�쳣���ϵͳ��©������
���DZ�1, 2��������1
(1. ���ϴ�ѧ ��Ϣ��ѧ�빤��ѧԺ������ ��ɳ��410083��
2. ������ѧԺ �ִ������������ģ����� ��ɳ��410205)
ժ Ҫ���������ѡ���㷨���ɵ��쳣���ϵͳ���ڴ���©�������⣬���һ���ܹ�̽��ϵͳȫ��©���ķǼ��ģʽ©��̽���㷨(EHANDP)�����ȣ�ָ��Ŀǰ���ϵͳ©��̽���㷨(EHASP)�IJ��걸�ԣ�Ȼ����������ռ��еĴ�ģʽ֤���ռ��и����Ϊ©���ij�ֱ�Ҫ�����������̽��ϵͳ©�����걸���㷨EHANDP���ܹ��ҳ�����ϵͳ��ȫ��©���Ǹ��㷨����Ҫ�ص㡣ʵ���в���������ݼ����˹����ݼ��Ƚ�2��©��̽���㷨���о��������������ͬ��ʵ�黷���£�EHANDP�㷨��EHASP��Ȳ�������ͬ�ļ��㸴�Ӷȣ������и�ǿ��̽��������
�ؼ��ʣ��˹�����ϵͳ������ѡ���㷨��©�����쳣���
��ͼ����ţ�TP311 ���ױ�ʶ�룺A ���±�ţ�1672-7207(2009)04-0986-07
Properties assessments of holes in anomaly detection systems
LIU Xing-bao1, 2, CAI Zi-xing1
(1. School of Information Science and Engineering, Central South University, Changsha 410083, China;
2. Center of Modern Education Technology, Hunan Business College, Changsha 410205, China)
Abstract��A novel exploring holes algorithm based on non-detector pattern (EHANDP) was proposed for holes existing in anomaly detection system generated by negative selection algorithm. Incompleteness of current exploring holes algorithm grounded on self pattern (EHASP) was pointed out. And then the sufficient and necessary condition for individuals to become holes was proven using the string patterns in problem space, and an exploring holes algorithm named EHANDP which could find all holes of a given detection system was proposed. The above two algorithms were compared using random dataset and artificial dataset. The results show that the exploring capability of EHANDP algorithm is greater than that of EHASP although they have the same computational complexity.
Key words: artificial immune systems; negative selection algorithm; hole; anomaly detection
�˹�����ϵͳ��������ѧ������ģ����������ϵͳ���ܡ�ԭ����ģ��������������������Ӧϵͳ�����о��ɹ��漰�������ȫ�������Ż��������ھ��ơ�������ϵ����������Ѿ���Ϊ�������硢ģ�����ͽ���������˹����ܵ���һ�о��ȵ�[1]���ڸ�������ϵͳ�����о���֧�У�����ѡ��¡ѡ������������ǹ�ע����ߵ�3���о���֧[2-3]��
