����ֵ�ش����������һ�ֲַ�ʽ���ݴ洢�㷨
����1, 2��������1��������2��������1, 2
(1. ���ӿƼ���ѧ �������ѧ�빤��ѧԺ���Ĵ� �ɶ���610054��
2. �й���ѧԺ �ɶ������Ӧ���о������Ĵ� �ɶ���610041)
ժҪ���������ֵ�ش�������������ݴ洢�ɿ������⣬���һ��ʵ�ּ����ܸ�Ч�ķֲ�ʽ�洢�㷨���㷨���ö���������߹��������е�k��Դ���ݰ����ݵ����������е�n���ڵ㣬�����е�ÿ���ڵ㰴һ���ĸ��ʽ���һ���µ����Դ���ݰ����������֮ǰ�洢�Ĵ洢���ݰ��С���ֵʵ��������洢�������֮��ʹ�в��ִ������ڵ���Sink�ڵ�ֻҪ�ռ�������k+�ţ��š�8���洢���ݰ������ܼ����ԭ����k��Դ���ݰ����������������Ļ���LT��ķ�����ȣ����㷨��ʡ�洢�����и��������ڵ�Լ61%��ͨ�ųɱ���ͬʱ����Sink�ڵ�Լ40%�ķ��ʳɱ������нϺõ�Ӧ��DZ�ʡ�
�ؼ��ʣ�����ֵ�ش��������磻���ݴ洢���ֲ�ʽ�洢�㷨���������
��ͼ����ţ�TP211.9��TP393 ���ױ�־�룺A ���±�ţ�1672-7207(2013)12-4894-09
Distributed data storage algorithm for unattended wireless sensor networks
XIAO Yilong1, 2, FANG Mingyu2, WANG Xiaojing2, JIANG Haibo1, 2
(1. School of Computer Science and Engineering,University of Electronic Science and Technology of China, Chengdu 610054, China;
2. Chengdu Institute of Computer Application, Chinese Academy of Sciences, Chengdu 610041, China)
Abstract: To solve the data storage reliability problem of unattended wireless sensor networks (UWSN) which is made of n unreliable nodes (k of them are data nodes used to produce source data packets), a new kind of distributed storage algorithm based on random walk was proposed. According to the proposed algorithm, k source data packets were transmitted to every node in the network based on random walk, and every node received a number of source data packets with the given probability and stored the XOR result of them as a stored data packet. The simulation results show that after the storage process is completed, even with some stored data packets missing, the data collector node can successfully recover the k source data packets from any survival k+��, �š�8 stored data packets. Compared with LT codes based method, this method reduced network��s communication cost by about 61% and the Sink node��s query cost by about 40%.
Key words: unattended wireless sensor networks; data storage; distributed storage algorithm; random walk
