not accessed, then
Accessing Vertex w; visited[w]=1; Vertex w entering the queue Q;
3.3.2 w= The next contact of the vertex v.
The goal of structural integrity inspection is to judge whether the product parts are complete by traversing all nodes of PST. The structure of one product is complete if all parts and components in BOM can be searched from PLM database; Otherwise, the structure is not complete. The correctness inspection of correlation relationship is to judge whether the relationship between parts is correct. The product logic connection is correct if the connection between all parts of the product is consistent with the PST; otherwise, it is necessary to be corrected.
2.2 Product module mining
The module mining process is shown in Fig. 3.
The first step is to initialize the basic parameters, which includes two processes, i.e., functional similarity analysis and structure correlation analysis. Then, fuzzy correlation matrix is generated according to the analysis results. After that, fuzzy equivalent matrix is built using the fuzzy equivalent transformation rules. Finally a certain level of threshold is selected to classify the parts, and the result is a dynamic clustering tree, which is the final module division scheme. The division process consists of the following three steps.
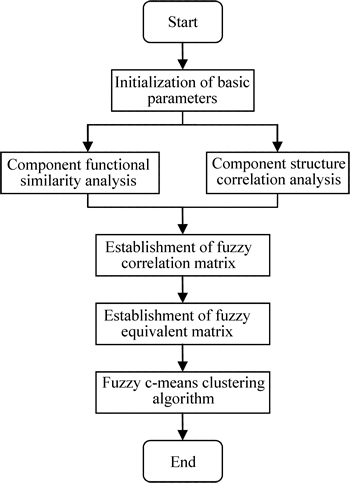
Fig. 3 Process of module division by FCM algorithm
1) Fuzzy correlation matrix
The first step of this process is correlation degree analysis about parts and components before module division. Parts or components should be classified into one module if the value of correlation degree is large. It assumed that the parts with high value of correlation degree will frequently appear in the product configuration. In order to quantitatively describe the correlation degree, the eigenvalue of parts or components in terms of function index and physical index should be considered. Function index, mainly investigating the function correlation of parts and components, can improve the functional independence of module if the parts or components which achieve the same function are gathered together to form one module. Physical index mainly investigates the connection among parts or components. For example, riveted parts and weldment should be gathered together to form a module in actual module division. In order for easy calculation, Table 1 gives a quantitative definition of different correlation degrees. The correlation degree between parts themselves is defined as 1.
The equation for calculating the correlation degree between parts i and j is expressed as
 (1)
(1)
where af(i, j) is function correlation; ap(i, j) is physical correlation; wf is the weight value of the function correlation; wp is the weight value of the physical correlation. Weights are determined by expert evaluation or analytic hierarchy process.
Fuzzy correlation matrix can be generated by Eq. (1), and the correlation matrix is a symmetric matrix as follows:
 (2)
(2)
where 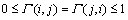 (i, j=1, 2, …, n).
(i, j=1, 2, …, n).
2) Fuzzy equivalent matrix
Usually fuzzy correlation matrix only has the characteristics of symmetry and reflexivity, but not transitivity, thus it can not be processed by the FCM algorithm. Therefore, fuzzy correlation matrix needs to be transformed to obtain a fuzzy equivalent matrix, which satisfies transitivity and the FCM algorithm can be used to divide product module. The transitive closure of fuzzy correlation matrix is the minimum equivalent matrix of Γ. The calculation method of the transitive closure Γ t is as follows.