����ѡ������ܹ�ȷ������������塢��������ϵͳ��������ת��������ϵͳ����Ҫ����[4]��Forrest��[5]����������ѡ���㷨��ܣ����ɹ�Ӧ�����쳣���ϵͳ��Ŀǰ������ѡ��ԭ����Ϊ�˹�����������о��ȵ�[6]��������Ȼ����ϵͳ��������ѡ���㷨Ϊ�����õ����쳣���ϵͳ�ܹ��ܺõ����֡�����/���塱����ɱ������ݵ�����[5, 7-8]�����ǣ�״̬�ռ��д��ڲ��ܱ����ϵͳʶ������壬��������Ĵ��ڽ�����ϵͳ�ļ�⾫��[9-10]��ͬ��������Ҳ��������������ϵͳ�У��粡ԭ��������©���ķ������������������ϵͳ�ļ���Ѷȡ���������ϵͳ����MHC���������©������[11]���ݴˣ�Hofmeyr[12]������ö��ر�ʾģ����������ϵͳ��MHC���ƣ��Լ���©�����������÷���ʹ��ͬһ��ƥ��������ò�ͬ��ģʽ��ʾ���������ȱ���Ƕ�ϵͳ�ȶ����нϴ�Ӱ�졣�ź� ��[13]��r-����λƥ����Ϊ���������һ��ƥ�䷧ֵ�ɱ������ѡ���㷨�����㷨�ĺ�����ͨ������ƥ����ֵ������©����������û�д������Ϸ���Ӱ��©�������ء�Stibor��[14]�����̽��ϵͳ©�����㷨������ֻ��̽�ϵͳ�IJ���©��������ȫ��©����
©���Ĵ��ڼ����ģȡ�������弯�ϵ�ģʽ�ṹ��ѵ�����弯�������õ�ƥ�����[6]�����ڴˣ����������������弯�ͼ��������״̬�ռ��е����ϵ��Ӧ��ʵ��֤��Stibor©��̽���㷨�IJ��걸�ԣ�Ȼ�����̽����ϵͳ©���ķǼ��ģʽ©��̽���㷨(EHANDP�㷨)��֤�����㷨���걸�ԣ����Ӧ��������ݼ����˹����ݼ���EHANDP�㷨����ȫ����ԣ�ͬʱ����ϵͳ��Ӱ��©����ģ�����ء�
1 ���ⶨ��
������ѡ�������ڣ����ö����Ʊ���[6, 8-9, 12, 14]��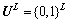 ��ʾ��ΪL�ַ��������ռ䣬S��ʾ����ռ��������ϣ�N��ʾ����ռ��������ϣ�D��ʾ������ռ��������ϡ�����ѡ���㷨�����ڿռ�
��ʾ��ΪL�ַ��������ռ䣬S��ʾ����ռ��������ϣ�N��ʾ����ռ��������ϣ�D��ʾ������ռ��������ϡ�����ѡ���㷨�����ڿռ�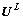 �У�����ij��ƥ����ѵ�����弯��S�����ɼ��������D���Ӷ������������ռ䵽����ռ��ӳ���ϵ��������㷨Ϊ[11]��
�У�����ij��ƥ����ѵ�����弯��S�����ɼ��������D���Ӷ������������ռ䵽����ռ��ӳ���ϵ��������㷨Ϊ[11]��
a. ���屻��������Ϊ����S�����볤��ΪL��
b. ����ƥ����ѵ�����弯�����ɼ��������D��
c. ��D̽�ⱻ������Ϣ�������쳣������Ӧ��
ѵ�����弯�ϲ��õ�ƥ����Լ��ϵͳ�кܴ��Ӱ�죬��ͬ��ƥ����������ͬƥ����IJ�ͬ��ֵr�Լ�����ܵ�Ӱ�춼��һ����r-����λƥ����(r-contiguous bits matching)��r-��ƥ����(r-chuck matching rule)������ƥ����(Hamming matching rule)���������Ŀǰʹ��������[6]�����ǣ�����Ӧ�ú��������ɵļ��ϵͳ������©��[14]����Щ©�����ܱ����ϵͳʶ�����ǵĴ��ڽ�����ϵͳ�ļ���ʣ�������ϵͳ�IJ���ȫ���أ���ˣ������о�©�������ʶ�����쳣���ϵͳ�İ�ȫ����Ϊ��Ҫ��Ϊ�˷��㣬�������¶��塣
����1 ��ΪL�������ַ���X=x1x2��xL��Y=y1y2��yL����r-����λƥ�䣬���ҽ���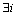 ��
�� ��ʹ��
��ʹ�� j=i, i+1, ��, i+r-1����X�dz�ΪL�Ķ�����������Y�Ƕ�����m��L�������������t(1��t��m)��i(1��i��L-r+1)������xj=Y(t, j)�����У�j=i, ��, i+r-1��
j=i, i+1, ��, i+r-1����X�dz�ΪL�Ķ�����������Y�Ƕ�����m��L�������������t(1��t��m)��i(1��i��L-r+1)������xj=Y(t, j)�����У�j=i, ��, i+r-1��
����2 �輯��D�����弯��SӦ��r-����λƥ�����ɵļ������������x��������������D�е��κθ���ƥ�䣬��x�������ϵͳ��©����
������ռ������弯�������弯�ϵı�Եͨ���Dz�����ģ�����©����������Ҫԭ��������s1��s2�ֱ����£�
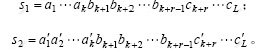
����s1��s2���������h1��h2��

����r-����λƥ����h1��h2�����ܱ�ϵͳ�е���������ʶ�𣬼�h1��h2��Ϊϵͳ��©����
�����弯��������ʽ��
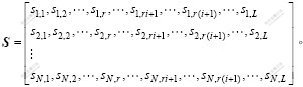
����r-����λƥ�佫��ֽ�ΪL-r+1��ģʽ����
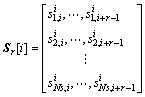 ��
��
���У�i=1, 2, ��, L-r+1��rΪģʽ�����и���ij��ȣ�iΪģʽ���ϵIJ�Σ�NsΪS���ϵĹ�ģ���������L-r+1��ģʽ����Ϊ������Stibor��[14]������ϵͳ©��̽���㷨(EHASP�㷨)��
�����弯��S={10010��11010��01101��00110}��ȡƥ�䷧ֵr=3��EHASP����©���Ĺ�����ͼ1��ʾ��
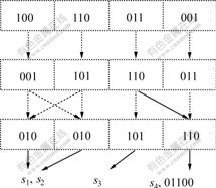
ͼ1 ©�������ɹ���
Fig.1 Process of generating holes
��ͼ1���Կ�����©�����������弯��������أ������ڽṹ�ϴ�����ͬ��ģʽ��ʵ���ϣ����ϵͳ�Ƿ����©��ȡ��������ģʽ���ϵ��ڲ��ṹ�����ɼ��ϵͳʹ�õ�ƥ��������ģʽ�ڲ��ṹ���ƶ�Խ�ߣ�ƥ������ԽС��©������Ŀ��Խ�ࡣ
2 ©������
2.1 ���ڷǼ�⼯ģʽ��©��̽���㷨
Stibor[14]���̽����ϵͳ©����̽���㷨���ĸ��嶼��ϵͳ��©������û��˵�����㷨���ɵļ����Ƿ�����˼��ϵͳ��ȫ��©����ͨ������1��ʾ������֤����EHASP�㷨�ǿռ�����Ϊ©���ı�Ҫ���dz��������
����1 ������ģʽ��Ϊ������Ӧ��EHASP̽��ĸ�����Ǽ��ϵͳ��©����
֤�� ��Lά�����ռ��У����ϵͳ�����弯��Sͨ��r-����λƥ�����ɼ��������D��H��EHASPͨ�����弯��S�õ���©�����ϡ�����H�д��ڸ���x�ܱ�D������D�����ٴ���1�����������d��x����r-����λƥ�䣬������i(1��i��L-r+1)����dj=aj��j=i, ��, i+r-1������x�������㷨��x��ȫ����Ϊr��ģʽ����������Ӧ��ε�����ģʽ�����������弯��S�д�������s��d����r-����λƥ�䣬������d�Ǽ����ì�ܡ�
����1˵����������ģʽ����Ϊ������Ӧ��EHASP̽��ĸ��嶼�Ǽ��ϵͳ��©����ͨ����1֤��EHASP����̽������ϵͳ��ȫ��©����
��1 ��S={110��010}������λƥ�䷧ֵr=2����������λƥ�������ɵļ��������Ϊ��
D={000��001��100��101}��
����EHASP��̽��ļ��ϵͳ©������H=?�����ǣ�����h=011���ܱ�Dʶ���Ǽ��ϵͳ��©������ˣ�EHASP�����걸��©��̽���㷨��
Ϊ���ܹ�̽����ϵͳ��ȫ��©������ģʽ��Ϊ����Ѱ���걸��©��̽���㷨����EHASP�����弯��SΪ����̽���©������H���䳤Ϊr��ģʽ����Ϊ