����������[1]�ɴ�����ͨ�š����㡢�洢���������Ĵ������ڵ���ɣ�����֪�����㡢����ͨ��Ϊһ�壬ͨ�������������ʵʱ��⣬����û�����Ȥ����Ϣ�������ú;��µ������й㷺��Ӧ�á�������������������Ϊ���ĵ����磬���֪���ݵĴ洢һֱ��ѧ������о��ȵ㣬�����ص��о�����ֵ�ش���������[2]�����ݴ洢���⡣��һ��Ĵ�����������ȣ�����ֵ�ش���������ͨ�������ڶ��ӵĻ����У�Sink�ڵ�(�����ռ��ڵ�)�����̶��������У�����ÿ��һ��ʱ���ų����������в��ռ��������ݽڵ���������ݰ�����ˣ���Sink�ڵ����֮ǰ��Ϊ�˱������ݰ���ڵ�������ʧ�������ݽڵ��֪�������ݰ�����ֻ�洢�ڽڵ㱾�������Dz��÷ֲ�ʽ�洢�����洢�����������С�����ֵ�ش���������ķֲ�ʽ���ݴ洢������Լ���Ϊ��������һ����Ч�ķֲ�ʽ�洢�㷨��������k�����ݽڵ��֪����k��Դ���ݰ��洢���������е�n���ڵ��У�n��k�����������洢�������֮��ʹ�в��ֽڵ��������´洢���еĴ洢���ݰ���ʧ��Sink�ڵ�Ҳ��ͨ������k������δ�ڵ�Ĵ洢���ݰ���ԭ��ԭ����k��Դ���ݰ�������ֵ�ش���������ķֲ�ʽ���ݴ洢�㷨��Ҫ��2�ࡣһ���ǽ�ÿ�����ݽڵ��Դ���ݰ����Ƶ�����ڵ���[2]������Sink�ڳ��ֺ�ֻҪÿ��Դ���ݰ�����һ�������ɷ��ʣ�Դ���ݰ��Ͳ��ᶪʧ�����������ִ�У����ǶԴ������ڵ����Ĵ洢�ռ���һ����ս����һ���Dz��þ�ɾ��ı������k��Դ���ݰ������n���洢���ݰ����ٽ�n���洢���ݰ��洢�������������n���ڵ���[3-8]��������Sink�ڵ���ֺ�ֻҪ�ܷ��ʵ�k�����ϵĴ洢���ݰ������ܰ��վ�ɾ�����������������е�k��Դ���ݰ�����ΰ��[3-4]����˻���RS��ķ��������������������Ҫ��ϸߣ�����Ҫ��ÿ���ڵ㶼����֪�������������ڵ��λ����Ϣ�⣬��Ҫ��ÿ���ڵ�����нϸߵļ�������(��ΪRS��ı������������������Ͻ��е�)��Aly��[5]����˻���Raptor��ķ�������������Raptor����һ�ּ�����ɾ�룬���ַ��������˴洢���̵ĸ��Ӷȣ�������ʵ��Ӧ�á���ߴ��������뱾�ķ�����ص���Kong��[6-8]����Ļ���LT��ķ��������������������Ҫ�ߣ�ÿ���ڵ�ֻ��֪�����ھӽڵ��λ����Ϣ���ɡ��洢�����и÷������ü�������߹���k��Դ���ݰ����͵������е�ÿ���ڵ㣻ÿ���ڵ㰴��LT��ĶȷֶȺ�������һ��������Դ���ݰ�������õ�һ���洢���ݰ��洢������Sink�ڵ���ֺ�ͨ��������Щ�洢���ݰ��ɻָ���ԭ��������Դ���ݰ���Ȼ���÷�����2�������ȱ�㣺һ�Ǽ�������ߵĵ�Ч�ʵ���ÿ��Դ���ݰ�����Ҫ����Զ������ֵ��ܶ�Ĵ������ܱ��������е����нڵ㣬����������������ͨ�ųɱ�������Sink�ڵ�Ϊ�˻ָ������е�k��Դ���ݰ�����Ҫ����k(1+��)���洢���ݰ�(�ˣ�0����k��ȡֵ�й�)��Kong��[6]��ʵ�����k��������Ϊ����ʱ��k(1+��)�ӽ�2k����ˣ������Sink�ڵ�ķ��ʳɱ��ϸߡ������Щ���⣬����Դ���ݰ����ݹ����еĶ���������߹����������ÿ���ڵ��Դ���ݰ��Ķ���������ƣ��������������һ��ִ�м��ף����ܸ�Ч�ķֲ�ʽ���ݴ洢�㷨��
1 ����ģ��
������[6]�еļ�����ͬ�����о�������ֵ�ش������������������ʣ�������n���������ڵ㹹�ɣ�����k���ڵ�Ϊ���ݽڵ㣬ÿ�����ݽڵ�������֪������������һ����С�̶������ݰ�����ΪԴ���ݰ�������ķ����ݽڵ�ֻ�����洢���ݡ�Sink�ڵ�ֻ��Դ���ݰ���ɴ洢֮���һ��ʱ���ڲų��֡�ÿ���������ڵ㶼����ͬ��ͨ�Ű뾶������С��ͨ�Ű뾶�������ڵ㻥��Ϊ�ھӽڵ㣬����ֱ��ͨ�ţ�����ͨ�Ű뾶֮��Ľڵ�ͨ���������Ƽ��ͨ�š���������ͨ�ģ�����2���ڵ㶼��ֱ�ӻ���ͨ�š�������ÿһ���ڵ㶼û��һ��·�ɱ���¼�������ͨ�Ű뾶֮��Ľڵ���ͨ�ţ����2���ڵ�֮��ļ��ͨ����ͨ�����ѡ���м�ڵ�����ɵġ�
ͼ1��ʾΪ���о�������ֵ�ش����������Դ���ݰ��洢�ͷ���ʾ��ͼ��ͼ��Բ�εĵ��ʾ���ݽڵ㣬�����εĵ��ʾ�����ݽڵ㣬���εĵ��ʾSink�ڵ㣬����ͷ����ָʾ�˽ڵ�֮���ͨ��·����

ͼ1 ����ֵ�ش���������ʾ��ͼ
Fig. 1 Unattended wireless sensor network model