Table 1 Definition of correlation degree
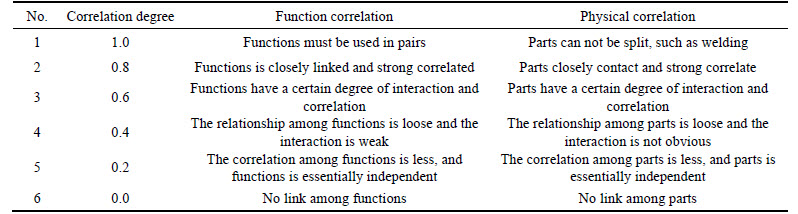
For Eq. (2), there is a natural number 
 to make Eq. (3) tenable, which is as follows:
to make Eq. (3) tenable, which is as follows:
 (3)
(3)
where  is the transitive closure of
is the transitive closure of 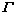 , namely, the minimal fuzzy equivalent matrix. In Eq. (3), “ o ” represents Zadeh operator
, namely, the minimal fuzzy equivalent matrix. In Eq. (3), “ o ” represents Zadeh operator 
When using the least-square method to calculate the transitive closure of Γ, if there is k to make:
 (4)
(4)
Then,
 (5)
(5)
3) Selecting the threshold t and generating the module by FCM algorithm
The FCM algorithm [20] can not only overcome the problem of complex relationship and fuzzy expression among parts in PLM database, but also process large database and multi-dimensional data quickly and effectively. In addition, it is easy to be realized by computer. Therefore, the FCM algorithm is used to mine product module in this work.
After obtaining the fuzzy equivalent matrix, the FCM algorithm is used to generate product module according to the threshold t, which is determined by experience or expert scoring. The FCM algorithm attempts to divide the n vectors i.e., Xi, (i=1, 2, …, n) into m fuzzy groups, and each vector represents a part or component. Then, the cluster center cj of each group is calculated to minimize the value of objective function. Each element uij of membership matrix U tells the degree to which vector Xi belongs to cluster cj. The value of every element in matrix U is between 0 and 1, and the sum of the membership degrees is 1 after the normalization, i.e.,
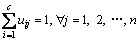 (6)
(6)
The objective function of FCM algorithm is given by
 (7)
(7)
where uij is the membership degree of Xi in group j; ci is the cluster center of fuzzy group i; dij=||ci-Xj|| is the Euclidean distance of between cluster center i and data point j; 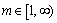 is a weighted index.
is a weighted index.
The new objective function is constructed, and the necessary condition of minimizing Eq. (7) is given by

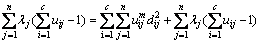 (8)
(8)
where λj (j=1, …, n) is the Lagrange multiplier of n constraint equations in Eq. (6).
The equation of membership degree and cluster center can be obtained after calculating the derivative of input parameters in Eq. (8) as follows:
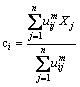 (9)
(9)
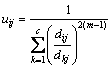 (10)
(10)
The clustering for the fuzzy equivalent matrix using FCM algorithm consists of the four steps:
Step 1: Initialization of membership matrix U with random numbers between 0 and 1 to satisfy the constraint conditions in Eq. (6).
Step 2: Calculation of every cluster center ci using Eq. (9).
Step 3: Calculation of objective function using Eq. (7). If its value is less than the given threshold, or it is less than a threshold value for the change of the previous objective function value, then stop.
Step 4: Recalculation of membership matrix U using Eq. (10) and return to Step 2.
After the above steps, dynamic clustering result is obtained, which is the final division of the product module.
2.3 Product module marking and post-processing
2.3.1 Product module marking
The product modules after mining need to be stored in product module library and product structure library. Therefore, it needs to mark these modules in storage. Besides, the rationality of module marking has important impact on module management, module choice and module combination. Module marking is to use a code with sufficient information to uniquely mark a module and the main purpose of it is to make the definition and expression of module information digitalization and standardization. The principles must be followed in module marking.
1) Uniqueness: An identification number must uniquely represent a module.
2) Integrity: All information contained in a module must be expressed as fully as possible through module marking.
3) Easiness to process: It would be better if the modules are easy to be recognized and processed by computer.
4) Conciseness: The identification number should be as few as possible under the premise of meeting the need.
5) Inheritance: The actual situation of enterprise production should be considered in coding operation, and it would be better to minimize the change of product code, drawing number and other enterprise standard caused by module coding.