Hr[i], i=1, 2, ��, L-r+1��
��h��H��h��2��������ģʽ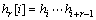 ��
�� ��Ȼ����
��Ȼ����
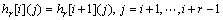 ��
��
Ϊȷ����hr[i]��hr[i+1]֮�������ƥ���ϵ�������µĶ��塣
����3 ��Ϊr���ַ���h1, h2, ��, hn��������ƥ�䣬���ҽ���hi�ĺ�r-1λ��hi+1��ǰr-1λ��Ӧ��ȣ�i=1, 2, ��, r-1������1, h2, ��, hn>��
����4 ��hi=i1hi2��hir��i=1, ��, n����������ƥ�䣬��ô��h1, h2, ��, hn��ϵõ��ij�Ϊr+n-1����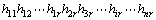 ��������ƥ�䴮������
��������ƥ�䴮������

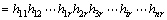 ��
��
�ӿռ�ṹ�Ͽ������弯�ϡ������������©�����ϵĵ�i��(i��{1, 2, ��, L-r+1})ģʽ��Sr[i]��Dr[i]��Hr[i]������Ur�ռ��е��������ϡ���
Cr[i]=Ur-Dr[i]��
��ô��
 ��
��
�����ⳤΪr������p?Cr[i]����������������ģʽ����©��ģʽ�����濼��Cr[1]��Cr[2]������Cr[L-r+1]���ݽ���ƥ��ԭ�����ɵij�ΪL�ĸ�����е����ʡ�
����2 D�����弯��S����r-����λƥ�������ɵļ�������ϣ�Ur��rά�����ռ䣬Dr[i]�Ǽ����D�ĵ�i��ģʽ���ϣ�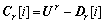 ����
���� ϵ��ģʽ���ϸ�������ƥ��ԭ�����ɵĸ��峤ΪL�ļ��ϼ���SH����H=SH-S�Ǽ��ϵͳ��©����������H�����˼��ϵͳ��ȫ��©����
ϵ��ģʽ���ϸ�������ƥ��ԭ�����ɵĸ��峤ΪL�ļ��ϼ���SH����H=SH-S�Ǽ��ϵͳ��©����������H�����˼��ϵͳ��ȫ��©����
֤�� ��H��Cr[1]��Cr[2]������Cr[L-r+1]��������ƥ��ԭ�����ɵij�ΪL�ĸ��弯�ϡ��������h��H����h�ܱ������Dʶ����D�����ٴ���1�����������d��h����r-����λƥ�䣬Ҳ����˵������������i(1��i��L-r+1)��ʹ��
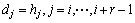 ��
��
��
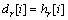 ��
��
����
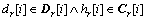 ��
��
���ǣ�
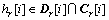 ��
��
���� ��ì�ܡ�Ҳ����˵�������D���ܼ�H�е�������壬��H�ַ����弯�ϣ����ԣ�H�Ǽ��ϵͳ��©�����ϡ�
��ì�ܡ�Ҳ����˵�������D���ܼ�H�е�������壬��H�ַ����弯�ϣ����ԣ�H�Ǽ��ϵͳ��©�����ϡ�
��һ���棬�����ϵͳ�д���©��a���� ����a�д��ڳ�Ϊr��ģʽ������Cr[i], i=1, ��, L-r+1���������ģʽΪa�ĵ�i��ģʽar[i]����������ô
����a�д��ڳ�Ϊr��ģʽ������Cr[i], i=1, ��, L-r+1���������ģʽΪa�ĵ�i��ģʽar[i]����������ô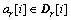 ��Ҳ����˵��D�����ٴ���1�����������d�����i��ģʽdr[i]=ar[i]����
��Ҳ����˵��D�����ٴ���1�����������d�����i��ģʽdr[i]=ar[i]����
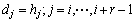 ��
��
���ǣ�d��a����r-����λƥ�䣬a�ܹ��������Dʶ������a��©���ļ�����ì�ܣ���H�а����˼��ϵͳ��ȫ��©����
����2��������Cr[i], i=1, ��, L-r+1Ϊ��������������ƥ��ԭ��̽���H�����Ǽ��ϵͳ��©�����ϣ����Ұ����˼��ϵͳ��ȫ��©����̽����ϵͳ©���ľ���������£�
a. ѵ�����弯��S���õ��ϸ�ļ��������D��
b. ����r-����λƥ����D�ֽ�Ϊ���峤Ϊr��L-r+1��ģʽ���ϣ�Dr[1], Dr[2], ��, Dr[L-r+1]��
c. ��rά״̬�ռ�Ur�����Dr[i]�Ļ���ģʽ����Cr[i]=Ur-Dr[i], i=1, 2, ��, L-r+1��
d. i=1����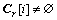 ��ȡ
��ȡ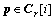 ������
������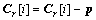 ��
��
e. ��i+1��ģʽ�����У��ҳ���p����ƥ���ģʽ�ṹ�����ò�ģʽ������û��ģʽ��p����ƥ�䣬�ز���c��
���ò�ģʽ������ֻ��1��ģʽx��p����ƥ�䣬��x��ĩβԪ������p��ĩβ��i=i+1��ת������d��
���ò�ģʽ��������x1��x2 2��ģʽ��p����ƥ�䣬��x1��ĩβԪ������p��ĩβ����Ϊp1�� ��x2ĩβԪ������p��ĩβ����Ϊp2����i=i+1��ת������e��
f. ��i=L-r+2���������ɵġ�����ΪL���ַ������뼯��Hole_ND�С�
g. ȥ������Hole_ND�к����弯��S�ظ���Ԫ�أ��õ�©������H��
��2�����˵����©��̽���㷨EHANDP̽����ϵͳ©���Ĺ��̡�
��2 �����弯��S = {01001, 00001, 10100, 11101}�������弯��S�����㷨EHASP̽���ϵͳ©������Ϊ��
H1= {10101, 11100}��
����r����λƥ�������ɵļ��������DΪ��
D= {00110, 00111, 01110, 01111, 10010, 10011, 11010, 11011}��
D�ij�Ϊr��ģʽ���ֱ�Ϊ��
D3[1]={001,011,100,110};
D3[2]={010,011,111,001,101};
D3[3]={110,111,011,010}��
D3[1]��D3[2]��D3[3]��U3�����ռ�����Ӧ�IJ�ģʽ���ֱ�Ϊ��
C3[1]={000,010,101,111};
C3[2]={000,100,110};
C3[3]={000,001,100,101}��
C3[1]��C3[2]��C3[3]����EHANDP�㷨�õ���©������Ϊ��
H2 = {00000, 01000, 10101, 11100}��
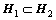 �������㷨EHANDP��EHASP�и�ǿ��̽��������
�������㷨EHANDP��EHASP�и�ǿ��̽��������
2.2 ���㸴���Է���
���ȿ����㷨EHASP���������ģʽ��ֻ��2�㼴L-r=1��������ӵ�1ģʽ����Sr[1]��ȡ1������p����p��ӡ�0������p0��ȡ���rλ���õ�tp0����p��ĩβ�ӡ�1������p1��ȡ���rλ���õ�tp1���ڵ�2����������tp0������tp1��ͬ�ĸ��塣��tp0����tp1����1�������弯�ϵ��Ӵ�������Ҫ���ң���ˣ������������㷨ƽ��ʱ��ķ�ΪNs/2������������£�ÿһ�㶼ƥ��ɹ���Ҳ����˵����2��ƥ�������õ�2�����壬��������ΪNs/2����3��ƥ�������õ�22�����壬��������Ϊ2��Ns/2����L-r+1��ƥ��ڽ�����õ�2L-r-1�����壬��������Ϊ2L-r-1��Ns/2����1�㹲��Ns�����壬���ԣ��㷨�ܵ�ƥ�����Ϊ��
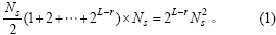