Ϊ�˴������Ϸ�������ʵ����ģ��ֲ�ʽ�洢�㷨�����Ľ�����ֵ�ش������������Ϊһ����ά���ͼ[9]�����������ڵ���ͼ�еĸ������ʾ����2���������ڵ㻥Ϊ�ھӽڵ㣬����ͼ�ж�Ӧ�Ķ���֮������һ������ߣ�����ÿ���������ڵ㶼û��·�ɱ������һ���������ڵ�����ݰ�ͨ���������ƴ��ݵ���һ���ڵ�Ĺ��������ͼ��һ���������[9]����ʾ��
��ά���ͼ����������������������£�
��ά���ͼ����һ����λ��������������ȵط���n�����㣬������2����֮���ŷ�Ͼ���С��rʱ(r��ӳ�˴������ڵ��ͨ�Ű뾶)����һ�������������2���㣬�������ɵ�һ��ͼ��Ϊ��ά���ͼ����T(n, r)��ʾ��
������ߣ���ά���ͼ�ϵ�һ��������߶���Ϊ��ijһ������з���ͼ�ж���Ĺ��̡�һ��������߿�ʼ��ijһ���㣬������һ��Ҫ���ʶ����Ǵӵ�ǰ���ʶ�����ھӶ�����ѡȡ�ģ�����һ��Ҫ���ʵ��ھӶ����Ǵӵ�ǰ���ʽڵ�������ھӶ����еȸ������ѡȡ�ģ���ô������������߳�Ϊ��������ߡ�
���ڶ�ά���ͼT(n, r)����r��������
 (1)
(1)
���У�bΪһ������1�ij�������ô�����Լ���ĸ��ʱ�֤ͼT(n, r)����ͨ�ġ�
����һ����ͨ�Ķ�ά���ͼT(n, r)����t��ʾ������ߵIJ�������ô��������߷��ʵ��IJ�ͬ������ռͼ���ܵĶ������ı�������Ϊ��������߶�ͼ�ĸ����ʣ���Ct(T)��ʾ��Ct(T)������ֵ���Խ��Ƶı�ʾΪ[10]��
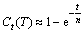 (2)
(2)
����һ����ͨ�Ķ�ά���ͼ����ͼ����һ���㿪ʼ�������������ܹ�����ͼ�е����ж��㣬Ҳ���Ƕ�ͼ�ĸ����ʴﵽ100%����ô��������ߵ�ƽ��������Ϊͼ�ĸ���ʱ�䣬��C(T)��ʾ����ʽ(1)����ʱ��C(T)���Ա�ʾΪ[9]��
 (3)
(3)
��ʽ(3)��֪����t=O(nln n)ʱ��Ct(T)��1��
1.1 ����������߹���
��������в�ͬ�Ĺ������㷨���ö���������߹���[11-12]�������д���ÿ��Դ���ݰ������ն���������߹���ÿ��Դ���ݰ������˵�ǰ���ʵĴ������ڵ�v��Ҫ��v�������ھӽ���ѡ��һ���ڵ�u��Ϊ��һ��Ҫ���ʵĽڵ㡣
��N(o)��ʾ����һ���ڵ�o���ھӽڵ�ļ��ϣ���(o)=|N(o)|��ʾ�ڵ�o���ھӽڵ�ĸ�����c(o)��ʾ�����������Ŀǰ�ѷ��ʽڵ�o�Ĵ�������ô��һ����Ҫ���ʵĽڵ�u��ѡȡ���̷�Ϊ2����
Step 1: �ӵ�ǰ���ʽڵ�v���ھӽڵ㼯��N(v)��������ȵ�ѡ��2���ڵ���Ϊ��ѡ�ڵ㣬���ǹ��ɵļ�����N����ʾ��
Step 2: ��2����ѡ�ڵ���ѡ��������ʽ�Ľڵ�u��Ϊ��һ����Ҫ���ʵĽڵ㣺
 (4)
(4)
2 �ֲ�ʽ���ݴ洢�㷨
���ȸ����㷨���õ��IJ��������Ľ���Щ������Ϊ2�ࣺһ��Ϊ��Ӳ����������������������Ϣ���ֱ����¡�
n����ʾ�����еĴ������ڵ�������
k����ʾ���ݽڵ�������
d����ʾ�ڵ�ͨ�Ű뾶��
N(o)����ʾ�ڵ�o���ھӼ��ϣ�
��(o)����ʾ�ڵ�o���ھӸ�����
Xj����ʾ���ݽڵ�j��Դ���ݰ���j=1��2������k��
IDj����ʾԴ���ݰ�Xj��ID�ţ�
Yi����ʾ�ڵ�i�Ĵ洢���ݰ���i=1��2������n��
cj(i)����ʾԴ���ݰ�Xj�ѷ��ʽڵ�i�ĵ�ǰ������
��һ�����Ӱ�챾���㷨�����ܣ���Ϊֱ�Ӳ������ֱ����¡�
cnln n����ʾ����ÿ��Դ���ݰ��Ķ���������ߵIJ���������c��1Ϊϵ�����ñ���N��¼����������ߵĵ�ǰ������Դ���ݰ�ÿ����һ�Σ�N��ֵ����1��
aln k/k����ʾÿ���ڵ����һ���µ����Դ���ݰ��ĸ��ʣ�����a��1Ϊϵ����
�㷨�Ļ���ԭ�����£�
�洢���̿�ʼ֮ǰ: ÿ���ڵ�(�������ݽڵ�ͷ����ݽڵ�)���洢��һ����ʼֵΪ0�Ĵ洢���ݰ�Yi����С��Դ���ݰ���ͬ������֮�⣬ÿ�����ݽڵ㶼��һ��Դ���ݰ�Xj��
�洢���̿�ʼ��: ��ÿ�����ݽڵ㿪ʼһ������Ϊcnln n�Ķ������������ǰ���ݸ����ݽڵ��Դ���ݰ���ÿ��Դ���ݰ�����һ���µĽڵ�ʱ���½ڵ㰴����aln k/k����Դ���ݰ����������յ�Դ���ݰ�����Լ��Ĵ洢���ݰ��У�(�����Ƿ����)�½ڵ�Ȼ���ն���������߹���Դ���ݰ�������ǰ���ݡ���Դ���ݵĴ��ݴ����ﵽ����������ߵĸ������� cnln n��N > cnln n ʱ��Դ���ݰ���������������ǰ���ݡ������е�k��Դ���ݰ����������������洢������ɡ�
2.1 �ֲ�ʽ���ݴ洢�㷨������
�����㷨�ľ���ʵ����������Ϊ������㷨1��
�㷨1������ֵ�ش���������ķֲ�ʽ���ݴ洢�㷨
���룺k ��Դ���ݰ�Xv��v=1������k��
�����n���洢���ݰ�Yu��u=1������n��
��ʼ
1: /*��ʼ����*/
2: For ÿ�����ݽڵ� v = 1 to k
3: ΪԴ���ݰ�Xv ����ͷ��Ϣ��IDv �ż�����������߲��������� N = 0��
4: For ÿ���ڵ� u = 1 to n
5: ��ʼ��ÿ���洢���ݰ���ֵ��Yu = 0��
6: ��ʼ��ÿ��Դ���ݰ�Xv �ѷ��ʽڵ�u�ĵ�ǰ������
cv(u)=1��v=1������k��
7: /*�ֲ�ʽ�洢��*/
8: For ÿ�����ݽڵ� v = 1 to k
9: ���ո���aln k/k����Xv�����Ҹ����Լ��Ĵ洢���ݰ���Yv=Yv��Xv��
10: ���ն���������߹���Դ���ݰ�Xv���ݵ�����һ���ھӽڵ㣻
11: cv(v)=cv(v)+1��
12: For ÿ���ڵ� u=1 to n
13: For ÿ������ڵ�u��Դ���ݰ�Xj
14: If Xj�ǵ�һ�η��ʽڵ�u
15: �ڵ�u���ո���aln k/k����Xj�����Ҹ����Լ��Ĵ洢���ݰ���Yu=Yu��Xj��
16: cj(u)=cj(u)+1��
17: Դ���ݰ�Xj����ͷ��Ϣ��N=N+1��
18: If N��cnln n��
19: �ڵ�u���ն���������߹���Դ���ݰ�Xj���ݵ�����һ���ھӽڵ㣻
20: Else
21: �ڵ�u����Xj��
����
�㷨1��10��19���е�ǰ�ڵ�ִ�еĶ���������߹�����1.1���е�Step1��Step2���塣
�㷨1���֮�������в��ٴ洢���κ�һ��Դ���ݰ���ȡ����֮����ÿ���ڵ㶼�洢��һ���洢���ݰ���
�㷨1�ĸ��Ӷȼ�Ҫ�������¡�
(1) ͨ�Ÿ��Ӷȡ��㷨1��ִ�й�����ÿ��Դ���ݰ���������cnln n�Σ����k��Դ���ݰ��������е�ͨ�Ŵ���Ϊkcnln n�Ρ�
(2) �洢���Ӷȡ��㷨1ִ�����֮��ÿ���ڵ�洢��һ����Դ���ݰ���С��ͬ�Ĵ洢���ݰ��������õ��ô洢���ݰ�������Դ���ݰ���ID�š�����֮�⣬�㷨ִ�й�����ÿ���ڵ㻹��¼�˸�Դ���ݰ����ʸýڵ�ĵ�ǰ�����������㷨���֮����һ��¼���ٴ洢��
(3) ���㸴�Ӷȡ�����ÿ���ڵ㰴����aln k/k����һ��Դ���ݰ������ƽ������£�ÿ���ڵ������Լk��aln k/k=aln k��Դ���ݰ���������Լalnk��Դ���ݰ�֮���������㡣
2.2 �ֲ�ʽ���ݴ洢�㷨�IJ��������ܷ���
�㷨1�ж���������ߵIJ�����Ҳ����ÿ��Դ���ݰ��������еĴ��ݴ�������Ϊcnln n��Ŀ����Ϊ�˱�֤ÿ��Դ���ݰ����ܴ��ݵ������е�ÿ���ڵ㣻ÿ���ڵ����һ���µ����Դ���ݰ��ĸ�������Ϊaln k/k�������ں����н�����ܵ������潫������2���������㷨���ܵ�Ӱ�졣
���㷨1ִ�����֮��k��Դ���ݰ����ֲ�ʽ�ش洢���������n���ڵ��У�ÿ���ڵ�洢�Ĵ洢���ݰ��������ɸ�Դ���ݰ������͡�
�ٶ�Sink�ڵ���ֺ�����ش�k+�Ÿ�δ�ڵ����ռ���k+�Ÿ��洢���ݰ������Цţ�0Ϊ������Ϊ������������k+�Ÿ��洢���ݰ���Yi��i=1��2������k+�ű�ʾ����Ϊÿ���洢���ݰ�����Դ���ݰ���������ϣ���ˣ�����һ��Yi��i=1��2������n�����Ա�ʾΪ��ʽ(ʽ�еij˷�Ϊ��Ԫ���ϵ�Ԫ����ȡֵ�ڶ�Ԫ���ϵ�����֮�������)��
 (5)
(5)
���У�X1������Xk��ʾk��δ֪��Դ���ݰ���giΪһ����������ȡֵ�ڶ�Ԫ��F2={0��1}�ϵ��������������Ϊ�洢���ݰ�Yi���������������ɴ洢�㷨1��֪��gi��ÿ��Ԫ��gij��j=1������k���Ƕ���ȡֵ���Ҷ�������ʽ����ķֲ���
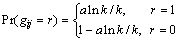 (6)
(6)
��k+�Ÿ��洢���ݰ�������������������һ��(k+��)��k����G(k+��)��k����Ϊk+�Ÿ��洢���ݰ������ɾ���G(k+��)��k=[g1�� g2������gk+��]T���������ɾ�����k+�Ÿ��洢���ݰ����Ա�ʾΪ��
 (7)
(7)
�����Դ������ۿ�֪�������ɾ���G(k+��)��k����һ������k��k���Ӿ���Ҳ����G�����ȣ���ʽ(7)�еķ��������Ψһ��(X1������XkΪδ֪��)��ͨ���ⷽ��������k��δ֪��Դ���ݰ�X1������Xk����ˣ�Sink�ڵ��������k+�Ÿ��洢���ݰ�����õ�k��δ֪��Դ���ݰ��ĸ��ʵȼ�����k+�Ÿ��洢���ݰ������ɾ���G(k+��)��k�����ȣ���Rank(G(k+��)��k) = k�ĸ��ʡ�
2.2.1 �㷨��������
���ڸ����㷨1��ÿ���ڵ����һ���µ����Դ���ݰ��ĸ�������Ϊaln k/k����(G(k+��)��k��ÿ��Ԫ��ȡֵ����ʽ(6)��ԭ��
�����ɾ���G(k+��)��k�У�������Ԫ��ȫΪ0���У���ôG(k+��)��kһ�����в����ȵġ��ٶ����ɾ���G(k+��)��k ��ÿ��Ԫ��ֵΪ1�ĸ���Ϊ�ѣ���ôΪ�˱�֤����ÿһ��������һ��1����
 (8)
(8)
���������ʴ���һ��������1��С���ģ���
 (9)
(9)
�ɴ˵ó���
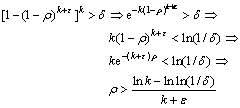 (10)
(10)
��ˣ�Ϊ��ʹʽ(10)���������İѾ���G(k+��)��k��ÿ��Ԫ��ȡֵΪ1�ĸ���Ϊ�ѵ�ֵ����Ϊaln k/k��a��1Ϊϵ����Ҳ����ʹG(k+��)��k��ÿ��Ԫ��ȡֵ����ʽ(6)����ķֲ���
2.2.2 �㷨���ܷ���
��Pfailure��ʾ��Ԫ��F2�ϵ����ɾ���G(k+��)��k�в����ȵĸ��ʣ���ô����ʽ(6)����ʱ�����Եõ����½��ۣ�
����1����G(k+��)��k��ÿ��Ԫ�ص�ȡֵ����ʽ(6)����ķֲ�ʱ��Pfailure���Ͻ�Ϊ��

 (11)
(11)
֤������G(k+��)��k�ĸ���������أ���G(k+��)��k�в����ȣ����
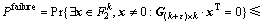
 (12)
(12)
��R��ʾG(k+��)��k������һ������������w��ʾ����x��1�ĸ�������Ϊ������R��ÿһ��Ԫ��ȡֵ��������ȡֵΪ1�ĸ�����ʽ(6)���壬���

 (13)
(13)
��Ϊ����G(k+��)��k��ÿһ�����������������G(k+��)��kxT=0�ĸ���Ϊ

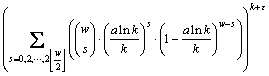 (14)
(14)
������xȡ���в�ͬ��ֵʱ������ʽ(12)�ɵõ�����1�еĽ��ۡ�
����2����G(k+��)��k��ÿ��Ԫ�ص�ȡֵ����ʽ(6)����ķֲ���aln k/k = 1/2ʱ��Pfailure���Ͻ���Լ�ʾΪ��
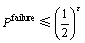 (15)
(15)
֤��������=1/2ʱ
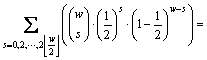
 (16)
(16)
����w��ȡֵΪ��������ż��������
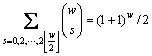 (17)
(17)
��ʽ(17)����ʽ(16)��
 (18)
(18)
��ʽ(18)����ʽ(14)��
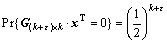 (19)
(19)
��ʽ(19)����ʽ(11)������2��֤��
��1�ͱ�2����Ϊaln k/k�еIJ���a��k����ȡ��ֵͬʱ���ֱ���ʽ(11)��ʽ(15)�����Pfailure���Ͻ���MATLAB�����µ���ֵ��������
��1 a=3.5ʱPfailure���Ͻ����ֵ������
Table 1 Numerical results of upper bound of Pfailure for a=3.5

��2 a=3ʱPfailure���Ͻ����ֵ������
Table 2 Numerical results of upper bound of Pfailure for a=3

�ӱ�1�ͱ�2���Կ��������Ź̶�ʱ������aln k/k�Ƿ����1/2����ʽ(11)�����Pfailure���Ͻ���ʽ(15)�����Pfailure���Ͻ��ǽ�����ȵġ���a���Ź̶�ʱ��Pfailure���Ͻ���k�ı仯������ˣ�Pfailure���Ͻ���Ҫ�ɦž�����������ʽ(15)�ļ�����Ʊ�ʾPfailure���Ͻ硣