2.3.2 Product module post-processing
1) Product structure pruning
This process is to merge part nodes and use module node to replace the merged nodes. And the relationship among parts code or component code will change after this process. For example in Fig. 4, the Component 3 includes Part 3-1, Part 3-2 and Part 3-3, which will be replaced by Module 1 if they are taken as a whole in the pruning. In actual operation, the pruning of product structure is realized by changing the product master configuration list in database. It is needed to specify that the modules in Fig. 4 are obtained by the mining algorithm in Section 2.2. The nodes of the module always appear together, so they can be replaced by one module.
2) Module attribute modification
Product modules are made up of parts and components, so they inherit the attribute of these parts and components. It needs to build module attribute table (including module code, module name, module serial number, module main attribute and other parameters) after parts and components are replaced by modules. The module serial number in module attribute table is directly composed by parts serial number, which directly reflects the composition of the module.
The product module will be stored in product module library after the completion of the above work.
3 Case study
Gate valve (200Z541H25-00) of a high pressure valve factory is taken as an example in the work to verify the proposed method. Figure 5 shows a product structure diagram of the gate valve, and it shows that the gate valve includes valve body, valve stem, wedge disc, valve cover, valve stem nut, bracket, hand wheel, packing seat, packing gland and other parts.
Relevant product data information of gate valve from the PLM database is extracted firstly. After a normalized processing and product structure logical inspection, the standardized product data are obtained. Then, on the basis of Table 2, the function and structure of gate valve are analyzed and matrices are established according to the relationship among parts of gate valve in database. After that, the FCM algorithm is used to mine the product modules. Finally, the product modules are stored in module library after the module marking and post-processing.
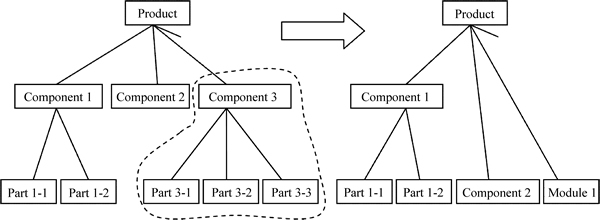
Fig. 4 Pruning of product structure
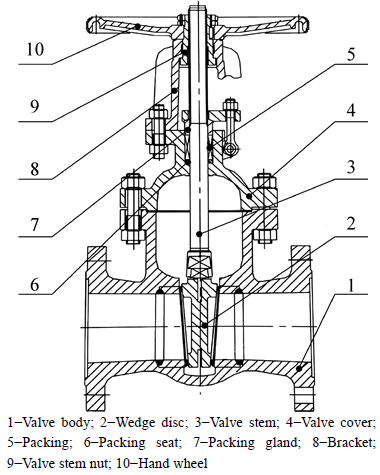
Fig. 5 Schematic diagram of valve structure (200Z541H25-00):
1) Data extraction and integration
Table 2 lists the BOM of valve (200Z541H25-00). It records the composition of the vale and relevant attribute of the parts in detail, and clearly describes the correlative relationship among parts by the field of parent node. Figure 6 shows the PST of valve (200Z541H25-00). The graph describes the hierarchical relation of the valve structure, and manages all data information related to the product.
According to the above method in Section 2.1, the standardized product data are obtained after the process of data extraction and integration. Firstly, relevant product data of gate valve are extracted from valve PLM database by the data extraction Algorithm 1. Then, according to the organization mode of product data, the code of data objects (parts, documents, 2D/3D model, etc.) is compared with the code in data dictionary in consistent processing. If the code of the same object is inconsistent, it will be corrected according to the coding standard of data dictionary. These data objects are detected by the improved neighbor sorting algorithm mentioned in Section 2.1, and the ambiguous data are corrected according to data dictionary. Finally, these methods (statistical analysis method, binning, simple rule base and the constraint relationship among attributes) are used to process the missed or wrong product data.