����õ�����¾���ϵͳ�в�����©�����㷨�ڵ�2��ģʽƥ�������õ�1�����壬��������ΪNs/2���ڵ�3��ƥ��������Եõ�1�����壬��������ΪNs����L-r+1��ƥ��ڽ�����õ�1�����壬��������ΪNs/2�����ԣ��㷨�ܵ���������Ϊ��

�����㷨EHANDP��ʱ�临�Ӷȷ�����EHASP�ķ������ƣ����������£����Ӷ�Ϊ��
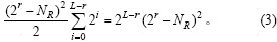
���������£����Ӷ�Ϊ��
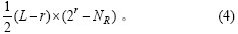
3 ©���㷨�ķ������
��EHASP��EHANDP���з��棬�����Ƚ���ͬ������EHASP��EHANDP����©���Ĺ�ģ��Ȼ����r-����λƥ�䷧ֵ�����弯���ڲ�ģʽ�ṹ��©����ģ��Ӱ�졣
3.1 ���ݲɼ�
Ϊ��ʾ���ݼ��ڲ�ģʽ�ṹ��©����ģ��Ӱ�죬ʵ�����������ݼ����˹����ݼ���ǰ�߲���Mat lab R2007bƽ̨�������˹����ݼ������㽶���ݼ��������ݼ�����400��2��ʵ����ʾ�����ݣ������б�ת����400��16�еĶ����ƾ���
3.2 ʵ�����
3.2.1 2���㷨��©����ģ�Ƚ�
����������ݼ����˹����ݼ�����ģΪNs=400�����峤��L=16��r-����λƥ�䷧ֵΪ9�����2�����ݼ��ֱ�����EHASP��EHANDP������©��H1��H2��ʵ�鲽�����£�
a. �ɼ��˹����ݼ���������ݼ���Ϊ���弯��
b. �����弯��Ϊ����������EHASP����©������H1����h1=# H1����#����ʾ���ϵ��ƣ�
c. ����r����λƥ�������ɼ��������D��
d. �Լ��������DΪ����������EHANDP̽��©������H2����h2=# H2����
e. �ظ�ʵ��100�Σ�ͳ�����ݡ�
ͨ������ʵ�鲽��õ���©����ͳ���������1��ʾ��
��1 ©����ͳ������
Table 1 Statistical properties of holes
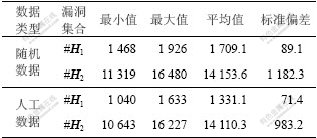
�ӱ�1��֪��2�����ݼ��¶�������100�Σ��㷨EHANDP����©����Զ��EHASP�õ���©�����࣬����ǰ�߱Ⱥ��ߵ�̽������ǿ����ͼ2~4��ʾ��
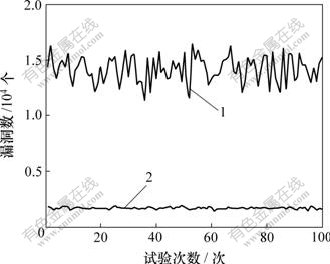
1��EHANDP��2��EHASP
ͼ2 ����������ݼ��õ���©��
Fig.2 Size of hole sets generated using random dataset
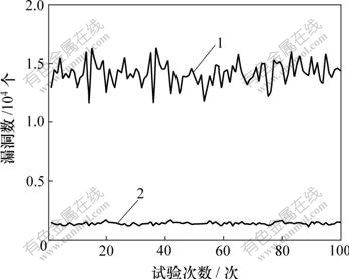
1��EHANDP��2��EHASP
ͼ3 �����˹����ݼ��õ���©��
Fig.3 Size of holes generated through artificial datasets
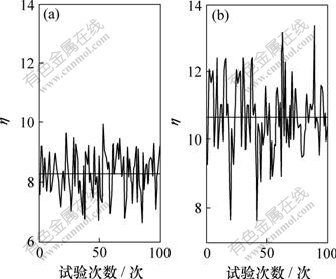
(a) �˹����ݼ���(b) ������ݼ�
ͼ4 �㷨EHASP���㷨EHANDP�ڲ�ͬ���ݼ��µı���
Fig.4 Performance of EHASP and EHANDP based on random and artificial dataset
h1��h2�Ĺ�ϵ��ͼ4��ʾ������ ���ɼ������˹����ݼ��£�h=6.5~10.2����ֵΪ8.3����ʹ��������ݼ�ʱ��h�ı仯�������ӣ�h=7.7~13.4����ֵҲ�ﵽ10.8��
���ɼ������˹����ݼ��£�h=6.5~10.2����ֵΪ8.3����ʹ��������ݼ�ʱ��h�ı仯�������ӣ�h=7.7~13.4����ֵҲ�ﵽ10.8��
3.2.2 ����λƥ�䷧ֵ��©������Ӱ��
����ʵ����������ݼ����˹����ݼ�Ϊ����������ƥ�䷧ֵr��©������Ӱ�졣���弯��ģΪ400��16�У�ƥ�䷧ֵr��6��16������Ϊ1��Ӧ��EHANDP��©�����ϡ���rȡ6��7��16ʱ��ϵͳ©���ӽ���0����r=8ʱ©����࣬��ͼ5��ʾ��
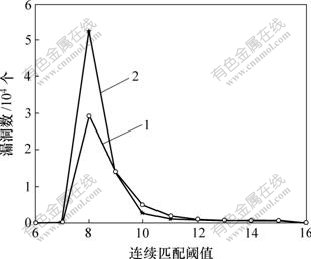
1���˹����ݼ���2��������ݼ�
ͼ5 ƥ�䷧ֵr��ϵͳ©����Ӱ��
Fig.5 Matching threshold on impact of holes
3.2.3 �����ڲ��ṹ�任��©����ģ��Ӱ��
�����弯��400��16�С�r=10ʱ�����������ݼ����˹����ݼ�Ӧ���㷨EHANDP̽��ϵͳ��©������ͼ6�ͱ�2���Կ����˹����ݼ����ɵ�©����������ݼ��õ���©���٣���˵�����弯���ڲ���ģʽ�ṹӰ��©������
��2 ��ͬ���ݼ��µ�ϵͳ©�����Ƚ�
Table 2 Comparison of holes explored in two dataset
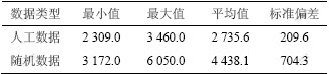
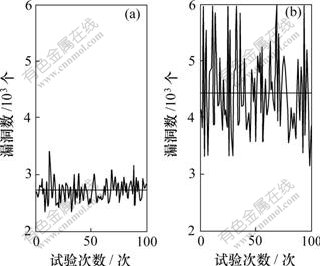
(a) �˹����ݼ���(b) ������ݼ�
ͼ6 ���ݼ���©������Ӱ��
Fig.6 Effect of datasets on holes
3.3 ʵ��������
���弯���ڲ���ģʽ�ṹ��Ӱ��©��������Ҫ���أ�EHASP�����弯���г�Ϊr��ģʽ��Ϊ�������ɼ��ϵͳ��©������H1����H1ֻ�Ǽ��ϵͳ��©�����ϵ�һ���֣�û�а���ȫ����©������������弯Ϊ400������ʱ��EHASP�õ���ƽ��©����1709.1������ͬ��ʵ�黷���£�EHANDP�õ���ƽ��©����Ϊ14 153.6��ԶԶ����ǰ��(��ͼ3��ʾ)�������˹�����Ϊ�����ظ������ʵ��ʱ��EHASP̽���©����Ϊ1 331.1��EHANDP̽��õ���©����Ϊ14 110.3����Ȼ����ǰ��(��ͼ3��ʾ)����ͼ4�ɼ�����������ݼ��õ���ƽ��ֵΪ8.3���˹������µõ���ƽ��ֵΪ10.8����ˣ�EHASP�õ���©������ֻ�Ǽ��ϵͳ©�����ϵ�һС���֣�����ȫ����
��r��7��r=16ʱ��©��������Ϊ0��ǰ������Ϊ�ڸ÷�ֵ�£�ģʽ�ռ���������27=128��ģʽ����Щģʽһ���ֹ����˼�������ϣ��ò��ֶ�©��û�й��ף�״̬�ռ��е�����һ����ģʽ���������弯�ϣ���Щģʽ����Ҫ���ɼ��ϵͳ��©���������㣺��10(L-r+1)��ģʽ�����У����ڲ�ε�ģʽ����������ƥ��ĸ��壻���������屾������2�������dz����̣�ʹ��ģʽ������װ����©������ĸ��ʺ�С����ˣ���r��7ʱ©�������٣���r=16ʱ��ƥ�䷧ֵr������볤��L��ȣ���Ȼģʽ���ϵ�״̬�ռ�ܴ�(216=65 536), ��ģʽ��ֻ��1�㣬��ʹ����ƥ��õ��ĸ��嶼�����壬��ˣ�©��������Ϊ0��ʵ��3�������ģʽ����������̽�ֲ�ͬģʽ����©����Ӱ�졣��Ns=400��L=16��r=10ʱ����������ݼ�Ϊ��������EHANDP�õ���©���ľ�ֵΪ4 438.1�������˹����ݼ�Ϊ�����õ���©���ľ�ֵΪ2 735.6��С��ǰ�ߡ������˹����ݼ���״̬�ռ��е���״���������¡�
4 �� ��
a. ������Stibor©��̽���㷨��֤����̽���㷨ֻ�ܹ�̽����ϵͳ�IJ���©������ʵ��ָ�����㷨����̽����ϵͳ��ȫ��©����
b. ��������λƥ�������弯�ֽ�Ϊ���ģʽ���ϣ�����������ģʽ���ϡ������ģʽ�����ڿռ�ṹ�ϵĹ�ϵ���ݴ˸����˼��ϵͳ©�����ڵij�ֱ�Ҫ������������֤����
c. ����걸��©��̽���㷨���ڲ����Ӽ��㸴���Ե�����£����㷨��̽��������ǿ��
�ο����ף�
[1] Emma H A, Timmis J. Application areas of AIS: The past, the present and the future[J]. Applied Soft Computing, 2008, 8(1): 191-201.