�ۺ������������������¶���1�����㷨1�����ܡ�
����1�����÷ֲ�ʽ���ݴ洢�㷨1��Sink�ڵ��������k+�Ÿ��洢���ݰ�����õ�ԭ����k��Դ���ݰ��ĸ���P����ʽ(20)��
 (20)
(20)
�ر�أ�������ֵ��������a��3ʱ��P���Ƶ�������ʽ��
 (21)
(21)
֤������ΪP=1-Pfailure���ۺ�����1������2����ֵ�������ɵñ��������ۡ�
3 ��ֵʵ�鼰����
�����㷨����ֵʵ������MATLAB������ʵ�ֵġ�ʵ���У���100��100������������������ȵķֲ���n����ģ�������������ڵ㣬�������ݽڵ�ı���Ϊ����Ϊ30%����k=0.3n��������ÿ���ڵ��ͨ�Ű뾶d��������d2=2ln n/(��n)��104(��һ������֤�������Լ���ĸ�������ͨ��)��
ʵ���Ϊ2�����֣���1����ʵ����Զ���������ߵIJ��������縲����֮��Ĺ�ϵ����ΪԴ���ݰ���������ʵ�飻��2����ʵ����Դ洢�������֮��Sink�ڵ���Ҫ���ʶ��ٸ��洢���ݰ����ָܻ���ԭ����k��Դ���ݰ�����ΪԴ���ݰ��ָ�����ʵ�顣
3.1 Դ���ݰ���������ʵ��
ÿ��Դ���ݰ�������������߹����������д��ݣ�����ʽ(2)����������ߵIJ���Ϊtʱ�����縲���ʵ�����ֵ����Ϊ1-e-t/n���ر�أ���t=O(nln n)����t=cnln nʱ��Դ���ݰ����Լ���ĸ��ʱ��������е�ÿ���ڵ㣬����ĸ����ʴﵽ1-e-cnln n/n��100%��ʵ�ʵ�Ӧ���У������縲���ʴﵽ���۽���ֵ��ǰ���£�Դ���ݰ����ݴ���Խ�٣���t=cnln n��ֵԽС��Խ�ܽ�Լ�����ͨ���ܺģ����ʵ������Ҫ����ϵ��c�ı仯�����縲���ʵ�Ӱ�죬��Ѱ�����縲���ʴﵽ���۽���ֵ1-e-t/nʱ��ϵ��c����Сֵ��
��Ϊ�Աȣ�ʵ���бȽ��˼�������߹���Ͷ���������߹����Դ���ݰ��������ܵ�Ӱ�졣
ͼ2��ͼ3��ʾΪn��kȡ��ֵͬ������ͬ�����ģ�����£���������߲���t�ֱ�����Ϊt=cn��t=cnln nʱ����ֵʵ������
��ͼ2��ͼ3���Կ��������ö���������߹���k��Դ���ݰ������縲����ƽ��ֵ��ʵ����ֵ��������ֵ1-e-t/n�ǽ�����ȵģ����ҵ�Դ���ݰ����ݴ�������2nln nʱ����c����2ʱ�����е�k��Դ���ݰ������������������еĽڵ㣬�����ü�������߹���k��Դ���ݰ������縲����ƽ��ֵ��ʵ����ֵ����С��������ֵ1-e-t/n������ֻ�е�������߲�������4.5nln nʱ����c����4.5ʱ�����е�k��Դ���ݰ����ܸ������������нڵ㡣��˲��ö���������߹����Դ���ݰ����ݷ������ܸ��ţ���ʵ��Ӧ���У�Ҫʹ���縲���ʴﵽ100%ʱ��c����Сֵ������Ϊ2��

ͼ2 Դ���ݰ��������ܲ���(������߲���t=cn)
Fig. 2 Source data packet transmitting performance for t=cn

ͼ3 Դ���ݰ��������ܲ���(������߲���t=cnln n)
Fig. 3 Source data packet transmitting performance for t=cnln n
3.2 Դ���ݰ��ָ�����ʵ��
ʵ����Ե��洢�������֮��Sink�ڵ���Ҫ���ʶ��ٸ��洢���ݰ����ܼ�������е�Դ���ݰ���Ҳ���Dz������涨���2������֮��Ĺ�ϵ��
Դ���ݰ��ָ������ǣ�Sink�ڵ���ʵĴ洢���ݰ�����h��Դ���ݰ�����k֮�����=h-k��
Դ���ݰ��ָ��ɹ���S��Sink�ڵ��ܹ���h�����ʵ��Ĵ洢���ݰ������k��Դ���ݰ��ĸ��ʡ�
ʵ���в��ö���������߹���ÿ��Դ���ݰ���ÿ��Դ���ݰ��Ĵ��ݴ�������Ϊ2nln n��
ͼ4��ͼ5��ʾΪn��kȡ��ֵͬ����ÿ���������ڵ����һ���µ����Դ���ݰ��ĸ���aln k/k��ϵ��a�ֱ�����Ϊa=2(ͼ4)��a=3(ͼ5) ʱԴ���ݰ��ָ��ɹ���S��Դ���ݰ��ָ�������֮��Ĺ�ϵ��
��ͼ�п��Կ�����ʵ���е�Sink�ڵ��ռ����Ĵ洢���ݰ���������k+8ʱ��Ҳ��Դ���ݰ��ָ������Ǵﵽk+8-k=8ʱ���ܼ����k��Դ���ݰ��ĸ���S�ﵽ��100%����ǡ����֤�˶���1�Ľ��ۣ��������������ģ��Ҳ��������n��kȡֵ��Σ�ֻҪÿ���������ڵ����һ���µ����Դ���ݰ��ĸ��ʷ���ʽ(6)����ķֲ���������Sink�ڵ��������k+�Ÿ��洢���ݰ�����õ�ԭ����k��Դ���ݰ��ĸ���S���ƴ���1-2��������=8ʱ��������S���ƴ���1-28��99.6%��
3.3 ���ܱȽϷ���
����[6]������Ļ���LT��ķ������뱾�ķ����������ߴ����Ե�һ�ַ�����������ͨ��ʵ��ȽϺͷ�����2�ַ�����Դ���ݰ��������ܺ�Դ���ݰ��ָ����ܡ���3~5����Ϊ2�ַ�������ֵʵ������
��3����Ϊ��Դ���ݰ���������ʵ���У��ڱ�֤ÿ��Դ���ݰ����ܷ��������е����нڵ��ǰ���£�ƽ��ÿ��Դ���ݰ��������еĴ��ݴ����Աȡ�
�ӱ�3��֪�����ñ�����ÿ��Դ�����������еĴ��ݴ���������[6]�з�����37% ~ 45%��ƽ��ֵԼΪ39%����ʵ��Ӧ���д���Դ���ݰ���ζ�������нڵ�ͨ�����������ģ����������[6]�з�����ȣ����ķ�������ʵ��Ӧ���н�Լ55% ~ 63%��ͨ���ܺ�(ƽ��ֵԼΪ61%)��
��4���5����Ϊ2�ַ�����Դ���ݰ��ָ����ܶԱ�ʵ����ֵ����������[6]�ķ����ǻ���LT��ģ����Sink�ڵ�Ϊ�˻ָ���k��Դ���ݰ�����Ҫ���ʵĴ洢���ݰ��ĸ�������LT������������йأ�������LT��������������۷���[13]��������[6]��ʵ�鶼��������kΪ����ʱ��ֻ�е�Դ���ݰ��ָ������ǽӽ�k��ֵʱ��Sink�ڵ�IJ��ܳɹ��ָ���Դ���ݰ�����4�ͱ�5����ʵ����ֵ��֤����һ���ۡ�
�ӱ�4���Կ�������������[6]�з�����Sink�ڵ���Ҫ����Լ200���洢���ݰ�������100%�ĸ��ʻָ���ԭ����100��Դ���ݰ��������ñ��ķ�����Sink�ڵ������110���洢����������100%�ĸ��ʻָ���ԭ����100��Դ���ݰ������ʳɱ���Լ��45%�� ͬ���أ��ӱ�5���Կ�������������[6]�з�����Sink�ڵ���Ҫ����520���洢���ݰ�������100%�ĸ��ʻָ���ԭ����300��Դ���ݰ��������ñ��ķ�����Sink�ڵ������310���洢����������100%�ĸ��ʻָ���ԭ����300��Դ���ݰ������ʳɱ���Լ��40%��
��3 ƽ��ÿ��Դ���ݰ����ݴ����Ա�(Դ���ݰ������縲����Ϊ100%)
Table 3 Average transmitting times of every source data packet in network on condition that every source data packet covers whole network

��4 Դ���ݰ��ָ����ܶԱ�(n=300, k=100, a=2)
Table 4 Comparison of source data packet recovery performance for n=300, k=100, a=2

��5 Դ���ݰ��ָ����ܶԱ�(n=900, k=300, a=2)
Table 5 Comparison of source data packet recovery performance for n=900, k=300, a=2

�����������Եó����ۣ����ñ�����������Ч��Լ�洢�����е�ͨ�ųɱ���Sink�ڵ�ķ��ʳɱ���
4 ����
(1) ����Դ���ݰ����ݹ����еĶ�����������ƺ�����ÿ���ڵ��Դ���ݰ��Ķ�������������ƣ������һ�ּ�Ч�ķֲ�ʽ�����ݴ洢�㷨��
(2) ��ͬ�����ȣ���������Ч�����˴洢�����и��������ڵ��ͨ���ܺĺ�Sink�ڵ�ķ��ʳɱ���
(3) ���㷨��k��Դ���ݰ�����Ϊһ���������洢�ģ��洢���֮��Sink�ڵ��ڷ��ʹ�����ֻ��һ���Եػָ���k��Դ���ݰ�����δ�����о������У��������������û���Ҫ�����ش洢�Ͷ�ȡij���ض�Դ���ݰ���
�ο����ף�
[1] ε�Դ�, ��ˮ��, ��٥��. ���ߴ��������������ݴ洢������о���չ[J]. ����ѧ��, 2008, 36(10): 2001-2010.