Table 2 Gate valve (200Z541H25-00) BOM
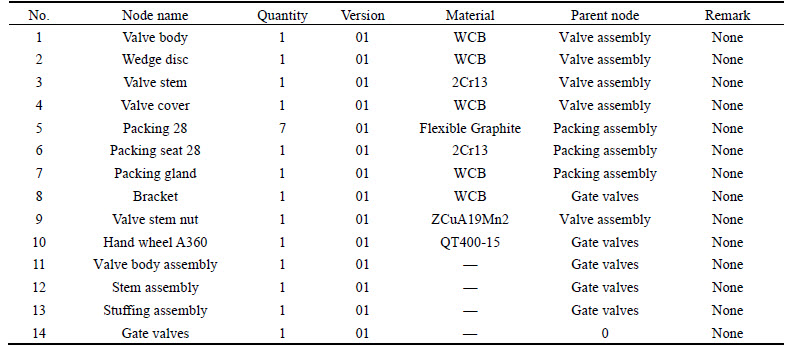
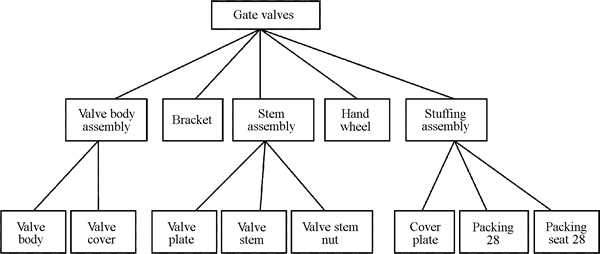
Fig. 6 PST of gate valves
The breath-first search algorithm is used to traverse the valve PLM database. If it can be searched for all parts in the BOM, the gate valve structure is complete; otherwise incomplete. Then, the correlation relationship of valve parts is checked according to the nodes connection relation in the PST. If the correlation relationship is inconsistent, it needs to be corrected. Finally, the integrated valve product data will be stored into the standard database.
2) Analysis of function correlation degree and physical correlation degree
According to the definition of parts function correlation and physical correlation, the function relationship, structure composition relationship, process, application rules and other valve parts data contained in standard database are analyzed as shown in Table 1. The purpose of this analysis is to get the function correlation matrix and structure correlation matrix, which are listed in Tables 3 and 4.
3) Calculation of correlation degree among all parts
The correlation degree among parts is calculated by Eq. (1). The weight of function correlation degree is 0.45, and the weight of physical correlation degree is 0.55 according to the expert evaluation. The results of the calculation are shown in Table 5 and converted to .csv file format.
4) Module division of valve product
The correlation matrix obtained by the previous step not only satisfies symmetry and reflexivity, but also satisfies transitivity, so it is a fuzzy equivalent matrix. Then, the FCM algorithm is applied to analyze this matrix and the final result of module division could be obtained. The FCM algorithm is inserted to the data mining software, Weka 3.6, to complete the work of valve module division, and the final results are shown in Fig. 7.
From Fig. 7, it can be seen that the clustering results will be different if the value of threshold t is different. The gate valve (200Z541H25-00) could be divided into five modules when the value of t is 0.71, and they are valve body assembly module, bracket module, valve stem assembly module, hand wheel module and packing module. Among them, the valve assembly module is composed of valve body and valve cover; the valve stem assembly module is composed of wedge disc, valve stem and valve stem nut; the packing module is composed of packing gland, packing and packing seat. The result of the algorithm is shown in Fig. 8, and Fig. 9 shows the visual representation of the mining results.