[2] �����, ����, ���ж�. ���������Ŵ��㷨�Ľ�DFNNģ�ͼ���Ӧ��[J]. ���ϴ�ѧѧ��; ��Ȼ��ѧ��, 2008, 39(2): 345-349.
LI Yan-bin, LI Cun-bin, YANG Shang-dong. A new DFNN improved by artificial immune-genetic hybrid algorithm and its application[J]. Journal of Central South University: Science and Technology, 2008, 39(2): 345-349.
[3] Dasgupta D, Zhou J, Gonzalez F, et al. Artificial immune system(A IS) research in the last five years[C]//Proceedings of the 2003 Congress on Evolutionary Computation. Canberra: IEEE, 2003: 123-130.
[4] Garrett S M. How do we evaluate artificial immune systems[J]. Evolutionary Computation, 2005, 13(2): 145-178.
[5] Forrest S, Perelson A S, All L, et al. Self-nonself discrimination in a computer[C]//Proceedings of IEEE Symposium on Research in Security and Privacy, Oakland: IEEE Press, 1994: 202-212
[6] Zhou J, Dasgupta D. Revisiting negative selection algorithms[J]. Evolutionary Computation, 2007, 15(2): 223-251.
[7] Dasgupta D, Gonz��lez F. An immunity-based technique to characterize intrusions in computer networks[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(3): 281-291
[8] Esponda F, Forrest S, Helman P. A formal framework for positive and negative detection schemes[J]. IEEE Transactions on Systems Man and Cybernetics Part B-Cybernetics, 2004, 34(1): 357-373.
[9] D'haeseleer P, Forrest S, Helman P. An immunological approach to change detection: algorithm, analysis and implications[C]// Proc of the IEEE Symposium on Security and Privacy, Los Alamitos: IEEE Computer Society Press, 1996: 132-143.
[10] D'haeseleer P. An immunological approach to change detection: Theoretical results[C]//Proceedings of the 9th IEEE Computer Security Foundations Workshop. IEEE Computer Society Press, 1996: 132-143.
[11] ������. ҽѧ����ѧ[M]. ����: ��������������, 1995.
LONG Zhen-zhou. Medical Immunology[M]. Beijing: People��s Medical Press, 1995.
[12] Hofmeyr S A. An immunological model of distributed detection and it s application to computer security[D]. Albuquerque: Department of Computer Sciences, University of New Mexico, 1999.
[13] �� ��, ����, ��عɭ, ��. һ��r�ɱ为ѡ���㷨����������[J]. �����ѧ��, 2005, 28(10): 1614-1619.
ZHANG Heng, WU Li-fa, ZHANG Yu-sen, et al. An algorithm of r-adjustable negative selection algorithm and its simulation analysis[J]. Chinese Journal of Computers, 2005, 28(10): 1614-1619.
[14] Stibor T, Mohr P, Timmis J. Is negative selection appropriate for anomaly detection[C]//GECCO��05. Washington D. C, 2005: 321-328.
�ո����ڣ�2008-09-05�������ڣ�2008-11-25
������Ŀ��������Ȼ��ѧ����������Ŀ(90820302, 60234030, 60805027)�����һ����о���Ŀ(A1420060159)�����Ҳ�ʿ�����������Ŀ(200805330005)
ͨ�����ߣ����DZ�(1977-)���У�ɽ�������ˣ���ʿ�о�������ʦ�������˹�����ϵͳ���о����绰��13723874826��E-mail: liuxb0608@gmail.com