YU Zhaochun, ZHOU Shuigeng, GUAN Jihong. Data storage and access in wireless sensor networks: A survey[J]. Acta Electronica Sinica, 2008, 36(10): 2001-2010.
[2] Vitali D, Spognardi A, Villani A, et al. Replication schemes in unattended wireless sensor networks[C]//Proceedings of 2011 4th IFIP International Conference on New Technologies, Mobility and Security. Paris: IFIP, 2011: 1-5.
[3] ��ΰ, ����, �Ż�, ��. ����ֵ�����ߴ�����������һ�ְ�ȫ��Ч�����ݴ�����[J]. ������о��뷢չ, 2009, 46(12): 2093-2100.
REN Wei, REN Yi, ZHANG Hui, et al. A secure and efficient data survival strategy in unattended wireless sensor networks[J]. Journal of Computer Research and Development, 2009, 46(12): 2093-2100.
[4] Madsen T K, Grauballe A, Jensen M G, et al. Reliable cooperative information storage in wireless sensor networks[C]//Proceedings of the IEEE International Conference on Telecommunications. Petersburg: IEEE, 2008: 1-6.
[5] Aly S A, Kong Z, Soljanin E. Raptor codes based distributed storage algorithms for wireless sensor networks[C]//Proceedings of the IEEE International Symposium on Information Theory. Toronto: IEEE, 2008: 2051-2055.
[6] Kong Z, Aly S A, Soljanin E. Decentralized coding algorithms for distributed storage in wireless sensor networks[J]. IEEE Journal on Selected Areas in Communications, 2010, 28(2): 261-267.
[7] Jamalipour J S. Distributed data storage in large-scale sensor networks based on LT codes[EB/OL]. [2012-01-21]. http://arxiv.org/ftp/arxiv/ papers/1201/1201.4479.pdf.
[8] Aly S A, Kong Z, Soljanin E. Fountain codes based distributed storage alogorithms for large-scale wireless sensor networks[C]//Proceedings of the IEEE 7th international Conference on Information Processing in Sensor Networks. Louis: IEEE, 2008: 171-182.
[9] Cooper C, Frieze A. The cover time of random geometric graphs[J]. Random Structures and Algorithms, 2011, 38(3): 324-349.
[10] Tzevelekas L, Oikonomou K, Stavrakakis I. Random walk with jumps in large-scale random geometric graphs[J]. Computer Communications, 2010, 33(13): 1505-1514.
[11] Avin C, Krishnamachari B. The power of choice in random walks: An empirical study[J]. Computer Networks, 2008, 52(1): 44-60.
[12] Avin C, Krishnamachari B. The power of choice in random walks: An empirical study[C]//Proceedings of the 9th ACM International Symposium on Modeling Analysis and Simulation of Wireless and Mobile Systems. New York: ACM, 2006: 219-228.
[13] Shokrollahi A. Raptor codes[J]. IEEE Transactions on Information Theory, 2006, 52(6): 2551-2567.
(�༭ �°���)
�ո����ڣ�2013-02-23�������ڣ�2013-05-05
������Ŀ�������ص�����о���չ�ƻ�(��973���ƻ�)��Ŀ(2011CB302402)�����Ҹ����о���չ�ƻ�(��863���ƻ�)��Ŀ(2008AA01Z402)
ͨ�����ߣ�Ф����(1983-)���У�ɽ��˷���ˣ���ʿ�о�����������Ϣ���뼰��Ϣ�洢���о����绰��15008428215��E-mail��yilongxiao@foxmail.com