Table 3 Component function correlation matrix
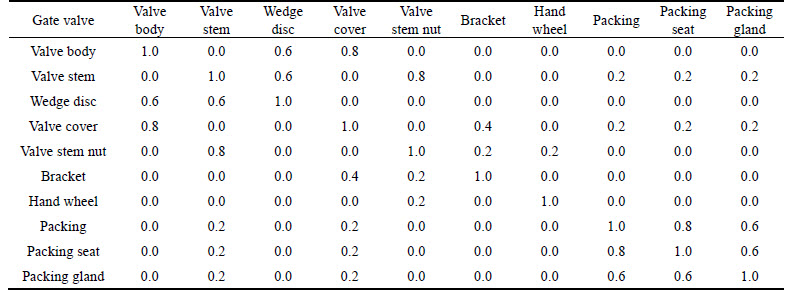
Table 4 Component structure correlation matrix
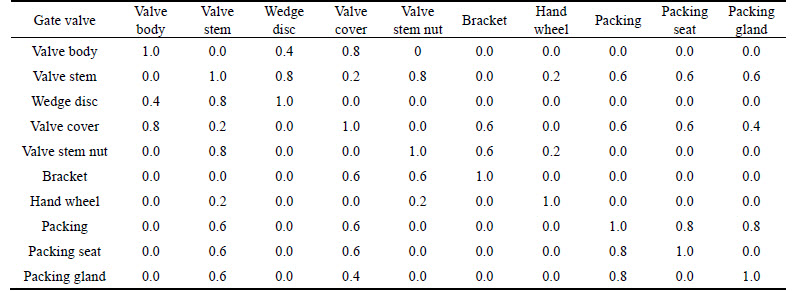
Table 5 Component correlation degree


Fig. 7 Dynamic results of valve module division
5) Comparison and analysis
The module clustering method based on the DSM is a widely used method in product module division. Matrix is used to express the dependency relationship in product development, and parts and components are divided into modules according to the dependency relationship. The bidding evaluation method [21] is a typical module division method based on the DSM, and it is taken to compare with the proposed module mining method. According to Table 6, Table 5 is converted into Table 7 and they are as follows.
The macro tool of MATLAB is used to realize the DSM clustering of valve products according to the research of CHEN and YANG [21], and the result is shown in Fig. 10.
As shown in Fig. 10, the ten parts of the valve product are clustered into four modules (M1-M4). The module M1 is composed of wedge disc and valve body; the module M2 is composed of bracket, valve stem nut and hand wheel; the module M3 is composed of packing gland, packing and packing seat; the module M4 is composed of valve cover and valve stem. Compared with Fig. 7, only module 3 is consistent with the packing module.
Figure 11 shows the module division of gate valve. It can be seen that the DSM-based method places more attention to physical connection in module division, and the effects caused by structure and function are less considered. For example, the Part 1 and Part 2 are divided into one module, which is reasonable in physical connection. However, the level of fitting accuracy among Part 2, Part 3 and Part 9 is very high, and these three parts have the same function (opening and closing the gate). Therefore, the Part 2, Part 3 and Part 9 should be divided into one module from the point of design. Similarly, both of Part 1 and Part 4 are shell parts, and they have close connection, so they should be divided into one module. The connection relation between the valve assembly module (including Part 1 and Part 4) and the valve stem assembly module (including Part 2, Part 3 and Part 9) is determined by the interface parameters. In the aspect of the maximum cycle index, the proposed method is 145(the similarity threshold is 0.71), while the method based on DSM is 155, which is basically the same with the former.
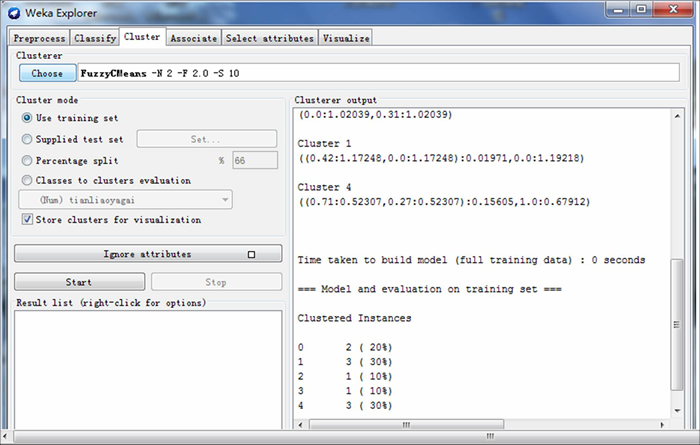
Fig. 8 Results of product module mining
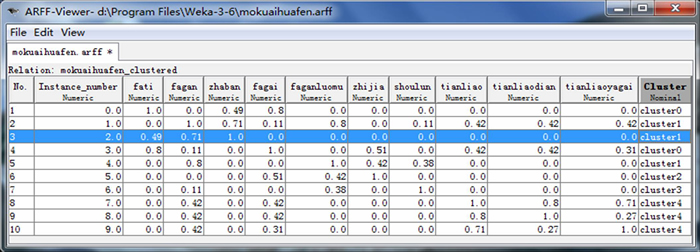
Fig. 9 ARFF format file of results of product module mining
Table 6 Level of dependency relationship
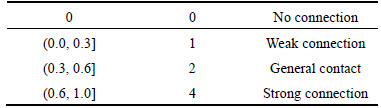
Compared with the general DSM-based module division method, the proposed module mining method combines the connection in structure and function. Besides, the PLM database is taken as the data source, it makes full use of the existing product data. By adjusting the threshold t, designers can get different moduledivision results in different similarity conditions, and the maximum cycle index is basically the same with the existing methods. In addition, this method adds the data preprocessing function, which can effectively deal with the defective product data. Experimental comparison shows that the results of the proposed method are more desirable for engineering practice.
Table 7 DSM model of gate valve


Fig. 10 DSM-based clustering model of gate valve
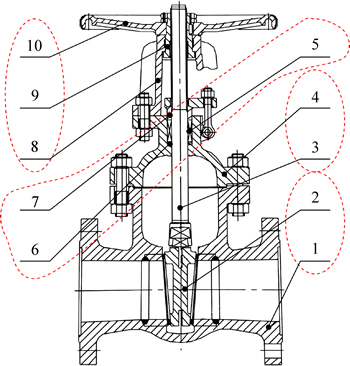
Fig. 11 Module division of gate valve
6) Valve module marking and post-processing
According to the results of module division, each valve product can be divided into transmission module, implementation module, connecting and supporting module. Module coding should describe the basic characteristics of the module and the module coding rules is shown in Fig. 12. For example, the code of FQ02C01 represents the first drive module category of the Jacket type eccentric hemispherical valve, and it is named as the worm gear drive module.
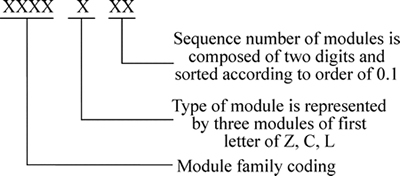
Fig. 12 Module marking rule
In the phase of post-processing, the merged part nodes are replaced by module node in the product master configuration list. At the same time, valve module attribute table is built, which includes module code, module name, module serial number, module main attribute and other parameters. Among them, the module serial number is directly composed of parts serial number.
4 Conclusions
1) The preprocessing for source data has been completed through data extraction and integration. The result shows that the proposed data extraction algorithm can be applied for the PLM database. In addition, the data normalized processing and structure logical inspection can overcome some problems in PLM database, such as non-uniform naming, inconsistent coding, attribute value lost, ambiguous data, structure not integral and correlation not correct.
2) Product modules are generated from the preprocessed product data after the step of product module mining using the FCM algorithm. The method takes BOM and PST as the data source, so it makes full use of the existing product data. The FCM algorithm not only overcomes complex relationship and fuzzy expression among parts, but provides a new method for module division. The mining result shows that the method can be applied to the module division for complex mechanical products.
3) The feasibility and effectiveness of the proposed method are verified by a case study of high pressure valve. The general DSM-based module division method is taken as an experimental comparison, and the results show that the proposed method is more practical and efficient. In addition, the proposed method can deal with the problems of complex relationship in the data source, vague expressions and data quality defects. It also makes full use of the existing enterprise product data information and it’s beneficial to mine the implicit design knowledge and technological process. This method can be applied to the design of complex products, and the mining results provide a basis for the development of mass customization product design platform.
References
[1] CHUNG W H, KREMER G E O, WYSK R A. A modular design approach to improve product life cycle performance based on the optimization of a closed-loop supply chain [J]. Journal of Mechanical Design, 2013, 136(2): 165-173.
[2] MCADAMS D A, STONE R B, WOOD K L. Functional interdependence and product similarity based on customer needs [J]. Research in Engineering Design, 1999, 11(1): 1-19.
[3] STONE R B, WOOD K L, CRAWFORD R H. A heuristic method for identifying modules for product architectures [J]. Design Studies, 2000, 21: 5-31.
[4] DAHMUS J B, GONZALEZ-ZUGASTI J P, OTTO K N. Modular product architecture [J]. Design Studies, 2001, 22(5): 409-424.
[5] Bryant C R, Sivaramakrishnan K L, van WIE M, STONE R B, MCADAMS D A. A modular design approach to support sustainable design [C]// ASME 2004 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference. Salt Lake City: American Society of Mechanical Engineers, 2004: 909-918.
[6] Kreng V B, Lee T P. QFD-based modular product design with linear integer programming―A case study [J]. Journal of Engineering Design, 2004, 15(3): 261-284.
[7] Ericsson A, Erixon G. Controlling design variants: Modular product platforms [M]. New York: ASME Press, 1999.
[8] GU P, SOSALE S. Product modularization for life engineering [J]. Computer Integrated Manufacturing, 1999, 15(5): 387-401.
[9] Sand J C, Gu P, Watson G. HOME: House of modular enhancement-tool for modular product redesign [J]. Concurrent Engineering Research & Applications, 2002, 10(2): 153-164.
[10] Yu Sui-ran, Yang Qing-yan, Tao Jing, TIAN Xia, YIN Feng-yu. Product modular design incorporating life cycle issues-Group genetic algorithm (GGA) based method [J]. Journal of Cleaner Production, 2011, 19(9): 1016-1032.
[11] Tseng H E, Chang C C, Li J D. Modular design to support green life-cycle engineering [J]. Expert Systems with Applications, 2008, 34(4): 2524-2537.
[12] Umeda Y, Fukushige S, Tonoike K, KONDOH S. Product modularity for life cycle design [J]. CIRP Annals - Manufacturing Technology, 2008, 57(1): 13-16.
[13] Kreng V B, Lee T P. Modular product design with grouping genetic algorithm―A case study [J]. Computers & Industrial Engineering, 2004, 46(3): 443-460.
[14] Smith S, Yen C C. Green product design through product modularization using atomic theory [J]. Robotics and Computer- Integrated Manufacturing, 2010, 26: 790-798.
[15] WANG Hai-jun, ZHANG Qiang, YUE Tong-qi. Process analysis in the generation of product modularization based on fuzzy cluster [C]// Proceedings of 8th International Conference on Computer Supported Cooperative Work in Design-Processing. Xiamen: IEEE, 2004: 521-525.
[16] LI Jian-zhi, ZHANG Hong-chao, GONZALEZ M A, YU S. A multi-objective fuzzy graph approach for modular formulation considering end-of-life issues [J]. International Journal of Production Research, 2008, 46(14): 4011-4033.
[17] QIAN Xue-qing. Environment analysis model for modular design of electromechanical products [D]. Lubbock: Texas Tech University, 2003.
[18] QIAN Xue-qing, ZHANG Hong-chao. Design for environment: An environmentally conscious analysis model for modular design [J]. IEEE Transactions on Electronics Packaging Manufacturing, 2009, 32(3): 164-175.
[19] Nepal B, Monplaisir L, Sing N. A methodology for integrating design for quality in modular product design [J]. Journal of Engineering Design, 2007, 17(5): 387-409.
[20] ZHOU De-xin, LI Wei. Research method of circuit fault diagnosis based on FCM [J]. Journal of Central South University, 2009, 40(suppl 1): 290-294.
[21] CHEN Pin, YANG Wen-yu. Modular clustering of complex product structure and quantity of design iteration calculation [J]. China Mechanical Engineering, 2007, 18(11): 1346-1349.
(Edited by YANG Hua)
Foundation item: Project(51275362) supported by the National Natural Science Foundation of China; Project(2013M542055) supported by China Postdoctoral Science Foundation Funded
Received date: 2015-07-29; Accepted date: 2015-11-04
Corresponding author: LEI Jin, PhD, Lecturer; Tel: +86-13100642010; E-mail: jinlei@whu.edu.cn

